Buzzword Bingo: Data Science – Teil II
Im ersten Teil unserer Serie „Buzzword Bingo: Data Science“ widmeten wir uns den Begriffen Künstliche Intelligenz, Algorithmen und Maschinelles Lernen. Nun geht es hier im zweiten Teil weiter mit der Begriffsklärung dreier weiterer Begriffe aus dem Data Science-Umfeld.
Buzzword Bingo: Data Science – Teil II: Big Data, Predictive Analytics & Internet of Things
Im zweiten Teil unserer dreiteiligen Reihe „Buzzword Bingo Data Science“ beschäftigen wir uns mit den Begriffen „Big Data“, „Predictive Analytics“ und „Internet of Things“.
Big Data
Interaktionen auf Internetseiten und in Webshops, Likes, Shares und Kommentare in Social Media, Nutzungsdaten aus Streamingdiensten wie Netflix und Spotify, von mobilen Endgeräten wie Smartphones oder Fitnesstrackern aufgezeichnete Bewegungsdate oder Zahlungsaktivitäten mit der Kreditkarte: Wir alle produzieren in unserem Leben alltäglich immense Datenmengen.
Im Zusammenhang mit künstlicher Intelligenz wird dabei häufig von „Big Data“ gesprochen. Und weil es in der öffentlichen Diskussion um Daten häufig um personenbezogene Daten geht, ist der Begriff Big Data oft eher negativ konnotiert. Dabei ist Big Data eigentlich ein völlig wertfreier Begriff. Im Wesentlichen müssen drei Faktoren erfüllt werden, damit Daten als „big“ gelten. Da die drei Fachbegriffe im Englischen alle mit einem „V“ beginnen, wird häufig auch von den drei V der Big Data gesprochen.
Doch welche Eigenschaften sind dies?
- Volume (Datenmenge): Unter Big Data werden Daten(-mengen) verstanden, die zu groß sind, um sie mit klassischen Methoden zu bearbeiten, weil beispielsweise ein einzelner Computer nicht in der Läge wäre, diese Datenmenge zu verarbeiten.
- Velocity (Geschwindigkeit der Datenerfassung und -verarbeitung): Unter Big Data werden Daten(-mengen) verstanden, die in einer sehr hohen Geschwindigkeit generiert werden und dementsprechend auch in einer hohen Geschwindigkeit ausgewertet und weiterverarbeitet werden müssen, um Aktualität zu gewährleisten.
- Variety (Datenkomplexität oder Datenvielfalt): Unter Big Data werden Daten(-mengen) verstanden, die so komplex sind, dass auf den ersten Blick keine Zusammenhänge erkennbar sind. Diese Zusammenhänge können erst mit speziellen maschinellen Lernverfahren aufgedeckt werden. Dazu gehört auch, dass ein Großteil aller Daten in unstrukturierten Formaten wie Texten, Bildern oder Videos abgespeichert ist.
Häufig werden neben diesen drei V auch weitere Faktoren aufgezählt, welche Big Data definieren. Dazu gehören Variability (Schwankungen, d.h. die Bedeutung von Daten kann sich verändern), Veracity (Wahrhaftigkeit, d.h. Big Data muss gründlich auf die Korrektheit der Daten geprüft werden), Visualization (Visualisierungen helfen, um komplexe Zusammenhänge in großen Datensets aufzudecken) und Value (Wert, d.h. die Auswertung von Big Data sollte immer mit einem unternehmerischen Vorteil einhergehen).
Predictive Analytics
- Heute schon die Verkaufszahlen von morgen kennen, sodass eine rechtzeitige Nachbestellung knapper Produkte möglich ist?
- Bereits am Donnerstagabend die Regenwahrscheinlichkeit für das kommende Wochenende kennen, sodass passende Kleidung für den Kurztrip gepackt werden kann?
- Frühzeitig vor bevorstehenden Maschinenausfällen gewarnt werden, sodass die passenden Ersatzteile bestellt und das benötigte technische Personal angefragt werden kann?
Als Königsdisziplin der Data Science gilt für viele die genaue Vorhersage zukünftiger Zustände oder Ereignisse. Im Englischen wird dann von „Predictive Analytics“ gesprochen. Diese Methoden werden in vielen verschiedenen Branchen und Anwendungsfeldern genutzt. Die Prognose von Absatzzahlen, die Wettervorhersage oder Predictive Maintenance (engl. für vorausschauende Wartung) von Maschinen und Anlagen sind nur drei mögliche Beispiele.
Zu beachten ist allerdings, dass Predictive-Analytics-Modelle keine Wahrsagerei sind. Die Vorhersage zukünftiger Ereignisse beruht immer auf historischen Daten. Das bedeutet, dass maschinelle Modelle mit Methoden des überwachten maschinellen Lernens darauf trainiert werden, Zusammenhänge zwischen vielen verschiedenen Eingangseigenschaften und einer vorherzusagenden Ausgangseigenschaft zu erkennen. Im Falle der Predicitve Maintenance könnten solche Eingangseigenschaften beispielsweise das Alter einer Produktionsmaschine, der Zeitraum seit der letzten Wartung, die Umgebungstemperatur, die Produktionsgeschwindigkeit und viele weitere sein. In den historischen Daten könnte ein Algorithmus nun untersuchen, ob diese Eingangseigenschaften einen Zusammenhang damit aufweisen, ob die Maschine innerhalb der kommenden 7 Tage ausfallen wird. Hierfür muss zunächst eine ausreichend große Menge an Daten zur Verfügung stehen. Wenn ein vorherzusagendes Ereignis in der Vergangenheit nur sehr selten aufgetreten ist, dann stehen auch nur wenige Daten zur Verfügung, um dasselbe Ereignis für die Zukunft vorherzusagen. Sobald der Algorithmus einen entsprechenden Zusammenhang identifiziert hat, kann dieses trainierte maschinelle Modell nun verwendet werden, um zukünftige Maschinenausfälle rechtzeitig vorherzusagen.
Natürlich müssen solche Modelle dauerhaft darauf geprüft werden, ob sie die Realität immer noch so gut abbilden, wie zu dem Zeitpunkt, zu dem sie trainiert worden sind. Wenn sich nämlich die Umweltparameter ändern, das heißt, wenn Faktoren auftreten, die zum Trainingszeitpunkt noch nicht bekannt waren, dann muss auch das maschinelle Modell neu trainiert werden. Für unser Beispiel könnte dies bedeuten, dass wenn die Maschine für die Produktion eines neuen Produktes eingesetzt wird, auch für dieses neue Produkt zunächst geprüft werden müsste, ob die in der Vergangenheit gefundenen Zusammenhänge immer noch Bestand haben.
Internet of Things
Selbstfahrende Autos, smarte Kühlschränke, Heizungssysteme und Glühbirnen, Fitnesstracker und vieles mehr: das Buzzword „Internet of Things“ (häufig als IoT abgekürzt) beschreibt den Trend, nicht nur Computer über Netzwerke miteinander zu verbinden, sondern auch verschiedene alltägliche Objekte mit in diese Netzwerke aufzunehmen. Seinen Anfang genommen hat dieser Trend in erster Linie im Bereich der Unterhaltungselektronik. In vielen Haushalten sind schon seit Jahren Fernseher, Computer, Spielekonsole und Drucker über das Heimnetzwerk miteinander verbunden und lassen sich per Smartphone bedienen.
Damit ist das IoT natürlich eng verbunden mit Big Data, denn all diese Geräte produzieren nicht nur ständig Daten, sondern sie sind auch auf Informationen sowie auf Daten von anderen Geräten angewiesen, um zu funktionieren.
