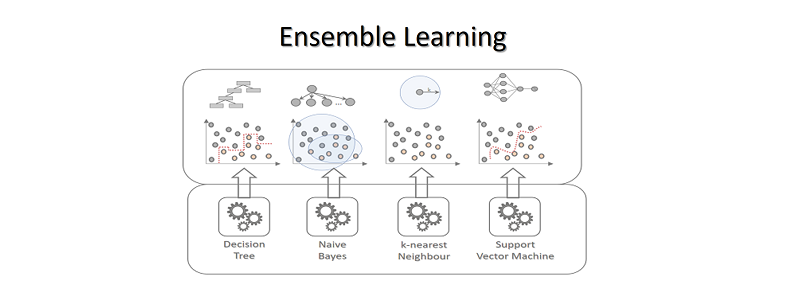
Ensemble Learning
Stellen Sie sich vor, Sie haben die Frage Ihres Lebens vor sich. Die korrekte Beantwortung dieser Frage wird Ihr Leben positiv beeinflussen, andernfalls negativ. Aber Sie haben Glück: Sie dürfen einen Experten, den Sie auswählen dürfen, um Rat fragen oder Sie dürfen eine annonyme Gruppe, sagen wir 1.000 Personen, um Rat fragen. Welchen Rat würden Sie sich einholen? Die einzelne Experten-Meinung oder die aggriegierte Antwort einer ganzen Gruppe von Menschen?
Oder wie wäre es mit einer Gruppe von Experten?
Ensemble Learning
Beim Einsatz eines maschinellen Lernalgorithmus auf ein bestimmtes Problem kann durchaus eine angemessene Präzision (Accuracy, eine Quote an Prädiktionsergebnissen, die als korrekt einzustufen sind) erzielt werden, doch oftmals reicht die Verlässlichkeit eines einzelnen Algorithmus nicht aus. Algorithmen können mit unterschiedlichen Parametern verwendet werden, die sich bei bestimmten Daten-Situationen verschieden auswirken. Bestimmte Algorithmen neigen zur Unteranpassung (Underfitting), andere zur Überanpassung (Overfitting).
Soll Machine Learning für den produktiven Einsatz mit bestmöglicher Zuverlässigkeit entwickelt und eingesetzt werden, kommt sinnvollerweise Ensemble Learning zum Einsatz. Beim Ensemble Learning wird ein Ensemble (Kollektiv von Prädiktoren) gebildet um ein Ensemble Average (Kollektivmittelwert) zu bilden. Sollte also beispielsweise einige Klassifizierer bei bestimmten Daten-Eingaben in ihren Ergebnissen ausreißen, steuern andere Klassifizierer dagegen. Ensemble Learning kommt somit in der Hoffnung zum Einsatz, dass eine Gruppe von Algorithmen ein besseres Ergebnis im Mittel erzeugen als es ein einzelner Algorithmus könnte.
Ich spreche nachfolgend bevorzugt von Klassifizierern, jedoch kommt Ensemble Learning auch bei der Regression zum Einsatz.
Voting Classifiers (bzw. Voting Regressors)
Eine häufige Form – und i.d.R. auch als erstes Beispiel eines Ensemble Learners – ist das Prinzip der Voting Classifiers. Das Prinzip der Voting Classifiers ist eine äußerst leicht nachvollziehbare Idee des Ensemble Learnings und daher vermutlich auch eine der bekanntesten Form der Kollektivmittelwert-Bildung. Gleich vorweg: Ja, es gibt auch Voting Regressors, jedoch ist dies ein Konzept, das nicht ganz ohne umfassendere Aggregation auf oberster Ebene auskommen wird, daher wäre für die Zwecke der akkurateren Regression eher das Stacking (siehe unten) sinnvoll.
Eine häufige Frage im Data Science ist, welcher Klassifizierer für bestimmte Zwecke die besseren sind: Entscheidungsbäume, Support-Vector-Machines, k-nächste-Nachbarn oder logistische Regressionen?
Warum nicht einfach alle nutzen? In der Tat wird genau das nicht selten praktiziert. Das Ziel dieser Form des Ensemble Learnings ist leicht zu erkennen: Die unterschiedlichen Schwächen aller Algorithmen sollen sich – so die Hoffnung – gegenseitig aufheben. Alle Algorithmen (dabei können auch mehrere gleiche Algorithmen mit jedoch jeweils unterschiedlichen Paramtern gemeint sein, z. B. mehrere knN-Klassifizierer mit unterschiedlichen k-Werten und Dimensionsgewichtungen) werden auf dasselbe Problem hin trainiert.
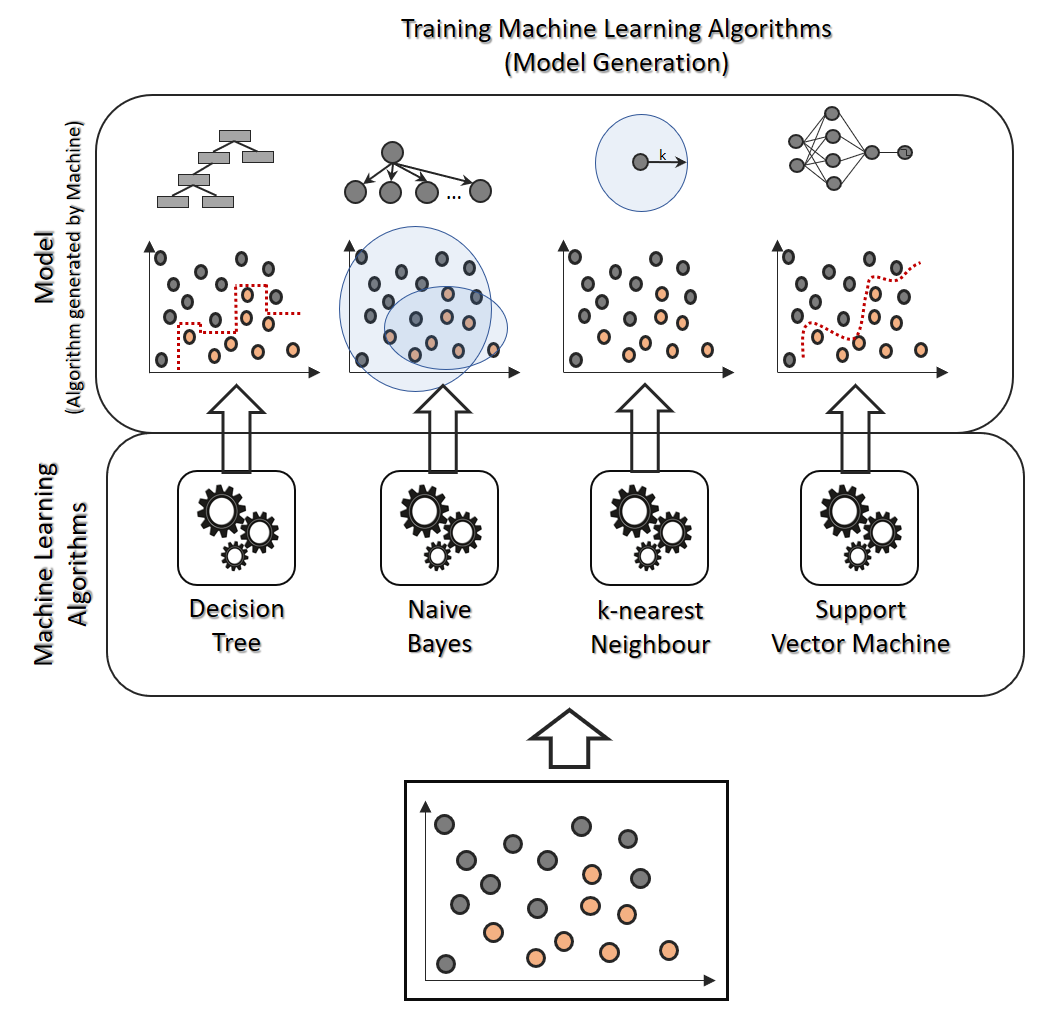
Bei der Prädiktion werden entweder alle Klassifizierer gleich behandelt oder unterschiedlich gewichtet (wobei größere Unterschiede der Gewichtungen unüblich, und vermutlich auch nicht sinnvoll, sind). Entsprechend einer Ensemble-Regel werden die Ergebnisse aller Klassifizierer aggregiert, bei Klassifikation durch eine Mehrheitsentscheidung, bei Regression meistens durch Durchschnittsbildung oder (beim Stacking) durch einen weiteren Regressor.
