Top 5 Email Verification and Validation APIs for your Product
If you have spent some time running a website or online business, you would be aware of the importance of emails.
What many see as a decadent communication medium still holds immense value for digital marketers.
More than 330 billion emails are sent every day, even in 2022.
While email marketing is very effective, it is very difficult to do it right. One of the key reasons being the many problems that email marketers face with their email lists. Are the email IDs correct? Do they have spam traps? Are these disposable email addresses? There are a multitude of questions to deal with in email marketing and newsletter campaigns.
Email verification and validation APIs help us deal with this problem. APIs integrate with your platform and automatically check all email addresses for spam, mistyping, fake email ids, and so on.
Top 5 email verification and validation APIs for your product
Today we will talk about the 5 best APIs that you can use to validate and verify the email addresses in your mailing list. Using an API can be a gamechanger for many email marketers. Before we get into the top 5 list, let’s discuss why APIs are so effective and how they work.
Why APIs are so efficient
The major reason APIs work so efficiently is that it does not require human supervision. APIs work automatically and users do not have to manually configure them each time. The ease of use is one among many reasons you should start using an email verification and validation API.
If you maintain a mailing list, you would also want to know where your effort is going. All email marketers spend considerable time perfecting their emails. On top of that, they need to use an email marketing platform like Klaviyo. An API ensures that your hard work does not go in vain. By filtering out fake and disposable email IDs, you get a better idea of where your mailing stand stands. As a result, when you use a platform like Klaviyo along with an email verification API, the results are much better. In case you want something other than Klaviyo, you can learn more about Klaviyo alternatives here.
How email verification and validation APIs work
Email verification and validation APIs work primarily in 7 ways:
- Syntax Check
- Address Name Detection
- DEA (disposable email address) Detection
- Spam Trap Detection
- DNSBL and URI DNSBL Check
- MX Record Lookup
- Active Mailbox Check
With the help of these email verification and validation methods, you will see much better results from your email marketing campaign. On top of that, your business will not be identified as spam and will help in building reputation and authority.
Now that we have some idea about what email verification APIs are and what they do, let’s head over to the list.
1. Abstract API
Abstract API is one of the most popular email verification and validation APIs out there. Here are some of its key features:
- MX record check
- GDPR and CCPA compliant
- Does not store any email
- Role email check
If you have looked for email address validation API on the internet, you must have come across Abstract API. It is among the best in the business and also comes with affordable subscription plans.
Abstract API helps with bounce rate detection, spam signups, differentiating between personal and business email IDs, and a lot more. However, the most significant feature of Abstract API is that it allows up to 500 free email checks every month. That’s a great way to see whether the product works for you before subscribing to it.
Abstract API is user-friendly and budget-friendly, which makes it a top choice for many email marketers. Anyone new to using these tools can easily learn about them from Abstract API. For these reasons, Abstract API has the number one spot on our list.
2. SendGrid Validation API
After Abstract API, the second product to have top-notch features is SendGrid Validation API. Here are its key features:
- Uses machine learning to verify email addresses in real-time
- Accurately identifies all inactive or inaccurate email addresses
- You can check how your email appears in different mailboxes
- Gives risk scores for all email addresses
While most email verification and validation APIs work similarly, SendGrid Validation API takes it a notch higher with machine learning and artificial intelligence. Despite having advanced features and functionalities, SendGrid Validation API is not difficult to use.
SendGrid Validation API operates on the cloud and does not store any of your email addresses. OIn top of that, there are easy settings and configuration options that users can tweak with. However, SendGrid Validation API does not have any free offering. There are only two plans: pro and premier. Users have to pay $89.95 per month to access SendGrid Validation API.
If you are looking for advanced email verification and validation API, no need to look beyond SendGrid Validation API. It has everything you would need for a solid email marketing campaign apart from having many additional features.
3. Captain Verify
Another email verification and validation API – Captain Verify – is a one-stop solution for all email verification needs. Here are its key features:
- Get reports on the overall quality of your email address database
- Affordable plans
- Compliant with GDPR regulations
- Export encrypted CSV files
Unlike other email verification and validation APIs, Captain Verify does not stop after verifying the emails for spam, fake or invalid addresses, and so on. It helps email marketers understand how their campaign is performing and gives detailed reports on returns on investment. It is one of the best APIs available for the overall growth of your mailing campaign.
If you are looking for something simple yet powerful, Captain Verify will be a great option. Along with the features we mentioned already, it also lets users filter and refine their email lists. It can help you understand the overall quality of your mailing list much better.
As you can see, Captain Verify ticks most of the boxes to be one of the best email verification and validation APIs out there. Anyone looking for a good email API should give it a go. The best thing is that users get all this and more at only $7 per 1000 emails.
