
ID3-Algorithmus: Ein Rechenbeispiel
Dieser Artikel ist Teil 3 von 4 der Artikelserie Maschinelles Lernen mit Entscheidungsbaumverfahren und nun wollen wir einen Entscheidungsbaum aus Daten herleiten, jedoch ohne Programmierung, sondern direkt auf Papier (bzw. HTML :-).
Folgender Datensatz sei gegeben:
| Zeile | Kundenart | Zahlungsgeschwindigkeit | Kauffrequenz | Herkunft | Zahlungsmittel: Rechnung? |
| 1 | Neukunde | niedrig | niedrig | Inland | false |
| 2 | Neukunde | niedrig | niedrig | Ausland | false |
| 3 | Stammkunde | niedrig | niedrig | Inland | true |
| 4 | Normalkunde | mittel | niedrig | Inland | true |
| 5 | Normalkunde | hoch | hoch | Inland | true |
| 6 | Normalkunde | hoch | hoch | Ausland | false |
| 7 | Stammkunde | hoch | hoch | Ausland | true |
| 8 | Neukunde | mittel | niedrig | Inland | false |
| 9 | Neukunde | hoch | hoch | Inland | true |
| 10 | Normalkunde | mittel | hoch | Inland | true |
| 11 | Neukunde | mittel | hoch | Ausland | true |
| 12 | Stammkunde | mittel | niedrig | Ausland | true |
| 13 | Stammkunde | niedrig | hoch | Inland | true |
| 14 | Normalkunde | mittel | niedrig | Ausland | false |
Gleich vorweg ein Disclaimer: Der Datensatz ist natürlich überaus klein, ja gerade zu winzig. Dafür würden wir in der Praxis niemals einen Machine Learning Algorithmus einsetzen. Dennoch bleiben wir besser übersichtlich und nachvollziehbar mit diesen 14 Zeilen. Das Lernziel dieser Übung ist es, ein Gefühl für die Erstellung von Entscheidungsbäumen zu erhalten.
Zu beachten ist ferner, dass dieser Datensatz bereits aggregiert ist, denn eigentlich nummerisch abbildbare Daten wurden in Klassen zusammengefasst.
Das Ziel:
Der Datensatz spielt wieder, welchem Kunden (ID) bisher die Zahlung per Rechnung erlaubt und nicht widerrufen wurde. Das Ziel soll sein, eine Vorhersage darüber zu machen zu können, wann ein Kunde per Rechnung zahlen darf und wann nicht (dann per Vorkasse).
Der Algorithmus:
Wir verwenden den ID3-Algorithmus in seiner Reinform. Der ID3-Algorithmus ist der gängigste Algorithmus zum Aufbau datengetriebener Entscheidungsbäume und es gibt mehrere Abwandlungen. Die Vorgehensweise des Algorithmus wird in dem Teil 2 der Artikelserie Entscheidungsbaum-Algorithmus ID3 erläutert.
1. Schritt: Auswählen des Attributes mit dem höchsten Informationsgewinn
Der Informationsgewinn eines Attributes ( ) im Sinne des ID3-Algorithmus ist die Differenz aus der Entropie (
) im Sinne des ID3-Algorithmus ist die Differenz aus der Entropie ( ) (siehe Teil 1 der Artikelserie Entropie, ein Maß für die Unreinheit in Daten) des gesamten Datensatzes (
) (siehe Teil 1 der Artikelserie Entropie, ein Maß für die Unreinheit in Daten) des gesamten Datensatzes ( ) und der Summe aus den gewichteten Entropien des Attributes für jeden einzelnen Wert (Value
) und der Summe aus den gewichteten Entropien des Attributes für jeden einzelnen Wert (Value  ), der im Attribut vorkommt:
), der im Attribut vorkommt:

1.1 Gesamt-Entropie des Datensatzes berechnen
Erstmal schauen wir uns die Entropie des gesamten Datensatzes an. Die Entropie bezieht sich dabei auf das gewünschte Klassifikationsergebnis, also ist die Zahlung via Rechnung erlaubt oder nicht? Diese Frage wird entweder mit true oder false beantwortet.

