1, Who is playing or being played?
Since playing Japanese video games named “Demon’s Souls” and “Dark Souls” when they were released by From Software, I had played almost no video games for many years. During the period, From Software established one genre named soul-like games. Soul-like games are called 死にゲー in Japanese, which means “dying games,” and they are also called マゾゲー, which means “masochistic games.” As the words imply, you have to be almost masochistic to play such video games because you have to die numerous times in them. And I think recently it has been one of the most remarkable times for From Software because in November of 2021 “Dark Souls” was selected the best video game ever by Golden Joystick Awards. And in the end of last February a new video game by From Software called “Elden Ring” was finally released. After it proved that Miyazaki Hidetaka, the director of Soul series, collaborated with George RR Martin, the author of the original of “Game of Thrones,” “Elden Ring” had been one of the most anticipated video games. In spite of its notorious difficulty as well as other soul-like games so far, “Elden Ring” became a big hit, and I think Miyazak Hidetaka is now the second most famous Miyazaki in the world. A lot of people have been playing it, raging, and screaming. I was no exception, and it took me around 90 hours to finish the video game, breaking a game controller by the end of it. It was a long time since I had been so childishly emotional last time, and I was almost addicted to trial and errors the video game provides. At the same time, one question crossed my mind: is it the video game or us that is being played?

The childhood nightmare strikes back. Left: the iconic and notorious boss duo Ornstein and Smough in Dark Souls (2011), right: Godskin Duo in Elden Ring (2022).
Miyazaki Hidetaka entered From Software in 2004 and in the beginning worked as a programmer of game AI, which controls video games in various ways. In the same year an AI researcher Miyake Youichiro also joined From Software, and I studied a little about game AI by his book after playing “Elden Ring.” I found that he also joined “Demon’s Souls,” in which enemies with merciless game AI were arranged, and I had to conquer them to reach the demon in the end at every dungeon. Every time I died, even in the terminal place with the boss fight, I had to restart from the start, with all enemies reviving. That requires a lot of trial and errors, and that was the beginning of soul-like video games today. In the book by the game AI researcher who was creating my tense and almost traumatizing childhood experiences, I found that very sophisticated techniques have been developed to force players to do trial and errors. They were sophisticated even at a level of controlling players at a more emotional level. Even though I am familiar with both of video games and AI at least more than average, it was not until this year that I took care about this field. After technical breakthroughs mainly made Western countries, video game industry showed rapid progress, and industry is now a huge entertainment industry, whose scale is now bigger that those of movies and music combined. Also the news that Facebook changed its named to Meta and that Microsoft announced to buy Activision Blizzard were sensational recently. However media coverage about those events would just give you impressions that those giant tech companies are making uses of the new virtual media as metaverse or new subscription services. At least I suspect these are juts limited sides of investments on the video game industry.
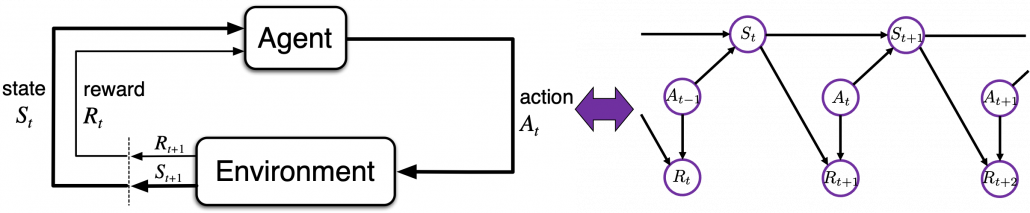
The book on game AI also made me rethink AI technologies also because I am currently writing an article series on reinforcement learning (RL) as a kind of my study note. RL is a type of training of an AI agent through trial-and-error-like processes. Rather than a labeled dataset, RL needs an environment. Such environment receives an action from an agent and gives the consequent state and next reward. From a view point of the agent, it give an action and gets the consequent next state and a corresponding reward, which looks like playing a video game. RL mainly considers a more simplified version of video-game-like environments called a Markov decision processes (MDPs), and in an MDP at a time step  an RL agents takes an action
an RL agents takes an action  , and gets the next state
, and gets the next state  and a corresponding reward
and a corresponding reward  . An MDP is often displayed as a graph at the left side below or the graphical model at the right side.
. An MDP is often displayed as a graph at the left side below or the graphical model at the right side.
Compared to a normal labeled dataset used for other machine learning, such environment is something hard to prepare. The video game industry has been a successful manufacturer of such environments, and as a matter of fact video games of Atari or Nintendo Entertainment System (NES) are used as benchmarks of theoretical papers on RL. Such video games might be too primitive for considering practical uses, but researches on RL are little by little tackling more and more complicated video games or simulations. But also I am sure creating AI that plays video games better than us would not be their goals. The situation seems like they are cultivating a form of more general intelligence inside computer simulations which is also effective to the real world. Someday, experiences or intelligence grown in such virtual reality might be dragged to our real world.
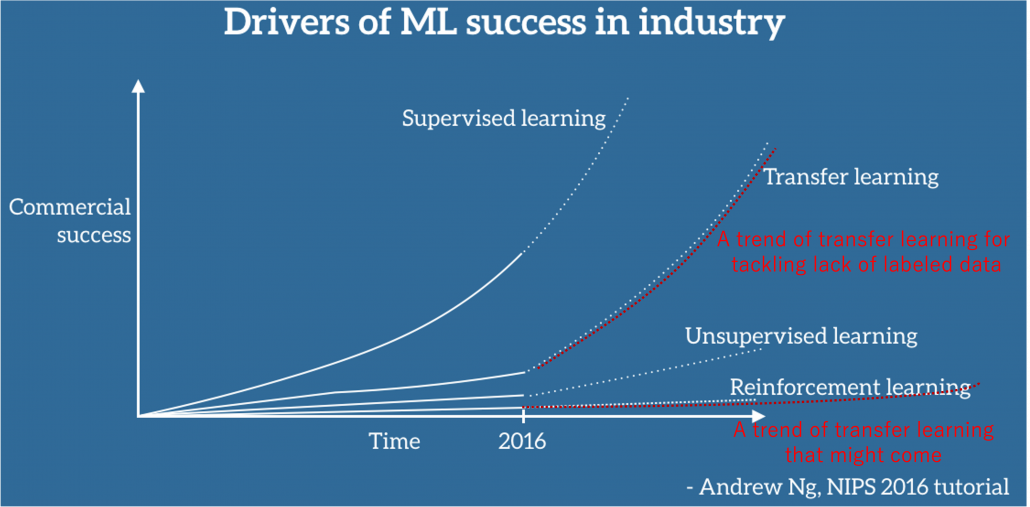
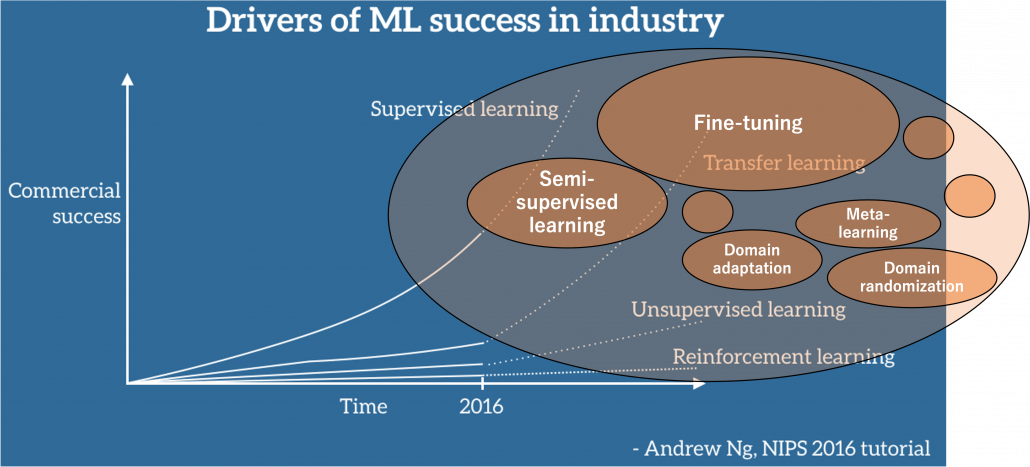
Testing systems in simulations has been a fascinating idea, and that is also true of AI research. As I mentioned, video games are frequently used to evaluate RL performances, and there are some tools for making RL environments with modern video game engines. Providing a variety of such sophisticated computer simulations will be indispensable for researches on AI. RL models need to be trained in simulations before being applied on physical devices because most real machines would not endure numerous trial and errors RL often requires. And I believe the video game industry has a potential of developing such experimental fields of AI fueled by commercial success in entertainment. I think the ideas of testing systems or training AI in simulations is getting a bit more realistic due to recent development of transfer learning.
Transfer learning is a subfield of machine learning which apply intelligence or experiences accumulated in datasets or tasks to other datasets or tasks. This is not only applicable to RL but also to more general machine learning tasks like regression or classification. Or rather it is said that transfer learning in general machine learning would show greater progress at a commercial level than RL for the time being. And transfer learning techniques like using pre-trained CNN or BERT is already attracting a lot of attentions. But I would say this is only about a limited type of transfer learning. According to Matsui Kota in RIKEN AIP Data Driven Biomedical Science Team, transfer learning has progressed rapidly after the advent of deep learning, but many types of tasks and approaches are scattered in the field of transfer learning. As he says, the term transfer learning should be more carefully used. I would like to say the type of transfer learning discussed these days are a family of approaches for tackling lack of labels. At the same time some of current researches on transfer learning is also showing possibilities that experiences or intelligence in computer simulations are transferable to the real world. But I think we need to wait for more progress in RL before such things are enabled.
Source: https://ruder.io/transfer-learning/
In this article I would like to explain how video games or computer simulations can provide experiences to the real world in two ways. I am first going to briefly explain how video game industry in the first place has been making game AI to provide game users with tense experiences. And next I will explain how RL has become a promising technique to beat such games which were originally invented to moderately harass human players. And in the end, I am going to briefly introduce ideas of transfer learning applicable to video games or computer simulations. What I can talk in this article is very limited for these huge study areas or industries. But I hope you would see the video game industry and transfer learning in different ways after reading this article, and that might give you some hints about how those industries interact to each other in the future. And also please keep it in mind that I am not going to talk so much about growing video game markets, computer graphics, or metaverse. Here I focus on aspects of interweaving knowledge and experiences generated in simulation or real physical worlds.
2, Game AI
The fact that “Dark Souls” was selected the best game ever at least implies that current video game industry makes much of experiences of discoveries and accomplishments while playing video games, rather than cinematic and realistic computer graphics or iconic and world widely popular characters. That is a kind of returning to the origin of video games. Video games used to be just hard because the more easily players fail, the more money they would drop in arcade games. But I guess this aspect of video games tend to be missed when you talk about video games as a video game fan. What you see in advertisements of video games are more of beautiful graphics, a new world, characters there, and new gadgets. And it has been actually said that qualities of computer graphics have a big correlation with video game sales. In the third article of my series on recurrent neural networks (RNN), I explained how video game industry laid a foundation of the third AI boom during the second AI winter in 1990s. To be more concrete, graphic cards developed rapidly to realize more photo realistic graphics in PC games, and the graphic card used in Xbox was one of the first programmable GPU for commercial uses. But actually video games developed side by side with computer science also outside graphics. Thus in this section I am going to how video games have developed by focusing on game AI, which creates intelligence in video games in several ways. And my explanations on game AI is going to be a rough introduction to a huge and great educational works by Miyake Youichiro.
Playing video games is made up by decision makings, and such decision makings are made in react to game AI. In other words, a display is input into your eyes or sight nerves, and sequential decision makings, that is how you have been moving fingers are outputs. Complication of the experiences, namely hardness of video games, highly depend on game AI. Game AI is mainly used to design enemies in video games to hunt down players. Ideally game AI has to be both rational and human. Rational game AI implemented in enemies frustrate or sometimes despair users by ruining users’ efforts to attack them, to dodge their attacks, or to use items. At the same time enemies have to retain some room for irrationality, that is they have to be imperfect. If enemies can perfectly conquer players’ efforts by instantly recognizing their commands, such video games would be theoretically impossible to beat. Trying to defeat such enemies is nothing but frustrating. Ideal enemies let down their guard and give some timings for attacking and trying to conquer them. Sophisticated game AI is inevitable to make grownups all over the world childishly emotional while playing video games.
These behaviors of game AI are mainly functions of character AI, which is a part of game AI. In order to explain game AI, I also have to explain a more general idea of AI, which is not the one often called “AI” these days. Artificial intelligence (AI) is in short a family of technologies to create intelligence, with computers. And AI can be divided into two types, symbolism AI and connectionism AI. Roughly speaking, the former is manual and the latter is automatic. Symbolism AI is described with a lot of rules, mainly “if” or “else” statements in code. For example very simply “If the score is greater than 5, the speed of the enemy is 10.” Or rather many people just call it “programming.”
*Note that in contexts of RL, “game AI” often means AI which plays video games or board games. But “game AI” in video games is a more comprehensive idea orchestrating video games.
This meme describes symbolism AI well.
What people usually call “AI” in this 3rd AI boom is the latter, connictionism AI. Connectionism AI basically means neural networks, which is said to be inspired by connections of neurons. But the more you study neural networks, the more you would see such AI just as “functions capable of universal approximation based on data.” That means, a function  , which you would have learned in school such as
, which you would have learned in school such as  is replaced with a complicated black box, and such black box is automatically learned with many combinations of
is replaced with a complicated black box, and such black box is automatically learned with many combinations of  . And such black boxes are called neural networks, and the combinations of datasets. Connectionism AI might sound more ideal, but in practice it would be hard to design characters in AI based on such training with datasets.
. And such black boxes are called neural networks, and the combinations of datasets. Connectionism AI might sound more ideal, but in practice it would be hard to design characters in AI based on such training with datasets.
*Connectionism, or deep learning is of course also programming. But in deep learning we largely depend on libraries, and a lot of parameters of AI models are updated automatically as long as we properly set datasets. In that sense, I would connectionism is more automatic. As I am going to explain, game AI largely depends on symbolism AI, namely manual adjustment of lesser parameters, but such symbolism AI would behave much more like humans than so called “AI” these days when you play video games.
Digital game AI today is application of the both types of AI in video games. It initially started mainly with symbolism AI till around 2010, and as video games get more and more complicated connectionism AI are also introduced in game AI. Video game AI can be classified to mainly navigation AI, character AI, meta AI, procedural AI, and AI outside video games. The figure below shows relations of general AI and types of game AI.
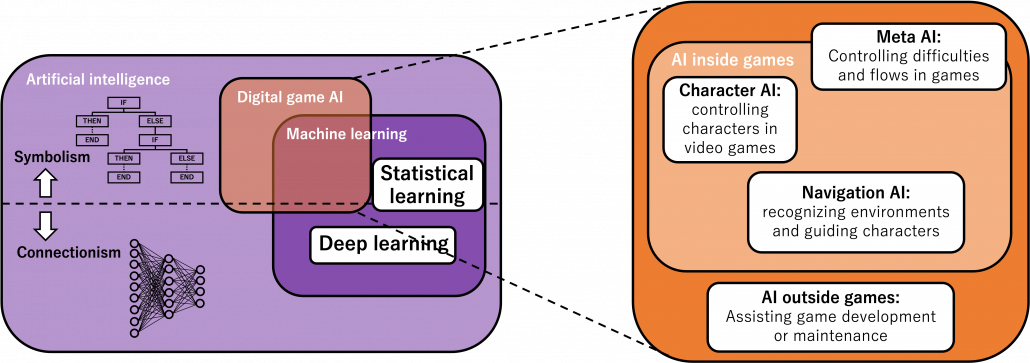
Very simply putting, video game AI traced a history like this: the initial video games were mainly composed of navigation AI showing levels, maps, and objects which move deterministically based on programming. Players used to just move around such navigation AI. Sooner or later, enemies got certain “intelligence” and learned to chase or hunt down players, and that is the advent of character AI. But of course such “intelligence” is nothing but just manual programs. After rapid progress of video games and their industry, meta AI was invented to control difficulties of video games, thereby controlling players’ emotions. Procedural AI automatically generates contents of video games, so video games are these days becoming more and more massive. And as modern video games are too huge and complicated to debug or maintain manually, AI technologies including deep learning are used. The figure below is a chronicle of development of video games and AI technologies covered in this article. Let’s see a brief history of video games and game AI by taking a closer look at each type of game AI a little more precisely.
Navigation AI
Navigation AI is the most basic type of game AI, and that allows character AI to recognize the world in video games. Even though I think character AI, which enables characters in video games to behave like humans, would be the most famous type of game AI, it is said navigation AI has an older history. One important function of navigation AI is to control objects in video games, such as lifts, item blocks, including attacks by such objects. The next aspect of navigation AI is that it provides character AI with recognition of worlds. Unlike humans, who can almost instantly roughly recognize circumstances, character AI cannot do that as we do. Even if you feel as if the character you are controlling are moving around mountains, cities, or battle fields, sometimes escaping from attacks by other AI, for character AI that is just moving on certain graphs. The figure below are some examples of world representations adopted in some popular video games. There are a variety of such representations, and please let me skip explaining the details of them. An important point is, relatively wide and global recognition of worlds by characters in video games depend on how navigation AI is designed.
