
Data Literacy Day 2023 by StackFuel

Über den Organisator, StackFuel:
![]()
Über den Organisator, StackFuel:
![]()
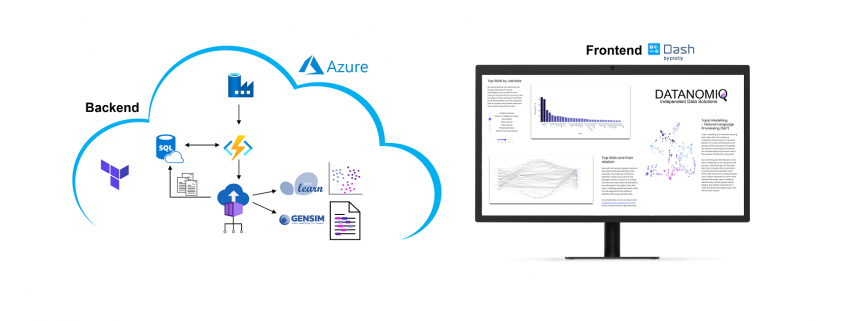
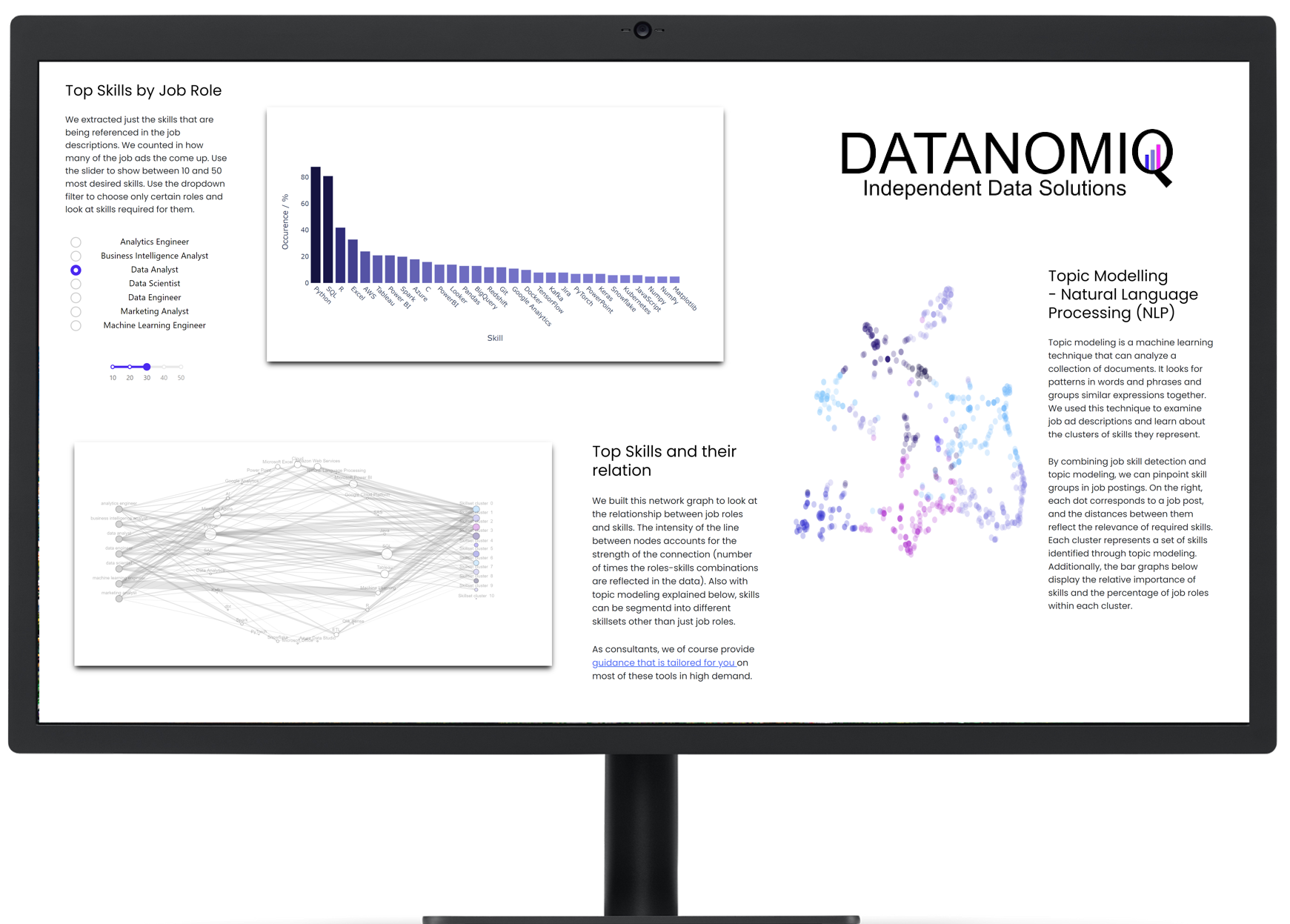
On own account, we from DATANOMIQ have created a web application that monitors data about job postings related to Data & AI from multiple sources (Indeed.com, Google Jobs, Stepstone.de and more).
The data is obtained from the Internet via APIs and web scraping, and the job titles and the skills listed in them are identified and extracted from them using Natural Language Processing (NLP) or more specific from Named-Entity Recognition (NER).
The skill clusters are formed via the discipline of Topic Modelling, a method from unsupervised machine learning, which show the differences in the distribution of requirements between them.
The whole web app is hosted and deployed on the Microsoft Azure Cloud via CI/CD and Infrastructure as Code (IaC).
The presentation is currently limited to the current situation on the labor market. However, we collect these over time and will make trends secure, for example how the demand for Python, SQL or specific tools such as dbt or Power BI changes.
Why we did it? It is a nice show-case many people are interested in. Over the time, it will provides you the answer on your questions related to which tool to learn! For DATANOMIQ this is a show-case of the coming Data as a Service (DaaS) Business.

Warum Data Engineering der Data Science in Bedeutung und Berufschancen längst die Show stiehlt, dabei selbst ebenso einem stetigen Wandel unterliegt.
Der Data Scientist als sexiest Job des 21. Jahrhunderts? Mag sein, denn der Job hat seinen ganz speziellen Reiz, auch auf Grund seiner Schnittstellenfunktion zwischen Technik und Fachexpertise. Doch das Spotlight der kommenden Jahre gehört längst einem anderen Berufsbild aus der Datenwertschöpfungskette – das zeigt sich auch bei den Gehältern.
Viele Unternehmen sind gerade auf dem Weg zum Data-Driven Business, einer Unternehmensführung, die für ihre Entscheidungen auf transparente Datengrundlagen setzt und unter Einsatz von Business Intelligence, Data Science sowie der Automatisierung mit Deep Learning und RPA operative Prozesse so weit wie möglich automatisiert. Die Lösung für diese Aufgabenstellungen werden oft vor allem bei den Experten für Prozessautomatisierung und Data Science gesucht, dabei hängt der Erfolg jedoch gerade viel eher von der Beschaffung valider Datengrundlagen ab, und damit von einer ganz anderen entscheidenden Position im Workflow datengetriebener Entscheidungsprozesse, dem Data Engineer.
Der Job des Data Scientists hingegen ist nach wie vor unter Studenten und Absolventen der MINT-Fächer gerade so gefragt wie nie, das beweist der tägliche Ansturm der vielen Absolventen aus Studiengängen rund um die Data Science auf derartige Stellenausschreibungen. Auch mangelt es gerade gar nicht mehr so sehr an internationalen Bewerben mit Schwerpunkt auf Statistik und Machine Learning. Der solide ausgebildete und bestenfalls noch deutschsprachige Data Scientist findet sich zwar nach wie vor kaum im Angebot, doch insgesamt gute Kandidaten sind nicht mehr allzu schwer zu finden. Seit Jahren sind viele Qualifizierungsangebote für Studenten sowie Arbeitskräfte am Markt auch günstig und ganz flexibel online verfügbar, ohne dabei Abstriche bei beim Ansehen dieser Aus- und Fortbildungsmaßnahmen in Kauf nehmen zu müssen.
Doch was bringt ein Data Scientist, wenn dieser gar nicht über die Daten verfügt, die für seine Aufgaben benötigt werden? Sicherlich ist die Aufgabe eines jeden Data Scientists auch die Vorbereitung und Präsentation seiner Vorhaben. Die Heranschaffung und Verwaltung großer Datenmengen in einer Enterprise-fähigen Architektur ist jedoch grundsätzlich nicht sein Schwerpunkt und oft fehlen ihm dafür auch die Berechtigungen in einer Enterprise-IT. Noch konkreter wird der Bedarf an Datenbeschaffung und -aufbereitung in der Business Intelligence, denn diese benötigt für nachhaltiges Reporting feste Strukturen wie etwa ein Data Warehouse.
