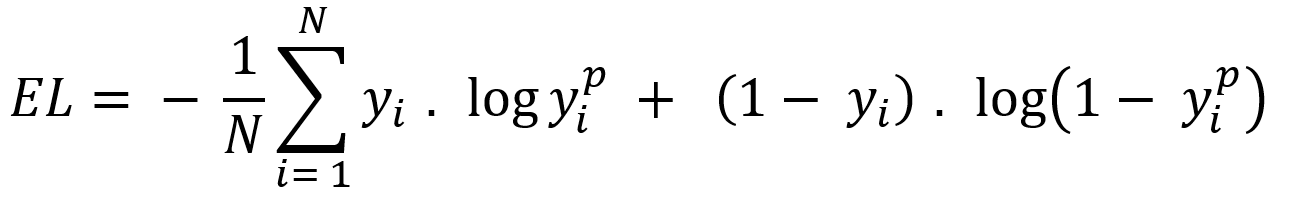1, Data is the new oil, but labeled data might be closer to it
Even though we have been in the 3rd AI boom and machine learning is showing concrete effectiveness at a commercial level, after the first two AI booms we are facing a problem: lack of labeled data or data themselves. The increasing number of papers on deep learning demonstrate that researches on AI have developed rapidly recently. If architectures of neural networks and supervised learning are all you know about deep learning, you will be overwhelmed by complications of topics studied these days, for example generative models, making more compact neural net models by for example knowledge distillation, and explainable AI (XAI). Those researches are often conducted on easily available benchmark datasets which you can easily download, often with corresponding ground truth data (label data) necessary for training. However once you try to apply the techniques to more specific data, you usually cannot prepare enough label data which theoretical researches assume. Thus among fascinating deep learning topics, in this article I am going to pick up how to tackle lack of label or data themselves, and transfer learning. Transfer learning is a technique of machine learning to take advantages of knowledge learned in one dataset to deal with a task in another dataset. Presumably due to this fact, Andrew Ng, in his presentation in NeurIPS 2016, gave a rough and abstract predictions of how transfer learning in machine learning would make commercial success like white lines in the figure below. The explanation is straightforward, and given the trends in topics of researches on machine learning these days, this prediction is actually right. But at the same time, in my opinion supervised learning, transfer learning, and unsupervised learning cannot be clearly separated like the graph originally suggested by Andrew Ng. Those fields complement each other, and one can easily shift to another.
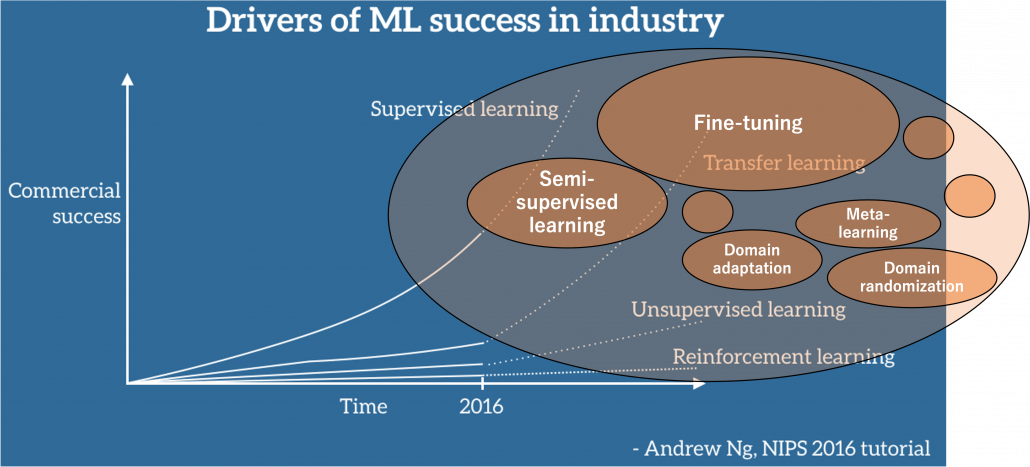
Source: https://ruder.io/transfer-learning/ The lines and texts in white are based on explanations by Andrew Ng. The orange cells are placed at random, so not that they represent commercial success of each field.
Along with the rapid progress of deep learning mentioned above, a lot of hypes and catchphrases regarding big data and machine learning were made, and an interesting one is “Data is the new oil.” That might have been said only because big data is sources of various industries. But I would say, the characteristic is more striking in training data for machine learning. Distributions of training data for machine learning are more complicated like various energy resources besides oil in the world. Labeled data might be also like uranium. Just as uranium-235 accounting for only less than one percent of uranium in the world can be used to generate energy, only a part of massive data in the world is labeled such that they can be used for supervised machine learning. And as uranium-235 is used effectively jointly with less active uranium-238, labeled data show greater potentials with unlabeled data. And training data for machine learning have another unpleasant analogy to energy resources. Like most mainstream energy resources, only limited companies or institutions would be able to mine and refine huge labeled datasets with gigantic computation resources, and most people more or less need to rely on that for their business. Even though alternative renewable energy resources are proposed, principal energy resources are indispensable for making industries stable. As well, even though a lot of techniques actually have been proposed to lack of data, it often turns out just fine-tuning pre-trained models is the most practical, which need huge datasets and rich computational resources. And I think recent success in for example BERT or GPT made this trend more visible.
*I am sorry in a case I am mistaken about energy resources. I just wanted to come up with some cool metaphors.
But I still think knowing about transfer learning more comprehensively would be effective. That is partly because I have been working on relatively unique data which are hard to even label. As I was studying computer vision (CV) in plant science field, I frequently saw relatively unique data obtained with special apparatuses. Such data are for the most part look far from very general dataset, which huge pre-trained models are trained on. At the same time such plant data have very complicated structures and hard to label. And also in my work, have to detect certain values in various formats in very specific documents, in German. Such data are far from general datasets, and even labeling is hard in that case. We have to carefully tackle lack of data every time on each type of data in that case.
In this article I would first like to explain in the first place what it is like to lack data and next introduce representative techniques to tackle lack of labeled data. Many of them are classified to transfer learning, but other techniques like unsupervised learning or self-supervised learning are used in them or share a lot in their ideas. Thus my main purpose of writing this article is to let you have a richer view on transfer learning. And you would see “transfer learning” these days are mainly about fine-tuning of pre-trained models. Also how to tackle lack of data or labels is in other words how to efficiently achieve good performance in machine learning. Thus even if tons of high quality labeled data are at your disposal, learning those ideas would be still effective to you. I hope you could find some hints of machine learning through my articles.
2, What does lack of data or labels mean in the first place?
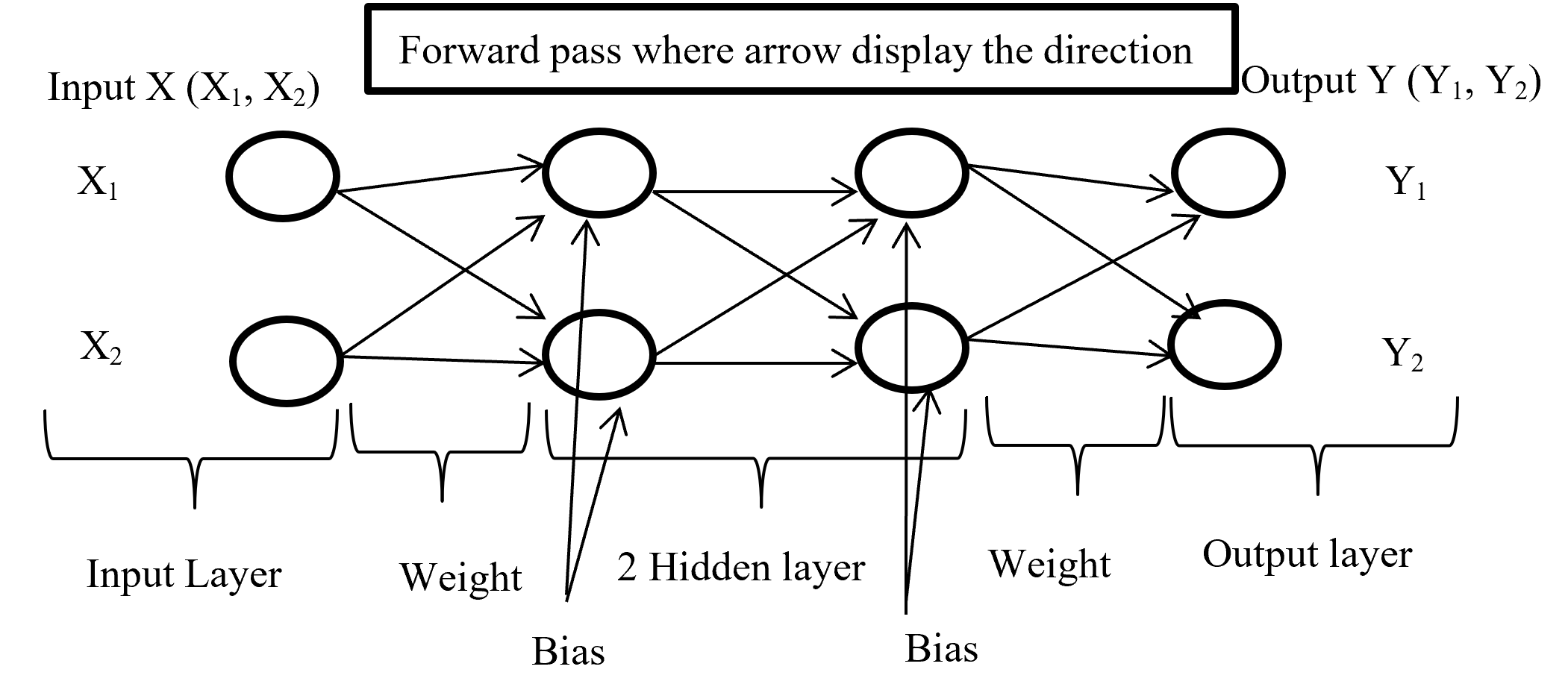
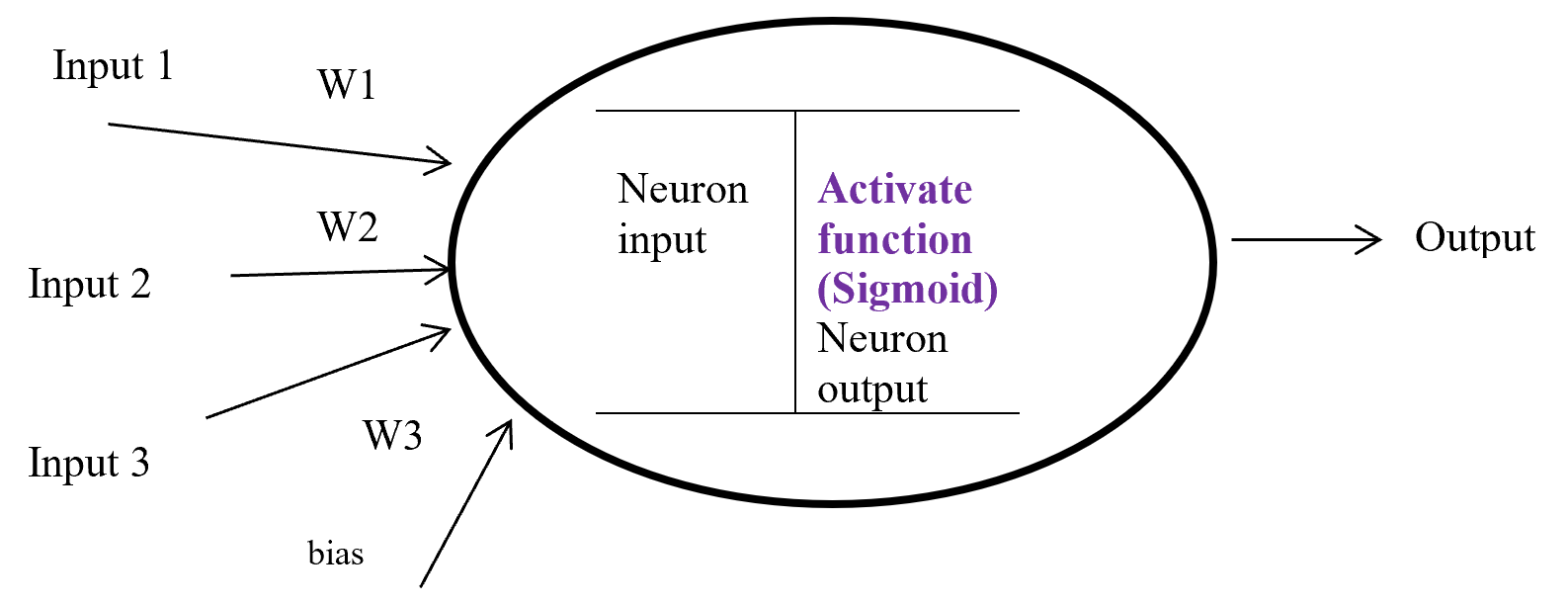
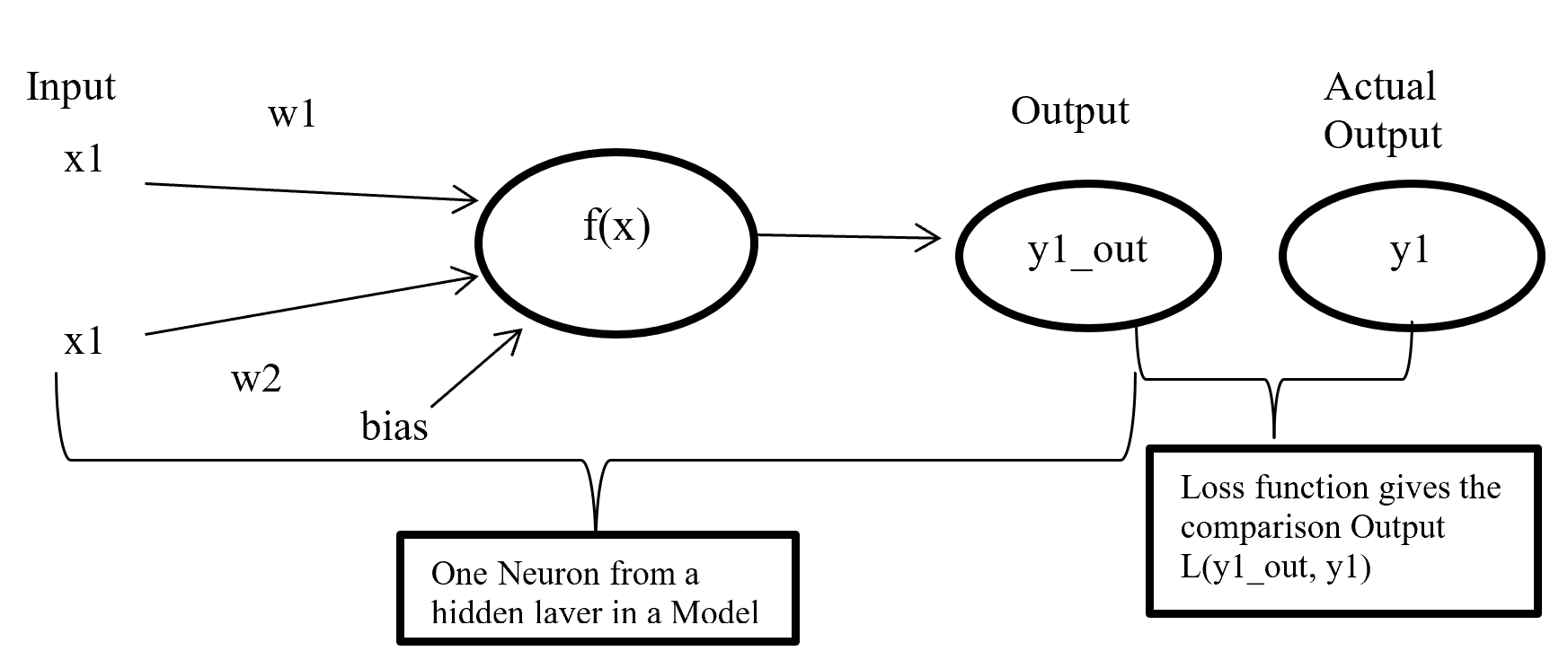
We need to first consider what lack of labels or data means, and my answer to the title of this section is “It depends.” The more data you have, the better performances you get. And the bigger machine learning models are, the more data they usually need for training. I assume that people reading this article more or less understand neural networks and how they are trained with back propagation. But let’s review the process here. Most machine learning frameworks are more or less expressed like the figure below unless reinforcement learning is considered. The ultimate purpose of machine learning is to train a model  by adjusting parameters
by adjusting parameters  . And the parameters are optimized so that a loss function
. And the parameters are optimized so that a loss function  is minimized. If it is a supervised learning, the a value of a loss function is denoted
is minimized. If it is a supervised learning, the a value of a loss function is denoted 
 , and it gets smaller as
, and it gets smaller as  gets closer to
gets closer to  . That is, is giving supervision to adjust
. That is, is giving supervision to adjust  via
via  . And in a case of unsupervised learning, a loss function is
. And in a case of unsupervised learning, a loss function is  , which is often heuristically handcrafted.
, which is often heuristically handcrafted.

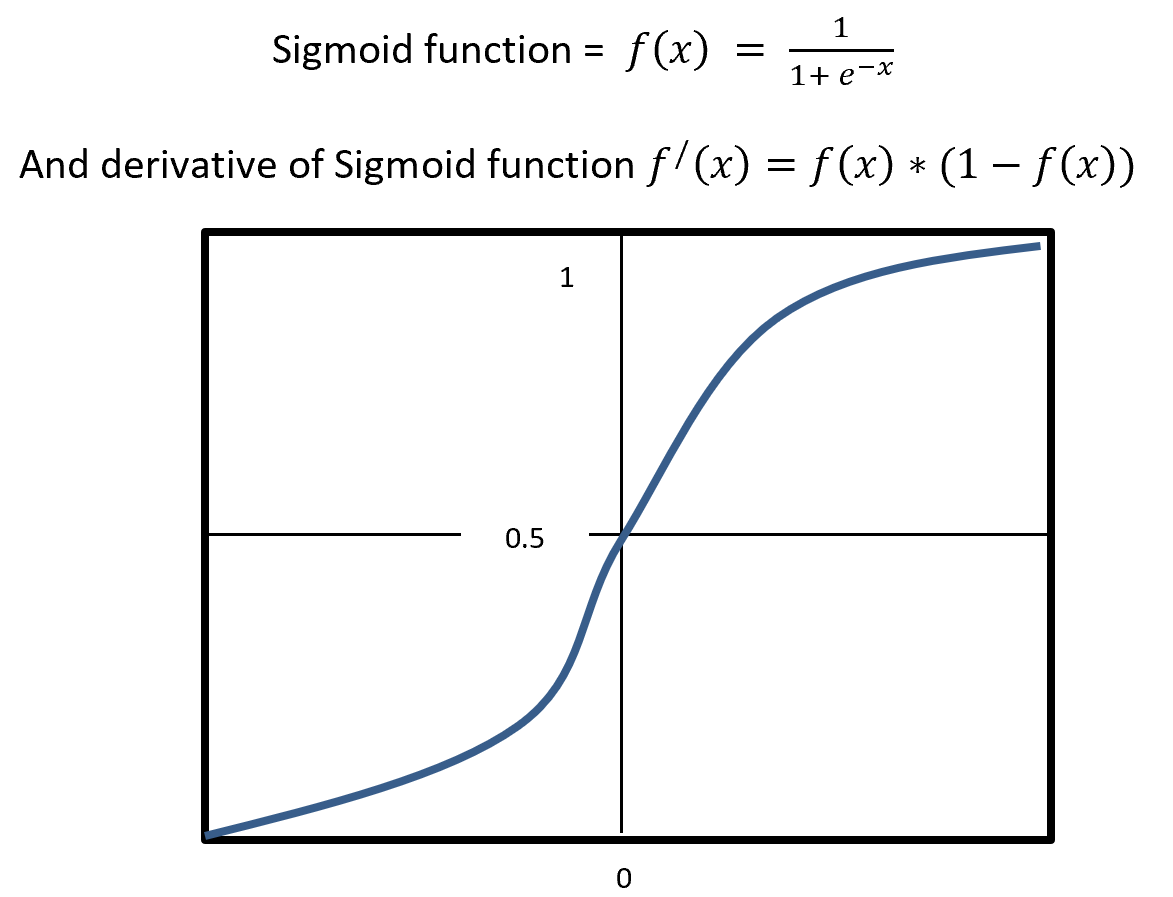
The very first problem from lacking training data you would learn is overfitting. That is, a machine learning model can be specialized too much for a training dataset, and it loses generalization to other data from the same dataset. It is like students with little imaginations and flexibility gradually memorizing all the answers in a textbook and failing to answer new questions they have not encountered yet. Overfitting is judged by relations of training and validation loss like in the graph below. Training loss in blue indicates how the students adjust to the textbook. The smaller the training loss is, the more they memorizes from the textbook and the less flexible they are. The orange line indicates their performance in newly appeared questions in tests. The smaller the validation loss is, the better the students perform on tests. Thus the students should stop learning with the textbook when the validation loss is about to increase. This is called early stopping in machine learning. And if you increase training data, the orange graph usually shifts to the right side, usually providing smaller validation loss, namely better performance. An important point is, this ideal relations of training and validation losses will not appear if sizes or expressivity of a model is not enough. Thus the more training data you use, the more parameters you need for the model to enhance its expressivity.
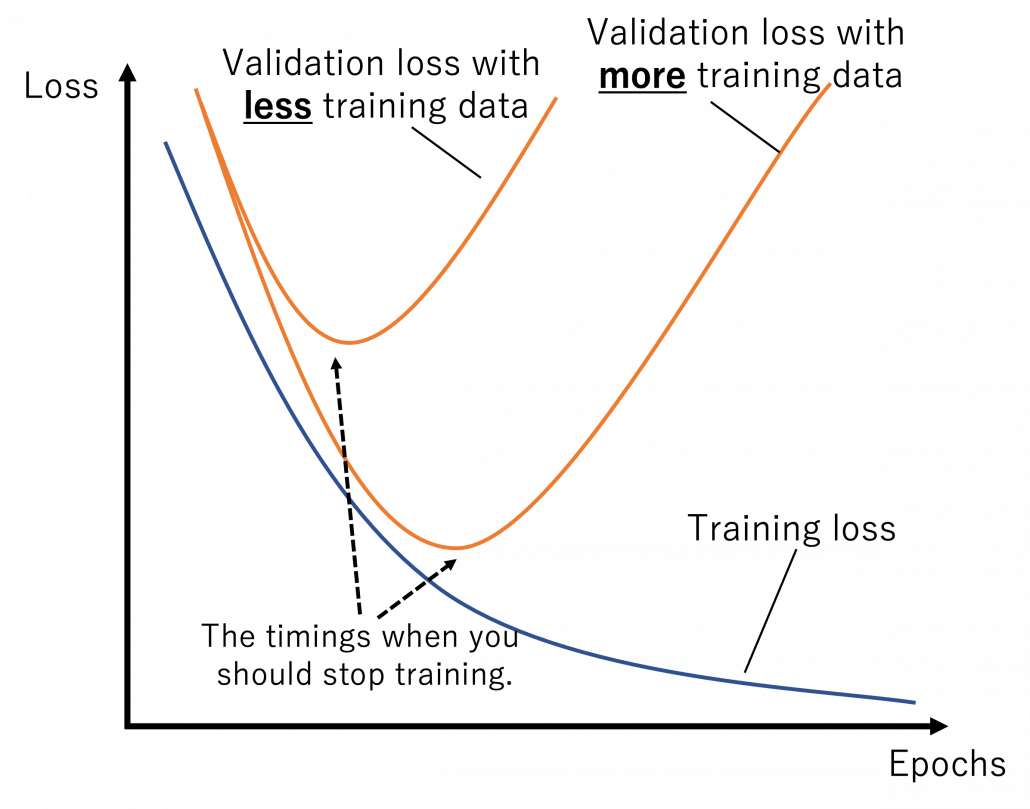
*Depending on sizes of training data, the curve of training loss also changes, so please bear it in mind that this graph is not correct and is very simplified.