4. Mailgun
Mailgun earns the fourth spot on our list. However, that does not mean it is any way less than the previous options discussed. Here’s what it offers:
- RFC standards compliant
- Daily and hourly tracking of API usage
- Has a bulk list validation tools for faster operations
- Supports both CSV and JSON format
- Track bounce and unsubscribe rates
Email marketers around the world prefer Mailgun for all their email verification and validation needs. It has multiple features that allow users to check their mailing list for fakes and scams. Apart from that, it also gives users a good idea of how their marketing campaign is performing.
Mailgun enjoys high ratings across review platforms like Capterra and G2. People use it for a wide range of purposes, but email verification and validation remain the most important. Mailgun keeps track of bounce rates, hard bounce rates, and unsubscribe rates. With the help of these stats, email marketers can measure how their campaign is doing.
If you are looking for a simple email verification and validation tool, Mailgun can be a good choice. It is worth trying for anyone who wants to take their email marketing to the next level.
5. Hunter
Our last entry to the list is Hunter. It is a well-known API that is widely used by email marketers. Here’s what it gets right:
- Compare your mailing list with the Hunter mailing list for comparative quality analysis
- SMTP checks, domain information verification, and multi-layer validation
- Easy integration with Google Sheets
- Supports both CSV and .txt formats
Hunter gives what it calls confidence scores which represent how strong or weak your mailing list is. This email verification and validation tool follows all the checks that we mentioned earlier, including SMTP verification, gibberish detection, MX record checks, and more. These features have worked together to make Hunter one of the most popular email verification and validation tools.
Hunter email verification API integrates easily with any platform and has a user-friendly interface. It also has a free plan that lets users check up to 50 emails for free. Giving it a try without spending money is very useful for anyone looking for a new email verification and validation API.
If you are looking for an email finder and email verifier rolled into one, Hunter is the best solution. With so many features and functionalities, it is one of the favorite email verification and validation APIs for thousands of marketers and entrepreneurs.
Conclusion
When used correctly, email verification and validation APIs can give any online business a significant boost. As an email marketer, digital marketer, website owner, or entrepreneur, you should be using one of these APIs. If you aren’t using one already, find your top pick from our list of the 5 best email verification and validation APIs.
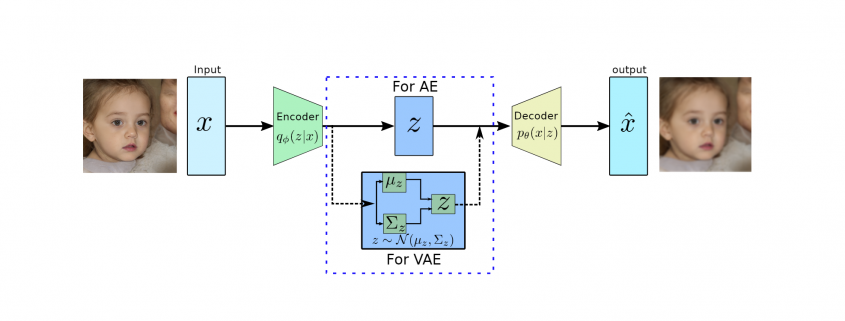

 produces meaningful information of
produces meaningful information of  .
.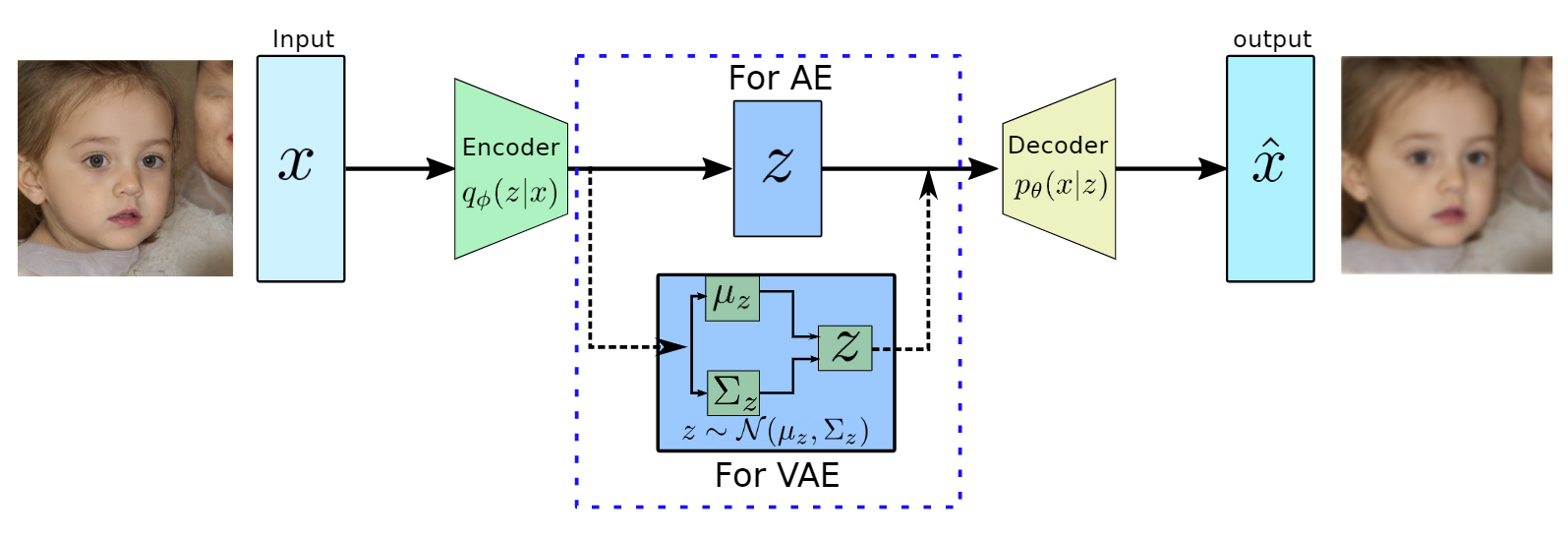
 usually has a much lower dimension than input
usually has a much lower dimension than input  and has the most dominant features of
and has the most dominant features of 
 to approximate the conditional
to approximate the conditional  to generate images based on a sample from a true prior,
to generate images based on a sample from a true prior,  are generally of Gaussian distribution.