Auch wenn Data Engineering von Hochschulen und Fortbildungsanbietern gerade noch etwas stiefmütterlich behandelt werden, werden der Einsatz und das daraus resultierende Anforderungsprofil eines Data Engineers am Markt recht eindeutig skizziert. Einsatzszenarien für diese Dateningenieure – auch auf Deutsch eine annehmbare Benennung – sind im Kern die Erstellung von Data Warehouse und Data Lake Systeme, mittlerweile vor allem auf Cloud-Plattformen. Sie entwickeln diese für das Anzapfen von unternehmensinternen sowie -externen Datenquellen und bereiten die gewonnenen Datenmengen strukturell und inhaltlich so auf, dass diese von anderen Mitarbeitern des Unternehmens zweckmäßig genutzt werden können.
Kein Data Engineer darf den eigentlichen Verbraucher der Daten aus den Augen verlieren, für den die Daten nach allen Regeln der Kunst zusammengeführt, bereinigt und in das Zielformat gebracht werden sollen. Klassischerweise arbeiten die Engineers am Data Warehousing für Business Intelligence oder Process Mining, wofür immer mehr Event Logs benötigt werden. Ein Data Warehouse ist der unter Wasser liegende, viel größere Teil des Eisbergs der Business Intelligence (BI), der die Reports mit qualifizierten Daten versorgt. Diese Eisberg-Analogie lässt sich auch insgesamt auf das Data Engineering übertragen, der für die Endanwender am oberen Ende der Daten-Nahrungskette meistens kaum sichtbar ist, denn diese sehen nur die fertigen Analysen und nicht die dafür vorbereiteten Datentöpfe.
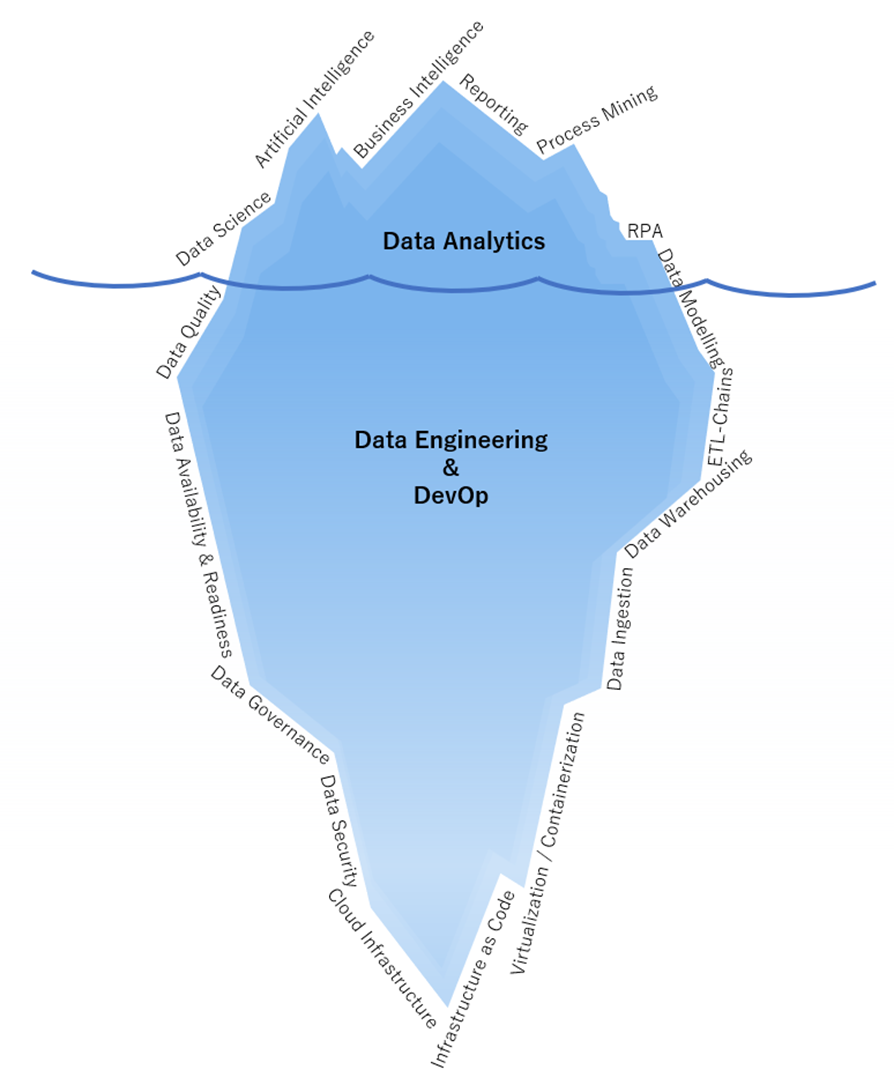
Abbildung 1 – Data Engineering ist der Mittelpunkt einer jeden Datenplattform. Egal ob für Data Science, BI, Process Mining oder sogar RPA, die Datenanlieferung bedingt gute Dateningenieure, die bis hin zur Cloud Infrastructure abtauchen können.
Daten liegen selten direkt in einer einzigen CSV-Datei strukturiert vor, sondern entstammen einer oder mehreren Datenbanken, die ihren eigenen Regeln unterliegen. Geschäftsdaten, beispielsweise aus ERP- oder CRM-Systemen, liegen in relationalen Datenbanken vor, oftmals von Microsoft, Oracle, SAP oder als eine Open-Source-Alternative. Besonders im Trend liegen derzeitig die Cloud-nativen Datenbanken BigQuery von Google, Redshift von Amazon und Synapse von Microsoft sowie die cloud-unabhängige Datenbank snowflake. Dazu gesellen sich Datenbanken wie der PostgreSQL, Maria DB oder Microsoft SQL Server sowie CosmosDB oder einfachere Cloud-Speicher wie der Microsoft Blobstorage, Amazon S3 oder Google Cloud Storage. Welche Datenbank auch immer die passende Wahl für das Unternehmen sein mag, ohne SQL und Verständnis für normalisierte Daten läuft im Data Engineering nichts.
Andere Arten von Datenbanken, sogenannte NoSQL-Datenbanken beruhen auf Dateiformaten, einer Spalten- oder einer Graphenorientiertheit. Beispiele für verbreitete NoSQL-Datenbanken sind MongoDB, CouchDB, Cassandra oder Neo4J. Diese Datenbanken exisiteren nicht nur als Unterhaltungswert gelangweilter Nerds, sondern haben ganz konkrete Einsatzgebiete, in denen sie jeweils die beste Performance im Lesen oder Schreiben der Daten bieten.
Ein Data Engineer muss demnach mit unterschiedlichen Datenbanksystemen zurechtkommen, die teilweise auf unterschiedlichen Cloud Plattformen heimisch sind.
Liegen Daten in einer Datenbank vor, können Analysten mit Zugriff einfache Analysen bereits direkt auf der Datenbank ausführen. Doch wie bekommen wir die Daten in unsere speziellen Analyse-Tools? Hier muss der Engineer seinen Dienst leisten und die Daten aus der Datenbank exportieren können. Bei direkten Datenanbindungen kommen APIs, also Schnittstellen wie REST, ODBC oder JDBC ins Spiel und ein guter Data Engineer benötigt Programmierkenntnisse, bevorzugt in Python, diese APIs ansprechen zu können. Etwas Kenntnis über Socket-Verbindungen und Client-Server-Architekturen zahlt sich dabei manchmal aus. Ferner sollte jeder Data Engineer mit synchronen und asynchronen Verschlüsselungsverfahren vertraut sein, denn in der Regel wird mit vertraulichen Daten gearbeitet. Ein Mindeststandard an Sicherheit gehört zum Data Engineering und darf keinesfalls nur Datensicherheitsexperten überlassen werden, eine Affinität zu Netzwerksicherheit oder gar Penetration-Testing ist positiv zu bewerten, mindestens aber ein sauberes Berechtigungsmanagement gehört zu den Grundfähigkeiten. Viele Daten liegen nicht strukturiert in einer Datenbank vor, sondern sind sogenannte unstrukturierte oder semi-strukturierte Daten aus Dokumenten oder aus Internetquellen. Mit Methoden wie Data Web Scrapping und Data Crawling sowie der Automatisierung von Datenabrufen beweisen herausragende Data Engineers sogar echte Hacker-Qualitäten.
Eine der Kernaufgaben des Data Engineers ist die Entwicklung von ETL-Strecken, um Daten aus Quellen zu Extrahieren, zu in das gewünschte Zielformat zu Transformieren und schließlich in die Zieldatenbank zu Laden. Dies mag erstmal einfach klingen, wird jedoch zur echten Herausforderung, wenn viele ETL-Prozesse sich zu ganzen ETL-Ketten und -Netzwerken zusammenfügen, diese dabei trotz hochfrequentierter Datenabfrage performant laufen müssen. Die Orchestrierung der Datenflüsse kann in der Regel in mehrere Etappen unterschieden werden, von der Quelle ins Data Warehouse, zwischen den Ebenen im Data Warehouse sowie vom Data Warehouse in weiterführende Systeme, bis hin zum Zurückfließen verarbeiteter Daten in das Data Warehouse (Reverse ETL).
