Artikelserie zu Process Mining Tools – PAFnow
Der zweite Artikel der Artikelserie Process Mining Tools beschäftigt sich mit dem Anbieter PAFnow. 2014 in Deutschland gegründet kann das Unternehmen PAF, dessen Kürzel für Process Analytics Factory steht, bereits auf eine beachtliche Anzahl an Projekten zurückblicken. Das klare selbst gesteckte Ziel von PAF: Mit dem eigenen Tool namens PAFnow Process Mining für jeden zugänglich machen.
PAFnow basiert auf dem bekannten BI-Tool „Power BI“. Wer sein Wissen zu Power BI noch einmal auffrischen möchte, kann das gerne in diesem Artikel aus der Artikelserie zu BI-Tools machen. Da Power BI selbst als Cloud- und On-Premise-Lösung erhältlich ist, gilt dies indirekt auch für PAFnow. Diese vier Versionen des Process Mining Tools werden von PAFnow angeboten:
|
Free |
Pro |
Premium |
Enterprise |
| Lizenz: |
Kostenfrei
(Marketplace Power BI) |
99€ pro User pro Monat |
499€ pro User pro Monat |
Nur auf Anfrage |
| Zielgruppe: |
Für kleine Unternehmen und Einzelanwender |
Für kleine bis mittlere Unternehmen |
Für mittlere und große Unternehmen |
Für mittlere und große Unternehmen |
| Datenquellen: |
Beliebig (Power BI Konnektoren), Transformationen in Power BI |
Beliebig (Power BI Konnektoren), Transformationen in Power BI |
