Microsoft Azure has taken a large chunk of the cloud marketplace, transforming companies with the speed and security of the cloud. Microsoft has over the years used Azure to cushion companies against risk, deal with fraud and differentiate their customer experience.
With Microsoft Cloud App Security, customers experience 75% automatic threat elimination because of increased visibility and automated threat protection. With all these and more amazing benefits of using Azure, its market share is bound to increase even more over the coming years.
Image Source
Financial companies have not been left behind by the Azure bandwagon. The financial industry is using Microsoft Azure to enhance its core functions— invest money by making informed decisions, and minimize risk while maximizing returns.
Azure facilitates these core functions by helping with the storage of huge amounts of data— some dating back to decades ago—, data retrieval and data security.
It also helps financial companies to keep up with regulatory compliance.
Microsoft Azure is not the only cloud services provider. But here’s why it is the most outstanding when it comes to helping financial companies achieve their business goals.
Azure Offers Hybrid and Multi-Cloud Computing for Financial Companies
The financial services industry is extremely dynamic. Organizations offering financial services have to constantly test the market and come up with new and innovative products and services.
They are also often under pressure to extend their services across borders. Remember they have to do all of this while at the same time managing their existing customers, containing their risk, and dealing with fraud.
Financial regulations also keep changing. As financial companies increasingly embrace new technology for their services— including intelligent cloud computing— and they have to comply with industry regulations. They cannot afford to leave loopholes as they take on their journey with the cloud.
The financial services industry is highly competitive and keeps up with modernity. These companies have had to resort to the dynamic hybrid, multi-cloud computing, and public cloud strategies to keep up with the trend.
This is how a hybrid cloud model works— it enables existing on-premises applications to be extended through a connection to the public cloud.
This allows financial companies to enjoy the speed, elasticity, and scale of the public cloud without necessarily having to remodel their entire applications. These organizations are afforded the flexibility of deciding what parts of their application remains in an existing data center and which one resides in the cloud.
Cloud computing with Azure allows financial organizations to operate more efficiently by providing end-to-end protection to information, allowing the digitization of financial services, and providing data security.
Data security is particularly important to financial firms because they are often targeted by fraudsters and cyber threats. They, therefore, need to protect crucial information which they achieve by authenticating their data centers using Azure.
Here’s why financial companies cannot think of doing without Azure’s hybrid cloud computing even for just a day.

Photo by Windows on Unsplash
- The ability to expand their geographic reach
Azure enables financial companies to establish data centers in new locations to meet globally growing demand. This allows them to open and explore new markets. They can then use Azure DevOps pipelines to maintain their data factories and keep everything consistent.
- Consistent Infrastructure management
The hybrid cloud model promotes a consistent approach to infrastructure management across all locations, whether it is on-premises, public cloud, or the edge.
Financial firms and banks utilizing Azure services can respond with great agility to transactional changes or changes in demand by provisioning or de-provisioning as the situation at hand demands.
In cases where the organization requires high computation such as complex risk modeling, a hybrid strategy allows it to expand its capacity beyond its data center without overwhelming its servers.
A hybrid strategy allows financial organizations to choose cloud services that fall within their budget, match their needs, and suit their features.
- Data security and enhanced regulatory compliance
Hybrid and multi-cloud strategies are a superb alternative for strictly on-premises strategies when one considers resiliency, data portability, and data security.
Managing on-premises infrastructure is expensive. Financial companies utilizing Azure do not need to spend large amounts of money setting them up and managing them.
With the increased elasticity of the hybrid system, financial organizations only pay for the resources they actually use, at a relatively lower cost.
Financial Organizations Have Access to an Analytics Platform
As we mentioned earlier, financial companies have the core function of making financial decisions in order to invest money and gain maximum returns at the least possible risk.
Having been entrusted with their customers’ assets, the best way to ensure success in making profits is by using an analytics system.
Getting the form of analytics that helps with solving this investment problem is the kind of headache that does not go away by taking a tablet of ibuprofen and a glass of water— integrating data is not an easy task. Besides, building a custom analytics solution from scratch is quite expensive.
Luckily for financial companies, Azure has a dedicated analytics platform for the financial services industry. It is custom-made just for these types of organizations.
Their system is quite intuitive and easy to use. Companies not only get to save the resources they would have otherwise used to build a custom solution, but they get to learn about their investment risks and get instant results at cloud speed.
They can mitigate against negatively impactful market occurrences and gain profits even when operating in adverse market conditions.

Image by Headway on Unsplash
Financial Companies Get Advanced Data Management
Good analytics goes hand-in-hand with a great data management system. Financial companies need to have good data, create an organized data warehouse, and have a secure data storage system.
In addition to storing your data, Microsoft Azure ensures your storage can be optimized to support advanced applications, for example, machine learning and forecasting.
Azure even allows you to compress and store documents for long periods of time when you write the data to Microsoft Azure Blob Storage. These documents can be retrieved anytime when the need arises for auditors’, regulators’, and lawyers’ perusal.
Conclusion
Microsoft has over time managed to gain the trust of many industries, the financial services industry inclusive. Using its cloud computing giant, Azure, it has empowered these companies to carry out their functions efficiently and at the lowest cost and risk possible.
Azure’s hybrid cloud computing strategy has made financial operations flexible, opened doors for financial companies to establish their services in multiple locations, and provided them with consistent infrastructure management, among many other benefits.
With their futuristic model and commitment to growth, it’s only prudent to assume that Microsoft Azure will continue carrying the mantle as the best cloud services provider in the financial services industry.


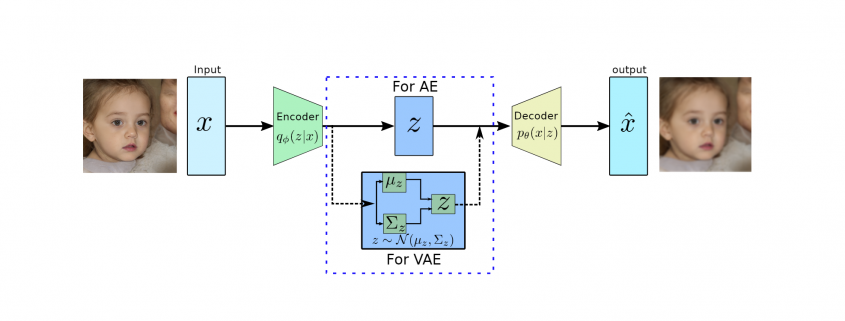

 produces meaningful information of
produces meaningful information of  .
.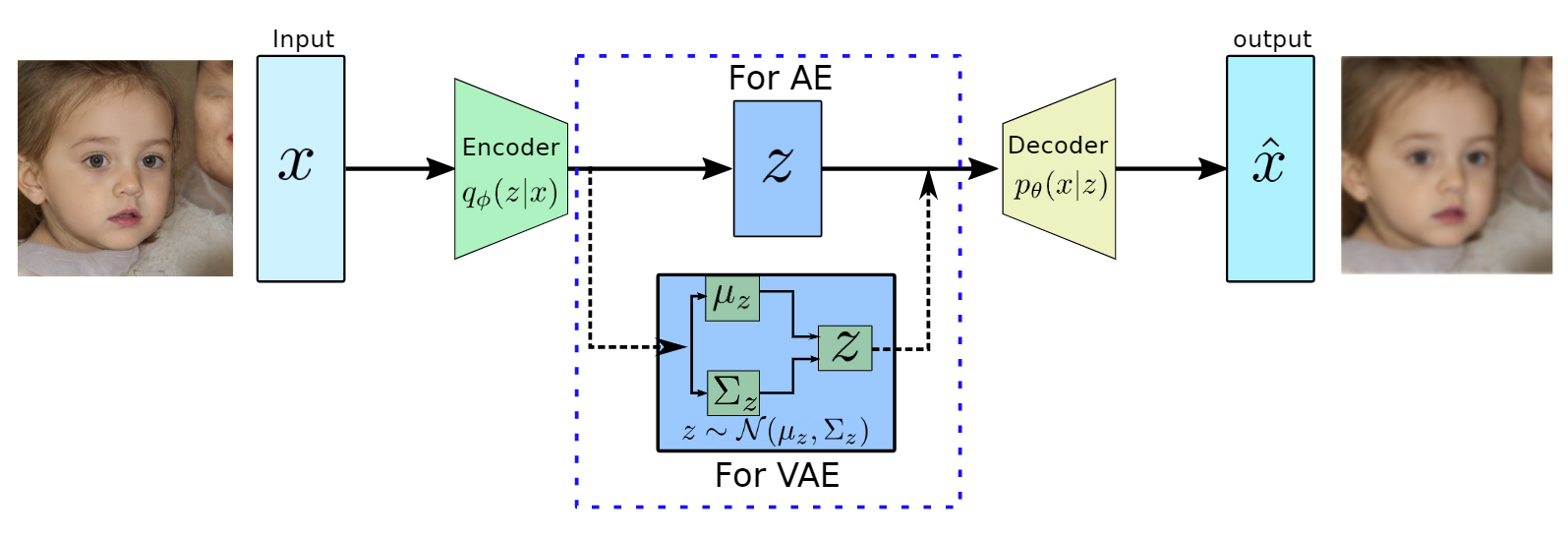
 usually has a much lower dimension than input
usually has a much lower dimension than input  and has the most dominant features of
and has the most dominant features of 
 to approximate the conditional
to approximate the conditional  to generate images based on a sample from a true prior,
to generate images based on a sample from a true prior,  are generally of Gaussian distribution.
are generally of Gaussian distribution. as it will be performing probabilistic generation of data. Therefore the encoder and decoder should be probabilistic.
as it will be performing probabilistic generation of data. Therefore the encoder and decoder should be probabilistic. prior distribution, which is a Gaussian function, therefore, both of them are tractable. However, the integration won’t be tractable because of the high dimensionality of data.
prior distribution, which is a Gaussian function, therefore, both of them are tractable. However, the integration won’t be tractable because of the high dimensionality of data. to approximate the conditional
to approximate the conditional  . Furthermore, the conditional
. Furthermore, the conditional  , which is intractable. This additional encoder part will help to derive a lower bound on the data likelihood that will make the likelihood function tractable. In the following we will derive the lower bound of the likelihood function:
, which is intractable. This additional encoder part will help to derive a lower bound on the data likelihood that will make the likelihood function tractable. In the following we will derive the lower bound of the likelihood function:![\begin{equation*} \begin{flalign} \begin{aligned} log \: p_\theta (x) = & \mathbf{E}_{z\sim q_\phi(z|x)} \Bigg[log \: \frac{p_\theta (x|z) p_\theta (z)}{p_\theta (z|x)} \: \frac{q_\phi(z|x)}{q_\phi(z|x)}\Bigg] \\ = & \mathbf{E}_{z\sim q_\phi(z|x)} \Bigg[log \: p_\theta (x|z)\Bigg] - \mathbf{E}_{z\sim q_\phi(z|x)} \Bigg[log \: \frac{q_\phi (z|x)} {p_\theta (z)}\Bigg] + \mathbf{E}_{z\sim q_\phi(z|x)} \Bigg[log \: \frac{q_\phi (z|x)}{p_\theta (z|x)}\Bigg] \\ = & \mathbf{E}_{z\sim q_\phi(z|x)} \Big[log \: p_\theta (x|z)\Big] - \mathbf{D}_{KL}(q_\phi (z|x), p_\theta (z)) + \mathbf{D}_{KL}(q_\phi (z|x), p_\theta (z|x)). \end{aligned} \end{flalign} \end{equation*}](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-94567d6202e7ed5971ce2e83cbc2d369_l3.png "Rendered by QuickLaTeX.com")
 and then it is expanded using Bayes theorem with additional constant
and then it is expanded using Bayes theorem with additional constant  multiplication. In the next line, it is expanded using the logarithmic rule and then rearranged. Furthermore, the last two terms in the second line are the definition of KL divergence and the third line is expressed in the same.
multiplication. In the next line, it is expanded using the logarithmic rule and then rearranged. Furthermore, the last two terms in the second line are the definition of KL divergence and the third line is expressed in the same.
![\begin{equation*} log \: p_\theta (x)\geq \mathcal{L}(x, \phi, \theta) , \: \text{where} \: \mathcal{L}(x, \phi, \theta) = \mathbf{E}_{z\sim q_\phi(z|x)} \Big[log \: p_\theta (x|z)\Big] - \mathbf{D}_{KL}(q_\phi (z|x), p_\theta (z)). \end{equation*}](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-959a973388a0ab24ad2464bb87d185e7_l3.png "Rendered by QuickLaTeX.com")
 is presenting the tractable lower bound for the optimization and is also termed as ELBO (Evidence Lower Bound Optimization). During the training process, we maximize ELBO using the following equation:
is presenting the tractable lower bound for the optimization and is also termed as ELBO (Evidence Lower Bound Optimization). During the training process, we maximize ELBO using the following equation: