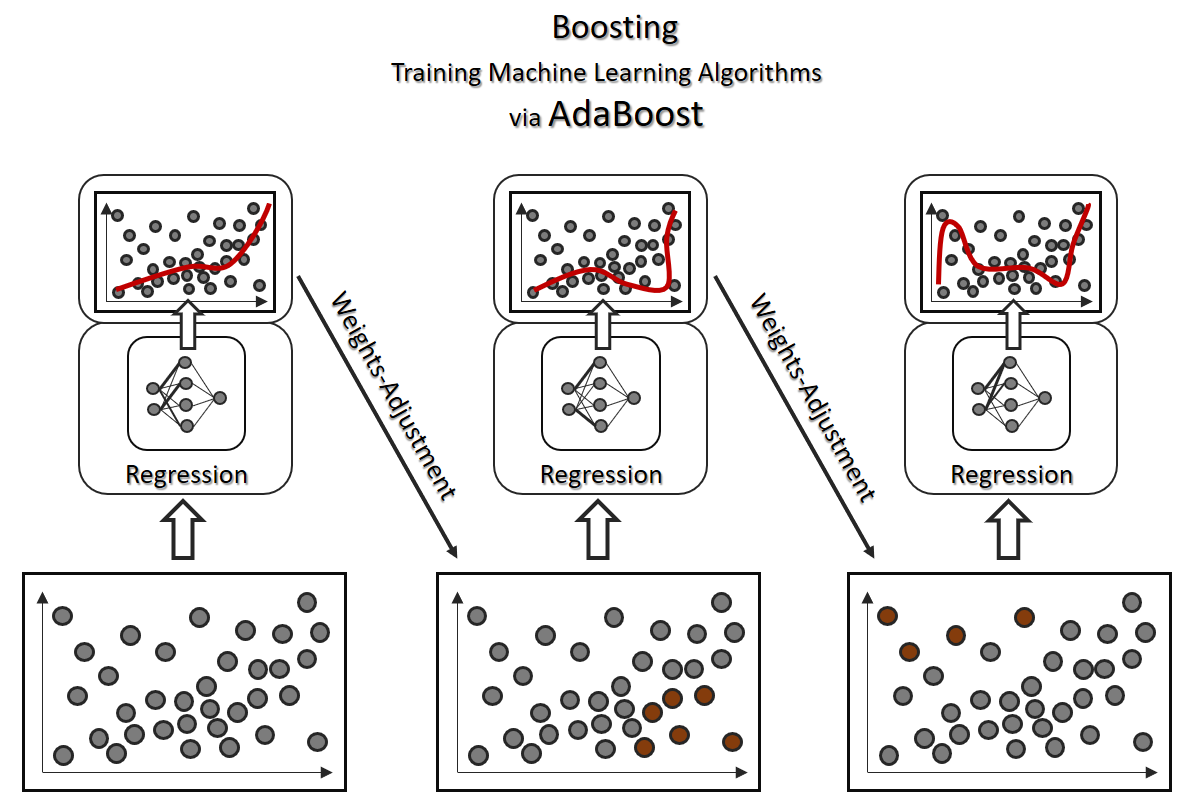
Maschinelles Lernen: Klassifikation vs Regression
Das ist Artikel 2 von 4 aus der Artikelserie – Was ist eigentlich Machine Learning? Die Unterscheidung zwischen Klassifikation und Regression ist ein wichtiger Schritt für das Verständnis von Predictive Analytics. Nun möchte ich eine Erklärung liefern, die den Unterschied (hoffentlich) deutlich macht.
Regression – Die Vorhersage von stetigen Werten
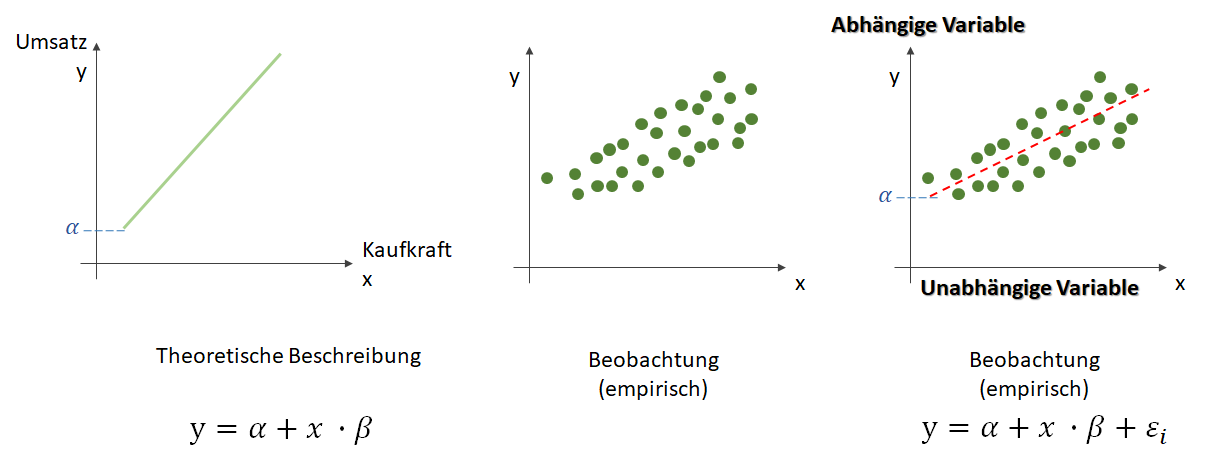 Wir suchen bei der Regression demnach eine Funktion
Wir suchen bei der Regression demnach eine Funktion  , die unsere Punktwolke – mit der wir uns zutrauen, Vorhersagen über die abhängige Variable vornehmen zu können – möglichst gut beschreibt. Dabei ist
, die unsere Punktwolke – mit der wir uns zutrauen, Vorhersagen über die abhängige Variable vornehmen zu können – möglichst gut beschreibt. Dabei ist  der Zielwert (abhängige Variable) und
der Zielwert (abhängige Variable) und  der Eingabewert. Wir arbeiten also in einer zwei-dimensionalen Welt. Variablen, die die Funktion mathematisch definieren, werden oft als griechische Buchstaben darsgestellt. Die Variable
der Eingabewert. Wir arbeiten also in einer zwei-dimensionalen Welt. Variablen, die die Funktion mathematisch definieren, werden oft als griechische Buchstaben darsgestellt. Die Variable  (Alpha) ist der -Achsenschnitt bei
(Alpha) ist der -Achsenschnitt bei  . Dieser wird als Bias, selten auch als Default-Wert, bezeichnet. Der Bias ist also der Wert, wenn die -Eingabe gleich Null ist. Eine weitere Variable
. Dieser wird als Bias, selten auch als Default-Wert, bezeichnet. Der Bias ist also der Wert, wenn die -Eingabe gleich Null ist. Eine weitere Variable  (Beta) beschreibt die Steigung.
