
Data Literacy Day 2023 by StackFuel

Über den Organisator, StackFuel:
![]()
Über den Organisator, StackFuel:
![]()
Companies use Business Intelligence (BI), Data Science, and Process Mining to leverage data for better decision-making, improve operational efficiency, and gain a competitive edge. BI provides real-time data analysis and performance monitoring, while Data Science enables a deep dive into dependencies in data with data mining and automates decision making with predictive analytics and personalized customer experiences. Process Mining offers process transparency, compliance insights, and process optimization. The integration of these technologies helps companies harness data for growth and efficiency.
More and more all these disciplines are growing together as they need to be combined in order to get the best insights. So while Process Mining can be seen as a subpart of BI while both are using Machine Learning for better analytical results. Furthermore all theses analytical methods need more or less the same data sources and even the same datasets again and again.
While all these analytical concepts grow together, they are often still seen as separated applications. There often remains the question of responsibility in a big organization. If this responsibility is decided as not being a central one, Data Mesh could be a solution.
Data Mesh is an architectural approach for managing data within organizations. It advocates decentralizing data ownership to domain-oriented teams. Each team becomes responsible for its Data Products, and a self-serve data infrastructure is established. This enables scalability, agility, and improved data quality while promoting data democratization.
In the context of a Data Mesh, a Data Product refers to a valuable dataset or data service that is managed and owned by a specific domain-oriented team within an organization. It is one of the key concepts in the Data Mesh architecture, where data ownership and responsibility are distributed across domain teams rather than centralized in a single data team.
A Data Product can take various forms, depending on the domain’s requirements and the data it manages. It could be a curated dataset, a machine learning model, an API that exposes data, a real-time data stream, a data visualization dashboard, or any other data-related asset that provides value to the organization.
However, successful implementation requires addressing cultural, governance, and technological aspects. One of this aspect is the cloud architecture for the realization of Data Mesh.
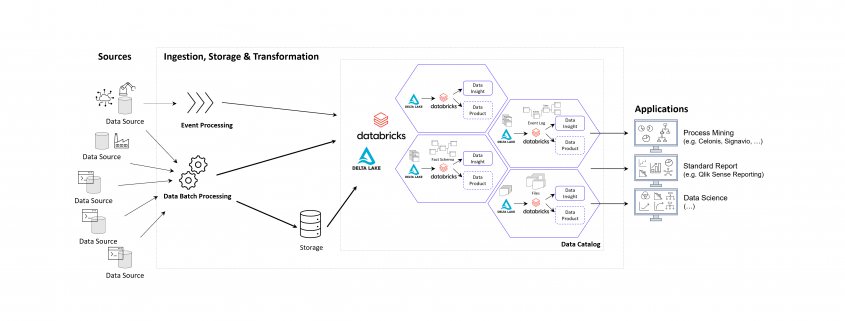
The following image shows an example of a Data Mesh created and managed by DATANOMIQ for an organization which uses and re-uses datasets from various data sources (ERP, CRM, DMS, IoT,..) in order to provide the data as well as suitable data models as data products to applications of Data Science, Process Mining (Celonis, UiPath, Signavio & more) and Business Intelligence (Tableau, Power BI, Qlik & more).
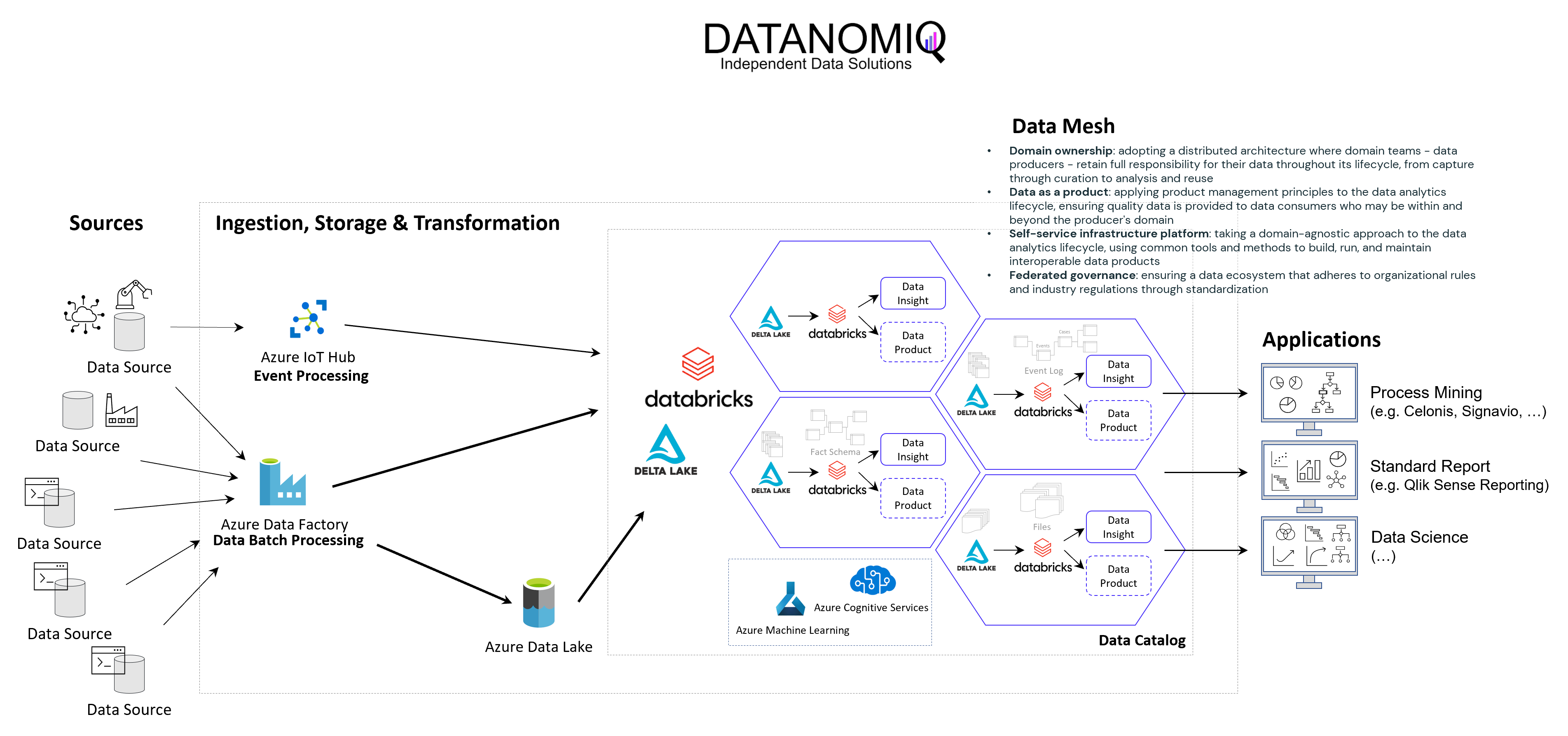
Data Mesh on Azure Cloud with Databricks and Delta Lake for Applications of Business Intelligence, Data Science and Process Mining.
Microsoft Azure Cloud is favored by many companies, especially for European industrial companies, due to its scalability, flexibility, and industry-specific solutions. It offers robust IoT and edge computing capabilities, advanced data analytics, and AI services. Azure’s strong focus on security, compliance, and global presence, along with hybrid cloud capabilities and cost management tools, make it an ideal choice for industrial firms seeking to modernize, innovate, and improve efficiency. However, this concept on the Azure Cloud is just an example and can easily be implemented on the Google Cloud (GCP), Amazon Cloud (AWS) and now even on the SAP Cloud (Datasphere) using Databricks.
Databricks is an ideal tool for realizing a Data Mesh due to its unified data platform, scalability, and performance. It enables data collaboration and sharing, supports Delta Lake for data quality, and ensures robust data governance and security. With real-time analytics, machine learning integration, and data visualization capabilities, Databricks facilitates the implementation of a decentralized, domain-oriented data architecture we need for Data Mesh.
Furthermore there are also alternate architectures without Databricks but more cloud-specific resources possible, for Microsoft Azure e.g. using Azure Synapse instead. See this as an example which has many possible alternatives.
With the concept of Data Mesh you will be able to access all your organizational internal and external data sources once and provides the data as several data models for all your analytical applications. The data models are seen as data products with defined value, costs and ownership. Each applications has its own data model. While Data Science Applications have more raw data, BI applications get their well prepared star schema galaxy models, and Process Mining apps get normalized event logs. Using data sharing (in Databricks: Delta Sharing) data products or single datasets can be shared through applications and owners.
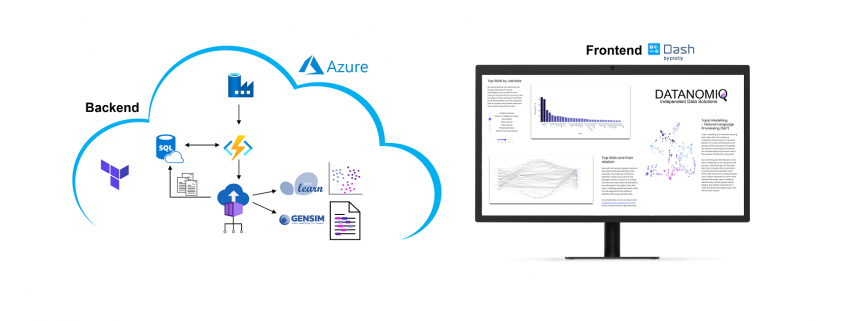
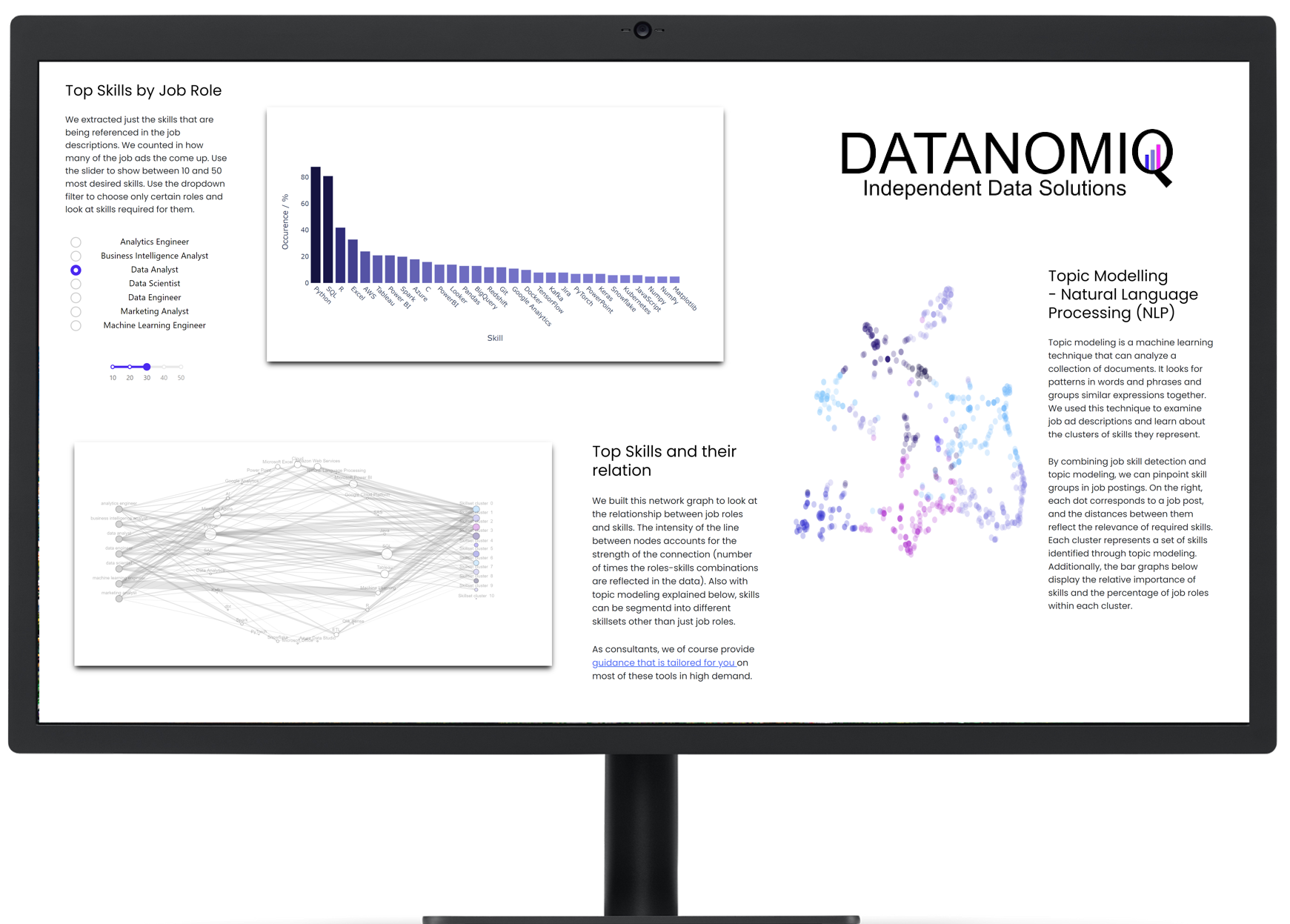
On own account, we from DATANOMIQ have created a web application that monitors data about job postings related to Data & AI from multiple sources (Indeed.com, Google Jobs, Stepstone.de and more).
The data is obtained from the Internet via APIs and web scraping, and the job titles and the skills listed in them are identified and extracted from them using Natural Language Processing (NLP) or more specific from Named-Entity Recognition (NER).
The skill clusters are formed via the discipline of Topic Modelling, a method from unsupervised machine learning, which show the differences in the distribution of requirements between them.
The whole web app is hosted and deployed on the Microsoft Azure Cloud via CI/CD and Infrastructure as Code (IaC).
The presentation is currently limited to the current situation on the labor market. However, we collect these over time and will make trends secure, for example how the demand for Python, SQL or specific tools such as dbt or Power BI changes.
Why we did it? It is a nice show-case many people are interested in. Over the time, it will provides you the answer on your questions related to which tool to learn! For DATANOMIQ this is a show-case of the coming Data as a Service (DaaS) Business.
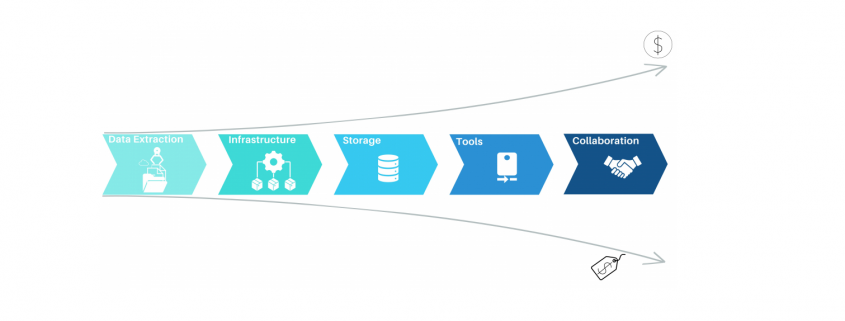
Process mining has emerged as a powerful Business Process Intelligence discipline (BPI) for analyzing and improving business processes. It involves extracting data from source systems to gain insights into process behavior and uncover opportunities for optimization. While there are many approaches to create value with process mining, organizations often face challenges when it comes to the cost of implementing the necessary solution. In this article, we will highlight the key elements when it comes to process mining architectures as well as the most common mistakes, to help organizations leverage the power of process mining while maintain cost control.
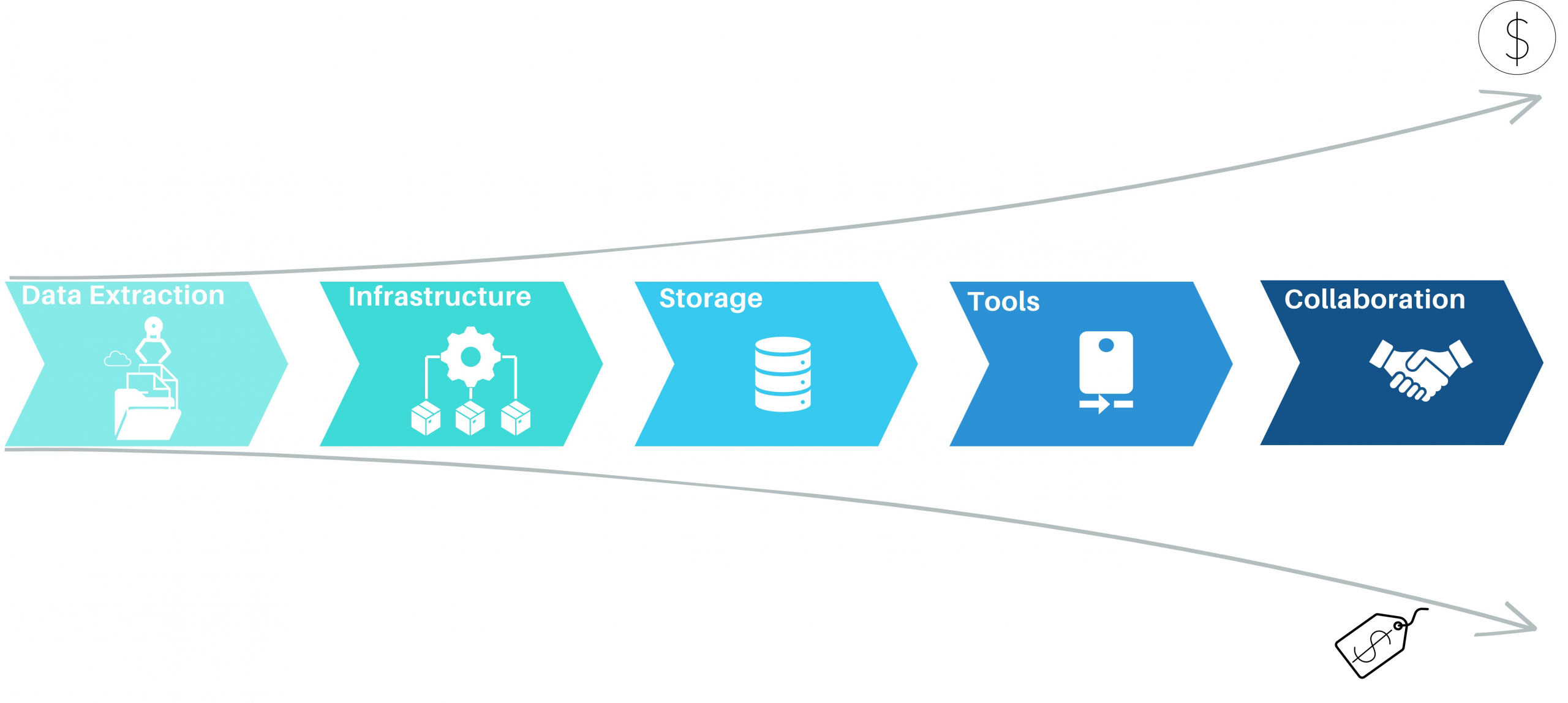
Process Mining – Elements of Process Mining and their cost aspects
Most process mining projects underestimate the complexity of data extraction. Even for well-known sources like SAP-ERP’s, the extraction often consumes 50% of the first pilot’s resources. As a result, the extraction pipelines are often built with the credo of “asap” and this is where the cost-drama begins. Process Mining demands Big Data in 99% of the cases, releasing bad developed extraction jobs will end in big cost chunks down the value stream. Frequently organizations perform full loads of big SAP tables, causing source system performance impact, increasing maintenance, and moving hundred GB’s of data on daily basis without any new value. Other organizations fall for the connectors, provided by some process mining platform tools, promising time-to-value being the best. Against all odds the data is getting extracted then into costly third-party platforms where they can be only consumed by the platforms process mining tool itself. On top of that, these organizations often perform more than one Business Process Intelligence discipline, resulting in extracting the exact same data multiple times.
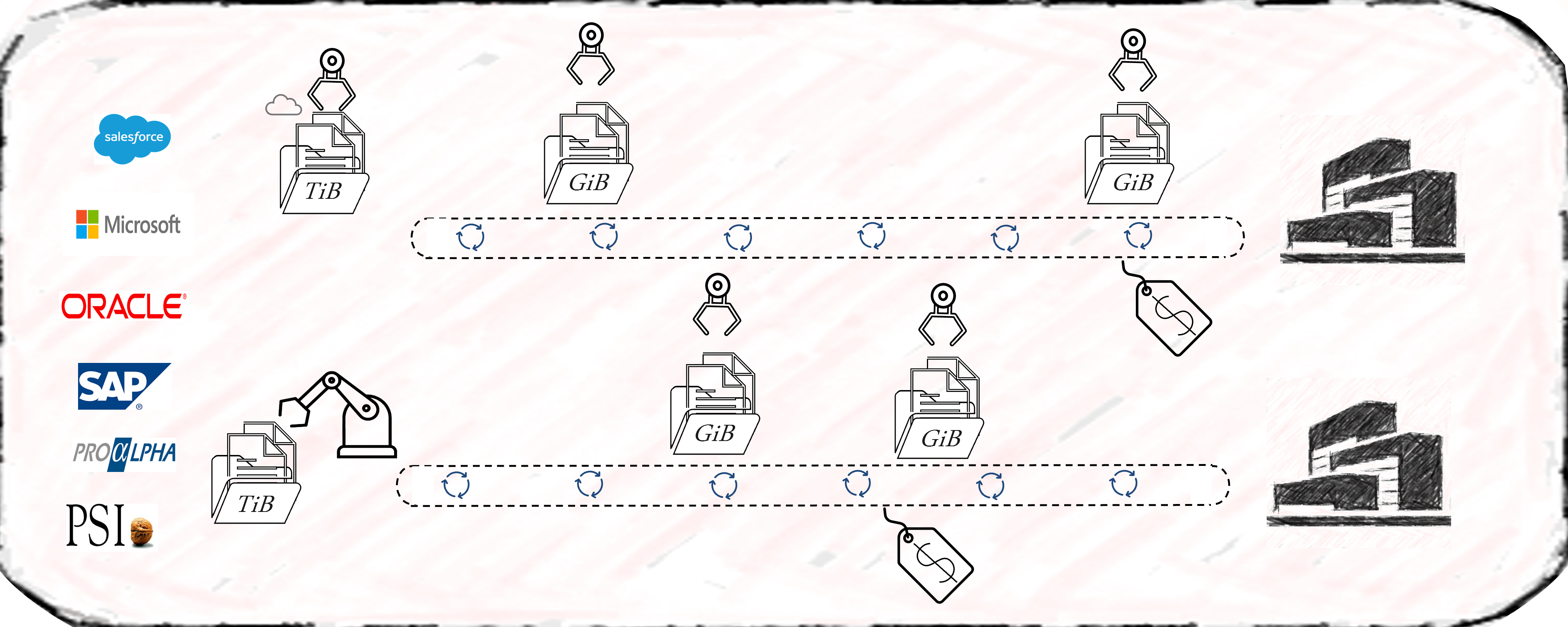
Process Mining – Data Extraction
The data extraction for process mining should be well planed and match the data strategy of the organization. By considering lightweighted data preprocessing techniques organizations can save both time and money. When accepting the investment character of big data extractions, the investment should be done properly in the beginning and therefore cost beneficial in the long term.
Depending on the data strategy of one organization, one cost-effective approach to process mining could be to leverage cloud computing resources. Cloud platforms, such as Amazon Web Services (AWS), Microsoft Azure, or Google Cloud Platform (GCP), provide scalable and flexible infrastructure options. By using cloud services, organizations can avoid the upfront investment in hardware and maintenance costs associated with on-premises infrastructure. They can pay for resources on a pay-as-you-go basis, scaling up or down as needed, which can significantly reduce costs. When dealing with big data in the cloud, meeting the performance requirements while keeping cost control can be a balancing act, that requires a high skillset in cloud technologies. Depending the organization situation and data strategy, on premises or hybrid approaches should be also considered. But costs won’t decrease only migrating from on-premises to cloud and vice versa. What makes the difference is a smart ETL design capturing the nature of process mining data.
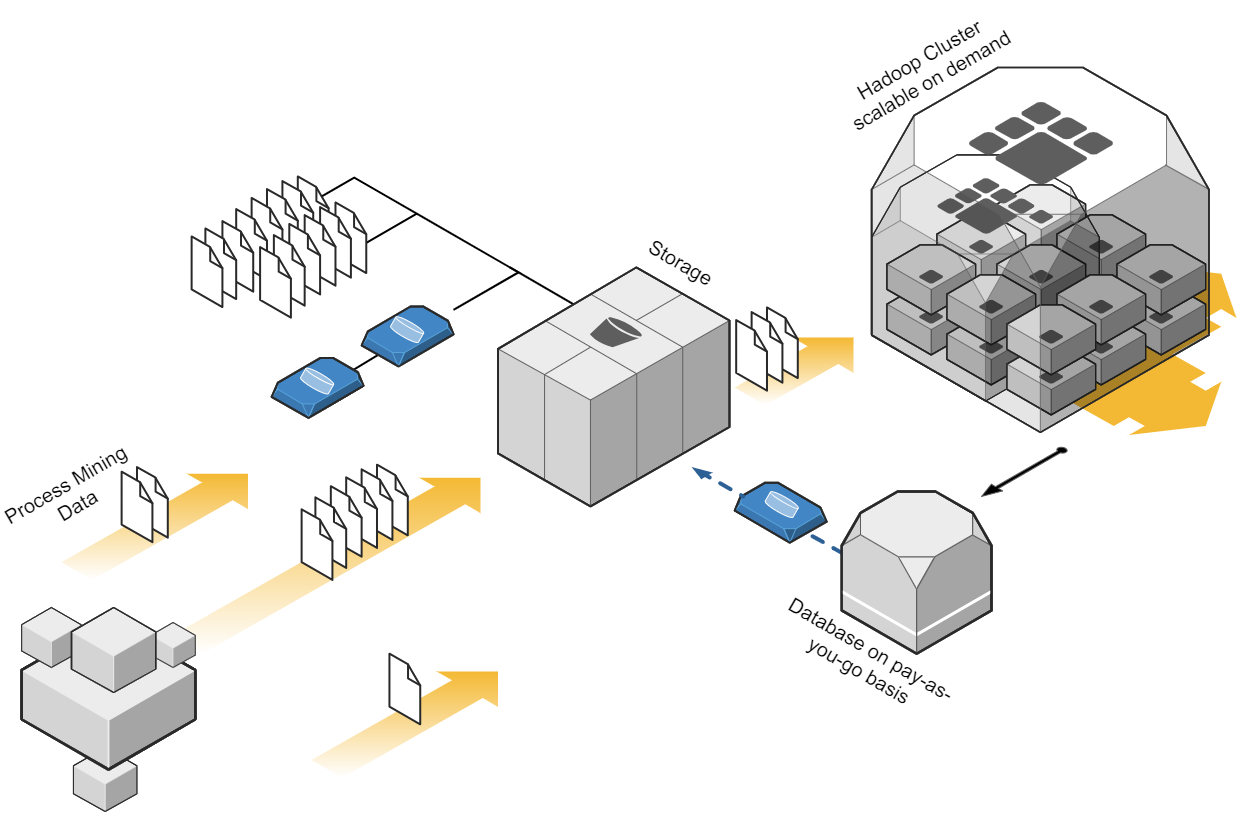
Process Mining Cloud Architecture on “pay as you go” base.
Storing data is a crucial aspect of process mining, as in most cases big data is involved. Instead of investing in expensive data storage solutions, which some process mining solutions offer, organizations can opt for cost-effective alternatives. Cloud storage services like Amazon S3, Azure Blob Storage, or Google Cloud Storage provide highly scalable and durable storage options at a fraction of the cost of process mining storage systems. By utilizing these services, organizations can store large volumes of event data without incurring substantial expenses. Moreover, when big data engineering technics, consider profound process mining logics the storage cost cut down can be tremendous.
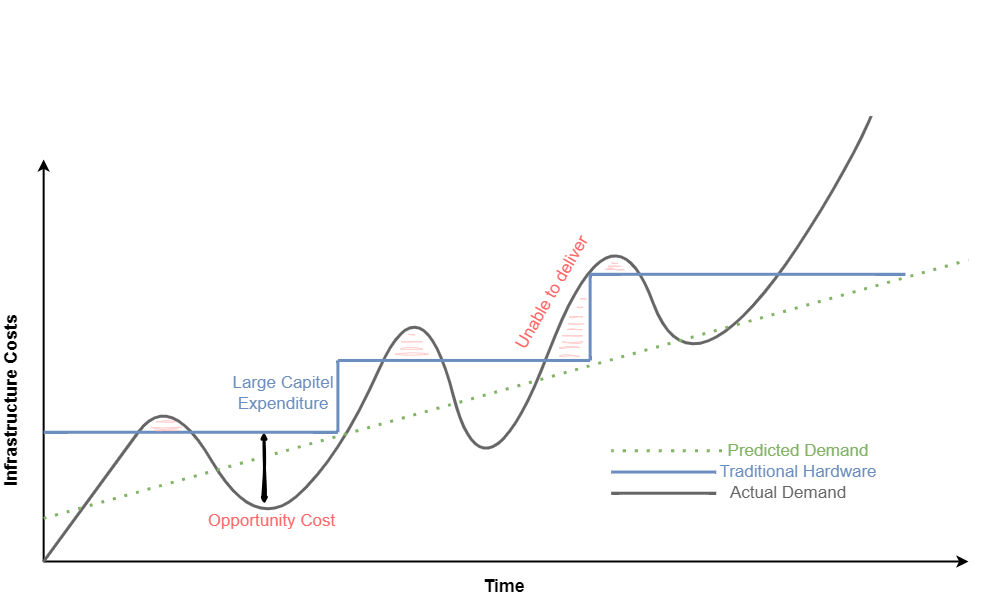
Process Mining – Infrastructure Cost Curve: On-Premise vs Cloud
While some commercial process mining tools can be expensive, there are several powerful more economical alternatives available. Tools like Process Science, ProM, and Disco provide comprehensive process mining capabilities without the hefty price tag. These tools offer functionalities such as event log import, process discovery, conformance checking, and performance analysis. Organizations often mismanage the fact, that there can and should be more then one process mining tool available. As expensive solutions like Celonis have their benefits, not all use cases make up for the price of these tools. As a result, these low ROI-use cases will eat up the margin, or (and that’s even more critical) little promising use cases won’t be investigated on and therefore high hanging fruits never discovered. Leveraging process mining tools can significantly reduce costs while still enabling organizations to achieve valuable process insights.

Process Mining Tool Landscape (examples shown)
Another cost-saving aspect is to encourage collaboration within the organization itself. Most process mining initiatives require the input from process experts and often involve multiple stakeholders across different departments. By establishing cross-functional teams and supporting collaboration, organizations can share resources and distribute the cost burden. This approach allows for the pooling of expertise, reduces duplication of efforts, and facilitates knowledge exchange, all while keeping costs low.
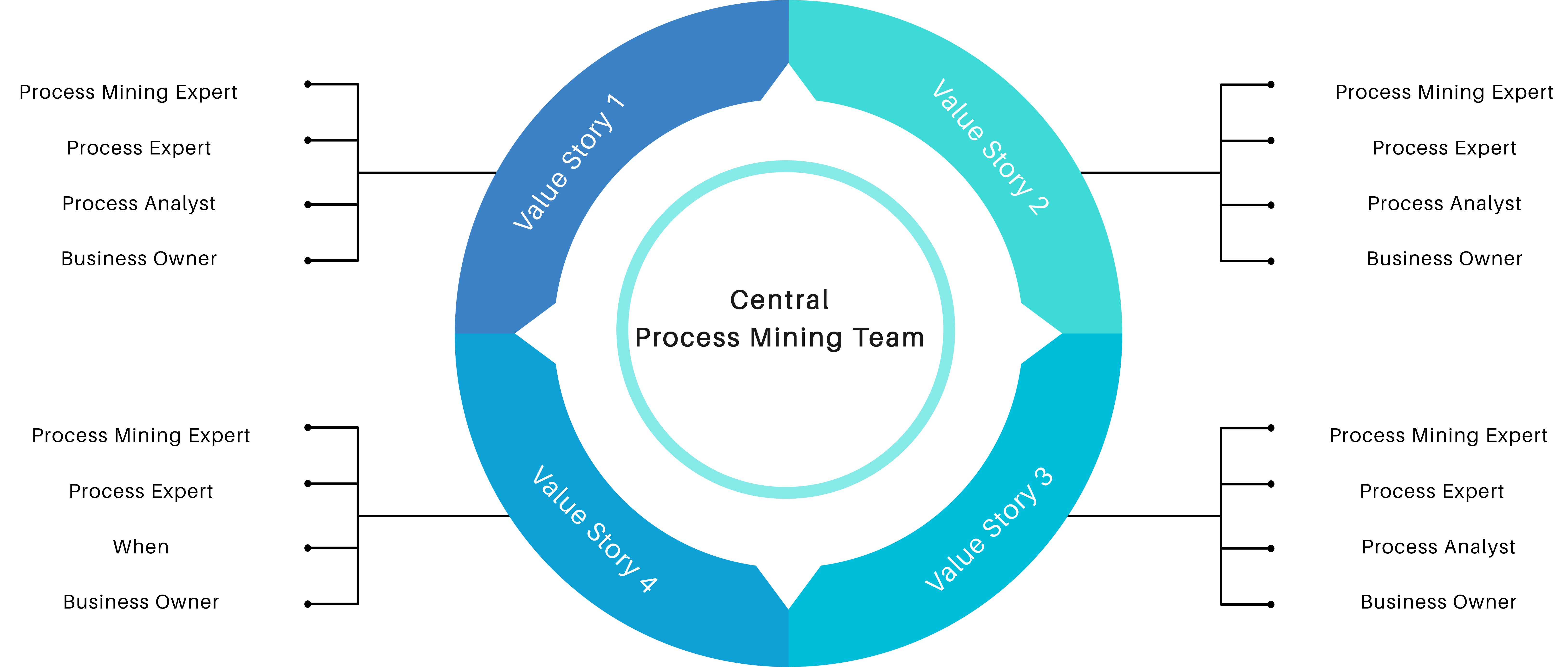
Process Mining Team Structure
Process mining offers tremendous potential for organizations seeking to optimize their business processes. While many organizations start process mining projects euphorically, the costs set an abrupt end to the party. Implementing a low-cost and collaborative architecture can help to create a sustainable value for the organization. By leveraging cloud-based infrastructure, cost-effective storage solutions, big data engineering techniques, process mining tools, well developed data extractions, lightweight data preprocessing techniques, and fostering collaboration, organizations can embark on process mining initiatives without straining their budgets. With the right approach, organizations can unlock the power of process mining and drive operational excellence without losing cost control.
One might argue that implementing process mining is not only about the costs. In the end each organization must consider the long-term benefits and return on investment (ROI). But with a cost controlled and sustainable process mining approach, return on investment is likely higher and less risky.
This article provides general information for process mining cost reduction. Specific strategic decisions should always consider the unique requirements and restrictions of individual organizations.