Beliebig (Power BI Konnektoren), Transformationen in Power BI |
Beliebig (Power BI Konnektoren), Transformationen auch via MS SSIS |
| Datenvolumen: |
Limitiert auf 30.000 Events,
1 Visual |
Unlimitierte Events,
1 Visual, 1 Report |
Unlimitierte Events,
9 Visual, 10 Reports |
Unlimitierte Events,
10 Visual, 10 Reports, Content Packs |
| Architektur: |
Nur On-Premise |
Nur On-Premise |
Nur On-Premise |
Nur On-Premise |
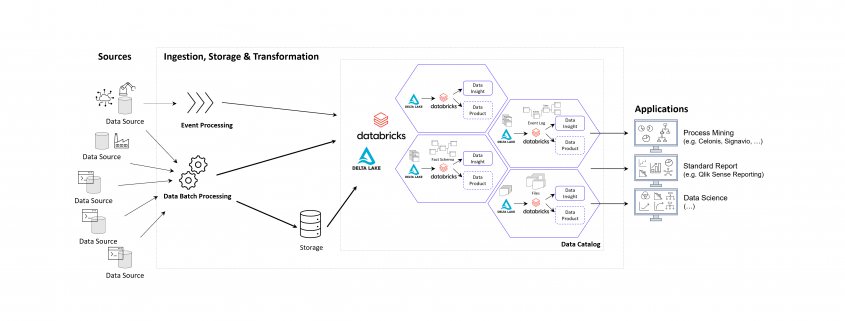
Abbildung 1: Übersicht zu den vier verschiedenen Produktversionen des Process Mining Tools PAFnow
PAF führt auf seiner Website weitere Informationen zu den jeweiligen Versionsunterschieden an. Für diesen Artikel wird sich im weiteren Verlauf auf die Enterprise Version bezogen, wenn nicht anderes gekennzeichnet.
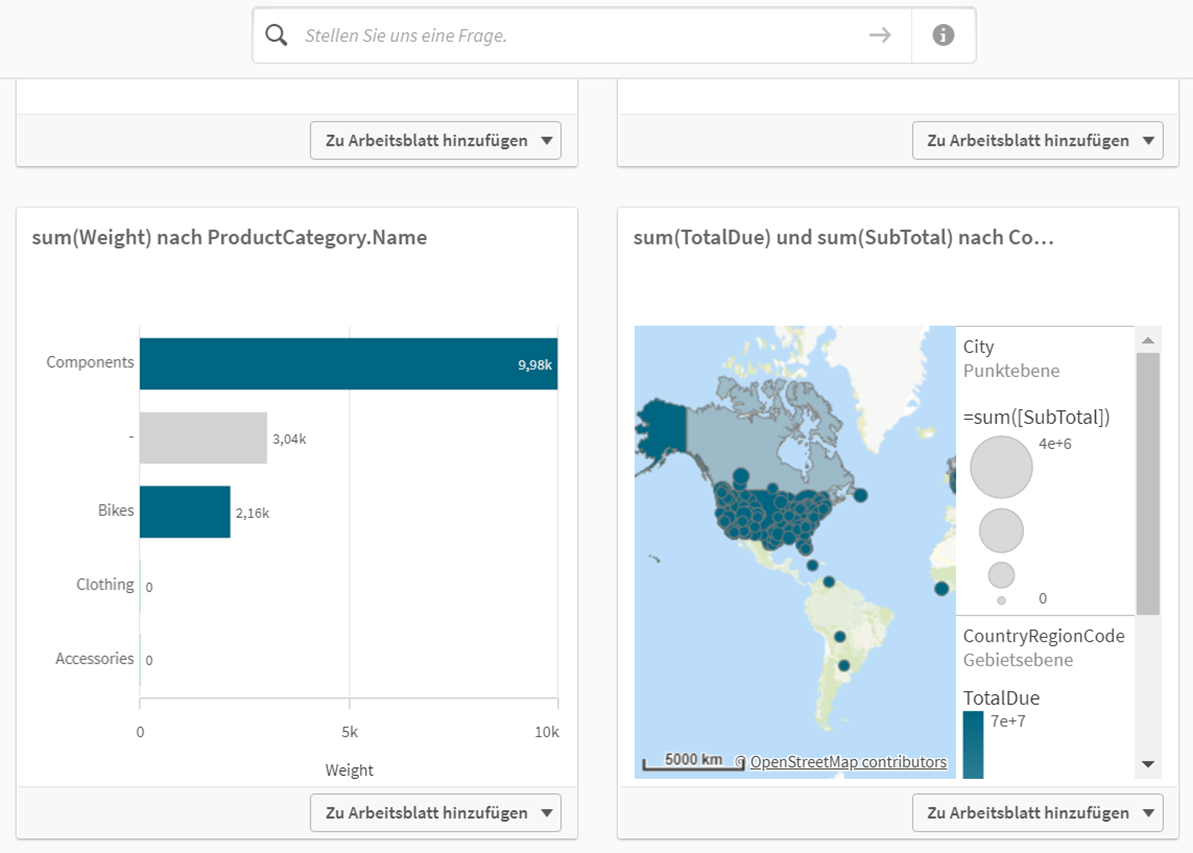
Bedienbarkeit und Anpassungsfähigkeit der Analysen
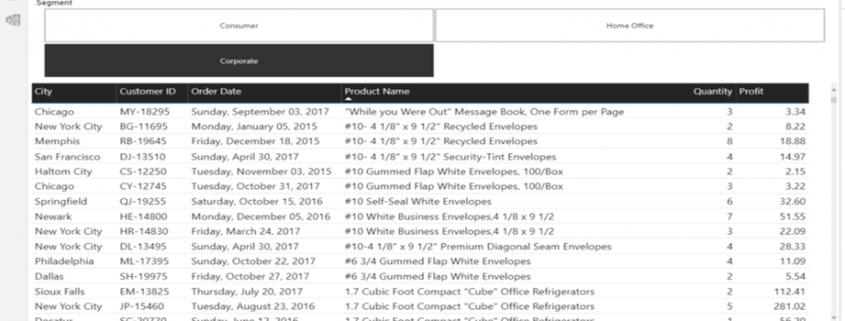
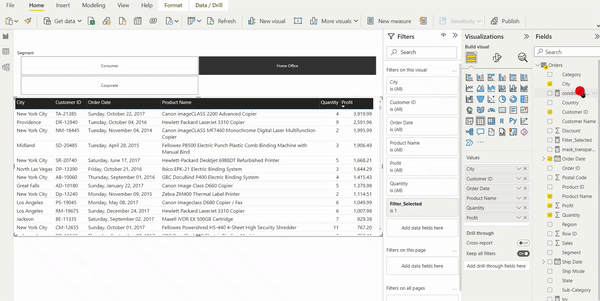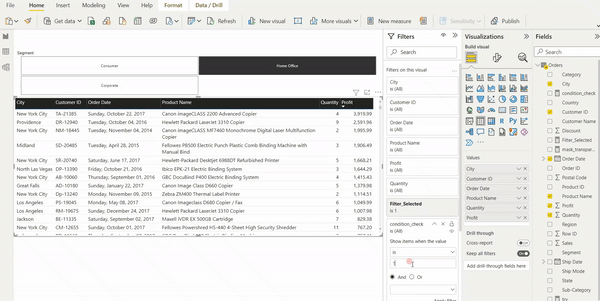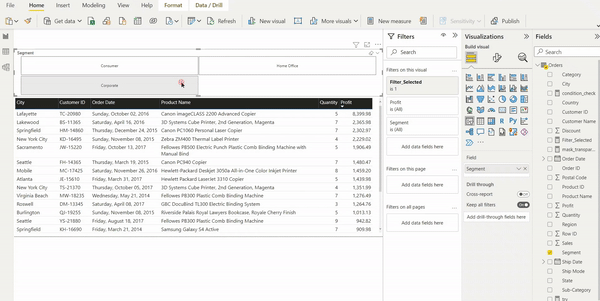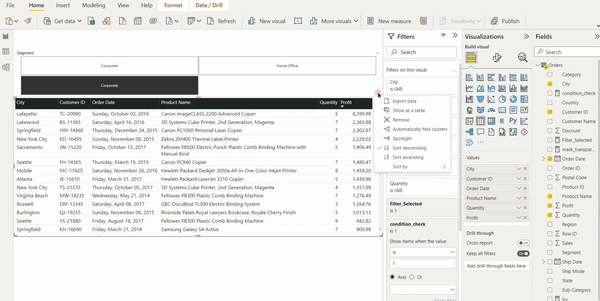
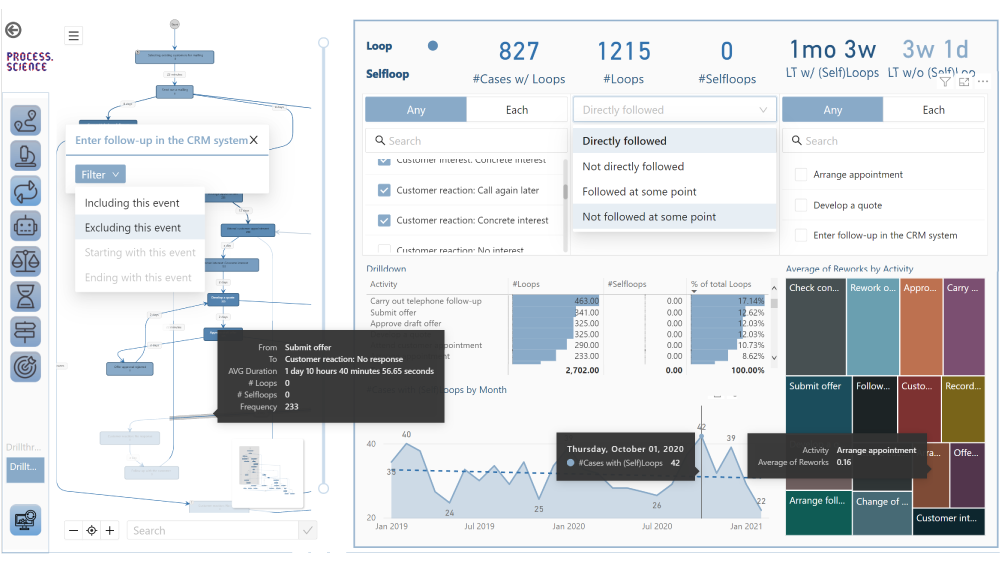
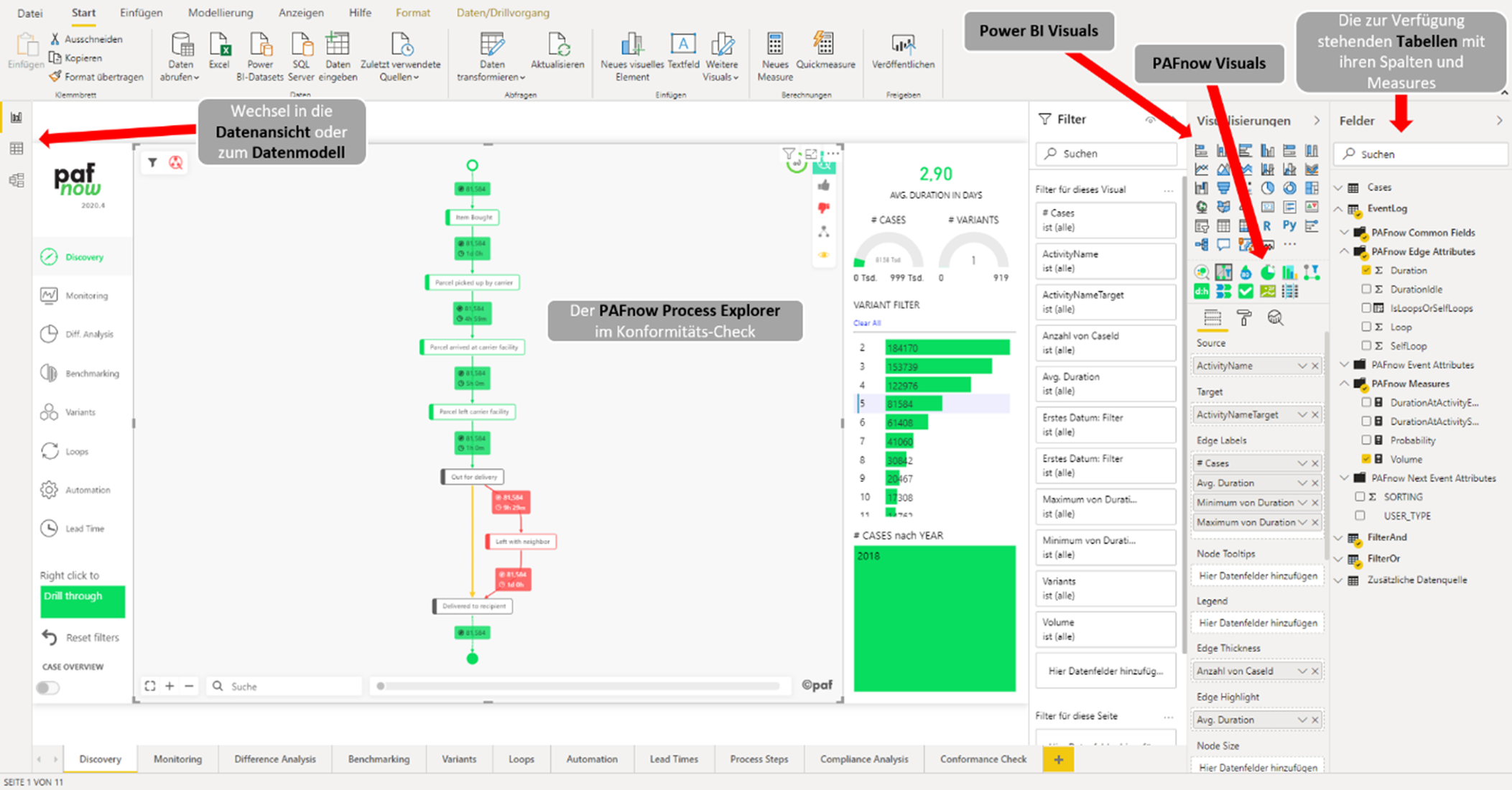
Das übersichtliche Userinterface von Power BI unterstützt die Analyse von Prozessen mit PAFnow. Und auch Anfänger können sich glücklich schätzen, denn es gibt eine beeindruckende Vielzahl an hochwertigen Lernvideos und Dokumentation zu Power BI. Die von PAFnow entwickelten Visuals, wie zum Beispiel der „Process Explorer“ fügt sich reibungslos zu den Power BI Visuals ein. Denn die Bedienung dieser Visuals entspricht größtenteils demselben Prinzip wie dem der Power BI Visuals. Neue Anwendungen wie beim Process Explorer der Conformance Check, werden jedoch auch von PAFnow in Lernvideos erläutert.
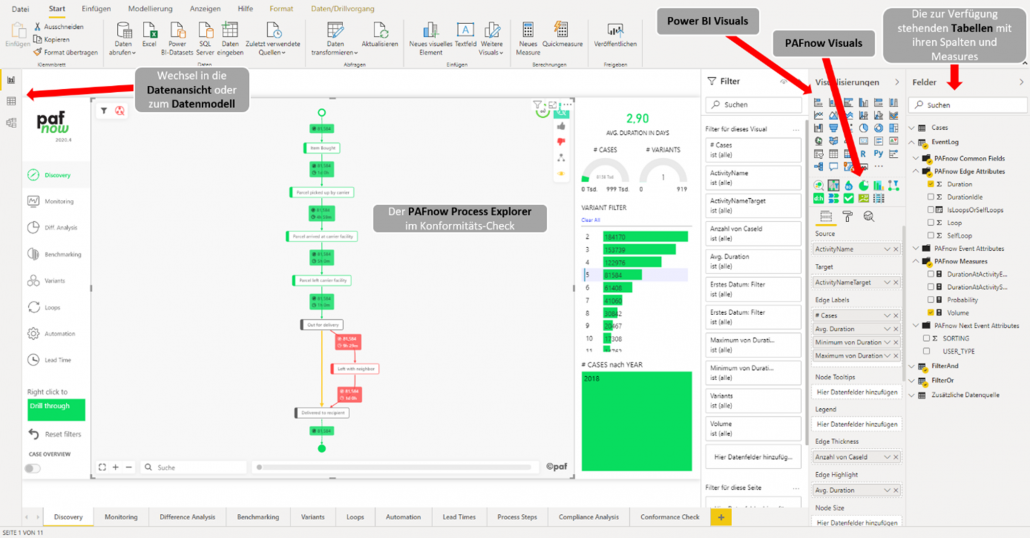 Abbildung 1: Userinterface von PAFnow in dem vorgefertigten Report „Discovery“
Abbildung 1: Userinterface von PAFnow in dem vorgefertigten Report „Discovery“
Die PAFnow Visuals werden – wie in Power BI – üblich per drag & drop platziert und mit den gewünschten Dimensionen und Measures bestückt. Die Visuals besitzen verschiedenste Einstellungsmöglichkeiten, um dem Benutzer das Visual nach seinen Vorstellungen gestallten zu lassen. Kommt man an die Grenzen der Einstellungen, lohnt sich immer ein Blick in den Marketplace von Power BI. Dort werden viele und teilweise auch technisch sehr gute Visuals kostenlos angeboten, welche viele weitere Analyseideen im Kontext der Prozessanalyse abdecken.
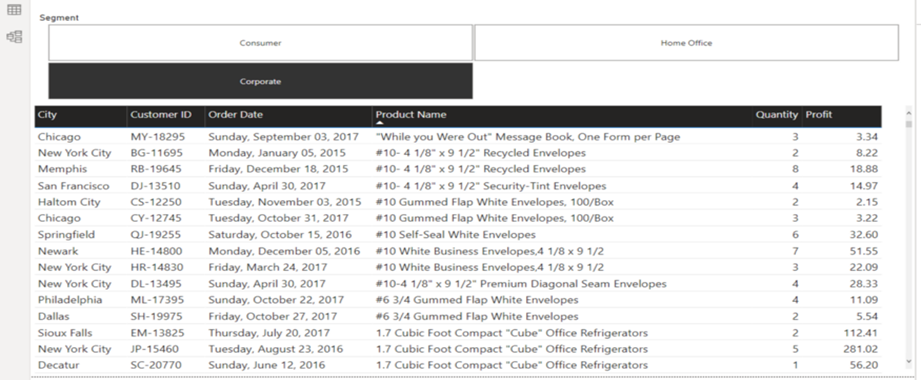
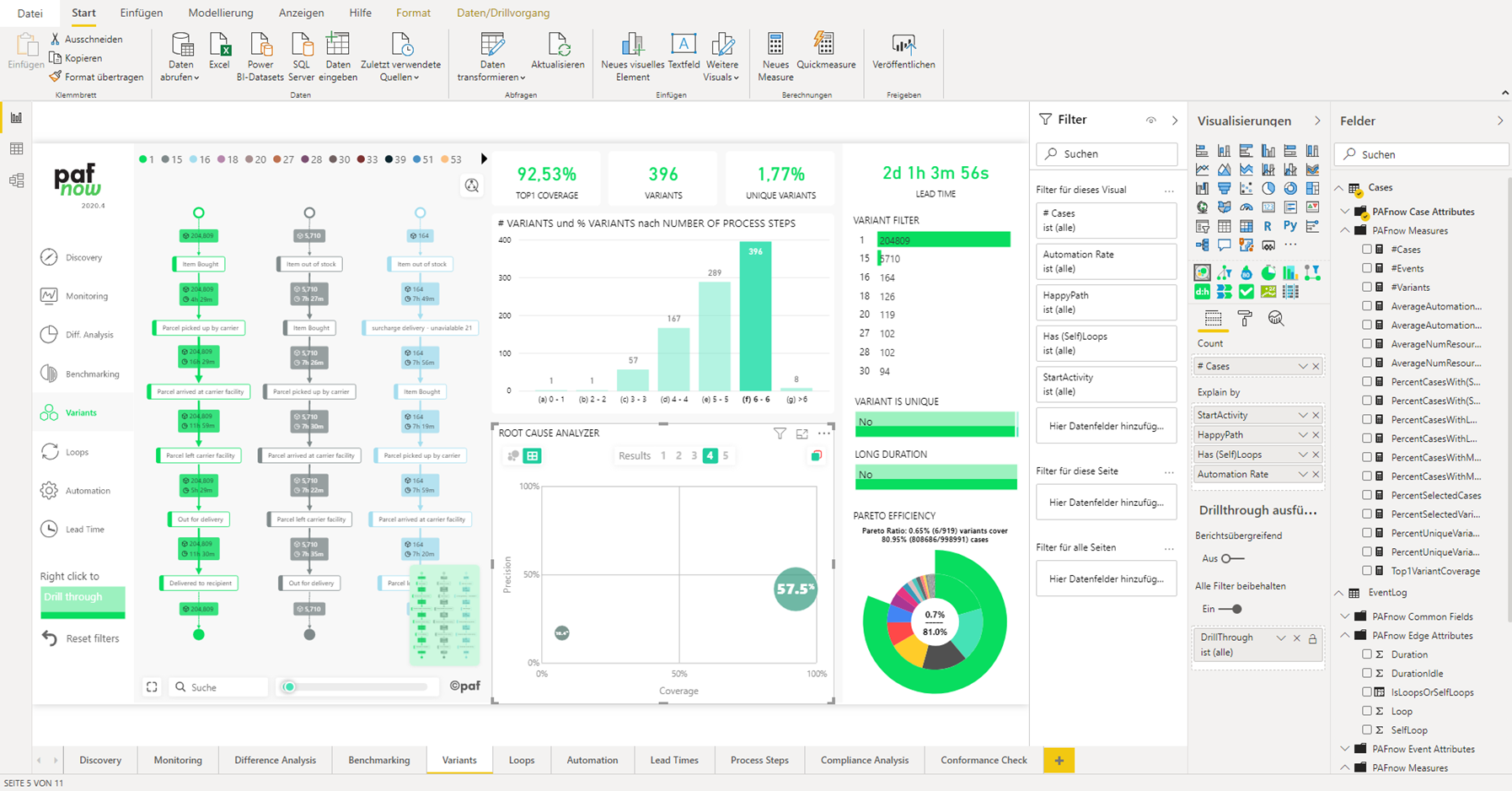
Die vorgefertigten Reports von PAFnow sind intuitiv zu handhaben, denn sie vermitteln dem Analysten direkt den passenden Eindruck, wie die jeweiligen Visuals am besten einzusetzen sind. Einzelne Elemente aus dem Report können gelöscht und nach Belieben ergänzt werden. Dadurch kann Zeit gespart und mit der eigentlichen Analyse schnell begonnen werden.
 Abbildung 2: Vorgefertigter Report „Variants“ an dem direkt eine Root-Cause Analyse durchgeführt werden kann
Abbildung 2: Vorgefertigter Report „Variants“ an dem direkt eine Root-Cause Analyse durchgeführt werden kann
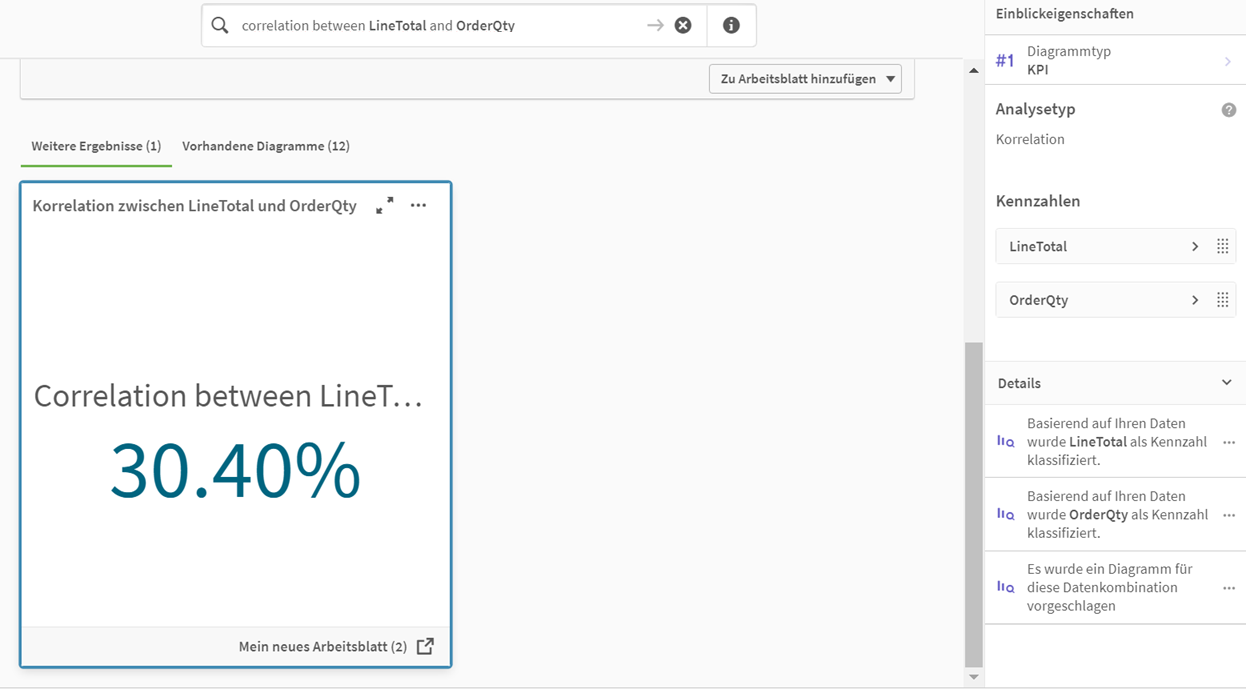
In Power BI werden die KPI’s bzw. Measures in einer von Microsoft eigens entwickelten Analysesprache namens DAX (Data Analysis Expressions) definiert. Diese Formelsprache ist ein sehr stark an Excel angelehnter Syntax und bietet für viele Nutzer in dieser Hinsicht einen guten Einstieg. Allerdings bietet der Umfang von DAX noch deutlich mehr, als es die meisten Excel Nutzer gewohnt sein werden, so können auch motivierte und technisch affine Business Experten recht tief in die Analyse abtauchen. Da es auch hier eine sehr gut aufgestellte Community als auch Dokumentation gibt, sind die Informationen zu den verborgenen Fähigkeiten von DAX meist nur ein paar Klicks entfernt.
Integrationsfähigkeit
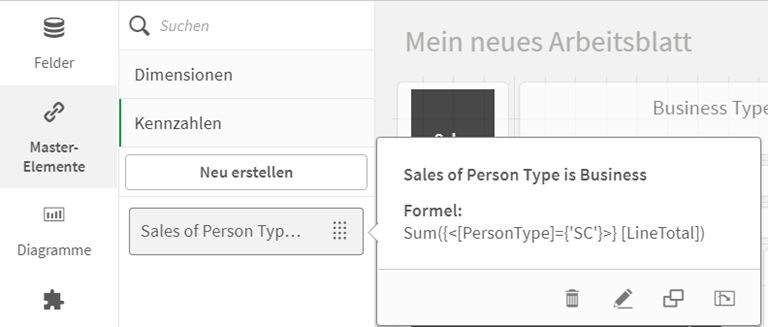
PAF bietet für sein Process Mining Tool aktuell noch keine eigene Cloud-Lösung an und ist somit nur über Power BI selbst als Cloud-Lösung erhältlich. Anwender, die sich eine unabhängige Process Mining – Plattform wünschen, müssen sich daher mit Power BI zufriedengeben. Ob PAFnow in absehbarer Zeit diese Lücke schließen wird und die Enterprise-Readiness des Tools somit erhöhen wird, bleibt abzuwarten, wünschenswert wäre es. Mit Power BI als Cloud-Lösung ist man als Anwender jedoch in den meisten Fällen nicht schlecht vertröstet. Da Power BI sowohl als Cloud- und als On-Premise-Lösung verfügbar ist, kann hier situationsabhängig entschieden werden. An dieser Stelle gilt es abzuwägen, welche Limitationen die beiden Lösungen mit sich bringen und daher sei auch an dieser Stelle der Artikel zu Power BI aus der BI-Tool-Artikelserie empfohlen. Darüber hinaus sollte die Größe der zu analysierenden Prozessdaten berücksichtigt werden. So kann bei plötzlich zu großen Datenmengen auch später noch ein Wechsel von der recht günstigen Power BI Pro-Lizenz auf die deutlich kostenintensivere Premium-Lizenz erfordern. In der Enterprise Version von PAFnow sind zwei frei wählbare Content Packs enthalten, welche aus SAP-Konnektoren, sowie vorentwickelten SSIS Packages bestehen. Mittels Datenextraktor werden die benötigten Prozessdaten, z. B. für die Prozesse P2P (Purchase-to-Pay) und O2C (Order-to-Cash), in eine Datenbank eines MS SQL Servers geladen und dort durch die SSIS-Packages automatisch in das für die Analyse benötigte Format transformiert. SSIS ist ein ETL-Tool von Microsoft und steht für SQL Server Integration Services. SSIS ist ein Teil der Enterprise-Vollversion des Microsoft SQL Servers.
Die vorgefertigten Reports die PAFnow zur Verfügung stellt, können Projekte zusätzlich beschleunigen. Neben den zwei frei wählbaren Content Packs, die in der Enterprise Version von PAFnow enthalten sind, stellen Partner die von Ihnen selbstentwickelte Packs zur Verfügung. Diese sind sofern die zwei kostenlosen Content Packs bereits beansprucht wurden jedoch zahlungspflichtig. PAFnow profitiert von der beeindruckenden Menge an verschiedenen Konnektoren, die Microsoft in Power BI zur Verfügung stellt. So können zusätzlich Daten direkt aus den Quellsystemen in Power BI geladen werden und dem Datenmodel ggf. hinzugefügt werden. Der Vorteil liegt in der Flexibilität, Daten nicht immer zwingend über ein Data Warehouse verfügbar machen zu müssen, sondern durch den direkten Zugriff auf die Datenquellen schnelle Workarounds zu ermöglichen. Allerdings ist dieser Vorteil nur auf ergänzende Daten beschränkt, denn das Event-Log wird stets via SSIS-ETL in der Datenbank oder der sogenannten „Companion-Software“ transformiert und bereitgestellt. Da der Companion jedoch ohne Schedule-Funktion auskommt, Transformationen also manuell angestoßen werden müssen, eignet sich dieser kaum für das Monitoring von Prozessen. Falls eine hohe Aktualität der Daten gefordert ist, sollte daher auf die SSIS-Package-Funktion der Enterprise Version zurückgegriffen werden.
Ergänzende Daten können anschließend mittels einer der vielen Power BI Konnektoren auch direkt aus der Datenquelle geladen werden, um Sie anschließend mit dem Datenmodell zu verknüpfen. Dabei sollte bei der Modellierung jedoch darauf geachtet werden, dass ein entsprechender Verbindungsschlüssel besteht. Die Flexibilität, Daten aus verschiedensten Datenquellen in nahezu x-beliebigem Format der Process Mining Analyse hinzufügen zu können, ist ein klarer Pluspunkt und der große Vorteil von PAFnow, auf die erfolgreiche BI-Lösung von Microsoft aufzusetzen. Mit der Wahl von SSIS als Event-Log/ETL-Lösung, positioniert sich PAFnow noch ein deutliches Stück näher zum Microsoft Stack und erleichtert die Integration in diejenige IT-Infrastruktur, die auf eben diesen Microsoft Stack setzt.
Auch in Sachen Benutzer-Berechtigungsmanagement können die Process Mining Analysen mittels Power BI Features, wie z.B. Row-based Level Security detailliert verwaltet werden. So können ganze Reports nur für bestimmte Personen oder Gruppen zugänglich gemacht werden, aber auch Teile des Reports sowie einzelne Datenausschnitte kontrolliert definierten Rollen zugewiesen werden.
Skalierbarkeit
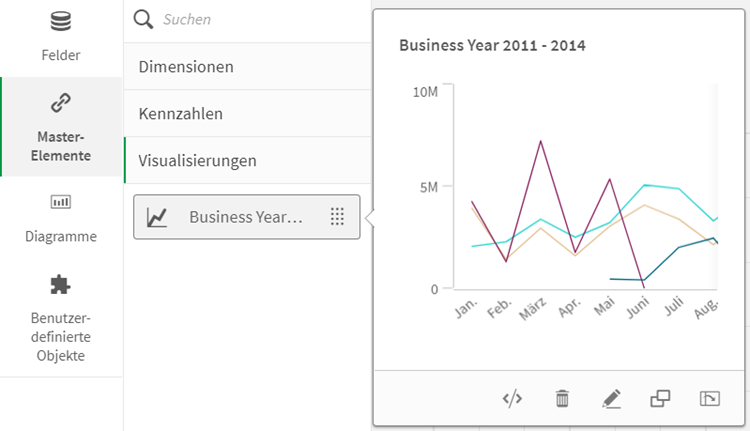
Um große Datenmengen mit Analysemethodik aus dem Process Mining analysieren zu können, muss die Software bei Bedarf skalieren. Wer mit großen Datasets in Power BI Pro lokal auf seinem Rechner schon Erfahrungen sammeln durfte, wird sicherlich schon mal an seine Grenzen gestoßen sein und Power BI nicht unbedingt als Big Data ready bezeichnen. Diese Performance spiegelt allerdings nur die untere Seite des Spektrums wider. So ist Power BI mit der Premium-Lizenz und einer ausreichend skalierten Azure SQL Data Warehouse Instanz durchaus dazu in der Lage, Daten im Petabytebereich zu analysieren. Microsoft entwickelt Power BI kontinuierlich weiter und wird mit an Sicherheit grenzender Wahrscheinlichkeit auch für weitere Performance-Verbesserung sorgen. Dabei wird MS Azure, die Cloud-Plattform von Microsoft, weiterhin eine entscheidende Rolle spielen. Hiervon wird PAFnow profitieren und attraktiv auch für Process Mining Projekte mit Big Data werden. Referenzprojekte mit besonders großen Datenmengen, die mit PAFnow analysiert wurden, sind öffentlich nicht bekannt. Im Grunde sind jegliche Skalierungsfähigkeiten jedoch nicht jene dieser Analysefunktionalität, sondern liegen im Microsoft Technology Stack mit all seinen Vor- und Nachteilen der Nutzung on-Premise oder in der Microsoft Cloud. Dabei steckt der Teufel übrigens immer im Detail und so muss z. B. stets auf die richtige Version von Power BI geachtet werden, denn es gibt für die Nutzung On-Premise mit dem Power BI Report Server als auch für jene Nutzung über Microsoft Azure unterschiedliche Versionen, die zueinander passen müssen.
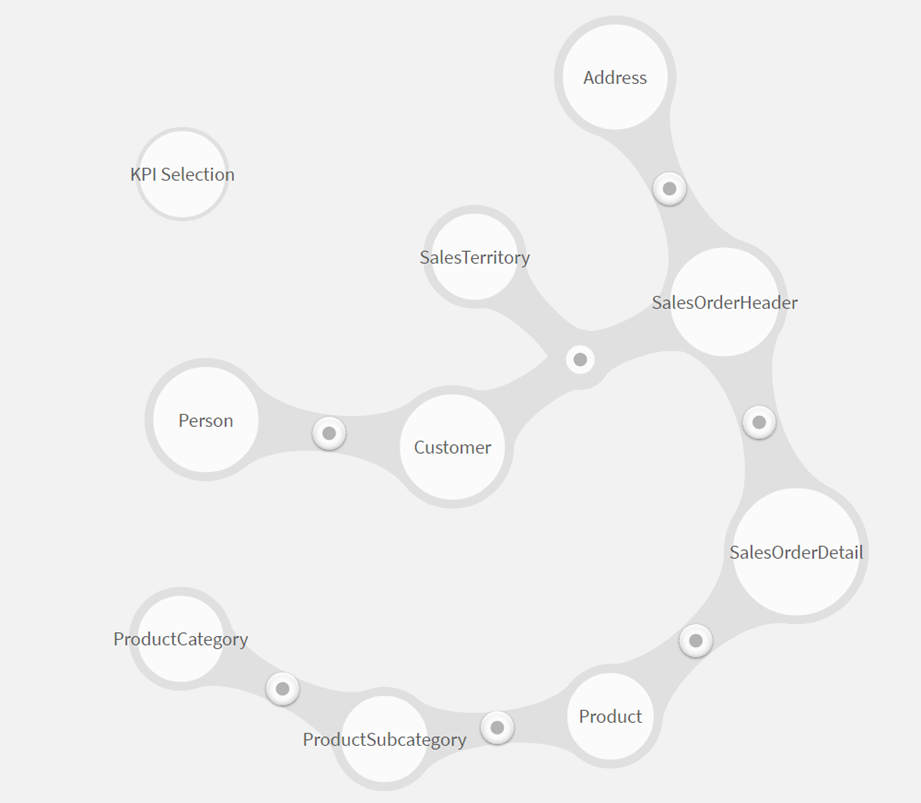
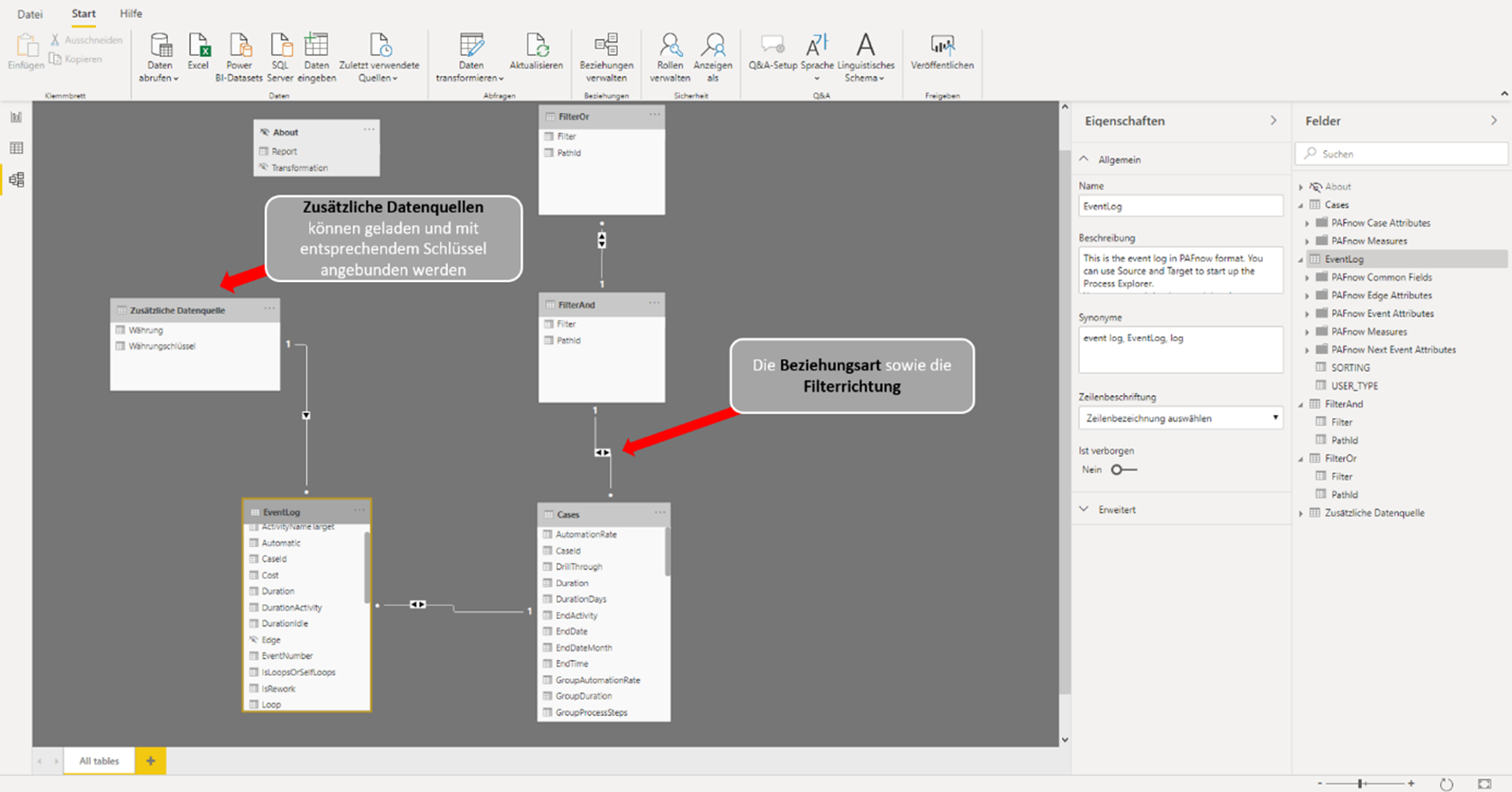
Die Datenmodellierung erfolgt in der Datenbank (On-Premise oder in der Cloud) und wird dann in Power BI geladen. Das Datenmodell wird in Power BI grafisch und übersichtlich dargestellt, wodurch auch der End-Nutzer jederzeit nachvollziehen kann in welcher Beziehung die einzelnen Tabellen zueinanderstehen. Die folgende Abbildung zeigt ein beispielhaftes Datenmodel visuell in Power BI.
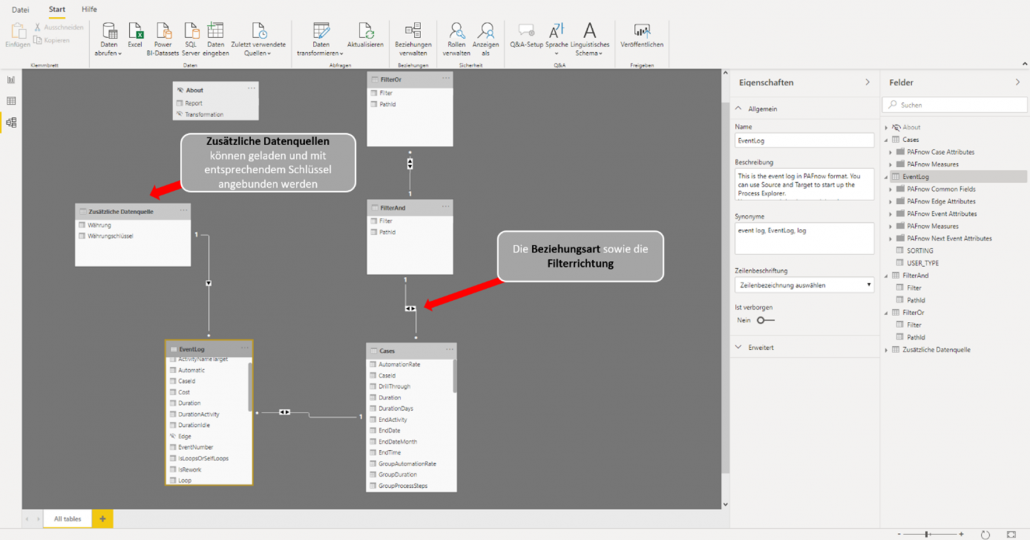 Abbildung 3: Grafische Darstellung des Datenmodels in Power BI
Abbildung 3: Grafische Darstellung des Datenmodels in Power BI
Zusätzliche Daten lassen sich – wie bereits erwähnt – sehr einfach hinzufügen und auch einfach anbinden, sofern ein Verbindungsschlüssel besteht. Sollten also zusätzliche Slicer benötigt werden, können diese problemlos ergänzt werden. An dieser Stelle sorgen die vielen von Power BI bereitgestellten Konnektoren für einen hohen Grad an Flexibilität. Für erfahrene Power BI Benutzer ist die Datenmodellierung also wie immer reibungslos und übersichtlich. Aber auch Neulinge sollten, sofern sie Erfahrung in der Datenmodellierung haben, hier keine Schwierigkeiten haben. Kleinere Transformationen beim Datenimport können im Query Editor von Power BI, mit Hilfe der Formelsprache Power Query (M) gemacht werden. Diese Formelsprache ist einsteigerfreundlich und ähnelt in Teilen der Programmiersprache F#. Aber auch ohne diese Formelsprache können einfache Transformationen mit Hilfe des übersichtlichen und mit vielen Funktionen ausgestatteten Userinterfaces im Query Editor intuitiv erledigt werden. Bei größeren und komplexeren Transformationen sollten die Daten jedoch auf Datenbankebene erfolgen. Dort werden die Rohdaten auch für die PAFnow Visuals vorbereitet, sofern die Enterprise-Version genutzt wird. PAFnow stellt für diese Transformationen vorgefertigte SSIS-Packages zur Verfügung, welche auch angepasst und erweitert werden können. Die Modellierung erfolgt somit in T-SQL, das in den SSIS-Queries eingebettet ist und stellt für jeden erfahrenden SQL-Anwender keine Schwierigkeiten dar. Bei der Erweiterbarkeit und Flexibilität der Datenmodelle konnte ich ebenfalls keine besonderen Einschränkungen feststellen. Einzig das Schema, welches von den PAFnow Visuals vorgegeben wird, muss eingehalten werden. Durch das Zurückgreifen auf die Abfragesprache SQL, kann bei der Modellierung auf eine sehr breite Community zurückgegriffen werden. Darüber hinaus können bestehende SQL-Skripte eingefügt und leicht angepasst werden. Und auch die Suche nach einem geeigneten Data Engineer gestaltet sich dadurch praktisch, da SQL im Generellen und der MS SQL Server im Speziellen im Einsatz sehr verbreitet sind.
Zukunftsfähigkeit
Grundsätzlich verfolgt PAF nach eigener Aussage einen anderen Ansatz als der Großteil ihrer Mitbewerber: “So setzt PAF weniger auf monolithische Strukturen, sondern verfolgt einen Plattform-agnostischen Ansatz“. Damit grenzt sich PAF von sogenannte All-in-one Lösungen ab, bei welchen alle Funktionen bereits integriert sind. Der Vorteil solcher Lösungen ist, dass sie vollumfänglich „ready-to-use“ sind, sobald sie erfolgreich implementiert wurden. Der Nachteil solcher Systeme liegt in der unzureichenden Steuerungsmöglichkeit der einzelnen Bestandteile. Microservices hingegen versprechen eben genau diese Kontrolle und erlauben es dem Anwender, nur die Funktionen, die benötigt werden nach eigenen Vorstellungen in das System zu integrieren. Auf der anderen Seite ist der Aufbau solcher agnostischen Systeme deutlich komplexer und beansprucht daher oft mehr Zeit bei der Implementierung und setzt auch ein gewissen Know-How voraus. Die Entscheidung für den einen oder anderen Ansatz gleicht ein wenig einer make-or-buy Entscheidung und muss daher in den individuellen Situationen abgewogen werden.
In den beiden Trendthemen Machine Learning und Task Mining kann PAFnow aktuell noch keine Lösungen vorzeigen. Nach eigenen Aussagen gibt es jedoch bereits einige Neuerungen in der Pipeline, welche PAFnow in Zukunft deutlich AI-getriebener gestalten werden. Näheres zu diesem Thema wollte man an dieser Stelle zum Zeitpunkt der Veröffentlichung dieses Artikels nicht verkünden. Jedoch kann der Website von PAFnow diverse Forschungsprojekte eingesehen werden, welche sich unteranderem mit KI und RPA befassen. Sicherlich profitieren PAFnow Anwender auch von der Zukunftsfähigkeit von Power BI bzw. Microsoft selbst. Inwieweit diese Entwicklungen in dieselbe Richtung gehen wie die Trends im Bereich Process Mining bleibt abzuwarten.
Preisgestaltung
Der Kostenrahmen für das Process Mining Tool von PAFnow ist sehr weit gehalten. Da die Pro Version bereits für 120$ im Monat zu haben ist, spiegelt sich hier die Philosophie von PAFnow wider, Process Mining für jedermann zugänglich zu machen. Mit dieser niedrigen Einstiegshürde können Unternehmen erste Erfahrungen im Process Mining sammeln und diese ohne großes Investitionsrisiko validieren. Nicht im Preis enthalten, sind jedoch etwaige Kosten für das notwendige BI-Tool Power BI. Da jedoch auch hier der Kostenrahmen sehr weit ausfällt und mittlerweile auch im Serviceportfolio von Microsoft 365 enthalten ist, bleibt es bei einer niedrigen Einstieghürde aus finanzieller Sicht. Allerdings kann bei umfangreicher Nutzung der Preis der Power BI Lizenzgebühren auch deutlich höher ausfallen. Kommt Power BI z. B. aus Gründen der Data Governance nur als On-Premise-Lösung in Betracht, steigen die Kosten für Power BI grundsätzlich bereits auf mindestens 4.995 EUR pro Monat. Die Preisbewertung von PAFnow ist also eng verbunden mit dem Power BI Lizenzmodel und sollte im Einzelfall immer mit einbezogen werden. Wer gerne mehr zum Lizenzmodel von Power BI wissen möchte, bekommt hier eine zusammengefasste Übersicht.
Fazit
Mit PAFnow ist ein durchaus erschwingliche Process Mining Tool auf dem Markt erhältlich, welches sich geschickt in den Microsoft-BI-Stack eingliedert und die Hürden für den Einstieg relativ geringhält. Unternehmen, die ohnehin Power BI als Reporting Lösung nutzen, können ohne großen Aufwand erste Projekte mit Process Mining starten und den Umfang der Funktionen über die verschiedenen Lizenzen hochskalieren. Allerdings sind dem Autor auch Unternehmen bekannt, die Power BI und den MS SQL Server explizit für die Nutzung von PAFnow erstmalig in ihre Unternehmens-IT eingeführt haben. Da Power BI bereits mit vielen Features ausgestattet ist und auch kontinuierlich weiterentwickelt wird, profitiert PAFnow von dieser Entwicklungsarbeit ungemein. Die vorgefertigten Reports von PAFnow können die Time-to-Value lukrativ verkürzen und sind flexibel erweiterbar. Für erfahrene Anwender von Power BI ist der Umgang mit den Visuals von PAF sehr intuitiv und bedarf keines großen Schulungsaufwandes. Die Datenmodellierung erfolgt auf SSIS-Basis in SQL und weist somit auch keine nennenswerten Hürden auf. Wie leistungsstark PAFnow mit großen Datenmengen umgeht kann an dieser Stelle nicht bewertet werden. PAFnow steht nicht nur in diesem Punkt in direkter Abhängigkeit von der zukünftigen Entwicklung des Microsoft Technology Stacks und insbesondere von Microsoft Power BI. Für strategische Überlegungen bzgl. der Integrationsfähigkeit in das jeweilige Unternehmen sollte dies immer berücksichtigt werden.