(Beta) beschreibt die Steigung.
Ferner ist zu beachten, dass sich eine Punktwolke durch eine Gerade nie perfekt beschreiben lässt, und daher für jedes  ein Fehler
ein Fehler  existiert. Diesen Fehler wollen wir in diesem Artikel ignorieren.
existiert. Diesen Fehler wollen wir in diesem Artikel ignorieren.
In einem zwei-dimensionalen System (eine Eingabe und eine Ausgabe) sprechen wir von einer einfachen Regression. Generalisieren wir die Regressionsmethode auf ein multivariates System (mehr als eine Eingabe-Variable), werden die Variablen in der Regel nicht mehr als griechische Buchstaben (denn auch das griechische Alphabet ist endlich) dargestellt, sondern wir nehmen eines abstrahierende Darstellung über Gewichtungen (weights). Dies ist eine sehr treffende Symbolisierungen, denn sowohl der Bias ( statt ) als auch die Steigungen (
statt ) als auch die Steigungen ( ) sind nichts anderes als Gewichtungen zwischen den Eingaben.
) sind nichts anderes als Gewichtungen zwischen den Eingaben.
![\[y = w_{0} \cdot x_{0} + w_{1} \cdot x_{1} + \ldots + w_{n} \cdot x_{n}\]](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-19728ae5f9e3065a4c17d50c417e0a8b_l3.png "Rendered by QuickLaTeX.com")
ist eine Summe aus den jeweiligen Produkten aus und  . Verkürzt ausgedrückt:
. Verkürzt ausgedrückt:
![\[y = \sum_{i=0}^n w_{i} \cdot x_{i}\]](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-3bbcbb30d482e7a1fd8da528030d6561_l3.png "Rendered by QuickLaTeX.com")
Noch kürzer ausgedrückt:
![\[y = w^T \cdot x\]](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-939f4bae6617db519d13b502d6337ee1_l3.png "Rendered by QuickLaTeX.com")
Anmerkung: Das hochgestellte T steht für Transponieren, eine Notation aus der linearen Algebra, die im Ergebnis nichts anderes bewirkt als  .
.
Diese mathematische lineare Funktion kann wie folgt abgebildet werden:
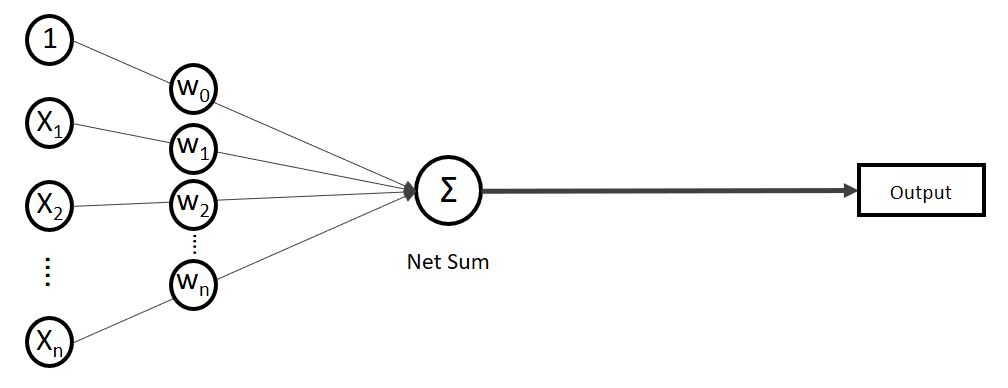 Der Output ist gleich bzw. die Ausgabe der Nettoeingabe (Net Sum)
Der Output ist gleich bzw. die Ausgabe der Nettoeingabe (Net Sum)  . Auf der linken Seite finden wir alle Eingabewerte, wobei der erste Wert statisch mit 1.0 belegt ist, nur für den Zweck, den Bias () in der Nettoeingabe aufrecht zu erhalten. Im Falle einer einfachen linearen Regression hätten wir also eine Funktion mit zwei Gewichten:
. Auf der linken Seite finden wir alle Eingabewerte, wobei der erste Wert statisch mit 1.0 belegt ist, nur für den Zweck, den Bias () in der Nettoeingabe aufrecht zu erhalten. Im Falle einer einfachen linearen Regression hätten wir also eine Funktion mit zwei Gewichten: 
Das Modell beschreibt, wie aus einer Reihe von Eingabewerten (n = Anzahl an x-Dimensionen) und einer Reihe von Gewichtungen (n + 1) eine Funktion entsteht, die einen y-Wert berechnet. Diese Berechnung wird auch als Forward-Propagation bezeichnet.
Doch welche Werte brauchen wir für die Gewichtungen, damit bei gegebenen x-Werten ein (mehr oder weniger) korrekter y-Wert berechnet wird? Anders gefragt, wie schaffen wir es, dass die Forward-Propagation die richtigen Werte ausspuckt?
Mit einem Training via Backpropagation!
Einfache Erklärung der Backpropagation
Die Backpropagation ist ein Optimierungsverfahren, unter Einsatz der Gradientenmethode, den Fehler einer Forward-Propagation zu berechnen und die Gewichtungen in Gegenrichtung des Fehlers anzupassen. Optimiert wird in der Form, dass der Fehler minimiert wird. Es ist ein iteratives Verfahren, bei dem mit jedem Iterationsschritt wieder eine Forward-Propagation auf Basis von Trainingsdaten durchgeführt wird und die Prädiktionsergebnisse mit den vorgegebenen Ergebnissen (der gekennzeichneten Trainingsdaten) verglichen und damit die Fehler berechnet werden. Die resultierende Fehlerfunktion ist konvex, ableitbar und hat ein zentrales globales Minimum. Dieses Minimum finden wir durch diese iterative Vorgehensweise.
Die Backpropagation zu erklären, erfordert einen separaten Artikel. Merken wir uns einfach: Die Backpropagation nutzt eine Fehlerfunktion, um die Werte der Gewichtungen schrittweise entgegen des Fehlers (bei jeder Forward-Propagation) bis zu einem Punkt anzupassen, bis keine wesentliche Verbesserung (Reduzierung des Fehlers) mehr eintritt. Nach dem Vollzug der Backpropagation erhalten wir die “richtigen” Gewichtungen und haben eine Funktion zur Vorhersage von y-Werten bei Eingabe neuer x-Werte.
Klassifikation – Die Vorhersage von Gruppenzugehörigkeiten
Bei der Klassifikation möchten wir jedoch keine Gerade oder Kurve vorhersagen, die sich durch eine Punktwolke legt, sondern wie möchten Punktwolken voneinander als Klassen unterscheiden, um später hinzukommende Punkte ihren richtigen Klassen zuweisen zu können (Klassifikation). Wir können jedoch auf dem vorherigen Modell der Prädiktion von stetigen Werten aufbauen und auch die Backpropagation zum Training einsetzen, möchten das Training dann jedoch auf die Trennung der Punktwolken ausrichten.
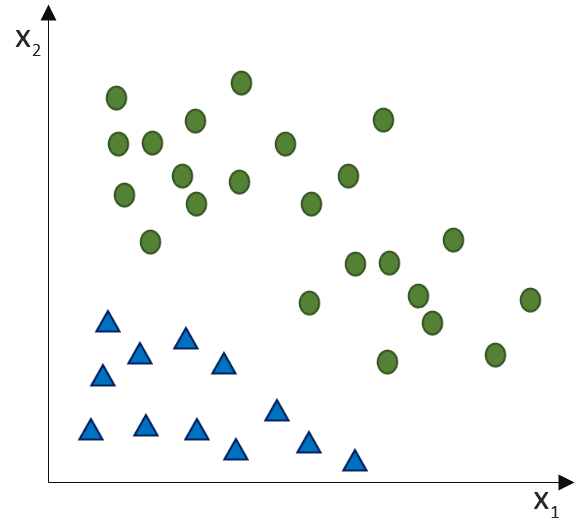 Hinweis: Regressions- und Klassifikationsherausforderungen werden in den Dimensionen unterschiedlich dargestellt. Zur Veranschaulichung: Während wir bei der einfachen Regression eine x-Eingabe als unabhängige Variable und eine y-Ausgabe als abhängige Variable haben, haben wir bei einer zwei-dimensionalen Klassifikation zwei x-Dimensionen als Eingabe. Die Klassen sind die y-Ausgabe (hier als Farben visualisiert).
Hinweis: Regressions- und Klassifikationsherausforderungen werden in den Dimensionen unterschiedlich dargestellt. Zur Veranschaulichung: Während wir bei der einfachen Regression eine x-Eingabe als unabhängige Variable und eine y-Ausgabe als abhängige Variable haben, haben wir bei einer zwei-dimensionalen Klassifikation zwei x-Dimensionen als Eingabe. Die Klassen sind die y-Ausgabe (hier als Farben visualisiert).
Ergänzen wir das Modell nun um eine Aktivierungsfunktion, dass die stetigen Werte der Nettosumme über eine Funktion in Klassen unterteilt, erhalten wir einen Klassifikator: Den Perceptron-Klassifikator. Das Perzeptron gilt als der einfachste Klassifikator und ist bereits die kleinste Form eines künstlichen neuronalen Netzes. Es funktioniert nur bei linearer Trennbarkeit der Klassen.
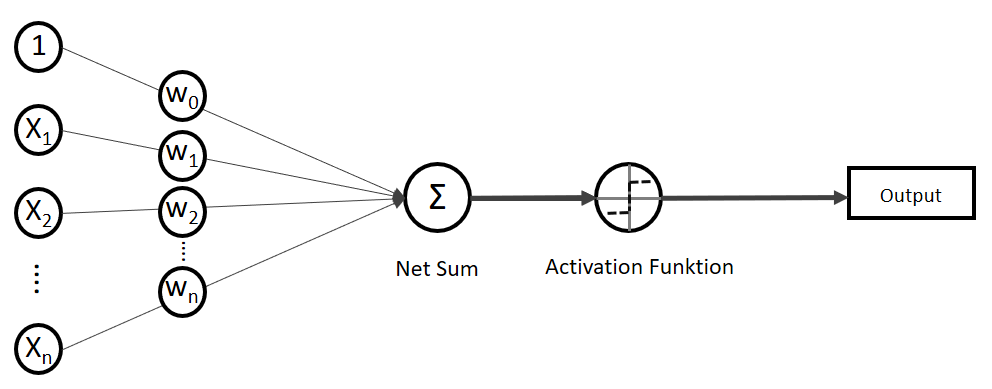 Was soll die Aktivierungsfunktion bewirken? Wir berechnen wieder eine Nettoeingabe , die uns stetige Werte ausgiebt. Wir haben also immer noch unsere Gewichtungen, die wir trainieren können. Nun trainieren wir nur nicht auf eine “korrekte” stetige Ausgabe der Nettoeingabe hin, sondern auf eine korrekte Ausgabe der Aktivierungsfunktion
Was soll die Aktivierungsfunktion bewirken? Wir berechnen wieder eine Nettoeingabe , die uns stetige Werte ausgiebt. Wir haben also immer noch unsere Gewichtungen, die wir trainieren können. Nun trainieren wir nur nicht auf eine “korrekte” stetige Ausgabe der Nettoeingabe hin, sondern auf eine korrekte Ausgabe der Aktivierungsfunktion  (Phi), die uns die stetigen Werte der Nettoeingabe in einen binären Wert (z. B. 0 oder 1) umwandelt.
(Phi), die uns die stetigen Werte der Nettoeingabe in einen binären Wert (z. B. 0 oder 1) umwandelt. 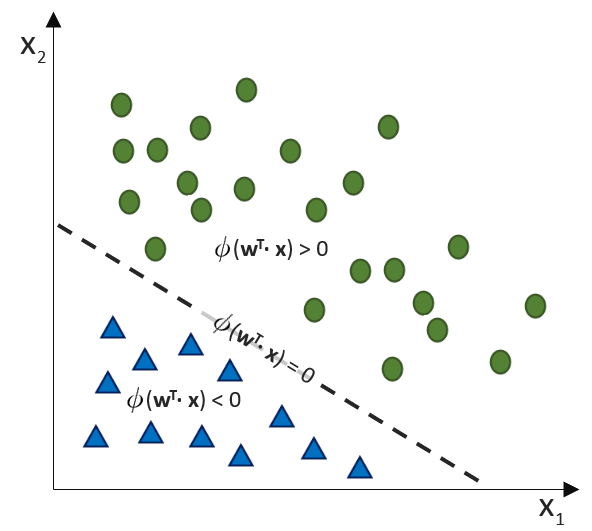 Das Perzeptron ist die kleinste Form des künstlichen neuronalen Netzes und funktioniert wie der lineare Regressor, jedoch ergänzt um eine Aktivierungsfunktion die bewirken soll, dass ein Neuron (hier: der einzelne Output) “feuert” oder nicht “feuert”. Es ist ein binärer Klassifikator, der beispielsweise die Wertebereiche -1 oder +1 annehmen kann.
Das Perzeptron ist die kleinste Form des künstlichen neuronalen Netzes und funktioniert wie der lineare Regressor, jedoch ergänzt um eine Aktivierungsfunktion die bewirken soll, dass ein Neuron (hier: der einzelne Output) “feuert” oder nicht “feuert”. Es ist ein binärer Klassifikator, der beispielsweise die Wertebereiche -1 oder +1 annehmen kann.
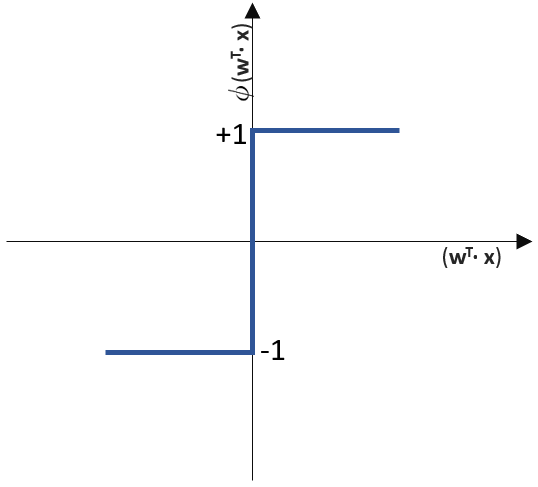 Das Perceptron verwendet die einfachste Form der Aktivierungsfunktion: Eine Sprungfunktion, die einer einfachen if… else… Anweisung gleich kommt.
Das Perceptron verwendet die einfachste Form der Aktivierungsfunktion: Eine Sprungfunktion, die einer einfachen if… else… Anweisung gleich kommt.
![\[ y = \phi(w^T \cdot x) = \left\{ \begin{array}{12} 1 & w^T \cdot x > 0\\ -1 & \text{otherwise} \end{array} \]](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-7b828cf4bbabf9e1a84ec9b628d51249_l3.png "Rendered by QuickLaTeX.com")
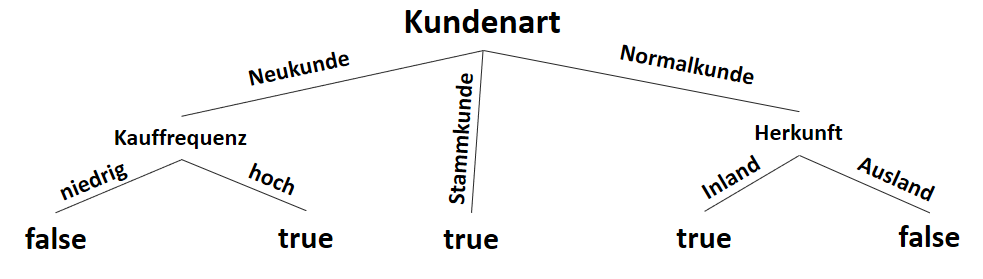
Fazit – Unterschied zwischen Klassifikation und Regression
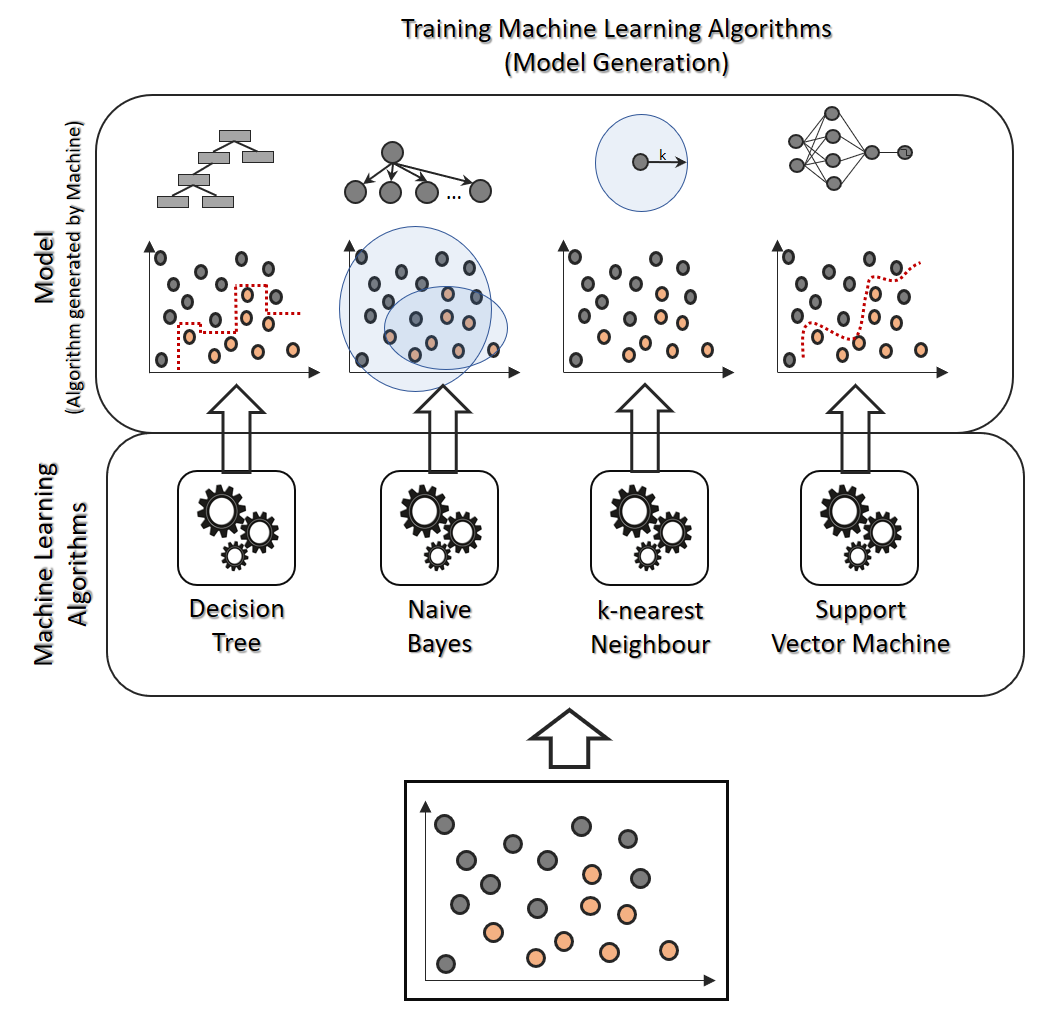
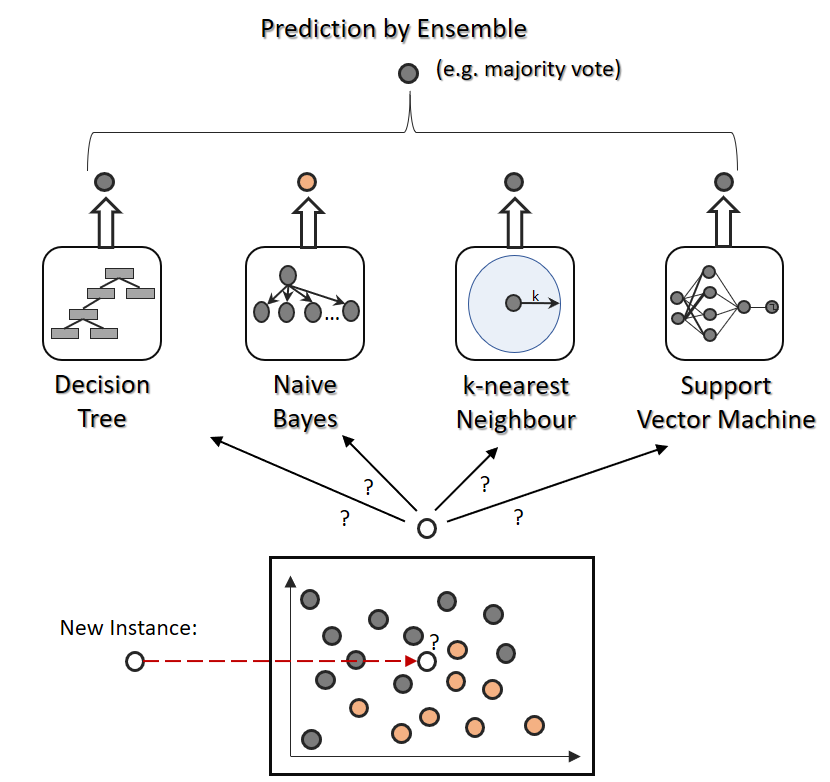
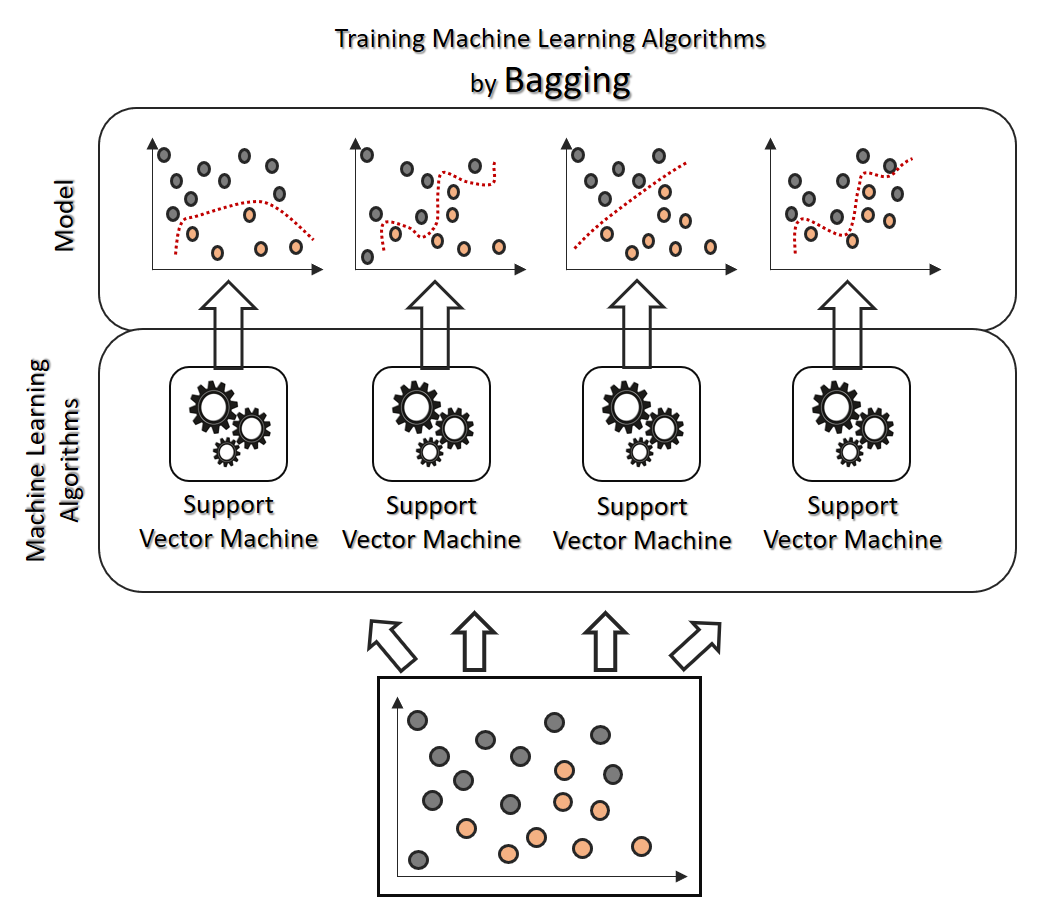
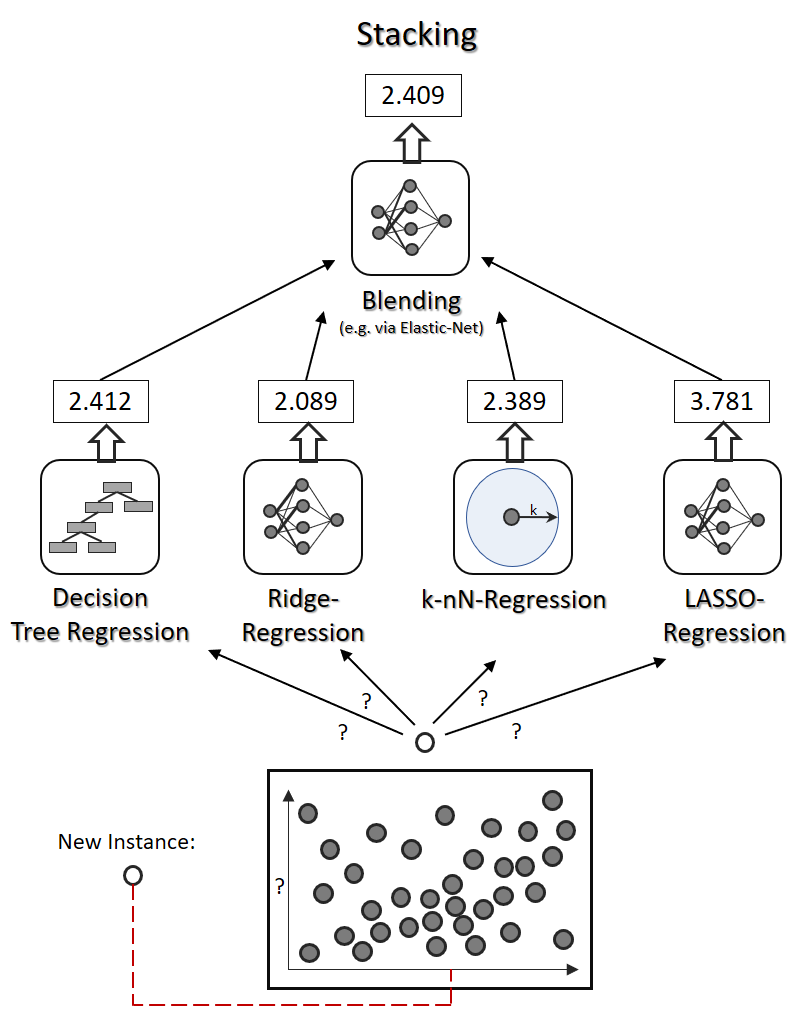
Mathematisch müssen sich Regression und Klassifikation gar nicht all zu sehr voneinander unterscheiden. Viele Verfahren der Klassifikation lassen sich mit nur wenig Anpassung auch zur Regression anwenden, oder umgekehrt. Künstliche neuronale Netze, k-nächste-Nachbarn und Entscheidungsbäume sind gute Beispiele, die in der Praxis sowohl für Klassifkation als auch für Regression eingesetzt werden, natürlich mit unterschiedlichen Stärken und Schwächen.
Unterschiedlich ist jedoch der Zweck der Anwendung: Bei der Regression möchten wir stetige Werte vorhersagen (z. B. Temperatur der Maschine), bei der Klassifikation hingegen Klassen unterscheiden (z. B. Maschine überhitzt oder überhitzt nicht).
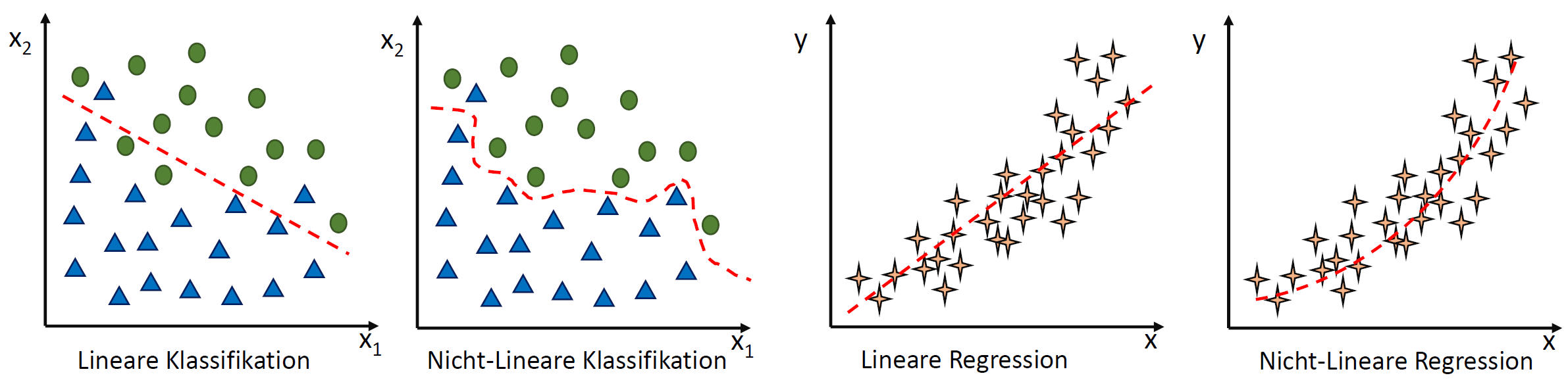 Unterschiede zwischen linearer und nicht-linearer Klassifikation und linearer und nicht-linearer Regression. Für Einsteiger in diese Thematik ist beachten, dass jede maschinell erlernte Klassifikation und Regression einen gewissen Fehler hat, der unter Betrachtung der Trainings- und Testdaten zu minimieren ist, jedoch nie ganz verschwindet.
Unterschiede zwischen linearer und nicht-linearer Klassifikation und linearer und nicht-linearer Regression. Für Einsteiger in diese Thematik ist beachten, dass jede maschinell erlernte Klassifikation und Regression einen gewissen Fehler hat, der unter Betrachtung der Trainings- und Testdaten zu minimieren ist, jedoch nie ganz verschwindet.
Und Clustering?
Clustering ist eine Disziplin des unüberwachten Lernens, um Gruppen von Klassen bzw. Grenzen dieser Klassen innerhalb von unbekannten Daten zu finden. Es ist im Prinzip eine untrainierte Klassifikation zum Zwecke des Data Minings. Clustering gehört auch zum maschinellen Lernen, ist aber kein Predictive Analytics. Da keine – mit dem gewünschten Ergebnis vorliegende – Trainingsdaten vorliegen, kann auch kein Training über eine Backpropagation erfolgen. Clustering ist folglich eine schwache Klassifikation, die mit den trainingsbasierten Klassifikationsverfahren nicht funktioniert.




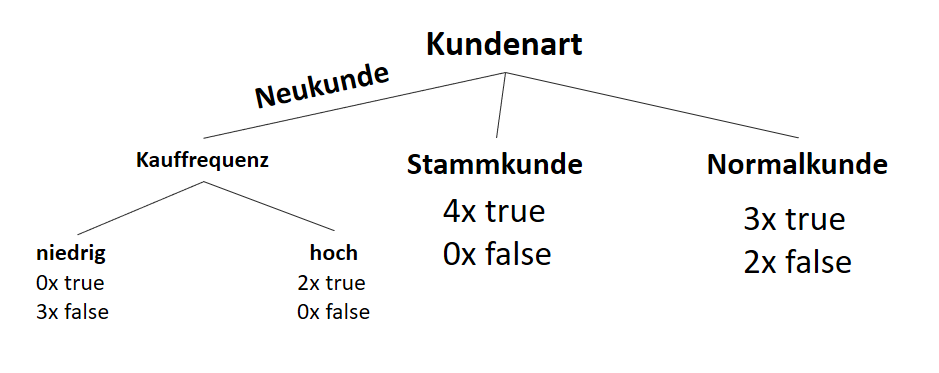
 ) im Sinne des ID3-Algorithmus ist die Differenz aus der Entropie (
) im Sinne des ID3-Algorithmus ist die Differenz aus der Entropie ( ) (siehe Teil 1 der Artikelserie
) (siehe Teil 1 der Artikelserie  ) und der Summe aus den gewichteten Entropien des Attributes für jeden einzelnen Wert (Value
) und der Summe aus den gewichteten Entropien des Attributes für jeden einzelnen Wert (Value  ), der im Attribut vorkommt:
), der im Attribut vorkommt:

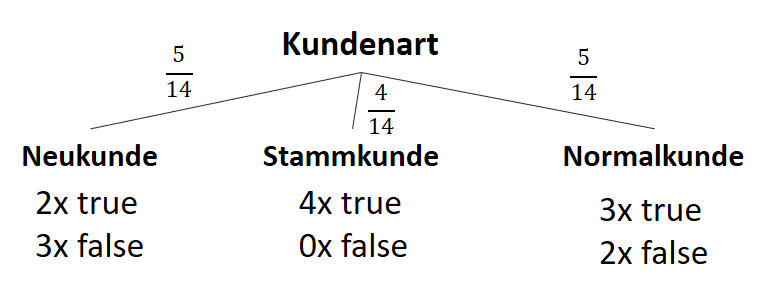



![\[ IG(S, A_{Kundenart}) = - \sum_{i=1}^n \frac{\bigl|S_i\bigl|}{\bigl|S\bigl|} \cdot H(S_i) \]](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-6380891cc61bb855d4208480091fdef0_l3.png "Rendered by QuickLaTeX.com")
![\[ IG(S, A_{Kundenart}) = H(S) - \frac{\bigl|S_{Neukunde}\bigl|}{\bigl|S\bigl|} \cdot H(S_{Neukunde}) - \frac{\bigl|S_{Stammkunde}\bigl|}{\bigl|S\bigl|} \cdot H(S_{Stammkunde}) - \frac{\bigl|S_{Normalkunde}\bigl|}{\bigl|S\bigl|} \cdot H(S_{Normalkunde}) \]](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-b3c9d40c7a171fd7b9e5fbed0aed041a_l3.png "Rendered by QuickLaTeX.com")
![\[ IG(S, A_{Kundenart}) = 0.94 - \frac{5}{14} \cdot 0.97 - \frac{4}{14} \cdot 0.00 - \frac{5}{14} \cdot 0.97 = 0.247 \]](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-33144ba5df6858348666daef5a5cf5d3_l3.png "Rendered by QuickLaTeX.com")
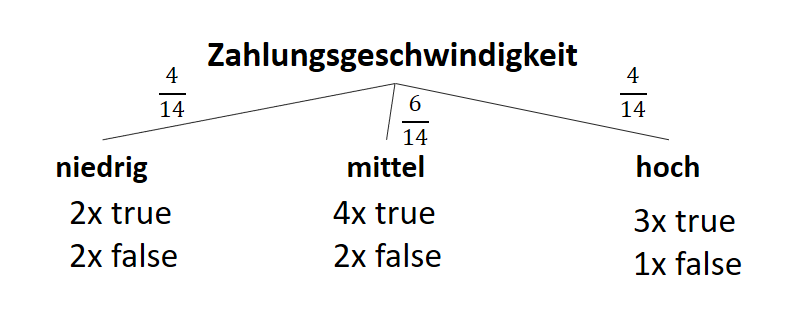



![\[ IG(S, A_{Zahlungsgeschwindigkeit}) = H(S) - \frac{\bigl|S_{niedrig}\bigl|}{\bigl|S\bigl|} \cdot H(S_{niedrig}) - \frac{\bigl|S_{mittel}\bigl|}{\bigl|S\bigl|} \cdot H(S_{mittel}) - \frac{\bigl|S_{schnell}\bigl|}{\bigl|S\bigl|} \cdot H(S_{schnell}) \]](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-a80e61c0adf9dff8ca219a28bce359cd_l3.png "Rendered by QuickLaTeX.com")
![\[ IG(S, A_{Zahlungsgeschwindigkeit}) = 0.94 - \frac{4}{14} \cdot 1.00 - \frac{6}{14} \cdot 0.92 - \frac{4}{14} \cdot 0.81 = 0.029 \]](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-ed4f1d54de66a9956bc2c1e53a0de2e8_l3.png "Rendered by QuickLaTeX.com")