What I said so far might sound too elementary. My point is, the more data you have, and the bigger computation resource you have, the better performance you get. In other words, machine learning has scalability with data and parameters. This characteristic is clearly observed in models in natural language processing (NLP) and computer vision (CV) like in the graphs below. When I read some papers,often I am very fascinated by their performances. But sometimes it turns out that the methods are mainly creatively in terms of how they increase training data, which is personally boring. And even if performance of GPT looks astonishing, I cannot really like them because of this simple fact.
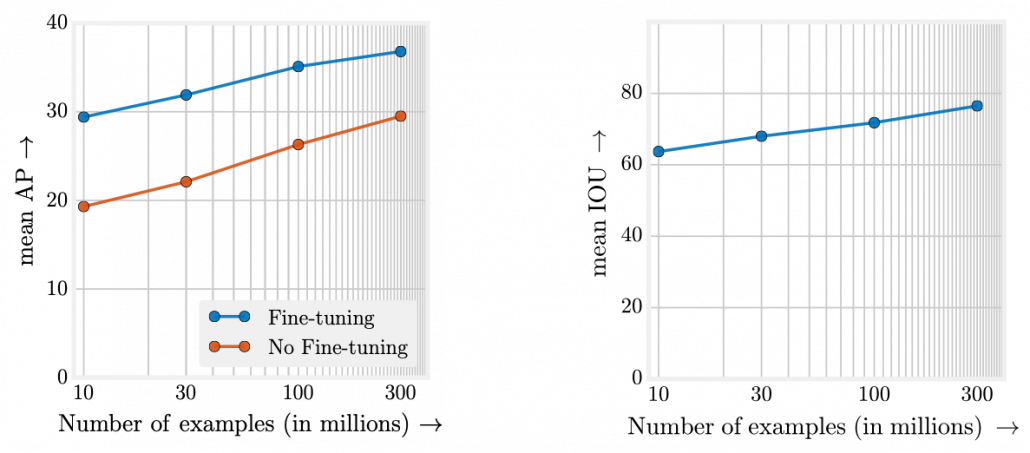
However another important point is, conversely you don’t need to increase training data or parameters of a model once it achieves an ideal score in metrics. When you make a toy model with small training data, as long as your clients or co-researchers are already happy, that is enough. Therefore lack of data or labels has to be discussed depending on sizes of machine learning and their performances you expect. Given those points mentioned so far, my answer to the question “What does lack of data or labels mean?” would rephrased like “If your model is properly designed to reach the performance you expect and it starts overfitting, you are facing lack of data.” And such decisions basically has to be made based on experiments.
3, Types of lack of data
Even though I explained lack of labels or data is a contextual matter, the problems actually exist at any case. That is, you often fail to achieve ideas accuracy partly due to lack of training data. I would like to classify types of situations of data of label shortage as below.

We should first think about the case where lack of labels does not matter in the first place. If you can analyze data with statistical knowledge or unsupervised machine learning, just extracting data without labeling would be enough. And sometimes ad hoc analysis with simple data visualization will help your decision makings. And some dashboards made from those unlabeled data will already give you some insights into data.
The next case is that, popular machine learning fields with enough investments usually have huge datasets that huge academic institutes or companies have been preparing. For example KITTI dataset, which include labels like trajectories and depth data, is by Karlsruhe Institute of Technology and Toyota Technological Institute. Such datasets are useful for self-driving-related researches, and many types of ground truth data are provided such as odometry, depth, opticla flow, detection. This kind of data might be considered “enough” only because they are enough for training machine learning models and quantitatively evaluating them in papers, regardless of practical usefulness at a commercial level. But at any rate, popular fields with large benchmark datasets are likely to get investments for commercial uses.

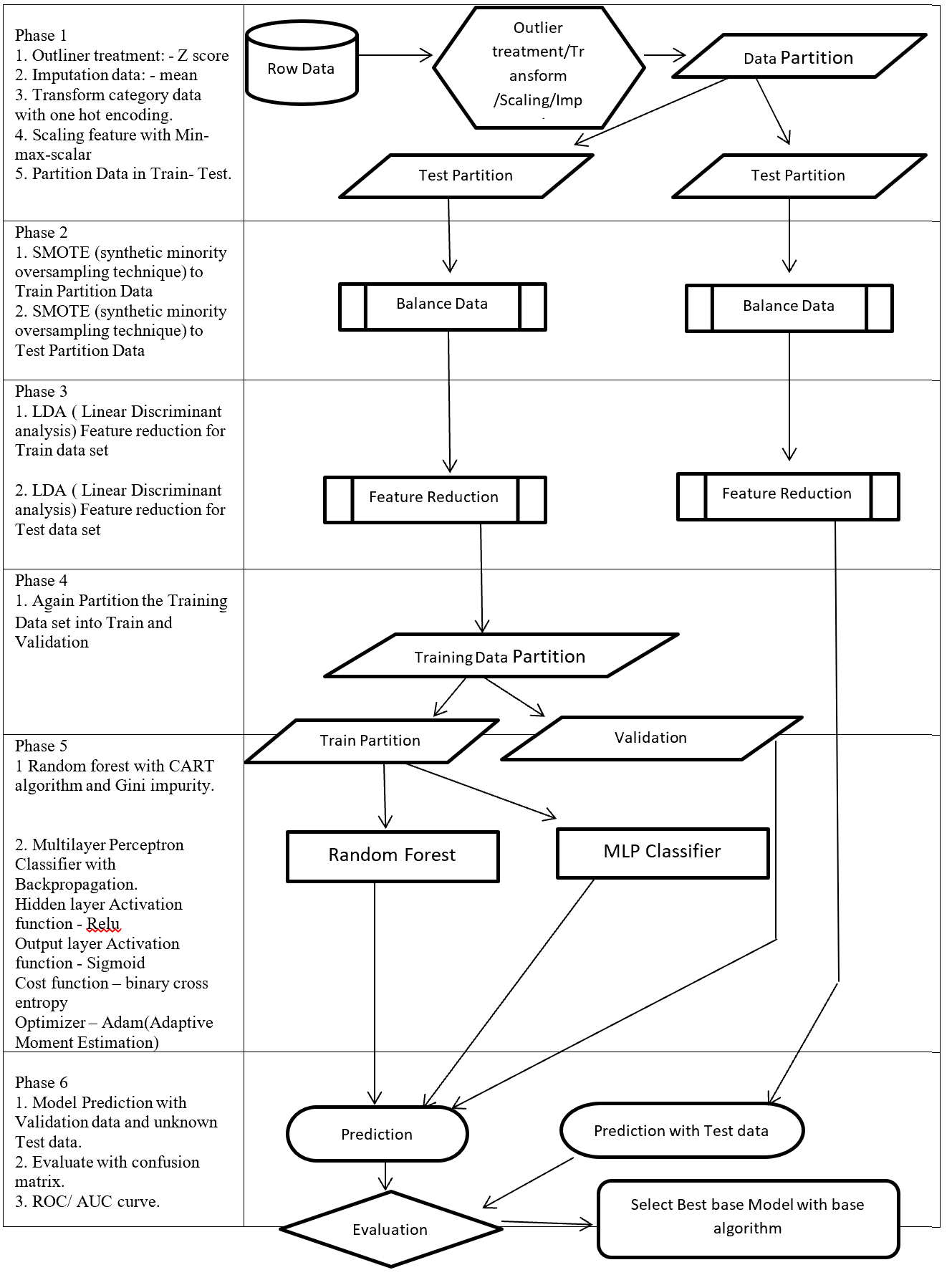
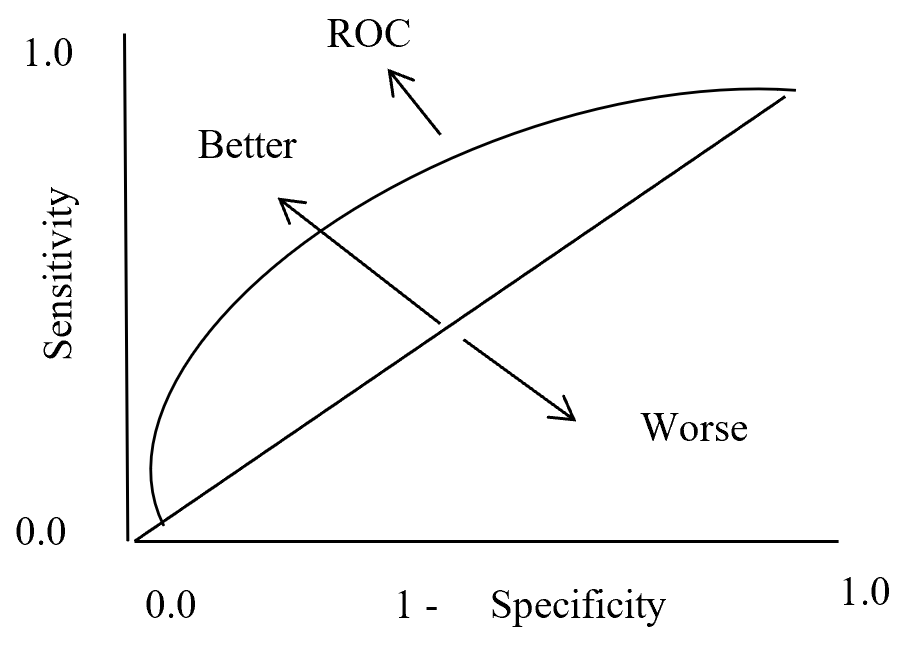
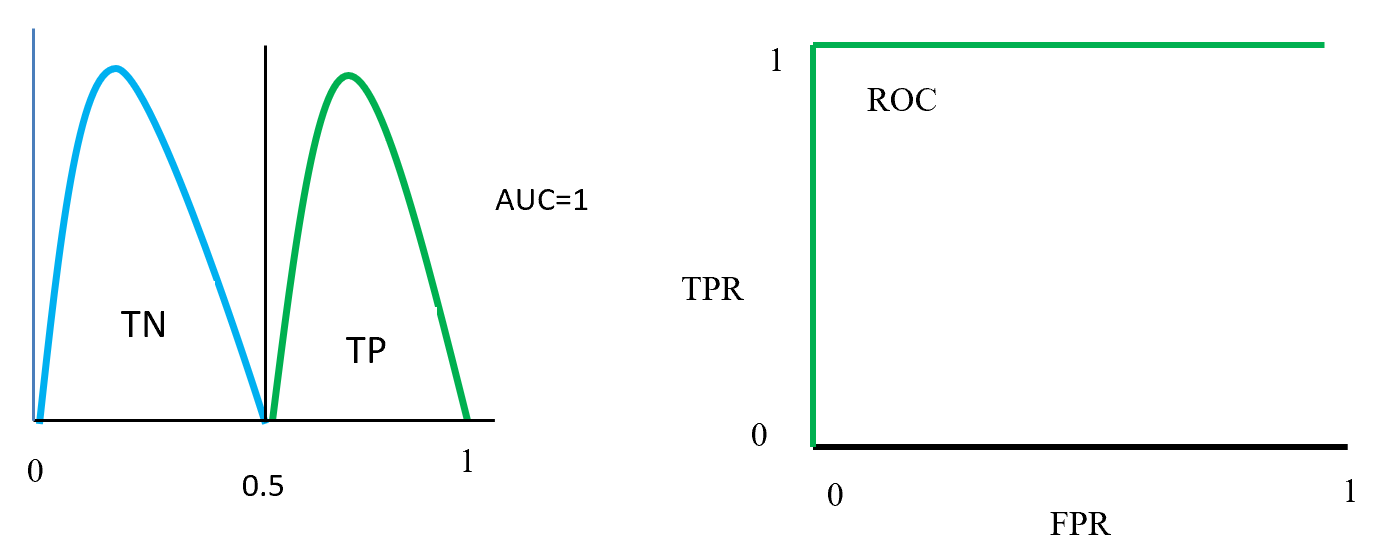
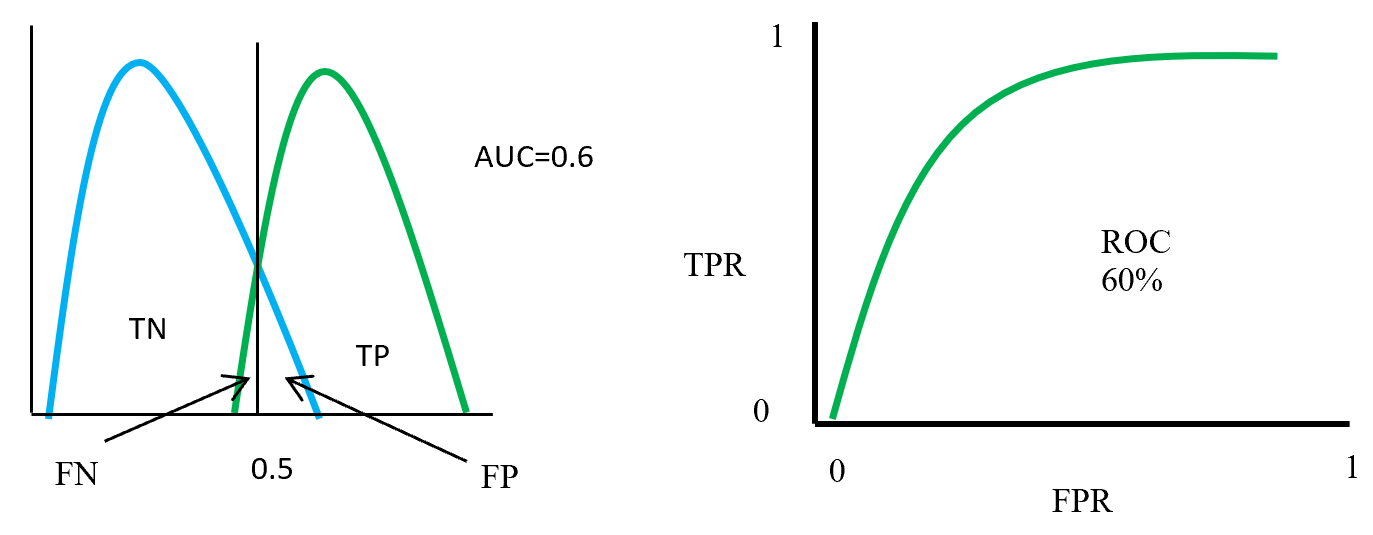
Next let’s see cases of data shortage. You should also keep it in mind that there are also several types of situations of data shortage. In fact there are cases where certain labels are supposed to be scarce such as classifications of imbalanced data, for example anomaly detection, judging spam mails, or medical examination. In those problems only some percent of data are classified as “errors,” “spam,” or “disease,” and others are classified as “normal.” Just keeping classifying data into “normal” would give maybe more than 95% accuracy. But finding the rest some percent accurately is much more important. In this case model performances need to be evaluated with ROC curves, namely relations of true positives and false positives.
The next type is more related to cases assumed in transfer learning. Some data are in the first place very expensive to obtain. For example CT images have to be stored by special medical apparatuses as you know. And even if a lot of CT images are already obtained, annotating the images often needs professional skills, thus its annotations cost is high. Another case of high annotation cost is for example detection or segmentation of objects in images. Even if you can collect numerous images on the Internet, annotating bounding boxes or pixel-wise segments require a lot of time. Annotating around 1000 images for classification might be ok, but annotating them at a pixel level is really time consuming. If you have a tablet, I would like you to paint each segment of objects in a picture with different colors. And you should multiply the time spent by 80,000, as many as the training images needed for Mask R-CNN, a popular model for instance segmentation. As you can imagine, it is a huge tediou work. Even preparing some 50 labeled images for fine-tuning is paiful, and even annotations for computer vision tasks itself is also a field of deep learning.
*I would say medical image processing is a relatively popular field in CV with deep learning, and there are several famous datasets on this field.
4, An overview on ways for dealing with lack of labeled data
I am going to first roughly introduce what kind of approaches can be taken to deal with lack of labeled data or data itself, but you should also keep it in mind that they are not clearly separated. Just as I am going to explain, one type of techniques can easily shift to another type. You should flexibly switch among them depending on your situations. And also please keep it in mind that these are well-studied areas, and tons of ingenious papers are announced one after another, usually giving slight changes in their performances. Problems I point out about each technique might not be a problem anymore with recently published researches on researches currently peer-read. It is hard to prove that something does not exist. Given those points, I think it is convenient to classify technique of dealing with label or data shortage as below.

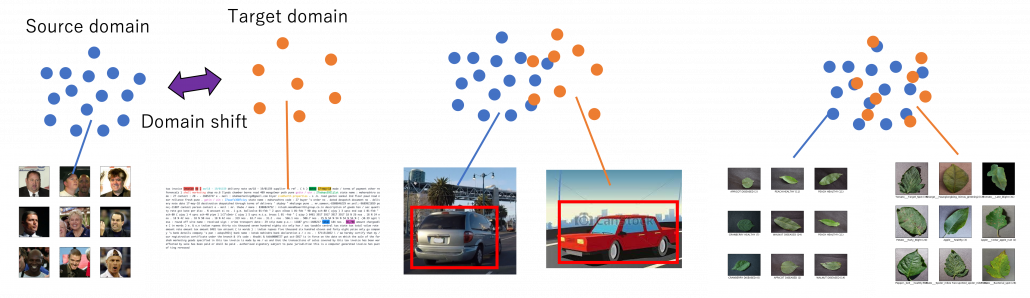
Through this article, ideas of domains are important. A domain simply means a combination of a dataset and a task with it. Transfer learning is a family of machine learning techniques to make uses of knowledge learned in a domain to another domain, and the former is called a source domain, the latter a target domain. And discrepancies between a source domain and a target domain is called a domain shift. The figure below abstractly visualize examples of domains and domain shifts. Intuitively it is easy to imagine that face a CV task and an NLP task have bigger domain shifts than domains of leaf images taken from different angles, but quantitatively evaluating domain shifts is in practice hard, and I am not going to introduce the topic because that will need a lot of mathematics.
Instead of formulating transfer learning, I would like to take learning languages as an intuitive example of transfer learning. Most people master at least one native language before learning another one. Baby brains are a kind of fantastic machine learning models, and after overcoming many obstacles they master native languages. And people take advantages of their mother tongues to learn another language. Usually they learn foreign languages by comparing structures of translated sentences. And naturally, if both a foreign language and your language have analogies like grammatical cases or genders in common, language learning would be easy. In other words, proficiency in one language is helpful in leaning some language. But it is also possible that your native language badly affects learning the second language, due to grammatical structures, pronunciations. The case of a source domain deteriorating performances in a target domain is called negative transfer and contexts of transfer learning.
*I know similarities languages are not the sole and definite barometers of effectiveness in learning foreign languages. Sizes of economy or markets in a country would also affects English language acquisition of people there. But at least it is unfair to compare for example German or Dutch people learning English with Japanese, Chinese people learning it. Unlike Eastern Asian people who have to learn thousands of characters to at least read decent texts or who use very different grammars, European people obviously can use “transfer learning” to learn English.
5, Increasing training data
When you lack data or labels, the most straightforward and often quick solution is to just increase data. The two topics I will cover in this section are mainly conducted in one domain.
Data augmentation
Data augmentation is one of the first techniques you would learn to mitigate overfitting of machine learning, which is in short caused by lack of data. The idea is very simple and it is implemented well in deep learning libraries, so I would only briefly talk about it here. The idea of data augmentation is simply transforming input data by for example flipping, rotating, zooming, changing colors. By doing so for example an input image  of a butterfly below with a label of
of a butterfly below with a label of  can be converted to more than 6 images. This corresponds to getting a converted
can be converted to more than 6 images. This corresponds to getting a converted  in the machine learning outline in the last section. And this process is the same as increasing the size of a dataet
in the machine learning outline in the last section. And this process is the same as increasing the size of a dataet  . And one point you have to be careful is, you must not change too much to change corresponding . For example if is distorted too much, it cannot be recognized as anymore even by humans. Or if you rotate an image of a digit 6 180 degrees, its becomes 9. Recent researches focus on automatically find what kind of data augmentation is effective by using for example reinforcement learning.
. And one point you have to be careful is, you must not change too much to change corresponding . For example if is distorted too much, it cannot be recognized as anymore even by humans. Or if you rotate an image of a digit 6 180 degrees, its becomes 9. Recent researches focus on automatically find what kind of data augmentation is effective by using for example reinforcement learning.
 Here let me take an example of data augmentation technique that would be contrary to your intuition. A technique named mixup literally mix up data with different classes and their labels. In classification problems, labels are expressed as one-hot vectors, that is only an element corresponding to a correct element is
Here let me take an example of data augmentation technique that would be contrary to your intuition. A technique named mixup literally mix up data with different classes and their labels. In classification problems, labels are expressed as one-hot vectors, that is only an element corresponding to a correct element is  and the others are
and the others are  . In a case of binary dog-or-cat classification, each label is
. In a case of binary dog-or-cat classification, each label is  or
or  , respectively. In data augmentation, distorting data too much is a taboo because label data is contaminated, but in mixup you literally mix up labels. Randomly choosing a two inputs
, respectively. In data augmentation, distorting data too much is a taboo because label data is contaminated, but in mixup you literally mix up labels. Randomly choosing a two inputs  and a number
and a number ![\lambda \in [0,1]](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-ca07e0e397d614f2de6877183c93fa3a_l3.png "Rendered by QuickLaTeX.com") , you prepare a input and label pair
, you prepare a input and label pair  . The figure below is an example of a mixing up a cat input and a dog input, and corresponding labels. It is known augmenting training data like this improves classification performances. It is said this is partly due to machine learning models effectively learning decision boundaries. In classification ambiguous inputs are bottlenecks, so learning to giving ambiguous outputs to ambiguous inputs can enhance classification abilities.
. The figure below is an example of a mixing up a cat input and a dog input, and corresponding labels. It is known augmenting training data like this improves classification performances. It is said this is partly due to machine learning models effectively learning decision boundaries. In classification ambiguous inputs are bottlenecks, so learning to giving ambiguous outputs to ambiguous inputs can enhance classification abilities.