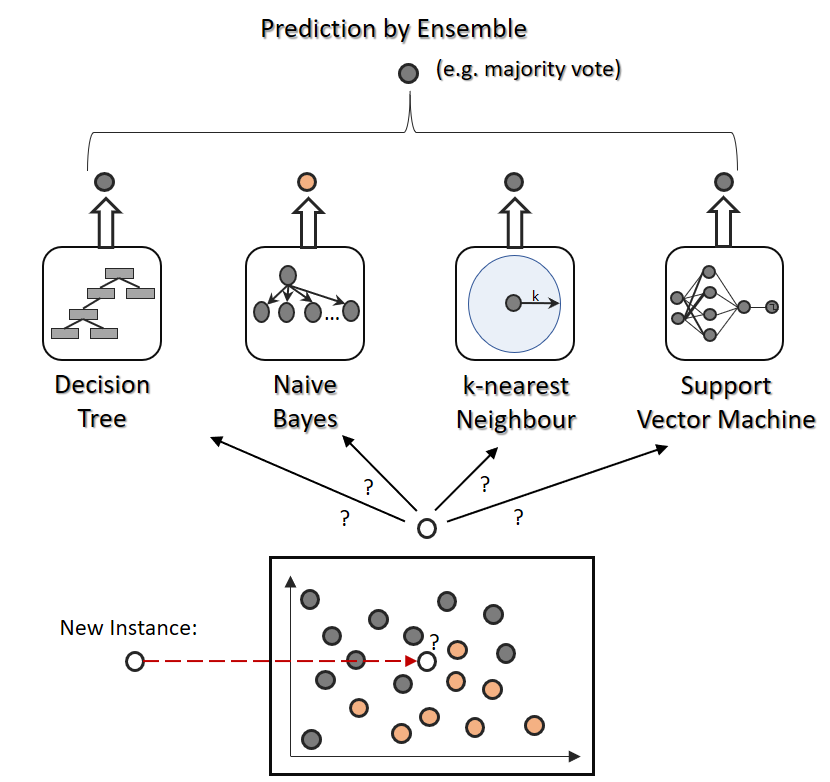 Abgesehen davon, dass wir mit dem Ensemble-Klassifizierer bzw. Regressoren vermutlich bessere Ergebnisse haben werden, haben wir nun auch eine weitere Information hinzubekommen: Eine Entropie über die Wahrscheinlichkeit. Bestenfalls haben alle Klassifizierer die gleiche Vorhersage berechnet, schlechtestensfalls haben wir ein Unentschieden. So können wir Vorhersagen in ihrer Aussagekraft bewerten. Analog kann bei Regressionen die Varianz der Ergebnisse herangezogen werden, um das Ergebnis in seiner Aussagekraft zu bewerten.
Abgesehen davon, dass wir mit dem Ensemble-Klassifizierer bzw. Regressoren vermutlich bessere Ergebnisse haben werden, haben wir nun auch eine weitere Information hinzubekommen: Eine Entropie über die Wahrscheinlichkeit. Bestenfalls haben alle Klassifizierer die gleiche Vorhersage berechnet, schlechtestensfalls haben wir ein Unentschieden. So können wir Vorhersagen in ihrer Aussagekraft bewerten. Analog kann bei Regressionen die Varianz der Ergebnisse herangezogen werden, um das Ergebnis in seiner Aussagekraft zu bewerten.
