Webinar zum Statistikprogramm R
Anzeige
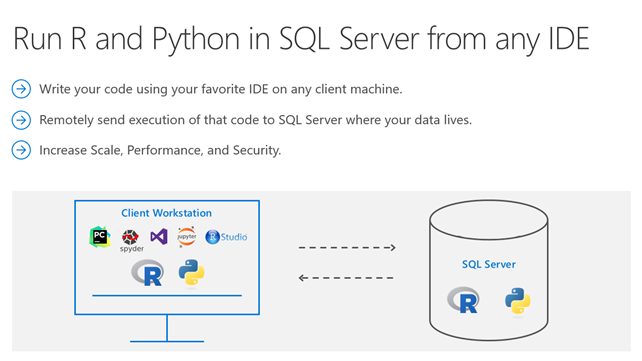
R – ein unverzichtbares Werkzeug für Data Scientists. Lassen Sie auch Ihre Mitarbeitenden auf den neusten Stand in der Open Source Statistiksoftware R aus der modernen Datenanalyse bringen. Zielgruppe unserer Fortbildungen sind nicht nur Statistikerinnen und Statistiker, sondern auch Anwenderinnen und Anwender jeder Fachrichtung aus Industrie und Forschungseinrichtungen, die mit R ihre Daten effektiv analysieren möchten. Die Teilnehmenden erwerben Qualifikationen zur selbstständigen Analyse eigener Daten sowie Schlüsselkompetenzen im Umgang mit Big Data.
Webinar zum Statistikprogramm R
Inhalte Basiskurs:
- Installation von R und zugehöriger Entwicklungsumgebung
- Grundlagen von R: Syntax, Datentypen, Operatoren, Funktionen, Indizierung
- R-Hilfe effektiv nutzen
- Ein- und Ausgabe von Daten
- Behandlung fehlender Werte
- Statistische Kennzahlen
- Visualisierung
Inhalte Vertiefungskurs:
- Effizienter Umgang mit R:
- Eigene Funktionen, Schleifen vermeiden durch *apply – Einführung in ggplot2 und dplyr
- Statistische Tests und Lineare Regression
- Dynamische Berichterstellung
- Angewandte Datenanalyse anhand von Fallbeispielen
Termine:
- R-Basiskurs: 14. und 15. November 2022 (jeweils 9:00 – 17:30 Uhr)
- R-Vertiefungskurs: 17. und 18. November 2022 (jeweils 9:00 – 16:30 Uhr)
Kosten: pro 2-tägigem Kurs 750 €; bei Buchung beider Kurse im November erhalten Sie einen Preisnachlass von 200€
Weitere Informationen zu den Inhalten und zur Anmeldung finden Sie unter: https://wb.zhb.tu-dortmund.de/seminare/dortmunder-r-kurse/
Bei Fragen können Sie sich an Daniel Neubauer (daniel.neubauer@tu-dortmund.de; Tel.: 0231 755 6632) wenden.