![\[ IG(S, A_{Kauffrequenz}) = H(S) - \frac{\bigl|S_{niedrig}\bigl|}{\bigl|S\bigl|} \cdot H(S_{niedrig}) - \frac{\bigl|S_{hoch}\bigl|}{\bigl|S\bigl|} \cdot H(S_{hoch}) \]](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-cbcfb6a5b118cfc2df4185ef03e4e1dd_l3.png "Rendered by QuickLaTeX.com")
![\[ IG(S, A_{Kauffrequenz}) = 0.94 - \frac{7}{14} \cdot 1.00 - \frac{7}{14} \cdot 0.59 = 0.150 \]](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-dc9f358f2d2cd071b815b3f6c571f813_l3.png "Rendered by QuickLaTeX.com")
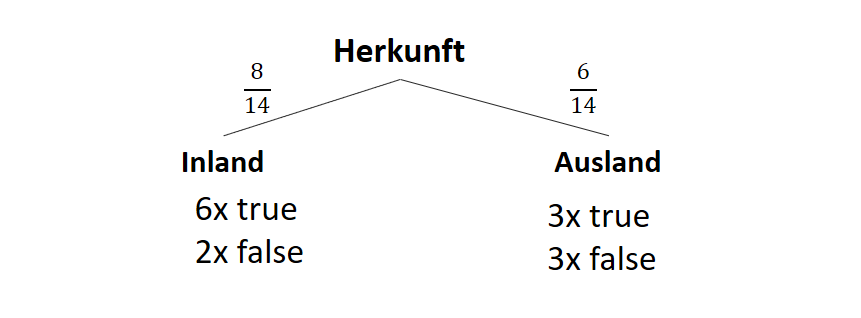


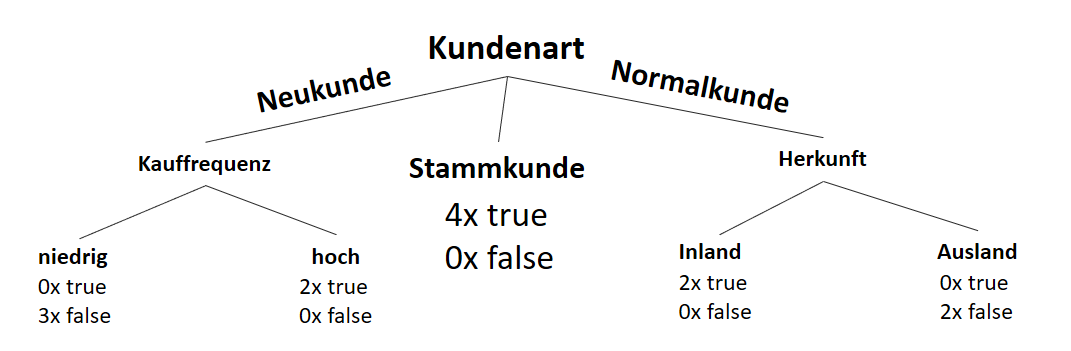
![\[ IG(S, A_{Herkunft}) = H(S) - \frac{\bigl|S_{Inland}\bigl|}{\bigl|S\bigl|} \cdot H(S_{Inland}) - \frac{\bigl|S_{Ausland}\bigl|}{\bigl|S\bigl|} \cdot H(S_{Ausland}) \]](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-3a0ecd4412fa44ca26c64ea16aa536d1_l3.png "Rendered by QuickLaTeX.com")
![\[ IG(S, A_{Herkunft}) = 0.94 - \frac{8}{14} \cdot 0.81 - \frac{6}{14} \cdot 1.00 = 0.05 \]](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-ab4db275a73c092813d00f26ef4c1183_l3.png "Rendered by QuickLaTeX.com")
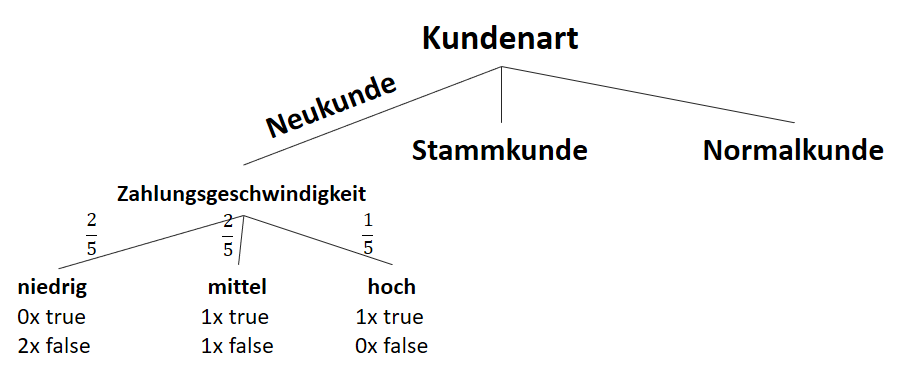



![\[ IG(S_{Neukunde},A_{Zahlungsgeschwindigkeit}) = 0.97 - \frac{3}{5} \cdot 0.00 - \frac{2}{5} \cdot 1.00 - \frac{1}{5} \cdot 0.00 = 0.57 \]](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-35c0216b5e69ee73831980225531ecc7_l3.png "Rendered by QuickLaTeX.com")
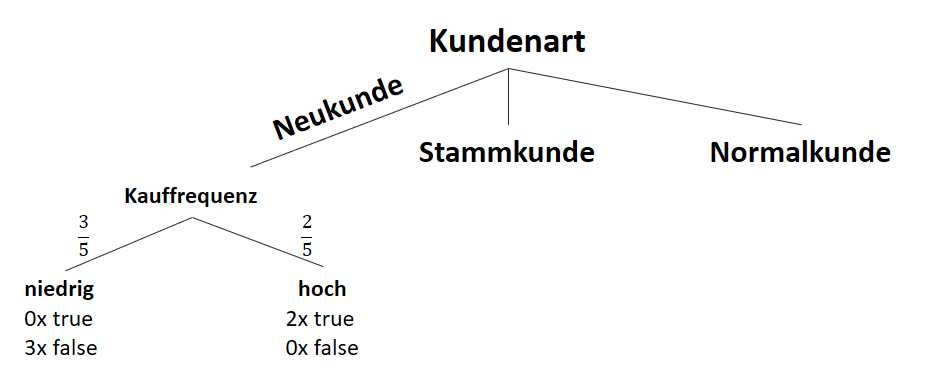
![\[ IG(S_{Neukunde},A_{Kauffrequenz}) = 0.97 - \frac{3}{5} \cdot 0.00 - \frac{2}{5} \cdot 0.00 = 0.97 \]](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-5f6849e7156c9505f53b484a8e7f505a_l3.png "Rendered by QuickLaTeX.com")



![\[ IG(S_{Neukunde},A_{Herkunft}) = 0.97 - \frac{3}{5} \cdot 0.92 - \frac{2}{5} \cdot 1.00 = 0.018 \]](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-890f306c397d0ac28cbbd9a316eb049b_l3.png "Rendered by QuickLaTeX.com")