import numpy as np
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d.proj3d import proj_transform
from mpl_toolkits.mplot3d.axes3d import Axes3D
from matplotlib.text import Annotation
from matplotlib.patches import FancyArrowPatch
import matplotlib.patches as mpatches
class Annotation3D(Annotation):
def __init__(self, text, xyz, *args, **kwargs):
super().__init__(text, xy=(0,0), *args, **kwargs)
self._xyz = xyz
def draw(self, renderer):
x2, y2, z2 = proj_transform(*self._xyz, renderer.M)
self.xy=(x2,y2)
super().draw(renderer)
def _annotate3D(ax,text, xyz, *args, **kwargs):
'''Add anotation `text` to an `Axes3d` instance.'''
annotation= Annotation3D(text, xyz, *args, **kwargs)
ax.add_artist(annotation)
setattr(Axes3D,'annotate3D',_annotate3D)
class Arrow3D(FancyArrowPatch):
def __init__(self, x, y, z, dx, dy, dz, *args, **kwargs):
super().__init__((0,0), (0,0), *args, **kwargs)
self._xyz = (x,y,z)
self._dxdydz = (dx,dy,dz)
def draw(self, renderer):
x1,y1,z1 = self._xyz
dx,dy,dz = self._dxdydz
x2,y2,z2 = (x1+dx,y1+dy,z1+dz)
xs, ys, zs = proj_transform((x1,x2),(y1,y2),(z1,z2), renderer.M)
self.set_positions((xs[0],ys[0]),(xs[1],ys[1]))
super().draw(renderer)
def _arrow3D(ax, x, y, z, dx, dy, dz, *args, **kwargs):
'''Add an 3d arrow to an `Axes3D` instance.'''
arrow = Arrow3D(x, y, z, dx, dy, dz, *args, **kwargs)
ax.add_artist(arrow)
setattr(Axes3D,'arrow3D',_arrow3D)
jp_score = np.array([49, 58, 64, 65, 54, 58, 49, 67, 54, 66, 72, 66, 54, 64, 39,
56, 54, 56, 48, 57, 57, 47, 50, 60, 72, 54, 59, 61, 64, 70])
math_score = np.array([51, 58, 56, 70, 45, 70, 45, 69, 66, 73, 71, 72, 57, 53, 58,
57, 71, 63, 53, 62, 62, 59, 57, 65, 74, 66, 72, 50, 69, 60])
en_score = np.array([59, 63, 68, 77, 55, 71, 57, 79, 66, 81, 81, 77, 62, 67, 56,
62, 70, 67, 61, 70, 68, 59, 61, 71, 77, 66, 70, 59, 68, 71])
mean_vector = np.array([jp_score.mean(), math_score.mean(), en_score.mean()])
data_matrix = np.c_[jp_score, math_score, en_score]
data_mean_reduced = data_matrix - mean_vector
covariance_matrix = np.dot(data_mean_reduced.T, data_mean_reduced) / len(jp_score)
eigen_values, eigen_vectors = np.linalg.eig(covariance_matrix)
sorted_index = eigen_values.argsort()[::-1]
eigen_values=eigen_values[sorted_index]
eigen_vectors=eigen_vectors[:, sorted_index]
eigen_values, eigen_vectors = np.linalg.eig(covariance_matrix)
sorted_idx = eigen_values.argsort()[::-1]
eigen_values = eigen_values[sorted_idx]
eigen_vectors = eigen_vectors[:,sorted_idx]
eigen_vectors = eigen_vectors.astype(float)
subject_labels = ['Japanese score deviation', 'Math score deviation', 'English score deviation']
const_range = 2
X = np.arange(-const_range, const_range + 1, 1)
Y = np.arange(-const_range, const_range + 1, 1)
Z = np.arange(-const_range, const_range + 1, 1)
U_x, U_y, U_z = np.meshgrid(X, Y, Z)
V_x = np.zeros((len(U_x), len(U_y), len(U_z)))
V_y = np.zeros((len(U_x), len(U_y), len(U_z)))
V_z = np.zeros((len(U_x), len(U_y), len(U_z)))
temp_vec = np.zeros((1, 3))
W_x = np.zeros((len(U_x), len(U_y), len(U_z)))
W_y = np.zeros((len(U_x), len(U_y), len(U_z)))
W_z = np.zeros((len(U_x), len(U_y), len(U_z)))
fig = plt.figure(figsize=(15, 15))
grid_range = 15
for idx in range(2):
if idx ==0:
ax = fig.add_subplot(1, 2, idx + 1, projection='3d')
for i in range(len(U_x)):
for j in range(len(U_x)):
for k in range(len(U_x)):
temp_vec[0][0] = U_x[i][j][k]
temp_vec[0][1] = U_y[i][j][k]
temp_vec[0][2] = U_z[i][j][k]
temp_vec[0] = np.dot(covariance_matrix, temp_vec[0])
V_x[i][j][k] = temp_vec[0][0]
V_y[i][j][k] = temp_vec[0][1]
V_z[i][j][k] = temp_vec[0][2]
W_x[i][j][k] = (V_x[i][j][k] - U_x[i][j][k]) / (2*grid_range)
W_y[i][j][k] = (V_y[i][j][k] - U_y[i][j][k]) / (2*grid_range)
W_z[i][j][k] = (V_z[i][j][k] - U_z[i][j][k]) / (2*grid_range)
ax.arrow3D(0, 0, 0,
U_x[i][j][k], U_y[i][j][k], U_z[i][j][k],
mutation_scale=10, arrowstyle="-|>", fc='dimgrey', ec='dimgrey')
#ax.arrow3D(0, 0, 0,
# V_x[i][j][k], V_y[i][j][k], V_z[i][j][k],
# mutation_scale=10, arrowstyle="-|>", fc='red', ec='red')
ax.arrow3D(U_x[i][j][k], U_y[i][j][k], U_z[i][j][k],
W_x[i][j][k], W_y[i][j][k], W_z[i][j][k],
mutation_scale=10, arrowstyle="-|>", fc='darkviolet', ec='darkviolet')
if idx==1:
ax = fig.add_subplot(1, 2, idx + 1, projection='3d')
ax.scatter(data_mean_reduced[:, 0], data_mean_reduced[:, 1], data_mean_reduced[:, 2], marker='o', s=80)
ax.arrow3D(0, 0, 0, eigen_vectors.T[0][0]*10, eigen_vectors.T[0][1]*10, eigen_vectors.T[0][2]*10,
mutation_scale=10, arrowstyle="-|>", fc='orange', ec='orange', lw = 3)
ax.arrow3D(0, 0, 0, eigen_vectors.T[1][0]*10, eigen_vectors.T[1][1]*10, eigen_vectors.T[1][2]*10,
mutation_scale=10, arrowstyle="-|>", fc='orange', ec='orange', lw = 3)
ax.arrow3D(0, 0, 0, eigen_vectors.T[2][0]*10, eigen_vectors.T[2][1]*10, eigen_vectors.T[2][2]*10,
mutation_scale=10, arrowstyle="-|>", fc='orange', ec='orange', lw = 3)
ax.text(eigen_vectors.T[0][0]*8 , eigen_vectors.T[0][1]*8, eigen_vectors.T[0][2]*8+1, r'$u_1$', fontsize=20)
ax.text(eigen_vectors.T[1][0]*8 , eigen_vectors.T[1][1]*8, eigen_vectors.T[1][2]*8, r'$u_2$', fontsize=20)
ax.text(eigen_vectors.T[2][0]*8 , eigen_vectors.T[2][1]*8, eigen_vectors.T[2][2]*8, r'$u_3$', fontsize=20)
ax.set_xlim(-grid_range, grid_range)
ax.set_ylim(-grid_range, grid_range)
ax.set_zlim(-grid_range, grid_range)
#ax.set_xlabel(r'$x_1$', fontsize=25)
#ax.set_ylabel(r'$x_2$', fontsize=25)
#ax.set_zlabel(r'$x_3$', fontsize=25)
ax.set_xlabel(subject_labels[0], fontsize=10)
ax.set_ylabel(subject_labels[1], fontsize=10)
ax.set_zlabel(subject_labels[2], fontsize=10)
#lt.savefig("visualizing_covariance_matrix.png")
plt.show()
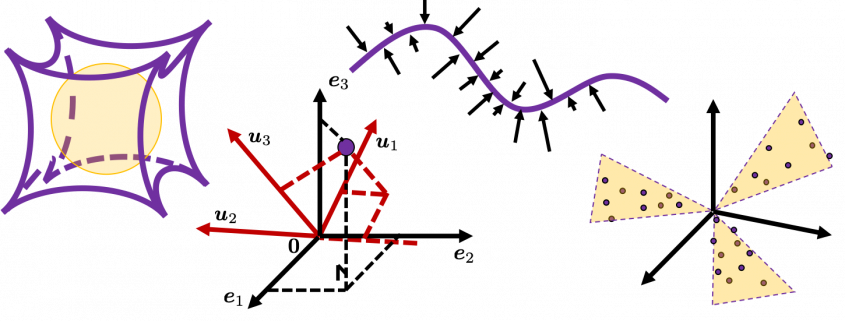
 is a certain type of
is a certain type of  matrix, the formula of a D-dimensional ellipsoid whose center is identical to the origin point is as follows:
matrix, the formula of a D-dimensional ellipsoid whose center is identical to the origin point is as follows:  , where
, where  . As is always the case with formulas in data science, you can visualize such ellipsoids if you are talking about 1, 2, or 3 dimensional data like in the figure below, but in general D-dimensional space, it is theoretical/imaginary stuff on blackboards.
. As is always the case with formulas in data science, you can visualize such ellipsoids if you are talking about 1, 2, or 3 dimensional data like in the figure below, but in general D-dimensional space, it is theoretical/imaginary stuff on blackboards.
 , where
, where  or
or  , where
, where  . These are special cases of the equation
. These are special cases of the equation  . In this case the axes of ellipsoids the same as those of the coordinate system. Thus in this simple case,
. In this case the axes of ellipsoids the same as those of the coordinate system. Thus in this simple case,  or
or  .
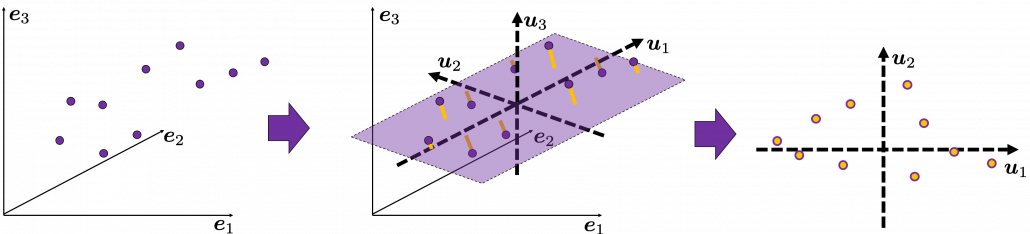
. as below (The samples are plotted in purple). Intuitively, the data “swell” the most along the vector
as below (The samples are plotted in purple). Intuitively, the data “swell” the most along the vector  . Also it is clear that
. Also it is clear that  is the only vector orthogonal to
is the only vector orthogonal to  expresses the data in a better way, and you you can get new coordinate points of the samples by projecting them on new axes as done with yellow lines below.
expresses the data in a better way, and you you can get new coordinate points of the samples by projecting them on new axes as done with yellow lines below.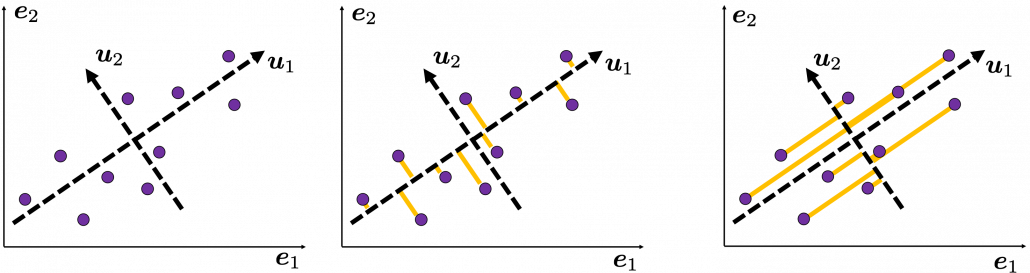
 as below, the data “swell” the most also along
as below, the data “swell” the most also along  .
.

 on the axis
on the axis  .
. is the mean of data in the original coordinate, then the deviation of
is the mean of data in the original coordinate, then the deviation of  on the axis
on the axis  , as shown in the figure. Hence the variance, I mean the mean of the deviation on is
, as shown in the figure. Hence the variance, I mean the mean of the deviation on is  , where
, where  is the total number of data points. After some deformations, you get the next equation
is the total number of data points. After some deformations, you get the next equation  , where
, where  .
.  is known as a covariance matrix.
is known as a covariance matrix. , and for mathematical derivation we need some college level calculus, so if that is too much for you, you can skip reading this part till the next section.
, and for mathematical derivation we need some college level calculus, so if that is too much for you, you can skip reading this part till the next section. including
including  . Introducing a
. Introducing a  . In conclusion
. In conclusion  satisfies
satisfies  . If you have read my last article on eigenvectors, you wold soon realize that this is an equation for calculating eigenvectors, and that means
. If you have read my last article on eigenvectors, you wold soon realize that this is an equation for calculating eigenvectors, and that means  . We have seen that
. We have seen that  is a the variance of data when projected on a vector
is a the variance of data when projected on a vector  is the biggest variance possible when the data are projected on a vector.
is the biggest variance possible when the data are projected on a vector. , and it it the second biggest variance possible, and in this case the date are projected on
, and it it the second biggest variance possible, and in this case the date are projected on 
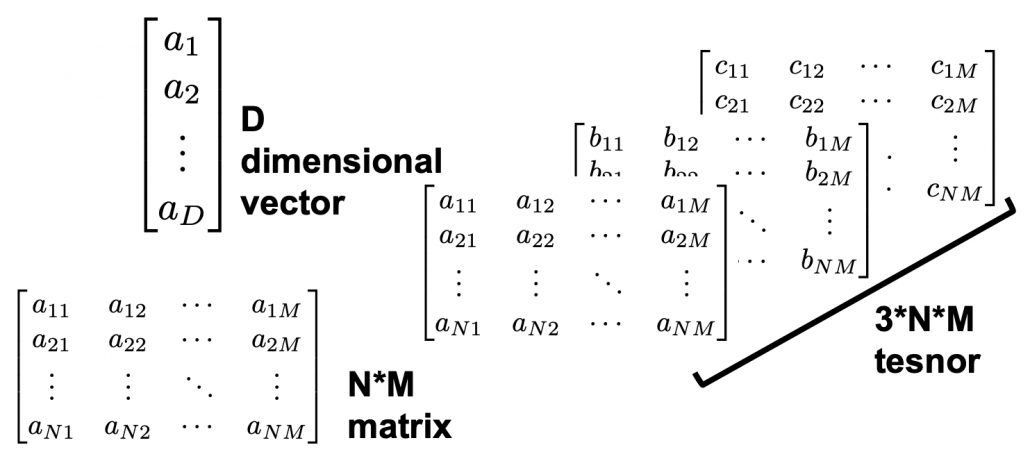
 matrix
matrix  , and in fact the matrix is just a constant multiplication of this covariance matrix. I think now you understand that PCA is calculating the orthogonal eigenvectors of covariance matrix of data, that is diagonalizing covariance matrix with orthonormal eigenvectors. Hence we can guess that covariance matrix enables a type of linear transformation of rotation and expansion and contraction of vectors. And data points swell along eigenvectors of such matrix.
, and in fact the matrix is just a constant multiplication of this covariance matrix. I think now you understand that PCA is calculating the orthogonal eigenvectors of covariance matrix of data, that is diagonalizing covariance matrix with orthonormal eigenvectors. Hence we can guess that covariance matrix enables a type of linear transformation of rotation and expansion and contraction of vectors. And data points swell along eigenvectors of such matrix.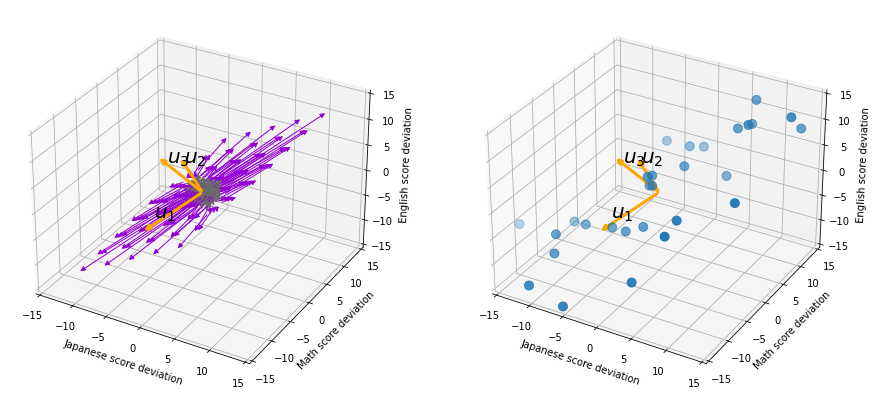
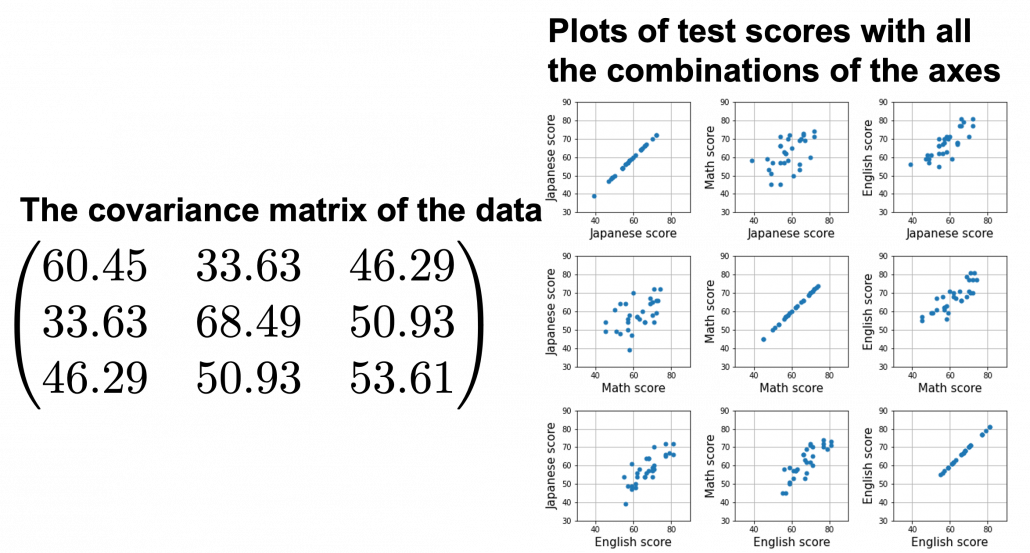
 denote Japanese, Math, English scores respectively. The mean of the data is
denote Japanese, Math, English scores respectively. The mean of the data is  , and the covariance matrix of data in the original coordinate system is
, and the covariance matrix of data in the original coordinate system is  . The eigenvalues of
. The eigenvalues of  are
are  , and
, and  , and their corresponding unit eigenvectors are
, and their corresponding unit eigenvectors are  respectively.
respectively.  is an orthonormal matrix, where
is an orthonormal matrix, where  . As I explained in the last article, you can diagonalize
. As I explained in the last article, you can diagonalize  :
:  .
. .
. means. Each element of
means. Each element of  denotes coordinate of the data point
denotes coordinate of the data point  , and
, and  ).
).  enables a rotation of a rigid body, which means the shape or arrangement of data will not change after the rotation, and
enables a rotation of a rigid body, which means the shape or arrangement of data will not change after the rotation, and  , and
, and  is the coordinate of
is the coordinate of  denotes the coordinate point of the purple point in the red coordinate system.
denotes the coordinate point of the purple point in the red coordinate system.  denotes the coordinates of data projected on new axes
denotes the coordinates of data projected on new axes  , which are unit eigenvectors of
, which are unit eigenvectors of 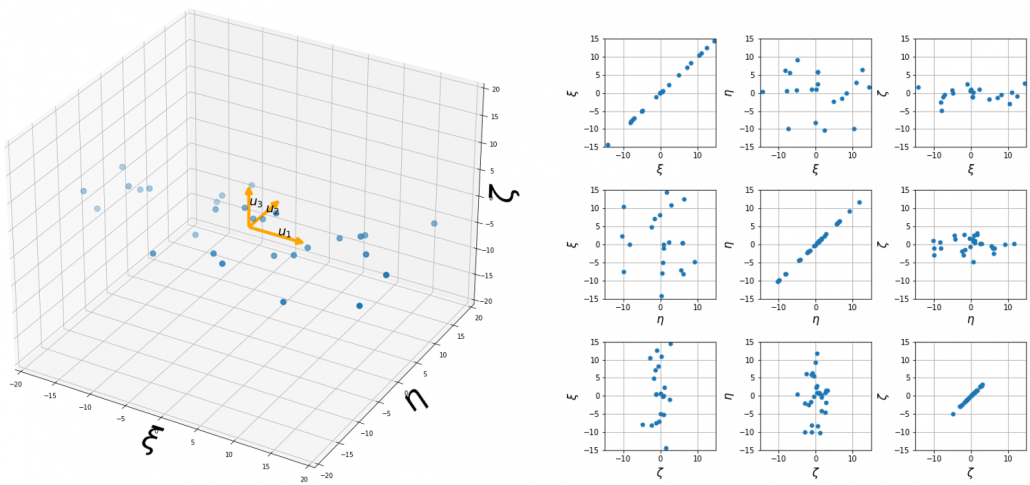
 , which means you can express deviations of the original data as linear combinations of the three factors
, which means you can express deviations of the original data as linear combinations of the three factors  , and
, and  . We expect that those three factors contain keys for understanding the original data more efficiently. If you concretely write down all the equations for the factors:
. We expect that those three factors contain keys for understanding the original data more efficiently. If you concretely write down all the equations for the factors:  ,
,  , and
, and  . If you examine the coefficients of the deviations
. If you examine the coefficients of the deviations  , and
, and  , we can observe that
, we can observe that  almost equally reflects the deviation of the scores of all the subjects, thus we can say
almost equally reflects the deviation of the scores of all the subjects, thus we can say  is
is  . You can see
. You can see  , where
, where  . The variance of data projected on new D-dimensional coordinate system is
. The variance of data projected on new D-dimensional coordinate system is 




 . This means that in the new coordinate system after PCA, covariances between any pair of variants are all zero.
. This means that in the new coordinate system after PCA, covariances between any pair of variants are all zero. .
. from the reduced two dimensional coordinate system
from the reduced two dimensional coordinate system  . Then it mathematically clearer that we can express the data with two factors: “how smart the student is” and “whether he is at scientific side or liberal art side.”
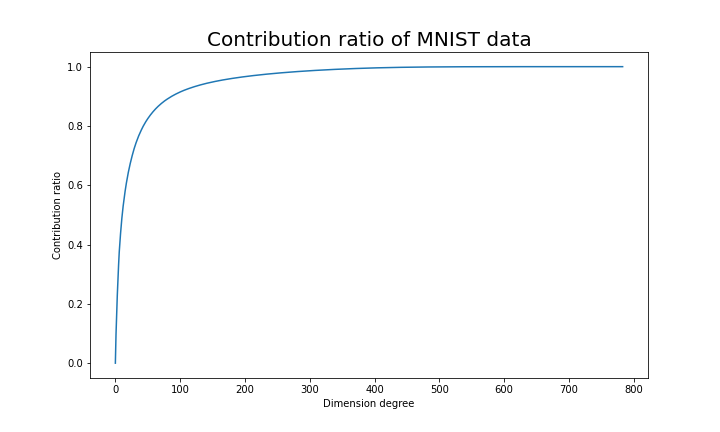
. Then it mathematically clearer that we can express the data with two factors: “how smart the student is” and “whether he is at scientific side or liberal art side.” is a statistic which indicates how much the corresponding
is a statistic which indicates how much the corresponding  is called the contribution ratio of eigenvector
is called the contribution ratio of eigenvector  and
and  are respectively
are respectively  ,
,  ,
,  . You can decide how many degrees of dimensions you reduce based on this information.
. You can decide how many degrees of dimensions you reduce based on this information.



 be a vector space and let
be a vector space and let  be a mapping of
be a mapping of  into itself, defined as
into itself, defined as  , where
, where  is
is  dimensional vector. An element
dimensional vector. An element  is called an eigen vector if there exists a number
is called an eigen vector if there exists a number  such that
such that  and
and  . In this case
. In this case  , belonging to
, belonging to  . If
. If  is basis of the vector space
is basis of the vector space  matrices
matrices  , whose column vectors are eigen vectors
, whose column vectors are eigen vectors  , where
, where  .
. Most textbooks keep explaining these type of stuff, but I have to say they lack efforts to make it understandable to readers with low mathematical literacy like me. Especially if you have to apply the idea to data science field, I believe you need more visual understanding of diagonalization. Therefore instead of just explaining the definitions and theorems, I would like to take a different approach. But in order to understand them in more intuitive ways, we first have to rethink waht linear transformation
Most textbooks keep explaining these type of stuff, but I have to say they lack efforts to make it understandable to readers with low mathematical literacy like me. Especially if you have to apply the idea to data science field, I believe you need more visual understanding of diagonalization. Therefore instead of just explaining the definitions and theorems, I would like to take a different approach. But in order to understand them in more intuitive ways, we first have to rethink waht linear transformation  means in more visible ways.
means in more visible ways. is a vector transformed by
is a vector transformed by  *I am not going to use the term “linear transformation” in a precise way in the context of linear algebra. In this article or in the context of data science or machine learning, “linear transformation” for the most part means products of matrices or vectors.
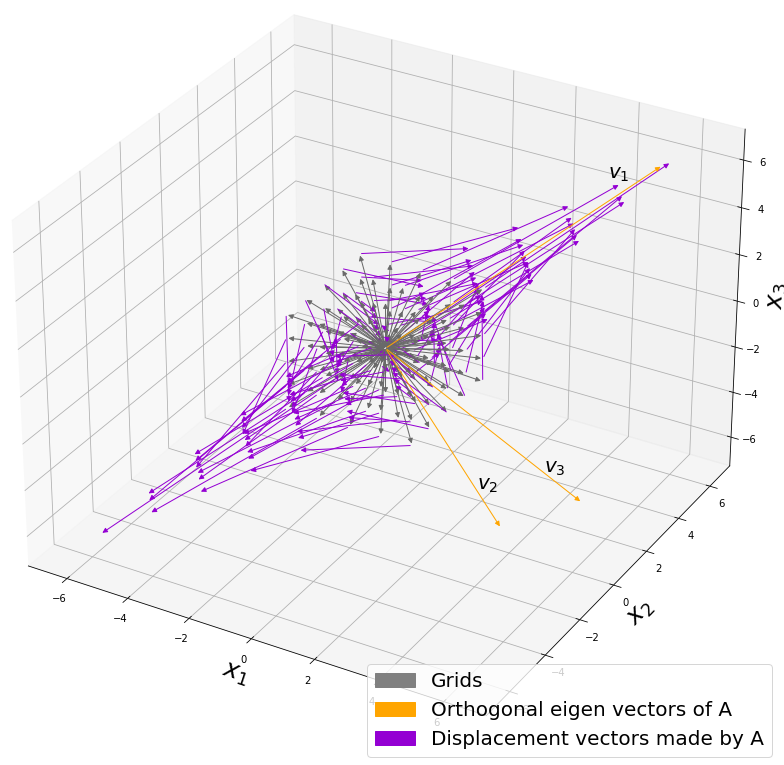
*I am not going to use the term “linear transformation” in a precise way in the context of linear algebra. In this article or in the context of data science or machine learning, “linear transformation” for the most part means products of matrices or vectors. 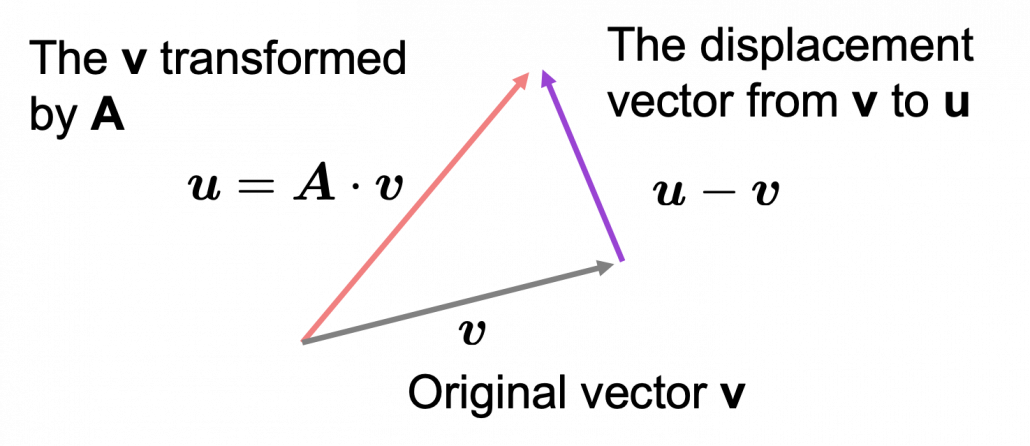 Let’s calculate the displacement vector with more vectors
Let’s calculate the displacement vector with more vectors  , and I prepared several grid vectors
, and I prepared several grid vectors  , which are in purple.
, which are in purple. square matrices
square matrices  , and I plotted displace vectors made by the matrices respectively in the figure below.
, and I plotted displace vectors made by the matrices respectively in the figure below. , the matrix does not have any real eigan values.
, the matrix does not have any real eigan values. is classified to, and I am going to explain positive semidefinite matrices in the fourth section.
is classified to, and I am going to explain positive semidefinite matrices in the fourth section.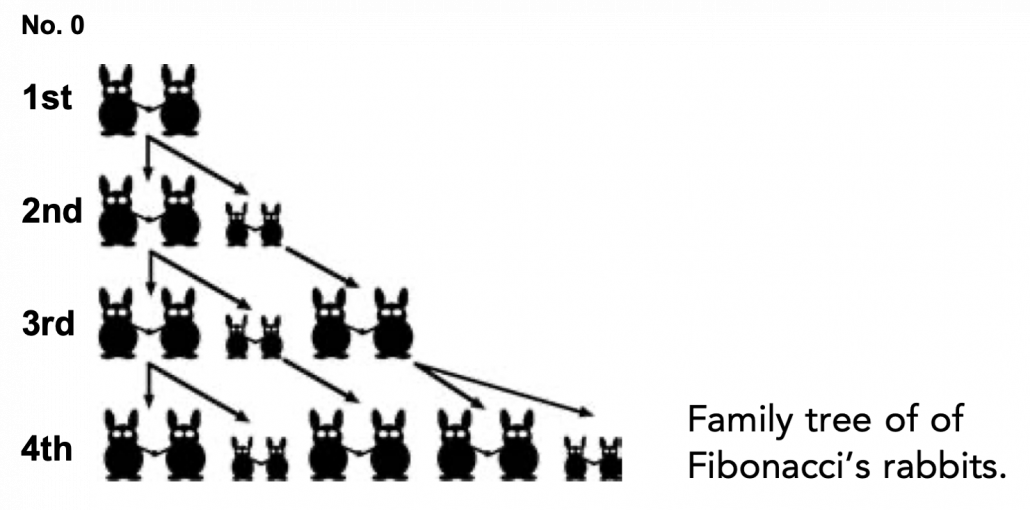
 be the number of pairs of grown up rabbits in the
be the number of pairs of grown up rabbits in the  generation. One pair of grown up rabbits produce one pair of young rabbit The concrete values of
generation. One pair of grown up rabbits produce one pair of young rabbit The concrete values of  are
are  ,
,  ,
,  ,
,  ,
,  ,
,  ,
,  ,
,  . Assume that
. Assume that  and that
and that  , then you can calculate the number of the pairs of grown up rabbits in the next generation with the following recurrence relation.
, then you can calculate the number of the pairs of grown up rabbits in the next generation with the following recurrence relation.  .Let
.Let  be
be  , then the recurrence relation can be written as
, then the recurrence relation can be written as  , and the transition of
, and the transition of 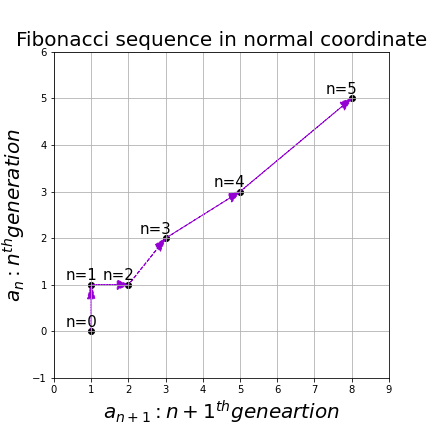
 are eigen values of
are eigen values of  scalars such that
scalars such that  . According to the definition of eigen values and eigen vectors belonging to them, the following two equations hold:
. According to the definition of eigen values and eigen vectors belonging to them, the following two equations hold:  . If you calculate
. If you calculate  is, using eigen vectors of
is, using eigen vectors of  . In the same way,
. In the same way,  , and
, and  . These equations show that in coordinate system made by eigen vectors of
. These equations show that in coordinate system made by eigen vectors of 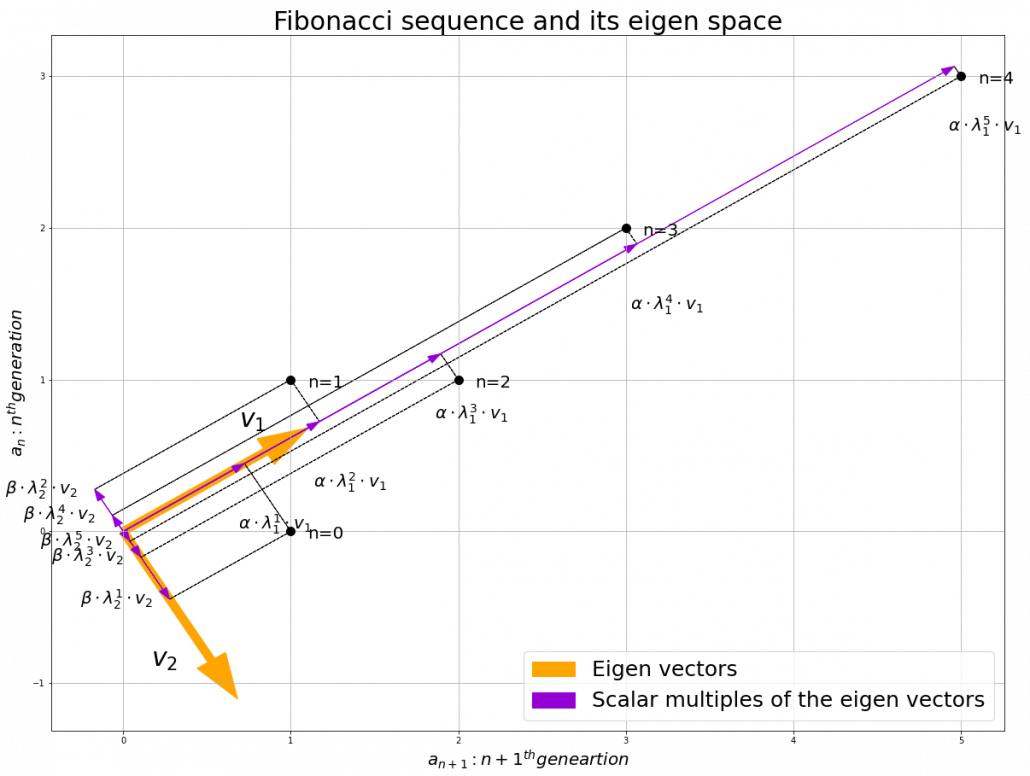
 for all values of the vector
for all values of the vector  for all the eigen values
for all the eigen values  .
. for all values of the vector
for all values of the vector  square positive semidefinite matrix
square positive semidefinite matrix  , whose linear transformation I visualized the second section, is also positive semidefinite.
, whose linear transformation I visualized the second section, is also positive semidefinite. .
.
 , there exist orthonormal matrices
, there exist orthonormal matrices  , where
, where  .
. , where
, where  . In other words column vectors
. In other words column vectors  form an orthonormal coordinate system.
form an orthonormal coordinate system. . Combining this fact with what I have told you so far, you we can reach one conclusion: you can orthogonalize a real symmetric matrix
. Combining this fact with what I have told you so far, you we can reach one conclusion: you can orthogonalize a real symmetric matrix  . This is known as spectral decomposition or singular value decomposition.
. This is known as spectral decomposition or singular value decomposition. is also orthonormal. In other words, assume
is also orthonormal. In other words, assume  ,
,  also forms a orthonormal coordinate system.
also forms a orthonormal coordinate system. expands or contracts vectors along each axis. I am going to explain that more precisely in the upcoming articles.
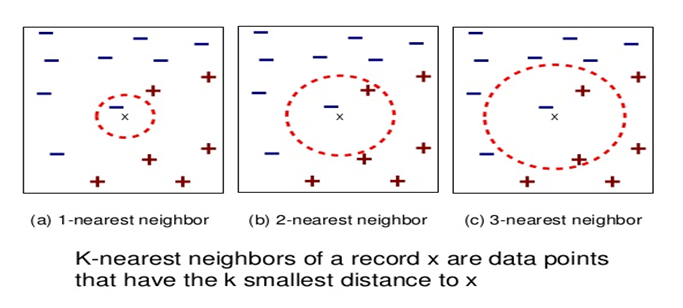
expands or contracts vectors along each axis. I am going to explain that more precisely in the upcoming articles.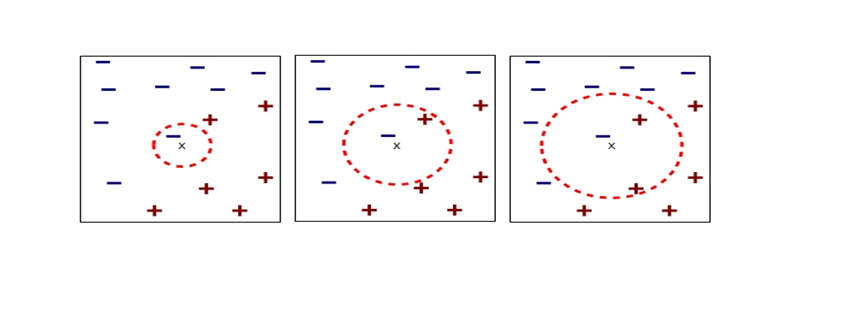
 plotted against parameter
plotted against parameter  out of 12 parameters.
out of 12 parameters.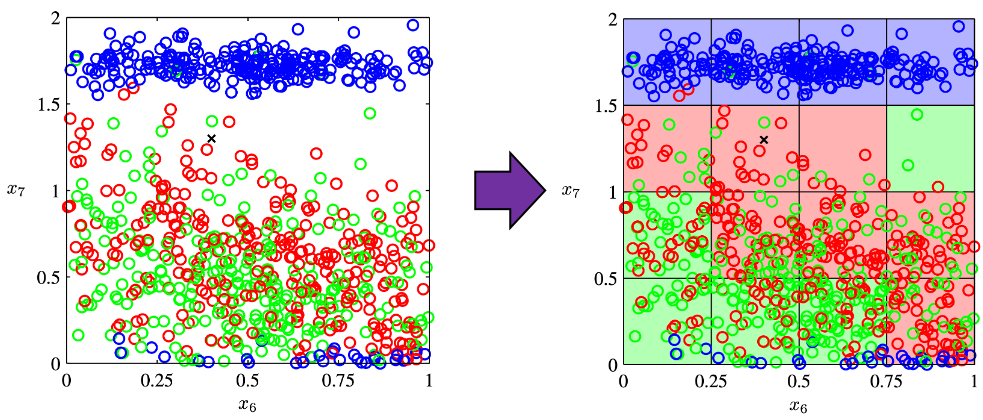
 grids respectively in 1, 2, 3 dimensional spaces, the number of the small regions in the grids are respectively 10, 100, 1000. Even though you cannot visualize it anymore, you can make grids for more than 3 dimensional data. If you continue increasing the degree of dimension, the number of grids increases exponentially, and that can soon surpass the number of training data points. That means there would be a lot of empty spaces in such high dimensional grids. And the classifying method above: coloring each grid and classifying unknown samples depending on the colors of the grids, does not work out anymore because there would be a lot of empty grids.
grids respectively in 1, 2, 3 dimensional spaces, the number of the small regions in the grids are respectively 10, 100, 1000. Even though you cannot visualize it anymore, you can make grids for more than 3 dimensional data. If you continue increasing the degree of dimension, the number of grids increases exponentially, and that can soon surpass the number of training data points. That means there would be a lot of empty spaces in such high dimensional grids. And the classifying method above: coloring each grid and classifying unknown samples depending on the colors of the grids, does not work out anymore because there would be a lot of empty grids.
 , where
, where  is the center point and
is the center point and  is length of radius. When
is length of radius. When 
 , and that in each cube is
, and that in each cube is  .
. 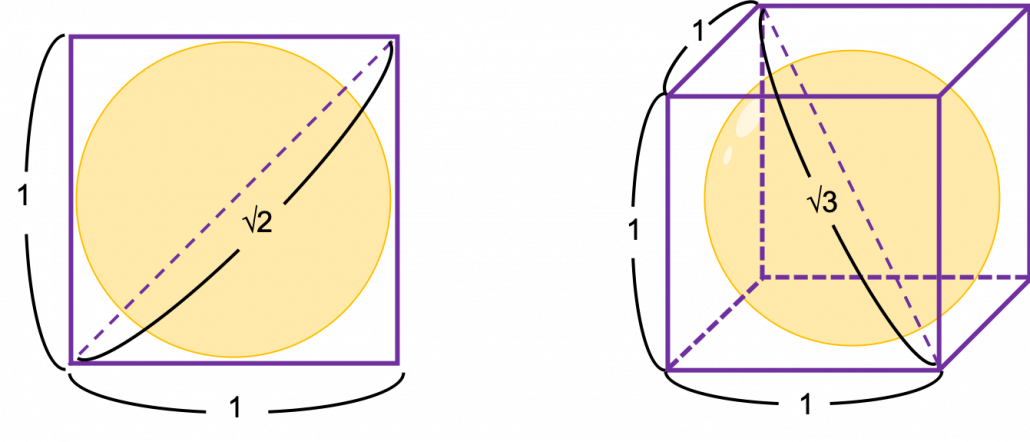
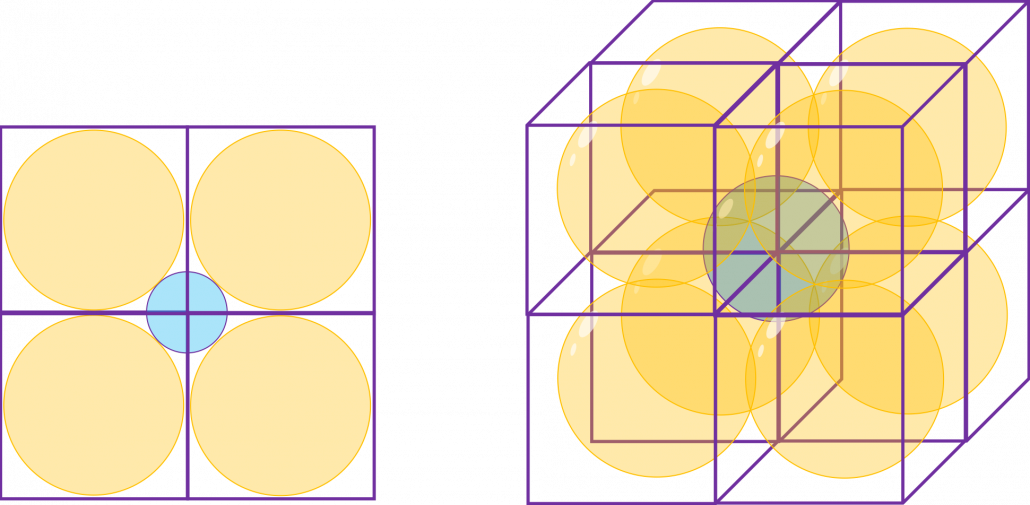
 , and the diameter of the blue sphere is
, and the diameter of the blue sphere is  .
. . If that is true, there is one strange point:
. If that is true, there is one strange point:  can soon surpass 2: that means in the chart above the blue sphere will stick out of the stacked cubes. That sounds like a paradox, but with one hypothesis, the phenomenon makes sense: cubes become more spiky as the degree of dimension grows. This hypothesis is a natural deduction because diagonal lines of hyper cubes get longer, and the the center of each surface of hypercubes still touches the unit D-ball with diameter 1, inscribing inscribing inside each unit hypercube.
can soon surpass 2: that means in the chart above the blue sphere will stick out of the stacked cubes. That sounds like a paradox, but with one hypothesis, the phenomenon makes sense: cubes become more spiky as the degree of dimension grows. This hypothesis is a natural deduction because diagonal lines of hyper cubes get longer, and the the center of each surface of hypercubes still touches the unit D-ball with diameter 1, inscribing inscribing inside each unit hypercube. 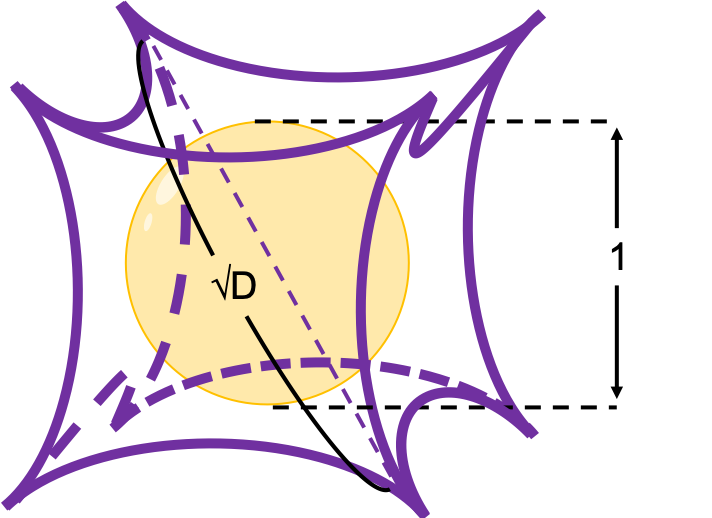

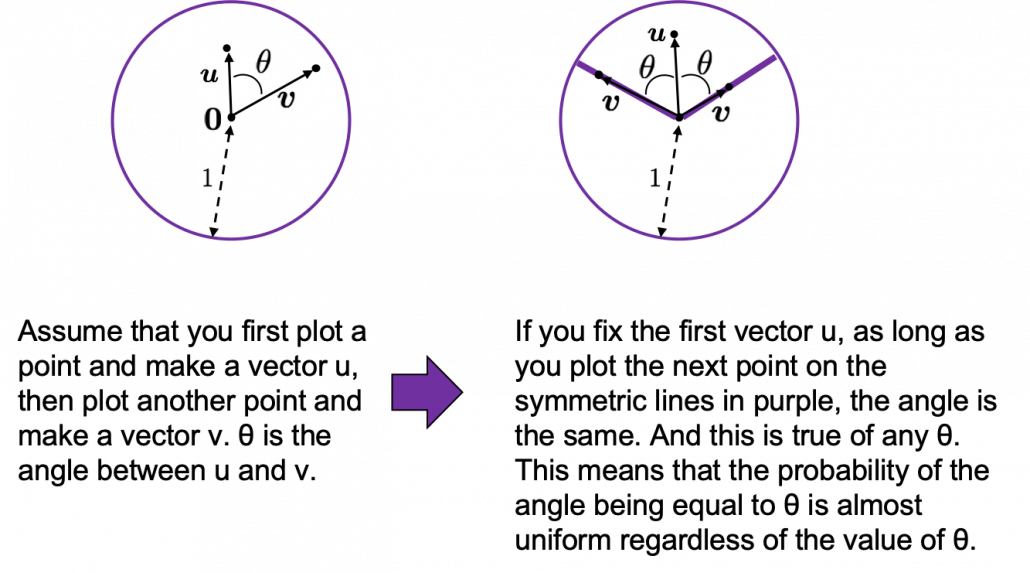
 . Let’s see the general meaning of angle between two vectors in any dimensional spaces. Assume that the angle between two vectors
. Let’s see the general meaning of angle between two vectors in any dimensional spaces. Assume that the angle between two vectors  , then
, then  is calculated as
is calculated as  . In 1, 2, or 3 dimensional space, you can actually see the angle, but again you can define higher dimensional angle, which you cannot visualize anymore. And angles are sometimes used as similarity of two vectors.
. In 1, 2, or 3 dimensional space, you can actually see the angle, but again you can define higher dimensional angle, which you cannot visualize anymore. And angles are sometimes used as similarity of two vectors. is the inner product of
is the inner product of 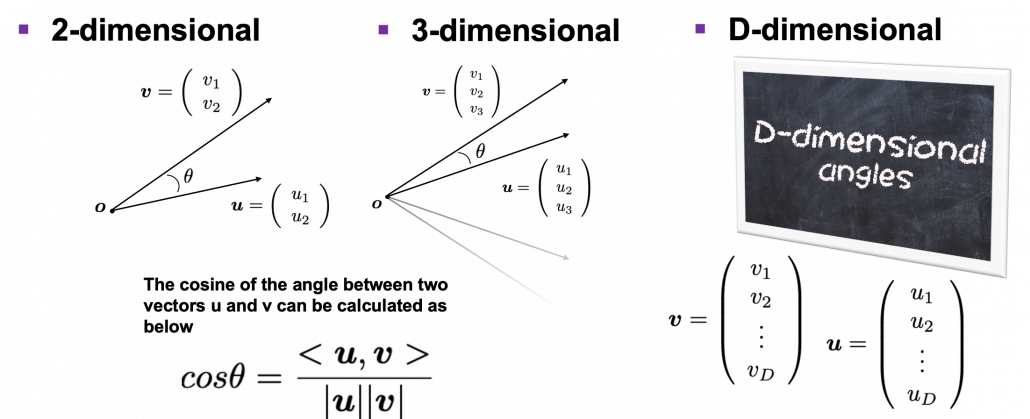
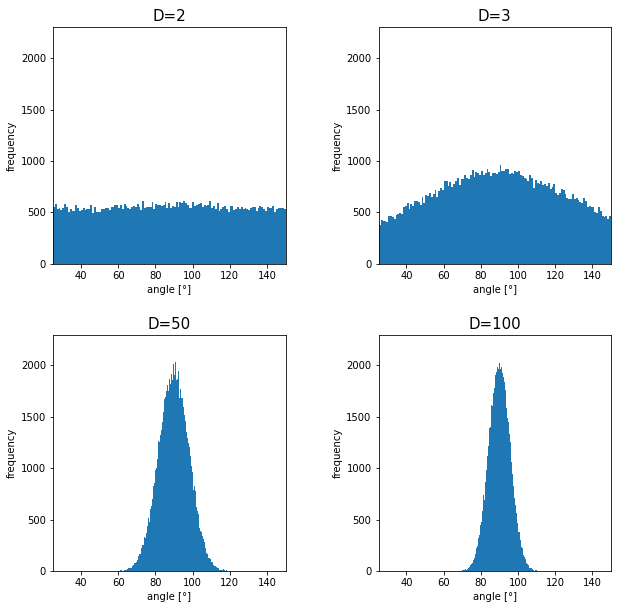
 How about in 3-dimensional space? In fact the distribution of
How about in 3-dimensional space? In fact the distribution of  is the most likely to be generated. As I explain in the figure below, if you compare the area of cross section of a hemisphere and the area of a cone whose vertex is the center point of the sphere, you can see why.
is the most likely to be generated. As I explain in the figure below, if you compare the area of cross section of a hemisphere and the area of a cone whose vertex is the center point of the sphere, you can see why.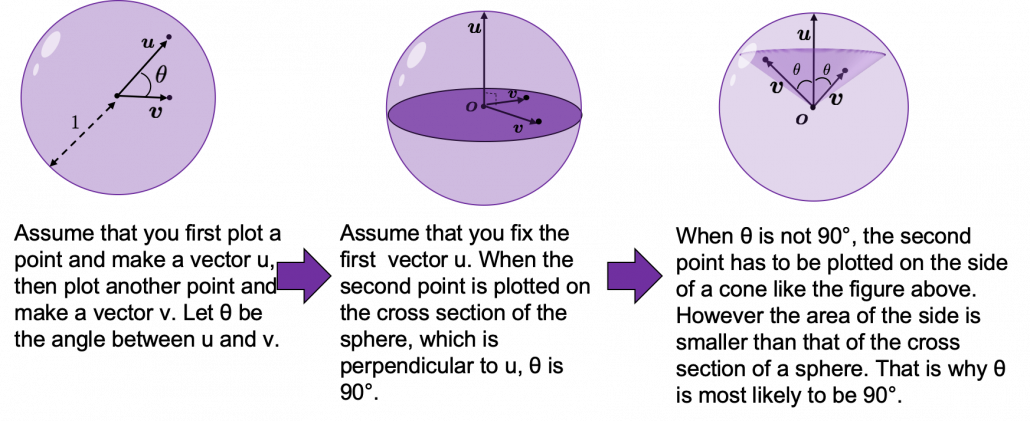

 surface of general spheres with radius
surface of general spheres with radius  First, in 2 two dimensional space, spheres are circles. The area of the brown part of the circle below is
First, in 2 two dimensional space, spheres are circles. The area of the brown part of the circle below is  . In order calculate the are of
. In order calculate the are of  thick surface of the circle, you have only to subtract the area of
thick surface of the circle, you have only to subtract the area of  . When
. When  , the area of outer most surface is
, the area of outer most surface is  , and its proportion to the area of the whole circle is
, and its proportion to the area of the whole circle is  .
.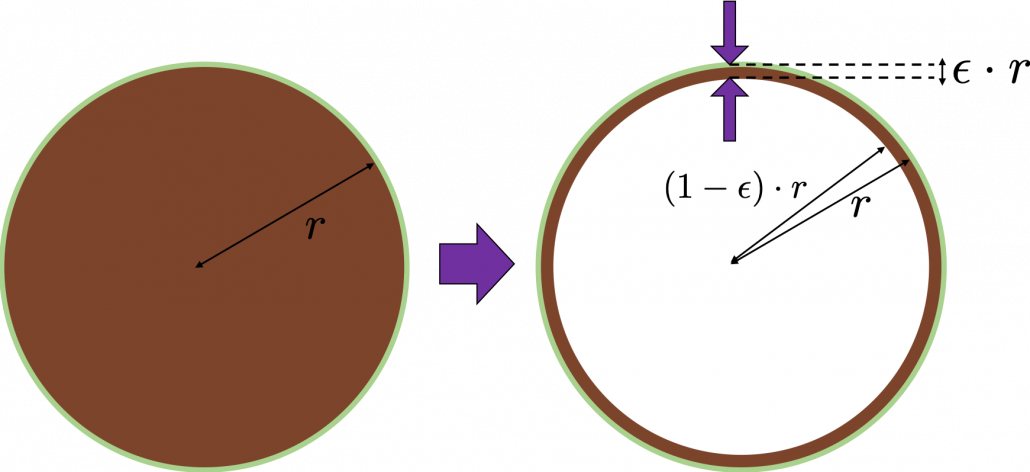
 , so the proportion of the
, so the proportion of the  . Compared to the case in 2 dimensional space, the proportion is a little bigger.
. Compared to the case in 2 dimensional space, the proportion is a little bigger.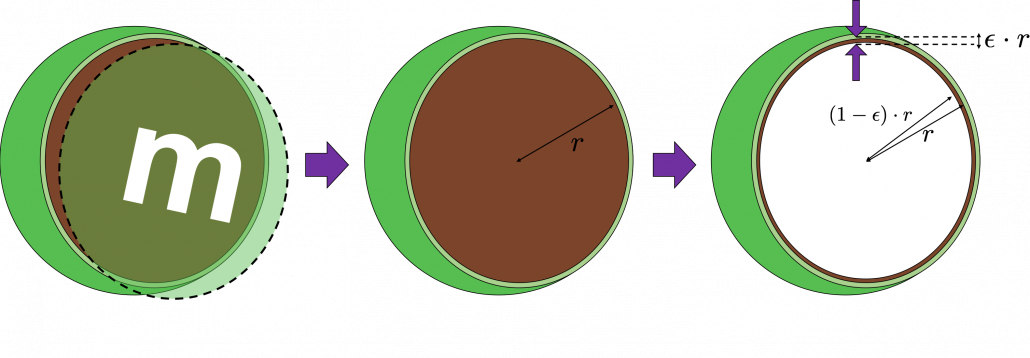
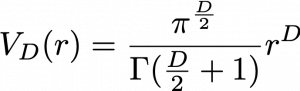
 is called gamma function, but in this article it is not so important. The most important point now is, if you discuss any D-ball, their volume only depends on their radius
is called gamma function, but in this article it is not so important. The most important point now is, if you discuss any D-ball, their volume only depends on their radius  . When
. When  , and when
, and when 
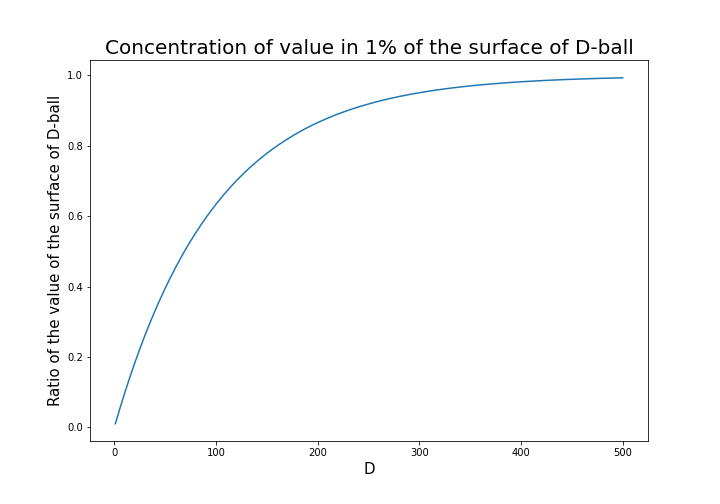
 radius of the center is almost zero. But if you reach the outermost
radius of the center is almost zero. But if you reach the outermost 
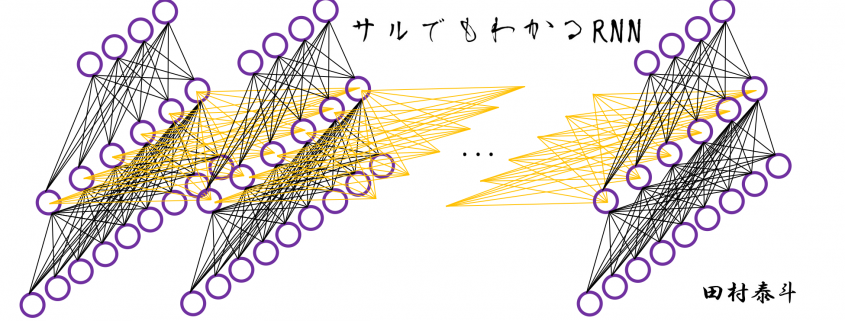

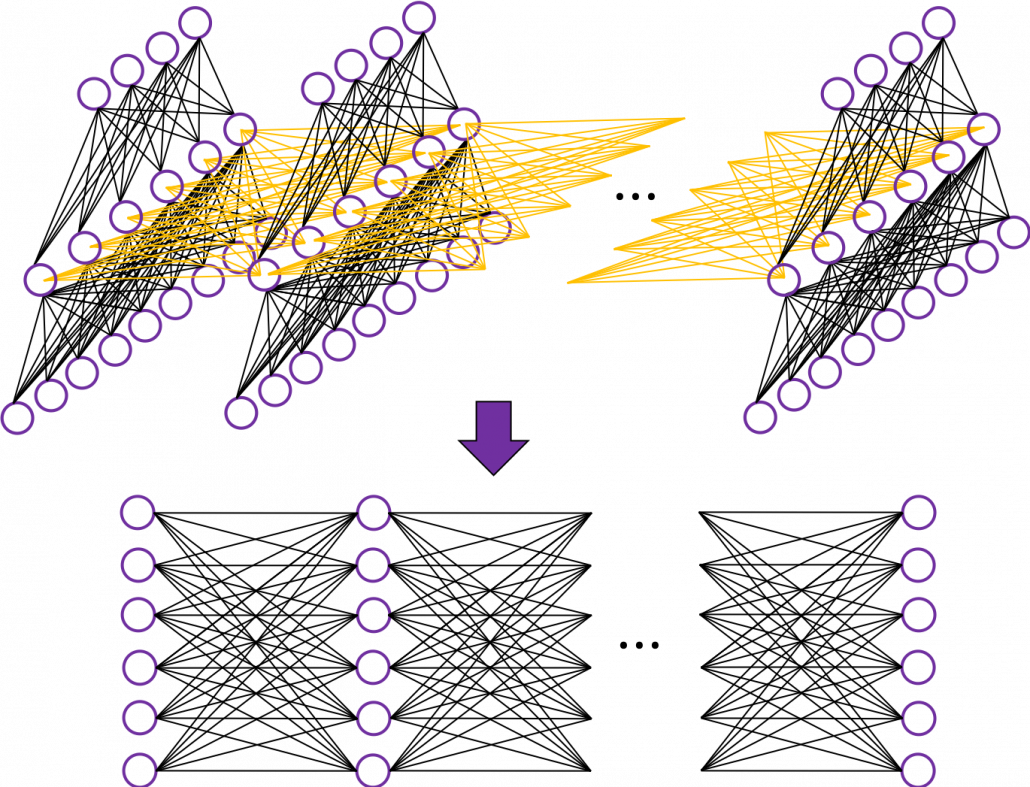

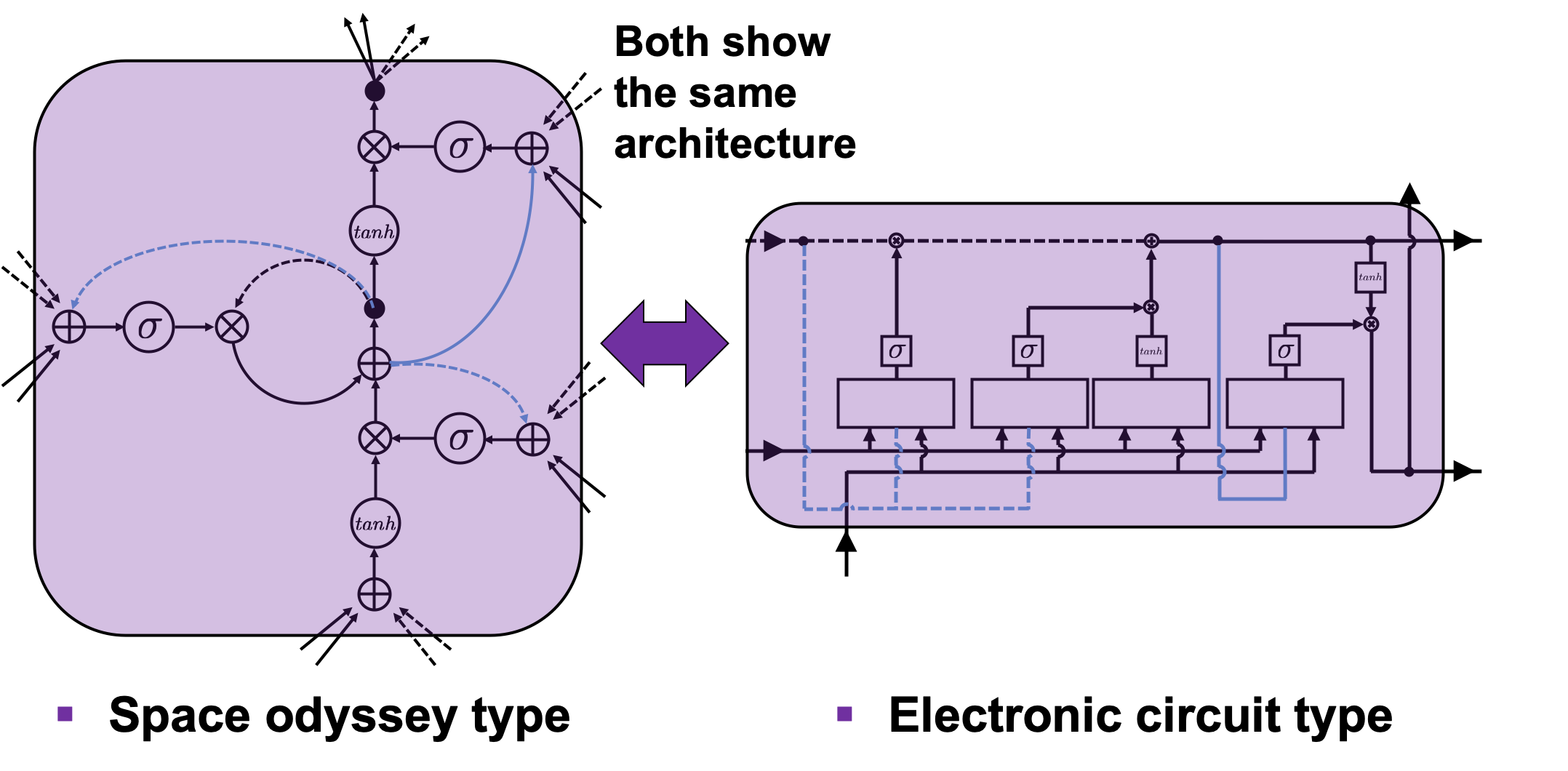

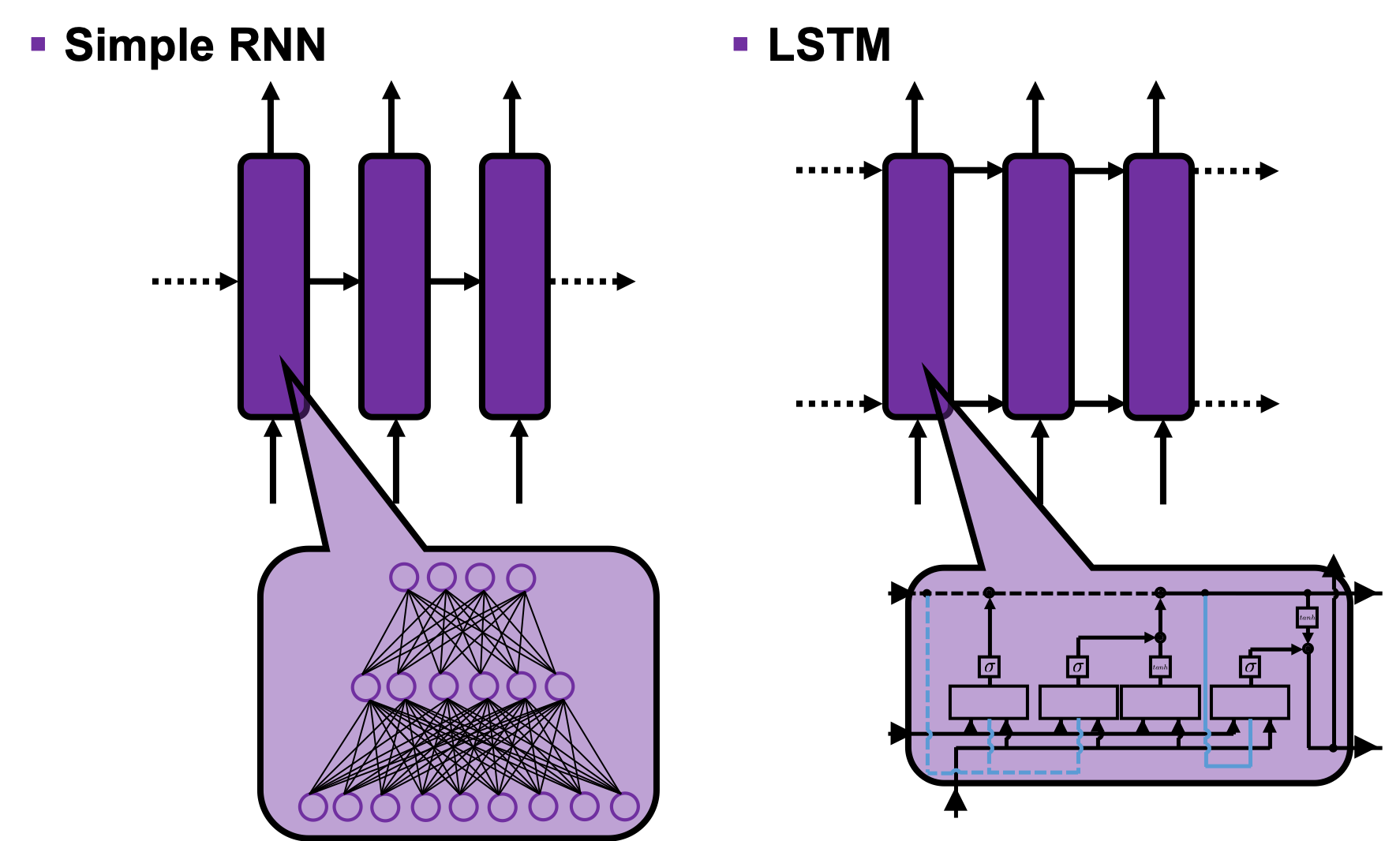

 gets
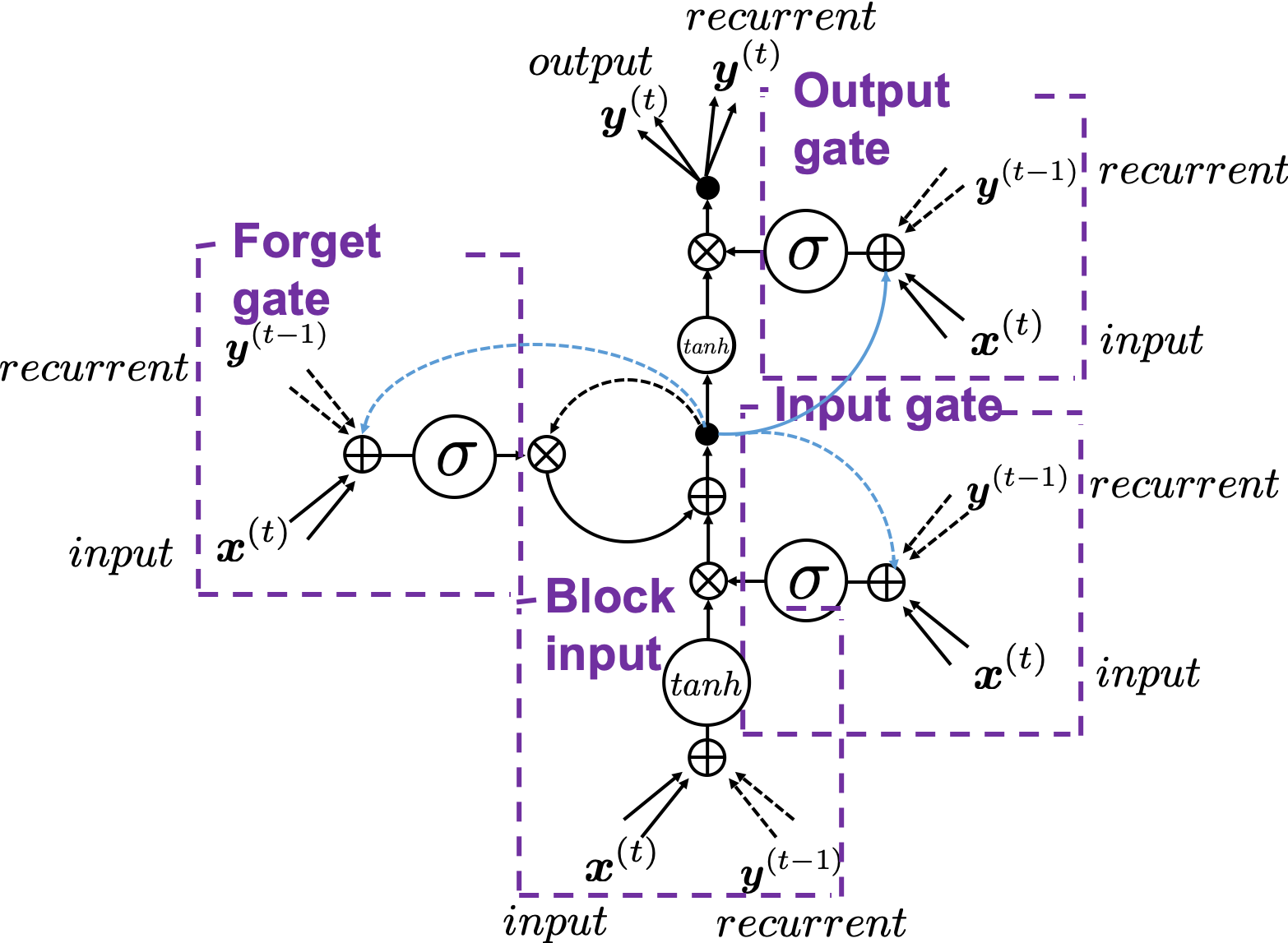
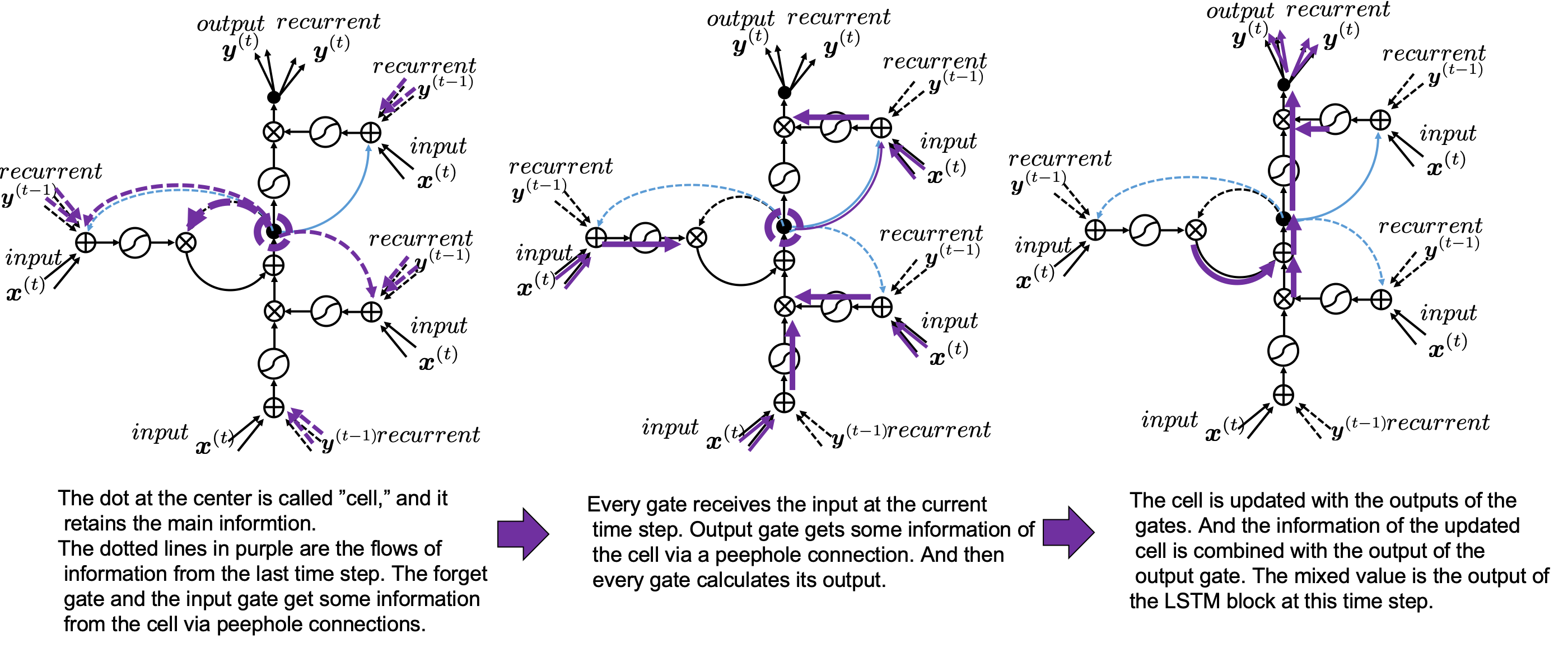
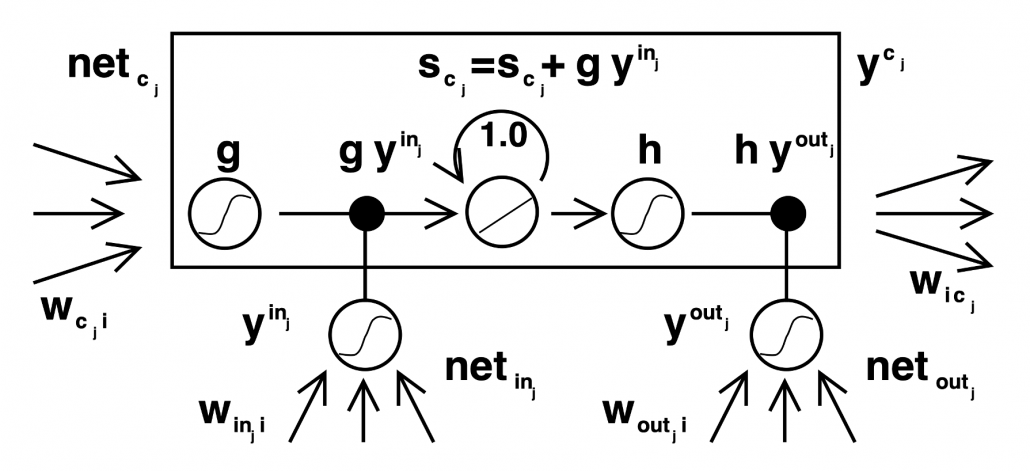
gets  , the output at the last time step, and
, the output at the last time step, and  , the information of the cell at the time step
, the information of the cell at the time step  , via recurrent connections. The block at time step
, via recurrent connections. The block at time step  , and it separately goes through each gate, together with
, and it separately goes through each gate, together with  . The outputs of the gates are mixed with
. The outputs of the gates are mixed with  , and gives
, and gives  to the next LSTM block via recurrent connections.
to the next LSTM block via recurrent connections.




 . This is a very simple operator. This operator produces an elementwise product of two vectors or matrices with identical shape.
. This is a very simple operator. This operator produces an elementwise product of two vectors or matrices with identical shape.


![[0, 1]](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-caffaae885a1287e3dfc31bfb1cd0694_l3.png "Rendered by QuickLaTeX.com") or
or ![[-1, 1]](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-96395345c57f8928c42918c656dd1364_l3.png "Rendered by QuickLaTeX.com") with activation functions. You can see that the input gate and the block input give new information to the cell. The part
with activation functions. You can see that the input gate and the block input give new information to the cell. The part  means that the output of the forget gate “forgets” the cell of the last time step by multiplying the values from 0 to 1 elementwise. And the cell
means that the output of the forget gate “forgets” the cell of the last time step by multiplying the values from 0 to 1 elementwise. And the cell  and the output of the output gate “suppress” the activated value of
and the output of the output gate “suppress” the activated value of  , LSTMs forget nothing, retain information of inputs at every time step, and gives out everything. And if all the outputs of every gate are always
, LSTMs forget nothing, retain information of inputs at every time step, and gives out everything. And if all the outputs of every gate are always  , LSTMs forget everything, receive no inputs, and give out nothing.
, LSTMs forget everything, receive no inputs, and give out nothing.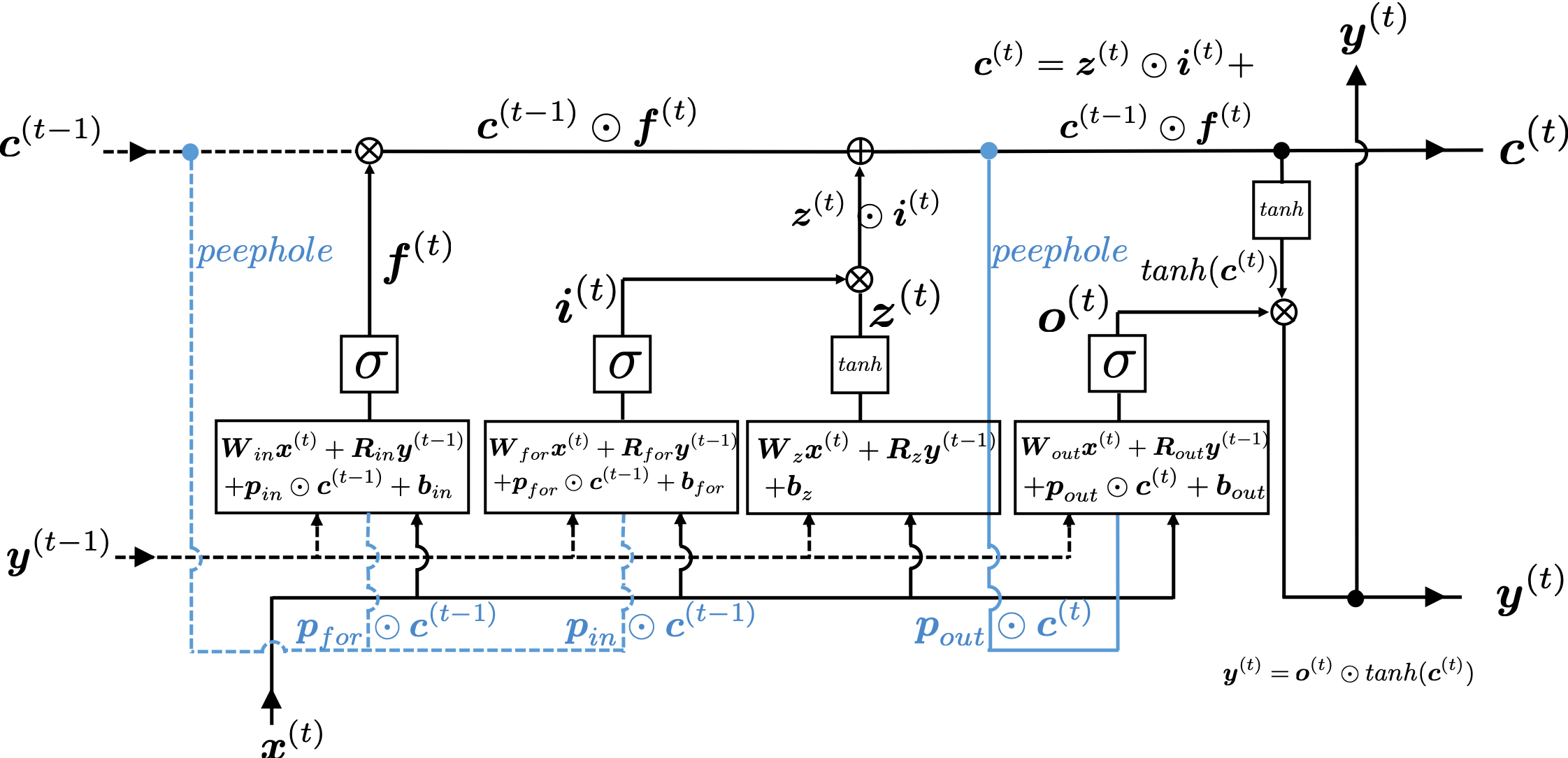









 Dr. Florian Nielsen ist Principal for AI und Data Science bei Miele im Bereich Smart Home und zuständig für die Entwicklung daten-getriebener digitaler Produkte und Produkterweiterungen. Der studierte Informatiker promovierte an der Universität Ulm zum Thema multimodale kognitive technische Systeme.
Dr. Florian Nielsen ist Principal for AI und Data Science bei Miele im Bereich Smart Home und zuständig für die Entwicklung daten-getriebener digitaler Produkte und Produkterweiterungen. Der studierte Informatiker promovierte an der Universität Ulm zum Thema multimodale kognitive technische Systeme.