Data Driven Thinking
Daten gelten als vierter Produktionsfaktor – diese Erkenntnis hat sich mittlerweile in den meisten Führungsetagen durchgesetzt. Während das Buzzword Big Data gerade wieder in der Senke verschwindet, wird nun vor allem von der Data Driven Company gesprochen, oder – im Kontext von I4.0 – von der Smart Factory.
Entsprechend haben die meisten Konzerne in den Aufbau einer Big-Data-Infrastruktur investiert und auch die größeren Mittelständler beginnen allmählich damit, einen Anfang zu setzen. Für den Anfang bedarf es jedoch gar nicht erst eine neue IT-Infrastruktur oder gar eine eigene Data Science Abteilung, ein richtiger Start zum datengetriebenen Unternehmen beginnt mit dem richtigen Mindset – ein Bewusst sein für Datenpotenziale.
Data Driven Thinking
Auch wenn es spezielle Lösungsanbieter anders verkaufen, ist nicht etwa eine bestimmte Datenbank oder eine bestimmte Analysemethodik für die Bewerkstelligung der Digitalisierung notwendig, sondern die datengetriebene Denkweise. In den Datenbeständen der Unternehmen und jenen aus weiteren bisher unerschlossenen Datenquellen stecken große Potenziale, die erkannt werden wollen. Es ist jedoch nicht notwendig, gleich als ersten Schritt jegliche Potenziale in Daten erkennen zu müssen, denn es ist viel hilfreicher, für aktuelle Problemstellungen die richtigen Daten zu suchen, in denen die Antworten für die Lösungen stecken könnten.
Data Driven Thinking oder auch kurz Data Thinking, wie angeblich von einem der ersten Chief Data Officer als solches bezeichnet und auch von meinem Chief Data Scientist Kollegen Klaas Bollhoefer beworben, ist die korrekte Bezeichnung für das richtige Mindset, mit dem sowohl aktuelle Probleme als auch deren Lösungen aus Daten heraus besser identifiziert werden können. Hierfür braucht man auch kein Data Scientist zu sein, es reicht bereits ein in den Grundzügen ausgeprägtes Bewusstsein für die Möglichkeiten der Datenauswertung – Ein Skill, der zeitnah für alle Führungskräfte zum Must-Have werden wird!
Data Scientists als Design Thinker
Was gerade in Europa vordergründig kritisiert wird: Es treffen traditionelle Denkmuster auf ganz neue Produkte und Dienste, mit immer schnelleren Entwicklungsprozessen und tendenziell kürzeren Lebenszyklen – eine zum Scheitern verurteilte Kombination und sicherlich auch einer der Gründe, warum us-amerikanische und auch chinesische Internetunternehmen hier die Nase vorn haben.
Ein zeitgemäßer Ansatz, der im Produktmanagement bereits etabliert ist und genau dort das letzte Quäntchen Innovationskraft freisetzt, ist Design Thinking. Dabei handelt es sich um einen iterativen Ideenfindungs und -validierungsprozess, bei dem die Wünsche und Bedürfnisse der Anwender durchgängig im Fokus stehen, im Hintergrund jedoch steht ein interdisziplinäres Team, dass ein Geschäftsmodell oder einen Geschäftsprozess unter Berücksichtigung des Kundenfeedbacks designed. Nutzer und Entwickler müssen dabei stets im engen Austausch stehen. Erste Ideen und Vorschläge werden bereits möglichst früh vorgestellt, damit bereits lange vor der Fertigstellung das Feedback der Anwender in die weitere Realisierung einfließen kann. Somit orientiert sich die gesamte Entwicklungsphase am Markt – Zu spät erkannte Fehlentwicklungen und Flops lassen sich weitgehend vermeiden. Design Thinker stellen dem Nutzer gezielte Fragen und analysieren dessen Abläufe (und nichts anderes tut ein Data Scientist, er beobachtet seine Welt jedoch viel umfassender, nämlich über jegliche zur Verfügung stehende Daten).
Der Design Thinking Prozess führt crossfunktionale Arbeitsgruppen durch sechs Phasen:
In der ersten Phase, dem Verstehen, definiert die Arbeitsgruppe den Problemraum. In der darauffolgenden Phase des Beobachtens ist es entscheidend, die Aktivitäten im Kontext, also vor Ort, durchzuführen und Anwender in ihrem jeweiligen Umfeld zu befragen. In der dritten Phase werden die gewonnenen Erkenntnisse zusammengetragen. In der nachfolgenden Phase der Ideenfindung entwickelt das Team zunächst eine Vielzahl von Lösungsoptionen. Abschließend werden beim Prototyping, in der fünften Phase, konkrete Lösungen entwickelt, die in der letzten Phase an den Zielgruppen auf ihren Erfolg getestet werden.
Beim Design Thinking mag es zwar eine grundsätzliche Vorgabe für den Ablauf der Ideenfindung und -erprobung geben – der eigentliche Mehrwert steckt jedoch in der dafür nötigen Denkweise und der Einstellung gegenüber dem Experimentieren sowie die Arbeit in einem interdisziplinären Team.

Data Driven Thinking überträgt diesen Ansatz auf die Mehrwert-Generierung unter Einsatz von Datenanalytik und leistet einen Transfer dieser systematischen Herangehensweise an komplexe Problemstellungen im Hinblick auf die Realisierung dafür angesetzter Big Data Projekte. Design Thinking unter Nutzung von Big Data ist überaus mächtig, wenn es darum geht, kundenorientierte Produkte und Prozesse zu entwickeln. Im Data Driven Business Cycle werden für immer neue Ideen und Fragestellungen:
- Daten generiert und gesammelt
- Daten gesichert, verwaltet und aufbereitet
- Daten analysiert
- daraus Erkenntnisse gezogen
Aus diesen sich iterativ kreisenden Prozessen der Datennutzung entsteht ein Data Pool (oftmals auch als Data Lake bezeichnet), der immer wieder zum für die Beantwortung von Fragen genutzt werden kann.
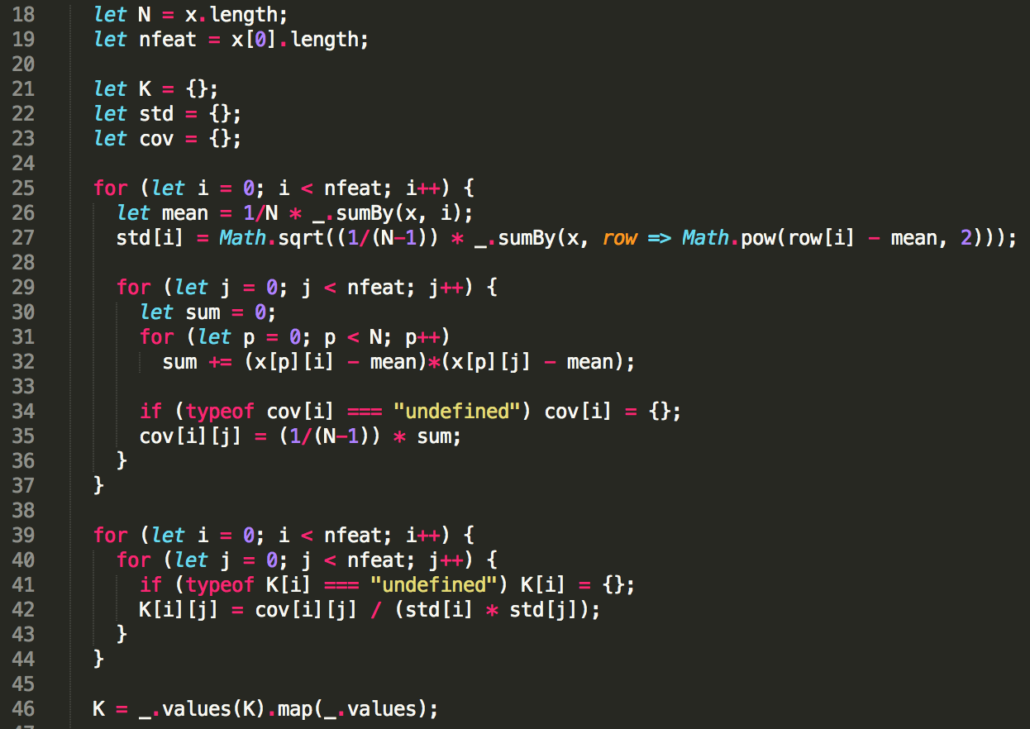
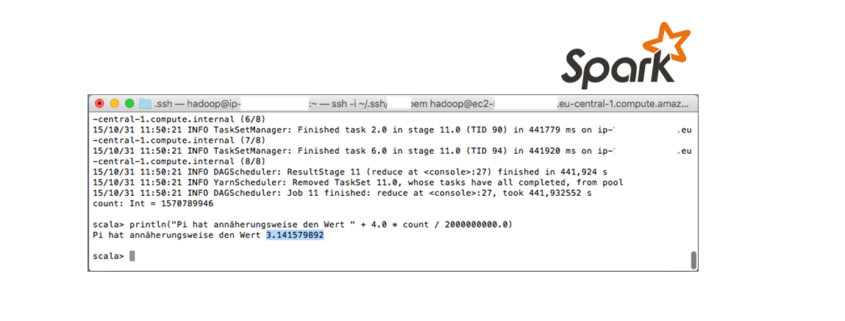
Prinzipien des maschinellen Lernen verstehen lernen