Betrachtung im Kontext von: Eine Kette ist nur so stark, wie ihr schwächstes Glied
Oft heißt es, dass Ensemble Learning zwar bessere Ergebnisse hervorbringt, als der schwächste Klassifizier in der Gruppe, aber auch schlechtere als der beste Klassifizierer. Ist Ensemble Learning also nur ein Akt der Ratlosigkeit, welcher Klassifizierer eigentlich der bessere wäre?
Ja und nein. Ensemble Learning wird tatsächlich in der Praxis dazu verwendet, einzelne Schwächen abzufangen und auch Ausreißer-Verhalten auf bisher andersartiger Daten abzuschwächen. Es ist ferner jedoch so, dass Ensemble Learner mit vielen Klassifizieren sogar bessere Vorhersagen liefern kann, als der beste Klassifizierer im Programm.
Das liegt an dem Gesetz der großen Zahlen, dass anhand eines Beispiels verdeutlicht werden kann: Bei einem (ausbalanzierten) Münzwurf liegt die Wahrscheinlichkeit bei genau 50,00% dafür, Kopf oder Zahl zu erhalten. Werfe ich die Münze beispielsweise zehn Mal, erhalte ich aber vielleicht drei Mal Kopf und sieben mal Zahl. Werfe ich sie 100 Mal, erhalte ich vielleicht 61 Mal Kopf und 39 Mal Zahl. Selbst nur 20 Mal die Zahl zu erhalten, wäre bei nur 100 Würfen gar nicht weit weg von unwahrscheinlich. Würde ich die Münze jedoch 10.000 Male werfen, würde ich den 50% schon sehr annähern, bei 10 Millionen Würfen wird sich die Verteilung ganz sicher als Gleichverteilung mit 50,0x% für Kopf oder Zahl einpendeln.
Nun stellt man sich (etwas überspitzt, da analog zu den Wünzwürfen) nun einen Ensemble Learner mit einer Gruppe von 10.000 Klassifiziern vor. Und angenommen, jeder einzelne Klassifizierer ist enorm schwach, denn eine richtige Vorhersage trifft nur mit einer Präzision von 51% zu (also kaum mehr als Glücksspiel), dann würde jedoch die Mehrheit der 10.000 Klassifizierer (nämlich 51%) richtig liegen und die Mehrheitsentscheidung in den absolut überwiegenden Fällen die korrekte Vorhersage treffen.
Was hingehen in diesem Kontext zutrifft: Prädiktionen via Ensemble Learning sind zwangsläufig langsam. Durch Parallelisierung der Klassifikation kann natürlich viel Zeit eingespart werden, dann ist das Ensemble Learning jedoch mindestens immer noch so langsam, wie der langsamste Klassifizierer.
Bagging
Ein Argument gegen den Einsatz von gänzlich verschiedenen Algortihmen ist, dass ein solcher Ensemble Learner nur schwer zu verstehen und einzuschätzen ist (übrigens ein generelles Problem im maschinellen Lernen). Bereits ein einzelner Algorithmus (z. B. Support Vector Machine) kann nach jedem Training alleine auf Basis der jeweils ausgewählten Daten (zum Training und zum Testen) recht unterschiedlich in seiner Vorhersage ausfallen.
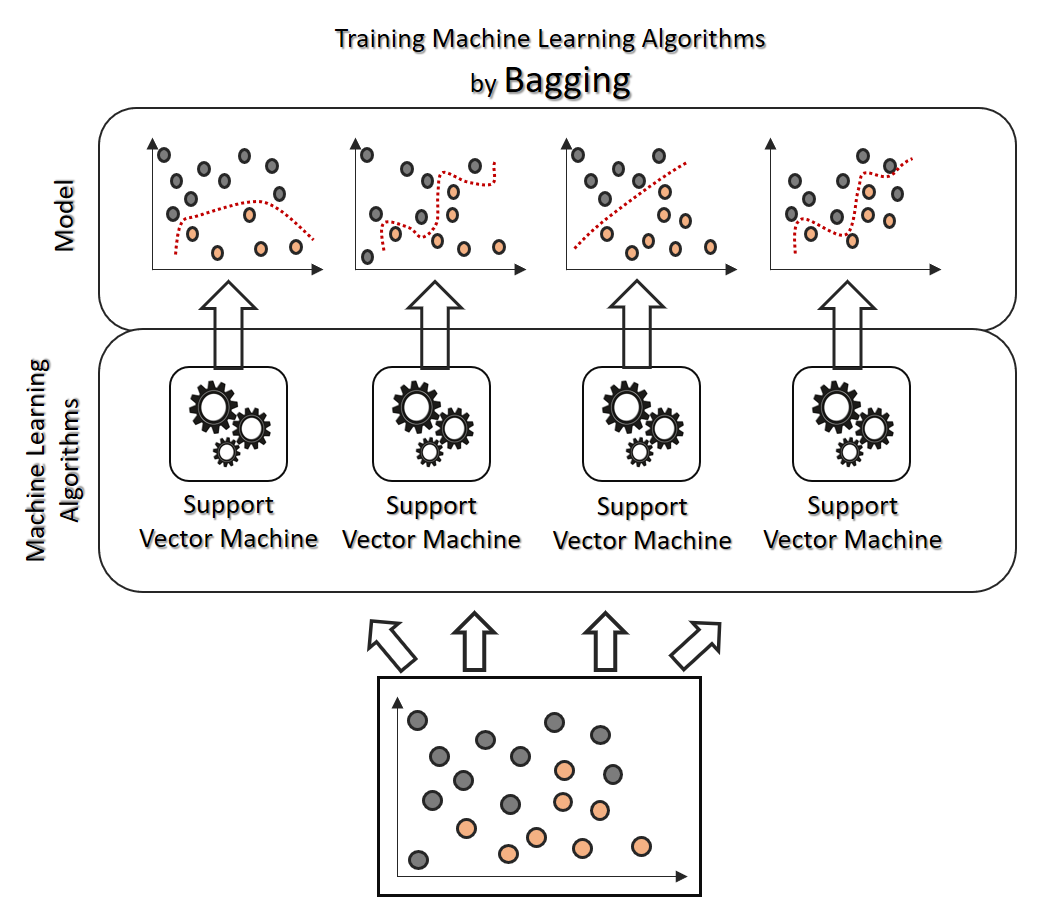
Bagging (kurze Form von Bootstrap Aggregation) ist ein Ensemble Learning Prinzip, bei dem grundsätzlich der gleiche Algorithmus parallel mit unterschiedlichen Aufteilungen der Daten trainiert (und natürlich getestet) wird. Die Aufteilung der Daten kann dabei komplett (der vollständige Datensatz wird verteilt und verwendet) oder auch nur über Stichproben erfolgen (dann gibt es mehrfach verwendete Datenpunkte, aber auch solche, die überhaupt nicht verwendet werden). Das Ziel ist dabei insbesondere, im Endergebnis Unter- und Überanpassung zu vermeiden. Gibt es viele Dichte-Cluster und Ausreißer in den Daten, wird nicht jeder Klassifizierer sich diesen angepasst haben können. Jede Instanz der Klassifizierer erhält weitgehend unterschiedliche Daten mit eigenen Ausreißern und Dichte-Clustern, dabei darf es durchaus Überschneidungen bei der Datenaufteilung geben.
Pasting
Pasting ist fast genau wie Bagging, nur mit dem kleinen aber feinen Unterschied, dass sich die Datenaufteilung nicht überschneiden darf. Wird ein Datenpunkt durch Zufallsauswahl einem Klassifizierer zugewiesen, wird er nicht mehr für einen anderen Klassifizierer verwendet. Über die Trainingsdaten des einen Klassifizierers verfügt demnach kein anderer Klassifizierer. Die Klassifizierer sind somit völlig unabhängig voneinander trainiert, was manchmal explizit gewollt sein kann. Pasting setzt natürlich voraus, dass genug Daten vorhanden sind. Diese Voraussetzung ist gleichermaßen auch eine Antwort auf viele Probleme: Wie können große Datenmengen schnell verarbeitet werden? Durch die Aufteilung ohne Überschneidung auf parallele Knoten.
Random Forest
Random Forests sollten an dieser Stelle im Text eigentlich nicht stehen, denn sie sind ein Beispiel des parallelen Ensembles bzw. des Voting Classifiers mit Entscheidungsbäumen (Decision Trees). Random Forests möchte ich an dieser Stelle dennoch ansprechen, denn sie sind eine äußerst gängige Anwendung des Baggings oder (seltener) auch des Pastings für Entscheidungsbaumverfahren. Die Datenmenge wird durch Zufall aufgeteilt und aus jeder Aufteilung heraus wird ein Entscheidungsbaum erstellt. Eine Mehrheitsentscheidung der Klassifikationen aller Bäume ist das Ensemble Learning des Random Forests.
Random Forest ist ein Verfahren der Klassifikation oder Regression, das bereits so üblich ist, dass es mittlerweile längst in (fast) allen Machine Learning Bibliotheken implemeniert ist und – dank dieser Implementierung – in der Anwendung nicht komplizierter, als ein einzelner Entscheidungsbaum.
Stacking
Stacking ist eine Erweiterung des Voting Classifiers oder Voting Regressors um eine höhere Ebene (Blending-Level), die die beste Aggregation der Einzel-Ergebnisse erlernt. An der Spitze steht beim Stacking (mindestens) ein weiterer Klassifikator oder Regressor
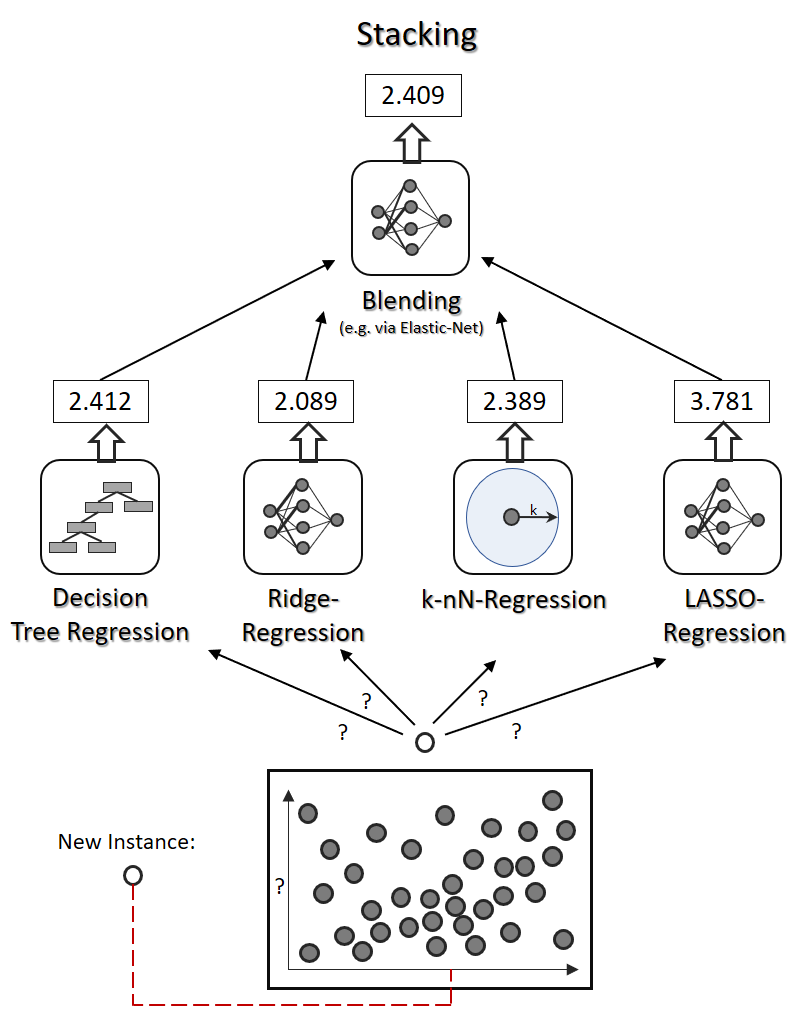 Stacking ist insbesondere dann sinnvoll, wenn die Ergebnisse der einzelnen Algorithmen sehr unterschiedlich ausfallen können, was bei der Regression – da stetige Werte statt wenige Klassen – nahezu immer der Fall ist. Stacking-Algorithmen können sogar mehrere Schichten umfassen, was ihr Training wesentlich schwieriger gestaltet.
