Data Science mit Neo4j und R
Traurig, aber wahr: Data Scientists verbringen 50-80% ihrer Zeit damit, Daten zu bereinigen, zu ordnen und zu bearbeiten. So bleibt nur noch wenig Zeit, um tatsächlich vorausschauende Vorhersagemodelle zu entwickeln. Vor allem bei klassischen Stacks, besteht die Datenanalyse zum Großteil darin, Zeile für Zeile in SQL zu überführen. Zeit zum Schreiben von Modell-Codes in einer statistischen Sprache wie R bleibt da kaum noch. Die langen, kryptischen SQL-Abfragen verlangsamen aber nicht nur die Entwicklungszeit. Sie stehen auch einer sinnvollen Zusammenarbeit bei Analyse-Projekten im Weg, da alle Beteiligten zunächst damit beschäftigt sind, die SQL-Abfragen der jeweils anderen zu verstehen.
Komplexität der Daten steigt
Der Grund für diese Schwierigkeiten: Die Datenstrukturen werden immer komplexer, die Vernetzung der Daten untereinander nimmt immer stärker zu. Zwängt man diese hochgradig verbundenen Datensätze in eine SQL-Datenbank, in der Beziehungen naturgemäß abstrakt über Fremdschlüssel dargestellt werden, erhält man als Ergebnis übermäßig komplizierte Schematas und Abfragen. Als Alternative gibt es jedoch einige NoSQL-Lösungen – allen voran Graphdatenbanken – die solche hochkomplexen und heterogenen Daten ohne Informationsverlust speichern können – und zwar nicht nur die Entitäten an sich, sondern auch besonders die Beziehungen der Daten untereinander.
Datenanalysen zielen immer stärker darauf ab, das Verhalten und die Wünsche von Kunden besser verstehen zu können. Die Fragen lauten z. B.:
- Wie hoch ist die Wahrscheinlichkeit, dass ein Besucher auf eine bestimmte Anzeige klickt?
- Welcher Kunde sollte in welchem Kontext welche Produktempfehlungen erhalten?
- Wie kann man aus der bisherigen Interaktionshistorie des Kunden sein Ziel vorhersagen, bevor er selbst dort ankommt?
- In welchen Beziehungen steht Nutzer A zu Nutzer B?
Menschen sind bekanntermaßen von Natur aus sozial. Einige dieser Fragen lassen sich daher beantworten, wenn man weiß, wie Personen miteinander in Verbindung stehen: Unsere Zielperson, Nutzer A ähnelt in seinem Kontext und Verhalten Benutzer B. Und da Benutzer B ein bestimmtes Produkt (z. B. ein Spielfilm) gefällt, empfehlen wir diesen Film auch Nutzer A. In diese Auswertung fließen natürlich auch noch weitere Faktoren mit ein, z. B. die Demographie und der soziale Status des Nutzers, seine Zuordnung zu Peer Groups, vorher gesehene Promotions oder seine bisherigen Interaktionen.
Visualisierung eines Graphen mit RNeo4j
Mit R und Neo4j lassen sich Graphen und Teilgraphen ganz einfach mit RNeo4j, igraph und visNetwork libraries visualisieren.
|
1 2 3 |
library(igraph) library(visNetwork) library(RNeo4j) |
Das folgende Beispiel zeigt wie in einem Graphen Schauspieler und Filme sowie ihre Beziehungen zueinander anschaulich dargestellt werden können, z. B. um Empfehlungen innerhalb eines Filmportals zu generieren. Dabei sind zwei Schauspieler über eine Kante miteinander verbunden, wenn sie beide im gleichen Film mitspielen.
Im ersten Schritt werden dazu in Neo4j die Film-Datensätze importiert (Achtung: Dieser Vorgang löscht die aktuelle Datenbank).
|
1 2 3 |
graph = startGraph("http://localhost:7474/db/data/") importSample(graph, "movies", input=F) |
Als nächstes wird mit Cypher eine entsprechende Liste von Beziehungen aus Neo4j gezogen. Wie man sehen kann, ist die Darstellung des gewünschten Graph-Musters innerhalb der Abfrage sehr anschaulich.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
query = " MATCH (p1:Person)-[:ACTED_IN]->(:Movie)<-[:ACTED_IN]-(p2:Person) WHERE p1.name < p2.name RETURN p1.name AS from, p2.name AS to, COUNT(*) AS weight " edges = cypher(graph, query) head(edges) ## from to weight ## 1 Brooke Langton Keanu Reeves 1 ## 2 Jack Nicholson Kevin Bacon 1 ## 3 Jerry O'Connell Kiefer Sutherland 1 ## 4 Oliver Platt Sam Rockwell 1 ## 5 John Goodman Susan Sarandon 1 ## 6 Gary Sinise Kevin Bacon 1 |
Die visNetwork Funktion erwartet sowohl Kanten-Dataframes als auch Knoten-Dataframes. Ein Knoten-Dataframe lässt sich daher über die eindeutigen Werte des Kanten-Dataframes generieren.