In den letzten Jahren sind Anforderungen an Data Engineers deutlich gestiegen, denn neben dem eigentlichen Verwalten von Datenbeständen und -strömen für Analysezwecke wird zunehmend erwartet, dass ein Data Engineer auch Ressourcen in der Cloud managen, mindestens jedoch die Datenbanken und ETL-Ressourcen. Darüber hinaus wird zunehmend jedoch verlangt, IT-Netzwerke zu verstehen und das ganze Zusammenspiel der Ressourcen auch als Infrastructure as Code zu automatisieren. Auch das automatisierte Deployment von Datenarchitekturen über CI/CD-Pipelines macht einen Data Engineer immer mehr zum DevOp.
Im Vergleich zum Data Scientist, der besonders viel Methodenverständnis für Datenanalyse, Statistik und auch für das zu untersuchende Fachgebiet benötigt, sind Data Engineers mehr an Tools und Plattformen orientiert. Ein Data Scientist, der Deep Learning verstanden hat, kann sein Wissen zügig sowohl mit TensorFlow als auch mit PyTorch anwenden. Ein Data Engineer hingegen arbeitet intensiver mit den Tools, die sich über die Jahre viel zügiger weiterentwickeln. Ein Data Engineer für die Google Cloud wird mehr Einarbeitung benötigen, sollte er plötzlich auf AWS oder Azure arbeiten müssen.
Ein Data Engineer kann in Deutschland als Einsteiger mit guten Vorkenntnissen und erster Erfahrung mit einem Bruttojahresgehalt zwischen 45.000 und 55.000 EUR rechnen. Mehr als zwei Jahre konkrete Erfahrung im Data Engineering wird von Unternehmen gerne mit Gehältern zwischen 50.000 und 80.000 EUR revanchiert. Darüber liegen in der Regel nur die Data Architects / Datenarchitekten, die eher in großen Unternehmen zu finden sind und besonders viel Erfahrung voraussetzen. Weitere Aufstiegschancen für Data Engineers sind Berater-Karrieren oder Führungspositionen.
Wer einen Data Engineer in Festanstellung gebracht hat, darf sich jedoch nicht all zu sicher fühlen, denn Personalvermittler lauern diesen qualifizierten Fachkräften an jeder Ecke des Social Media auf. Gerade in den Metropolen wie Berlin schaffen es längst nicht alle Unternehmen, jeden Data Engineer über Jahre hinweg zu beschäftigen. Bei der großen Auswahl an Jobs und Herausforderungen fällt diesen Datenexperten nicht schwer, seine Gehaltssteigerungen durch Jobwechsel proaktiv voranzutreiben.

Ein Softwareunternehmen generierte durch Marketing- und Sales-Aktivitäten eine große Anzahl potenzieller Leads, die nicht alle gleichzeitig bearbeitet werden konnten. Die zentrale Frage war nun: Wie kann eine Priorisierung der Leads erfolgen, sodass erfolgsversprechende Leads zuerst bearbeitet werden können?
Definition: Ein Lead bezeichnet einen Kontakt zu einem/einer potenziellen Kund:in, die/der sich für ein Produkt oder eine Dienstleistung eines Unternehmens interessiert und deren/dessen Kontaktdaten dem Unternehmen vorliegen. Solche Leads können durch Online- und Offline-Werbemaßnahmen gewonnen werden.
In der Vergangenheit beruhte die Priorisierung und somit auch die Bearbeitung der Leads in dem Unternehmen häufig auf der persönlichen Erfahrung der zuständigen Vertriebsmitarbeiter:innen. Diese Vorgehensweise ist jedoch sehr ressourcenintensiv und stark abhängig von der Erfahrung einzelner Vertriebsmitarbeiter:innen.
Aus diesem Grund beschloss das Unternehmen, ein KI-gestütztes System zu entwickeln, welches zum einen erfolgsversprechende Leads datenbasiert priorisiert und zum anderen Handlungsempfehlungen für die Vertriebsmitarbeiter:innen bereitstellt.
Grundlage dieses Projektes waren bereits vorhandene Daten zu früheren Leads sowie CRM-Daten zu bereits geschlossenen Aufträgen und Deals mit diesen früheren Leads. Dazu gehörten beispielsweise:
Diese Daten aus der Vergangenheit konnten zunächst einer explorativen Datenanalyse unterzogen werden, bei der untersucht wurde, inwiefern die Eigenschaften der Leads und das Verhalten der Vertriebsmitarbeiter:innen in der Vergangenheit einen Einfluss darauf hatten, ob es mit einem Lead zu einem Geschäftsabschluss kam oder nicht.
Diese Erkenntnisse aus den vergangenen Leads sollten jedoch nun auch auf aktuelle bzw. zukünftige Leads und die damit verbundenen Vertriebsaktivitäten übertragen werden. Deshalb ergaben sich aus der explorativen Datenanalyse zwei weiterführende Fragen:
Durch die explorative Datenanalyse konnte das Unternehmen bereits erste Einblicke in die verschiedenen Eigenschaften der Leads erlangen. Bei einigen dieser Eigenschaften ist anzunehmen, dass sie die Wahrscheinlichkeit erhöhen, dass ein:e potenzielle:r Kund:in Interesse am Produkt des Unternehmens zeigt. Es gibt mehrere Wege, um die Erkenntnisse aus der explorativen Datenanalyse nun für zukünftiges Verhalten der Vertriebsmitarbeiter:innen zu nutzen.
Auf Grundlage der explorativen Datenanalyse und der dort gewonnenen Erkenntnisse könnte das Unternehmen, z. B. dessen Vertriebsleitung, bestimmte Regeln oder Kriterien definieren, wie beispielsweise die Unternehmensgröße des Kunden oder die Branche. So könnte die Vertriebsleitung anordnen, dass Leads aus größeren Unternehmen oder aus Unternehmen aus dem Energiesektor priorisiert behandelt werden sollten, weil diese Leads auch in der Vergangenheit zu erfolgreichen Geschäftsabschlüssen geführt haben.
Der Vorteil eines solchen regelbasierten Vorgehens ist, dass es einfach zu definieren und schnell umzusetzen ist.
Der Nachteil ist jedoch, dass die hier definierten Regeln sehr starr sind und dass Menschen meist nicht in der Lage sind, mehr als zwei oder drei der Eigenschaften gleichzeitig zu betrachten. Obwohl sich die Regeln dann zwar grundsätzlich an den Erkenntnissen aus den Daten orientieren, hängen sie doch immer noch stark vom Bauchgefühl der Vertriebsleitung ab.
Ein besserer Ansatz war es, die vergangenen Leads anhand aller verfügbaren Eigenschaften in Gruppen einzuteilen, innerhalb derer die Leads sich einander stark ähneln. Hierfür kommt ein maschinelles Lernverfahren namens Clustering zum Einsatz, welches genau dieses Ziel verfolgt: Beim Clustering werden Datenpunkte, also in diesem Falle die Leads, anhand ihrer Eigenschaften, also beispielsweise die Unternehmensgröße oder die Branche, aber auch ob es zu einem Geschäftsabschluss kam oder nicht, zusammengefasst.
Beispiel: Leads aus Unternehmen zwischen 500 und 999 Mitarbeitern aus der Energiebranche kauften 250 Lizenzen der Software A.
Kommt nun ein neuer Lead hinzu, kann er anhand seiner bereits bekannten Eigenschaften einem Cluster zugeordnet werden. Anschließend können die Vertriebsmitarbeiter:innen jene Leads priorisieren, die einem Cluster zugeordnet worden sind, in dem in der Vergangenheit bereits häufig erfolgreich Geschäfte abgeschlossen worden sind.
Der Vorteil eines solchen datenbasierten Vorgehens ist, dass eine Vielzahl an Kriterien gleichzeitig in die Priorisierung einbezogen werden kann.
Im zweiten Schritt wurde eine weitere Frage gestellt: Welche Aktivitäten der Vertriebsmitarbeiter:innen führen zu einem erfolgreichen Geschäftsabschluss mit einem Lead? Dabei standen nicht nur die Leistungen einzelner Mitarbeiter:innen im Fokus, sondern auch die übergreifenden Muster, die beim Vergleich der verschiedenen Mitarbeiter:innen deutlich wurden. Mithilfe von Process Mining konnte festgestellt werden, welche Maßnahmen und Aktivitäten der Vertriebler:innen im Umgang mit einem Lead zum Erfolg bzw. zu einem Misserfolg geführt hatten. Weniger erfolgsversprechende Maßnahmen konnten somit in der Zukunft vermieden werden.
Vor allem zeitliche Aspekte spielten hierbei eine Rolle: Parameter, die aussagten, wie schnell oder an welchem Wochentag Leads eine Antwort erhielten, waren entscheidend für erfolgreiche Geschäftsabschlüsse. Diese Erkenntnisse konnte das Unternehmen dann in zukünftige Sales Trainings sowie die Sales-Strategie einfließen lassen.