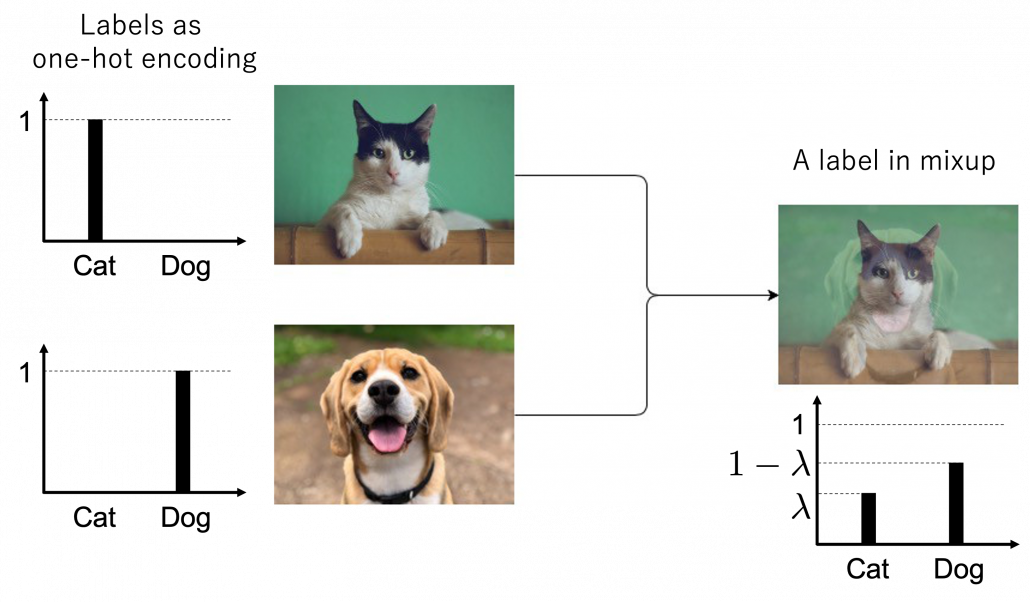
*One-hot-encoded labels are called hard labels, and otherwise soft labels. Recent topics in deep learning, such as lottery hypothesis, knowledge distillation, imply that whether supervising labels are hard or not is important in deep learning. Hopefully I would like to explain why little by little in my articles.
6, Active learning
Active learning is about how to annotate data and get labeled data efficiently. Labels of data do not equally contribute to enhancing machine learning models, and labels actually have qualities. Even if you give apparently similar images with the same label to machine learning models during training, the models cannot learn so much from the pair of data. You need to efficiently dig data to know its distribution by giving labels to samples. I think a good metaphor is geological survey by excavating with some boring. In order to know substances or features of ground, some earth need to be sampled with boring. But you cannot freely penetrate everywhere mainly due to costs. They need to be sampled one by one due to uncertainty about the ground.
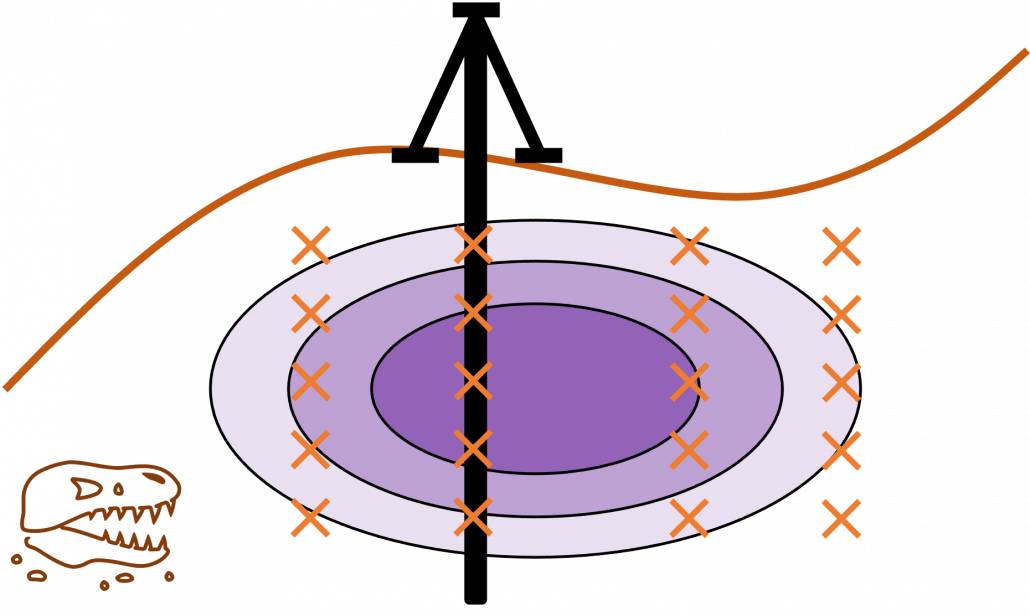
Similar approaches are often taken in machine learning or statistics, that is estimating distributions of data with a small size of samples is an important idea. A basic idea for doing that is you sample or annotate data which decreases uncertainty of your model the most. The figure simply exhibits the idea. We want to regress a data distribution with the red curve, and the cross marks can be sampled from the distribution. And the part filled with light blue shows uncertainty of the model to predict a value of  for a
for a  . When you want to regress the data with as few samples as possible, data points should be sampled from the parts with great uncertainties. And by doing so, you can see that the data is regressed efficiently with few samples.
. When you want to regress the data with as few samples as possible, data points should be sampled from the parts with great uncertainties. And by doing so, you can see that the data is regressed efficiently with few samples.
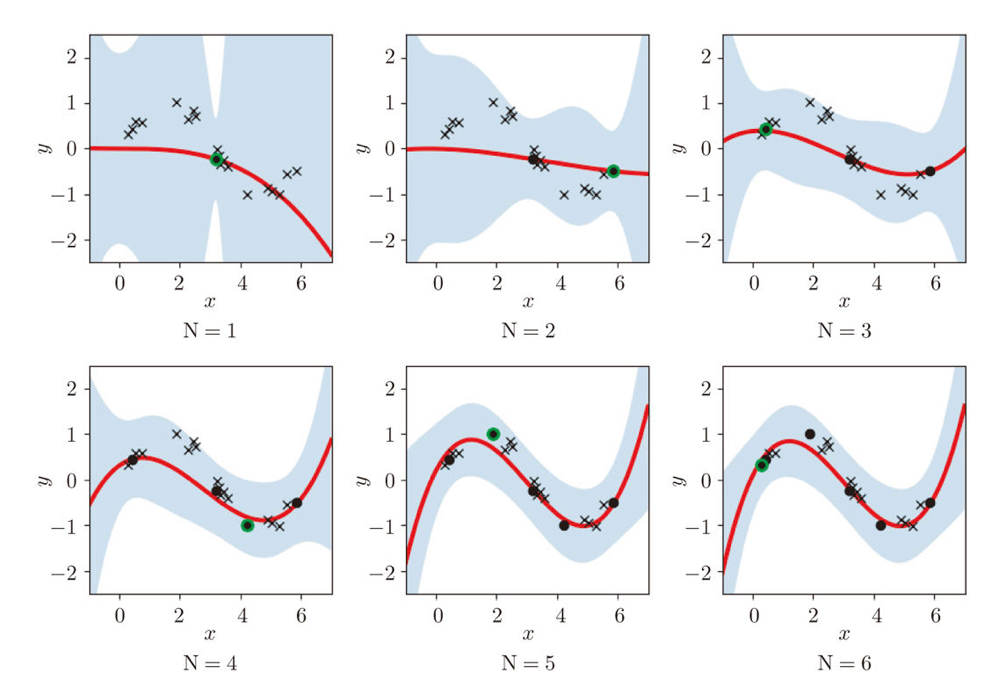
We have seen that modeling uncertainty is the key to active learning, and that can be applied to annotations of data in deep learning. An example of the process is displayed below, and in this case a deep neural network model (DNN model) is trained with some labeled data, and you give some signals for data annotations based on uncertainty of outputs of DNN models. And human annotators prioritize giving labels to the data. Such uncertainly can be estimated by using entropy of outputs or modeling data distributions.
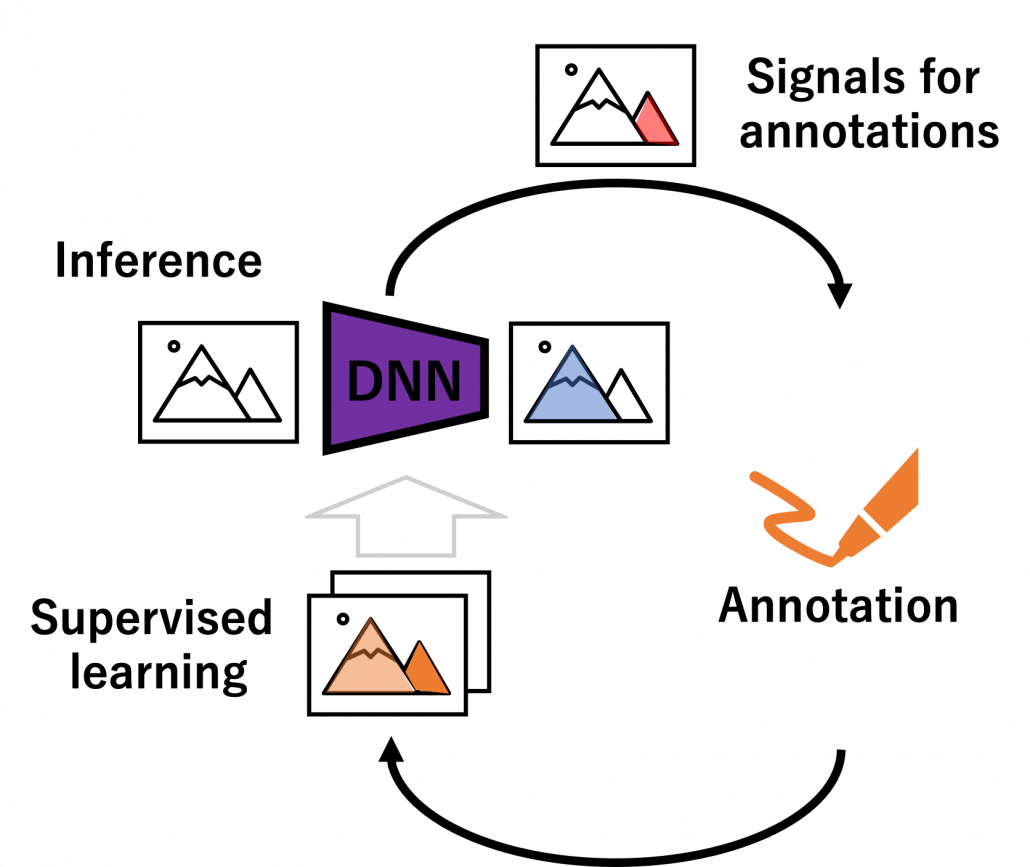
But when you get a certain amount of labels, the situation will be the same as semi-supervised learning, which I will explain next. That is, you might be already able to make the most of the labels so far with the help of unlabeled data. You should consider stopping labeling and start labeling depending on situations. And importantly, starting naively annotating data might become a quick solution rather than thinking about how to make uses of limited labels if extracting data itself is easy and does not cost so much. “Shut up and annotate!” could be often the best practice in practice. And annotations would be an effective way for exploratory data analysis (EDA), so I recommend you to immediately start annotating about 10 random samples at any rate.
7, Dealing with lack of labels in a single domain
In many cases, data themselves are easily available, and only annotations costs matter. The following two topics consider such cases, and again only one domain is considered. But by the end of this article you would see that other techniques covered in this article have a lot of analogies with topics introduced here.
Semi-supervised learning
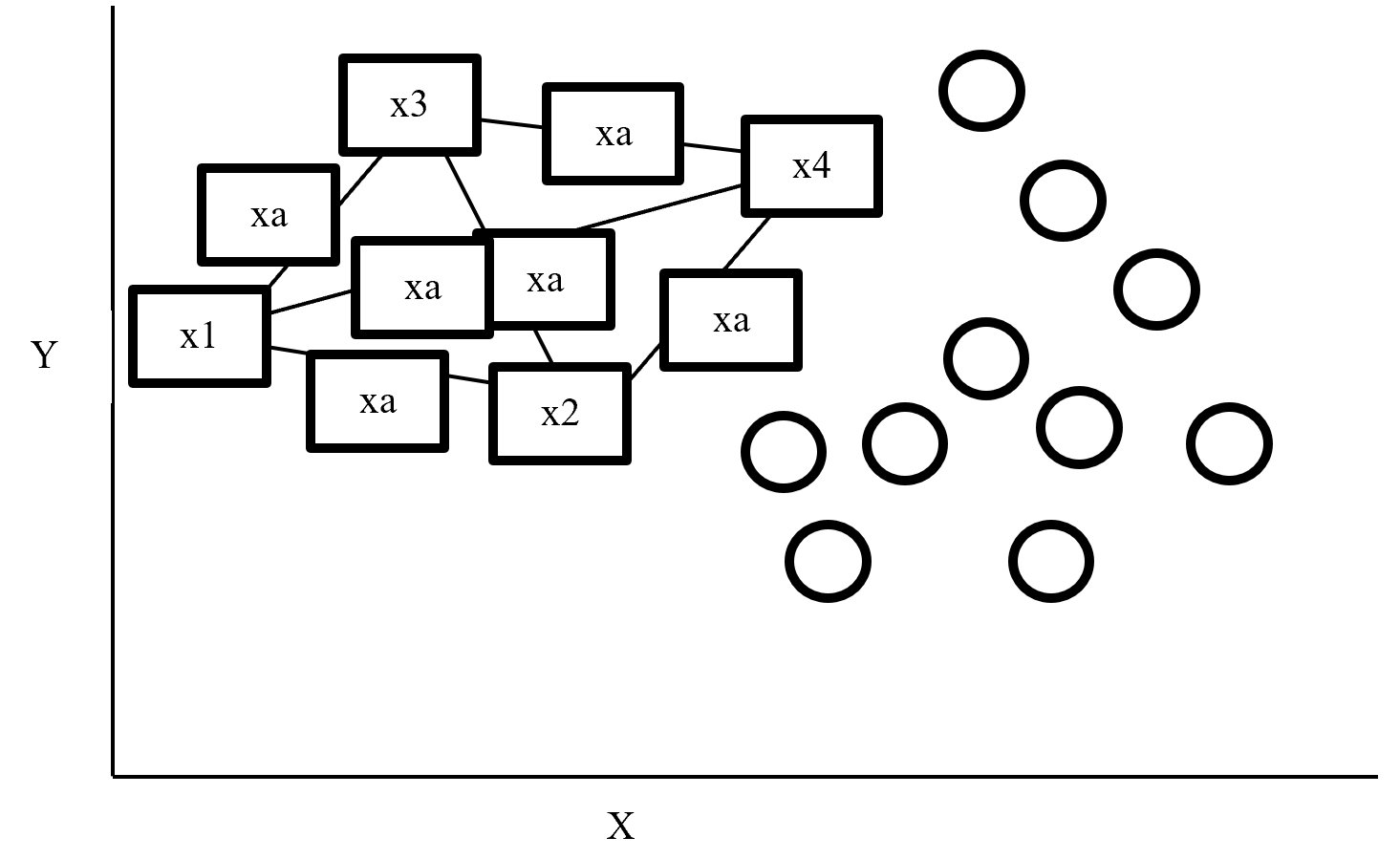
Semi-supervised learning is a type of supervised learning where only limited labels are available in one domain. This is important in because many of other techniques in this article can be seen as semi-supervised learning from certain points of views. The figure below shows an intuition on semi-supervised learning in a case of classification task. In this case, original data distribution have two clusters of circles and triangles and a clear border can be drawn between them. But only with limited labeled data, decision boundaries would be ambiguous. However in fact, with a help of unlabeled data in dotted lines, machine learning model might be able to recognize two clusters with a help of unlabeled data. In other words, unlabeled data help models learn distribution of data. this might be natural as clusters of data can be estimated with unsupervised learning.
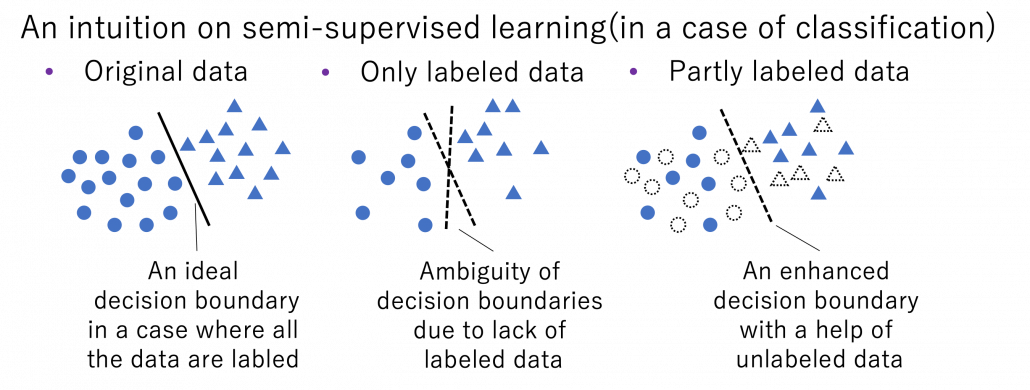
*As I have already mentioned, active learning could soon shift to semi-supervised learning, and it might be worth trying it before finishing labeling. But suspending labeling and resuming it later might not be efficient. At any rate you need to be flexible depending on situations.
Semi-supervised learning is applicable to several tasks, not only classification. I explained that normal supervised learning is adjusting parameters of a model so that it minimize loss function  for a labeled dataset
for a labeled dataset  . In semi-supervised learning, we assume that usually a bigger unsupervised dataset
. In semi-supervised learning, we assume that usually a bigger unsupervised dataset  is available in the same domain. And semi-supervised learning optimize by jointly minimizing
is available in the same domain. And semi-supervised learning optimize by jointly minimizing  after designing a loss function
after designing a loss function  for the unlabeled dataset. There are following 3 major ways of semi-supervised learning depending on how you design a .
for the unlabeled dataset. There are following 3 major ways of semi-supervised learning depending on how you design a .
- Consistency regularization: adding slight changes to data
 in and get
in and get  . And training so that
. And training so that  and
and  give out a consistent output.
give out a consistent output.
- Pseudo label: after training with , using some estimations as labels of .
- Entropy minimization: encouraging outputs to have smaller entropy.
More or less similar ideas show up in different transfer learning techniques, so it would be effective to learn the three semi-supervised learning ideas above.
Self-supervised learning
Self-supervised learning is often counted as unsupervised learning. Both unsupervised and self-supervised learning do not need label data, but especially when labels generated by processing themselves, that is often called self-supervised learning. A representative case of using self-supervised learning is auto-encoder. Simpler labels can be generated from input data themselves with elementary data processing. For example in a case of image processing, by rotating an input image 0, 90, 180, 270 degrees respectively, a classification task of estimating rotation degrees can be made. Another case is estimating the original input image after some simple image processing (for example colorization). These simple tasks generated solely from an input is called pretext task. And in a case of image processing, deep learning models can be prompted to learn image features .

Source: https://atcold.github.io/pytorch-Deep-Learning/en/week10/10-1/
Pretext tasks are applicable also to other fields for example NLP. A very simple task is hiding a part of an input sentence, and let neural networks estimate the blank word. And this is a basic idea of how to train BERTs, famous pre-trained NLP models. BERT models are trained this way with a huge and very general corpus without any specific topics. By doing so BERT model can already learn to detect some clusters of meanings in texts, as I visualize in the next section. But if you fine-tune BERT models with labeled texts with very specific topics, that often fails to achieve satisfying performance. In that case, the BERT models have to “get used to” the new dataset. In that case, BERT can “get used to” the new dataset by applying self-supervised learning on the new dataset. This tutorial of Huggingface demonstrates this with an example of adjusting a BERT model trained with Wikipedia to the IMDb dataset.
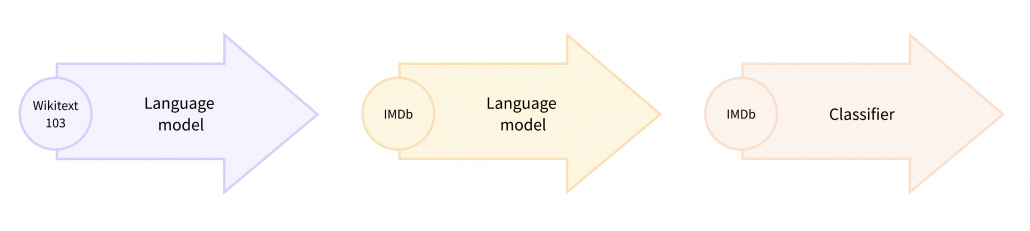
In the case above, the BERT model is fine-tuned with relatively lots of unlabeled data and after that trained with fewer labels. As a whole this can be seen as semi-supervised learning ,with fewer labels of the IMBb dataset and more unlabeled data. Also the ideas of pretext tasks, which prompt models to give consistent outputs given preprocessed inputs, have some analogies with consistency regularization in semi-supervised learning.
*The Huggingface tutorial says, they fine-tune a pre-trained BERT model trained in a self-supervised way to adjus it, and they call it “domain adaptation.” As you can see from the statement, distinctions of topics covered in this article can be just ambiguous.
8, Dealing with lack of data or labels over several domains
Another approach for tackling label or data shortage is taking advantages of other domains, which are usually larger and have enough labels. And such techniques is called transfer learning as I mentioned. It seems like transfer learning in business refers to “fine-tuning” explained below, but in academic contexts it is often also said transfer learning is almost synonym to “domain adaptation.” At any rate, my point is it would be more important to have comprehensive view on the techniques rather than clearly distinguishing them.
Fine tuning
Fine tuning would be the easiest way of transfer learning, and at the same time it is very powerful. Even though I am going to introduce other technique of transfer learning, more often than not it turns out that fine tuning can compensate them. Here I will only explain what it is like to use fine-tuning. I would say using fine-tuning is easy like using instant coffee. Conventionally you needed to train your original model with your own data, and that is very affected by sizes of data you have. I would say, that was like making coffee or coffee cakes from coffee you made from beans. But by using pre-trained models already trained somewhere with huge datasets, you can use models which can already more or less recognize data. The idea was very normal already in the field of CV, and NLP got the same idea with the advent of BERT, or already with word embeddings. That is like people learned to use instant coffee instead of roasting and brewing coffee every time.
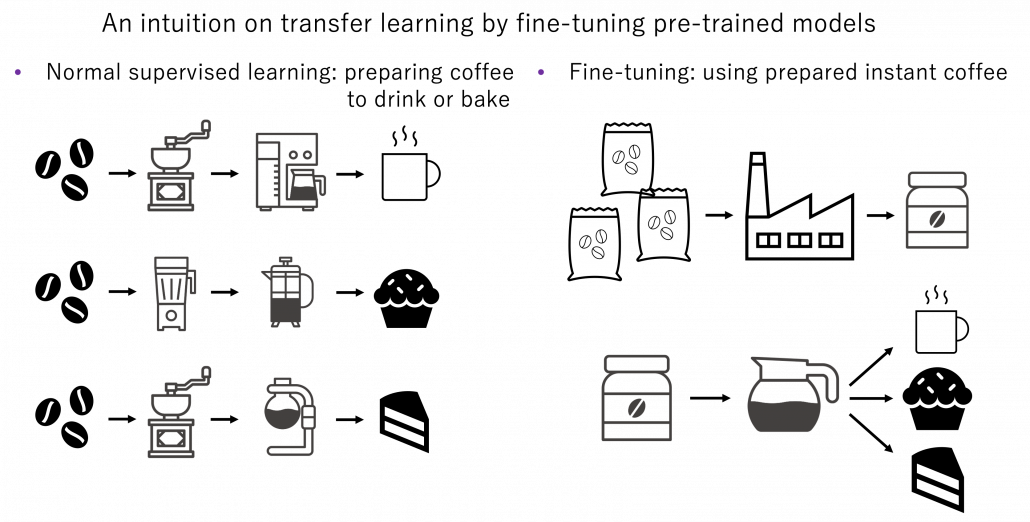
How such instant coffee is made depends on which type of deep learning is used on a huge dataset. Backbone CNN is usually trained on ImageNet dataset with supervised learning of a classification task. In case of BERT, it is trained with a huge corpus with a pretext task of estimating blank words of input sentences, which is classified to self-supervised learning. Let me more practically what the “coffee syrup” means. Machine learning is at any rate just mapping of tensors or vectors. In CV, an input images as a tensor is converted into a a vector or a tensor, and tasks like image classification are conducted with the converted tensor or vector. In case of an NLP task, usually a sequence of vectors is converted to a vector or another sequence of vectors. And these resulting tensors of vectors from models are the very “coffee syrup” I am talking about. An important point is, fine-tuning also considers transfer learning between different tasks. Backbone CNNs are usually trained with classification, BERT with self-supervised learning, but the there are a variety of final tasks. They are called downstream tasks. In other words, you don’t necessarily drink instant coffee as coffee.