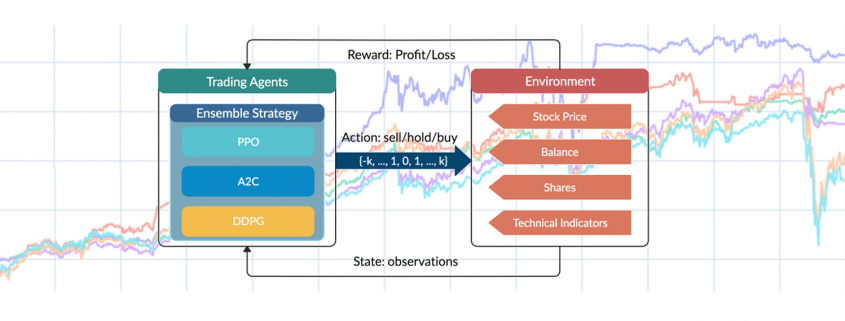
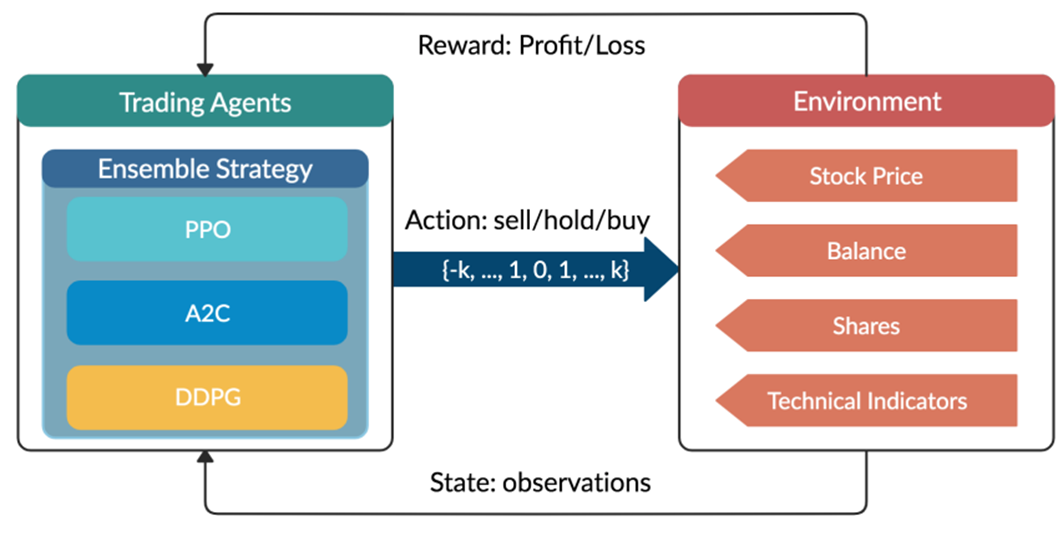
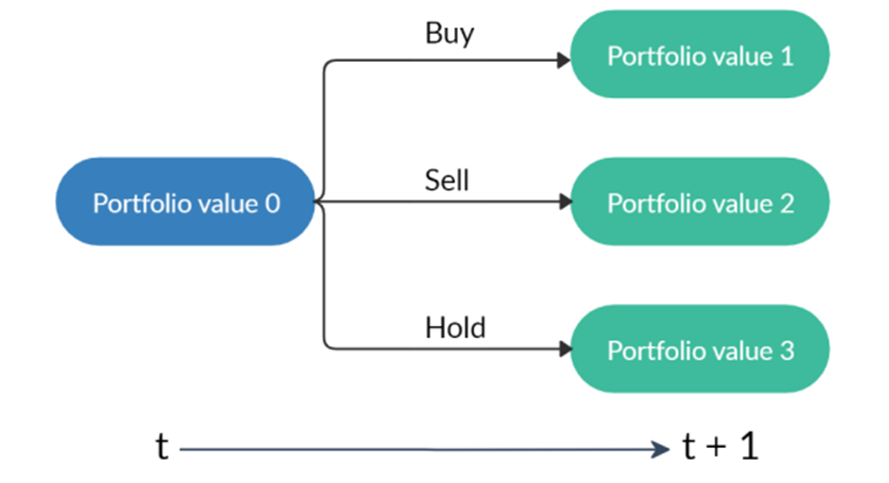
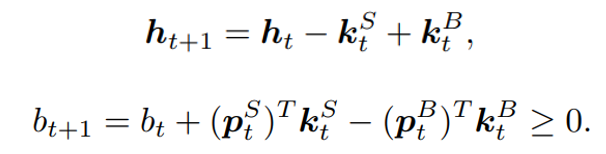
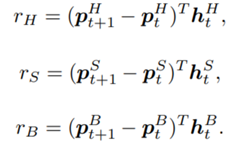
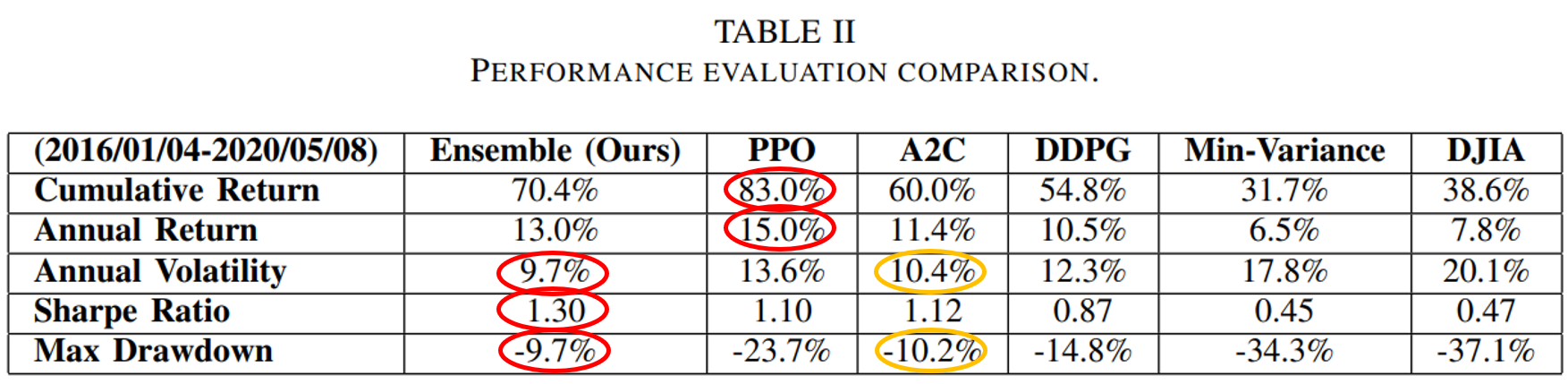
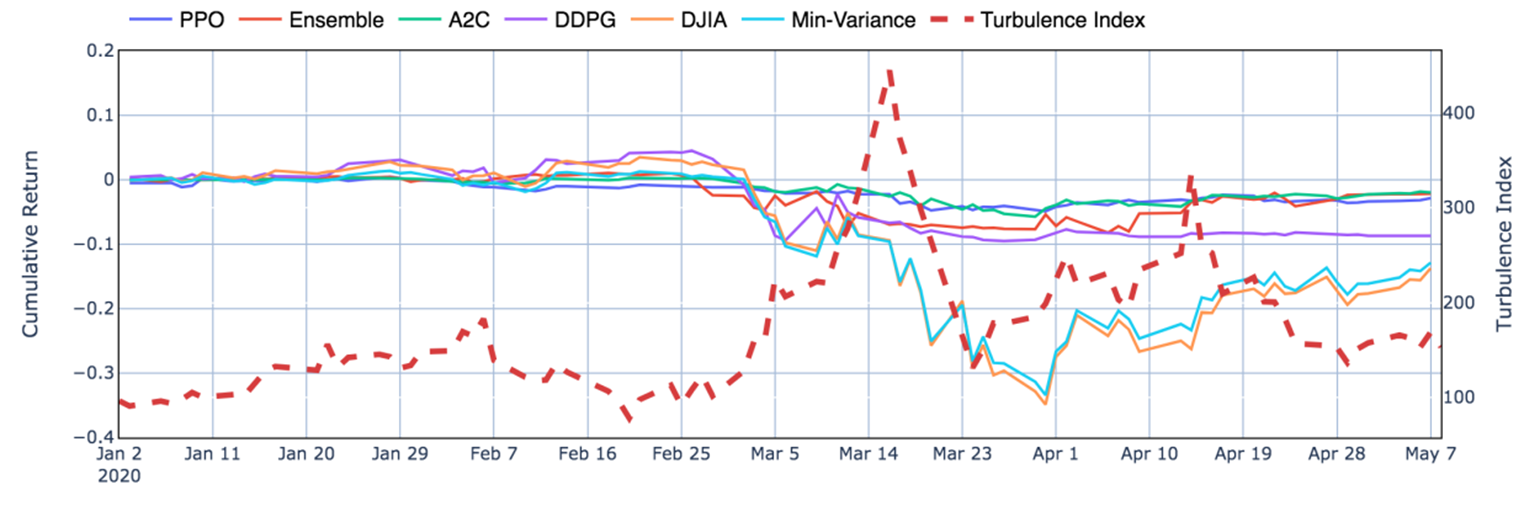
 are initialized to 0, while the policy π(s) is uniformly distributed among all actions. Afterwards, everything is updated through interacting with the stock market environment. By the Bellman Equation,
are initialized to 0, while the policy π(s) is uniformly distributed among all actions. Afterwards, everything is updated through interacting with the stock market environment. By the Bellman Equation,  is the expectation of the sum of direct reward
is the expectation of the sum of direct reward  and the future reqard
and the future reqard  at the next state discounted by a factor γ, resulting in the state-action value function:
at the next state discounted by a factor γ, resulting in the state-action value function:![[b_t, p_t, h_t, M_t, R_t, C_t, X_t]](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-0fbdf800e4e901e62bc4396f3815d15f_l3.png "Rendered by QuickLaTeX.com") storing information about
storing information about : Portfolio balance
: Portfolio balance : Adjusted close prices
: Adjusted close prices : Shares owned of each stock
: Shares owned of each stock : Moving Average Convergence Divergence
: Moving Average Convergence Divergence : Relative Strength Index
: Relative Strength Index : Commodity Channel Index
: Commodity Channel Index : Average Directional Index
: Average Directional Index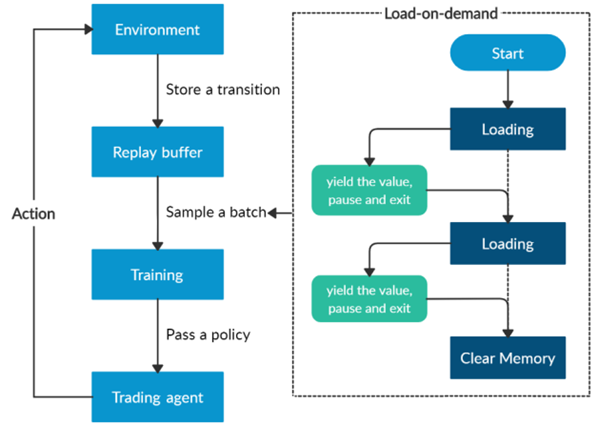
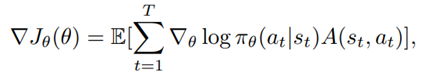
 is the policy network, and
is the policy network, and  is the advantage function to reduce the high variance of it:
is the advantage function to reduce the high variance of it: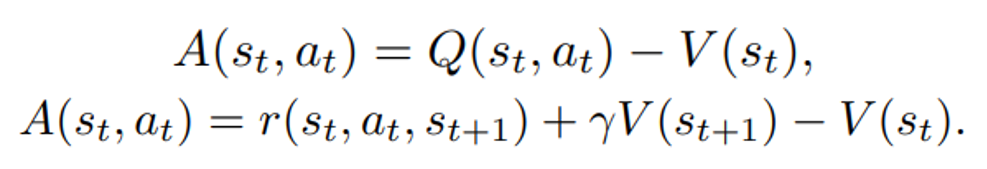
 is the value function of state
is the value function of state  , regardless of actions. DDPG: combines the frameworks of Q-learning and policy gradients and uses neural networks as function approximators; it learns directly from the observations through policy gradient and deterministically map states to actions. The Q-value is updated by:
, regardless of actions. DDPG: combines the frameworks of Q-learning and policy gradients and uses neural networks as function approximators; it learns directly from the observations through policy gradient and deterministically map states to actions. The Q-value is updated by: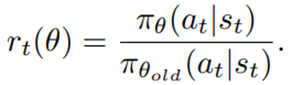










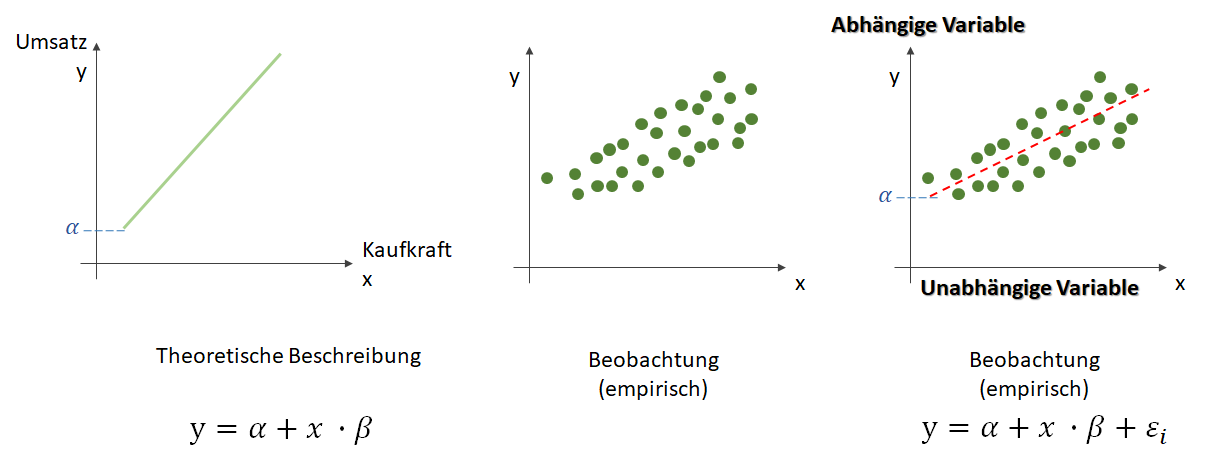
 , die unsere Punktwolke – mit der wir uns zutrauen, Vorhersagen über die abhängige Variable vornehmen zu können – möglichst gut beschreibt. Dabei ist
, die unsere Punktwolke – mit der wir uns zutrauen, Vorhersagen über die abhängige Variable vornehmen zu können – möglichst gut beschreibt. Dabei ist  der Zielwert (abhängige Variable) und
der Zielwert (abhängige Variable) und  der Eingabewert. Wir arbeiten also in einer zwei-dimensionalen Welt. Variablen, die die Funktion mathematisch definieren, werden oft als griechische Buchstaben darsgestellt. Die Variable
der Eingabewert. Wir arbeiten also in einer zwei-dimensionalen Welt. Variablen, die die Funktion mathematisch definieren, werden oft als griechische Buchstaben darsgestellt. Die Variable  (Alpha) ist der
(Alpha) ist der  . Dieser wird als Bias, selten auch als Default-Wert, bezeichnet. Der Bias ist also der Wert, wenn die
. Dieser wird als Bias, selten auch als Default-Wert, bezeichnet. Der Bias ist also der Wert, wenn die  (Beta) beschreibt die Steigung.
(Beta) beschreibt die Steigung. ein Fehler
ein Fehler  existiert. Diesen Fehler wollen wir in diesem Artikel ignorieren.
existiert. Diesen Fehler wollen wir in diesem Artikel ignorieren. statt
statt  ) sind nichts anderes als Gewichtungen zwischen den Eingaben.
) sind nichts anderes als Gewichtungen zwischen den Eingaben.![\[y = w_{0} \cdot x_{0} + w_{1} \cdot x_{1} + \ldots + w_{n} \cdot x_{n}\]](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-19728ae5f9e3065a4c17d50c417e0a8b_l3.png "Rendered by QuickLaTeX.com")
 . Verkürzt ausgedrückt:
. Verkürzt ausgedrückt:![\[y = \sum_{i=0}^n w_{i} \cdot x_{i}\]](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-3bbcbb30d482e7a1fd8da528030d6561_l3.png "Rendered by QuickLaTeX.com")
![\[y = w^T \cdot x\]](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-939f4bae6617db519d13b502d6337ee1_l3.png "Rendered by QuickLaTeX.com")
 .
.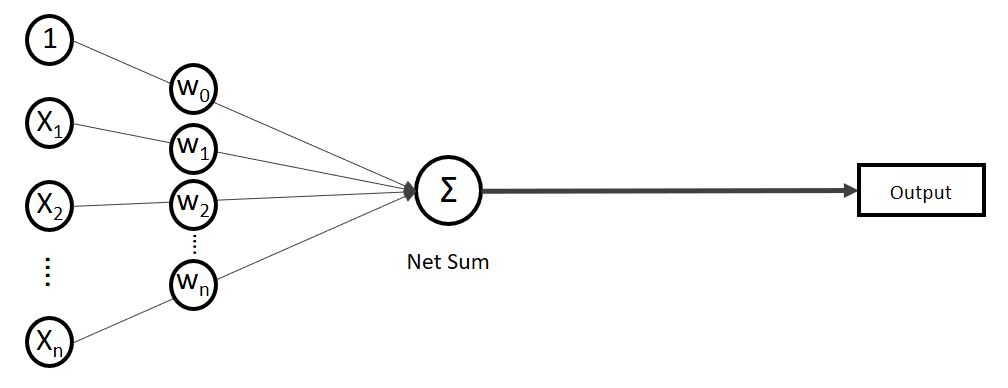
 . Auf der linken Seite finden wir alle Eingabewerte, wobei der erste Wert statisch mit 1.0 belegt ist, nur für den Zweck, den Bias (
. Auf der linken Seite finden wir alle Eingabewerte, wobei der erste Wert statisch mit 1.0 belegt ist, nur für den Zweck, den Bias (
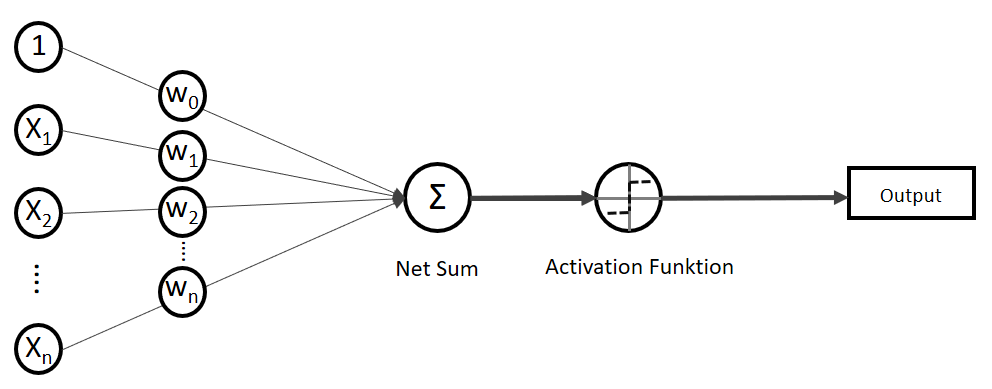
 (Phi), die uns die stetigen Werte der Nettoeingabe in einen binären Wert (z. B. 0 oder 1) umwandelt.
(Phi), die uns die stetigen Werte der Nettoeingabe in einen binären Wert (z. B. 0 oder 1) umwandelt. 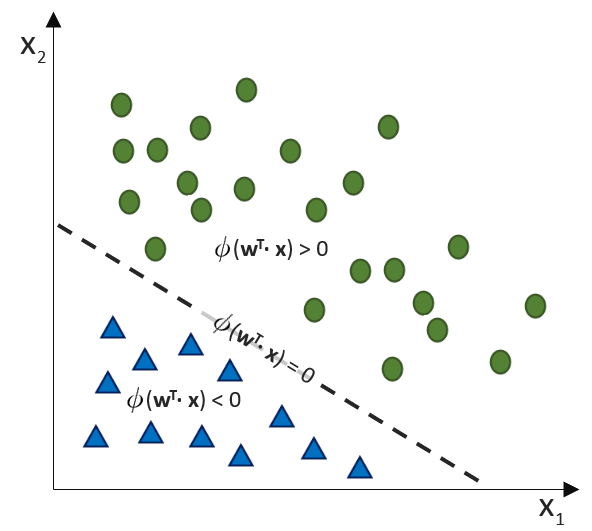
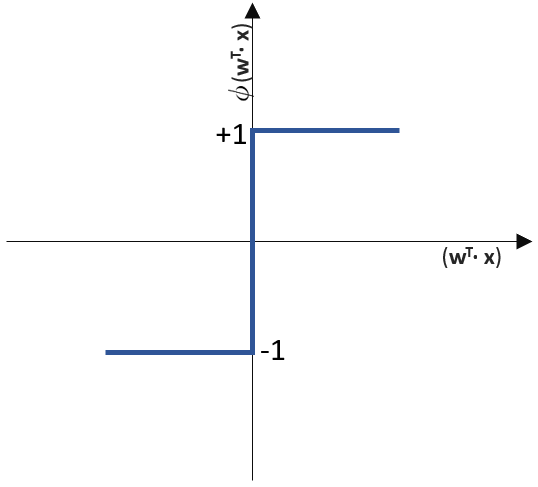
![\[ y = \phi(w^T \cdot x) = \left\{ \begin{array}{12} 1 & w^T \cdot x > 0\\ -1 & \text{otherwise} \end{array} \]](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-7b828cf4bbabf9e1a84ec9b628d51249_l3.png "Rendered by QuickLaTeX.com")