Stacking ist insbesondere dann sinnvoll, wenn die Ergebnisse der einzelnen Algorithmen sehr unterschiedlich ausfallen können, was bei der Regression – da stetige Werte statt wenige Klassen – nahezu immer der Fall ist. Stacking-Algorithmen können sogar mehrere Schichten umfassen, was ihr Training wesentlich schwieriger gestaltet.
Boosting (Sequential Ensemble Learning)
Bagging, Pasting und Stacking sind parallele Verfahren des Ensemble Learning (was nicht bedeutet, dass die parallel dargestellten Algorithmen in der Praxis nicht doch sequenziell abgearbeitet werden). Zwangsweise sequenziell durchgeführt wird hingegen das Boosting, bei dem wir schwache Klassifizierer bzw. Regressoren durch Iteration in ihrem Training verstärken wollen. Boosting kann somit als eine Alternative zum Deep Learning gesehen werden. Während beim Deep Learning ein starker Algorithmus durch ein mehrschichtiges künstliches neuronales Netz dafür entworfen und trainiert wird, um ein komplexes Problem zu lösen (beispielsweise Testerkennung [OCR]), können derartige Herausforderungen auch mit schwächeren Klassifikatoren unter Einsatz von Boosting realisiert werden.
Boosting bezieht sich allein auf das Training und ist aus einer Not heraus entstanden: Wie bekommen wir bessere Prädiktionen mit einem eigentlich schwachen Lernalgorithmus, der tendenziell Unteranpassung erzeugt? Boosting ist eine Antwort auf Herausforderungen der Klassifikation oder Regression, bei der ein Algorithmus iterativ, also in mehreren Durchläufen, durch Anpassung von Gewichten trainiert wird.
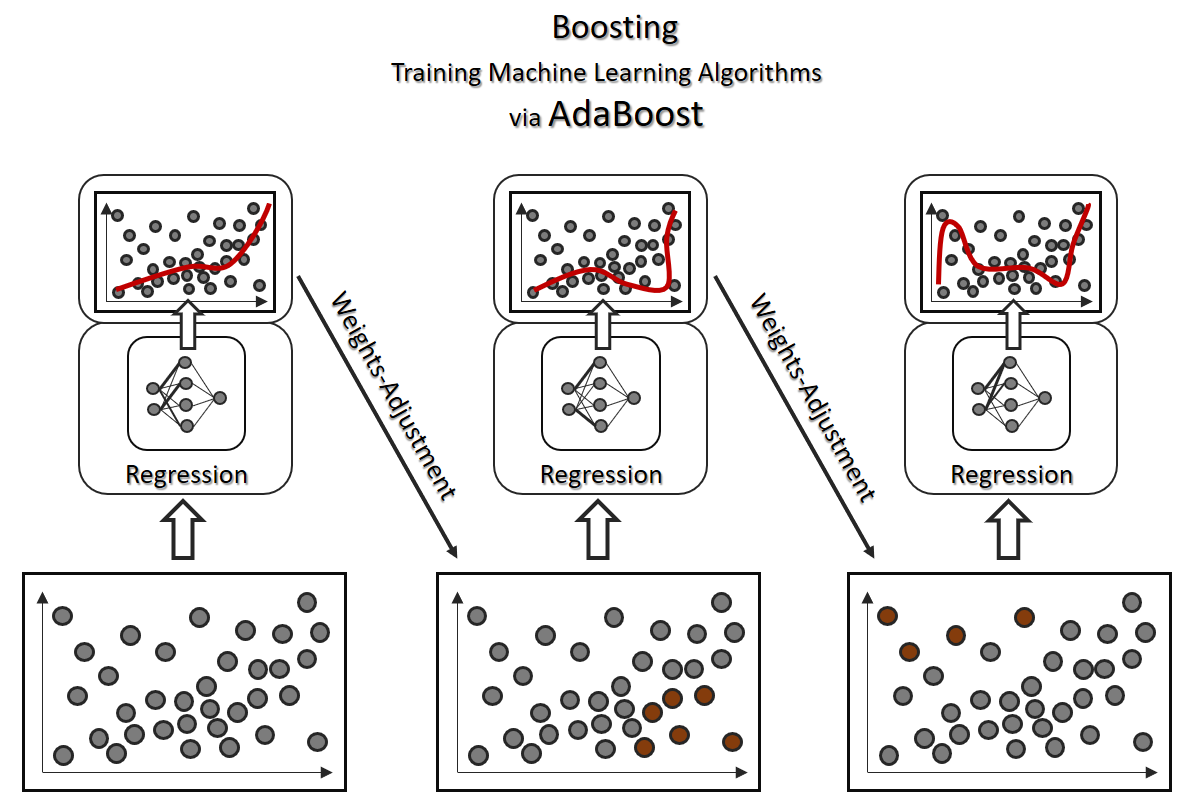 Eines der bekanntesten Boosting-Verfahren ist AdaBoost. Der erste Schritt ist ein normales Training. Beim darauffolgenden Testen zeigen sich Klassifikations-/Regressionsfehler. Die fehlerhaft vorhergesagten Datenpunkte werden dann für einen nächsten Durchlauf höher gewichtet. Diese Iteration läuft einige Male, bis die Fehlerquote sich nicht mehr verbessert.
Eines der bekanntesten Boosting-Verfahren ist AdaBoost. Der erste Schritt ist ein normales Training. Beim darauffolgenden Testen zeigen sich Klassifikations-/Regressionsfehler. Die fehlerhaft vorhergesagten Datenpunkte werden dann für einen nächsten Durchlauf höher gewichtet. Diese Iteration läuft einige Male, bis die Fehlerquote sich nicht mehr verbessert.
Bei AdaBoost werden falsch vorhergesagte Datensätze im jeweils nächsten Durchlauf höher gewichtet. Bei einem alternativen Boosing-Verfahren, dem Gradient Boosting (auf Basis der Gradientenmethode), werden Gewichtungen explizit in Gegenrichtung des Prädiktionsfehlers angepasst.
Was beispielsweise beim Voting Classifier der Random Forest ist, bei dem mehrere Entscheidungsbäume parallel arbeiten, sind das Äquvivalent beim Boosting die Gradient Boosted Trees, bei denen jeder Baum nur einen Teil der Daten akkurat beschreiben kann, die sequentielle Verschachtelung der Bäume jedoch auch herausfordernde Klassifikationen meistert.
Um bei dem Beispiel der Entscheidungsbäume zu bleiben: Sowohl Random Forests als auch Gradient Boosted Trees arbeiten grundsätzlich mit flachen Bäumen (schwache Klassifikatoren). Gradient Boosted Trees können durch die iterative Verstärkung generell eine höhere Präzision der Prädiktion erreichen als Random Forests, wenn die Feature- und Parameter-Auswahl bereits zu Anfang sinnvoll ist. Random Forests sind hingegen wiederum robuster bei der Feature- und Parameter-Auswahl, verstärken sich jedoch nicht gegenseitig, sondern sind in ihrem Endergebnis so gut, wie die Mehrheit der Bäume.
Buchempfehlungen
Mehr zum Thema Machine Learning und Ensemble Learning gewünscht? Folgende zwei Buchempfehlungen bieten nicht nur Erklärungen, sondern demonstrieren Ensemble Learning auch mit Beispiel-Code mit Python Scikit-Learn.








Trackbacks & Pingbacks
[…] Ensemble learning which included multiple learners, i.e. Machine Learning algorithms, may take much longer time than expected to develop. When using a search grid for parameter optimization to train an ensemble, depending on the included algorithms, the number of variables, and the corresponding iterations based on combinations of parameter settings and with cross validation, it may take a while to produce results, assuming not running out of computing resources. […]
Leave a Reply
Want to join the discussion?Feel free to contribute!