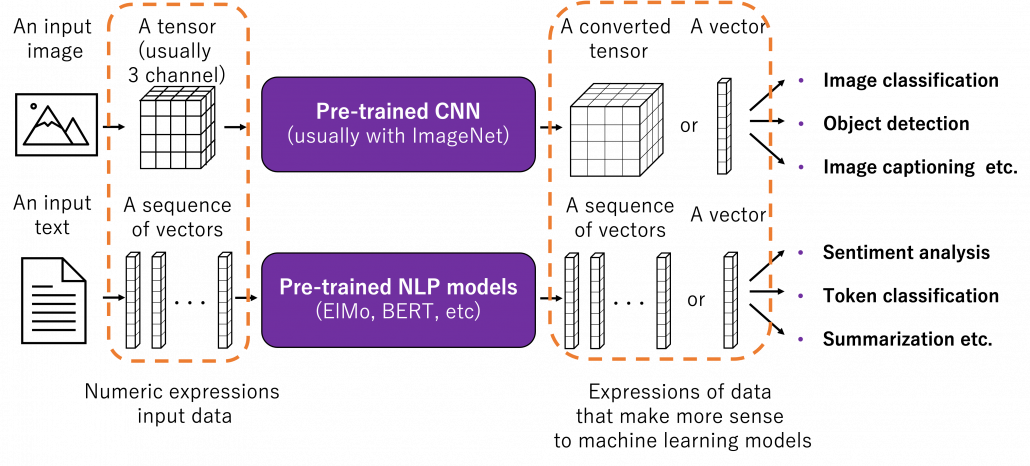
The two figures below are visualizations what the “instant coffee syrup” means. I processed random  images in a dataset with a pre-trained backbone CNN, and I got corresponding
images in a dataset with a pre-trained backbone CNN, and I got corresponding  dimensional vectors, that is a
dimensional vectors, that is a  tensor. And I applied t-SNE to reduce its dimension from to
tensor. And I applied t-SNE to reduce its dimension from to  and got a
and got a  tensor. The figure below shows arrangements of input images in the 2 dimensional space. As you can see, semantically similar images get closer.
tensor. The figure below shows arrangements of input images in the 2 dimensional space. As you can see, semantically similar images get closer.

Just as well, if you process random texts with BERT and apply a dimension reduction, you get a visualization like below. As well as the figure above, texts in similar topic get closer.
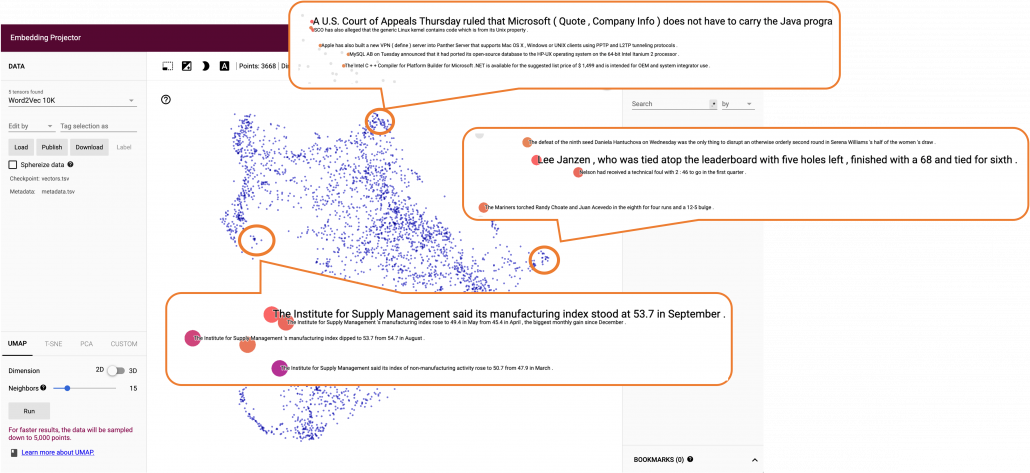
To make it catchy I expressed them as “coffee syrup” but this is a kind of how so-called AI sees data. Images and texts are just vectors or tensors on computer, and AI process another set of tensors of vectors in spaces which make sense to them.
Fine-tuning is quite easy. You have only to train a pre-trained model you downloaded just like normal supervised learning with your dataset. And when you train CV models with backbone CNN, the backbone is almost automatically downloaded. You have to be careful about some points, for example you have to set learning rate smaller. Let me avoid too detailed points in this article. Hopefully in the future, I’d like to write about more practical fine-tuning tips.
Domain adaptation
Domain adaptation is another family of techniques to make uses of knowledge gained in one domain in another domain. Domain adaptation is a Domain adaptation is these days often used as almost a synonym of transfer learning. But papers on domain adaptation usually assume to handle the same tasks both in a source and a target domain. So I would say domain adaptation is a subfield of transfer learning. Domain adaptation is more of how to tackle deterioration of machine learning performances when trained models are applied in different domains. Based on how much labels are available in each domain, domain adaptation is classified to several types. And unsupervised domain adaptation (UDA), where labels are available only in a source domain, is considered as the most challenging and studied well.
*Another explanation I often hear about domain adaptation is, when a models trained on a dataset is trained on another data, domain adaptation can be used to mitigate decreases in performance. I think in this context, performance of the model on the source domain is not discussed. When you apply some retraining with a new dataset, performance of the model on the source domain often drastically decrease. This is called catastrophic forgetting, and techniques like continuous learning are studied to tackle this problem. I have not really seen continuous learning in contexts of domain adaptation, but I thin these are related.
There several approaches in domain adaptation, and one frequently used approach is using adversarial loss. As we saw with the example of getting “coffee syrup,” data is first mapped into a certain space, and this is often called feature extraction. And outputs with the feature extractor are processed are processed more to give task-specific results with some networks. Often in domain adaptation, we put a domain discriminator network right after the feature extractor. And the domain discriminator classifies whether the features extracted come from the source or target domain. The feature extractor tries to extract features the domain have in common, and the domain discriminator tries to distinguish them, and two networks compete. In this way, the feature extractor and the domain discriminator form generative adversarial network (GAN), and the feature extractor learns to extract features that are hard to distinguish their domains. Feature extractor is trained so that it extract domain invariant features, for example edges and silhouette.
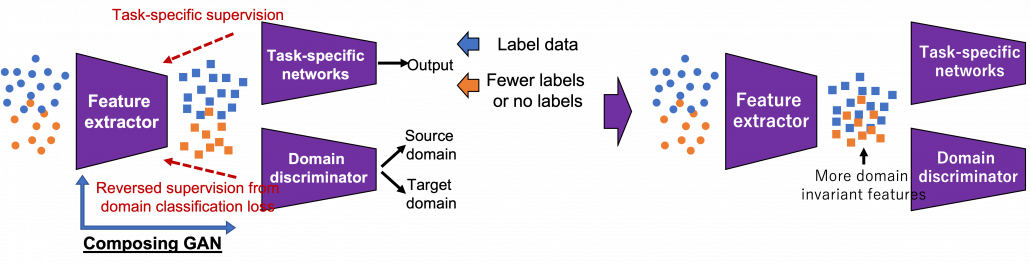
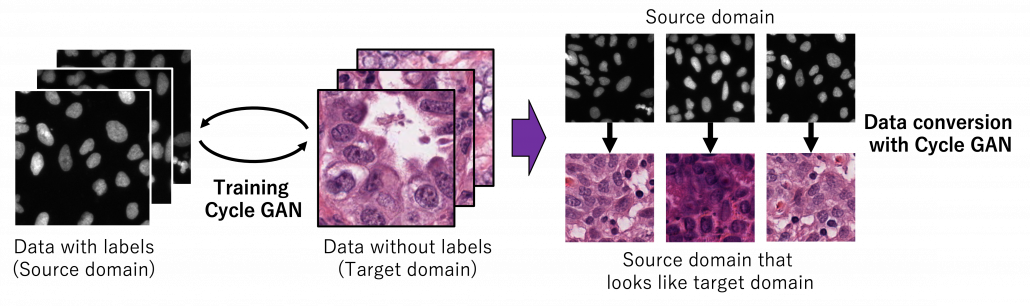
As well as in other transfer learning techniques, one ultimate goal of UDA is training a deep learning model only with synthetic labeled data, for example CGI, and apply the model on a totally unlabeled dataset. Converting a source domain to look like a target domain with Cycle GAN is an often used approach in domain adaptation. In domain adaptation a source domain is supposed to be easier to annotate. The figure below is an example of converting a black and white cell images to colored images.
*You could easily try converting data with Cycle GAN by preparing two datasets, and I made the converted data by myself. But you need at least one GPU to try that.
However some people insist that usefulness of UDA is very questionable. In the first place, if you do not have any labels on the target domain, that means you cannot evaluate anything qualitatively on the dataset of interest. And if you can prepare some of evaluation data or labels, applying other techniques like fine-tuning might be enough.
Meta learning and few-shot learning
One simple way to explain meta learning is that, it is a machine learning technique teach models to learn efficiently. We can also say that it is a transfer learning case where target domains are unknown. A famous meta learning method is Model-Agnostic Meta-Learning (MAML). MAML is used to get an ideal parameter which can be quickly and effectively used to new tasks. Like in the figure below, reaches the generally convenient parameter shown as the black dot. And the parameter can quickly reach the parameters  , which effective for each task.
, which effective for each task. 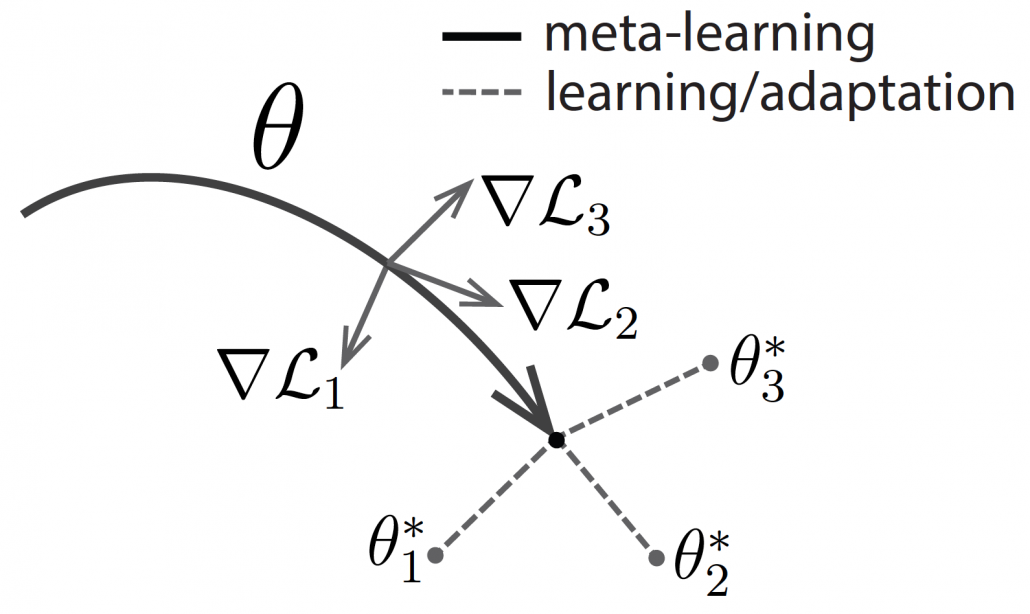
Another interesting application of meta learning is few-shot learning. Few-shot learning trains a classification model to learn to acquire classification ability based only on a very few samples. By letting the models learn classification tasks over many episodes, the model learn comes to learn efficiently from limited data samples at a test phase. The figure below shows a case of few-shot learning, where a model learns some episodes of 3-class classifications with only 4 samples per class. Few-shot learning attempts to enable human-level flexibility of perception. MAML is known to be effective also for few-shot learning.
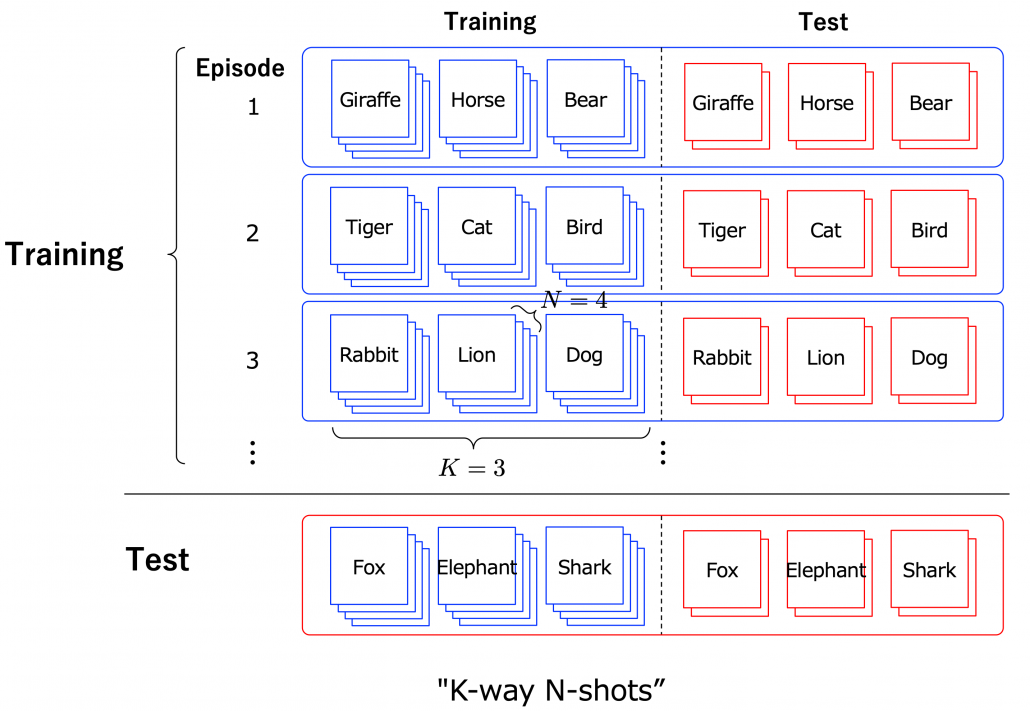
However, studies these days do also show that fine tuning pre-trained models with a few sample data show competitive results to those by few-shot learning. Similar things can be said about large language models like GPT. Chat GPT or GPT-3/GPT-4 for example can be fine-tuned with small extra training samples, and the logic behind is different from meta learning. Fine-tuning pre-trained models rather might be closer to human learning. Humans can effectively learn new topics based on what they have experienced so far. Thus again here, fine-tuning models can be an easier and realistic solution.
I have explained an overview of machine learning techniques for handling lack of data, and as you might have noticed, fine-tuning models could be enough in many cases. I am not sure how much other transfer learning technique would be widely as useful as fine-tuning at a business level. At least, I hope this article would be a rough guideline for machine learning tasks with small sizes of data or labels. And if you have a chance to work on very unique data with very few labels, you wouldn’t be able to rely so much on only naive fine tuning of pre-trained models. In that case, you tasks have your own problem, and you would have to be careful about your EDA, data cleaning, and labeling. In that case you should consider some techniques introduced here. Hopefully someday I would like to write more detailed tutorials with each transfer learning technique. And I hope you would be able to apply a variety of transfer learning locally, not only relying on huge resources of gigantic entities. And that would lead to a more secure future, I guess.

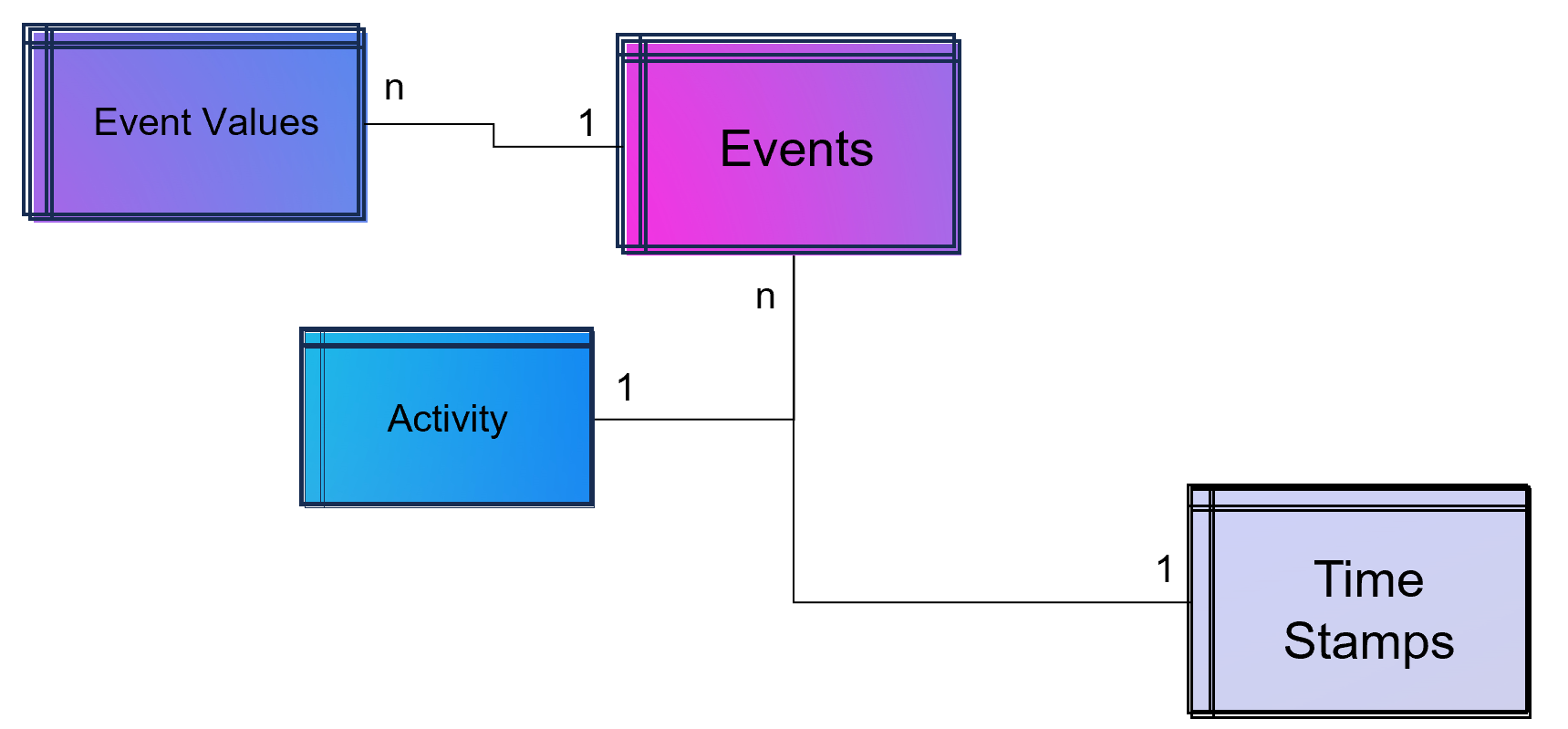
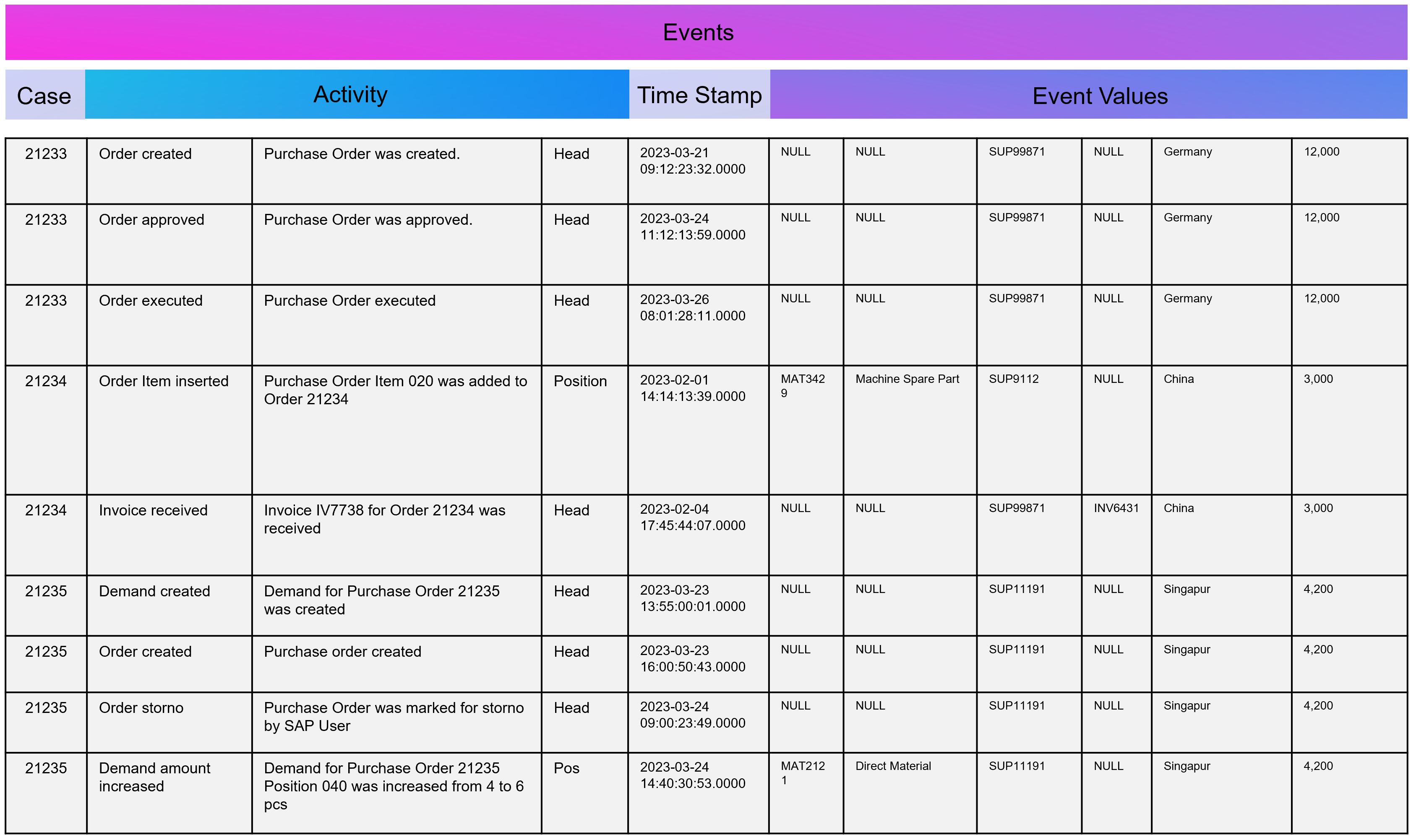
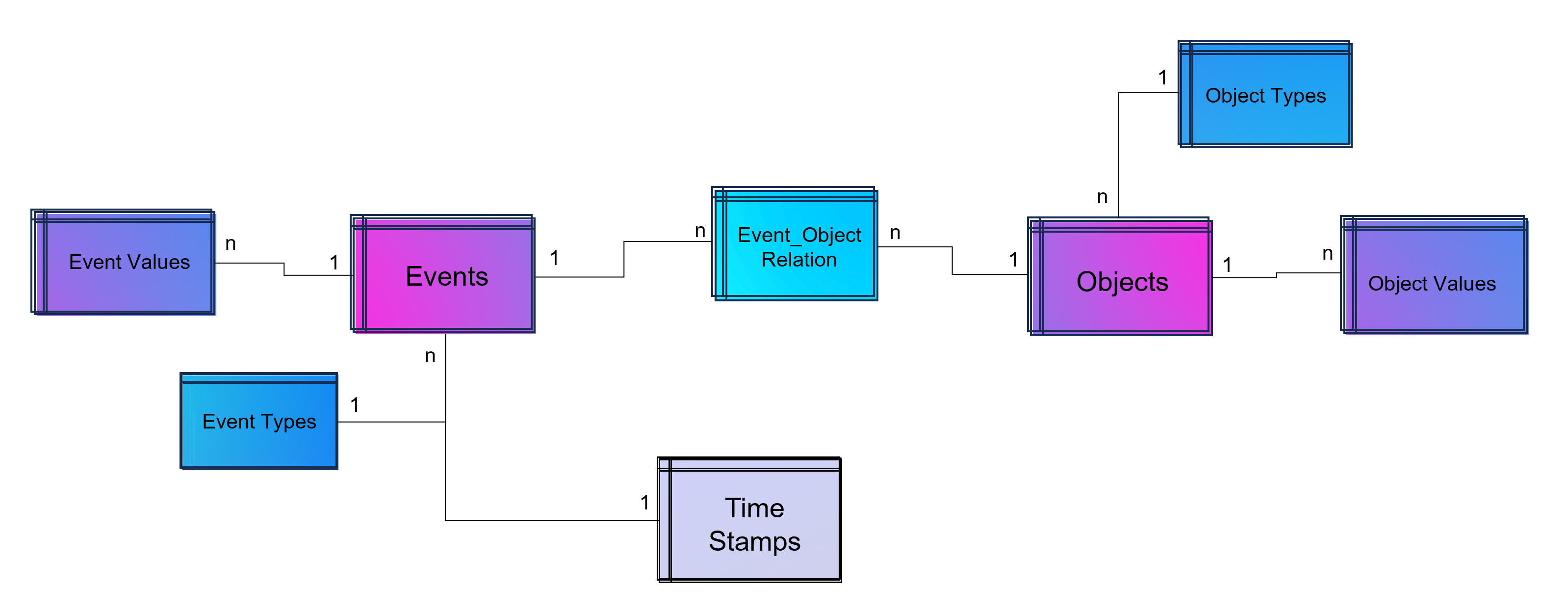
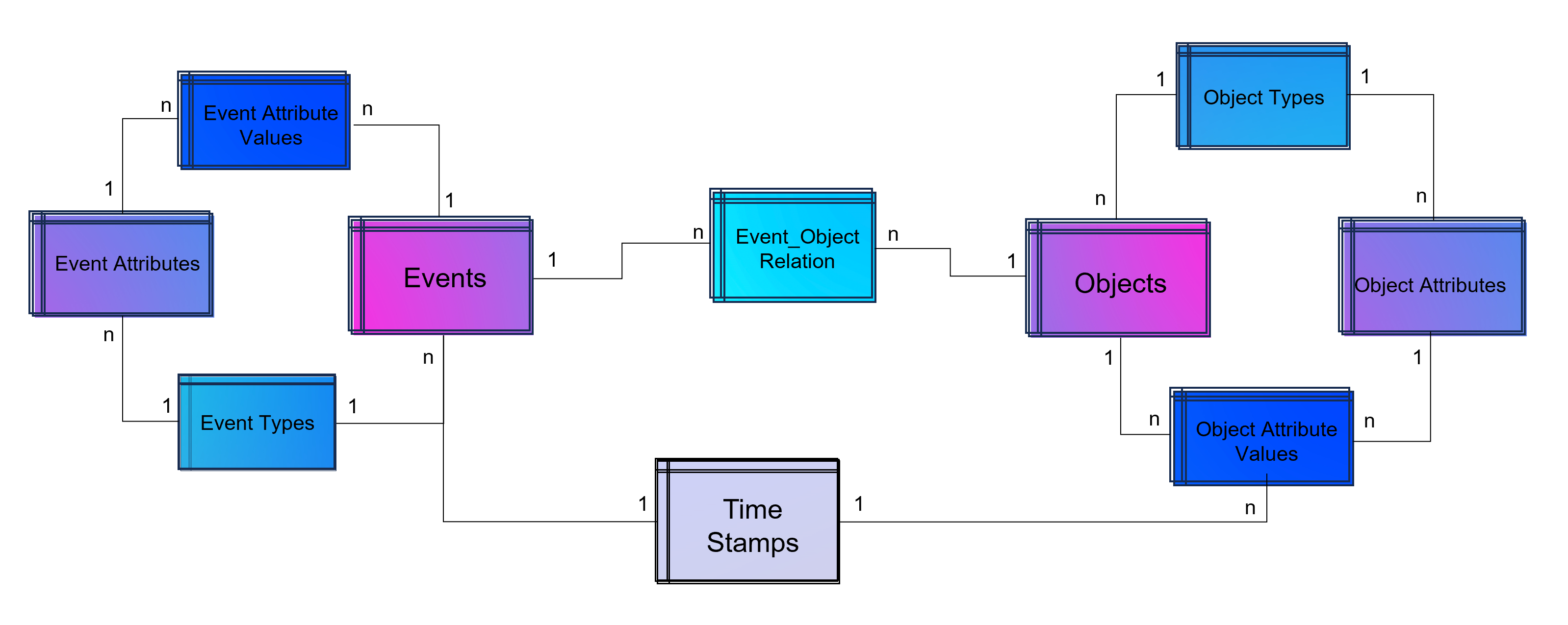
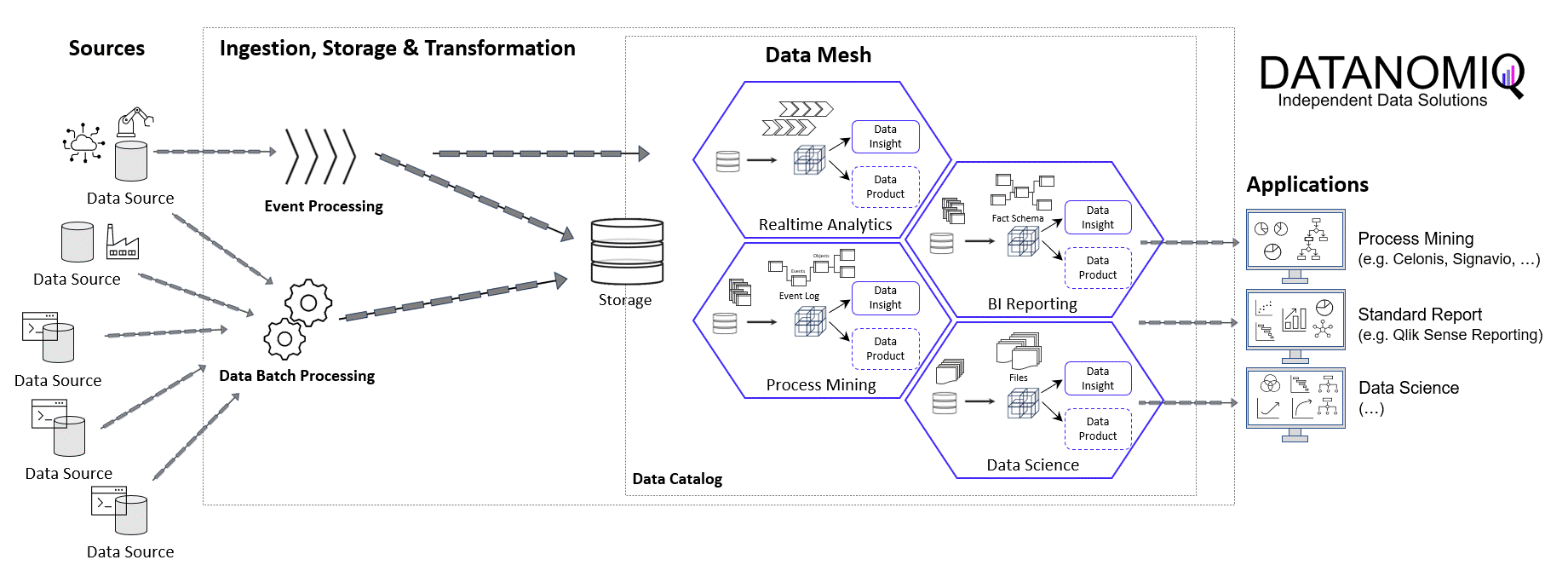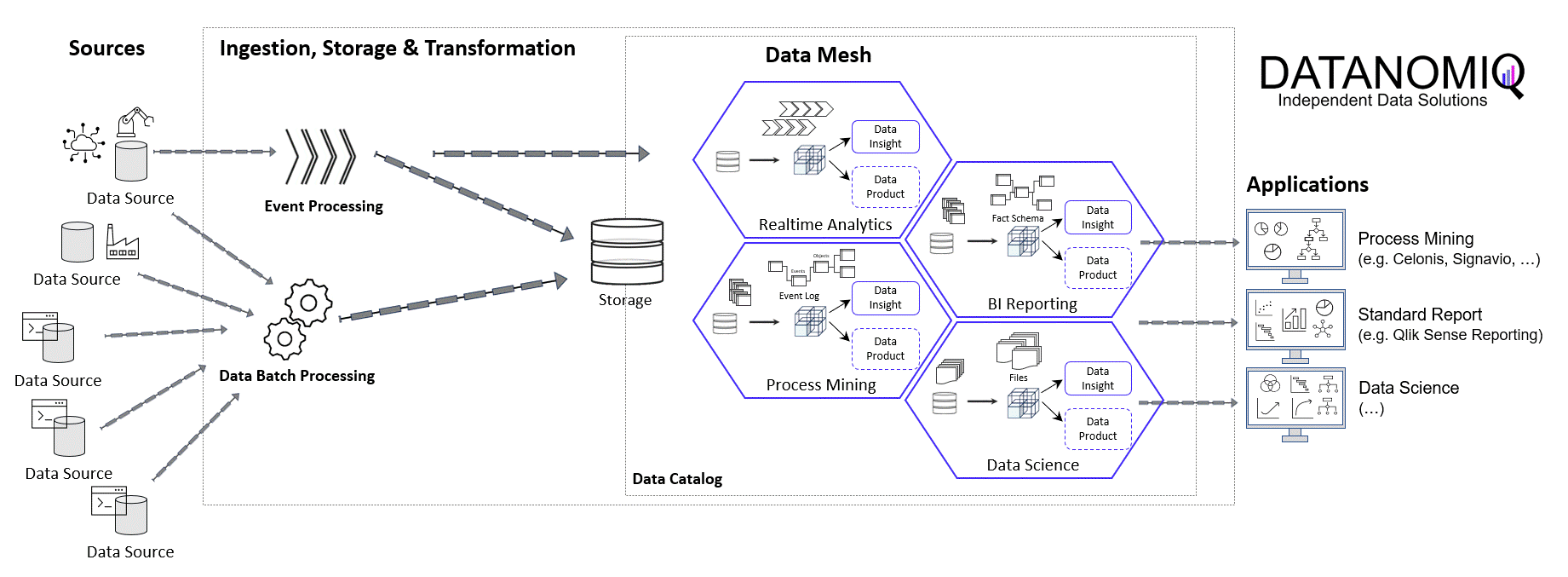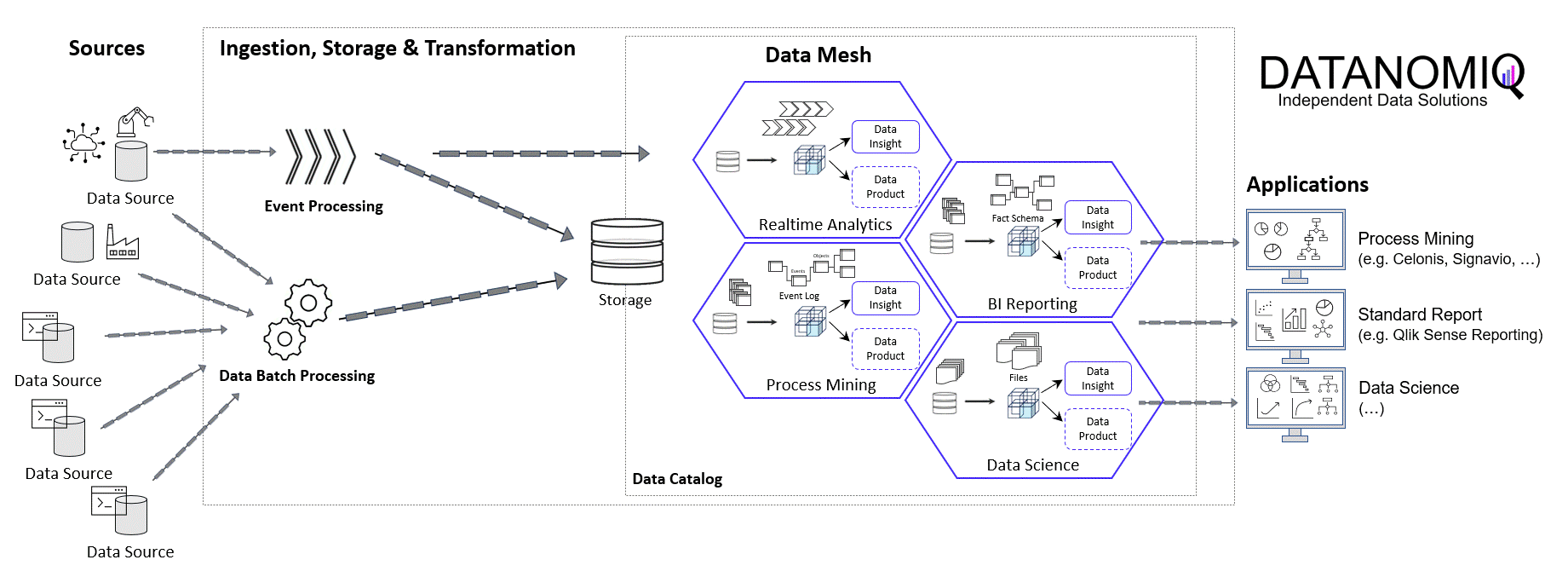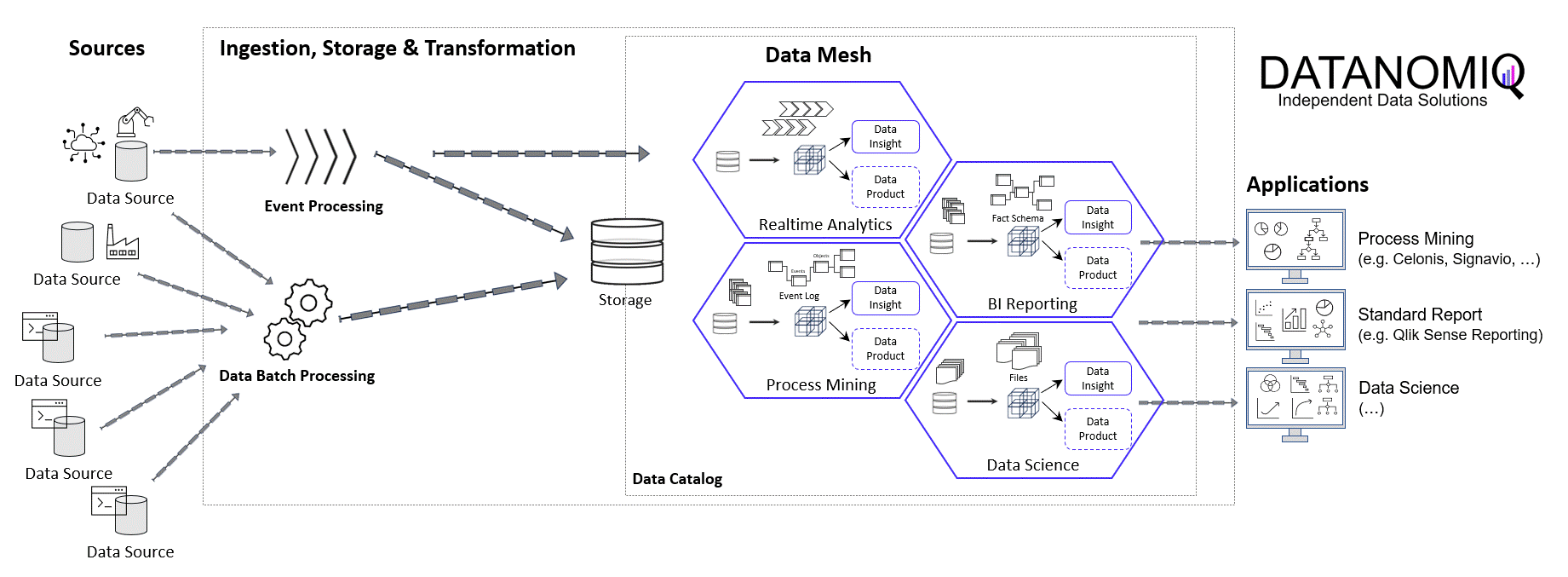
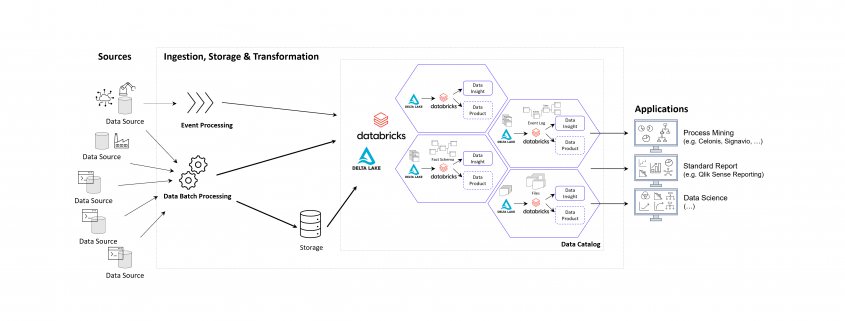
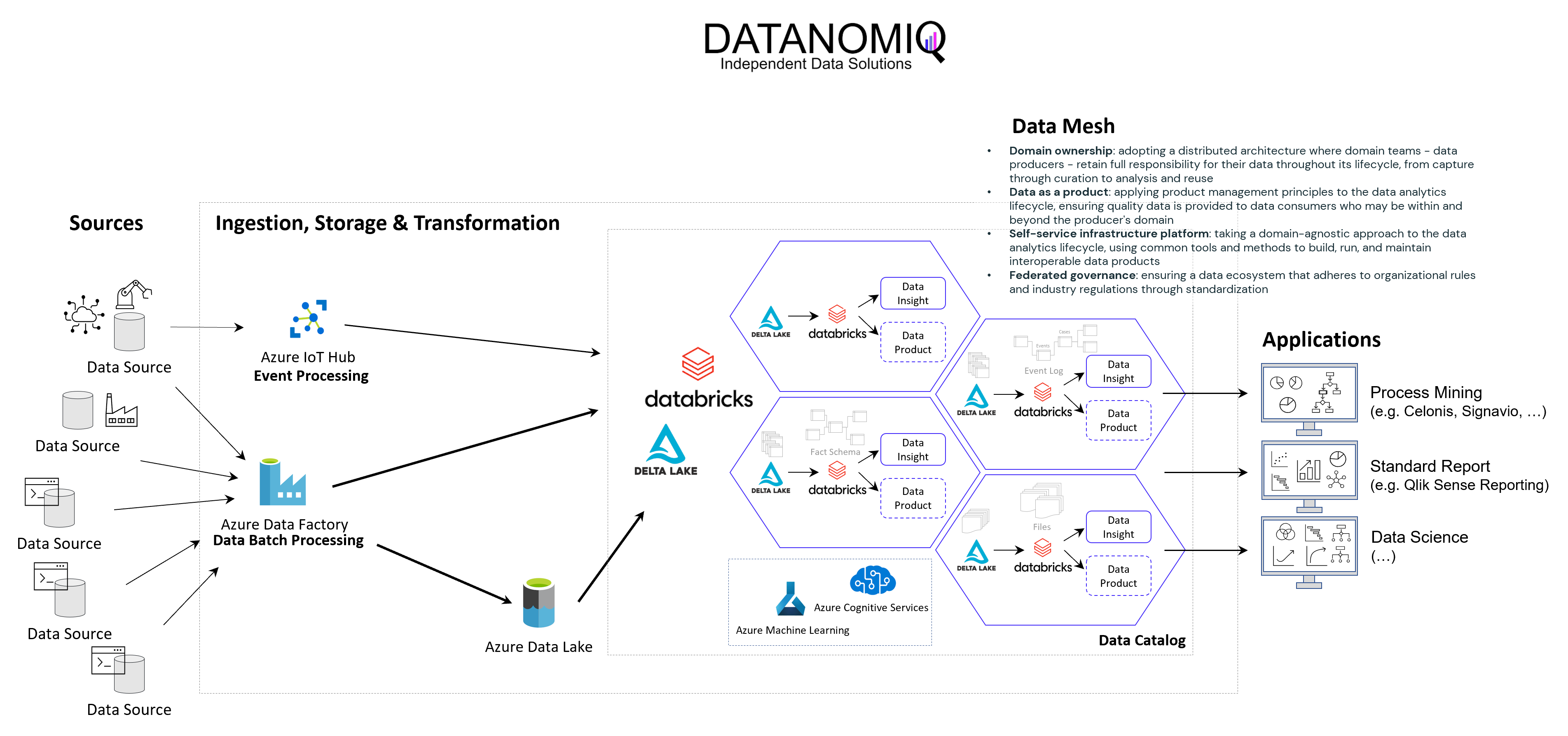
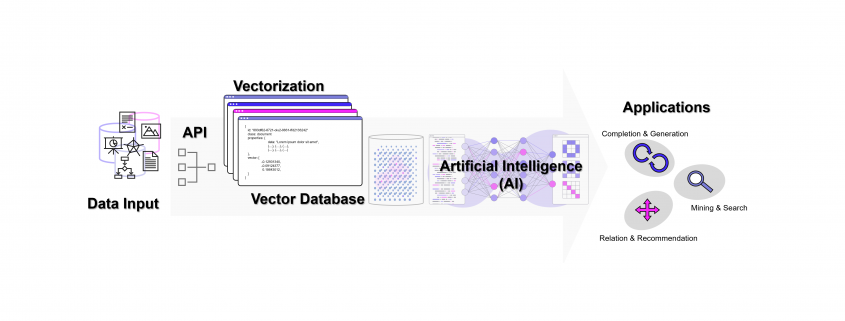 DATANOMIQ - Benjamin Aunkofer
DATANOMIQ - Benjamin Aunkofer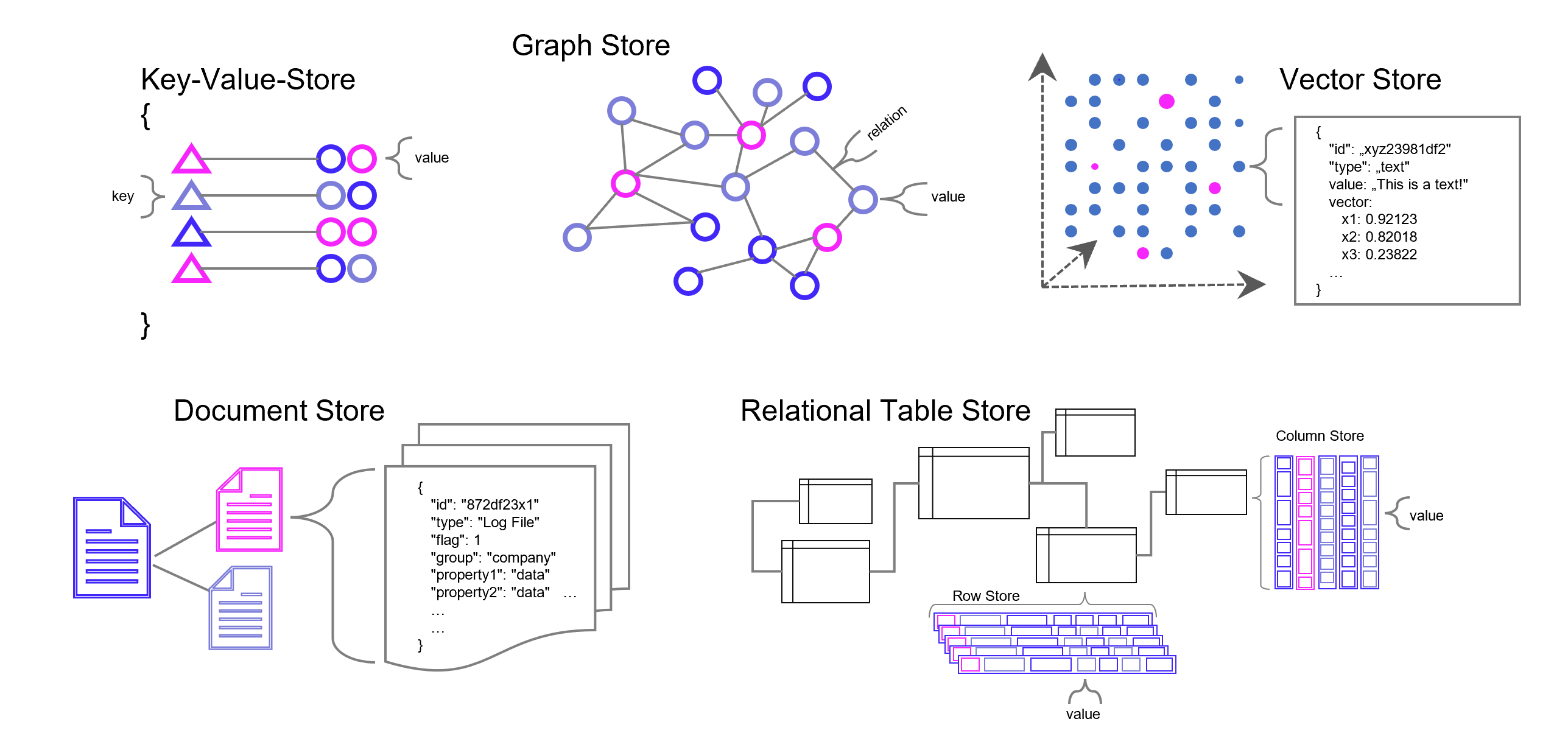
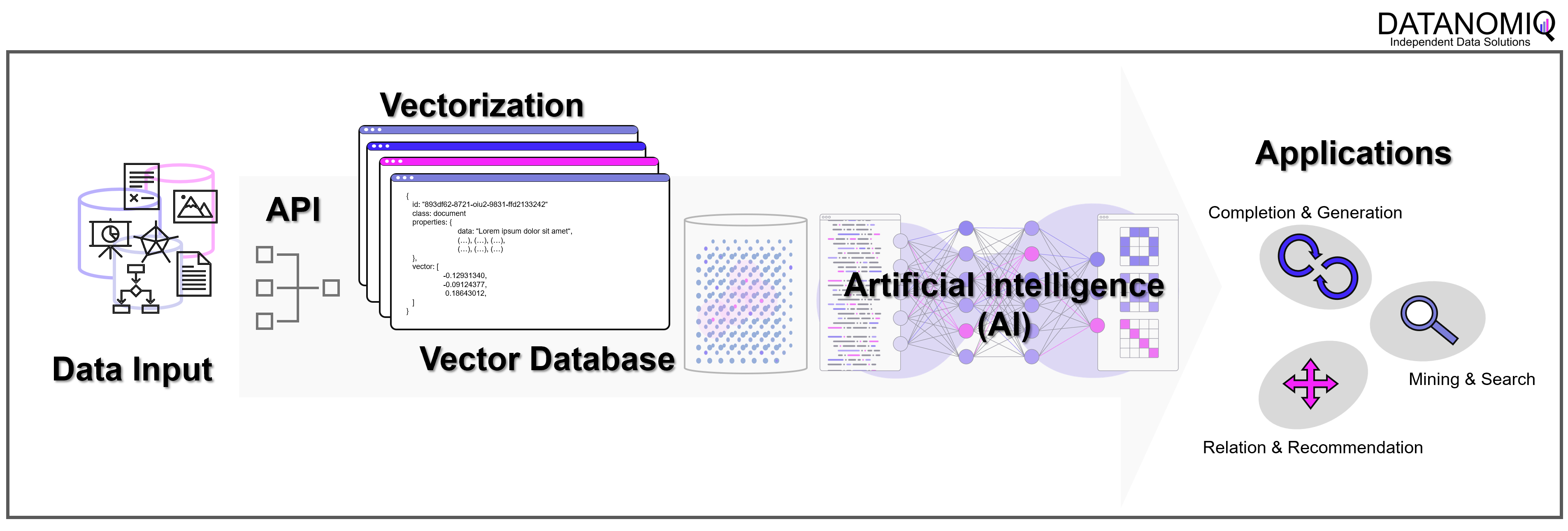
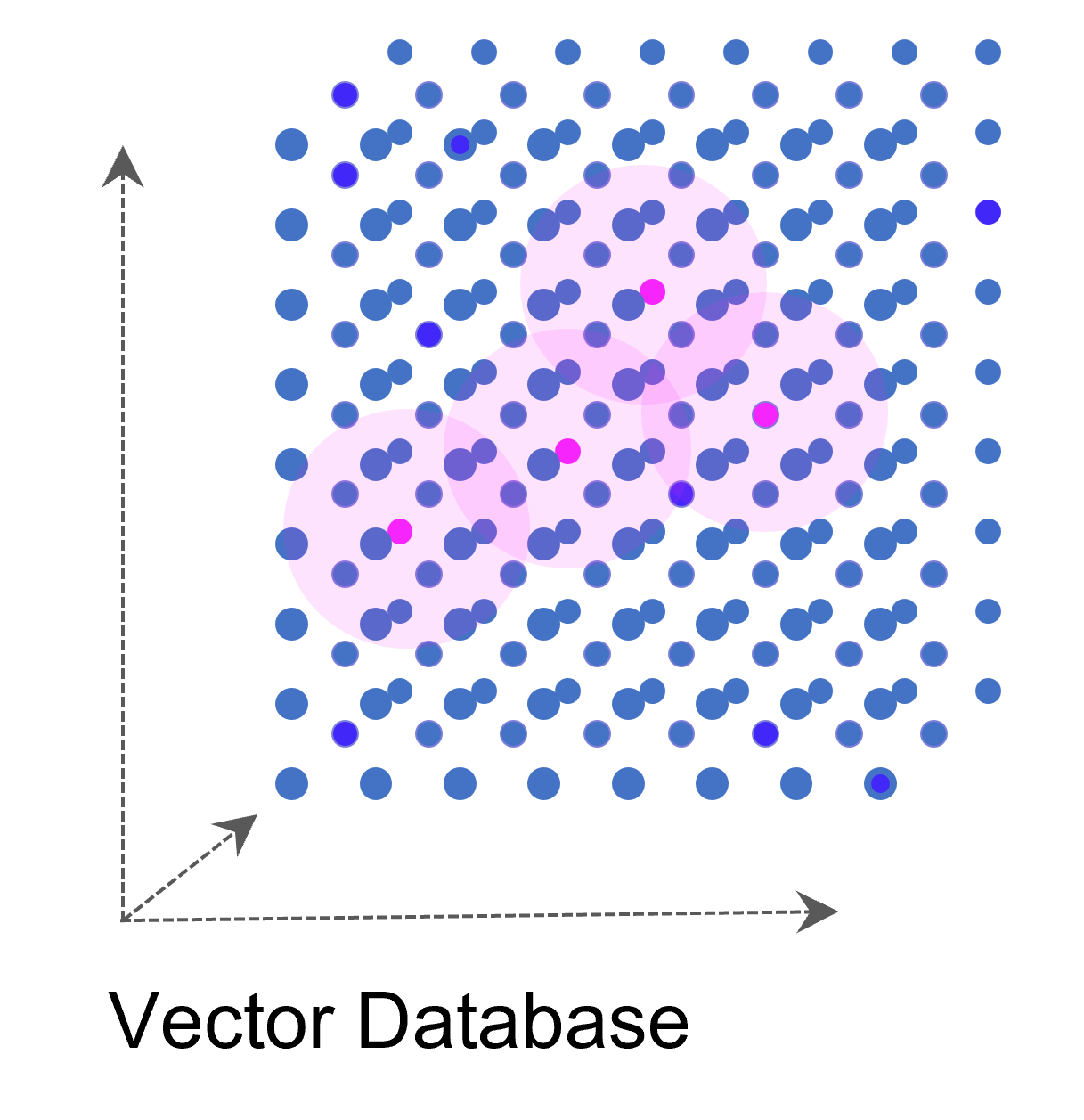 Weise kann eine ganze Sammlung von Bildern als eine Sammlung von Vektoren dargestellt werden. Noch gängiger jedoch sind Vektorräume, die Texte z. B. über die Häufigkeit des Auftretens von Textbausteinen (Wörter, Silben, Buchstaben) in sich einbetten (Embeddings). Embeddings sind folglich Vektoren, die durch die Projektion des Textes auf einen Vektorraum entstehen.
Weise kann eine ganze Sammlung von Bildern als eine Sammlung von Vektoren dargestellt werden. Noch gängiger jedoch sind Vektorräume, die Texte z. B. über die Häufigkeit des Auftretens von Textbausteinen (Wörter, Silben, Buchstaben) in sich einbetten (Embeddings). Embeddings sind folglich Vektoren, die durch die Projektion des Textes auf einen Vektorraum entstehen.


 and black nodes showing actions
and black nodes showing actions  . And when an agent goes from a node
. And when an agent goes from a node  , it gets a corresponding reward
, it gets a corresponding reward  . As I explained in the second article, a value of a state
. As I explained in the second article, a value of a state 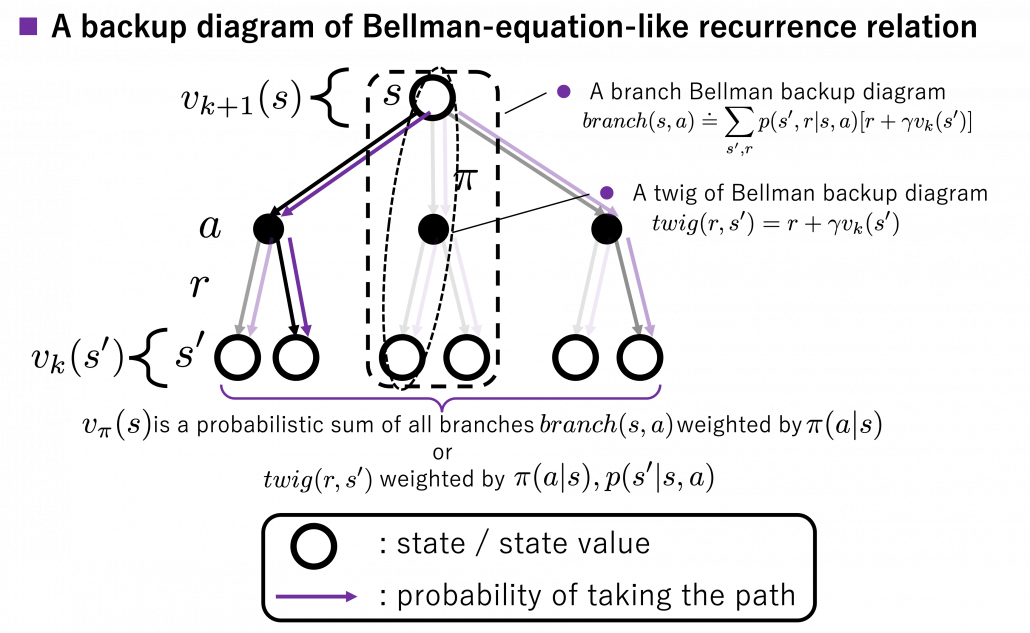
 is known, and
is known, and  .
.  , given that the state at the time step
, given that the state at the time step  is
is ![v_{\pi} (s)\doteq \mathbb{E}_{\pi} [ G_t | S_t =s ] =\mathbb{E}_{\pi} [ R_{t+1} + \gamma R_{t+2} + \gamma ^2 R_{t+3} + \cdots + \gamma ^{T-t -1} R_{T} |S_t =s]](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-10b9dc282a7d98ce7ecaf0316096f9c9_l3.png "Rendered by QuickLaTeX.com")
 like
like  . But the number
. But the number ![v_{\pi} (s)= \mathbb{E}_{\pi} [ R_{t+1} + \gamma v_{\pi}(S_{t+1}) | S_t =s ]](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-349331e8707784287bb3fd227c4f03af_l3.png "Rendered by QuickLaTeX.com")
 at the left side,
at the left side, ![v_{k+1} (s)\doteq \mathbb{E}_{\pi} [ R_{t+1} + \gamma v_{k}(S_{t+1}) | S_t =s ]](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-ba20177dbed44812a6f2ce98154e2c2e_l3.png "Rendered by QuickLaTeX.com")
 , namely a probabilistic sum of future rewards is defined as follows.
, namely a probabilistic sum of future rewards is defined as follows.![v_{k+1} (s) = \mathbb{E}_{\pi} [R_{t+1} + \gamma v_k (S_{t+1}) | S_t = s] \doteq \sum_a {\pi(a|s)} \sum_{s', r} {p(s', r|s, a)[r + \gamma v_k(s')]}](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-1a1aa71a4846a76bd8220751fa988103_l3.png "Rendered by QuickLaTeX.com")
 are policies, and
are policies, and  are probabilities of transitions. Policies are probabilities of taking an action
are probabilities of transitions. Policies are probabilities of taking an action  weighted by
weighted by  weighted by
weighted by  . “Branches” and “twigs” are terms which I coined.
. “Branches” and “twigs” are terms which I coined. is calculated like in the figure below, using values of
is calculated like in the figure below, using values of  . As I explained earlier, the value of the state
. As I explained earlier, the value of the state  is a sum of
is a sum of  . And I showed the weight as strength of purple color of the arrows.
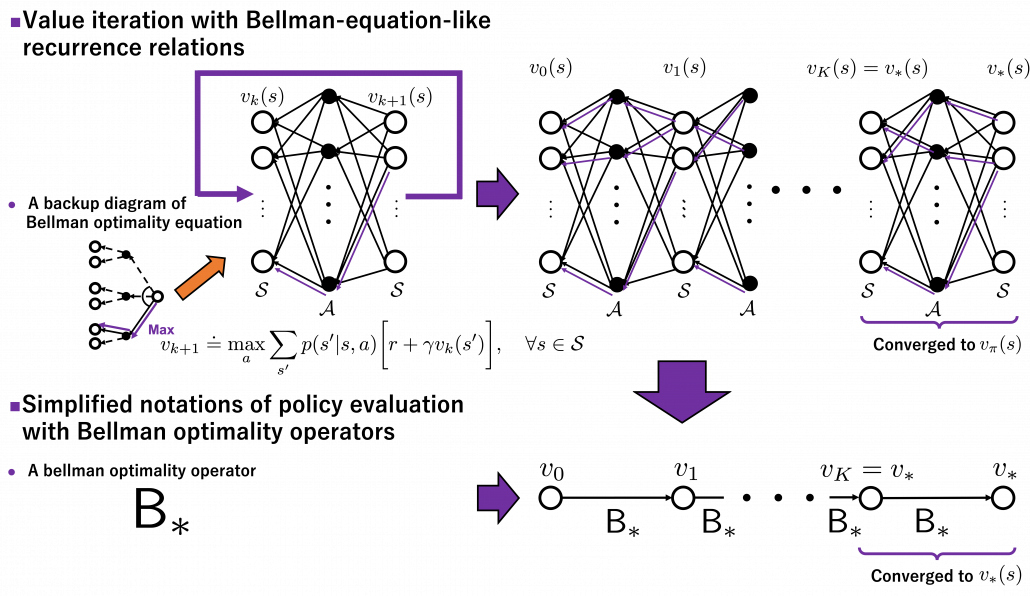
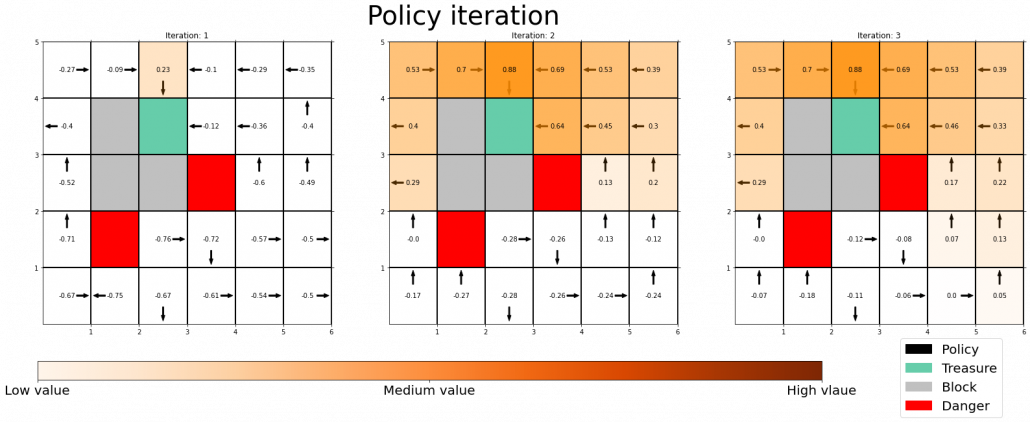
. And I showed the weight as strength of purple color of the arrows.  are corresponding rewards of each transition. And importantly, the Bellman-equation-like operation, whish is a part of DP, is conducted inside the agent. The agent does not have to actually move, and that is what planning is all about.
are corresponding rewards of each transition. And importantly, the Bellman-equation-like operation, whish is a part of DP, is conducted inside the agent. The agent does not have to actually move, and that is what planning is all about.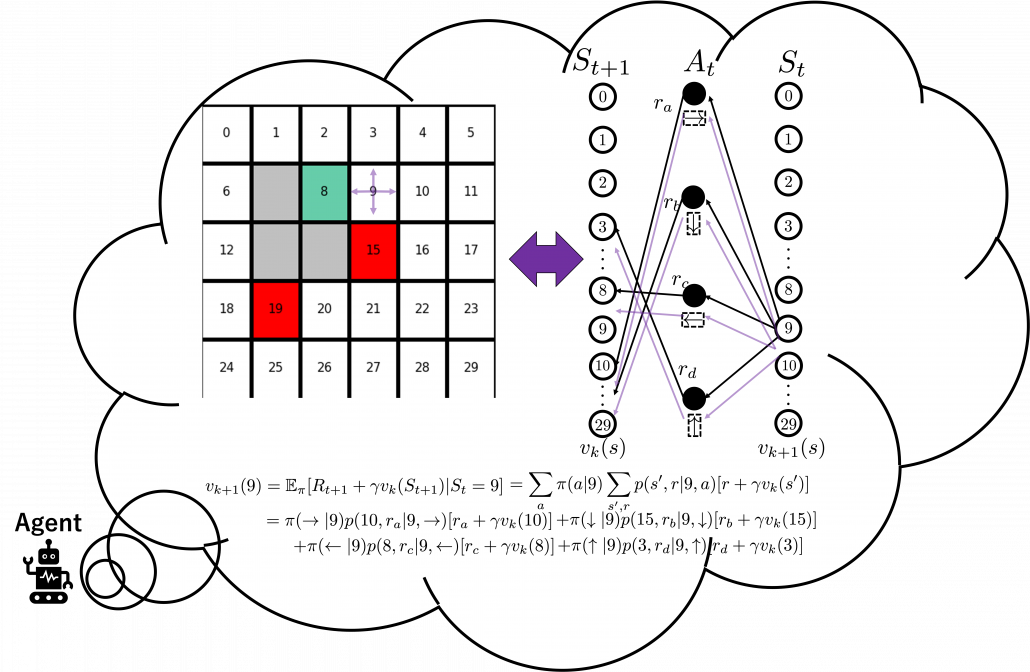
 to
to  . I tried to show the idea that values
. I tried to show the idea that values 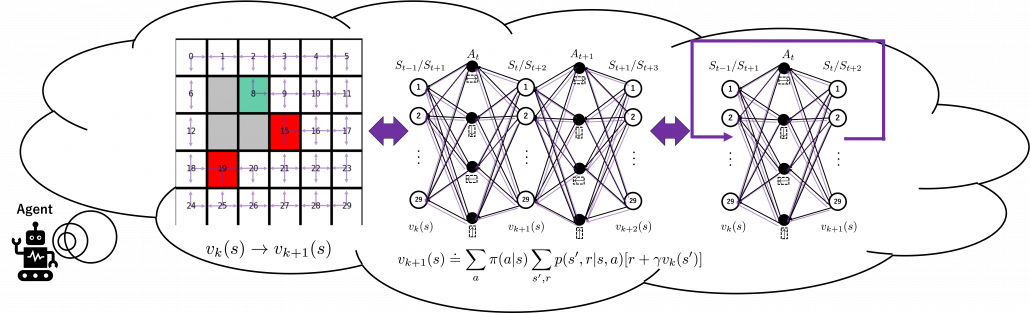
 in the figure below are of interest when you learn RL as a beginner. I am going to explain what each set of policies means one by one.
in the figure below are of interest when you learn RL as a beginner. I am going to explain what each set of policies means one by one.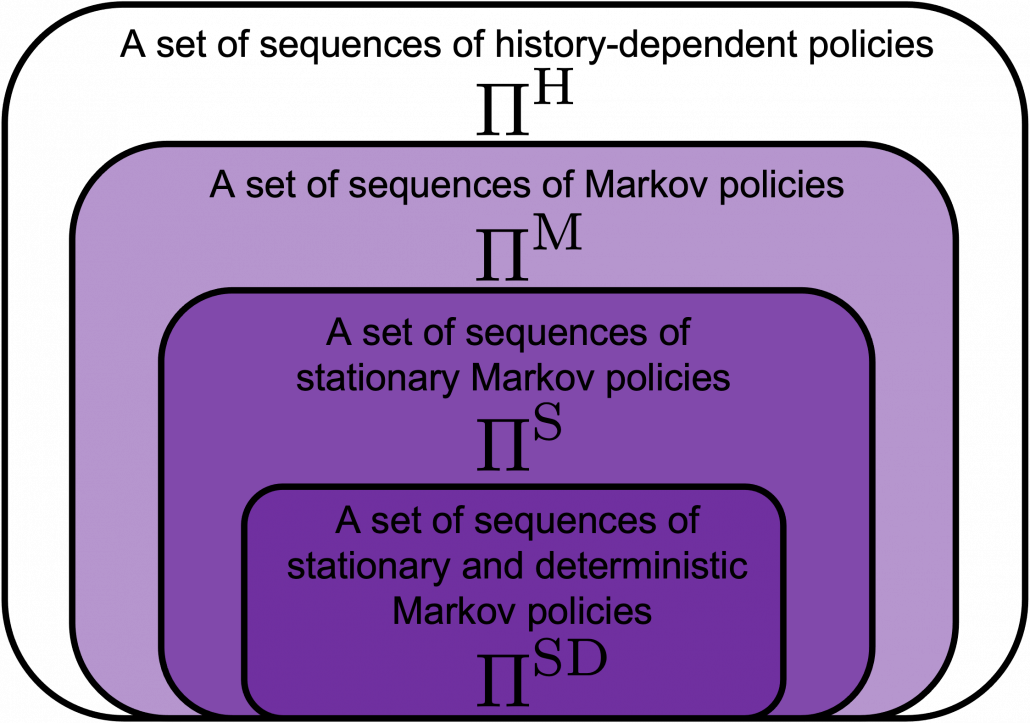
 , which mean probabilistic Markov policies. Remember that in the first article I explained Markov decision processes can be described like diagrams of daily routines. For example, the diagrams below are my daily routines. The indexes
, which mean probabilistic Markov policies. Remember that in the first article I explained Markov decision processes can be described like diagrams of daily routines. For example, the diagrams below are my daily routines. The indexes 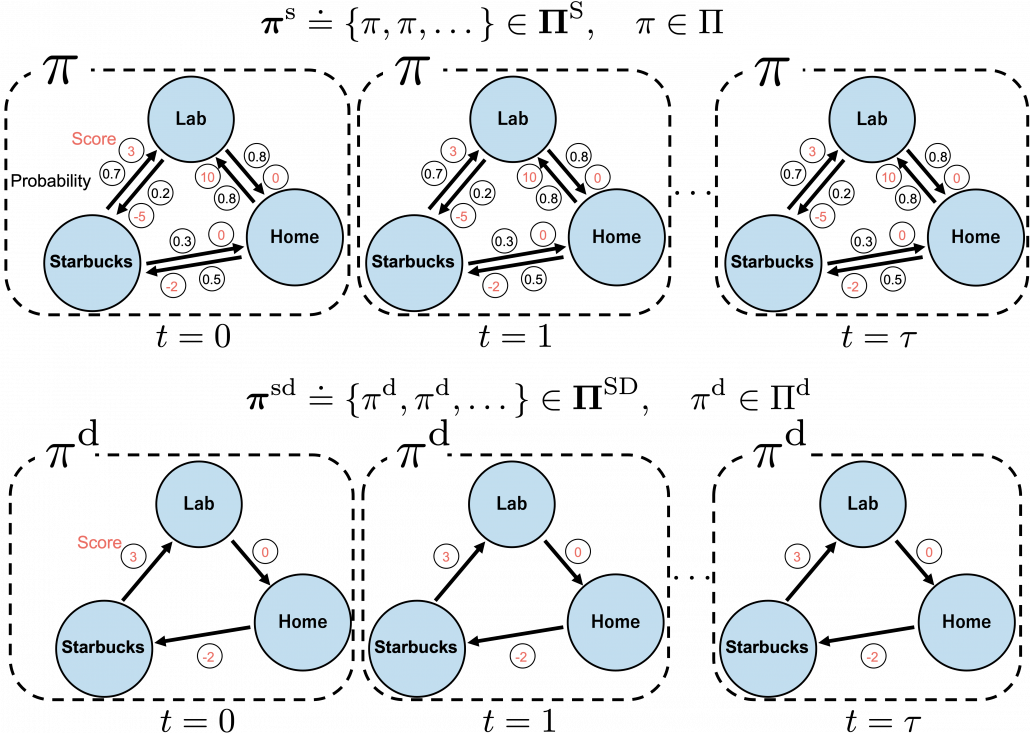
![\Pi \doteq \biggl\{ \pi : \mathcal{A}\times\mathcal{S} \rightarrow [0, 1]: \sum_{a \in \mathcal{A}}{\pi (a|s) =1, \forall s \in \mathcal{S} } \biggr\}](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-9a217cc6d5cfd59e564fd2132620f89f_l3.png "Rendered by QuickLaTeX.com")
 maps any combinations of an action
maps any combinations of an action  and a state
and a state  to a probability. The diagram above means you choose a policy
to a probability. The diagram above means you choose a policy  , and you use the policy every time step
, and you use the policy every time step  . And a set of such stationary Markov policy sequences is denoted as
. And a set of such stationary Markov policy sequences is denoted as  .
. are called deterministic policies.
are called deterministic policies.
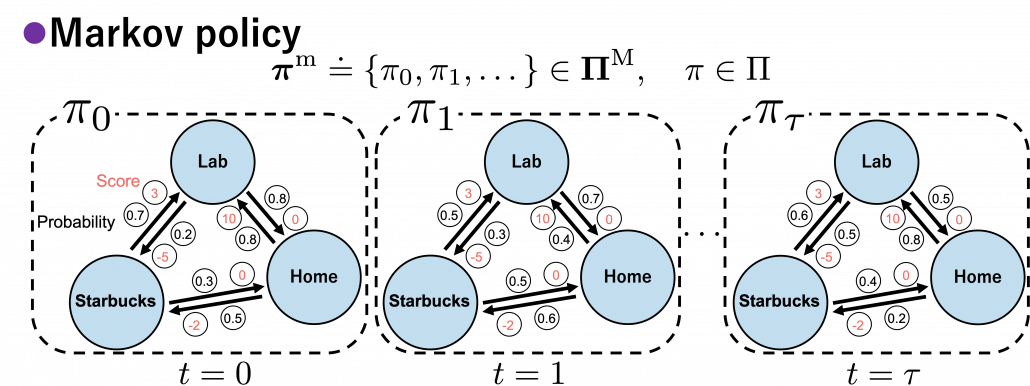
 .
.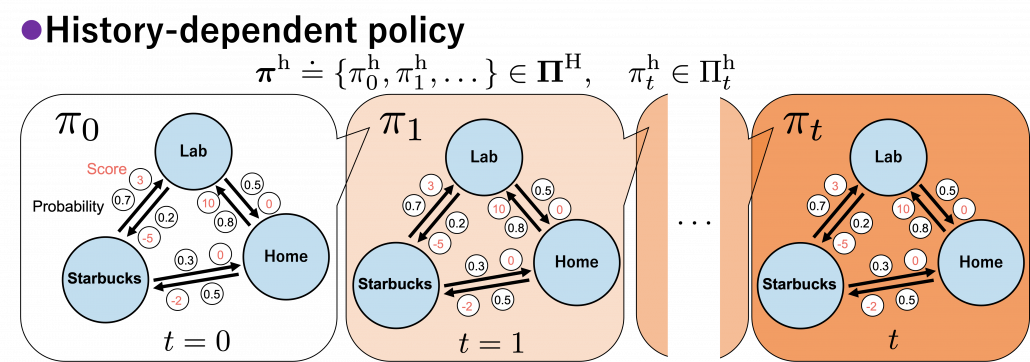
 . However as I said, only
. However as I said, only  in the context of DP or RL are defined as follows.
in the context of DP or RL are defined as follows.

 . It might be more understandable with the graphical model below, which I showed also in the first article. In the graphical model,
. It might be more understandable with the graphical model below, which I showed also in the first article. In the graphical model,  is a random variable, and
is a random variable, and 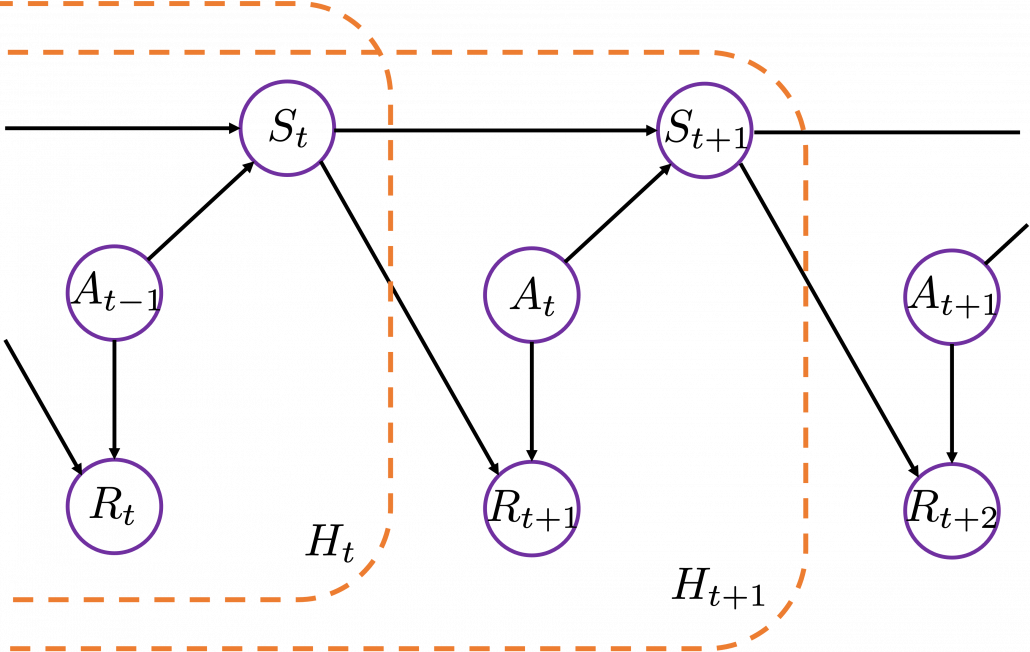
![\Pi _{t}^{\text{h}} \doteq \biggl\{ \pi _{t}^{h} : \mathcal{A}\times\mathcal{H}_t \rightarrow [0, 1]: \sum_{a \in \mathcal{A}}{\pi_{t}^{\text{h}} (a|h_{t}) =1 } \biggr\}](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-6414a4a7c3e4041e14077fce7a8c3fa1_l3.png "Rendered by QuickLaTeX.com")
 .
. or
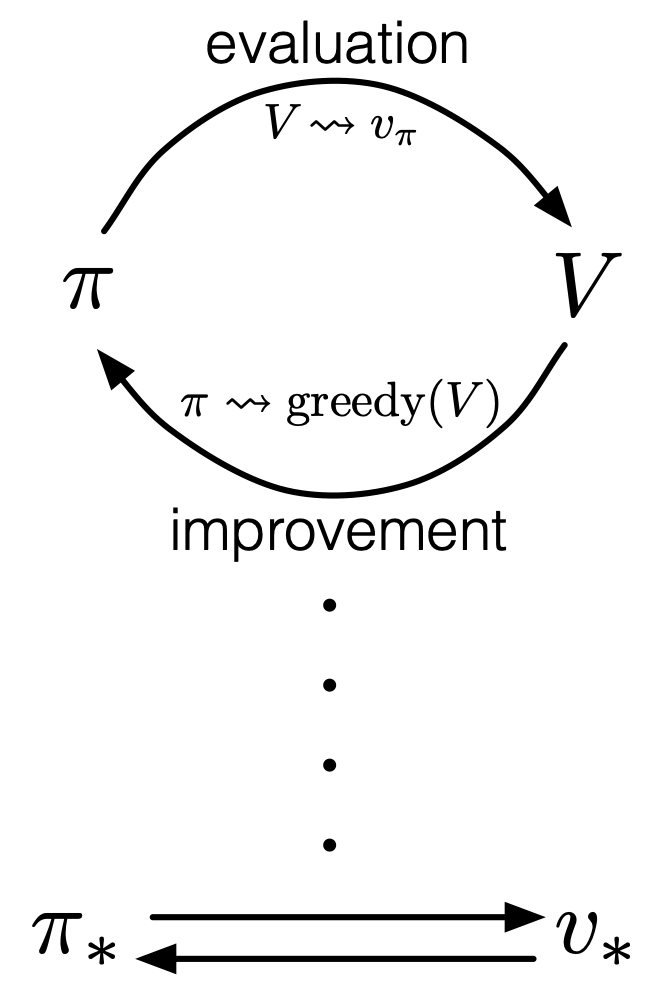
or  in my article series yet. I must admit it was not good to discuss DP without even defining the important ideas. But now that we have learnt types of policies, it should be less confusing to introduce their more precise definitions now. The optimal value function
in my article series yet. I must admit it was not good to discuss DP without even defining the important ideas. But now that we have learnt types of policies, it should be less confusing to introduce their more precise definitions now. The optimal value function  is defined as the maximum value functions for all states
is defined as the maximum value functions for all states  .
.

 . That means, in the example graphical models I displayed, you just have to deterministically go back and forth between the lab and the home in order to maximize value function, never stopping by at a Starbucks. Also you do not have to change your plans depending on days.
. That means, in the example graphical models I displayed, you just have to deterministically go back and forth between the lab and the home in order to maximize value function, never stopping by at a Starbucks. Also you do not have to change your plans depending on days. is defined. But to make things easier for now, let me skip ore precise formulations. Value functions are defined as expectations of rewards with respect to a single policy or a sequence of policies. You have only to keep it in mind that
is defined. But to make things easier for now, let me skip ore precise formulations. Value functions are defined as expectations of rewards with respect to a single policy or a sequence of policies. You have only to keep it in mind that 
 or
or  .
. , which is deterministic. And it is an optimal policy if and only if it satisfies the Bellman expectation equation
, which is deterministic. And it is an optimal policy if and only if it satisfies the Bellman expectation equation  , with the optimal value function
, with the optimal value function  .
. , or rather an application of a Bellman expectation operator on any state functions
, or rather an application of a Bellman expectation operator on any state functions  is defined as below.
is defined as below.![(\mathsf{B}_{\pi} (v))(s) \doteq \sum_{a}{\pi (a|s)} \sum_{s'}{p(s'| s, a) \biggl[r + \gamma v (s') \biggr]}, \quad \forall s \in \mathcal{S}](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-35022b46d30c7f99c53089770a9dea7e_l3.png "Rendered by QuickLaTeX.com")
 . In the last article I explained that when
. In the last article I explained that when  is an arbitrarily initialized value function, a sequence of value functions
is an arbitrarily initialized value function, a sequence of value functions  converge to
converge to ![v_{k+1} = \sum_{a}{\pi (a|s)} \sum_{s'}{p(s'| s, a) \biggl[r + \gamma v_{k} (s') \biggr]}](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-792e43affeeb5f73e731a3bbd6469f93_l3.png "Rendered by QuickLaTeX.com")

 is obtained by applying
is obtained by applying 
 times in total. Such operation is denoted as follows.
times in total. Such operation is denoted as follows.
 converges to
converges to 
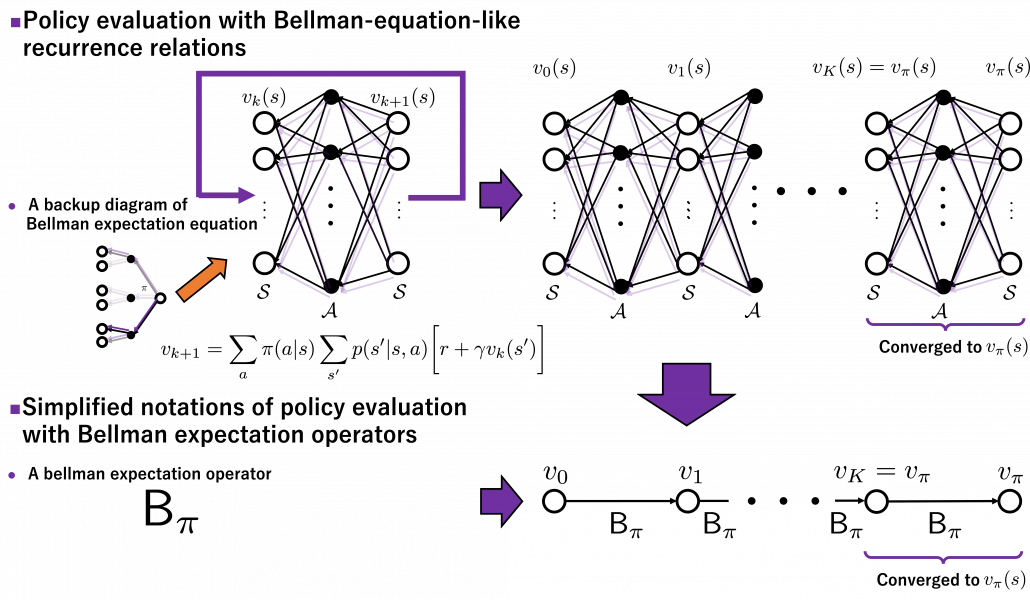
 is defined as follows.
is defined as follows.![(\mathsf{B}_{\ast} v)(s) \doteq \max_{a} \sum_{s'}{p(s' | s, a) \biggl[r + \gamma v(s') \biggr]}, \quad \forall s \in \mathcal{S}](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-1c6fc7233a418b4abdfbde6886da4b58_l3.png "Rendered by QuickLaTeX.com")
 . With a Bellman optimality operator, you can get a recurrence relation
. With a Bellman optimality operator, you can get a recurrence relation  . Multiple applications of Bellman optimality operators can be written down as below.
. Multiple applications of Bellman optimality operators can be written down as below.
 converges to the optimal value function
converges to the optimal value function  .
.
 . If you apply Bellman operators of the policies one by one in an order of
. If you apply Bellman operators of the policies one by one in an order of  on a state function
on a state function  , the resulting state function is calculated as below.
, the resulting state function is calculated as below.
 , we can also discuss convergence of
, we can also discuss convergence of  , but that is just confusing. Please let me know if you are interested.
, but that is just confusing. Please let me know if you are interested. , the value function for a policy
, the value function for a policy ![v(s) = \sum_{a}{\pi (a|s)} \sum_{s'}{p(s'| s, a) \biggl[r + \gamma v (s') \biggr]}](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-d96ea8fd9bc433436f0c1636288df540_l3.png "Rendered by QuickLaTeX.com")
 . But whichever the notation is, the equation holds when the value function
. But whichever the notation is, the equation holds when the value function  is
is  .
. , and the
, and the 
 . And also, you can judge whether a policy is optimal by a Bellman expectation equation below.
. And also, you can judge whether a policy is optimal by a Bellman expectation equation below.
![\pi^{\text{d}}_{\ast}(s) = \text{argmax}_{a\in \matchal{A}} \sum_{s'}{p(s' | s, a) \biggl[r + \gamma v_{\ast}(s') \biggr]}, \quad \forall s \in \mathcal{S}](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-f892c961c509bf6562fc0c5cdeabc355_l3.png "Rendered by QuickLaTeX.com")
 . After some calculations,
. After some calculations, 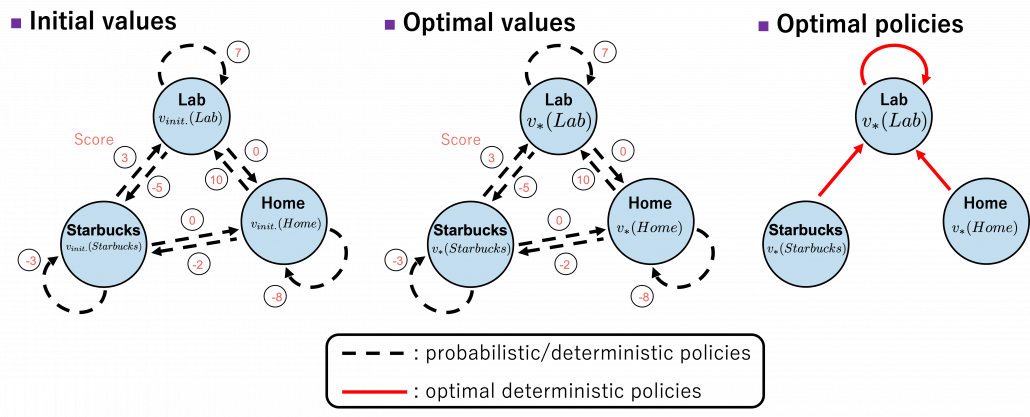
![b(s, a)\doteq\sum_{s'}{p(s' | s, a) \biggl[r + \gamma v_{\ast}(s') \biggr]} = r + \gamma \sum_{s'}{p(s' | s, a) v_{\ast}(s') }](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-cb95afc26ed333c0bc782b865d2595f1_l3.png "Rendered by QuickLaTeX.com") . Let me call the part
. Let me call the part  ” a value of a branch,” and finding the optimal deterministic policy is equal to choosing the maximum branch for all
” a value of a branch,” and finding the optimal deterministic policy is equal to choosing the maximum branch for all  and all the all the states
and all the all the states 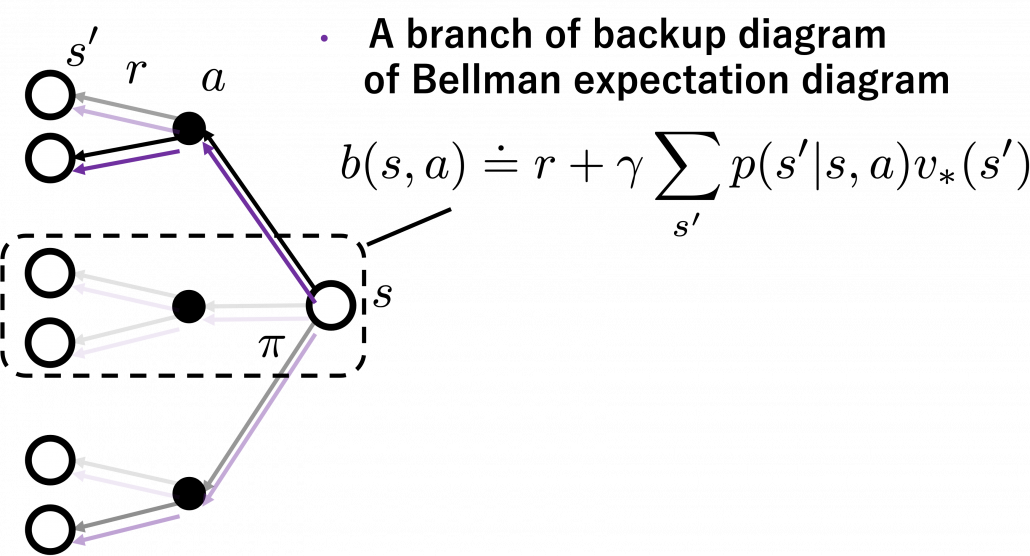
 . After you get the optimal value, if you choose the direction with the maximum branch at each state, you get the optimal deterministic policy. And that means “Just go to the lab, not Starbucks.”
. After you get the optimal value, if you choose the direction with the maximum branch at each state, you get the optimal deterministic policy. And that means “Just go to the lab, not Starbucks.”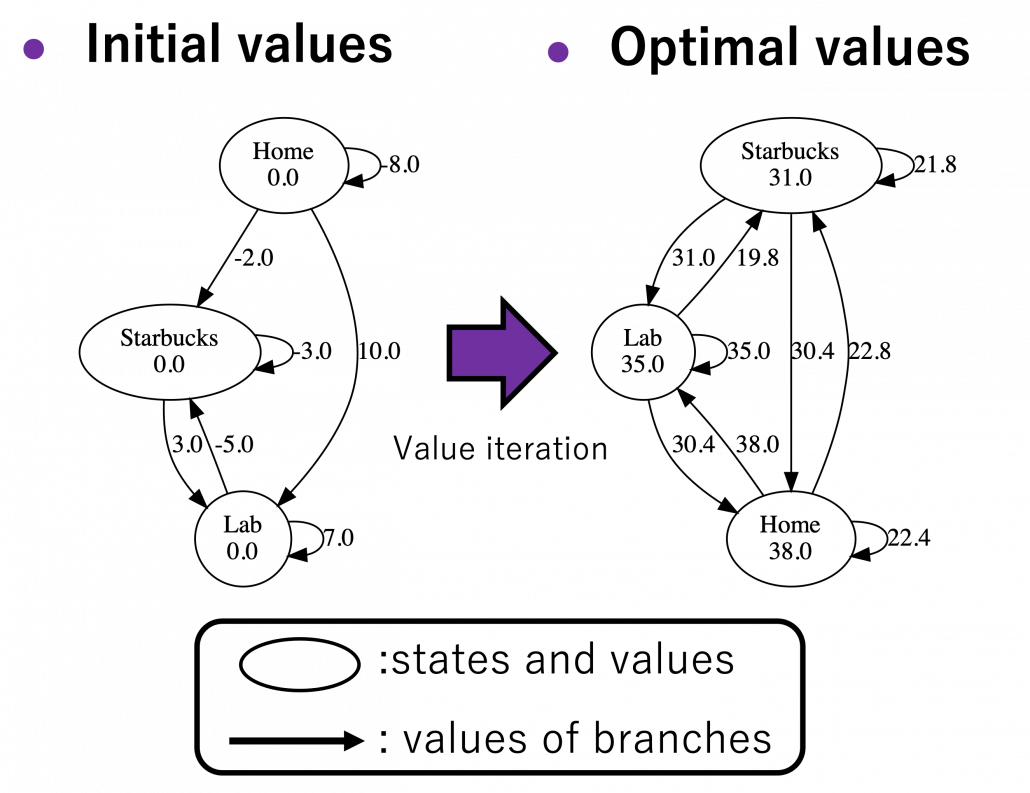

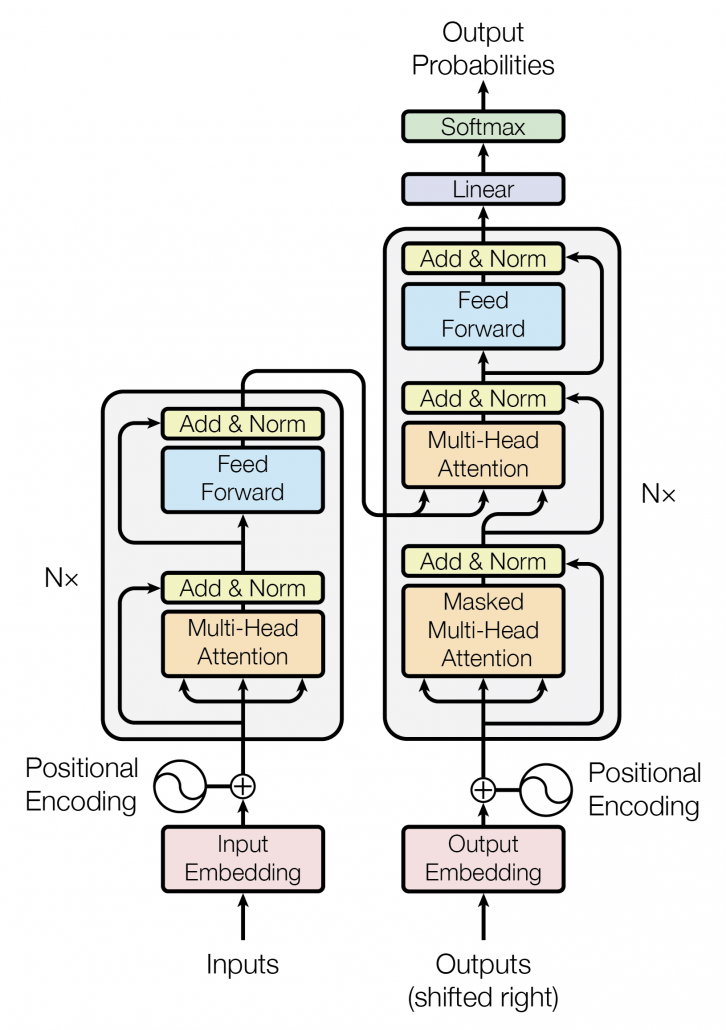
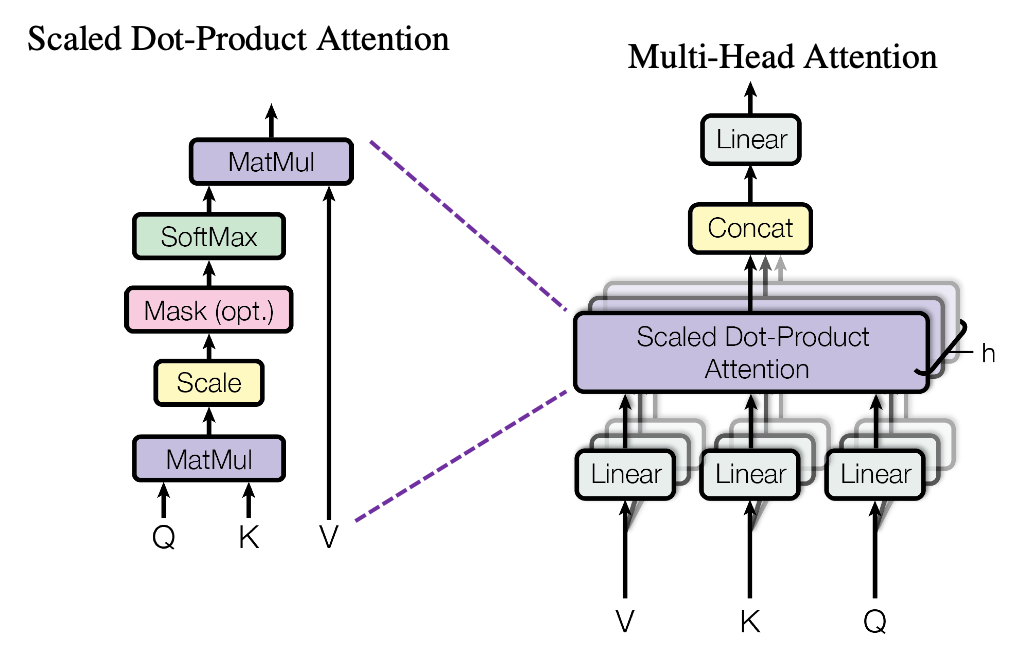
 matrix. You first split each token into
matrix. You first split each token into  dimensional, 8 vectors in total, as I colored in the figure below. In other words, the input matrix is divided into 8 colored chunks, which are all
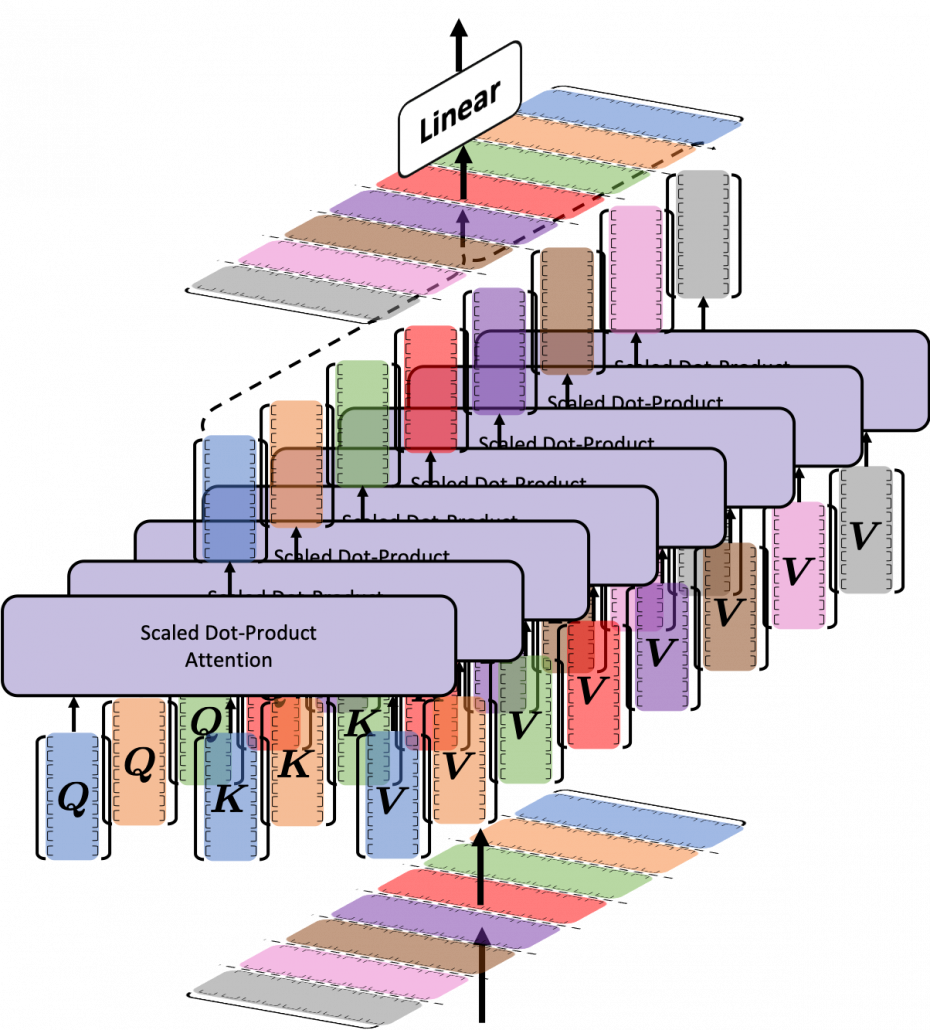
dimensional, 8 vectors in total, as I colored in the figure below. In other words, the input matrix is divided into 8 colored chunks, which are all  matrices, but each colored matrix expresses the same sentence. And you calculate self-attentions of the input sentence independently in the 8 heads, and you reweight the “values” according to the attentions/weights. After this, you stack the sum of the reweighted “values” in each colored head, and you concatenate the stacked tokens of each colored head. The size of each colored chunk does not change even after reweighting the tokens. According to Ashish Vaswani, who invented Transformer model, each head compare “queries” and “keys” on each standard. If the a Transformer model has 4 layers with 8-head multi-head attention , at least its encoder has
matrices, but each colored matrix expresses the same sentence. And you calculate self-attentions of the input sentence independently in the 8 heads, and you reweight the “values” according to the attentions/weights. After this, you stack the sum of the reweighted “values” in each colored head, and you concatenate the stacked tokens of each colored head. The size of each colored chunk does not change even after reweighting the tokens. According to Ashish Vaswani, who invented Transformer model, each head compare “queries” and “keys” on each standard. If the a Transformer model has 4 layers with 8-head multi-head attention , at least its encoder has  heads, so the encoder learn the relations of tokens of the input on 32 different standards.
heads, so the encoder learn the relations of tokens of the input on 32 different standards.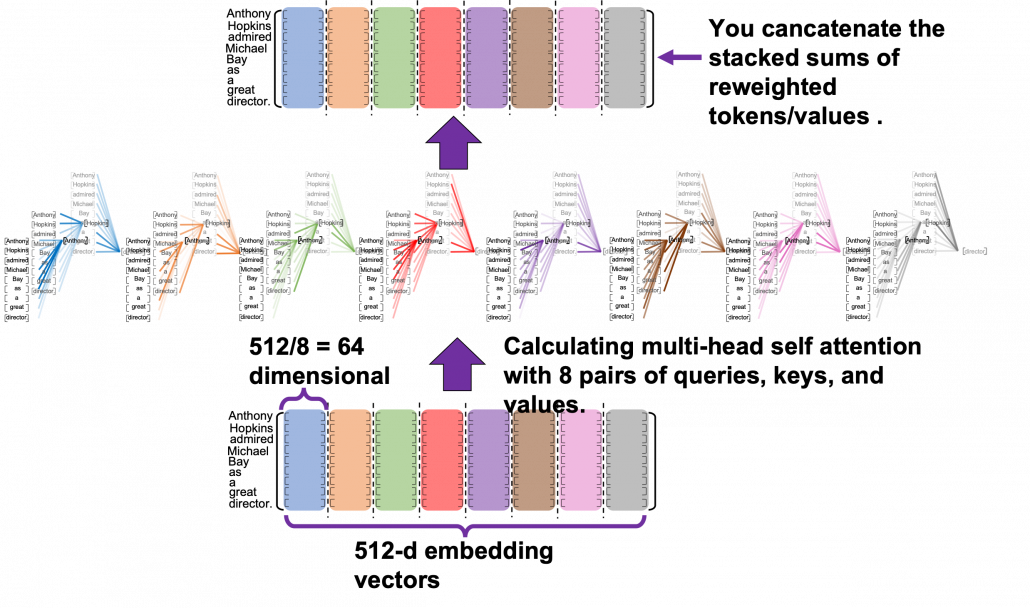
![[ \cdots ]](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-a935a6ae352397cdde28cd5115cc275a_l3.png "Rendered by QuickLaTeX.com") denotes a token, which is usually an embedding vector in practice.
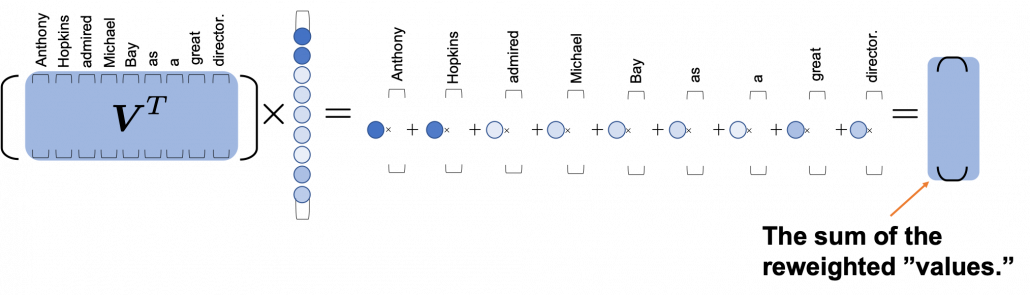
denotes a token, which is usually an embedding vector in practice.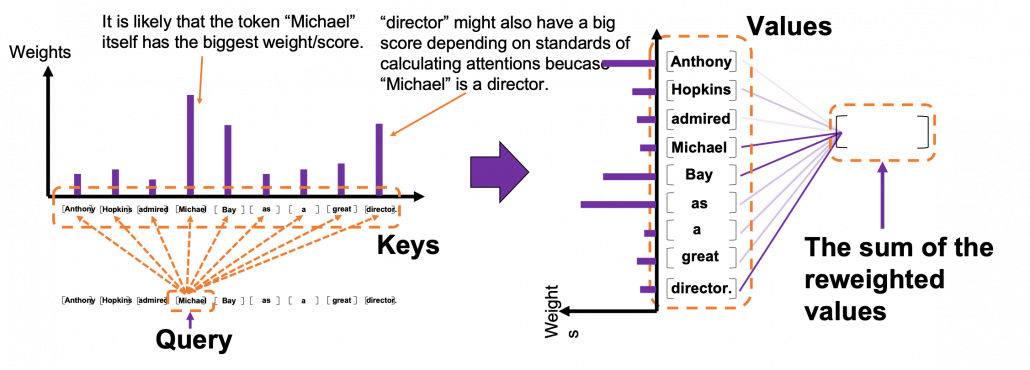 *I have been repeating the phrase “reweighting ‘values’ with attentions,” but you in practice calculate the sum of those reweighted “values.”
*I have been repeating the phrase “reweighting ‘values’ with attentions,” but you in practice calculate the sum of those reweighted “values.”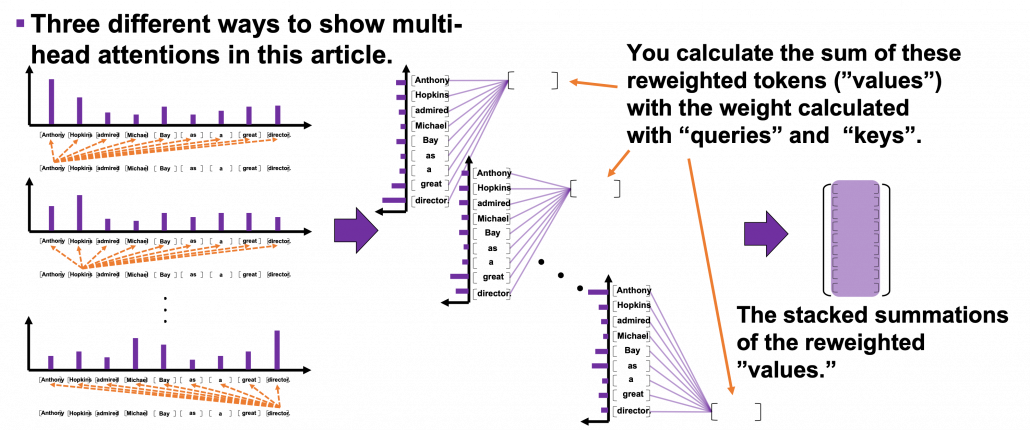

 . Let’s take an example of calculating a scaled dot-product in the blue head.
. Let’s take an example of calculating a scaled dot-product in the blue head. , which are “queries”, “keys”, and “values” respectively.
, which are “queries”, “keys”, and “values” respectively. by
by  in the formula. According to the original paper, it is known that re-scaling
in the formula. According to the original paper, it is known that re-scaling  by
by 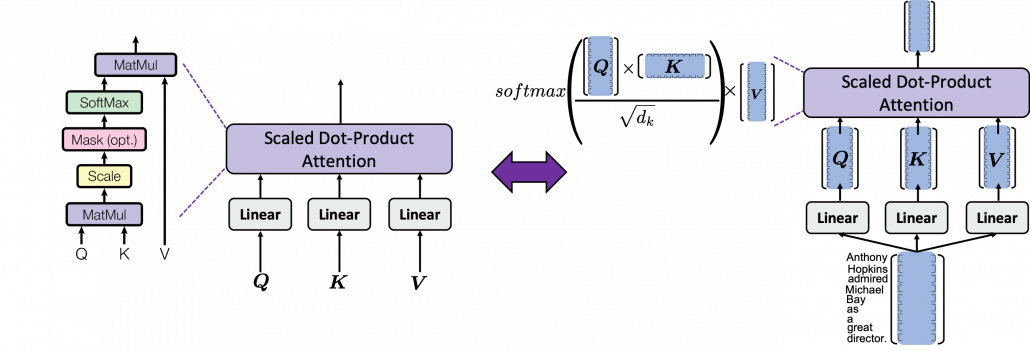
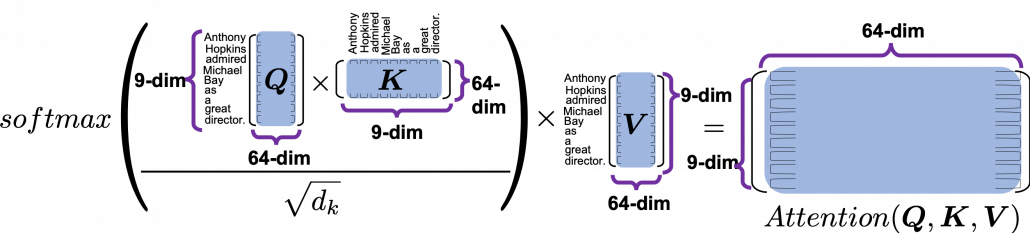
 is calculated like in the figure below. The softmax function regularize each row of the re-scaled product
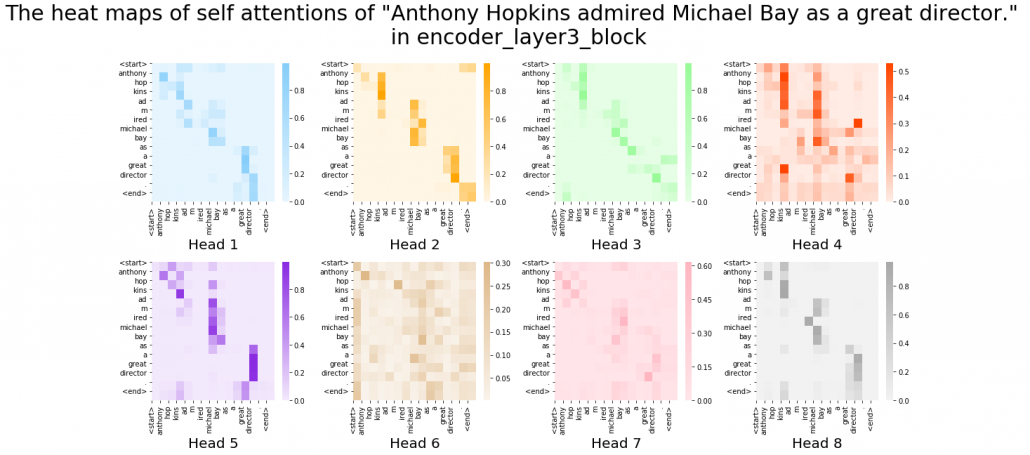
is calculated like in the figure below. The softmax function regularize each row of the re-scaled product  , and the resulting
, and the resulting  matrix is a kind a heat map of self-attentions.
matrix is a kind a heat map of self-attentions.
 and regularizing them with a softmax function, you stack those vectors, and the stacked vectors is the heat map of attentions.
and regularizing them with a softmax function, you stack those vectors, and the stacked vectors is the heat map of attentions.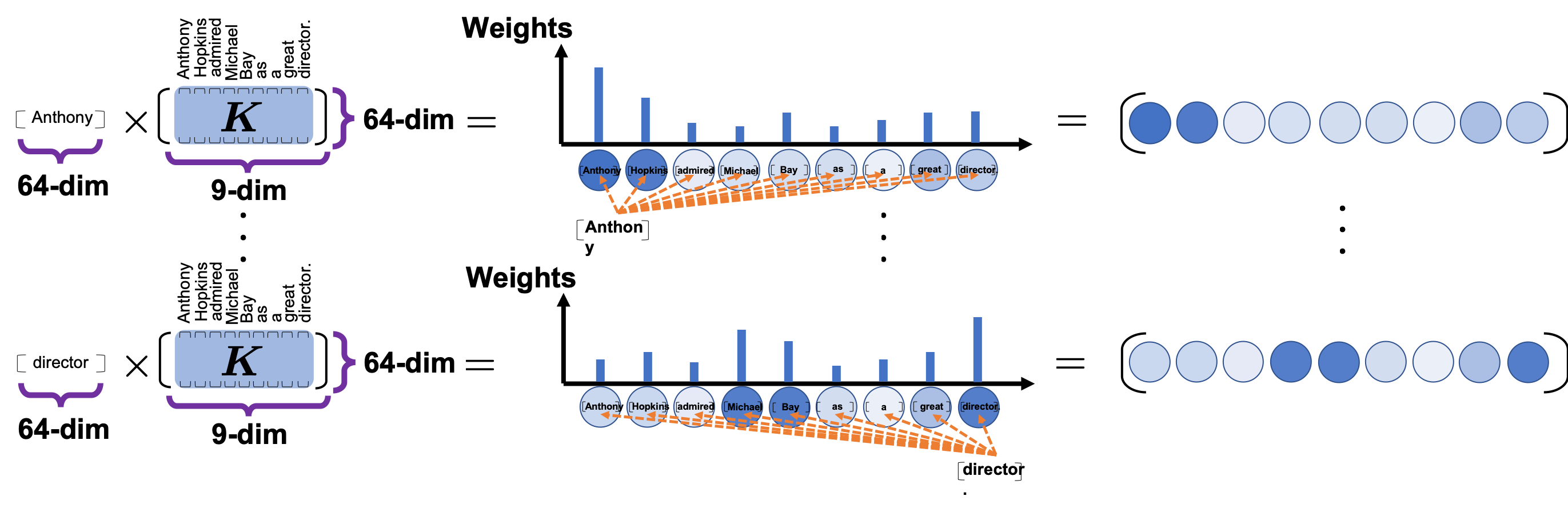
 . This also should be easy to understand if you know basics of linear algebra.
. This also should be easy to understand if you know basics of linear algebra.