In diesem Projekt konnte die Sales-Abteilung des Softwareunternehmens durch zwei verschiedene Ansätze die Priorisierung der Leads und damit die Geschäftsabschlüsse deutlich verbessern:
Mithilfe des Clustering war es möglich, Leads in Gruppen einzuteilen, die sich in ihren Eigenschaften ähneln, u.a. auch in der Eigenschaft, ob es zu einem Geschäftsabschluss kommt oder nicht. Neue Leads wurden den verschiedenen Clustern zuordnen. Leads, die einem Cluster mit hoher Erfolgswahrscheinlichkeit zugeordnet wurden, konnten nun priorisiert bearbeitet werden.
Mithilfe von Process Mining wurden erfolgsversprechende Aktivitäten der Sales-Mitarbeiter:innen identifiziert und skaliert. Umgekehrt wurden wenig erfolgsversprechende Aktivitäten erkannt und eliminiert, um Ressourcen zu sparen.
Infolgedessen konnte das Softwareunternehmen Leads erfolgreicher bearbeiten und höhere Umsätze erzielen.
Quants kennt man aus Filmen wie Margin Call, The Hummingbird Project oder The Big Short. Als coole Typen oder introvertierte Nerds dargestellt, geht es in diesen Filmen im Kern um sogenannte Quantitative Analysts, oder kurz Quants, die entweder die großen Trading Deals abschließen oder Bankenpleiten früher als alle anderen Marktteilnehmer erkennen, stets mit Computern und Datenzugriffen ausgestattet, werfen Sie tiefe Blicke in die Datenbestände von Finanzinstituten und Märken, das alles unter Einsatz von Finanzmathematik.
Quants sind in diesen und anderen Filmen (eine Liste für das persönliche Abendprogramm füge ich unten hinzu) die Helden, manchmal auch die Gangster oder eine Mischung aus beiden. Den Hackern nicht unähnlich, scheinen sie in Filmen geradezu über Super-Kräfte zu verfügen, dem normalen Menschen, ja sogar dem erfahrenen Banken-Manager gegenüber deutlich überlegen zu sein. Nicht von ungefähr daher auch “Quant”, denn die Kurzform gefällt mit der namentlichen Verwechslungsgefahr gegenüber der kaum verstandenen Quantenphysik, mit der hier jedoch kein realer Bezug besteht.
Auf Grundlage der Filme zu urteilen, scheint der Quant dem Data Scientist in seiner Methodik dem Data Scientist ebenbürtig zu sein, wenn auch mit wesentlich prominenterer Präsenz in Kinofilmen.
Kleiner Hinweis zu den Geschlechtern: Mit Quant, Analyst und Scientist sind stets beide biologische Geschlechter gemeint. In den Filmen scheinen diese nahezu ausschließlich männlich zu sein, in der Realität aber habe ich in etwa genauso viele weibliche wie männliche Quants und Data Scientists kennenlernen dürfen.
Um es gleich vorweg zu nehmen: Gar nicht so viel, aber dann doch ganze Welten.
Während die Bezeichnung des Berufes Data Scientists bereits ausführlich erläutert wurde – siehe den Data Science Knowledge Stack – haben wir uns auf dieser Seite noch gar nicht mit dem Quantitative Analyst befasst, der ausgeschriebenen Bezeichnung des Quants. Vom Wortlaut der Berufsbezeichnung her betrachtet gehören Quants zu den Analysten oder genauer zu den Financial Analysts. Sie arbeiten oft in Banken oder auch Versicherungen. In letzteren arbeiten sie vor allem an Analysen rund um Versicherungs- und Liquiditätsrisiken. Auch andere Branchen wie der Handel oder die Energiebranche arbeiten mit Quantitativen Analysten, z. B. bei der Optimierung von Preisen und Mengen.
Aus den Filmen kennen wir Quants beinahe ausschließlich aus dem Investmentbanking und Risikomanagement, hier sind sie die Ersten, die Finanzschwierigkeiten aufdecken oder neue Handelschancen entdecken, auf die andere nicht kommen. Die Außenwahrnehmung ist denen der Hacker gar nicht so unähnlich, tatsächlich haben sie auch Berührungspunkte (nicht aber Überlappungen in ihren Arbeitsbereichen) zumindest mit forensischen Analysten, wenn es um die Aufdeckung von Finanzskandalen bzw. dolose Handlungen (z. B. Bilanzmanipulation, Geldwäsche oder Unterschlagung) geht. Auch bei Wirtschaftsprüfungsgesellschaften arbeiten Quants, sind dort jedoch eher als Consultants für Audit oder Forensik bezeichnet. Diese setzen ebenfalls vermehrt auf Data Science Methoden.
In ihrer Methodik sind sie sowohl in Filmen als auch in der Realität der Data Science nicht weit entfernt, so analysieren Sie Daten oft direkt auf der Datenbank oder in ihrem eigenen Analysesystem in einer Programmiersprache wie R oder Python. Sie nutzen dabei die Kunst der Datenzusammenführung und -Visualisierung, arbeiten auf sehr granularen Daten, filtern diese entsprechend ihres Analysezieles, um diese zu einer Gesamtaussage z. B. über die Liquiditätssituation des Unternehmens zu verdichten. Im Investmentbanking nutzen Quants auch Methoden aus der Statistik und des maschinellen Lernens. Sie vergleichen Daten nach statistischen Verteilungen und setzen auf Forecasting-Algorithmen zur Optimierung von Handelsstrategien, bis hin zum Algorithmic Trading.
Quants arbeiten, je nach Situation und Erfahrungsstufe, auch mit den Methoden aus der Data Science. Ein Quant kann folglich ein Data Scientist sein, ist es jedoch nicht zwingend. Ein Data Scientist ist heutzutage darüber hinaus jedoch ein genereller Experte für Statistik und maschinelles Lernen und kann dies nahezu branchenunabhängig einbringen. Andererseits spezialisieren sich Data Scientists mehr und mehr auf unterschiedliche Themenbereiche, z. B. NLP, Computer Vision, Maschinen-Sensordaten oder Finanz-Forecasts, womit wir bei letzterem wieder bei der quantitativen Finanz-Analyse angelangt sind. Die Data Science tendiert darüber hinaus jedoch dazu, sich nahe an die Datenbereitstellung (Data Engineering) – auch unstrukturierte Daten – sowie an die Modell-Bereitstellung (Deployment) anzuknüpfen (MLOp).
Der Vergleich zwischen Quant und Data Scientist hinkt, denn beide Berufsbezeichnungen stehen nicht auf der gleichen Ebene, ein Quant kann auch ein Data Scientist sein, muss es jedoch nicht. Beim Quant handelt es sich, je nach Fähigkeit und Tätigkeitsbedarf, um einen Data Analyst oder Scientist, der insbesondere Finanzdaten auf Chancen und Risiken hin analysiert. Dies kann ich nahezu allen Branchen erfolgen, haben in Hollywood-Filmen ihre Präsenz dem Klischee entsprechend in einer Investmentbank und sind dort tiefer drin als alle anderes (was der Realität durchaus entsprechen kann).
Lust auf abgehobene Inspiration aus Hollywood? Hier Liste an Filmen mit oder sogar über Quants [in eckigen Klammern das Kernthema des Films]:
Meine besondere Empfehlung ist “Margin Call” von 2011. Hier kommt die Bedeutung der Quants im Investment Banking besonders eindrucksvoll zur Geltung.
Data Scientists haben in Hollywood noch nicht ganz die Aufmerksamkeit des Quants bekommen, ein bisschen etwas gibt es aber auch hier zur Unterhaltung, ein Auszug:
Meine persönliche Empfehlung ist Moneyball von 2011. Hier wurde zum ersten Mal im Kino deutlich, dass Statistik kein Selbstzweck ist, sondern sogar bei Systemen (z. B. Spielen) mit hoher menschlicher Individualität richtige Vorhersagen treffen kann.

Die digitale Transformation nimmt Fahrt auf und stellt sowohl Arbeitgeber:innen als auch Arbeitnehmer:innen vor neue Herausforderungen. Um mit dieser Entwicklung Schritt zu halten, lohnt es sich, auf den Zug aufzuspringen und das eigene Portfolio um wichtige Schlüsselkompetenzen zu erweitern. Doch in der heutigen Zeit, wo täglich mehr Lernoptionen und -angebote auf den Markt drängen, ist es besonders wichtig, die eigene, knappe Zeit in die richtigen, zukunftsträchtigen Fähigkeiten zu investieren.
Infolge des rasanten, digitalen Wandels haben sich neue, wichtige Qualifikationen herauskristallisiert, die sich langfristig für Lernwillige auszahlen. Insbesondere technische Fähigkeiten werden von Unternehmen dringend benötigt, um den eigenen Marktanteil zu verteidigen. Unter allen möglichen Qualifikationen hat sich eine bestimmte Fähigkeit in den letzten Jahren von vielversprechend zu unverzichtbar gemausert: Die Programmiersprache Python. Denn Python ist insbesondere in den vergangenen fünf Jahren dem Image des Underdogs entwachsen und hat sich zum Champion unter den Tech-Skills entwickelt.
