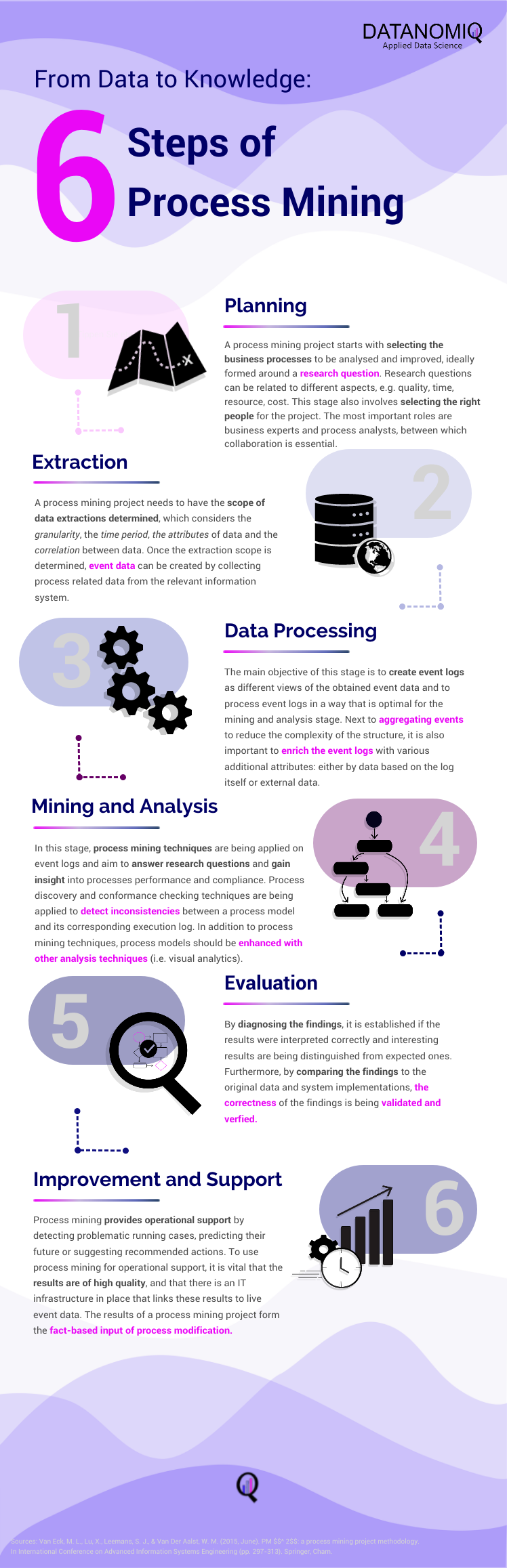
Zertifikatsstudium – Data Science & Big Data
Anzeige
Datenanalyse, Datenmanagement und die zielgerichtete Darstellung der Ergebnisse – darum geht es im berufsbegleitenden Zertifikatsstudium ‚Data Science & Big Data‘ der TU Dortmund.
Datenanalyse, Datenmanagement und die zielgerichtete Darstellung der Ergebnisse – darum geht es im berufsbegleitenden Zertifikatsstudium ‚Data Science & Big Data‘ der TU Dortmund.
Der Kurs richtet sich an alle Berufsgruppen, die sich mit dem Management und der Analyse von Daten beschäftigen, wie z. B. Data Scientists, Business Analysten, Softwareentwickler, Consultants, wissenschaftliche Mitarbeitende (universitär oder außeruniversitär) o.ä.
Ziel ist der Erwerb moderner Kenntnisse in Theorie und Praxis von Data Science- und Big Data-Projekten. Die Übungen mit realen Datensätzen sowie die Option, die Abschlussarbeit auf Basis von eigenen Daten (‚bring your own data‘) zu verfassen, unterstützen den Transfer des Gelernten in die berufliche Praxis. Das Zertifikatsstudium umfasst zehn Termine und dauert neun Monate. Nach erfolgreicher Abschlussprüfung vergibt die Technische Universität Dortmund ein Zertifikat, mit dem der Kompetenzausbau nachgewiesen werden kann.
Näheres finden Sie unter: https://wb.zhb.tu-dortmund.de/datascience
Bei frühzeitiger Anmeldung oder wenn mehrere Personen aus Ihrem Unternehmen am Kurs teilnehmen, profitieren Sie zudem von unseren Rabattangeboten:
- Early Bird: Sie erhalten 5% Preisnachlass auf das Teilnahmeentgelt bei Anmeldung bis zum 30. September 2022.
- Weitersagen lohnt sich: Wenn Sie gemeinsam mit einer/einem Kollegin/Kollegen oder mehreren Personen aus Ihrem Unternehmen am Kurs teilnehmen, reduziert sich das Teilnahmeentgelt bei bis zu zwei angemeldeten Personen um 5 % pro Person, darüber hinausgehend zahlt jede weitere Person 10 % weniger.
Bei Fragen können Sie sich an Daniel Neubauer (daniel.neubauer@tu-dortmund.de; 0231 755 6632) wenden.