
Espresso AI: Q&A mit Mathias Golombek, CTO bei Exasol
Nahezu alle Unternehmen beschäftigen sich heute mit dem Thema KI und die überwiegende Mehrheit hält es für die wichtigste Zukunftstechnologie – dennoch tun sich nach wie vor viele schwer, die ersten Schritte in Richtung Einsatz von KI zu gehen. Woran scheitern Initiativen aus Ihrer Sicht?
Zu den größten Hindernissen zählen Governance-Bedenken, etwa hinsichtlich Themen wie Sicherheit und Compliance, unklare Ziele und eine fehlende Implementierungsstrategie. Mit seinen flexiblen Bereitstellungsoptionen in der Public/Private Cloud, on-Premises oder in hybriden Umgebungen macht Exasol seine Kunden unabhängig von bestimmten Plattform- und Infrastrukturbeschränkungen, sorgt für die unkomplizierte Integration von KI-Funktionalitäten und ermöglicht Zugriff auf Datenerkenntnissen in real-time – und das, ohne den gesamten Tech-Stack austauschen zu müssen.
Dies ist der eine Teil – der technologische Teil – die Schritte, die die Unternehmen –selbst im Vorfeld gehen müssen, sind die Festlegung von klaren Zielen und KPIs und die Etablierung einer Datenkultur. Das Management sollte für Akzeptanz sorgen, indem es die Vorteile der Nutzung klar beleuchtet, Vorbehalte ernst nimmt und sie ausräumt. Der Weg zum datengetriebenen Unternehmen stellt für viele, vor allem wenn sie eher traditionell aufgestellt sind, einen echten Paradigmenwechsel dar. Führungskräfte sollten hier Orientierung bieten und klar darlegen, welche Rolle die Nutzung von Daten und der Einsatz neuer Technologien für die Zukunftsfähigkeit von Unternehmen und für jeden Einzelnen spielen. Durch eine Kultur der offenen Kommunikation werden Teams dazu ermutigt, digitale Lösungen zu finden, die sowohl ihren individuellen Anforderungen als auch den Zielen des Unternehmens entsprechen. Dazu gehört es natürlich auch, die eigenen Teams zu schulen und mit dem entsprechenden Know-how auszustatten.
Wie unterstützt Exasol die Kunden bei der Implementierung von KI?
Datenabfragen in natürlicher Sprache können, das ist spätestens seit dem Siegeszug von ChatGPT klar, generativer KI den Weg in die Unternehmen ebnen und ihnen ermöglichen, sich datengetrieben aufzustellen. Mit der Integration von Veezoo sind auch die Kunden von Exasol Espresso in der Lage, Datenabfragen in natürlicher Sprache zu stellen und KI unkompliziert in ihrem Arbeitsalltag einzusetzen. Mit dem integrierten autoML-Tool von TurinTech können Anwender zudem durch den Einsatz von ML-Modellen die Performance ihrer Abfragen direkt in ihrer Datenbank maximieren. So gelingt BI-Teams echte Datendemokratisierung und sie können mit ML-Modellen experimentieren, ohne dabei auf Support von ihren Data-Science-Teams angewiesen zu sei.
All dies trägt zur Datendemokratisierung – ein entscheidender Punkt auf dem Weg zum datengetriebenen Unternehmen, denn in der Vergangenheit scheiterte die Umsetzung einer unternehmensweiten Datenstrategie häufig an Engpässen, die durch Data Analytics oder Data Science Teams hervorgerufen werden. Espresso AI ermöglicht Unternehmen einen schnelleren und einfacheren Zugang zu Echtzeitanalysen.
Was war der Grund, Exasol Espresso mit KI-Funktionen anzureichern?
Immer mehr Unternehmen suchen nach Möglichkeiten, sowohl traditionelle als auch generative KI-Modelle und -Anwendungen zu entwickeln – das entsprechende Feedback unserer Kunden war einer der Hauptfaktoren für die Entwicklung von Espresso AI.
Ziel der Unternehmen ist es, ihre Datensilos aufzubrechen – oft haben Data Science Teams viele Jahre lang in Silos gearbeitet. Mit dem Siegeszug von GenAI durch ChatGPT hat ein deutlicher Wandel stattgefunden – KI ist greifbarer geworden, die Technologie ist zugänglicher und auch leistungsfähiger geworden und die Unternehmen suchen nach Wegen, die Technologie gewinnbringend einzusetzen.
Um sich wirklich datengetrieben aufzustellen und das volle Potenzial der eigenen Daten und der Technologien vollumfänglich auszuschöpfen, müssen KI und Data Analytics sowie Business Intelligence in Kombination gebracht werden. Espresso AI wurde dafür entwickelt, um genau das zu tun.
Und wie sieht die weitere Entwicklung aus? Welche Pläne hat Exasol?
Eines der Schlüsselelemente von Espresso AI ist das AI Lab, das es Data Scientists ermöglicht, die In-Memory-Analytics-Datenbank von Exasol nahtlos und schnell in ihr bevorzugtes Data-Science-Ökosystem zu integrieren. Es unterstützt jede beliebige Data-Science-Sprache und bietet eine umfangreiche Liste von Technologie-Integrationen, darunter PyTorch, Hugging Face, scikit-learn, TensorFlow, Ibis, Amazon Sagemaker, Azure ML oder Jupyter.
Weitere Integrationen sind ein wichtiger Teil unserer Roadmap. Während sich die ersten auf die Plattformen etablierter Anbieter konzentrierten, werden wir unser AI Lab weiter ausbauen und es werden Integrationen mit Open-Source-Tools erfolgen. Nutzer werden so in der Lage sein, eine Umgebung zu schaffen, in der sich Data Scientists wohlfühlen. Durch die Ausführung von ML-Modellen direkt in der Exasol-Datenbank können sie so die maximale Menge an Daten nutzen und das volle Potenzial ihrer Datenschätze ausschöpfen.
 Über Exasol-CEO Martin Golombek
Über Exasol-CEO Martin Golombek
Mathias Golombek ist seit Januar 2014 Mitglied des Vorstands der Exasol AG. In seiner Rolle als Chief Technology Officer verantwortet er alle technischen Bereiche des Unternehmens, von Entwicklung, Produkt Management über Betrieb und Support bis hin zum fachlichen Consulting.
Über Exasol und Espresso AI
Sie leiden unter langsamer Business Intelligence, mangelnder Datenbank-Skalierung und weiteren Limitierungen in der Datenanalyse? Exasol bietet drei Produkte an, um Ihnen zu helfen, das Maximum aus Analytics zu holen und schnellere, tiefere und kostengünstigere Insights zu erzielen.
Kein Warten mehr auf das “Spinning Wheel”. Von Grund auf für Geschwindigkeit konzipiert, basiert Espresso auf einer einmaligen Datenbankarchitektur aus In-Memory-Caching, spaltenorientierter Datenspeicherung, “Massively Parallel Processing” (MPP), sowie Auto-Tuning. Damit können selbst die komplexesten Analysen beschleunigt und bessere Erkenntnisse in atemberaubender Geschwindigkeit geliefert werden.



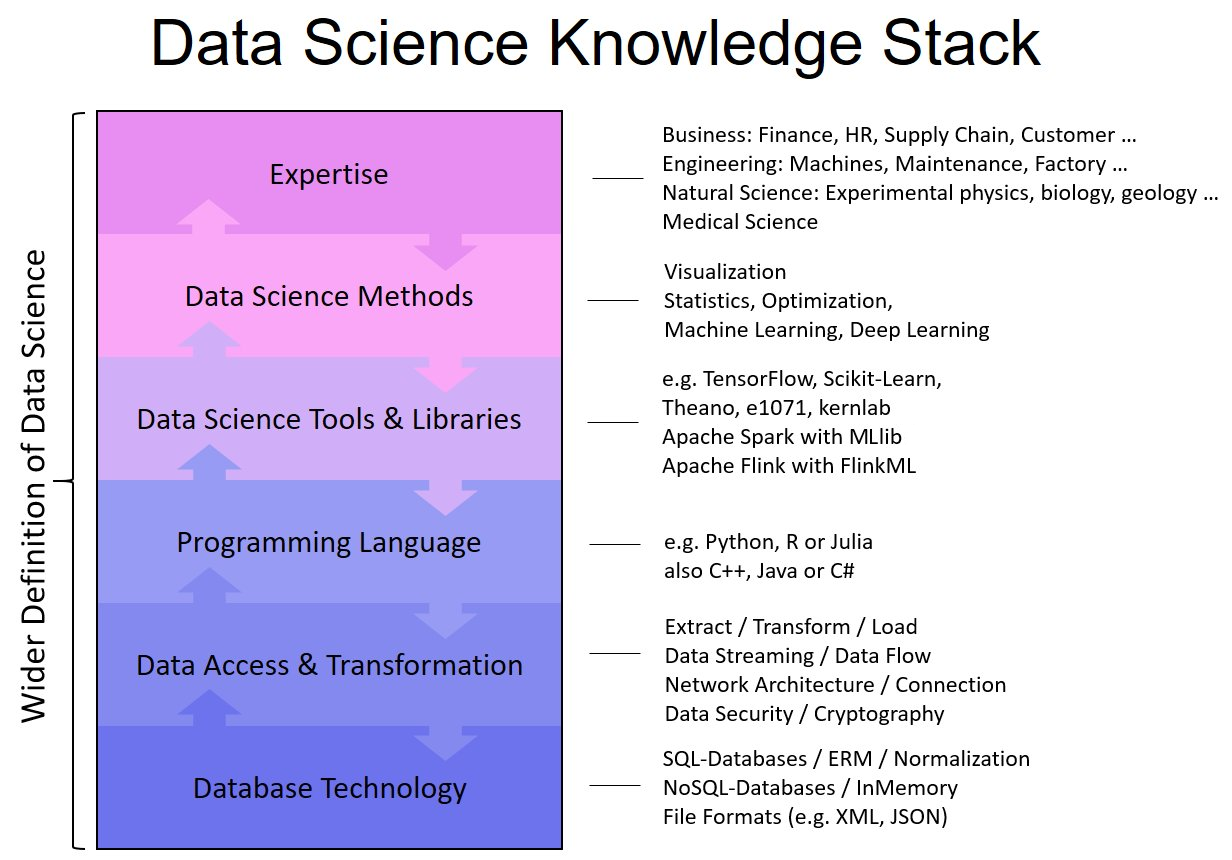
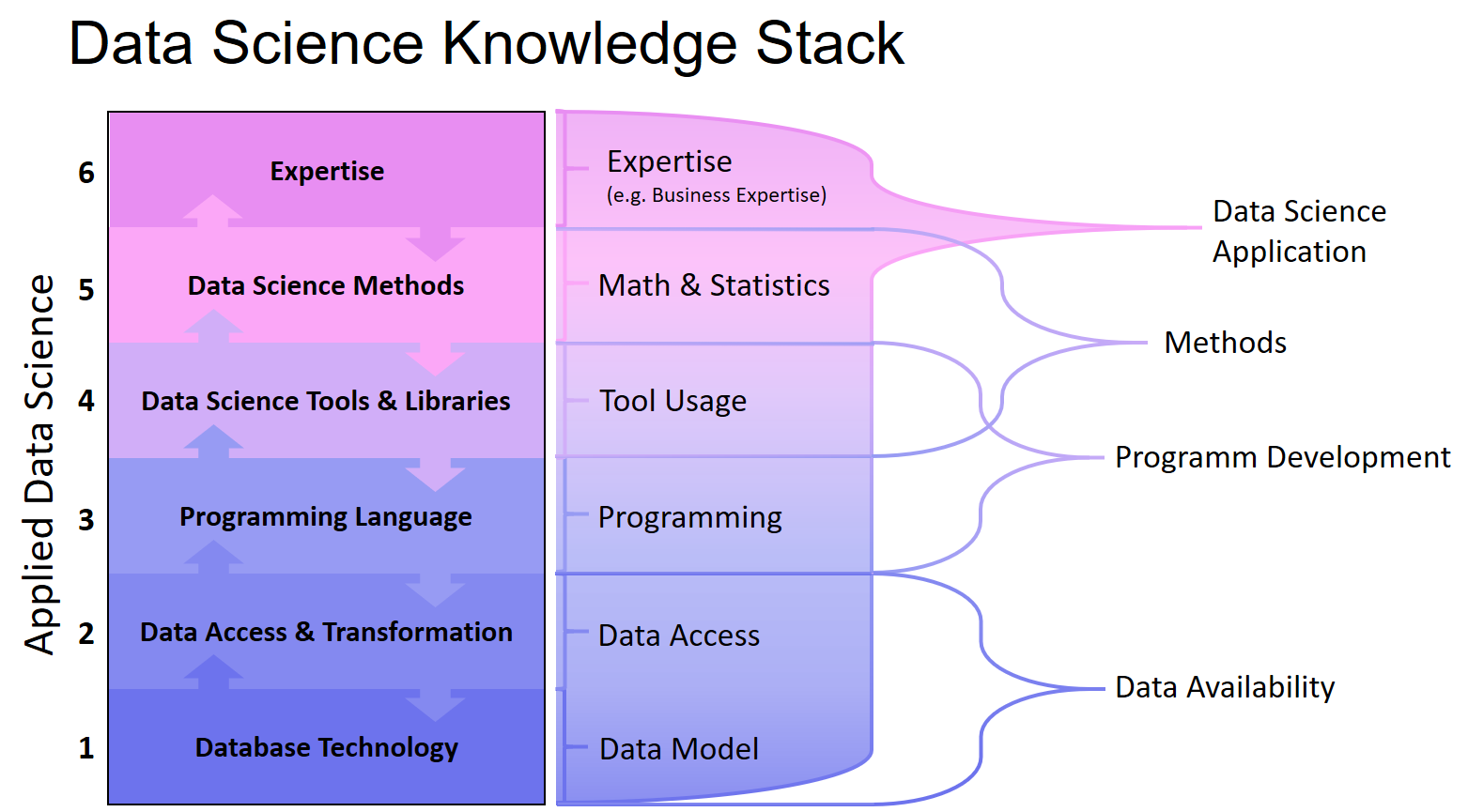
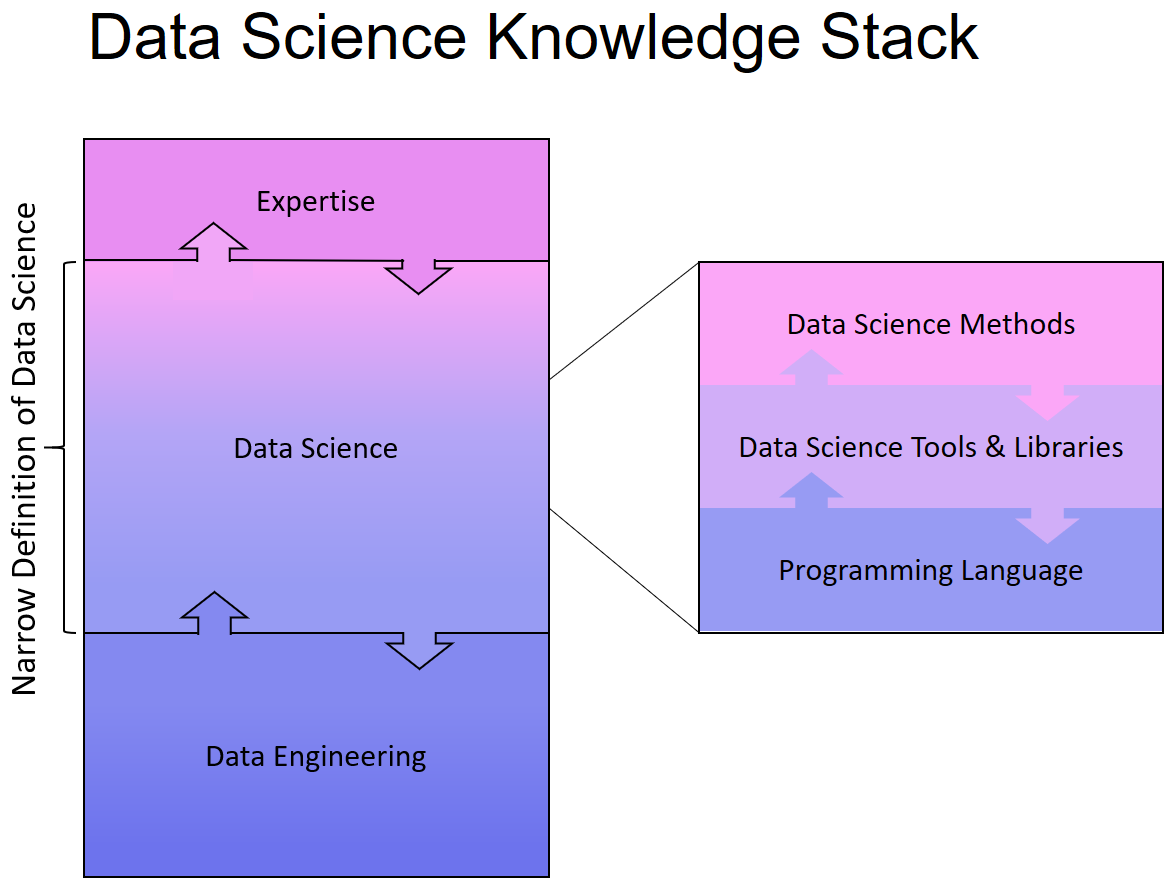


 scientists, which will involve more sophisticated analysis, predictive modeling, regressions and Bayesian classification. That stuff at scale doesn’t work well on anyone’s engine right now. If you want to do complex analytics on big data, you have a big problem right now.”
scientists, which will involve more sophisticated analysis, predictive modeling, regressions and Bayesian classification. That stuff at scale doesn’t work well on anyone’s engine right now. If you want to do complex analytics on big data, you have a big problem right now.”

{kind=link}