1.2 Berechnung der Informationsgewinne aller Attribute
Berechnen wir nun also die Informationsgewinne über alle Spalten.
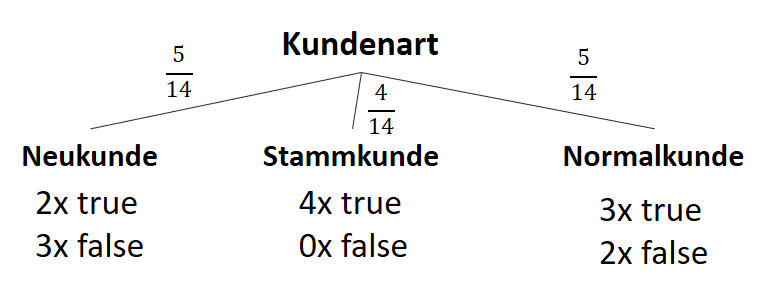
| Attribut | Subset | Count(true) | Count(false) |
| Kundenart | “Neukunde” | 2 | 3 |
| “Stammkunde” | 4 | 0 | |
| “Normalkunde” | 3 | 2 |
Wir zerlegen den gesamten Datensatz gedanklich in drei Kategorien der Kundenart und berechnen die Entropie bezogen auf das Klassifikationsziel:



Zur Erinnerung, der Informationsgewinn (Information Gain) wird wie folgt berechnet:
![\[ IG(S, A_{Kundenart}) = - \sum_{i=1}^n \frac{\bigl|S_i\bigl|}{\bigl|S\bigl|} \cdot H(S_i) \]](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-6380891cc61bb855d4208480091fdef0_l3.png "Rendered by QuickLaTeX.com")
Angewendet auf das Attribut “Kundenart”…
![\[ IG(S, A_{Kundenart}) = H(S) - \frac{\bigl|S_{Neukunde}\bigl|}{\bigl|S\bigl|} \cdot H(S_{Neukunde}) - \frac{\bigl|S_{Stammkunde}\bigl|}{\bigl|S\bigl|} \cdot H(S_{Stammkunde}) - \frac{\bigl|S_{Normalkunde}\bigl|}{\bigl|S\bigl|} \cdot H(S_{Normalkunde}) \]](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-b3c9d40c7a171fd7b9e5fbed0aed041a_l3.png "Rendered by QuickLaTeX.com")
… erhalten wir der Formal nach folgenden Informationsgewinn:
![\[ IG(S, A_{Kundenart}) = 0.94 - \frac{5}{14} \cdot 0.97 - \frac{4}{14} \cdot 0.00 - \frac{5}{14} \cdot 0.97 = 0.247 \]](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-33144ba5df6858348666daef5a5cf5d3_l3.png "Rendered by QuickLaTeX.com")
Nun für die weiteren Spalten:
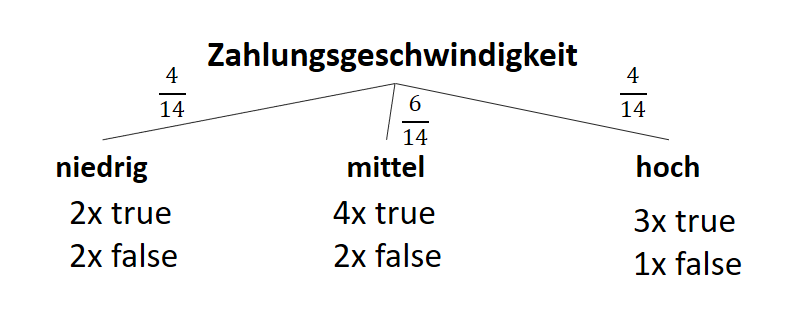
| Attribut | Subset | Count(true) | Count(false) |
| Zahlungsgeschwindigkeit | “niedrig” | 2 | 2 |
| “mittel” | 4 | 2 | |
| “schnell” | 3 | 1 |
Entropien für die “Zahlungsgeschwindigkeit”:



So berechnen wir wieder den Informationsgewinn:
![\[ IG(S, A_{Zahlungsgeschwindigkeit}) = H(S) - \frac{\bigl|S_{niedrig}\bigl|}{\bigl|S\bigl|} \cdot H(S_{niedrig}) - \frac{\bigl|S_{mittel}\bigl|}{\bigl|S\bigl|} \cdot H(S_{mittel}) - \frac{\bigl|S_{schnell}\bigl|}{\bigl|S\bigl|} \cdot H(S_{schnell}) \]](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-a80e61c0adf9dff8ca219a28bce359cd_l3.png "Rendered by QuickLaTeX.com")
Einsatzen und ausrechnen:
![\[ IG(S, A_{Zahlungsgeschwindigkeit}) = 0.94 - \frac{4}{14} \cdot 1.00 - \frac{6}{14} \cdot 0.92 - \frac{4}{14} \cdot 0.81 = 0.029 \]](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-ed4f1d54de66a9956bc2c1e53a0de2e8_l3.png "Rendered by QuickLaTeX.com")
Und nun für die Spalte “Kauffrequenz”:

| Attribut | Subset | Count(true) | Count(false) |
| Kauffrequenz | “niedrig” | 3 | 4 |
| “hoch” | 6 | 1 |
Entropien:


Informationsgewinn:
![\[ IG(S, A_{Kauffrequenz}) = H(S) - \frac{\bigl|S_{niedrig}\bigl|}{\bigl|S\bigl|} \cdot H(S_{niedrig}) - \frac{\bigl|S_{hoch}\bigl|}{\bigl|S\bigl|} \cdot H(S_{hoch}) \]](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-cbcfb6a5b118cfc2df4185ef03e4e1dd_l3.png "Rendered by QuickLaTeX.com")
Einsetzen und Ausrechnen:
![\[ IG(S, A_{Kauffrequenz}) = 0.94 - \frac{7}{14} \cdot 1.00 - \frac{7}{14} \cdot 0.59 = 0.150 \]](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-dc9f358f2d2cd071b815b3f6c571f813_l3.png "Rendered by QuickLaTeX.com")
Und last but not least die Spalte “Herkunft”:
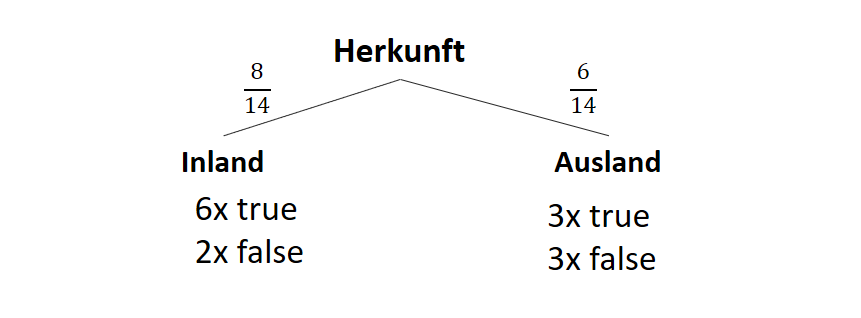
| Attribut | Subset | Count(true) | Count(false) |
| Herkunft | “Inland” | 6 | 2 |
| “Ausland” | 3 | 3 |
Entropien:


Informationsgewinn:
![\[ IG(S, A_{Herkunft}) = H(S) - \frac{\bigl|S_{Inland}\bigl|}{\bigl|S\bigl|} \cdot H(S_{Inland}) - \frac{\bigl|S_{Ausland}\bigl|}{\bigl|S\bigl|} \cdot H(S_{Ausland}) \]](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-3a0ecd4412fa44ca26c64ea16aa536d1_l3.png "Rendered by QuickLaTeX.com")
Einsetzen und Ausrechnen:
![\[ IG(S, A_{Herkunft}) = 0.94 - \frac{8}{14} \cdot 0.81 - \frac{6}{14} \cdot 1.00 = 0.05 \]](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-ab4db275a73c092813d00f26ef4c1183_l3.png "Rendered by QuickLaTeX.com")
2. Schritt: Anlegen des Wurzel-Knotens
Der Informationsgewinn ist für das Attribut “Kundenart” am größten, daher entscheiden wir uns im Sinne des ID3-Algorithmus für dieses Attribut als Wurzel-Knoten.
 3. Schritt: Rekursive Wiederholung (!!!)
3. Schritt: Rekursive Wiederholung (!!!)
Nun stellt sich natürlich die Frage: Wie geht es weiter?
Der Algorithmus kann eigentlich nur eines: Einen Wurzelknoten finden. Diesen Vorgang müssen wir nun nur noch rekursiv wiederholen, und das tun wir wie folgt.
Der Datensatz wurde bereits aufgeteilt in die drei Kundenarten. Für jede Kundenart ergibt sich jeweils ein Subset mit den verbleibenden Attributen. Für alle drei Subsets erstellen wir dann wieder einen Wurzelknoten, so dass ein neuer Ast entsteht.
3.1 Erster Rekursionsschritt
Machen wir also weiter und bestimmen wir das nächste Attribut nach der Kundenart, für die Fälle Kundenart = “Neukunde”:
| Zeile | Kundenart | Zahlungsgeschwindigkeit | Kauffrequenz | Herkunft | Zahlungsmittel: Rechnung? |
| 1 | Neukunde | niedrig | niedrig | Inland | false |
| 2 | Neukunde | niedrig | niedrig | Ausland | false |
| 8 | Neukunde | mittel | niedrig | Inland | false |
| 9 | Neukunde | hoch | hoch | Inland | true |
| 11 | Neukunde | mittel | hoch | Ausland | true |
Die Entropie des Gesamtdatensatzes (ja, es ist für diesen Schritt betrachtet der gesamte Datensatz!) ist wie folgt:
Die Entropie ist weit weg von einer bestimmten Wahrscheinlichkeit (nahe der Gleichverteilung). Daher müssen wir hier nochmal ansetzen und losrechnen:
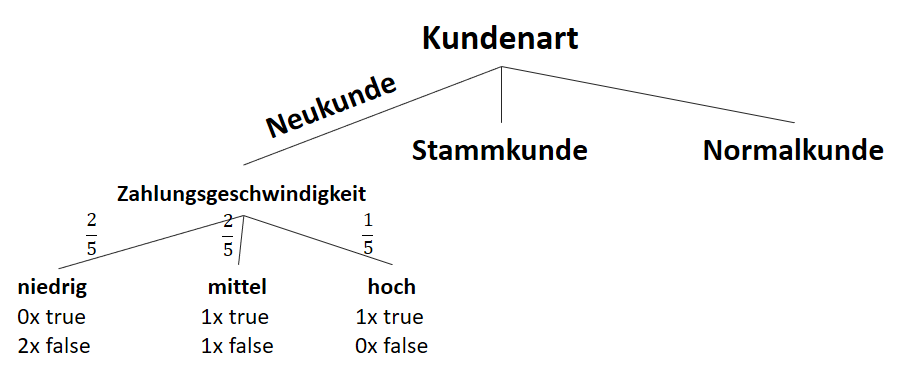 Entropien für “Zahlungsgeschwindigkeit” bei Neukunden:
Entropien für “Zahlungsgeschwindigkeit” bei Neukunden:



Informationsgewinn des Attributes “Zahlungsgeschwindigkeit” bei Neukunden:
![\[ IG(S_{Neukunde},A_{Zahlungsgeschwindigkeit}) = 0.97 - \frac{3}{5} \cdot 0.00 - \frac{2}{5} \cdot 1.00 - \frac{1}{5} \cdot 0.00 = 0.57 \]](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-35c0216b5e69ee73831980225531ecc7_l3.png "Rendered by QuickLaTeX.com")
Betrachtung der Spalte “Kauffrequenz” bei Neukunden:
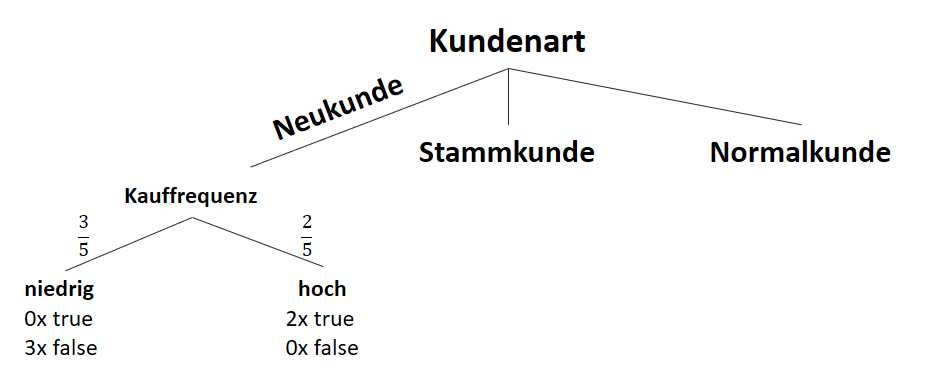
Entropien für “Kauffrequenz” bei Neukunden:
Informationsgewinn des Attributes “Kauffrequenz” bei Neukunden:
![\[ IG(S_{Neukunde},A_{Kauffrequenz}) = 0.97 - \frac{3}{5} \cdot 0.00 - \frac{2}{5} \cdot 0.00 = 0.97 \]](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-5f6849e7156c9505f53b484a8e7f505a_l3.png "Rendered by QuickLaTeX.com")
Betrachtung der Spalte “Herkunft” bei Neukunden:
 Entropien für “Herkunft” bei Neukunden:
Entropien für “Herkunft” bei Neukunden:


Informationsgewinn des Attributes “Herkunft” bei Neukunden:
![\[ IG(S_{Neukunde},A_{Herkunft}) = 0.97 - \frac{3}{5} \cdot 0.92 - \frac{2}{5} \cdot 1.00 = 0.018 \]](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-890f306c397d0ac28cbbd9a316eb049b_l3.png "Rendered by QuickLaTeX.com")
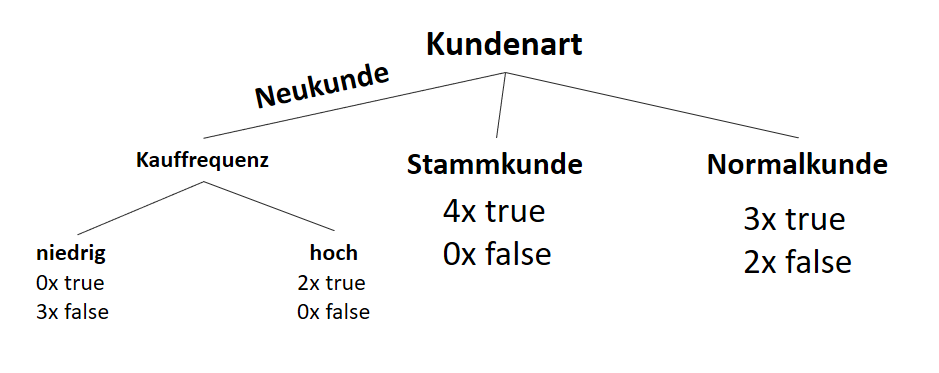
Wir entscheiden uns also für das Attribut “Kauffrequenz” als Ast nach der Entscheidung “Neukunde”, denn dieses Attribut bring uns den größten Informationsgewinn und trennt uns die Unterscheidung für oder gegen das Zahlungsmittel “Rechnung” eindeutig auf.
3.1 Zweiter Rekursionsschritt
Was passiert mit der Kundenart “Stammkunde”?
| Zeile | Kundenart | Zahlungsgeschwindigkeit | Kauffrequenz | Herkunft | Zahlungsmittel: Rechnung? |
| 3 | Stammkunde | niedrig | niedrig | Inland | true |
| 7 | Stammkunde | hoch | hoch | Ausland | true |
| 12 | Stammkunde | mittel | niedrig | Ausland | true |
| 13 | Stammkunde | niedrig | hoch | Inland | true |
Die Antwort ist einfach: Nichts!
Wer ein Stammkunde ist, dem wurde stets die Zahlung per Rechnung erlaubt.

3.1 Dritter Rekursionsschritt
Fehlt nun nur noch die Frage nach der Unterscheidung von Normalkunden.
| Zeile | Kundenart | Zahlungsgeschwindigkeit | Kauffrequenz | Herkunft | Zahlungsmittel: Rechnung? |
| 4 | Normalkunde | mittel | niedrig | Inland | true |
| 5 | Normalkunde | hoch | hoch | Inland | true |
| 6 | Normalkunde | hoch | hoch | Ausland | false |
| 14 | Normalkunde | mittel | niedrig | Ausland | false |
Zwar ist die Entropie des Subsets der Normalkunden…

… denkbar schlecht, da maximal. Aber wir können genauso vorgehen, wie wir es bei dem Subset der Neukunden getan haben. Ich nehme es nun aber vorweg: Wenn wir uns den Datensatz näher ansehen, erkennen wir, dass wir diese Gesamtentropie von 1.0 für das Subset “Normalkunde” nicht mit den Attributen “Kauffrequenz” oder “Zahlungsgeschwindigkeit” reduzieren können, da dieses auch für sich betrachtet in Entropien der Größe 1.0 erhalten werden. Das Attribut “Herkunft” hingegen teilt den Datensatz sauber in true und false auf:
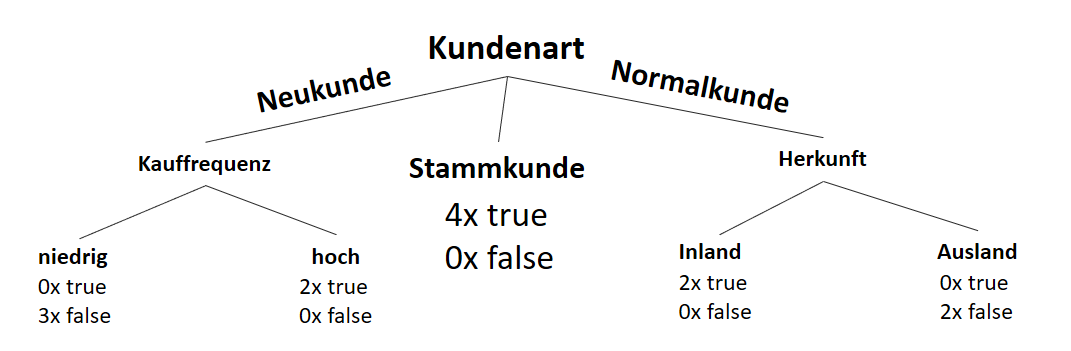 Somit ist der Informationsgewinn für das Attribut “Herkunft” am größten und wir haben unseren Baum komplett und – glücklicherweise – eindeutig bestimmen können!
Somit ist der Informationsgewinn für das Attribut “Herkunft” am größten und wir haben unseren Baum komplett und – glücklicherweise – eindeutig bestimmen können!
Ergebnis: Der Entscheidungsbaum
Somit haben wir den Entscheidungsbaum über den ID3-Algorithmus erstellt, der eine Auskunft darüber macht, ob einem Kunden die Zahlung über Rechnung (statt Vorkasse) erlaubt wird:
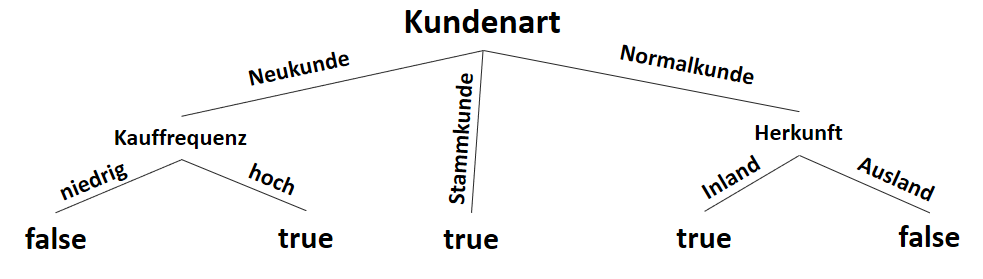 true = Rechnung als Zahlungsmittel erlaubt
true = Rechnung als Zahlungsmittel erlaubt
false = Rechnung als Zahlungsmittel nicht erlaubt







Hallo, vielen Dank für die gut verfasste Artikelreihe.
Jedoch hat sich direkt am Anfang (1.1) ein Fehler in der Rechnung eingeschlichen.
Es müsste bei log2() jeweils “14” im Nenner heißen und nicht “4”.
VG
Hallo Bernd,
vielen lieben Dank für den freundlichen Hinweis! Ich weiß aus eigener Erfahrung, dass solche Tippfehler Einsteiger schnell verunsichern können.
Besten Dank!
Benjamin Aunkofer
Hallo Benjamin,
tolle Website, hier werde ich bestimmt öfter mal vorbeischauen.
Bei Punkt 3.1 Dritter Rekursionsschritt hast du im Subset für Normalkunde einen Eintrag (Zeile 10) vergessen.
Dadurch ändert sich zwar im Endergebnis nichts, aber es gibt eben andere Werte bei der Berechnung.
VG
Hallo Benjamin,
Danke für die schöne und einfache Demo.
Frage zum Ende der Rekursionsschritte:
– wenn wir nach einem der Knotenpunkte einen IG von der Entropie des Vorknotens bekommen, also das Set sauber in True und Falls aufteilen können, können wir diesen automatisch als besten Knoten annehmen, oder müssten wir die anderen Alternativen auch noch betrachten.
Bsp. bei dir Schritt 3.1
– wie würde man vorgehen wenn Kauffrequenz ebenfalls eine Entropy von 0 hätte? Gilt hier dann first come first serve oder wie geht man vor?
Lg
Hallo,
Ich glaube bei 3.1 im ersten Rekursionsschritt gibt es einen Fehler bei der Berechnung von IG. Es müssten doch 2/5 * 0.00 sein und nicht 3/5 * 0.00 oder liege ich falsch?
MfG
Yannick