are generally of Gaussian distribution. as it will be performing probabilistic generation of data. Therefore the encoder and decoder should be probabilistic.
as it will be performing probabilistic generation of data. Therefore the encoder and decoder should be probabilistic. prior distribution, which is a Gaussian function, therefore, both of them are tractable. However, the integration won’t be tractable because of the high dimensionality of data.
prior distribution, which is a Gaussian function, therefore, both of them are tractable. However, the integration won’t be tractable because of the high dimensionality of data. to approximate the conditional
to approximate the conditional  . Furthermore, the conditional
. Furthermore, the conditional  , which is intractable. This additional encoder part will help to derive a lower bound on the data likelihood that will make the likelihood function tractable. In the following we will derive the lower bound of the likelihood function:
, which is intractable. This additional encoder part will help to derive a lower bound on the data likelihood that will make the likelihood function tractable. In the following we will derive the lower bound of the likelihood function:![\begin{equation*} \begin{flalign} \begin{aligned} log \: p_\theta (x) = & \mathbf{E}_{z\sim q_\phi(z|x)} \Bigg[log \: \frac{p_\theta (x|z) p_\theta (z)}{p_\theta (z|x)} \: \frac{q_\phi(z|x)}{q_\phi(z|x)}\Bigg] \\ = & \mathbf{E}_{z\sim q_\phi(z|x)} \Bigg[log \: p_\theta (x|z)\Bigg] - \mathbf{E}_{z\sim q_\phi(z|x)} \Bigg[log \: \frac{q_\phi (z|x)} {p_\theta (z)}\Bigg] + \mathbf{E}_{z\sim q_\phi(z|x)} \Bigg[log \: \frac{q_\phi (z|x)}{p_\theta (z|x)}\Bigg] \\ = & \mathbf{E}_{z\sim q_\phi(z|x)} \Big[log \: p_\theta (x|z)\Big] - \mathbf{D}_{KL}(q_\phi (z|x), p_\theta (z)) + \mathbf{D}_{KL}(q_\phi (z|x), p_\theta (z|x)). \end{aligned} \end{flalign} \end{equation*}](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-94567d6202e7ed5971ce2e83cbc2d369_l3.png "Rendered by QuickLaTeX.com")
 and then it is expanded using Bayes theorem with additional constant
and then it is expanded using Bayes theorem with additional constant  multiplication. In the next line, it is expanded using the logarithmic rule and then rearranged. Furthermore, the last two terms in the second line are the definition of KL divergence and the third line is expressed in the same.
multiplication. In the next line, it is expanded using the logarithmic rule and then rearranged. Furthermore, the last two terms in the second line are the definition of KL divergence and the third line is expressed in the same.
![\begin{equation*} log \: p_\theta (x)\geq \mathcal{L}(x, \phi, \theta) , \: \text{where} \: \mathcal{L}(x, \phi, \theta) = \mathbf{E}_{z\sim q_\phi(z|x)} \Big[log \: p_\theta (x|z)\Big] - \mathbf{D}_{KL}(q_\phi (z|x), p_\theta (z)). \end{equation*}](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-959a973388a0ab24ad2464bb87d185e7_l3.png "Rendered by QuickLaTeX.com")
 is presenting the tractable lower bound for the optimization and is also termed as ELBO (Evidence Lower Bound Optimization). During the training process, we maximize ELBO using the following equation:
is presenting the tractable lower bound for the optimization and is also termed as ELBO (Evidence Lower Bound Optimization). During the training process, we maximize ELBO using the following equation: