Was ist ein Data Lakehouse?
tl;dr
Ein Data Lakehouse ist eine moderne Datenarchitektur, die die Vorteile eines Data Lake und eines Data Warehouse kombiniert. Es kann strukturierte, halbstrukturierte und unstrukturierte Daten in einer Vielzahl von Formaten speichern und verarbeiten und bietet eine flexible und skalierbare Möglichkeit zur Speicherung und Analyse großer Datenmengen. In diesem Artikel werden die Geschichte von Data Lakehouses, ihre Vor- und Nachteile sowie einige der am häufigsten verwendeten Tools für ihre Erstellung erörtert, darunter Apache Spark, Delta Lake, Databricks, Apache Hudi und Apache Iceberg. Organisationen können je nach ihren spezifischen Bedürfnissen und Anforderungen zwischen einem Data Warehouse und einem Data Lakehouse wählen.
Einführung
In der Welt der Daten ist der Begriff Data Lakehouse allgegenwärtig und wird als Lösung für alle Datenanforderungen verkauft. Aber Moment mal, was ist eigentlich ein Data Lakehouse? Der Artikel beginnt mit einer Definition, was ein Lakehouse ist, gibt einen kurzen geschichtlichen Abriss, wie das Lakehouse entstanden ist und zeigt, warum und wie man ein Data Lakehouse aufbauen sollte.
Die Definition eines Data Lakehouse
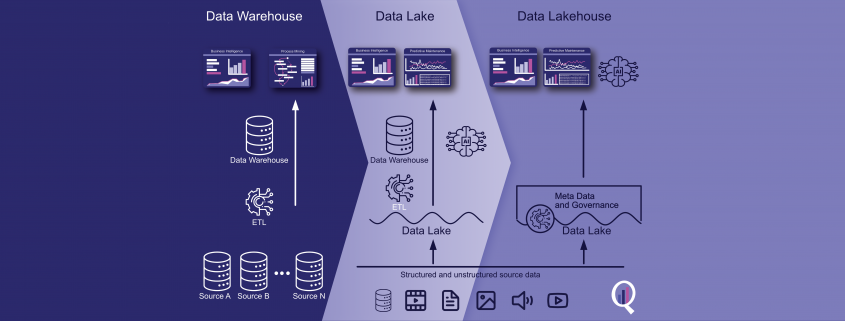
Ein Data Lakehouse ist eine moderne Datenspeicher- und -verarbeitungsarchitektur, die die Vorteile von Data Lakes und Data Warehouses vereint. Es ist darauf ausgelegt, große Mengen an strukturierten, halbstrukturierten und unstrukturierten Daten aus verschiedenen Quellen zu verarbeiten und eine einheitliche Sicht auf die Daten für die Analyse bereitzustellen.
Data Lakehouses werden auf Cloud-basierten Objektspeichern wie Amazon S3, Google Cloud Storage oder Azure Blob Storage aufgebaut. Sie nutzen auch verteilte Computing-Frameworks wie Apache Spark, um skalierbare und effiziente Datenverarbeitungsfunktionen bereitzustellen.
In einem Data Lakehouse werden die Daten in ihrem Rohformat gespeichert, und Transformationen und Datenverarbeitung werden je nach Bedarf durchgeführt. Dies ermöglicht eine flexible und agile Datenexploration und -analyse, ohne dass komplexe Datenaufbereitungs- und Ladeprozesse erforderlich sind. Darüber hinaus können Data Governance- und Sicherheitsrichtlinien auf die Daten in einem Data Lakehouse angewendet werden, um die Datenqualität und die Einhaltung von Vorschriften zu gewährleisten.
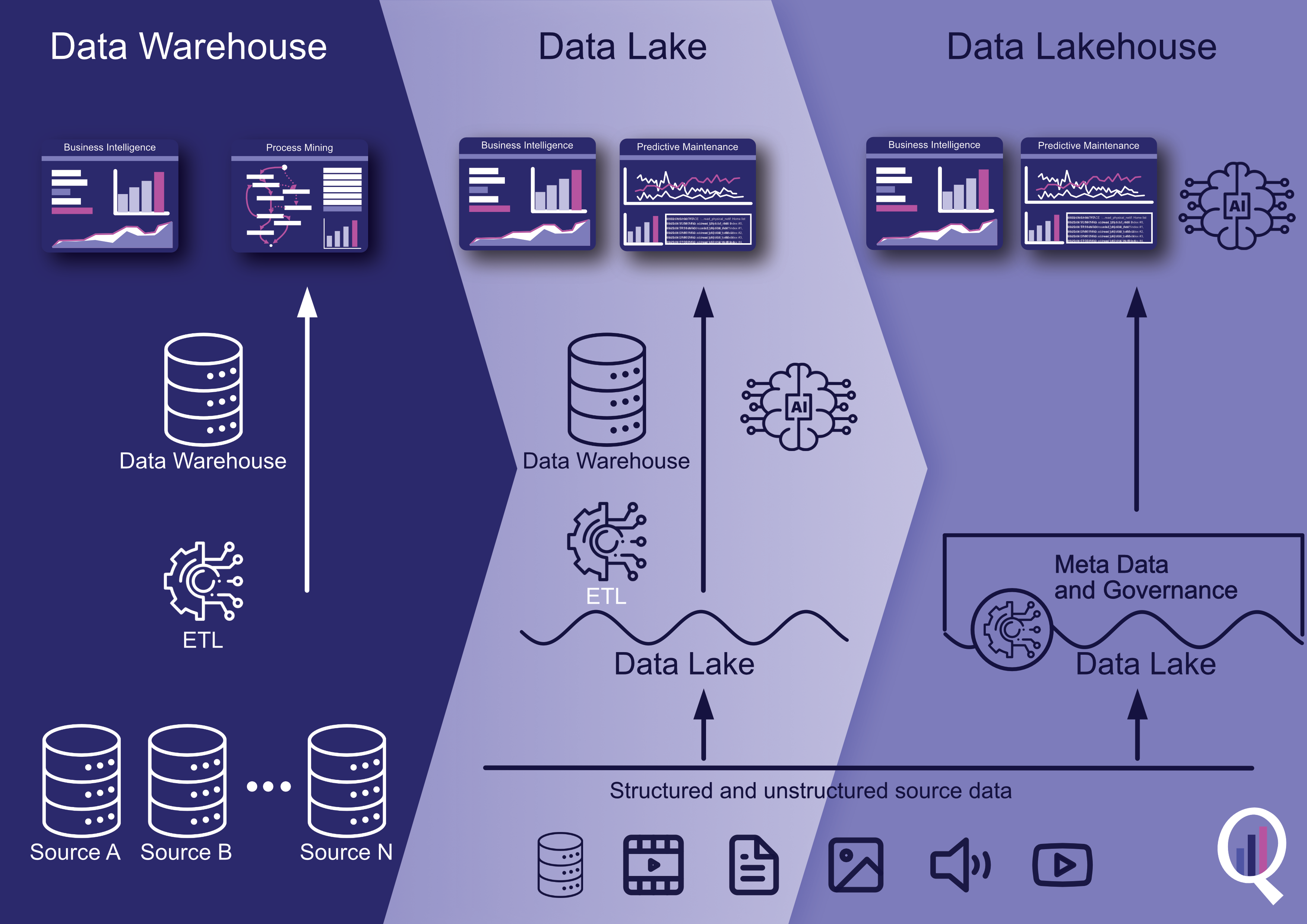
Data Lakehouse Architecture
Eine kurze Geschichte des Data Lakehouse
Das Konzept des Data Lakehouse ist relativ neu und entstand Mitte der 2010er Jahre als Reaktion auf die Einschränkungen des traditionellen Data Warehousing und die wachsende Beliebtheit von Data Lakes.
Data Warehousing ist seit den 1980er Jahren die wichtigste Lösung für die Speicherung und Verarbeitung von Daten für Business Intelligence und Analysen. Data Warehouses wurden entwickelt, um strukturierte Daten aus Transaktionssystemen in einem zentralen Repository zu speichern, wo sie mit SQL-basierten Tools bereinigt, umgewandelt und analysiert werden konnten.
Mit der zunehmenden Datenmenge und -vielfalt wurde die Verwaltung von Data Warehouses jedoch immer schwieriger und teurer. Data Lakes, die Mitte der 2000er Jahre aufkamen, boten einen alternativen Ansatz für die Datenspeicherung und -verarbeitung. Data Lakes wurden entwickelt, um große Mengen an rohen und unstrukturierten Daten auf skalierbare und kostengünstige Weise zu speichern.
Data Lakes boten zwar viele Vorteile, verfügten aber nicht über die Struktur und die Data Governance-Funktionen von Data Warehouses. Dies machte es schwierig, aus den Daten aussagekräftige Erkenntnisse zu gewinnen und die Datenqualität und die Einhaltung von Vorschriften sicherzustellen.
Das Data Lakehouse wurde als Lösung für dieses Problem entwickelt und kombiniert die Vorteile von Data Lakes und Data Warehouses. Bei einem Data Lakehouse werden die Daten in ihrem Rohformat gespeichert, genau wie bei einem Data Lake. Das Data Lakehouse bietet jedoch auch die Struktur und die Governance-Funktionen eines Data Warehouse, was eine einfachere Datenverwaltung und -analyse ermöglicht.
Wann wird ein Data Lakehouse verwendet?
Ein Data Lakehouse kann für eine Vielzahl von Anwendungsfällen der Datenspeicherung und -verarbeitung eingesetzt werden, insbesondere für solche, bei denen große Mengen unterschiedlicher Datentypen aus verschiedenen Quellen anfallen. Einige häufige Anwendungsfälle sind:
- Datenexploration und -erkennung: Ein Data Lakehouse ermöglicht es Benutzern, Rohdaten auf flexible und agile Weise zu untersuchen und zu analysieren, ohne dass komplexe Datenaufbereitungsprozesse erforderlich sind. Dies kann Unternehmen dabei helfen, Muster und Erkenntnisse zu erkennen, die sonst nur schwer zu entdecken wären.
- Erweiterte Analysen und maschinelles Lernen: Data Lakehouses können erweiterte Analysen und maschinelles Lernen unterstützen, indem sie eine einheitliche Sicht auf die Daten bieten, die zum Trainieren von Modellen und zur Erstellung von Vorhersagen verwendet werden kann.
- Datenverarbeitung in Echtzeit: Ein Data Lakehouse kann zum Speichern und Verarbeiten von Echtzeit-Datenströmen von IoT-Geräten, Social-Media-Feeds und anderen Quellen verwendet werden, um Einblicke und Maßnahmen in Echtzeit zu ermöglichen.
- Datenintegration und -verwaltung: Data Lakehouses können Unternehmen dabei helfen, Daten aus verschiedenen Quellen zu integrieren und zu verwalten, um Datenqualität, Konsistenz und Compliance zu gewährleisten.
- Kunde 360: Ein Data Lakehouse kann zur Konsolidierung von Kundendaten aus verschiedenen Quellen wie Transaktionssystemen, sozialen Medien und Kundensupportsystemen verwendet werden, um eine vollständige Sicht auf den Kunden zu erhalten und personalisierte Erfahrungen zu ermöglichen.
Data Lakehouse vs. Data Warehouse
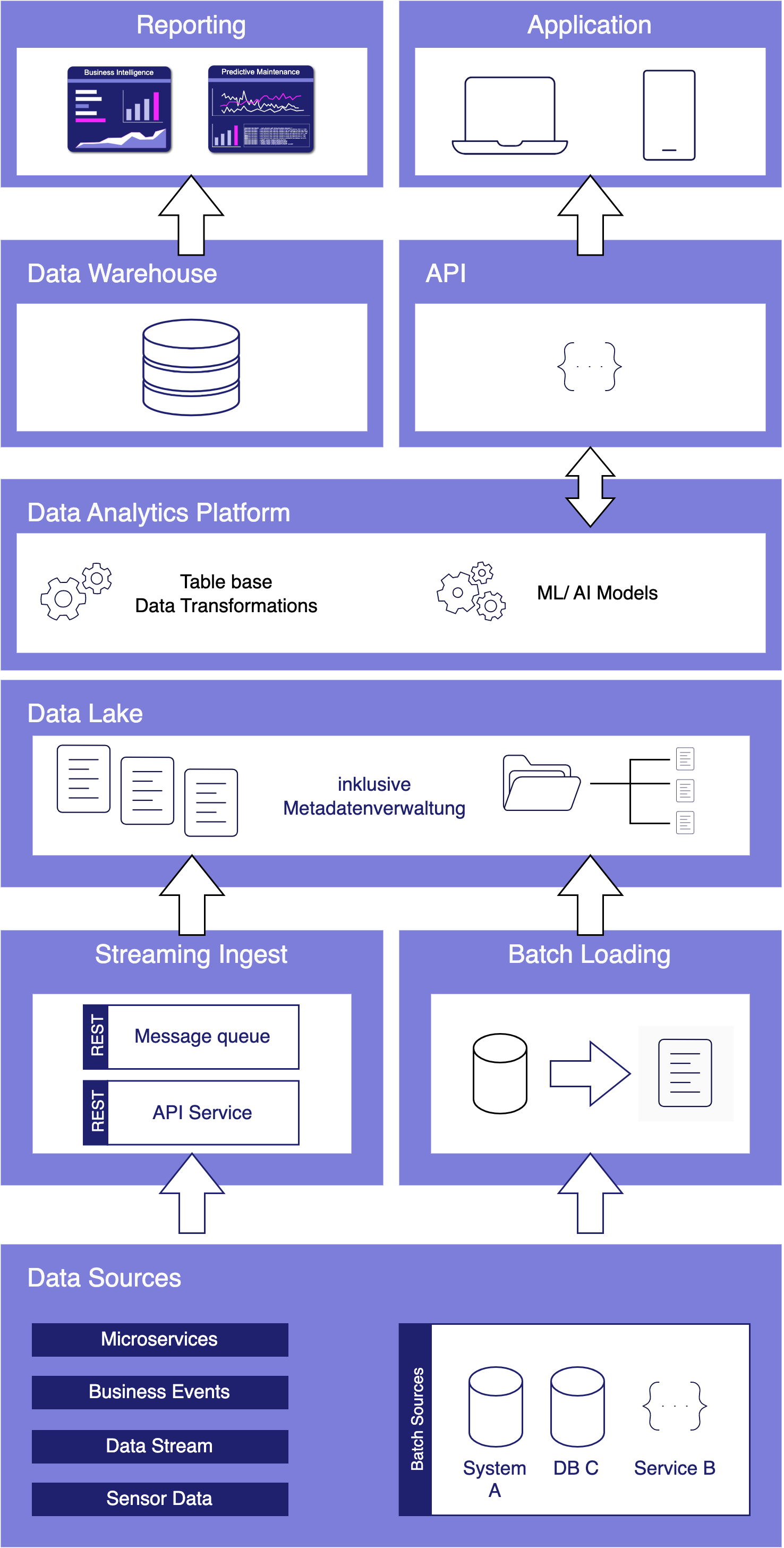
Data Lakehouse Schema
Das Data Lakehouse ist also eine moderne Alternative zu Data Warehouse und Data Lake. Aber wie entscheidet man, ob man ein Data Lakehouse oder ein Data Warehouse einsetzt? Hier sind einige Faktoren, die bei der Bewertung der Verwendung eines Data Lakehouse gegenüber einem Data Warehouse für Ihr Unternehmen zu berücksichtigen sind:
- Datentypen und -quellen: Wenn Ihr Unternehmen strukturierte Daten aus transaktionalen Systemen speichern und analysieren muss, ist ein Data Warehouse möglicherweise die bessere Wahl. Wenn Sie jedoch verschiedene Datentypen und -quellen haben, einschließlich unstrukturierter und halbstrukturierter Daten, ist ein Data Lakehouse die bessere Wahl.
- Anforderungen an die Datenverarbeitung: Wenn Ihr Unternehmen komplexe Abfragen und Aggregationen von Daten durchführen muss, ist ein Data Warehouse möglicherweise die bessere Wahl. Wenn Sie jedoch Ad-hoc-Abfragen und explorative Analysen durchführen müssen, ist ein Data Lakehouse besser geeignet.
- Datenvolumen: Wenn Sie relativ kleine Datenmengen haben, ist ein Data Warehouse möglicherweise die kostengünstigere Wahl. Wenn Sie jedoch große Datenmengen haben, die schnell wachsen, wäre ein Data Lakehouse die bessere Wahl.
- Datenlatenz: Wenn Ihr Unternehmen Daten in Echtzeit verarbeiten und analysieren muss, ist ein Data Lakehouse möglicherweise die bessere Wahl. Wenn Ihre Analyse jedoch eine gewisse Latenzzeit tolerieren kann, könnte ein Data Warehouse die bessere Wahl sein.
- Data Governance und Compliance: Wenn Ihr Unternehmen strenge Anforderungen an die Datenverwaltung und -einhaltung hat, ist ein Data Warehouse möglicherweise die bessere Wahl. Ein Data Lakehouse kann jedoch auch Data Governance und Compliance unterstützen, indem es die Datenabfolge, Zugriffskontrollen und Auditing-Funktionen bereitstellt.
Die Entscheidung für das eine oder das andere hängt hauptsächlich von der Menge und Häufigkeit der zu verarbeitenden Daten ab. Aber auch die Art der Daten (strukturiert oder unstrukturiert) spielt eine wichtige Rolle.
Tools zum Aufbau eines Data Lakehouse
Nachfolgend eine Liste an Tools, die für Data Lakehouses infrage kommen, ohne Anspruch auf Vollständigkeit:
- Apache Spark: Spark ist eine beliebte Open-Source-Datenverarbeitungs-Engine, die für den Aufbau eines Data Lakehouse verwendet werden kann. Spark unterstützt eine Vielzahl von Datenquellen, einschließlich strukturierter, halbstrukturierter und unstrukturierter Daten, und kann sowohl für die Batch- als auch für die Echtzeit-Datenverarbeitung verwendet werden. Spark ist direkt auf mehreren Cloud-Plattformen verfügbar, darunter AWS, Azure und Google Cloud Platform.Apacke Spark ist jedoch mehr als nur ein Tool, es ist die Grundbasis für die meisten anderen Tools. So basieren z. B. Databricks und Azure Synapse auf Apache Spark, vereinfachen den Umgang mit Spark für den Benutzer dabei gleichzeitig sehr.
- Delta Lake: Delta Lake ist eine Open-Source-Speicherschicht, die auf einem Data Lake läuft und Funktionen für die Zuverlässigkeit, Qualität und Leistung von Daten bietet. Delta Lake baut auf Apache Spark auf und ist auf mehreren Cloud-Plattformen verfügbar, darunter AWS, Azure und Google Cloud Platform.
- AWS Lake Formation: AWS Lake Formation ist ein verwalteter Service, der den Prozess der Erstellung, Sicherung und Verwaltung eines Data Lakehouse auf AWS vereinfacht. Lake Formation bietet eine Vielzahl von Funktionen, einschließlich Datenaufnahme, Datenkatalogisierung und Datentransformation, und kann mit einer Vielzahl von Datenquellen verwendet werden.
- Azure Synapse Analytics: Azure Synapse Analytics ist ein verwalteter Analysedienst, der eine einheitliche Erfahrung für Big Data und Data Warehousing bietet. Synapse Analytics umfasst eine Data Lakehouse-Funktion, die das Beste aus Data Lakes und Data Warehouses kombiniert, um eine flexible und skalierbare Lösung für die Speicherung und Verarbeitung von Daten zu bieten.
- Google Cloud Data Fusion: Google Cloud Data Fusion ist ein vollständig verwalteter Datenintegrationsdienst, der zum Aufbau eines Data Lakehouse auf der Google Cloud Platform verwendet werden kann. Data Fusion bietet eine Vielzahl von Funktionen zur Datenaufnahme, -umwandlung und -verarbeitung und kann mit einer Vielzahl von Datenquellen verwendet werden.
- Databricks: Databricks ist eine Cloud-basierte Datenverarbeitungs- und Analyseplattform, die auf Apache Spark aufbaut. Sie bietet einen einheitlichen Arbeitsbereich für Data Engineering, Data Science und maschinelles Lernen, der zum Aufbau und Betrieb eines Data Lakehouse verwendet werden kann. Databricks ist auf AWS, Azure und Google Cloud Platform verfügbar.
- Apache Hudi: Apache Hudi ist ein Open-Source-Datenmanagement-Framework, das eine effiziente und skalierbare Datenaufnahme, -speicherung und -verarbeitung ermöglicht. Hudi bietet Funktionen wie inkrementelle Verarbeitung, Upserts und Deletes sowie Datenversionierung, um die Datenqualität in einem Data Lakehouse zu erhalten. Apache Hudi ist auf AWS, Azure und Google Cloud Platform verfügbar.
- Apache Iceberg: Apache Iceberg ist ein Open-Source-Tabellenformat, das schnelle und effiziente Datenabfragen ermöglicht und gleichzeitig transaktionale und konsistente Ansichten von Daten in einem Data Lakehouse bietet. Es ist so konzipiert, dass es mit einer Vielzahl von Speichersystemen wie dem Hadoop Distributed File System (HDFS), Amazon S3 und Azure Blob Storage zusammenarbeitet. Apache Iceberg ist auf AWS, Azure und Google Cloud Platform verfügbar.
Alle diese Tools haben sich aufgrund ihrer Benutzerfreundlichkeit, Skalierbarkeit und Unterstützung für eine Vielzahl von Datenverarbeitungs- und Analyseanwendungen für den Aufbau von Data Lakehouses durchgesetzt. Die Wahl des Tools hängt von Ihren spezifischen Anforderungen ab, und es ist wichtig, jedes Tool sorgfältig zu bewerten, um festzustellen, welches den Anforderungen Ihres Unternehmens am besten entspricht.
Fazit
In diesem Artikel haben wir das Konzept des Data Lakehouse, seine Geschichte sowie seine Vor- und Nachteile erläutert. Wir haben auch über einige der gängigsten Tools gesprochen, die zum Aufbau eines Data Lakehouse verwendet werden, darunter Apache Spark, Apache Delta Lake, Databricks, Apache Hudi und Apache Iceberg.
Wir haben erörtert, wie Unternehmen zwischen einem Data Warehouse und einem Data Lakehouse wählen können und welche Faktoren bei dieser Entscheidung zu berücksichtigen sind. Zusammenfassend lässt sich sagen, dass es Vor- und Nachteile gibt, die zu berücksichtigen sind und mit den eigenen Anforderungen verglichen werden sollten.
Zusammengefasst bietet ein Data Lakehouse folgende Vor- und Nachteile:
Vorteile eines Data Lakehouse:
- Flexibilität: Ein Data Lakehouse bietet eine flexible Datenarchitektur, die strukturierte, halbstrukturierte und unstrukturierte Daten in einer Vielzahl von Formaten speichern und verarbeiten kann, einschließlich Data Lakes und Data Warehouses.
- Skalierbarkeit: Ein Data Lakehouse kann skaliert werden, um die Anforderungen großer und komplexer Datenverarbeitungs- und Analyse-Workloads zu erfüllen.
- Kosteneffektiv: Ein Data Lakehouse kann zur Kostensenkung beitragen, indem es den Bedarf an mehreren Datensilos beseitigt und die Datenduplizierung reduziert.
- Verarbeitung in Echtzeit: Ein Data Lakehouse kann für die Datenverarbeitung in Echtzeit genutzt werden, so dass Unternehmen datengesteuerte Entscheidungen in Echtzeit treffen können.
- Datenverwaltung: Ein Data Lakehouse kann zur Verbesserung der Data Governance beitragen, indem es ein zentrales Repository für alle Daten bereitstellt und eine fein abgestufte Zugriffskontrolle ermöglicht.
Nachteile, die vor der Entscheidung für ein Data Lakehouse zu berücksichtigen sind:
- Komplexität: Der Aufbau eines Data Lakehouse kann komplex sein und erfordert ein tiefes Verständnis von Datenmanagement- und -verarbeitungstechnologien.
- Datenqualität: Die Datenqualität kann in einem Data Lakehouse aufgrund der Vielfalt der Datenquellen und der fehlenden Struktur eine Herausforderung darstellen.
- Sicherheit: Die Sicherheit kann in einem Data Lakehouse ein Problem darstellen, da es oft notwendig ist, den Zugriff auf große Datenmengen zu verwalten, die an verschiedenen Orten gespeichert sind.
- Qualifikationen: Der Aufbau und die Pflege eines Data Lakehouse erfordern ein spezifisches Skillset, das sich von dem des traditionellen Data Warehousing oder der Big Data-Verarbeitung unterscheiden kann.
- Werkzeuge: Es gibt zwar viele Tools für den Aufbau eines Data Lakehouse, aber angesichts des rasanten Innovationstempos kann es eine Herausforderung sein, mit den neuesten Tools und Technologien Schritt zu halten.
Abschließend lässt sich sagen, dass ein Data Lakehouse für Unternehmen, die eine flexible, skalierbare und kosteneffiziente Methode zur Speicherung und Verarbeitung großer Datenmengen benötigen, erhebliche Vorteile bieten. Auch wenn der Aufbau eines Data Lakehouse grundsätzlich komplexer ist, gibt es viele Tools und Technologien, die Unternehmen beim Aufbau und Betrieb einer erfolgreichen Data Lakehouse-Architektur unterstützen und dieses vereinfachen.
Haben Sie bereits ein Data Lakehouse im Einsatz oder überlegen Sie, eines für Ihr Unternehmen zu bauen? Schreiben Sie mich an!








 scientists, which will involve more sophisticated analysis, predictive modeling, regressions and Bayesian classification. That stuff at scale doesn’t work well on anyone’s engine right now. If you want to do complex analytics on big data, you have a big problem right now.”
scientists, which will involve more sophisticated analysis, predictive modeling, regressions and Bayesian classification. That stuff at scale doesn’t work well on anyone’s engine right now. If you want to do complex analytics on big data, you have a big problem right now.”