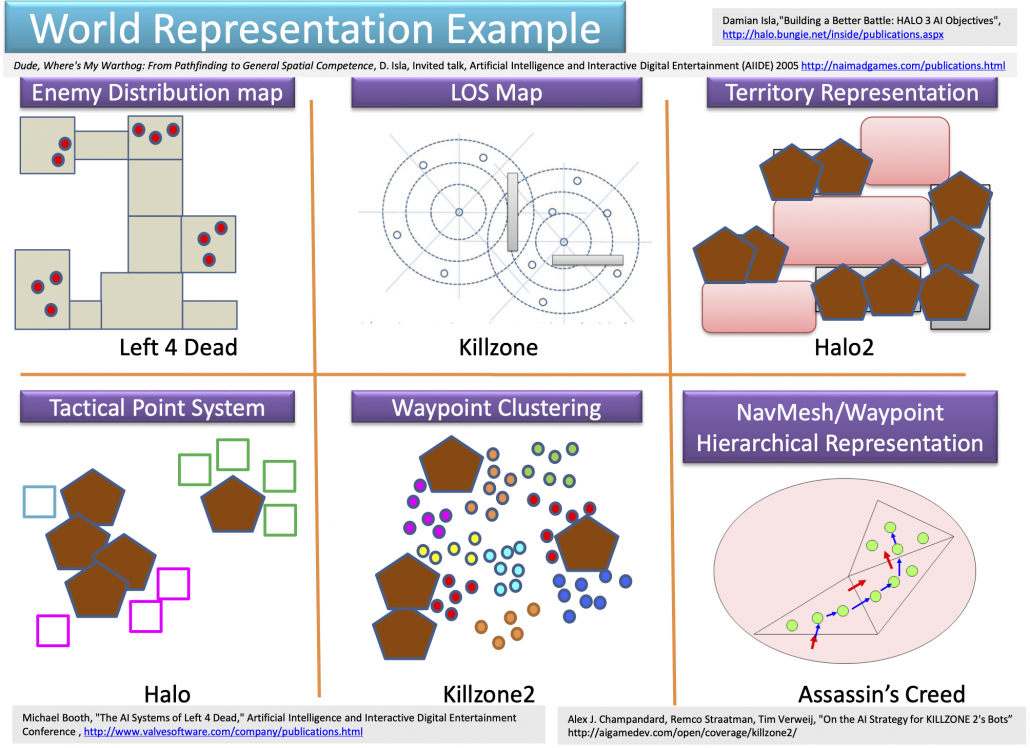
Source: Youichiro Miyake, “AI Technologies in Game Industry”, (2020)
The next important feature of navigation AI is path finding. If you have learned engineering or programming, you should be already familiar with pathfiniding algorithms. They had been known since a long time ago, but it was not until “Counter-Strike” in 2000 the techniques were implemented at an satisfying level for navigating characters in a 3d world. Improvements of pathfinding in video games released game AI from fixed places and enabled them to be more dynamic.
*According to Miyake Youichiro, the advent of pathfinding in video games released character AI from staying in a narrow space and enable much more dynamic and human-like movements of them. And that changed game AI from just static objects to more intelligent entity.
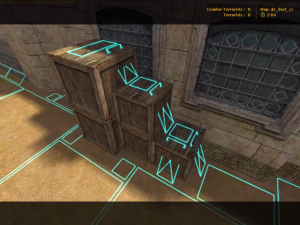
Navigation meshes in “Counter-Strike (2000).” Thanks to these meshes, continuous 3d world can be processed as discrete nodes of graphs. Source: https://news.denfaminicogamer.jp/interview/gameai_miyake/3
Character AI
Character AI is something you would first imagine from the term AI. It controls characters’ actions in video games. And differences between navigation AI and character AI can be ambiguous. It is said Pac-Man is one of the very first character AI. Compared to aliens in Space Invader deterministically moved horizontally, enemies in Pac-Man chase a player, and this is the most straightforward difference between navigation AI and character AI.
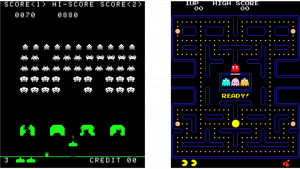
Source: https://en.wikipedia.org/wiki/Space_Invaders https://en.wikipedia.org/wiki/Pac-Man
Character AI is a bunch of sophisticated planning algorithms, so I can introduce only a limited part of it just like navigation AI. In this article I would like to take an example of “F.E.A.R.” released in 2005. It is said goal-oriented action planning (GOAP) adopted in this video game was a breakthrough in character AI. GOAP is classified to backward planning, and if there exists backward ones, there is also forward ones. Using a game tree is an examples of forward planning. The figure below is an example of a tree game of tic-tac-toe. There are only 9 possible actions at maximum at each phase, so the number of possible states is relatively limited.
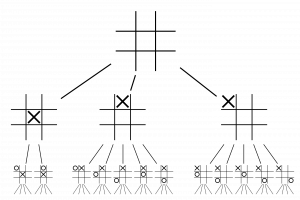
https://en.wikipedia.org/wiki/Game_tree
But with more options of actions like most of video games, forward plannings have to deal much larger sizes of future action combinations. GOAP enables realistic behaviors of character AI with a heuristic idea of planning backward. To borrow Miyake Youichiro’s expression, GOAP processes actions like sticky notes. On each sticky note, there is a combination of symbols like “whether a target is dead,” “whether a weapon is armed,” or “whether the weapon is loaded.” A sticky note composed of such symbols form an action, and each action comprises a prerequisite, an action, and an effect. And behaviors of character AI is conducted with planning like pasting the sticky notes.
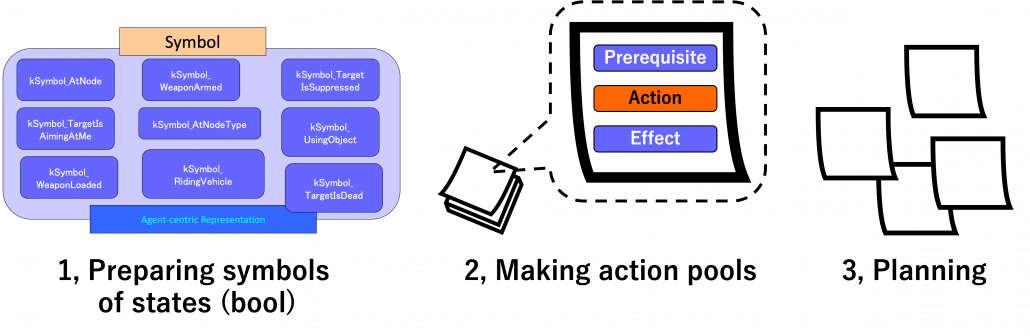
Based on: Youichiro Miyake, “AI Technologies in Game Industry”, (2020)
More practically sticky notes, namely actions are stored in actions pools. For a decision making, as displayed in the left side of the figure below, actions are connected as a chain. First an action of a goal is first set, and an action can be connected to the prerequisite of the goal via its effect. Just as well corresponding former actions are selected until the initial state. In the example of chaining below, the goal is “kSymbol_TargetIsDead,” and actions are chained via “kSymbol_TargetIsDead,” “kSymbol_WeaponLoaded,” “kSymbol_WeaponArmed,” and “None.” And there are several combinations of actions to reach a certain goal, so more practically each action has a cost, and the most ideal behavior of character AI is chosen by pathfinding on a graph like the right side of the figure below. And the best planning is chosen by a pathfinding algorithm.
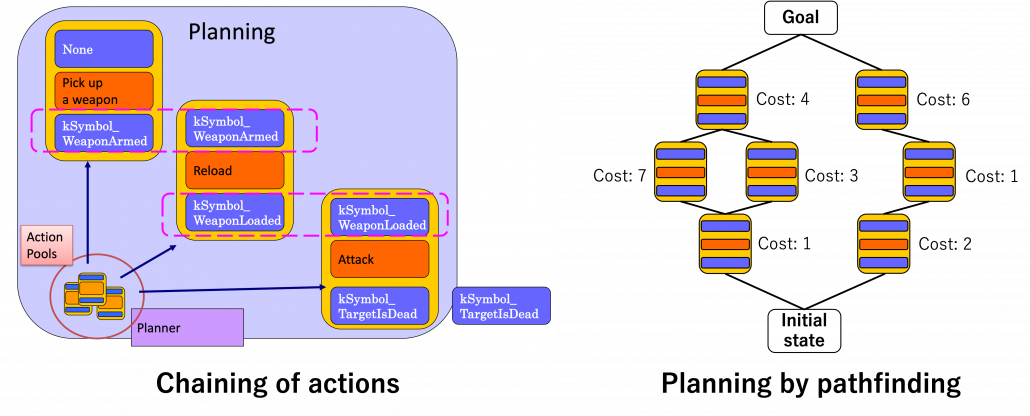
Based on: Youichiro Miyake, “AI Technologies in Game Industry”, (2020)
Even though many of highly intelligent behaviors of character AI are implemented as backward plannings as I explained, planning forward can be very effective in some situations. Board game AI is a good example. A searching algorithm named Monte Carlo tree search is said to be one breakthroughs in board game AI. The searching algorithm randomly plays a game until the end, which is called playout. Numerous times of playouts enables evaluations of possibilities of winning. Monte Carlo Tree search also enables more efficient searches of games trees.
Meta AI
Meta AI is a type of AI such that controls a whole video game to enhance player’s experiences. To be more concrete, it adjusts difficulties of video games by for example dynamically arranging enemies. I think differences between meta AI and navigation AI or character AI can be also ambiguous. As I explained, the earliest video games were composed mainly with navigation AI, or rather just objects. Even if there are aliens or monsters, they can be just part of interactive objects as long as they move deterministically. I said character AI gave some diversities to their behaviors, but how challenging a video game is depends on dynamic arrangements of such objects or enemies. And some of classical video games like “Xevious,” as a matter of fact implemented such adjustments of difficulties of game plays. That is an advent of meta AI, but I think they were not so much distinguished from other types of AI, and I guess meta AI has been unconsciously just a part of programming.
It is said a turning point of modern meta AI is a shooting game “Left 4 Dead” released in 2008, where zombies are dynamically arranged. As well as many masterpiece thriller films, realistic and tense terrors are made by combinations of intensities and relaxations. Tons of monsters or zombies coming up one after another and just shooting them look stupid or almost like comedies. .And analyzing the success of “Counter-Strike,” they realized that users liked rhythms of intensity and relaxation, so they implemented that explicitly in “Left 4 Dead.” The graphs below concisely shows how meta AI works in the video game. When the survivor intensity, namely players’ intensity is low, the meta AI arrange some enemies. Survivor intensity increases as players fight with zombies or something, and then meta AI places fewer enemies so that players can relax. While players re relatively relaxing, desired population of enemies increases when they actually show up in video games, again the phase of intensity comes.
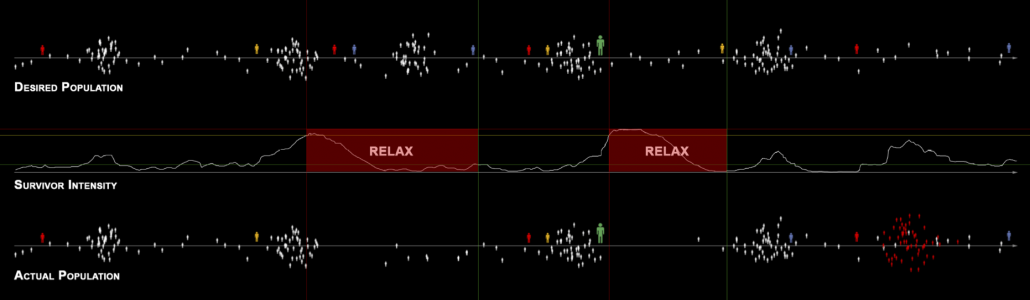
Source: Michael Booth, “Replayable Cooperative Game Design: Left 4 Dead”, (2009), Valve
*Soul series video games do not seem to use meta AI so much. Characters in the games are rearranged in more or less the same ways every time players fail. Soul-like games make much of experiences that players find solutions by themselves, which means that manual but very careful arrangements of enemies and interactive objects are also very effective.
Meta AI can be used to make video games more addictive using data analysis. Recent social network games can record logs of game plays. Therefore if you can observe a trend that more users unsubscribe when they get less rewards in certain online events, operating companies of the game can adjust chances of getting “rare” items.
Procedural AI and AI outside video games
How clearly you can have an image of what I am going to explain in this subsection would depend how recently you have played video games. If your memories of playing video games stops with good old days of playing side-scrolling ones like Super Mario Brothers, you should at first look up some videos of playing open world games. Open world means a use of a virtual reality in which players can move an behave with a high degree of freedom. The term open world is often used as opposed to the linear games, where players have process games in the order they are given. Once you are immersed in photorealistic computer graphic worlds in such open world games, you would soon understand why metaverse is attracting attentions these days. Open world games for example like “Fallout 4” are astonishing in that you can even talk to almost everyone in them. Just as “Elden Ring” changed former soul series video games into an open world one, it seems providing open world games is one way to keep competitive in the video game industry. And such massive world can be made also with a help of procedural AI. Procedural AI can be seen as a part of meta AI, and it generates components of games such as buildings, roads, plants, and even stories. Thanks to procedural AI, video game companies with relatively small domestic markets like Poland can make a top-level open world game such as “The Witcher 3: Wild Hunt.”

An example of technique of procedural AI adopted in “The Witcher 3: Wild Hunt” for automatically creating the massive open world. Source: Marcin Gollent, “Landscape creation and rendering in REDengine 3”, (2014), Game Developers Conference
Creating a massive world also means needs of tons of debugging and quality assurance (QA). Combining works by programmers, designers, and procedural AI will cause a lot of unexpected troubles when it is actually played. AI outside game can be used to find these problems for quality assurance. Debugging and and QA have been basically done manually, and especially when it comes to QA, video game manufacturer have to employ a lot of gamer to let them just play prototype of their products. However as video games get bigger and bigger, their products are not something that can be maintained manually anymore. If you have played even one open world game, that would be easy to imagine, so automatic QA would remain indispensable in the video game industry. For example an open world game “Horizon Zero Dawn” is a video game where a player can very freely move around a massive world like a jungle. The QA team of this video game prepared bug maps so that they can visualize errors in video games. And they also adopted a system named “Apollo-Autonomous Automated Autobots” to let game AI automatically play the video game and record bugs.
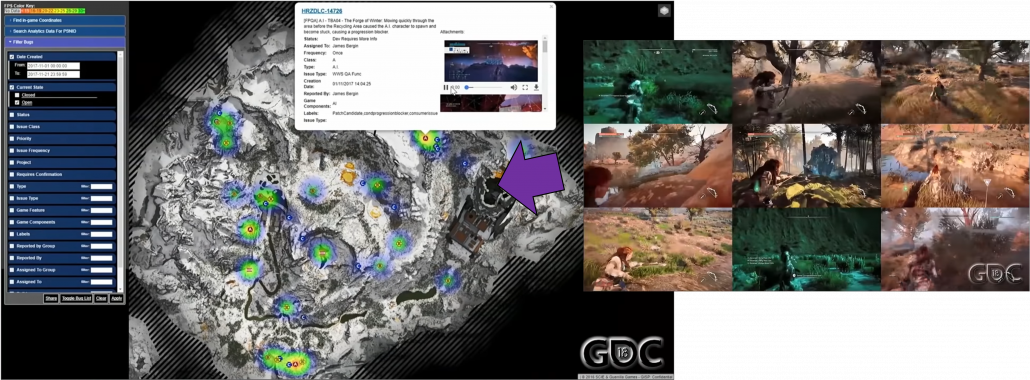
As most video games both in consoles or PCs are connected to the internet these days, these bugs can be fixed soon with updates. In addition, logs of data of how players played video games or how they failed can be stored to adjust difficulties of video games or train game AI. As you can see, video games are not something manufacturers just release. They are now something develop interactively between users and developers, and players’ data is all exploited just as your browsing history on the Internet.
I have briefly explained AI used for video games over four topics. In the next two sections, I am going to explain how board games and video games can be used for AI research.
3, Reinforcement learning: we might be a sort of well-made game AI models
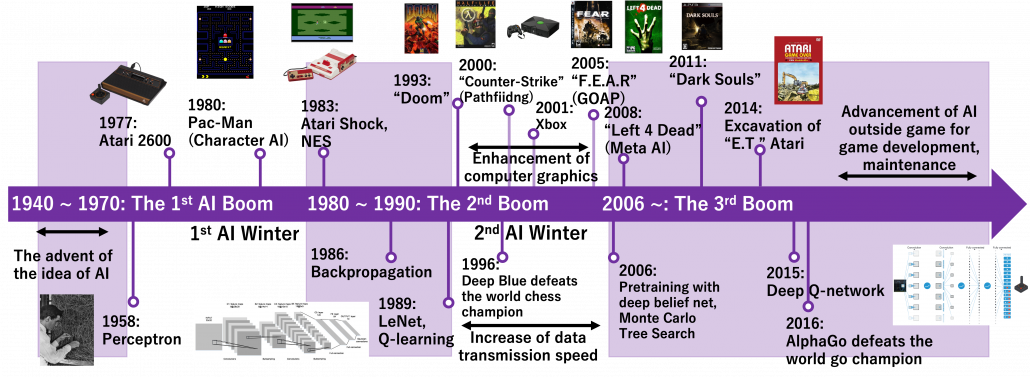
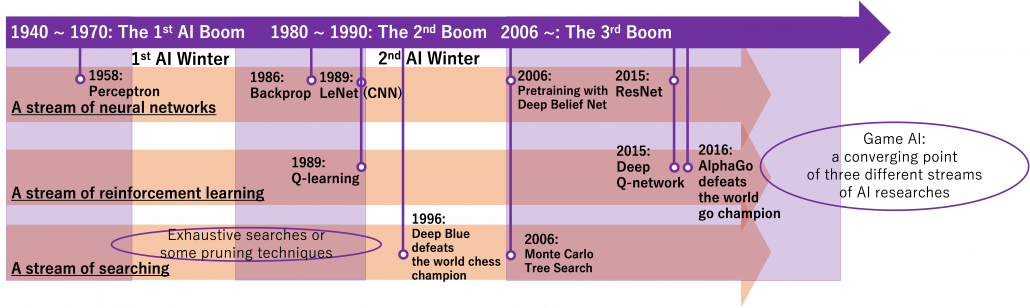
Machine learning, especially RL is replacing humans with computers, however with incredible computation resources. Invention of game AI, in this context including computers playing board games, has been milestones of development of AI for decades. As Western countries had been leading researches on AI, defeating humans in chess, a symbol of intelligence, had been one of goals. Even Alan Turing, one of the fathers of computers, programmed game AI to play chess with one of the earliest calculators. Searching algorithms with game trees were mainly studied in the beginning. Game trees are a type of tree graphs to show how games proceed, by expressing future possibilities with diverging tree structures. And searching algorithms are often used on tree graphs to ignore future steps which are not likely to be effective, which often looks like cutting off branches of trees. As a matter of fact, chess was so “simple” that searching algorithms alone were enough to defeat Garry Kasparov, the world chess champion at that time in 1997. That is, growing trees and trimming them was enough for the “simplicity” of chess as long as a super computer of IBM was available. After that computer defeated one of the top players of shogi, a Japanese version of chess, in 2013. And remarkably, in 2016 AlphaGo of DeepMind under Google defeated the world go champion. Game AI has been gradually mastering board games in order of increasing search space size.

Source: https://www.livescience.com/59068-deep-blue-beats-kasparov-progress-of-ai.html https://fortune.com/2016/03/21/google-alphago-win-artificial-intelligence/
We can say combinations of techniques which developed in different streams converged into game AI today, like I display in the figure below. In AlphaGo or maybe also general game AI, neural networks enable “intuition” on phases of board games, searching algorithms enables “foreseeing,” and RL “experiences.” And as almost no one can defeat computers in board games anymore, the next step of game AI is how to conquer other video games. Since progress of convolutional neural network (CNN) in this 3rd AI boom, computers got “eyes” like we do, and the invention of ResNet in 2015 is remarkable. Thus we can now use displays of video games as inputs to neural networks. And combinations of reinforcement learning and neural networks like (CNN) is called deep reinforcement learning. Since the advent of deep reinforcement learning, many people are trying to apply it on various video games, and they show impressive results. But in general that is successful in bird’s-eye view games. Even if some of researches can be competitive or outperform human players, even in first person shooting video games, they require too much computational resources and heuristic techniques. And usually they take too much time and computer resource to achieve the level.
*Even though CNN is mainly used as “eyes” of computers, it is also used to process a phase of a board game. That means each phase of is processed like an arrangement of pixels of an image. This is what I mean by “intuition” of deep learning. Just as neural networks can recognize objects, depending on training methods they can recognize boards at a high level.
Now I would like you to think about what “smartness” means. Competency in board games tend to have correlations with mathematical skills. And actually in many cases people proficient in mathematics are also competent in board games. Even though AI can defeat incredibly smart top board game players to the best of my knowledge game AI has yet to play complicated video games with more realistic computer graphics. As I explained, behaviors of character AI is in practice implemented as simpler graphs, and tactics taken in such graphs will not be as complicated as game trees of competitive board games. And the idea of game AI playing video games itself not new, and it is also used in debugging of video games. Thus the difficulties of computers playing video games would come more from how to associate what they see on displays with more long-term and more abstract plannings. And currently, kids would more flexibly switch to other video games and play them more professionally in no time. I would say the difference is due to frames of tasks. A frame roughly means a domain or a range which is related to a task. When you play a board game, its frame is relatively small because everything you can do is limited in the rule of the game which can be expressed as simple data structure. But playing video games has a wider frame in that you have to recognize only the necessary parts important for playing video games from its constantly changing displays, namely sequences of RGB images. And in the real world, even a trivial action like putting a class on a table is selected from countless frames like what your room looks like, how soft the floor is, or what the temperature is. Human brains are great in that they can pick up only necessary frames instantly.
As many researchers would already realize, making smaller models with lower resources which can learn more variety of tasks is going to be needed, and it is a main topic these days not only in RL but also in other machine learning. And to be honest, I am skeptical about industrial or academic benefits of inventing specialized AI models for beating human players with gigantic computation resources. That would be sensational and might be effective for gathering attentions and funds. But as many AI researchers would already realize, inventing a more general intelligence which would more flexibly adjust to various tasks is more important. Among various topics of researches on the problem, I am going to pick up transfer learning in the next section, but in a more futuristic and dreamy sense.
4, Transfer learning and game for AI
In an event with some young shogi players, to a question “What would you like to request to a god?” Fujii Sota, the youngest top shogi player ever, answered “If he exists, I would like to ask him to play a game with me.” People there were stunned by the answer. The young genius, contrary to his sleepy face, has an ambition which only the most intrepid figures in mythology would have had. But instead of playing with gods, he is training himself with game AI of shogi. His hobby is assembling computers with high end CPUs, whose performance is monstrous for personal home uses. But in my opinion such situation comes from a fact that humans are already a kind of well-made machine learning models and that highly intelligent games for humans have very limited frames for computers.
*It seems it is not only computers that need huge energy consumption to play board games. Japanese media often show how gorgeous and high caloric shogi players’ meals are during breaks. And more often than not, how fancy their feasts are is the only thing most normal spectators like me in front of TVs can understand, albeit highly intellectual tactics made beneath the wooden boards.
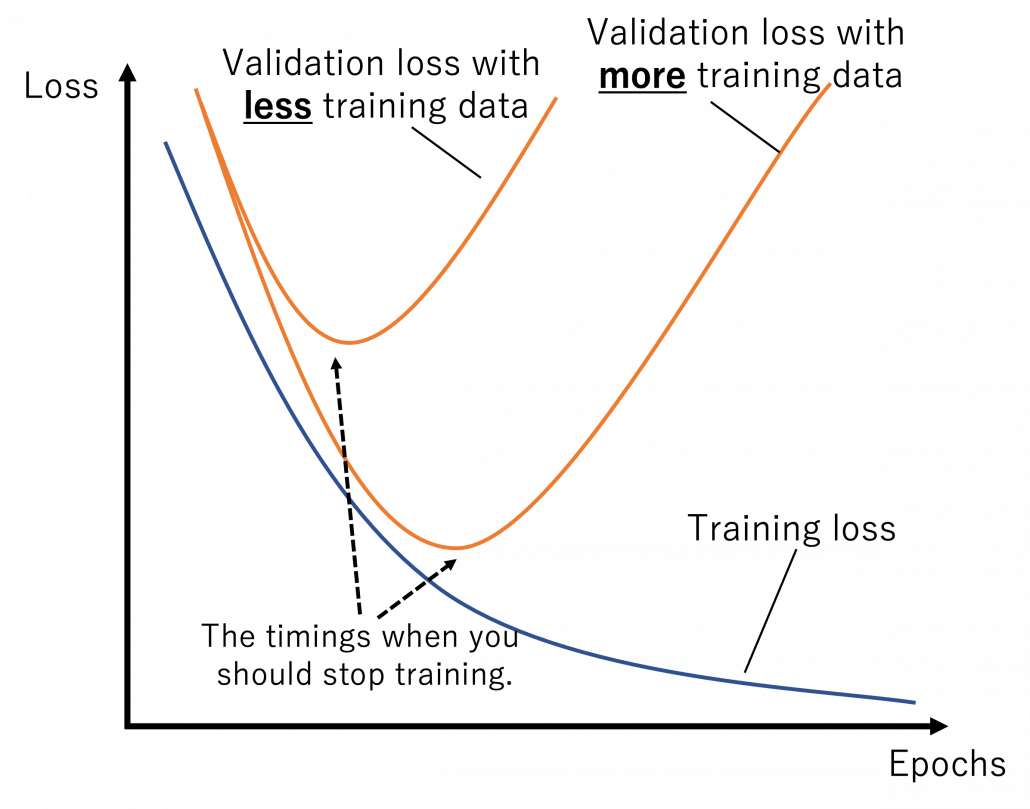
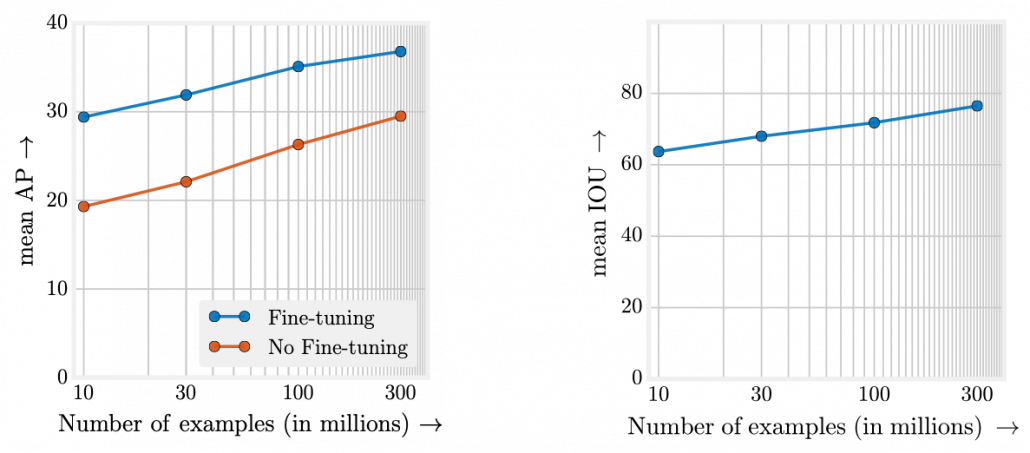
As I have explained, the video game industry has been providing complicated simulational worlds with sophisticated ensemble of game AI in both symbolism and connectionism ways. And such simulations, initially invented to hunt down players, are these days being conquered especially by RL models, and the trend showed conspicuous progress after the advent of deep learning, that is after computers getting “eyes.” The next problem is how to transfer the intelligence or experiences cultivated in such simulations to the real world. Only humans can successfully train themselves with computer simulations today as far as I know, but more practically it is desired to transfer experiences with wider frames to more inflexible entities like robots. Such technologies would be ideal especially for RL because physical devices cannot make numerous trial and errors in the real world. They should be trained in advance in computer simulations. And transfer learning could be one way to take advantages of experiences in computer simulations to the real world. But before talking about such transfer learning, we need to be careful about the term “transfer learning.” Transfer learning is a family of machine learning technologies to makes uses of knowledge learned in a dataset, which is usually relatively huge, to another task with another dataset. Even though I have been emphasizing transferring experiences in computer simulations, transfer learning is a more general idea applicable to more general use cases, also outside computer simulations. Or rather, transfer learning is attracting a lot of attentions as a promising technique for tackling lack of data in general machine learning. And another problem is even though transfer learning has been rapidly developing recently, various research topics are scattered in the field called “transfer learning.” And arranging these topics would need extra articles or something. Thus in the rest of this article, I would like to especially focus on uses of video games or computer simulations in transfer learning. When it comes to already popular and practical transfer learning techniques like fine tuning with pre-trained backbone CNN or BERT, I am planning to cover them with more practical introduction in one of my upcoming articles. Thus in this article, after simply introducing ideas of domains and transfer learning, I am going to briefly introduce transfer learning and explain domain adaptation/randomization.
Domain and transfer learning
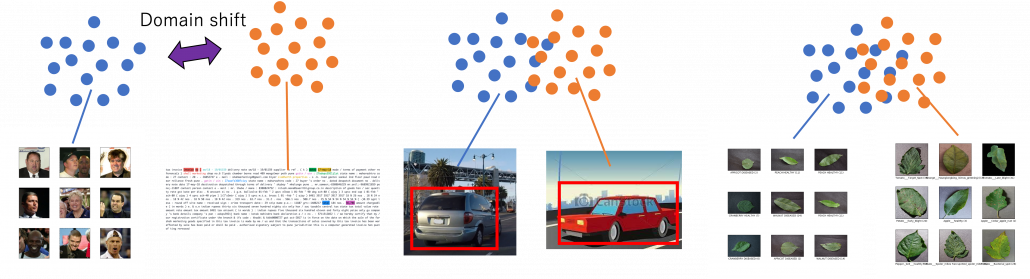
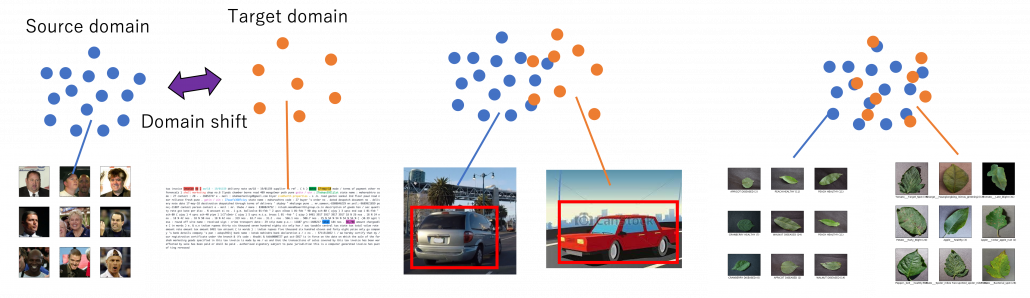
There is a more strict definition of a domain in machine learning, but all you have to know is it means in short a type of dataset used for a machine learning task. And different domains have a domain shift, which in short means differences in the domains. A text dataset and an image dataset have a domain shift. An image dataset of real objects and one with cartoon images also have a smaller domain shift. Even differences in lighting or angles of cameras would cause a domain shift. In general, even if a machine learning model is successful in tasks in a domain, even a domain shift which is trivial to humans declines performances of the model. In other words, intelligence learned in one domain is not straightforwardly applicable to another domain as humans can do. That is, even if you can recognize objects both a real and cartoon cars as a car, that is not necessarily true of machine learning models. As a family of techniques for tackling this problem, transfer learning makes a use of knowledge in a source domain (the dots in blue below), and apply the knowledge to a target domain. And usually, a source domain is assumed to be large and labeled, and on the other hand a target domain is assumed to be relatively small or even unlabeled. And tasks in a source or a target domain can be different. For example, CNN models trained on classification of ImageNet can be effectively used for object detection. Or BERT is trained on a huge corpus in a self-supervised way, but it is applicable to a variety of tasks in natural language processing (NLP).
*To people in computer vision fields, an explanation that BERT is a NLP version of pre-trained CNN would make the most sense. Just as a pre-trained CNN maps an image, arrangements of RGB pixels values, to a vector representing more of “meaning” of the image, BERT maps a text, a sequence of one-hot encodings, into a vector or a sequence of vectors in a semantic field useful for NLP.
Transfer learning is a very popular topic, and it is hard to arrange and explain types of existing techniques. I think that is because many people are tackling more or less the similar problems with slightly different approaches. For now I would like you to keep it in mind that there are roughly three points below to consider in transfer learning
- What to transfer
- When to transfer
- How to transfer
The answer of the second point above “When to transfer” is simply “when domains are more or less alike.” Transfer learning assume similarities between target and source domains to some extent. “How to transfer” is very task-specific, so this is not something I can explain briefly here. I think the first point “what to transfer” is the most important for now to avoid confusions about what “transfer learning” means. “What to transfer” in transfer learning is also classified to the three types below.
- Instance transfer (transferring datasets themselves)
- Feature transfer (transferring extracted features)
- Parameter transfer (transferring pre-trained models)
In fact, when you talk about already practical transfer learning techniques like using pre-trained CNN or BERT, they refer to only parameter transfer above. And please let me skip introducing it in this article. I am going to focus only on techniques related to video games in this article.
*I would like to give more practical introduction on for example BERT in one of my upcoming articles.
Domain adaptation or randomization
I first got interested in relations of video games and AI research because I was studying domain adaptation, which tackles declines of machine learning performance caused by a domain shift. Domain adaptation is sometimes used as a synonym to transfer learning. But compared to that general transfer learning also assume different tasks in different domains, domain adaptation assume the same task. Thus I would say domain adaptation is a subfield of transfer learning. There are several techniques for domain adaptation, and in this article I would like to take feature alignment as an example of frequently used approaches. Input datasets have a certain domain shift like blue and circle dots in the figure below. This domain shift cannot be changed if datasets themselves are not directly converted. Feature alignment make the domain shift smaller in a feature space after data being processed by the feature extractor. The features expressed as square dots in the figure are passed to task-specific networks just as normal machine learning. With sufficient labels in the source domain and with fewer or no labels in the target one, the task-specific networks are supervised. On the other hand, the features are also passed to the domain discriminator, and the discriminator predicts which domain the feature comes from. The domain discriminator is normally trained with supervision by classification loss, but the feature supervision is reversed when it trains the feature extractor. Due to the reversed supervision the feature extractor learns mix up features because that is worse for discriminating distinguishing the source or target domains. In this way, the feature extractor learns extract domain invariant features, that is more general features both domains have in common.
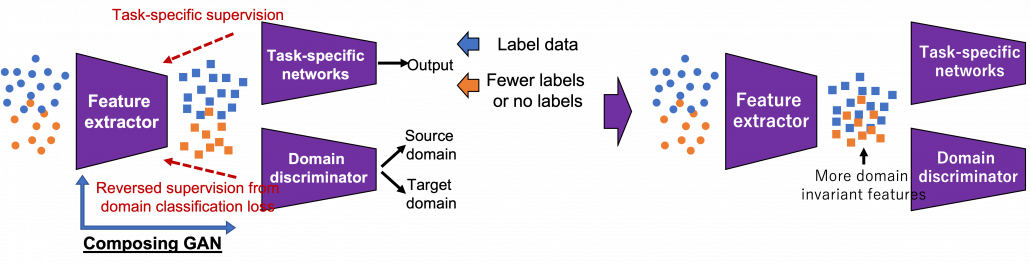
*The feature extractor and the domain discriminator is in a sense composing generative adversarial networks (GAN), which is often used in data generation. To know more about GAN, you could check for example this article.
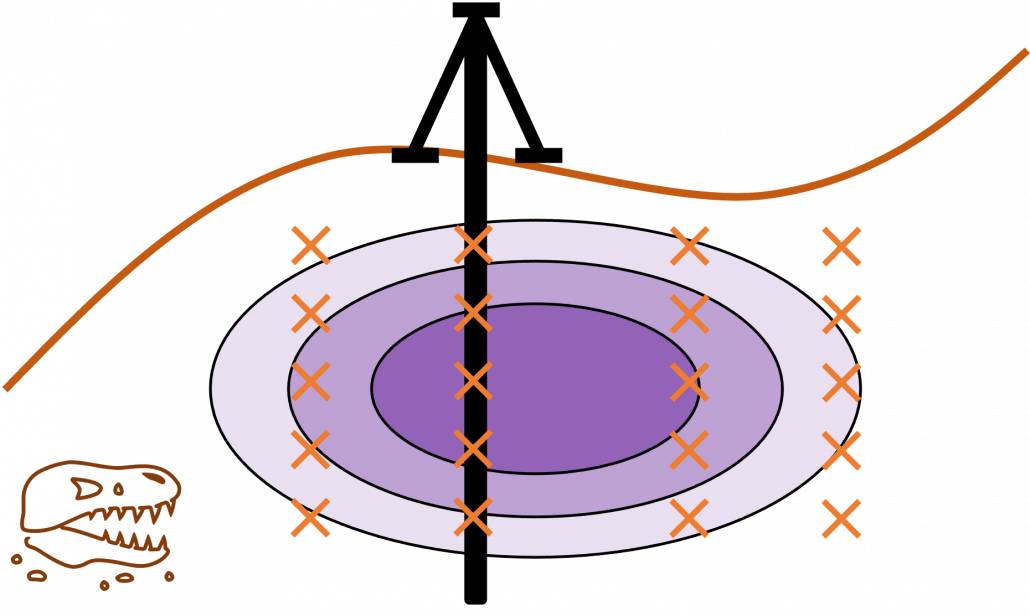
One of motivations behind domain adaptation is that it enables training AI tasks with synthetic datasets made by for example computer graphics because they are very easy to annotate and prepare labels necessary for machine learning tasks. In such cases, domain invariant features like curves or silhouettes are expected to learn. And learning computer vision tasks from GTA5 dataset which are applicable to Cityscapes dataset is counted as one of challenging tasks in papers on domain adaptation. GTA of course stands for “Grand Theft Auto,” the video open-world video game series. If this research continues successfully developing, that would imply possibilities of capability of teaching AI models to “see” only with video games. Imagine that a baby first learns to play Grand Theft Auto 5 above all and learns what cars, roads, and pedestrians are. And when you bring the baby outside, even they have not seen any real cars, they point to a real cars and people and say “car” and “pedestrians,” rather than “mama” or “dada.”
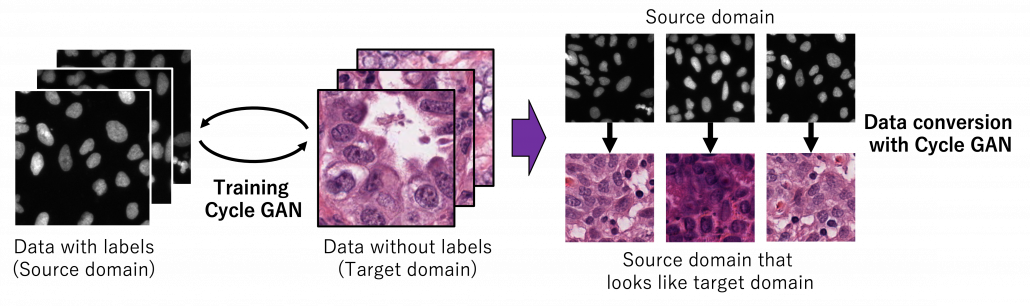
In order to enable more effective domain adaptation, Cycle GAN is often used. Cycle GAN is a technique to map texture in one domain to another domain. The figure below is an example of applying Cycle GAN on GTA5 dataset and Cityspaces Dataset, and by doing so shiny views from a car in Los Santos can be converted to dark and depressing scenes in Germany in winter. This instance transfer is often used in researches on domain adaptation.

Source: https://junyanz.github.io/CycleGAN/
Even if you mainly train depth estimation with data converted like above, the model can predict depth data of the real world domain without correct depth data. In the figure below, A is the target real data, B is the target domain converted like a source domain, and C is depth estimation on A.

Source: Abarghouei et al., “Real-Time Monocular Depth Estimation using Synthetic Data with Domain Adaptation via Image Style Transfer”, (2018), Computer Vision and Pattern Recognition Conference
Crowd counting is another field where making a labeled dataset with video games is very effective. A MOD for making a crowd arbitrarily is released, and you can make labeled datasets like below.

Source: https://gjy3035.github.io/GCC-CL/
*Introducing GTA mod into research is hilarious. You first need to buy PC software of Grand Theft Auto 5 and gaming PC at first. And after finishing the first tutorial in the video game, you need to find a place to place a camera, which looks nothing but just playing video games with public money.
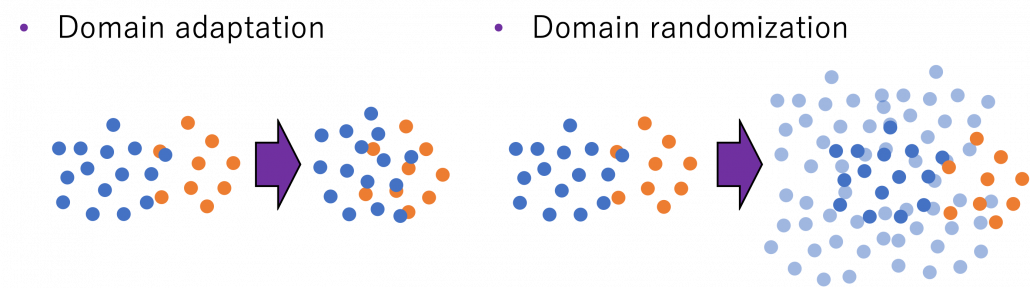
Domain adaptation problems I mentioned are more of matters of how to let computers “see” the world with computer simulations. But the gap between the simulational worlds and the real world does not exist only in visual ways like in CV. How robots or vehicles are parametrized in computers also have some gaps from the real world, so even if you replace only observations with simulations, it would be hard to train AI. But surprisingly, some researches have already succeeded in training robot arms only with computer simulations. An approach named domain randomization seems to be more or less successful in training robot arms only with computer simulations and apply the learned experience to the real world. Compared to domain adaptation aligned source domain to the target domain, domain randomization is more of expanding the source domain by changing various parameters of the source domain. And the target domain, namely robot arms in the real world is in the end included in the expanded source domain. And such expansions are relatively easy with computer simulations.
For example a paper “Closing the Sim-to-Real Loop: Adapting Simulation Randomization with Real World Experience” proposes a technique to reflect real world feed back to simulations in domain randomization, and this pipeline enables a robot arm to do real world tasks in a few iteration of real world trainings.

Based on: Chebotar et al. , “Closing the Sim-to-Real Loop: Adapting Simulation Randomization with Real World Experience”, (2019), International Conference on Robotics and Automation
As the video shows, the ideas of training a robot with computer simulations is becoming more realistic.
The future of games for AI
I have been emphasizing how useful video games are in AI researches, but I am not sure if how much the field purely rely on video games like it is doing especially on RL. Autonomous driving is a huge research field, and modern video games like Grand Thef Auto are already good driving simulations in urban areas. But other realistic simulations like CARLA have been developed independent of video games. And in a paper “Exploring the Limitations of Behavior Cloning for Autonomous Driving,” some limitations of training self-driving cars in the simulation are reported. And some companies like Waymo switched to recurrent neural networks (RNN) for self-driving cars. It is natural that fields like self-driving, where errors of controls can be fatal, are not so optimistic about adopting RL for now.
But at the same time, Microsoft bought a Project Bonsai, which is aiming at applying RL to real world tasks. Also Microsoft has Project Malmo or AirSim, which respectively use Minecraft or Unreal Engine for AI reseraches. Also recently the news that Microsoft bought Activision Blizzard was a sensation last year, and media’s interests were mainly about metaverse or subscription service of video games. But Microsoft also bouth Zenimax Media, is famous for open world like Fallout or Skyrim series. Given that these are under Microsoft, it seems the company has been keen on merging AI reserach and developing video games.
As I briefly explained, video games can be expanded with procedural AI technologies. In the future AI might be trained in video game worlds, which are augmented with another form of AI. Combinations of transfer learning and game AI might possibly be a family of self-supervising technologies, like an octopus growing by eating its own feet. At least the biggest advantage of the video game industry is, even technologies themselves do not make immediate profits, researches on them are fueled by increasing video game fans all over the world. This is a kind of my sci-fi imagination of the world. Though I am not sure which is more efficient to manually design controls of robots or training AI in such indirect ways. And I prefer to enhance physical world to metaverse. People should learn to put their controllers someday and to enhance the real world. Highly motivated by “Elden Ring” I wrote this article. Some readers might got interested in the idea of transferring experiences in computer simulations to the real world. I am also going to write about transfer learning in general that is helpful in practice.
[1]三宅 陽一郎, 「ゲームAI技術入門 – 広大な人工知能の世界を体系的に学ぶ」, (2019), 技術評論社
Miyake Youichiro, “An Introduction to Game AI – Systematically Learning the Wide World of Artificial Intelligence”, (2019), Gijutsu-hyoron-sya
[2]三宅 陽一郎, 「21世紀に“洋ゲー”でゲームAIが遂げた驚異の進化史。その「敗戦」から日本のゲーム業界が再び立ち上がるには?【AI開発者・三宅陽一郎氏インタビュー】」, (2017), 電ファミニコゲーマー
Miyake Youichiro, ”The history of Astonishing Game AI which Western Video Games in 21st Century Traced. What Should the Japanese Video Game Industry Do to Recover from the ‘Defeat in War’? [An Interview with an AI Developer Miyake Yoichiro]”
[3]Rob Leane, “Dark Souls named greatest game of all time at Golden Joysticks”, (2021), RadioTimes.com
[4] Matsui Kota, “Recent Advances on Transfer Learning and Related Topics (ver.2)”, (2019), RIKEN AIP Data Driven Biomedical Science Team
[3] Sebastian Ruder, “Transfer Learning – Machine Learning’s Next Frontier”, (2017)
https://ruder.io/transfer-learning/
[4] Matsui Kota, “Recent Advances on Transfer Learning and Related Topics (ver.2)”, (2019), RIKEN AIP Data Driven Biomedical Science Team
[5] Youichiro Miyake, “AI Technologies in Game Industry”, (2020)
https://www.slideshare.net/youichiromiyake/ai-technologies-in-game-industry-english
[6] Michael Booth, “Replayable Cooperative Game Design: Left 4 Dead”, (2009), Valve
[7] Marcin Gollent, “Landscape creation and rendering in REDengine 3”, (2014), Game Developers Conference
https://www.gdcvault.com/play/1020197/Landscape-Creation-and-Rendering-in
* I make study materials on machine learning, sponsored by DATANOMIQ. I do my best to make my content as straightforward but as precise as possible. I include all of my reference sources. If you notice any mistakes in my materials, including grammatical errors, please let me know (email: yasuto.tamura@datanomiq.de). And if you have any advice for making my materials more understandable to learners, I would appreciate hearing it.
 DATANOMIQ
DATANOMIQ


 by adjusting parameters
by adjusting parameters  . And the parameters
. And the parameters  is minimized. If it is a supervised learning, the a value of a loss function is denoted
is minimized. If it is a supervised learning, the a value of a loss function is denoted 
 , and it gets smaller as
, and it gets smaller as  gets closer to
gets closer to  . That is,
. That is,  via
via  . And in a case of unsupervised learning, a loss function is
. And in a case of unsupervised learning, a loss function is  , which is often heuristically handcrafted.
, which is often heuristically handcrafted.


 of a butterfly below with a label of
of a butterfly below with a label of  can be converted to more than 6 images. This corresponds to getting a converted
can be converted to more than 6 images. This corresponds to getting a converted  in the machine learning outline in the last section. And this process is the same as increasing the size of a dataet
in the machine learning outline in the last section. And this process is the same as increasing the size of a dataet  . And one point you have to be careful is, you must not change
. And one point you have to be careful is, you must not change  Here let me take an example of data augmentation technique that would be contrary to your intuition. A technique named mixup literally mix up data with different classes and their labels. In classification problems, labels are expressed as one-hot vectors, that is only an element corresponding to a correct element is
Here let me take an example of data augmentation technique that would be contrary to your intuition. A technique named mixup literally mix up data with different classes and their labels. In classification problems, labels are expressed as one-hot vectors, that is only an element corresponding to a correct element is  and the others are
and the others are  . In a case of binary dog-or-cat classification, each label is
. In a case of binary dog-or-cat classification, each label is  or
or  , respectively. In data augmentation, distorting data too much is a taboo because label data is contaminated, but in mixup you literally mix up labels. Randomly choosing a two inputs
, respectively. In data augmentation, distorting data too much is a taboo because label data is contaminated, but in mixup you literally mix up labels. Randomly choosing a two inputs  and a number
and a number ![\lambda \in [0,1]](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-ca07e0e397d614f2de6877183c93fa3a_l3.png "Rendered by QuickLaTeX.com") , you prepare a input and label pair
, you prepare a input and label pair  . The figure below is an example of a mixing up a cat input and a dog input, and corresponding labels. It is known augmenting training data like this improves classification performances. It is said this is partly due to machine learning models effectively learning decision boundaries. In classification ambiguous inputs are bottlenecks, so learning to giving ambiguous outputs to ambiguous inputs can enhance classification abilities.
. The figure below is an example of a mixing up a cat input and a dog input, and corresponding labels. It is known augmenting training data like this improves classification performances. It is said this is partly due to machine learning models effectively learning decision boundaries. In classification ambiguous inputs are bottlenecks, so learning to giving ambiguous outputs to ambiguous inputs can enhance classification abilities.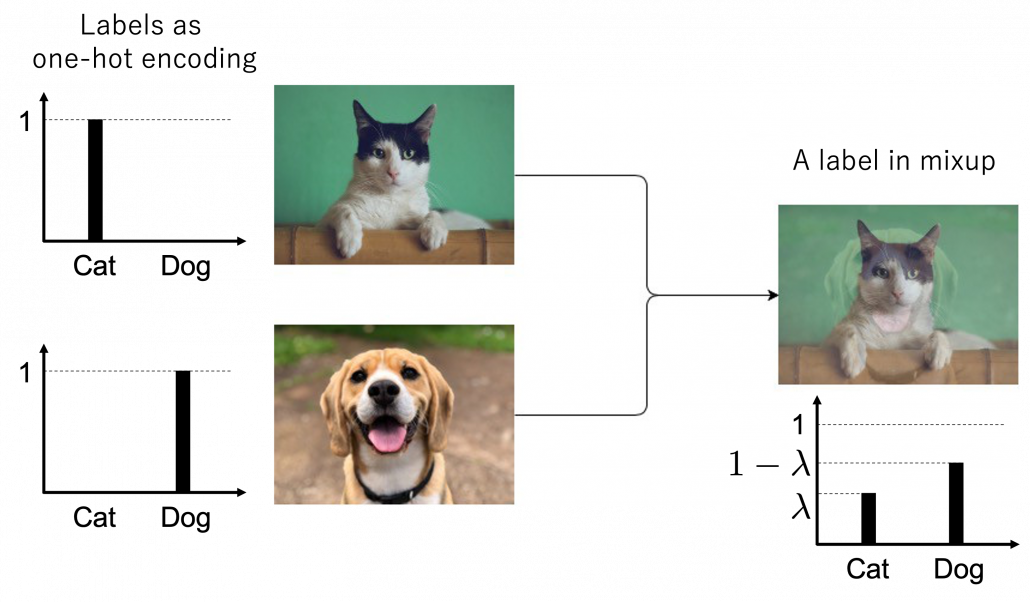
 for a
for a  . When you want to regress the data with as few samples as possible, data points should be sampled from the parts with great uncertainties. And by doing so, you can see that the data is regressed efficiently with few samples.
. When you want to regress the data with as few samples as possible, data points should be sampled from the parts with great uncertainties. And by doing so, you can see that the data is regressed efficiently with few samples.
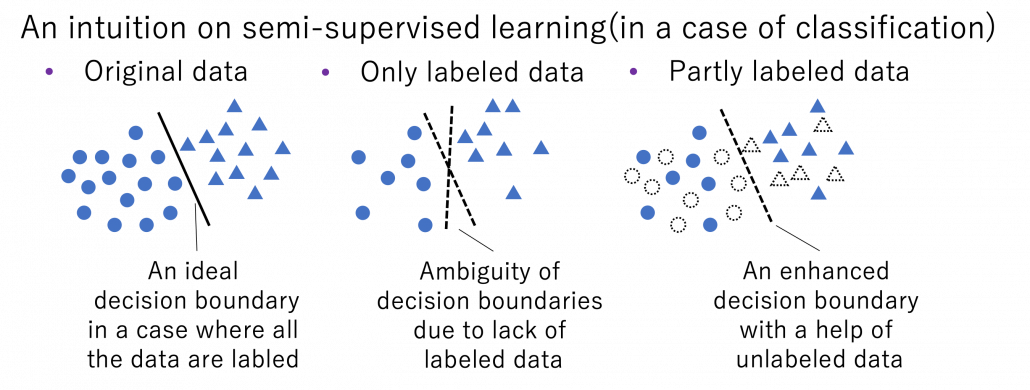
 for a labeled dataset
for a labeled dataset  . In semi-supervised learning, we assume that usually a bigger unsupervised dataset
. In semi-supervised learning, we assume that usually a bigger unsupervised dataset  is available in the same domain. And semi-supervised learning optimize
is available in the same domain. And semi-supervised learning optimize  after designing a loss function
after designing a loss function  for the unlabeled dataset. There are following 3 major ways of semi-supervised learning depending on how you design a
for the unlabeled dataset. There are following 3 major ways of semi-supervised learning depending on how you design a  in
in  . And training
. And training  and
and  give out a consistent output.
give out a consistent output.
 images in a dataset with a pre-trained backbone CNN, and I got corresponding
images in a dataset with a pre-trained backbone CNN, and I got corresponding  dimensional vectors, that is a
dimensional vectors, that is a  tensor. And I applied t-SNE to reduce its dimension from
tensor. And I applied t-SNE to reduce its dimension from  and got a
and got a  tensor. The figure below shows arrangements of input images in the 2 dimensional space. As you can see, semantically similar images get closer.
tensor. The figure below shows arrangements of input images in the 2 dimensional space. As you can see, semantically similar images get closer.
 , which effective for each task.
, which effective for each task. 
 DATANOMIQ
DATANOMIQ