Wer jetzt denkt, dass Python als Programmiersprache nur für ITler und Tech Nerds lohnenswert ist: Weit gefehlt! Viele Unternehmen beginnen gerade erst die wahren Möglichkeiten von Big Data und künstlicher Intelligenz zu erschließen und Führungskräfte suchen aktiv nach Mitarbeiter:innen, die in der Lage sind, diese Transformation durch technische Fähigkeiten zu unterstützen. Wenn Sie sich in diesem Jahr weiterentwickeln möchten und nach einer Fähigkeit Ausschau halten, die Ihre Karriere weiter voranbringt und langfristig sichert, dann ist dies der ideale Zeitpunkt für Sie, sich mit Python weiterzuqualifizieren.
Falls Sie bei dem Wort Python eher an glänzende Schuppen denken als an Programmcode, dann lassen Sie uns Ihnen etwas Kontext geben: Python ist eine Programmiersprache, die für die Entwicklung von Software genutzt wird. Als serverseitige Sprache ist sie die Logik und das Fundament hinter Benutzereingaben und der Interaktion von Datenbanken mit dem Server. Python ist Open-Source, kostenlos und kann von jedem benutzt und verändert werden, weshalb ihre Verwendung besonders in der Datenwissenschaft sehr beliebt ist. Nicht zuletzt lebt Python von seiner Community, einer engagierten Gemeinschaft rund um die Themen künstliche Intelligenz, maschinelles Lernen, Datenanalyse und -modellierung, mit umfangreichen Ressourcen und über 137.000 Bibliotheken wie TensorFlow, Scikit-learn und Keras.
In der Data Science wird Python verwendet, um große Mengen komplexer Daten zu analysieren und aus ihnen relevante Informationen abzuleiten. Lohnt es sich also, Python zu lernen? Absolut! Laut der Stack Overflow Developer Survey wurde Python 2020 als die drittbeliebteste Technologie des Jahres eingestuft. Sie gilt als eine der angesagtesten Fähigkeiten und als beliebteste Programmiersprache in der Welt nach Angaben des PYPL Popularität der Programmiersprache Index. Wir haben 7 Gründe zusammengefasst, warum es sich jetzt lohnt, Python zu lernen:.
Python ist ein wahrer Allrounder unter den Hard Skills! Ein wesentlicher Vorteil von Python ist, dass es in einer Vielzahl von Fachbereichen eingesetzt werden kann. Die häufigsten Bereiche, in denen Python Verwendung findet, sind u. a.:
Diejenigen, für die sich eine neue Fähigkeit doppelt lohnen soll, liegen mit Python goldrichtig. Python-Entwickler:innen zählen seit Jahren zu den Bestbezahltesten der Branche. Und auch Data Scientists, für deren Job Python unerlässlich ist, liegen im weltweiten Gehaltsrennen ganz weit vorn. Die Nachfrage nach Python-Entwickler:innen ist hoch – und wächst. Und auch für andere Abteilungen wird die Fähigkeit immer wertvoller. Wer Python beherrscht, wird nicht lange nach einem guten Job Ausschau halten müssen. Unter den Top 10 der gefragtesten Programmier-Skills nach denen Arbeitgeber:innen suchen, liegt Python auf Platz 7. Die Arbeitsmarktaussichten sind also hervorragend.
2016 war das schillernde Jahr, in dem Python Java als beliebteste Sprache an US-Universitäten ablöste und seitdem ist die Programmiersprache besonders unter Anfänger:innen sehr beliebt. In den letzten Jahren konnte Python seine Pole Position immer weiter ausbauen. Und das mit gutem Grund: Python ist leicht zu erlernen und befähigt seine Nutzer:innen dazu, eigene Webanwendungen zu erstellen oder simple Arbeitsabläufe zu automatisieren. Dazu bringt Python eine aufgeräumte und gut lesbare Syntax mit, was sie besonders einsteigerfreundlich macht. Wer mit dem Programmieren anfängt, will nicht mit einer komplizierten Sprache mit allerhand seltsamen Ausnahmen starten. Mit Python machen Sie es sich einfach und sind dennoch effektiv. Ein Doppelsieg!
Mit der Python-Programmierung erwarten Sie nicht nur schnelle Lernerfolge, auch Ihre Arbeit wird effektiver und damit schneller. Im Gegensatz zu anderen Programmiersprachen, braucht die Entwicklung mit Python weniger Code und damit weniger Zeit. Für alle Fans von Effizienz ist Python wie gemacht. Und sie bietet einen weiteren großen Zeitbonus. Unliebsame, sich wiederholende Aufgaben können mithilfe von Python automatisiert werden. Wer schon einmal Stunden damit verbracht hat, Dateien umzubenennen oder Hunderte von Tabellenzeilen zu aktualisieren, der weiß, wie mühsam solche Aufgaben sein können. Umso schöner, dass diese Aufgaben von jetzt an von Ihrem Computer erledigt werden könnten.
Ob im Marketing, Sales oder im Business Development, Python hat sich längst aus seiner reinen IT-Ecke heraus und in andere Unternehmensbereiche vorgewagt. Denn auch diese Abteilungen stehen vor einer Reihe an Herausforderungen, bei denen Python helfen kann: Reporting, Content-Optimierung, A/B-Tests, Kundensegmentierung, automatisierte Kampagnen, Feedback-Analyse und vieles mehr. Mit Python können Erkenntnisse aus vorliegenden Daten gewonnen werden, besser informierte, datengetriebene Entscheidungen getroffen werden, viele Routineaktivitäten automatisiert und der ROI von Kampagnen erhöht werden.
Wollten Sie schon immer für einen Tech-Giganten wie Google oder Facebook arbeiten? Dann könnte Python Ihre goldene Eintrittskarte sein, denn viele große und vor allem technologieaffine Unternehmen wie YouTube, IBM, Dropbox oder Instagram nutzen Python für eine Vielzahl von Zwecken und sind immer auf der Suche nach Nachwuchstalenten. Dropbox verwendet Python fast für ihr gesamtes Code-Fundament, einschließlich der Analysen, der Server- und API-Backends und des Desktop-Clients. Wenn Sie Ihrem Lebenslauf einen großen Namen hinzufügen wollen, sollte Python auf demselben Blatt zu finden sein.
Besonders Pythons Anwendung in der Datenwissenschaft und im Data Engineering treibt seine Popularität in ungeahnte Höhen. Aber was macht Python so wichtig für Data Science und Machine Learning? Lange Zeit wurde R als die beste Sprache in diesem Spezialgebiet angesehen, doch Python bietet für die Data Science zahlreiche Vorteile. Bibliotheken und Frameworks wie PyBrain, NumPy und PyMySQL für KI sind wichtige Argumente. Außerdem können Skripte erstellt werden, um einfache Prozesse zu automatisieren. Das macht den Arbeitsalltag von Datenprofis besonders effizient.
![]() Investieren Sie in Ihre berufliche Zukunft und starten Sie jetzt Ihre Python-Weiterbildung! Egal, ob Programmier-Neuling oder Data Nerd: Die Haufe Akademie bietet die passende Weiterbildung für Sie: spannende Online-Kurse für Vollberufstätige und Schnelldurchläufer:innen im Bereich Python, Daten und künstliche Intelligenz.
Investieren Sie in Ihre berufliche Zukunft und starten Sie jetzt Ihre Python-Weiterbildung! Egal, ob Programmier-Neuling oder Data Nerd: Die Haufe Akademie bietet die passende Weiterbildung für Sie: spannende Online-Kurse für Vollberufstätige und Schnelldurchläufer:innen im Bereich Python, Daten und künstliche Intelligenz.
In Kooperation mit stackfuel.![]()
Get in IT: “WELCHE PROGRAMMIERSPRACHE SOLLTEST DU LERNEN?” [11.06.2021]
Coding Nomads: “Why Learn Python? 6 Reasons Why it’s So Hot Right Now.” [11.06.2021]
Das allgegenwärtige Internet und die Digitalisierung haben heutzutage viele Veränderungen in den Geschäften überall auf der Welt mit sich gebracht. Aus diesem Grund wird Data Science immer wichtiger.
In der Data Science werden große Datenmengen an Informationen aus allen Arten von Quellen gesammelt, sowohl aus strukturierten als auch aus unstrukturierten Daten. Dazu werden Techniken und Theorien aus verschiedenen Bereichen der Statistik, der Informationswissenschaft, der Mathematik und der Informatik verwendet.
Datenexperten und -expertinnen, d. h. Data Scientists, beschäftigen sich genau mit dieser Arbeit. Wenn Du Data Scientist werden möchten, kannst Du eine große Karriere in der Data Science beginnen, indem Du Dich für eine beliebige geeignete Weiterbildung einschreibst, der Deinem Talent, Deinen Interessen und Deinen Fähigkeiten in einigen der wichtigsten Data-Science-Kurse entspricht.
