
Big Data mit Hadoop und Map Reduce!
Foto von delfi de la Rua auf Unsplash.
Hadoop ist ein Softwareframework, mit dem sich große Datenmengen auf verteilten Systemen schnell verarbeiten lassen. Es verfügt über Mechanismen, welche eine stabile und fehlertolerante Funktionalität sicherstellen, sodass das Tool für die Datenverarbeitung im Big Data Umfeld bestens geeignet ist. In diesen Fällen ist eine normale relationale Datenbank oft nicht ausreichend, um die unstrukturierten Datenmengen kostengünstig und effizient abzuspeichern.
Unterschiede zwischen Hadoop und einer relationalen Datenbank
Hadoop unterscheidet sich in einigen grundlegenden Eigenschaften von einer vergleichbaren relationalen Datenbank.
| Eigenschaft | Relationale Datenbank | Hadoop |
| Datentypen | ausschließlich strukturierte Daten | alle Datentypen (strukturiert, semi-strukturiert und unstrukturiert) |
| Datenmenge | wenig bis mittel (im Bereich von einigen GB) | große Datenmengen (im Bereich von Terrabyte oder Petabyte) |
| Abfragesprache | SQL | HQL (Hive Query Language) |
| Schema | Statisches Schema (Schema on Write) | Dynamisches Schema (Schema on Read) |
| Kosten | Lizenzkosten je nach Datenbank | Kostenlos |
| Datenobjekte | Relationale Tabellen | Key-Value Pair |
| Skalierungstyp | Vertikale Skalierung (Computer muss hardwaretechnisch besser werden) | Horizontale Skalierung (mehr Computer können dazugeschaltet werden, um Last abzufangen) |
Vergleich Hadoop und Relationale Datenbank
Bestandteile von Hadoop
Das Softwareframework selbst ist eine Zusammenstellung aus insgesamt vier Komponenten.
Hadoop Common ist eine Sammlung aus verschiedenen Modulen und Bibliotheken, welche die anderen Bestandteile unterstützt und deren Zusammenarbeit ermöglicht. Unter anderem sind hier die Java Archive Dateien (JAR Files) abgelegt, die zum Starten von Hadoop benötigt werden. Darüber hinaus ermöglicht die Sammlung die Bereitstellung von grundlegenden Services, wie beispielsweise das File System.
Der Map-Reduce Algorithmus geht in seinen Ursprüngen auf Google zurück und hilft komplexe Rechenaufgaben in überschaubarere Teilprozesse aufzuteilen und diese dann über mehrere Systeme zu verteilen, also horizontal zu skalieren. Dadurch verringert sich die Rechenzeit deutlich. Am Ende müssen die Ergebnisse der Teilaufgaben wieder zu seinem Gesamtresultat zusammengefügt werden.
Der Yet Another Resource Negotiator (YARN) unterstützt den Map-Reduce Algorithmus, indem er die Ressourcen innerhalb eines Computer Clusters im Auge behält und die Teilaufgaben auf die einzelnen Rechner verteilt. Darüber hinaus ordnet er den einzelnen Prozessen die Kapazitäten dafür zu.
Das Hadoop Distributed File System (HDFS) ist ein skalierbares Dateisystem zur Speicherung von Zwischen- oder Endergebnissen. Innerhalb des Clusters ist es über mehrere Rechner verteilt, um große Datenmengen schnell und effizient verarbeiten zu können. Die Idee dahinter war, dass Big Data Projekte und Datenanalysen auf großen Datenmengen beruhen. Somit sollte es ein System geben, welches die Daten auch stapelweise speichert und dadurch schnell verarbeitet. Das HDFS sorgt auch dafür, dass Duplikate von Datensätzen abgelegt werden, um den Ausfall eines Rechners verkraften zu können.
Map Reduce am Beispiel
Angenommen wir haben alle Teile der Harry Potter Romane in Hadoop PDF abgelegt und möchten nun die einzelnen Wörter zählen, die in den Büchern vorkommen. Dies ist eine klassische Aufgabe bei der uns die Aufteilung in eine Map-Funktion und eine Reduce Funktion helfen kann.
Bevor es die Möglichkeit gab, solche aufwendigen Abfragen auf ein ganzes Computer-Cluster aufzuteilen und parallel berechnen zu können, war man gezwungen, den kompletten Datensatz nacheinander zu durchlaufen. Dadurch wurde die Abfragezeit auch umso länger, umso größer der Datensatz wurde. Der einzige Weg, um die Ausführung der Funktion zu beschleunigen ist es, einen Computer mit einem leistungsfähigeren Prozessor (CPU) auszustatten, also dessen Hardware zu verbessern. Wenn man versucht, die Ausführung eines Algorithmus zu beschleunigen, indem man die Hardware des Gerätes verbessert, nennt man das vertikale Skalieren.
Mithilfe von MapReduce ist es möglich eine solche Abfrage deutlich zu beschleunigen, indem man die Aufgabe in kleinere Teilaufgaben aufsplittet. Das hat dann wiederum den Vorteil, dass die Teilaufgaben auf viele verschiedene Computer aufgeteilt und von ihnen ausgeführt werden kann. Dadurch müssen wir nicht die Hardware eines einzigen Gerätes verbessern, sondern können viele, vergleichsweise leistungsschwächere, Computer nutzen und trotzdem die Abfragezeit verringern. Ein solches Vorgehen nennt man horizontales Skalieren.
Kommen wir zurück zu unserem Beispiel: Bisher waren wir bildlich so vorgegangen, dass wir alle Harry Potter Teile gelesen haben und nach jedem gelesenen Wort die Strichliste mit den einzelnen Wörtern einfach um einen Strich erweitert haben. Das Problem daran ist, dass wir diese Vorgehensweise nicht parallelisieren können. Angenommen eine zweite Person will uns unterstützen, dann kann sie das nicht tun, weil sie die Strichliste, mit der wir gerade arbeiten, benötigt, um weiterzumachen. Solange sie diese nicht hat, kann sie nicht unterstützen.
Sie kann uns aber unterstützen, indem sie bereits mit dem zweiten Teil der Harry Potter Reihe beginnt und eine eigene Strichliste nur für das zweite Buch erstellt. Zum Schluss können wir dann alle einzelnen Strichlisten zusammenführen und beispielsweise die Häufigkeit des Wortes “Harry” auf allen Strichlisten zusammenaddieren.