|
1 2 3 4 5 6 7 8 9 10 11 |
nodes = data.frame(id=unique(c(edges$from, edges$to))) nodes$label = nodes$id head(nodes) ## id label ## 1 Brooke Langton Brooke Langton ## 2 Jack Nicholson Jack Nicholson ## 3 Jerry O'Connell Jerry O'Connell ## 4 Oliver Platt Oliver Platt ## 5 John Goodman John Goodman ## 6 Gary Sinise Gary Sinise |
Im Anschluss können die Knoten- und Kanten-Dataframes in das visNetwork übertragen werden.
visNetwork(nodes, edges)
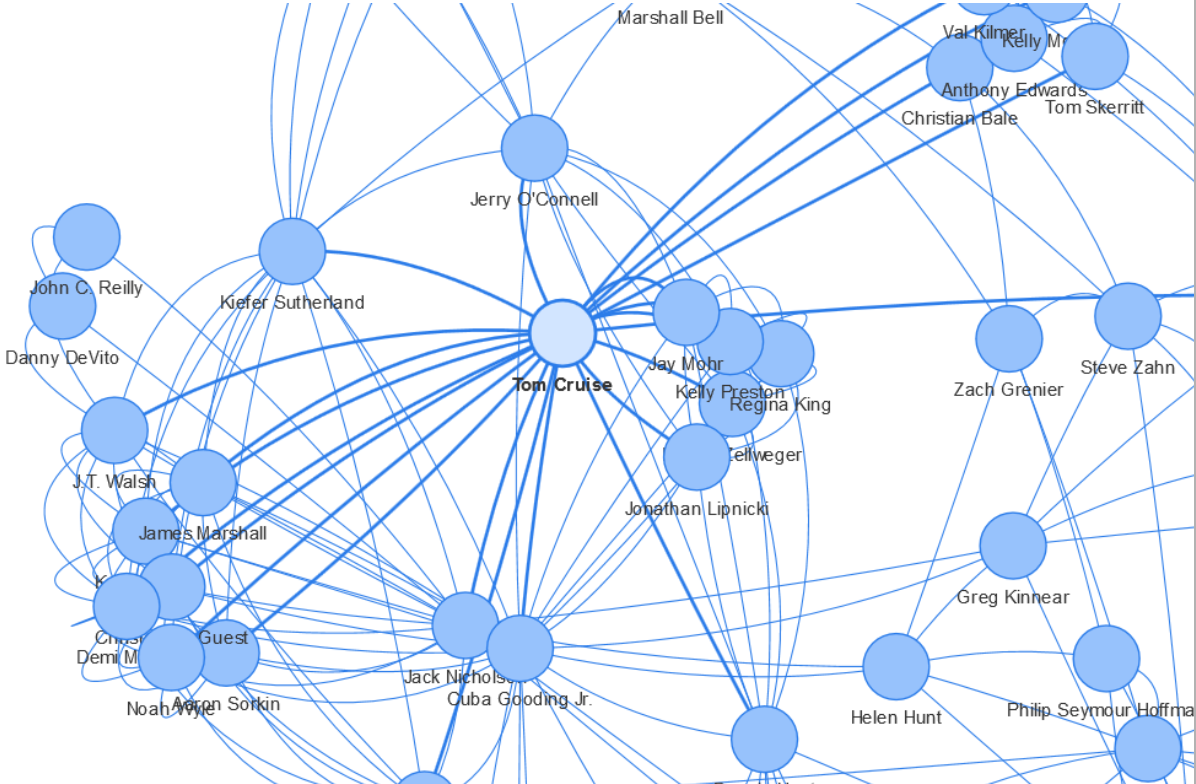
Nun kommt igraph mit ins Spiel, eine Bibliothek von Graph-Algorithmen. Durch Einbindung der Kantenliste lässt sich einfach ein igraph Graph-Objekt erstellen, das den Teilgraphen miteinschließt.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
ig = graph_from_data_frame(edges, directed=F) ig ## IGRAPH UNW- 102 362 -- ## + attr: name (v/c), weight (e/n) ## + edges (vertex names): ## [1] Brooke Langton --Keanu Reeves ## [2] Jack Nicholson --Kevin Bacon ## [3] Jerry O'Connell --Kiefer Sutherland ## [4] Oliver Platt --Sam Rockwell ## [5] John Goodman --Susan Sarandon ## [6] Gary Sinise --Kevin Bacon ## [7] J.T. Walsh --Noah Wyle ## [8] Jim Broadbent --Tom Hanks ## + ... omitted several edges |
Die Größe der Knoten kann als Funktion der Edge-Betweeness-Centrality definiert werden. In visNetwork entspricht dabei jede “value”-Spalte im Knoten-Dataframe der Größe des Knoten.
nodes$value = betweenness(ig)
|
1 2 3 4 5 6 7 8 |
head(nodes) ## id label value ## 1 Brooke Langton Brooke Langton 0.000000 ## 2 Jack Nicholson Jack Nicholson 511.443714 ## 3 Jerry O'Connell Jerry O'Connell 154.815234 ## 4 Oliver Platt Oliver Platt 20.643840 ## 5 John Goodman John Goodman 1.659259 ## 6 Gary Sinise Gary Sinise 33.723499 |
Mit Einführung der “Value”-Spalte werden die Knoten nun alle unterschiedlich groß dargestellt.
visNetwork(nodes, edges)

Mit Hilfe eines Community-Detection-Algorithmus lassen sich im Graphen nun Cluster finden. In diesem Beispiel wird der „Girvan-Newman”-Algorithmus verwendet, der in igraph als cluster_edge_betweenness bezeichnet wird.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
clusters = cluster_edge_betweenness(ig) clusters[1:2] ## $`1` ## [1] "Brooke Langton" "Liv Tyler" "Charlize Theron" ## [4] "Emil Eifrem" "Dina Meyer" "Diane Keaton" ## [7] "Keanu Reeves" "Gene Hackman" "Ice-T" ## [10] "Al Pacino" "Carrie-Anne Moss" "Clint Eastwood" ## [13] "Orlando Jones" "Takeshi Kitano" "Laurence Fishburne" ## [16] "Richard Harris" ## ## $`2` ## [1] "Jack Nicholson" "Jerry O'Connell" "J.T. Walsh" ## [4] "Renee Zellweger" "Kiefer Sutherland" "Cuba Gooding Jr." ## [7] "Marshall Bell" "Aaron Sorkin" "Kevin Bacon" ## [10] "Kevin Pollak" "Christopher Guest" "Demi Moore" ## [13] "Regina King" "Kelly Preston" "John Cusack" ## [16] "Danny DeVito" "Bonnie Hunt" "Corey Feldman" ## [19] "Jay Mohr" "James Marshall" "Jonathan Lipnicki" ## [22] "River Phoenix" "Tom Cruise" "Noah Wyle" ## [25] "Wil Wheaton" "John C. Reilly" |
In der Liste oben sind alle Schauspieler der ersten zwei Cluster zu sehen. Insgesamt konnten sechs Cluster identifiziert werden.
|
1 2 |
length(clusters) ## [1] 6 |
Durch Hinzufügen einer “Group”-Spalte im Knoten-Dataframe, werden alle Knoten in visNetwork entsprechend ihrer Gruppenzugehörigkeit farblich markiert. Diese Cluster-Zuordnung erfolgt über clusters$membership. Durch Entfernen der “Value”-Spalte lassen sich die Knoten wieder auf eine einheitliche Größe bringen.
|
1 2 3 4 5 6 7 8 9 10 11 |
nodes$group = clusters$membership nodes$value = NULL head(nodes) ## id label group ## 1 Brooke Langton Brooke Langton 1 ## 2 Jack Nicholson Jack Nicholson 2 ## 3 Jerry O'Connell Jerry O'Connell 2 ## 4 Oliver Platt Oliver Platt 3 ## 5 John Goodman John Goodman 4 ## 6 Gary Sinise Gary Sinise 3 |
Werden die Knoten- und Kanten-Datenframes erneut in visNetwork übertragen, sind nun alle Knoten eines Clusters in derselben Farbe dargestellt.
visNetwork(nodes, edges)
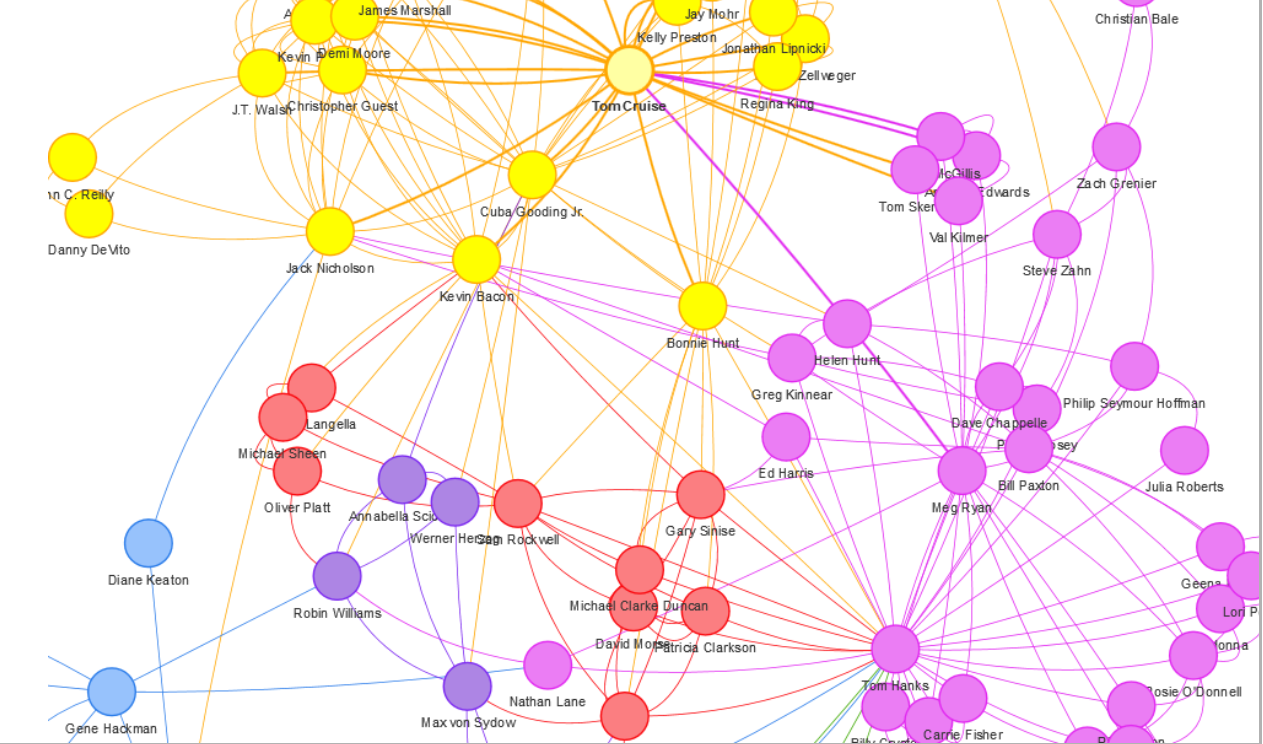
Mit diesem Workflow lassen sich Teilgraphen in Neo4j einfach abfragen und Cluster-Algorithmen einfach darstellen.
Generell eignen sich Graphdatenbanken wie Neo4j besonders gut, um stark vernetzte und beliebig strukturierte Informationen zu handhaben – egal ob es sich um Schauspieler, Filme, Kunden, Produkte, Kreditkarten oder Bankkonten handelt. Zudem können sowohl den Knoten als auch den Kanten beliebige qualitative und quantitative Eigenschaften zugeordnet werden. Beziehungen zwischen Daten sind also nicht mehr bloße Strukturinformationen, sondern stehen vielmehr im Zentrum des Modells.
Cypher: intuitiv nutzbare Programmiersprache
Die Zeiten, in denen Data Science zum Großteil aus Datenbereinigung und -mapping besteht, sind damit vorbei. Mit dem entsprechenden Ansatz laufen Entwicklungsprozesse deutlich schneller und einfacher ab. Data Scientists kommen mit weniger Code schneller ans Ziel und können mehr Zeit in das tatsächliche Entwickeln von relevanten Modellen investieren. Dabei nutzen sie die Flexibilität einer quelloffenen NoSQL-Graphdatenbank wie Neo4j kombiniert mit der Reife und weiten Verbreitung der Statistiksprache R für statistisches Rechnen und Visualisierung. Programmierer müssen nicht mehr stundenlang komplexe SQL-Anweisungen schreiben oder den ganzen Tag damit verbringen, eine Baumstruktur in SQL zu überführen. Sie benutzen einfach Cypher, eine musterbasierte, für Datenbeziehungen und Lesbarkeit optimierte Abfragesprache und legen los.