Was machen Data Scientists?
Zunächst einmal ist es wichtig zu verstehen, was man eigentlich unter dem Begriff „Data Scientist” versteht. Data Scientist ist lediglich ein neuer Beruf, der in vielen Artikeln häufig zusammen mit dem der Data Analysts beschrieben wird, weil die erforderlichen Grundfertigkeiten recht ähnlich sind. Vor allem müssen Data Scientists die Fähigkeit haben, Daten aus MySQL-Datenbanken zu extrahieren, Pivot-Tabellen in Excel zu verwalten, Datenbankansichten zu erstellen und Analytics zu verwalten.
Data Scientists werden viele Stellen in Unternehmen angeboten, die mit der zunehmenden Verfügbarkeit von Daten konfrontiert sind und Personen brauchen, die ihnen bei der Entwicklung der Infrastruktur helfen, die sie zur Verwaltung der Daten benötigen. Oft handelt es sich um Unternehmen, die ihre ersten Schritte in diesem Bereich machen. Dafür benötigen sie eine Person mit grundlegenden Fähigkeiten in der Softwaretechnik, um den gesamten Prozess voranzutreiben.
Dann gibt es stark datenorientierte Unternehmen, für diejenigen Daten sozusagen Rohprodukt und Rohstoff darstellen. In diesen Unternehmen werden Datenanalyse und maschinelles Lernen recht intensiv betrieben, wodurch Personen mit guten mathematischen, statistischen oder sogar physikalischen Fähigkeiten benötigt werden.
Es gibt auch Unternehmen, die keine Daten als Produkt haben, aber ihre Zukunft auf sie und ihre Sinne planen und abstimmen. Diese Unternehmen werden immer mehr und brauchen sowohl Data Scientists mit grundlegenden Fähigkeiten als auch Data Scientists mit speziellen Kenntnissen, von Visualisierung bis hin zu Machine Learning.
Kompetenzen der Data Scientists
Die Grundlagen sind zunächst für alle, die im Bereich der Data Science arbeiten, dieselben. Unabhängig von den Aufgaben, die Data Scientists zu erfüllen haben, muss man grundlegende Softwaretechnik beherrschen.
Selbstverständlich müssen Data Scientists mit Programmiersprachen wie R oder Python und mit Datenbanksprachen wie SQL umgehen können. Sie bedienen sich dann statistischer, grundlegender Fähigkeiten um zu bestimmen, welche Techniken für die zu erreichenden Ziele am besten geeignet sind.
Ebenso sind beim Umgang mit großen Datenmengen und in sogenannten „datengetriebenen” Kontexten Techniken und Methoden des maschinellen Lernens wichtig: KNN-Algorithmen (Nächste-Nachbarn-Klassifikation für Mustererkennung), Random Forests oder Ensemble Techniken kommen hier zum Einsatz.
Entscheidend ist, die für den jeweiligen Kontext am besten geeignete Technik unterscheiden zu können, und dies bevor man die verschiedenen Werkzeuge beherrscht.
Die lineare Algebra und die multivariate Berechnung sind auch unerlässlich. Sie bilden die Grundlage für viele der oben beschriebenen Fähigkeiten und können sich als nützlich erweisen, wenn das mit den Daten arbeitende Team beschließt, intern eigene Implementierungen zu entwickeln.
Eins ist noch entscheidend. In einer idealen Welt werden die Daten korrekt identifiziert, da sie vollständig und kohärent sind. In der realen Welt muss sich der Data Scientist mit unvollkommenen Daten auseinandersetzen, d. h. mit fehlenden Werten, Inkonsistenzen und unterschiedlichen Formatierungen. Hier kann man von Munging sprechen, d. h. von der Tätigkeit, die sogenannten Rohdaten in Daten umzuwandeln, die ein einheitliches Format haben und somit in den Prozess der Aufnahme und Analyse einbezogen werden können.
Wenn Daten als wesentlich für Geschäftsentscheidungen sind, reicht es nicht aus, eine Person zu haben, die sie verarbeiten, analysieren und aufnehmen kann. Die Visualisierung und Kommunikation von Daten ist ebenso zentral. Daten zu visualisieren und zu kommunizieren bedeutet, anderen die angewandten Techniken und die erzielten Ergebnisse zu beschreiben. Daher ist es wichtig zu wissen, wie man Visualisierungswerkzeuge wie ggplot oder D3.js verwendet.
Ausbildungsmöglichkeiten und Bootcamps, um Data Scientist zu werden
Kurz gesagt gibt es zwei gängige Wege, um Data Scientist zu werden.
Bei dieser DataScientest-Weiterbildung haben die Lernenden die Wahl zwischen einer weitgehenden Ausbildung (10 Stunden pro Woche) oder einer Bootcamp-Ausbildung (35 Stunden pro Woche).
Das am Ende des Kurses erworbene Zertifikat wird von der Pariser Universität La Sorbonne anerkannt.

In 2009, Google Chief Economist Hal Varian said to the McKinsey Quarterly that “the sexy job in the next 10 years will be statisticians.”
At the time, it was hard to believe. But more than a decade later, we can’t get around the importance of data. Where once oil ruled the world, data is now catching up—quickly. That calls for more and better data scientists. In this article, we’ll explain to you how to find them.

Source: https://www.pexels.com/
The demand for data scientist roles has increased by 650 percent since 2012, and that number will continue to grow as the amount of data—and power it holds—grows steadily, too.
But unsurprisingly, there hasn’t been an increase of 650 percent in available data scientists on the job market. Even though the job is a lot sexier—and better paid—than ten years ago, many employers are still struggling to fill their empty seats with talented data scientists.
McKinsey predicted that there would be a shortage of between 140,000 and 190,000 people with analytical skills in the U.S. alone in 2018, and even in 2022 good data scientists, data analysts, forecasting analysts, modelling analysts, machine learning scientists, are hard to find.
Add to that another 1.5 million managers who will also need to at least understand how data analysis drives decision-making, and you can see how employers can be in a bit of a pickle.
Even though demand is growing much faster than the number of data scientists, companies can’t simply settle for the first data lover who’s available from Monday to Friday.
It’s no longer the company with the most data that wins the game. The ones who are taking the lead are the ones that are able to get the most out of data. They can pull valuable information that helps with decision-making and innovation out of even the smallest pieces of data—and they’re right, over and over again.
This is why it’s vital to check if applicants have the skills you need to derive valuable input out of data. You’ll be basing a lot of business decisions on what these data scientists tell you, so best make sure they’re right.
But what makes someone a great data scientist? Some people turn their life around and go from being a maths teacher to following a 12-week data science boot camp or online data science course and quickly get the hang of it—others are top of their class, but aren’t confident enough data scientists to inform your business on its next big move.
The truth is that the skills a valuable data scientist has, will have to develop over the years. It’s not just the data literacy, hard skills and the brain for maths—they’ll also need to be able to present and communicate their findings the right way.
So, you’ll want to choose your data scientists carefully, but how do you do that? Resumes and portfolios might seem impressive, but how do you actually find out if someone has the skills you’re looking for—especially if you don’t have anyone on board yet that knows what to ask?
The easiest and most effective thing to do, is to screen candidates early in the process, using a data science test that’s been created by a real-life expert.
This will ensure that relevant questions are being asked, and you get a clear idea of who’s worth going through the hiring process with—and who isn’t.
In this article, we’ll walk you through four steps that will help you set up a data science job assessment that is of real value to your hiring managers. Let’s get started.

Source: https://www.pexels.com/
You could, of course, draw up an online survey and create a test in there to send out to all applicants, but these might be hard to ‘grade’—although you’ll develop a tremendous respect for teachers along the way.
In many cases, it’s better to choose a dedicated platform that has tests available, and will help you swift through the results effortlessly.
Before you start looking for platforms, make a list of absolute needs that you won’t compromise on. Ask yourself at least the following questions:
Once you’ve chosen a platform that is right for you, the fun can begin.
For roles like data scientists, you’ll be initially focusing on whether they possess the right hard skills. Depending on the specific role, you can test core data science topics such as:
You’re expecting your future data scientist to be fluent in statistics. Depending on the level you’re hiring at, you might want to throw in a few questions that quickly test how fast someone can see through the woods in a mess of statistics, and if they can interpret them the right way.
For some more senior roles, machine learning is becoming increasingly important in the world of data science. If this is the case for the role you’re hiring for, test to see if someone knows how to use data to feed it to machine learning and build awesome products.
A big part of data science is knowing how to work with neural networks. Neural networks are a way to solve problems through trial and error, based on human and animal brains. It’s incredibly helpful if your data scientist’s brain can use them.
Deep learning is a subfield of machine learning that can be necessary in specific data science roles. It works more closely to the way the human brain makes decisions, so this will require a specific set of test questions.
All that data has to come from somewhere, right? Your data scientists should not only be able to read and process data, but also know where and how to get the most valuable input. For this, include some questions about data extraction, data transformation, and data loading. This can also include tests on Excel and querying languages like SQL.
Databases should look nothing like the average teenage bedroom. Meaning that they should be nice and tidy, making it easier to extract valuable information from them. Since data isn’t just numbers, but can be anything from video to reviews, it’s crucial that you hire a data scientist who knows how to store this correctly.
Data wrangling, data exploration, analysis, and modeling need in-depth understanding of math and programming, but luckily, even data scientists get some help.
Data scientists use analytical tools like Apache Spark, D3.js Python, and many, many more to analyze all that data. If you’re using a specific one in your company and want your data scientists to be able to hit the ground running, quickly test if they’re actually able to use the tools they list on their resume.
At the end of the day, data scientists will have to be able to communicate their findings to other departments with people who are less data-savvy. For this, they often use tools that help them visualize data to explain it in a more easy-to-grasp way.
Test if your next data scientist is able to do that with a quick check on their skills in tools like Tableau, PowerBI, Plotly, Bokeh, or whichever one you use.
Your friendly neighborhood data scientist should not only be a math genius, they should possess the right soft skills too. If they’re impossible to work with, you won’t reap the benefits of their skill set. Productivity will suffer, and team morale might also take a hit. Here are some soft skills to test your candidates on:

Source: https://www.pexels.com/
If you want to make the most of your data science job assessment, it shouldn’t just be a test to see who goes through to the next round. For the candidates that ‘pass’, you can customize the questions in their follow-up interview based on the strengths and weaknesses they showed in their test.
Because the test they took says a lot, but at the same time—it’s just a snapshot. Did they score remarkably high on certain skills? Ask them how they got to be so experienced in that, and what projects contributed most to that.
Did you notice that they struggled with questions about X? Ask how they are planning to improve on that and how they make sure this doesn’t impact the quality of their work for the time being—are they calling in help from a peer, or do they simply take more time to figure things out?
These types of follow-up questions steer a job interview in a much more real-life direction: it’s not a generic set of questions that any company could ask any employee, but a real conversation between you and the candidate, in which you can evaluate if they fit in the future of the company—and if your company fits in theirs.
With these tips, we’re sure you’ll get some extra reassurance that your next hire will be a great fit—not just based on their previous experience and a couple of interviews. If you want, you can keep reading about data science jobs—or simply start hiring. Good luck!
In 2009, Google Chief Economist Hal Varian said to the McKinsey Quarterly that “the sexy job in the next 10 years will be statisticians.” At the time, it was hard to believe. But more than a decade later, we can’t get around the importance of data. Where once oil ruled the world, data is now catching up—quickly. That calls for more and better data scientists. In this article, we’ll explain to you how to find them.
The demand for data scientist roles has increased by 650 percent since 2012, and that number will continue to grow as the amount of data—and power it holds—grows steadily, too.
But unsurprisingly, there hasn’t been an increase of 650 percent in available data scientists on the job market. Even though the job is a lot sexier—and better paid—than ten years ago, many employers are still struggling to fill their empty seats with talented data scientists. McKinsey predicted that there would be a shortage of between 140,000 and 190,000 people with analytical skills in the U.S. alone in 2018, and even in 2022 good data scientists, data analysts, forecasting analysts, modelling analysts, machine learning scientists, are hard to find. Add to that another 1.5 million managers who will also need to at least understand how data analysis drives decision-making, and you can see how employers can be in a bit of a pickle.
Even though demand is growing much faster than the number of data scientists, companies can’t simply settle for the first data lover who’s available from Monday to Friday. It’s no longer the company with the most data that wins the game. The ones who are taking the lead are the ones that are able to get the most out of data. They can pull valuable information that helps with decision-making and innovation out of even the smallest pieces of data—and they’re right, over and over again. This is why it’s vital to check if applicants have the skills you need to derive valuable input out of data. You’ll be basing a lot of business decisions on what these data scientists tell you, so best make sure they’re right.
But what makes someone a great data scientist? Some people turn their life around and go from being a maths teacher to following a 12-week data science boot camp or online data science course and quickly get the hang of it—others are top of their class, but aren’t confident enough data scientists to inform your business on its next big move. The truth is that the skills a valuable data scientist has, will have to develop over the years. It’s not just the data literacy, hard skills and the brain for maths—they’ll also need to be able to present and communicate their findings the right way.
So, you’ll want to choose your data scientists carefully, but how do you do that? Resumes and portfolios might seem impressive, but how do you actually find out if someone has the skills you’re looking for—especially if you don’t have anyone on board yet that knows what to ask. The easiest and most effective thing to do, is to screen candidates early in the process, using a data science test that’s been created by a real-life expert. This will ensure that relevant questions are being asked, and you get a clear idea of who’s worth going through the hiring process with — and who isn’t. In this article, we’ll walk you through four steps that will help you set up a data science job assessment that is of real value to your hiring managers. Let’s get started.
You could, of course, draw up an online survey and create a test in there to send out to all applicants, but these might be hard to ‘grade’—although you’ll develop a tremendous respect for teachers along the way. In many cases, it’s better to choose a dedicated platform that has tests available, and will help you swift through the results effortlessly.
Before you start looking for platforms, make a list of absolute needs that you won’t compromise on. Ask yourself at least the following questions:
Once you’ve chosen a platform that is right for you, the fun can begin.
For roles like data scientists, you’ll be initially focusing on whether they possess the right hard skills. Depending on the specific role, you can test core data science topics such as:
You’re expecting your future data scientist to be fluent in statistics. Depending on the level you’re hiring at, you might want to throw in a few questions that quickly test how fast someone can see through the woods in a mess of statistics, and if they can interpret them the right way.
For some more senior roles, machine learning is becoming increasingly important in the world of data science. If this is the case for the role you’re hiring for, test to see if someone knows how to use data to feed it to machine learning and build awesome products.
A big part of data science is knowing how to work with neural networks. Neural networks are a way to solve problems through trial and error, based on human and animal brains. It’s incredibly helpful if your data scientist’s brain can use them.
Deep learning is a subfield of machine learning that can be necessary in specific data science roles. It works more closely to the way the human brain makes decisions, so this will require a specific set of test questions.
All that data has to come from somewhere, right? Your data scientists should not only be able to read and process data, but also know where and how to get the most valuable input. For this, include some questions about data extraction, data transformation, and data loading. This can also include tests on Excel and querying languages like SQL.
Databases should look nothing like the average teenage bedroom. Meaning that they should be nice and tidy, making it easier to extract valuable information from them. Since data isn’t just numbers, but can be anything from video to reviews, it’s crucial that you hire a data scientist who knows how to store this correctly.
Data wrangling, data exploration, analysis, and modeling need in-depth understanding of math and programming, but luckily, even data scientists get some help.
Data scientists use analytical tools like Apache Spark, D3.js Python, and many, many more to analyze all that data. If you’re using a specific one in your company and want your data scientists to be able to hit the ground running, quickly test if they’re actually able to use the tools they list on their resume.
At the end of the day, data scientists will have to be able to communicate their findings to other departments with people who are less data-savvy. For this, they often use tools that help them visualize data to explain it in a more easy-to-grasp way.
Test if your next data scientist is able to do that with a quick check on their skills in tools like Tableau, PowerBI, Plotly, Bokeh, or whichever one you use.
Your friendly neighborhood data scientist should not only be a math genius, they should possess the right soft skills too. If they’re impossible to work with, you won’t reap the benefits of their skill set. Productivity will suffer, and team morale might also take a hit. Here are some soft skills to test your candidates on:
If you want to make the most of your data science job assessment, it shouldn’t just be a test to see who goes through to the next round. For the candidates that ‘pass’, you can customize the questions in their follow-up interview based on the strengths and weaknesses they showed in their test. Because the test they took says a lot, but at the same time—it’s just a snapshot. Did they score remarkably high on certain skills? Ask them how they got to be so experienced in that, and what projects contributed most to that.
Did you notice that they struggled with questions about X? Ask how they are planning to improve on that and how they make sure this doesn’t impact the quality of their work for the time being—are they calling in help from a peer, or do they simply take more time to figure things out?
These types of follow-up questions steer a job interview in a much more real-life direction: it’s not a generic set of questions that any company could ask any employee, but a real conversation between you and the candidate, in which you can evaluate if they fit in the future of the company—and if your company fits in theirs.
With these tips, we’re sure you’ll get some extra reassurance that your next hire will be a great fit—not just based on their previous experience and a couple of interviews. If you want, you can keep reading about data science jobs—or simply start hiring. Good luck!

Today, data science is more than a buzzword. To simply put it, data science is an interdisciplinary field of gathering data from various sources and channels such as databases, analysing and transforming them into visualization and graphs. This basically facilitates the readability and understanding of the data to aid in soft-skills like insightful decision-making for any organization or business. In short, data science is a combination of incorporating scientific methods, different technologies, algorithms, and more when it comes to data.
Apart from the certified courses, as a data scientist, it is expected to have experience in various domains of computer science, including knowledge of a few programming languages such as Python and R as well as statistics and mathematics. An individual should be able to comprehend the data provided and be able to transform it into graphs which help in extracting insight for a particular business.
For those pursuing a career in data science, it is not just technical skills that matter, in business settings an individual is tasked with communicating complex ideas and making data-driven insightful decisions. As a result, people in the field of data science are expected to be effective communicators, leaders, and team members as well as high-level analytical thinkers too.
If we talk about applications of data science, it is used in myriad fields, including image and speech recognition, the gaming world, logistics and supply chain, healthcare, and risk detection, among others. It remains a limitless world indeed. Data scientists will continue to remain in high demand, while at the same time there is a substantial skill gap that needs to be currently addressed in the industry.
Here’s the lowdown on a few of the online resources—in no particular order—which can be checked out to learn data science. While a few of these educational platforms have been launched a couple of years ago, they would continue to hold equal relevance when it comes to resources for seeking in-depth knowledge related to everything in the field of data science.
![]() Udemy is a site that offers hands-on exercises while extending comprehensive data courses. At last count, there were about 10,000 data courses and almost 500 of which are free of cost. An individual can discover specialisations, including Python, Tableau, R, and many more. While offering real-world examples, Udemy courses are quite well-defined when it comes to specific topics.
Udemy is a site that offers hands-on exercises while extending comprehensive data courses. At last count, there were about 10,000 data courses and almost 500 of which are free of cost. An individual can discover specialisations, including Python, Tableau, R, and many more. While offering real-world examples, Udemy courses are quite well-defined when it comes to specific topics.
The courses are suitable for beginners as well as experts in the field of data science.
![]() Coursera is another online learning platform that offers massive open online courses (MOOC), specialisations, and degrees in a range of subjects, and this includes data science as well. Some of the courses hosted on the platform include top-notch names such as Harvard University, University of Toronto, Johns Hopkins University, University of Michigan, and MITx, among others. Coursera courses can be audited for free and certificates can be obtained by paying the mentioned amount. The courses from Coursera are part of a particular specialisation, which is a micro-credential offered by Coursera. These specialisations also include a capstone project.
Coursera is another online learning platform that offers massive open online courses (MOOC), specialisations, and degrees in a range of subjects, and this includes data science as well. Some of the courses hosted on the platform include top-notch names such as Harvard University, University of Toronto, Johns Hopkins University, University of Michigan, and MITx, among others. Coursera courses can be audited for free and certificates can be obtained by paying the mentioned amount. The courses from Coursera are part of a particular specialisation, which is a micro-credential offered by Coursera. These specialisations also include a capstone project.
![]() Pluralsight remains an educational platform for learners through insights from instructor-led courses or online courses, which lay stress on basics and some straightforward scenarios. Courses taken online will require you to exert more effort to gain detailed insights, thus helping you in the longer run. Pluralsight introduces one to several video training courses for Software developers and IT administrators.
Pluralsight remains an educational platform for learners through insights from instructor-led courses or online courses, which lay stress on basics and some straightforward scenarios. Courses taken online will require you to exert more effort to gain detailed insights, thus helping you in the longer run. Pluralsight introduces one to several video training courses for Software developers and IT administrators.
By using the service of Pluralsight, an individual can look forward to learning a lot of solutions. An individual can even get the key business objectives and even close the skill gaps in critical areas like cloud, design, security, and mobile data.
![]() The website, which is produced by Dr. Nathan Yau, Ph.D., offers insights from experts about how to present, analyse, and understand data. This comes with practical guides to illustrate the points with real-time examples. In addition, the site also offers book recommendations, as well as provides insights related to the field of data science.
The website, which is produced by Dr. Nathan Yau, Ph.D., offers insights from experts about how to present, analyse, and understand data. This comes with practical guides to illustrate the points with real-time examples. In addition, the site also offers book recommendations, as well as provides insights related to the field of data science.
There are also articles which an individual can browse related to gaining more in-depth insight into the correlation between data science and the world around.
![]() edX is an online platform, which has been created as a tie-up between Harvard University and the Massachusetts Institute of Technology. This website has been designed with the idea to highlight courses in a wide range of disciplines and deliver them to a larger audience across the world. edX extends courses that are offered by 140 top-notch universities at free or nominal charges to make learning easy. The website includes at least 3,000 courses and has programs available for learners to excel in the field of data science.
edX is an online platform, which has been created as a tie-up between Harvard University and the Massachusetts Institute of Technology. This website has been designed with the idea to highlight courses in a wide range of disciplines and deliver them to a larger audience across the world. edX extends courses that are offered by 140 top-notch universities at free or nominal charges to make learning easy. The website includes at least 3,000 courses and has programs available for learners to excel in the field of data science.
![]() Kaggle is an online learning platform that would be quite beneficial for individuals who already have some knowledge related to data science. In addition, most of the micro-courses require the users to have some prior knowledge in data science languages such as Python or R and machine learning. It remains an ideal site for upgrading skills and enhancing the capabilities in the field of data science. It offers extensive insights related to the field from experts.
Kaggle is an online learning platform that would be quite beneficial for individuals who already have some knowledge related to data science. In addition, most of the micro-courses require the users to have some prior knowledge in data science languages such as Python or R and machine learning. It remains an ideal site for upgrading skills and enhancing the capabilities in the field of data science. It offers extensive insights related to the field from experts.
![]() GitHub remains a renowned platform that uses Git, which is a DevOps tool used for source code management, to apply version control to a code. With over 40 million developers on its users list, it also opens up a lot of opportunities for data scientists to collaborate and manage projects together, besides gaining insights about the industry that continues to remain high in demand at the moment.
GitHub remains a renowned platform that uses Git, which is a DevOps tool used for source code management, to apply version control to a code. With over 40 million developers on its users list, it also opens up a lot of opportunities for data scientists to collaborate and manage projects together, besides gaining insights about the industry that continues to remain high in demand at the moment.
![]() This is a platform that comprises sub-forums, or subreddits, each focused on a subject matter of interest. Under this, the R/datascience subreddit has been titled the data science community, which remains one of the larger subreddit pages related to data science. Various data science professionals discuss relevant topics in data science. The data science subreddit remains insightful for individuals seeking a community that can provide related technical advice in the field of data science.
This is a platform that comprises sub-forums, or subreddits, each focused on a subject matter of interest. Under this, the R/datascience subreddit has been titled the data science community, which remains one of the larger subreddit pages related to data science. Various data science professionals discuss relevant topics in data science. The data science subreddit remains insightful for individuals seeking a community that can provide related technical advice in the field of data science.
![]() Udacity Data Science Nanodegree remains an ideal certification program for those who remain well-versed with languages such as Python, SQL, machine learning, and statistics. In terms of content, Udacity Data Science Nanodegree remains quite advanced and introduces hands-on practice in the form of real-world projects. While Udacity doesn’t offer an all-inclusive course, it introduces separate courses for becoming an expert in the field of data science. Professionals who aspire to become data scientists are advised to take Udacity’s three courses namely Intro to Data Analysis, Introduction to Inferential Statistics, and Data Scientist Nanodegree. These three courses extend real-world projects, which are provided by industry experts. In addition, technical mentor support, flexible learning program, and personal career coach and career services are also offered to aspirants in the domain.
Udacity Data Science Nanodegree remains an ideal certification program for those who remain well-versed with languages such as Python, SQL, machine learning, and statistics. In terms of content, Udacity Data Science Nanodegree remains quite advanced and introduces hands-on practice in the form of real-world projects. While Udacity doesn’t offer an all-inclusive course, it introduces separate courses for becoming an expert in the field of data science. Professionals who aspire to become data scientists are advised to take Udacity’s three courses namely Intro to Data Analysis, Introduction to Inferential Statistics, and Data Scientist Nanodegree. These three courses extend real-world projects, which are provided by industry experts. In addition, technical mentor support, flexible learning program, and personal career coach and career services are also offered to aspirants in the domain.
![]() KDnuggets remains a resourceful site on business analytics, big data, data mining, data science, and machine learning. The site is edited by Gregory Piatetsky-Shapiro, a co-founder of Knowledge Discovery and Data Mining Conferences. KDnuggets boasts of more than 4,00,000 unique visitors and has about 1,90,000 subscribers. The site also provides information related to tutorials, certificates, webinars, courses, education, and curated news, among others.
KDnuggets remains a resourceful site on business analytics, big data, data mining, data science, and machine learning. The site is edited by Gregory Piatetsky-Shapiro, a co-founder of Knowledge Discovery and Data Mining Conferences. KDnuggets boasts of more than 4,00,000 unique visitors and has about 1,90,000 subscribers. The site also provides information related to tutorials, certificates, webinars, courses, education, and curated news, among others.
Increasing technology and big data mean that organizations must leverage their data in order to deliver more powerful products and services to the world by analyzing that data and gaining insight, which is what the term “Data Science” means. You can jumpstart your career in Data Science by utilizing any of the resources listed above. Make sure you have the right resources and certifications. Now is the time to work in the data industry.
 https://unsplash.com/collections/28744506/work?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText
https://unsplash.com/collections/28744506/work?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText