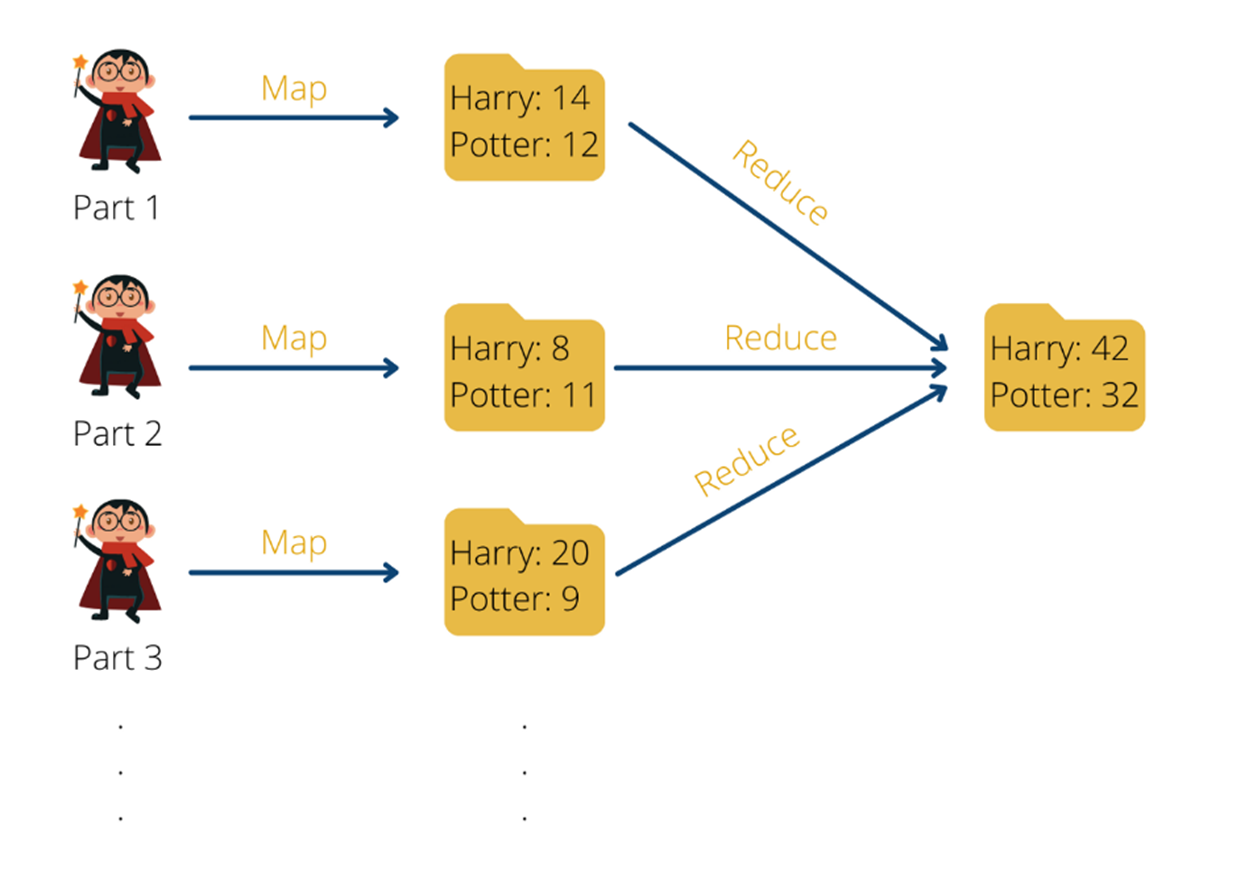
MapReduce am Beispiel von Wortzählungen in Harry Potter Büchern | Source: Data Basecamp
Dadurch lässt sich die Aufgabe auch relativ einfach horizontal skalieren, indem jeweils eine Person pro Harry Potter Buch arbeitet. Wenn wir noch schneller arbeiten wollen, können wir auch mehrere Personen mit einbeziehen und jede Person ein einziges Kapitel bearbeiten lassen. Am Schluss müssen wir dann nur alle Ergebnisse der einzelnen Personen zusammennehmen, um so zu einem Gesamtergebnis zu gelangen.
Das ausführliche Beispiel und die Umsetzung in Python findest Du hier.
Aufbau eines Hadoop Distributed File Systems
Der Kern des Hadoop Distributed File Systems besteht darin die Daten auf verschiedene Dateien und Computer zu verteilen, sodass Abfragen schnell bearbeitet werden können und der Nutzer keine langen Wartezeiten hat. Damit der Ausfall einer einzelnen Maschine im Cluster nicht zum Verlust der Daten führt, gibt es gezielte Replikationen auf verschiedenen Computern, um eine Ausfallsicherheit zu gewährleisten.
Hadoop arbeitet im Allgemeinen nach dem sogenannten Master-Slave-Prinzip. Innerhalb des Computerclusters haben wir einen Knoten, der die Rolle des sogenannten Masters übernimmt. Dieser führt in unserem Beispiel keine direkte Berechnung durch, sondern verteilt lediglich die Aufgaben auf die sogenannten Slave Knoten und koordiniert den ganzen Prozess. Die Slave Knoten wiederum lesen die Bücher aus und speichern die Worthäufigkeit und die Wortverteilung.
Dieses Prinzip wird auch bei der Datenspeicherung genutzt. Der Master verteilt Informationen aus dem Datensatz auf verschiedenen Slave Nodes und merkt sich, auf welchen Computern er welche Partitionen abgespeichert hat. Dabei legt er die Daten auch redundant ab, um Ausfälle kompensieren zu können. Bei einer Abfrage der Daten durch den Nutzer entscheidet der Masterknoten dann, welche Slaveknoten er anfragen muss, um die gewünschten Informationen zu erhalten.






Leave a Reply
Want to join the discussion?Feel free to contribute!