Wie sich mit Data Science die Profitabilität des Kreditkartengeschäfts einer Bank nachhaltig steigern lässt.
Die Fragestellung
Das Kreditkartengeschäft einer Bank brachte nicht die erhofften Gewinne ein, weshalb die Pricing-Strategie dieses Geschäftszweiges optimiert werden sollte. Hierbei sollte allerdings unbedingt vermieden werden, dass Kund:innen aufgrund erhöhter Zinskosten abspringen.
Die Frage, die sich hieraus ergab, lautete: Welche der Kund:innen würden höhere Zinskosten akzeptieren und welche würden bei einer Erhöhung der Zinsen ihre Kreditkarte kündigen? Um Kündigungen zu vermeiden, sollten deshalb zunächst eindeutige Kundensegmente identifiziert werden. Das Ziel war weiterhin, den weniger preissensitiven Kund:innen neue, lukrativere Kreditprodukte anzubieten, ohne gleichzeitig die Loyalität der Kund:innen zu gefährden.
Das Vorgehen
Um die verschiedenen Kundengruppen zu identifizieren, sollten die Kund:innen mithilfe einer Clustering-Analyse in klar voneinander abgegrenzte Segmente eingeteilt werden. Bei einer Clustering-Analyse handelt es sich um ein maschinelles Lernverfahren, bei dem Datenpunkte, in diesem Fall also Kund:innen zu Clustern oder Segmenten zusammengefasst werden. Bei einer solchen Analyse werden jene Kund:innen zu Clustern zusammengefasst, die sich in vielen Eigenschaften ähneln.
Der Vorteil an diesem Vorgehen ist, dass bei einer Clustering-Analyse eine Vielzahl an Eigenschaften gleichzeitig betrachtet werden kann. Außerdem können die erstellten Segmente dynamisch angepasst werden, wenn neue Daten in die Analyse eingehen. Zudem bietet ein Clustering-Modell die Möglichkeit, neue Kunden zu bewerten und einem bestehenden Cluster zuzuordnen, sofern die entsprechenden Daten über sie vorliegen.
Kunden segmentieren
Die Bank verfügte über vielfältige Daten den Kund:innen. Dazu gehörten persönliche Informationen wie Alter, Geschlecht, Bonität, Anzahl und Art der genutzten Kreditprodukte, Anzahl und Art der mit der Kreditkarte getätigten Transaktionen, aber auch Informationen zur bisherigen Beziehung zwischen Kund:in und Bank, wie beispielsweise Kontaktaufnahmen mit dem Kundenservice, Beschwerden, Net Promoter Score u.s.w.
Nachdem die Kund:innen anhand all dieser Eigenschaften einer Clustering-Analyse unterzogen worden waren, konnten verschiedene Gruppen identifiziert werden. Ein Vergleich dieser Gruppen untereinander ergab, dass es Kund:innen gibt, für die der Umfang der gebotenen Leistungen der Bank wichtiger war als der Zinssatz, also der Preis dieser Leistungen. Diese Kund:innen waren entsprechend als weniger preissensitiv bezüglich der Zinskosten einzuschätzen. In einem weiteren Segment wurden Kunden identifiziert, die eine Steigerung des Zinssatzes akzeptieren würden, weil sie die Kreditkarte sehr häufig verwendeten.
Durch die Bestimmung dieser wenig preissensitiven Cluster war die Bank zunächst in der Lage, diesen Kund:innen neue und lukrativere Kreditprodukte anzubieten.
Kundenloyalität messen
Darüber hinaus war der Bank wichtig, auch die Kundenzufriedenheit und -loyalität genauer zu beobachten, um Abwanderungen zu vermeiden.
Eine Möglichkeit, die Zufriedenheit und Loyalität von Kund:innen einzuschätzen besteht darin, ihre Sprache zu untersuchen, wenn sie im Austausch mit dem Kundenservice stehen. Aufgrund ihrer Wortwahl – ob mündlich oder schriftlich – können KI-Technologien den Emotionszustand der Kund:innen bestimmen. Positive Emotionen können hierbei allgemein als Zeichen der Loyalität und Zufriedenheit gedeutet werden, wohingegen negative Emotionen vor allem in Beschwerden oder schlechten Bewertungen vorkommen, die einen Kundenverlust zur Folge haben können. Das Ziel der Bank war es, Anfragen mit negativen Emotionen, also wahrscheinlich Beschwerden oder negative Bewertungen schneller zu erkennen, um diese priorisiert beantworten zu können und so einen drohenden Kundenverlust zu vermeiden.
In der Sprache ausgedrückte positive oder negative Emotionen können mit einer sogenannten Sentiment Analysis untersucht werden, wobei die Sprache der Kunden – ob schriftlich oder mündlich – mit KI-Technologien untersucht wird. Dafür kommt Natural Language Processing – eine Reihe der KI-Technologien zur Analyse menschlicher Sprache – zur Anwendung. Anhand dieser KI-Technologie wurden eingehende Nachrichten und Bewertungen einer automatischen Voruntersuchung unterzogen. Nachrichten und Bewertungen, die mit negativen Emotionen assoziiert wurden, wurden priorisiert bearbeitet. Durch die priorisierte Bearbeitung konnte eine 50%ige Reduktion der Antwortzeiten auf Beschwerden erzielt werden.
Die Ergebnisse
In diesem Projekt konnte die Bank durch verschiedene Ansätze das Kreditkartengeschäft optimieren sowie die Kundenreaktion auf die Zinssteigerung bzw. die Kundenloyalität in Echtzeit messen:
Dies ist nur eins von vielen Beispielen, wie Sie mit Data Science im Banking zu Erkenntnissen gelangen, die Sie gewinnbringend bzw. kostensparend einsetzen können.
Qualifizieren Sie sich mit den Seminaren und Trainings der Haufe Akademie rund um das Thema Data Science weiter!
Sie wollen auf Augenhöhe mit Data Scientists kommunizieren und im richtigen Moment die richtigen Fragen stellen können?
Oder Sie wollen selbst tief in die Welt der Data Science eintauchen und programmieren können? Wir bieten Ihnen die Qualifizierungen, die für Sie passen!
Aktuelle Kursangebot des Data Science Blog Sponsors, die Haufe Akademie:



Data Science und AI sind aufstrebende Arbeitsfelder, die sich mit der Gewinnung von Wissen aus Daten beschäftigen. Die Nachfrage nach Fähigkeiten im Bereich Data Science, aber auch in angrenzenden Bereichen wie Data Engineering oder Data Analytics, ist in den letzten Jahren explodiert, da Unternehmen versuchen, die Vorteile von Big Data und künstlicher Intelligenz (KI) zu nutzen. Es lohnt sich sehr, sich in diesen Bereich weiter zu entwickeln. Dafür eignen sich die Kurse von Coursera.org.
Online-Kurse lohnen sich dann, wenn eine Karriere im Bereich der Datenanalyse oder des maschinellen Lernens angestrebt oder einfach nur ihr Wissen in diesem Bereich erweitert werden soll.
Data Science hilft dabei, Entscheidungen auf Basis von Daten zu treffen, komplexe Probleme effektiver zu lösen und Karrierechancen zu verbessern. Die Tools von Google Cloud und Jupyter Notebook sind dafür geeignet, da sie eine leistungsstarke und skalierbare Infrastruktur sowie eine interaktive Entwicklungsplattform bieten.

Das Google Zertifikat für Datenanalyse behandelt neben dem Handwerkszeug für jeden Data Analyst – wie etwa SQL – auch die notwendige Datenbereinigung und Datenvisualisierung mit den Tools von Google. Es werden weder Erfahrung noch Vorkenntnisse vorausgsetzt.
Der Zertifikatskurs der erweiterten Datenanalyse von Google baut auf dem zuvorgenannten Data Analytics Kurs auf, kann jedoch auch direkt besucht werden. Hier werden grundlegende Fähigkeiten wie SQL vorausgesetzt und vertiefende Fähigkeiten vermittelt, die für einen Data Analysten nützlich sind und auch in die Data Science eintauchen.

Dieses Kursangebot zum Aufbau erweiterter Datenanalyse-Fähigkeiten von Coursera wird ebenfalls von Google angeboten. Hier werden die Tools der Datenanalyse sowie der statistischen Handwerkzeuge für Data Science eingeführt, bis hin zum ersten Einstieg in Machine Learning.
SQL ist wichtig für etablierte und angehende Data Scientists, da es eine grundlegende Technologie für die Arbeit mit Datenbanken und relationalen Datenbankmanagementsystemen ist. SQL für Data Science ermöglicht, Daten effektiv zu organisieren und schnell Abfragen zu erstellen, um Antworten auf komplexe Fragen zu finden. Es ist auch relevant für die Arbeit mit nicht-relationalen Datenbanken und hilft Data Scientists, wertvolle Erkenntnisse aus großen Datenmengen zu gewinnen.

Auch wenn Python als Skill für einen Data Scientist ganz vorne steht, ist eine Karriere als Data Scientist ohne SQL-Kenntnisse nicht vorstellbar und dieser Kurs daher der richtige, wenn Nachbolbedarf besteht.
Eine Karriere als Data Analyst ist attraktiv, da ihr eine hohe Nachfrage am Arbeitsmarkt gegenüber steht, die Arbeit vielfältig und herausfordernd ist, viele Weiterentwicklungsmöglichkeiten (z. B. zum Data Scientist) bietet und oft flexibel ist.

Der Online-Kurs von IBM bietet die Ausbildung der beruflichen Qualifikation zum Data Analyst. Ein weiterer Vorteil dieses Kurses ist, dass er für alle geeignet ist – unabhängig von ihrem Hintergrund oder der Vorbildung. Es sind keine Abschlüsse oder Vorkenntnisse erforderlich, was bedeutet, dass jeder, der sich für das Thema interessiert, am Kurs teilnehmen und von ihm profitieren kann.
Dieser Kurs bietet den Teilnehmern die Möglichkeit, ihre Kenntnisse in der Datenverarbeitung zu verbessern, eine Programmiersprache wie Python zu erlernen und grundlegende Kenntnisse in SQL zu erwerben. Diese Fähigkeiten sind für die Arbeit mit Daten unerlässlich und in der heutigen Arbeitswelt sehr gefragt. Darüber hinaus bietet der Kurs für Datenverarbeitung mit Python und SQL auch Schulungen zur Analyse und Visualisierung von Daten sowie zur Erstellung von Modellen für Maschinelles Lernen. Diese Fähigkeiten sind besonders wertvoll für die Entwicklung von Anwendungen und Systemen im Bereich der KI.

Dieser Kurs ist eine großartige Möglichkeit für alle, die ihre Kenntnisse im Bereich der Datenverarbeitung und des maschinellen Lernens verbessern möchten. Zwar werden auch hier keine Vorkenntnisse vorausgesetzt, jedoch geht der Kurs inhaltlich mehr in die Richtung Data Science als der zuvorgenannte Kurs zum Data Analyst und bietet ein umfassendes Training und Schulungen zu grundlegenden Fähigkeiten, die in der heutigen Arbeitswelt gefragt sind, und ist für jeden zugänglich, unabhängig von Hintergrund oder Erfahrung.
Das Erlernen der Grundlagen des maschinellen Lernens (Machine Learning) ist von großer Bedeutung, da es eine der am schnellsten wachsenden und wichtigsten Technologien in der heutigen Zeit ist. Maschinelles Lernen ermöglicht es Computern, aus Erfahrung zu lernen, ohne explizit programmiert zu werden. Die Teilnehmer lernen, dem Computer das lernen zu ermöglichen.

Machinelles Lernen ist der Schlüssel zur Entwicklung von Anwendungen und Systemen im Bereich der künstlichen Intelligenz (KI) und hat Anwendungen in vielen Bereichen, von der Gesundheitsversorgung und der Finanzindustrie bis hin zur Unterhaltungsbranche und der Automobilindustrie.
Der Kurs für Maschinelles Lernen ist nicht nur ein sinnvoller Einstieg in diese Materie, sondern kann darauf aufbauend mit dem Thema Deep Learning in der Qualifikation erweitert werden.
Das Verständnis von Deep Learning ist wichtig, da es eine Unterkategorie des maschinellen Lernens ist und viele noch mächtigere Anwendungen in verschiedenen Bereichen hat. Die populäre Applikation ChatGPT ist ein Produkt des Deep Learning. Deep Learning kann mit AI gleichgesetzt werden. Es ist eine gefragte Fähigkeit auf dem Arbeitsmarkt mit Job-Garantie.

Der Spezialisierungskurs für Deep Learning steht unabhängig für sich und erfordert keine speziellen Vorkenntnisse, darf jedoch auch als sinnvolle Ergänzung zum vorgenannten Einführungskurs in Machine Learning betrachtet werden.
![]()
Die Entscheidung für ein bestimmtes Thema eines Kurses in den Bereichen Data Analytics, Data Science und AI ist eine persönliche und abhängig von den eigenen Vorkenntnissen und Vorlieben, sowie den eigenen Karrierezielen. Für die Karriere des Data Analyst sind SQL sowie allgemeine Kenntnisse rund um Data Analytics bzw. Datenverarbeitung wichtig. Von einem Data Scientist wird ferner erwartet, die theoretischen Grundlagen sowie die praktische Anwendung von Machine Learning und Deep Learning als trainierte Fähigkeit abrufbar zu haben.
Weitere Kurse von Coursera zum Thema Data & AI (link).

Fristgerecht bezahlen oder Skontoeffekte nutzen? Wie Sie mit Data Science Ihre Zahlungsläufe intelligent gestalten.
Die Fragestellung: Die Geschäftsführung eines Unternehmens wollte den optimalen Zeitpunkt herausfinden, zu dem offene Verbindlichkeiten beglichen werden sollten. Im Fokus stand die Frage, ob Rechnungen zum vereinbarten Zahlungsdatum bezahlt werden sollten oder ob im Fall einer Skontogewährung eine vorzeitige Bezahlung lukrativer wäre, um mögliche Rabatteffekte zu nutzen.
Die zentrale Frage war nun: Welche finanziellen Auswirkungen hat es auf das Unternehmen, wenn eine offene Rechnung nicht zeitnah beglichen und somit auf das Skonto verzichtet wird, um dafür die Liquidität länger im Unternehmen zu halten?
Oder etwas anschaulicher gesprochen: Falls das Unternehmen eine Rechnung in Höhe von 100.000 € eine Woche vor Zahlungsdatum bezahlt und den Skontorabatt nutzt, wird ein prozentualer Rabatt auf den Standardpreis gewährt. Durch die vorgezogene Zahlung verliert das Unternehmen aber an Liquidität. Bei Bezahlung zum letztmöglichen Zahlungsziel würden die 100.000 € länger im Geldkreislauf des Unternehmens fließen und eine Rendite, genannt Return on Capital, erzielen.
Die Balance zwischen den beiden Geldflüssen wird dabei maßgeblich durch zwei Faktoren beeinflusst:
Vorgehen: Um sich dem Problem anzunähern, wurden die Daten zu den eingegangenen Rechnungen untersucht, die aus dem internen ERP-System abgerufen wurden. Mit Business Intelligence Tools konnten dann erste Analysen durchgeführt werden, um die folgenden Fragen zu beantworten:
Optimales Zahlungsdatum ermitteln
In einer folgenden Analyse sollte die ideale Balance zwischen Ausnutzung des Skontos und einer hohen Liquidität im Unternehmen gefunden werden. Ermittelt werden sollte das optimale Datum zur Begleichung einer Rechnung. Dabei wurden folgende Parameter verwendet:
Die oben beschriebene einfache Fragestellung wurde durch verschiedene Einflussfaktoren jedoch noch komplexer:
Wenn der monatliche Zahlungslauf am dritten Mittwoch eines Monats stattfindet, und die Rechnung am dritten Montag zu bezahlen ist, müsste diese im vorherigen Zahlungslauf, also beinahe einen Monat vor dem eigentlichen Fälligkeitsdatum bezahlt werden. Das bedeutet, dass beinahe ein Monat verloren geht, in dem das Geld im Unternehmen fließen und eine Rendite erzielen könnte. Die Skontorabatte oder auch die Maximierung der Liquidität im Unternehmen würden allerdings erst dann optimal ausgeschöpft, wenn jede Rechnung genau zu diesem Zahlungsdatum oder Skontodatum bezahlt würde.
Zahlungsläufe optimieren
Anhand der gewonnenen Erkenntnisse ergab sich also eine neue Fragestellung: Wie sind die Zahlungsläufe anzupassen, um die höchstmögliche Ersparnis zu erzielen? Hierfür wurde der erste Analyseschritt so angepasst, dass der Tag des Zahlungslaufs nicht als gesetzter Wert betrachtet wurde, sondern als unabhängiger Parameter zu verstehen war, dessen Wert es ebenfalls zu optimieren galt.
Zahlungsbedingungen analysieren
Die bisherige Analyse eignete sich schon sehr gut dafür, Maßnahmen zur Optimierung des Cash Managements sowie des Return on Capital voranzutreiben. Im nächsten Schritt sollten nun die Zahlungsbedingungen mit Lieferanten genauer analysiert und gegebenenfalls neu verhandelt werden.
Um die Zahlungsbedingungen in Rechnungen und Lieferverträgen der Lieferanten automatisch zu analysieren, wurde eine KI-Technologie eingesetzt, die in der Lage ist, gesprochene oder geschriebene Sprache zu erkennen, zu analysieren und weiterzuverarbeiten.
Mithilfe dieser KI-Technologie gelang es, die Zahlungsbedingungen zu analysieren und Diskrepanzen (z. B. zwischen Zahlungszielen und zu früh verschickten Mahnungen) zu identifizieren. Anhand der neu gewonnenen Erkenntnisse wurde im Anschluss an das KI-Projekt noch einmal mit den Lieferanten nachverhandelt. Dies stellt einen zentralen Punkt jedes Data Science-Projekts dar. Damit Data Science-Projekte nachhaltigen Wert schöpfen, müssen Auswertungen und Modelle ihren Platz in der betrieblichen Realität des Unternehmens finden und in die tagtägliche Arbeit eingebunden werden. Auf diese Weise gelingt es, Data Science gewinnbringend einzusetzen.
Ergebnisse:
In diesem Projekt konnte die Geschäftsführung mit Buchhaltungsdaten aus dem ERP-System drei maßgebliche Verbesserungen in der Buchhaltung erzielen:
Neugierig geworden? Denn dies ist nur eins von vielen Beispielen, wie Sie durch Data Science im Controlling zu Erkenntnissen gelangen, die Sie im Unternehmen gewinnbringend bzw. kostensparend umsetzen können.
Qualifizieren Sie sich mit den Seminaren und Trainings der Haufe Akademie rund um das Thema Data Science weiter!
Sie wollen auf Augenhöhe mit Data Scientists kommunizieren und im richtigen Moment die richtigen Fragen stellen können?
Oder Sie wollen selbst tief in die Welt der Data Science eintauchen und programmieren können? Wir bieten Ihnen die Qualifizierungen, die für Sie passen!
Aktuelle Kursangebot des Data Science Blog Sponsors, die Haufe Akademie:

Das Format Business Talk am Kudamm in Berlin führte ein drittes Interview mit Benjamin Aunkofer zum Thema “Datenstrategie und Data Team Organisation”.
In dem Interview erklärt Benjamin Aunkofer, was Unternehmen Datenstrategien entwickeln, um Ihren Herausforderungen gerecht zu werden. Außerdem gibt er Tipps, wie Unternehmen ein fähiges Data Team aufbauen, qualifizieren und halten.
Nachfolgend das Interview auf Youtube sowie die schriftliche Form zum Nachlesen:
Und beim Coaching schauen wir dann eigentlich nur zu und geben Ratschläge, wie man besser an die Aufgabenstellung herangehen könnte. Der Mitarbeiter hat also selbst das Zepter in der Hand und das Doing.Wir sind dann nur der Support.
So können wir Stellen schnell besetzen und niemand muss Sorge haben, dass die Kompetenz nicht ausreicht. Auf diese Weise habe ich schon mehrere Data Teams für Kunden aufgebaut und parallel natürlich auch mein eigenes.
Sehen Sie die zwei anderen Video-Interviews von Benjamin Aunkofer:

Die Fragestellung: Ein Hersteller von Elektrogeräten lancierte einen neuen Online-Shop, um einen neuen Vertriebskanal zu schaffen, der unabhängig von stationären Einzelhändlern und Amazon ist. Obwohl der Online-Shop von Interessent:innen häufig besucht wurde, war die Conversion-Rate zu niedrig und der Umsatz somit zu gering.
Die zentrale Frage war nun: Wie kann die Conversion-Rate erhöht werden, um den Umsatz über den neuen Vertriebskanal zu erhöhen?
Was ist eine Conversion-Rate? Die Conversion-Rate ist eine Marketing-Kennzahl, die in diesem Beispiel das Verhältnis der Besucher:innen des Online-Shops zu den getätigten Käufen meint. Halten sich viele Besucher:innen im Online-Shop auf und sind die Warenkorb-Abschlüsse dennoch gering, so ist die Conversion-Rate niedrig. Das Ziel ist es, die Conversion-Rate zu steigern, also dafür zu sorgen, dass Besucher:innen, die sich im Online-Shop befinden und dort etwas in den Warenkorb legen, auch einen Kauf tätigen.
Vorgehen: Um zu verstehen, warum eine Bestellung abgeschlossen bzw. nicht abgeschlossen wurde, wurden verschiedene Daten aus dem Web-Analytics-System des Online-Shops untersucht. Dazu gehörten im Wesentlichen Daten zu Besucherhandlungen auf der Website, die automatisch getrackt, also aufgezeichnet werden, wie z. B. Button & Link-Klicks, Bildergalerie öffnen, Produktvideo ansehen, Produktbeschreibung ausklappen, Time on page usw.
Mit diesen Daten wurden drei Analyseverfahren durchgeführt.
Zunächst wurden mit einer explorativen Datenanalyse die Website-Besucher:innen und deren Bedürfnisse untersucht. Über die meisten der Besucher:innen lagen bereits Daten vor, da sie in der Vergangenheit bereits Käufe auf der Website getätigt hatten und dafür ein Konto angelegt hatten. Darüber hinaus wurde untersucht, über welche Kanäle die Besucher:innen in den Online-Shop gelangten, beispielsweise über Google oder Facebook. Informationen zu Gerät, Standort, Browser und Betriebssystem waren ebenfalls verfügbar.
Anhand dieser unterschiedlichen Parameter wurden die Benutzerdaten einem Analyseverfahren, dem sog. Clustering, unterzogen, bei dem die Website-Besucher:innen aufgrund ihrer Ähnlichkeiten in verschiedenen Eigenschaften in Gruppen („Cluster“) eingeteilt wurden.
Beispiel: Besucher über Android-Smartphones und Chrome-Browser, die zwischen 17 und 19 Uhr am Samstag auf der Website sind, kaufen eher familienbezogene Produkte.
Daraufhin konnte man neue Website-Besucher:innen aufgrund der verschiedenen Eigenschaften meist recht eindeutig einem Cluster zuordnen, da ähnliche Besucher:innen tendenziell ein ähnliches Verhalten auf einer Website zeigen. Dieses Clustering lieferte dem Unternehmen bereits wertvolle Informationen. So konnten auf dieser Informationsgrundlage individuelle Marketingstrategien für verschiedene Zielgruppen entwickelt, das Werbe-Targeting angepasst und spezifische Sonderangebote erstellt werden.
Beispiel: Besucher über Android-Smartphones und Chrome-Browsern, die zwischen 17 und 19 Uhr am Samstag auf der Website sind, bekommen ein Sonderangebot für ein familienbezogenes Produkt, wie beispielsweise ein Babyfon ausgespielt.
In vielen Fällen reicht eine solche Analyse bereits aus, um die Conversion-Rate eines Online-Shops spürbar zu steigern. In diesem Projekt wurden jedoch noch zwei weitere Analyseschritte durchgeführt.
Der nächste Schritt bestand darin, den Conversion Path der Kund:innen zu untersuchen. Der Conversion Path umfasst alle Handlungen von Kund:innen vom Ankommen auf der Website über den Besuch verschiedener Seiten bis hin zum finalen Kauf bzw. Kaufabbruch. Bei der Analyse wurden alle Conversion Paths auf Gemeinsamkeiten und Unterschiede untersucht, um bestimmte Muster abzuleiten. Von besonderem Interesse waren mögliche Gründe, aus denen Besucher:innen ihre Sitzung vor Kaufabschluss abbrachen. Es stellte sich heraus, dass Besucher:innen ihre Sitzung vor allem dann abbrachen, wenn es für ein Produkt kein Produktvideo gab bzw. das Produktvideo nicht gefunden wurde. Diese mangelnde Produktinformation konnte anschließend gezielt bearbeitet werden, woraufhin sich die Conversion-Rate deutlich verbesserte.
Im dritten Schritt des Projektes zur Steigerung der Conversion-Rate wurde der Ansatz der Next-best-Action (NBA) gewählt. Damit wurde hier ein weiterer Schritt von der reinen Analyse von bereits vorhandenen Daten hin zur Vorhersage zukünftigen Verhaltens gewählt.
Was bedeutet Next-best-action? Next-best-action (NBA) ist eine Marketingstrategie, die darauf abzielt, Informationen über einzelne Kund:innen zu sammeln und zu nutzen, um einen Kauf anzuregen. Wie der Name schon sagt, wird versucht zu ermitteln, welcher der nächste beste Schritt im Verkaufsprozess für jede:n einzelne:n Kunde:in ist.
Mithilfe der allgemeinen Informationen über die Website-Besucher:innen und der Conversion Paths konnten unterschiedliche Aktionen identifiziert werden, die einen Kauf wahrscheinlicher machen würden. Dazu gehörte z. B., den Besucher:innen das Produktvideo anzuzeigen, einen Rabatt-Code oder ein Sonderangebot für eine spezielle Produktkategorie anzubieten oder ein Chat-Fenster für den Kundensupport zu öffnen.
Somit half die NBA-Vorhersage dabei, die Conversion erneut deutlich zu steigern, indem für jede:n Website-Besucher:in eine individuelle Aktion vorgeschlagen werden konnte.
In diesem Projekt konnte die Marketingabteilung des Elektrogeräte-Herstellers durch drei verschiedene Analyseansätze die Conversion-Rate im Online-Shop deutlich verbessern:

Das Format Business Talk am Kudamm in Berlin führte ein Interview mit Benjamin Aunkofer zum Thema “Business Intelligence und Process Mining nachhaltig umsetzen”.
In dem Interview erklärt Benjamin Aunkofer, was gute Business Intelligence und Process Mining ausmacht und warum Unternehmen in jedem Fall daran arbeiten sollten, den gefürchteten Vendor Lock-In zu vermeiden, der gerade insbesondere bei Process Mining droht, jedoch leicht vermeidbar ist.
Nachfolgend das Interview auf Youtube sowie die schriftliche Form zum Nachlesen:
Interview – Process Mining, Business Intelligence und Vendor Lock
1 – Herr Aunkofer, wir wollen uns heute über Best Practice bei der Verarbeitung von Daten unterhalten. Welche Fehler sollten Unternehmen unbedingt vermeiden, wenn sie ihre Daten zur Modellierung aufbereiten?
Mittlerweile weiß ja bereits jeder Laie, dass die Datenaufbereitung und -Modellierung einen Großteil des Arbeitsaufwandes in der Datenanalyse einnehmen, sei es nun für Business Intelligence, also Reporting, oder für Process Mining. Für Data Science ja sowieso. Vor einen Jahrzehnt war es immer noch recht üblich, sich einfach ein BI Tool zu nehmen, sowas wie QlikView, Tableau oder PowerBI, mittlerweile gibt es ja noch einige mehr, und da direkt die Daten reinzuladen und dann halt loszulegen mit dem Aufbau der Reports.
Schon damals in Ansätzen, aber spätestens heute gilt es zu recht als Best Practise, die Datenanbindung an ein Data Warehouse zu machen und in diesem die Daten für die Reports aufzubereiten. Ein Data Warehouse ist eine oder eine Menge von Datenbanken.
Das hat den großen Vorteil, dass die Daten auf einer Ebene modelliert werden, für die es viele Experten gibt und die technologisch auch sehr mächtig ist, nicht auf ein Reporting Tool beschränkt ist.
Außerdem veraltet die Datenbanktechnologie nur sehr viel langsamer als die ganzen Tools, in denen Analysen stattfinden.
Im Process Mining sind ja nun noch viele Erstinitiativen aktiv und da kommen die Unternehmen nun erst so langsam auf den Trichter, dass so ein Data Warehouse hier ebenfalls sinnvoll ist. Und sie liegen damit natürlich vollkommen richtig.
2 – Warum ist es so wichtig einen Vendor Lock zu umgehen?
Na die ganze zuvor genannte Arbeit für die Datenaufbereitung möchte man keinesfalls in so einem Tool haben, das vor allem für die visuelle Analyse gemacht wird und viel schnelleren Entwicklungszyklen sowie einem spannenden Wettbewerb unterliegt. Sind die ganzen Anbindungen der Datenquellen, also z. B. dem ERP, CRM usw., sowie die Datenmodelle für BI oder Process Mining direkt an das Tool gebunden, dann fällt es schwer z. B. von PowerBI nach Tableau oder SuperSet zu wechseln, von Celonis nach Signavio oder welches Tool auch immer. Die Migrationsaufwände sind dann ein ziemlicher Showstopper.
Bei Datenbanken sind Migrationen auch nicht immer ein Spaß, die Aufwände jedoch absehbarer und vor allem besteht selten die Notwendigkeit dazu, die Datenbanktechnologie zu wechseln. Das ist quasi die neutrale Zone.
3 – Bei der Nutzung von Daten fallen oft die Begriffe „Process Mining“ und „Business Intelligence“. Was ist darunter zu verstehen und was sind die Unterschiede zwischen PM und BI?
Business Intelligence, oder BI, geht letztendlich um die zur Verfügungstellung von guten Reports für das Management bis hin zu jeden Mitarbeiter des Unternehmens, manchmal aber sogar bis zum Kunden oder Lieferanten, die in Unternehmensprozesse inkludiert werden sollen. BI ist gewissermaßen schon seit zwei Jahrzehnten ein Trend, entwickelt sich aber auch immer weiter, mit immer größeren Datenmengen, in Echtzeit usw.
Process Mining ist im Grunde eng mit der BI verwandt, man kann auch sagen, dass es ein BI für Prozessanalysen ist. Bei Process Mining nehmen wir uns die Log-Daten von operativen IT-Systemen vor, in denen Unternehmensprozesse erfasst sind. Vornehmlich ERP-Systeme, CRM-Systeme, Dokumentenmangement-Systeme usw.
Die Daten bereiten wir in sogenannte Event Logs, also Prozessprotokolle, auf und laden sie dann ein eines der vielen Process Mining Tools, egal in welches. In diesen Tools kann man dann Prozess wirklich visuell betrachten, filtern und analysieren, rekonstruiert aus den Daten, spiegeln sie die tatsächlichen operativen Vorgänge wieder.
Auch bei Process Mining tut sich gerade viel, Machine Learning hält Einzug ins Process Mining, Prozesse können immer granularer analysiert werden, auch unstrukturierte Daten können unter Einsatz von AI mit in die Analyse einbezogen werden usw.
Der Markt bereinigt sich übrigens auch dadurch, dass Tool für Tool von größeren Software-Häusern aufgekauft werden. Also der Tool-Markt ist gerade ganz krass im Wandel und das wird die nächsten Jahre auch so bleiben.
4 – Wie ist denn die Best Practice bei der Speicherung, Aufbereitung und Modellierung von Daten?
BI und Process Mining sind eigentlich eher Methoden der Datenanalytik als einfach nur Tools. Es ist ein komplexes System. Ganz klar hierfür ist der Aufbau eines Data Warehouses, dass aus Datensicht quasi so eine Art Middleware ist und Daten zentral allen Tools bereitstellt. Viele Unternehmen haben ja um einiges mehr als nur ein Tool im Haus, die kann man dann auch alle weiterhin nutzen.
Was gerade zum Trend wird, ist der Aufbau eines Data Lakehouses. Ein Lakehouse inkludiert auch clevere Art und Weise auch einen Data Lake.
Den Unterschied kann man sich wie folgt vorstellen: Ein Data Warehouse ist wie das Regel zu Hause mit den Ordnern zum Abheften aller wichtigen Dokumente, geordnet nach … Ordner, Rubrik, Sortierung nach Datum oder alphabetisch. Allerdings macht es auch große Mühe, diese Struktur zu verwalten, alles ordentlich abzuheften und sich überhaupt erstmal eine Logik dafür zu erarbeiten. Ein Data Lake ist dann sowas wie die eine böse Schublade, die man eigentlich gar nicht haben möchte, aber in die man dann alle Briefe, Dokumente usw. reinwirft, bei denen man nicht weiß, ob man diese noch braucht. Die Inhalte des Data Lakes sind bestenfalls etwas vorsortiert, aber eigentlich hofft man ja nicht, da wieder irgendwas drin wiederfinden zu müssen.
5 – Sie haben ja einen guten Marktüberblick: Wie gut sind deutsche Unternehmen in diesen Bereichen aufgestellt?
Grundsätzlich schon mal gar nicht so schlecht, wie oft propagiert wird. In beinahe jedem deutschen Unternehmen existiert mittlerweile ein Data Warehouse sowie Initiativen zur Einführung von BI, Process Mining und Data Science bzw. KI, in Konzernen natürlich stets mehrere. Was ich oft vermisse, ist so eine gesamtheitliche Sicht auf die Dinge, es gibt ja viele Nischenexperten, die sich auf eines dieser Themen stürzen, es aber nicht in Verbindung zu den anderen Themen betrachten. Z. B. steht auch KI nicht für sich alleine, sondern kann sowohl der Business Intelligence als auch Process Mining über den Querverweis befähigen, z. B. zur Berücksichtigung von unstrukturierten Daten, oder ausbauen mit Vorhersagen, z. B. Umsatz-Forecasts. Das ist alles eine Datenevolution, vom ersten Report von Unternehmenskennzahlen über die Analyse von Prozessen bis hin zu KI-getriebenen Vorhersagesystemen.
6 – Wo sehen Sie den größten Nachholbedarf?
Da mache ich es kurz: Unternehmen brauchen Datenstrategien und ein Big Picture, wie sie Daten richtig nutzen, dabei dann auch die unterschiedlichen Methoden der Nutzung dieser Daten richtig kombinieren.
Sehen Sie die zwei anderen Video-Interviews von Benjamin Aunkofer:

Interview Benjamin Aunkofer – Datenstrategien und Data Teams entwickeln!
 Jurek Dörner @ DATANOMIQ
Jurek Dörner @ DATANOMIQ
