Unsupervised Learning in R: K-Means Clustering
Die Clusteranalyse ist ein gruppenbildendes Verfahren, mit dem Objekte Gruppen – sogenannten Clustern zuordnet werden. Die dem Cluster zugeordneten Objekte sollen möglichst homogen sein, wohingegen die Objekte, die unterschiedlichen Clustern zugeordnet werden möglichst heterogen sein sollen. Dieses Verfahren wird z.B. im Marketing bei der Zielgruppensegmentierung, um Angebote entsprechend anzupassen oder im User Experience Bereich zur Identifikation sog. Personas.
Es gibt in der Praxis eine Vielzahl von Cluster-Verfahren, eine der bekanntesten und gebräuchlichsten Verfahren ist das K-Means Clustering, ein sog. Partitionierendes Clusterverfahren. Das Ziel dabei ist es, den Datensatz in K Cluster zu unterteilen. Dabei werden zunächst K beliebige Punkte als Anfangszentren (sog. Zentroiden) ausgewählt und jedem dieser Punkte der Punkt zugeordnet, zu dessen Zentrum er die geringste Distanz hat. K-Means ist ein „harter“ Clusteralgorithmus, d.h. jede Beobachtung wird genau einem Cluster zugeordnet. Zur Berechnung existieren verschiedene Distanzmaße. Das gebräuchlichste Distanzmaß ist die quadrierte euklidische Distanz:

Nachdem jede Beobachtung einem Cluster zugeordnet wurde, wird das Clusterzentrum neu berechnet und die Punkte werden den neuen Clusterzentren erneut zugeordnet. Dieser Vorgang wird so lange durchgeführt bis die Clusterzentren stabil sind oder eine vorher bestimmte Anzahl an Iterationen durchlaufen sind.
Das komplette Vorgehen wird im Folgenden anhand eines künstlich erzeugten Testdatensatzes erläutert.
|
1 2 3 4 |
set.seed(123) Alter <- c(24, 22, 28, 25, 41, 39, 35, 40, 62, 57, 60, 55) Einkommen <- c(20000, 22000, 25000, 24000, 55000, 65000, 75000, 60000, 30000, 34000, 30000, 34000) Daten <- as.data.frame(cbind(Alter, Einkommen)) |
Zunächst wird ein Testdatensatz mit den Variablen „Alter“ und „Einkommen“ erzeugt, der 12 Fälle enthält. Als Schritt des „Data preprocessing“ müssen zunächst beide Variablen standardisiert werden, da ansonsten die Variable „Alter“ die Clusterbildung zu stark beeinflusst.
|
1 2 |
Daten$Alter <- scale(Daten$Alter) Daten$Einkommen <- scale(Daten$Einkommen) |
Das Ganze geplottet:
|
1 2 3 4 5 |
plot(Daten$Alter, Daten$Einkommen, col = "blue", pch = 19, xlab = "Alter (scaled)", ylab = "Einkommen (scaled)", main = "Alter vs. Einkommen (scaled)") |
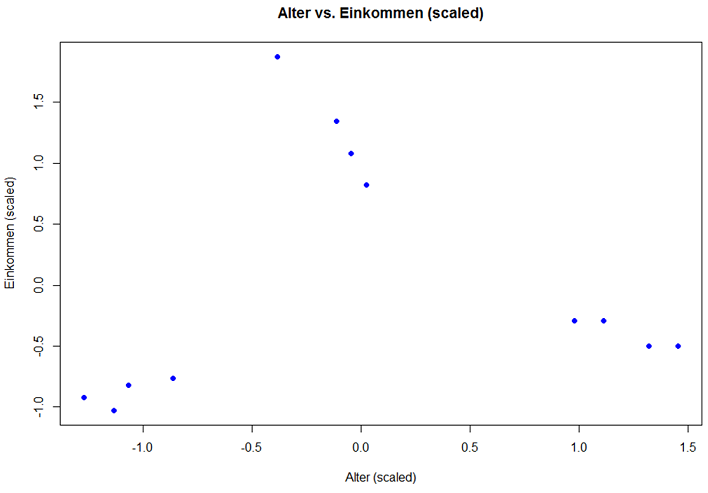
Wie bereits eingangs erwähnt müssen Cluster innerhalb möglichst homogen und zu Objekten anderer Cluster möglichst heterogen sein. Ein Maß für die Homogenität die „Within Cluster Sums of Squares“ (WSS), ein Maß für die Heterogenität „Between Cluster Sums of Squares“ (BSS).
Diese sind beispielsweise für eine 3-Cluster-Lösung wie folgt:
|
1 2 3 4 5 6 7 8 |
KmeansObj <- kmeans(Daten, 3, nstart = 20) KmeansObj$withinss # Within Cluster Sums of Squares (WSS) KmeansObj$totss # Between Cluster Sums of Suqares (BSS) > KmeansObj$withinss # Within Cluster Sums of Squares (WSS) [1] 0.7056937 0.1281607 0.1792432 > KmeansObj$totss # Between Cluster Sums of Suqares (BSS) [1] 22 |
Sollte man die Anzahl der Cluster nicht bereits kennen oder sind diese extern nicht vorgegeben, dann bietet es sich an, anhand des Verhältnisses von WSS und BSS die „optimale“ Clusteranzahl zu berechnen. Dafür wird zunächst ein leerer Vektor initialisiert, dessen Werte nachfolgend über die Schleife mit dem Verhältnis von WSS und WSS gefüllt werden. Dies lässt sich anschließend per „Screeplot“ visualisieren.
|
1 2 3 4 5 6 7 8 9 10 11 |
ratio <- vector() for (k in 1:6) { KMeansObj <- kmeans(Daten, k, nstart = 20) ratio[k] <- KMeansObj$tot.withinss / KMeansObj$totss } plot(ratio, type = "b", xlab = "Anzahl der Cluster", ylab = "Ratio WSS/BSS", main = "Screeplot für verschiedene Clusterlösungen", col = "blue", pch = 19) |
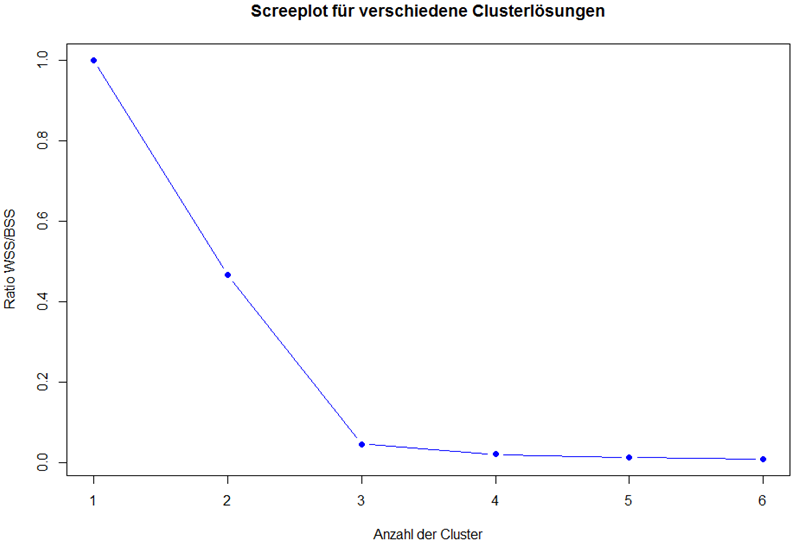
Die „optimale“ Anzahl der Cluster zählt sich am Knick der Linie ablesen (auch Ellbow-Kriterium genannt). Alternativ kann man sich an dem Richtwert von 0.2 orientieren. Unterschreitet das Verhältnis von WSS und BSS diesen Wert, so hat man die beste Lösung gefunden. In diesem Beispiel ist sehr deutlich, dass eine 3-Cluster-Lösung am besten ist.
|
1 2 3 4 5 6 |
KmeansObj <- kmeans(Daten, centers = 3, nstart = 20) plot(Daten$Alter, Daten$Einkommen, col = KmeansObj$cluster, pch = 19, cex = 4, xlab = "Alter (scaled)", ylab = "Einkommen (scaled)", main = "3-Cluster-Lösung") points(KmeansObj$centers, col = 1:3, pch = 3, cex = 5, lwd = 5) |
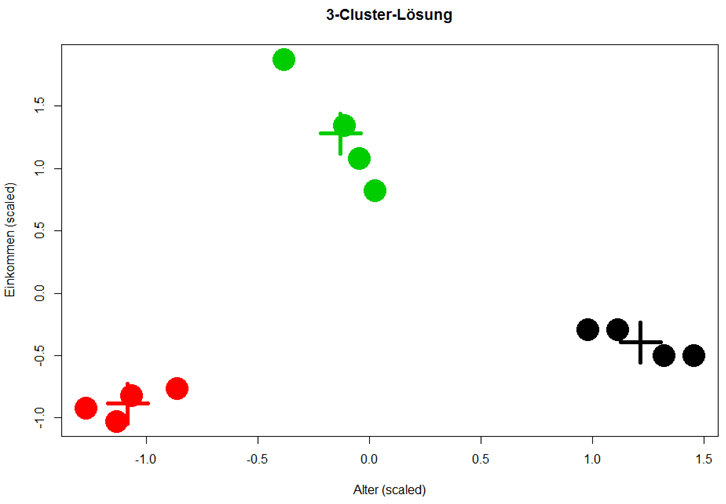
Fazit: Mit K-Means Clustering lassen sich schnell und einfach Muster in Datensätzen erkennen, die, gerade wenn mehr als zwei Variablen geclustert werden, sonst verborgen blieben. K-Means ist allerdings anfällig gegenüber Ausreißern, da Ausreißer gerne als separate Cluster betrachtet werden. Ebenfalls problematisch sind Cluster, deren Struktur nicht kugelförmig ist. Dies ist vor der Durchführung der Clusteranalyse mittels explorativer Datenanalyse zu überprüfen.

 Jurek Dörner @ DATANOMIQ
Jurek Dörner @ DATANOMIQ





Leave a Reply
Want to join the discussion?Feel free to contribute!