Data Driven Thinking entsteht mit dem Bewusstsein für die Potenziale, die in Daten liegen. Noch wirkungsvoller wird diese Denkweise, wenn auch ein Bewusstsein für die Möglichkeiten der Datenauswertung vorhanden ist.
„Kinder, die heute nicht programmieren können, sind die Analphabeten der Zukunft.“ schimpfte Vorzeige-Unternehmer Frank Thelen kürzlich in einer Politik-Talkrunde und bekräftigte damit meine noch davor verkündete Meinung “Karriere ohne Programmier-Erfahrung wird nahezu undenkbar”, denn “Systeme der künstlichen Intelligenz werden in der Zukunft unseren Einkauf und die Warenlieferung übernehmen, unsere Autos fahren, unsere Buchhaltung erledigen, unser Geld optimal auf den Finanzmärkten anlegen und unsere Krankheiten frühzeitig diagnostizieren und die bestmögliche medizinische Behandlung vorgeben.”
Jetzt muss niemand zum Experten für die Entwicklung künstlicher Systeme werden, um hier schritthalten zu können. Ein grundsätzliches Verständnis von den unterschiedlichen Prinzipien des maschinellen Lernen kann jedoch dabei helfen, solche Systeme und die dazugehörigen Chancen und Risiken besser einschätzen zu können, denn diese werden uns in Alltag und Beruf vermehrt begegnen, dabei einen entscheidenden Einfluss auf den Erfolg des Data Driven Business ausüben.

 Dr. Michael Müller-Wünsch ist seit August 2015 CIO der OTTO-Einzelgesellschaft in Hamburg. Herr Müller-Wünsch studierte die Diplom-Studiengänge Informatik sowie BWL mit Schwerpunkt Controlling an der TU Berlin. In seinen Rollen als IT-Leiter und CIO wurde er mehrfach für seine Leistungen ausgezeichnet und gilt heute als eine der erfahrensten Führungskräfte mit explizitem Know How in der Nutzung von Big Data für den eCommerce.
Dr. Michael Müller-Wünsch ist seit August 2015 CIO der OTTO-Einzelgesellschaft in Hamburg. Herr Müller-Wünsch studierte die Diplom-Studiengänge Informatik sowie BWL mit Schwerpunkt Controlling an der TU Berlin. In seinen Rollen als IT-Leiter und CIO wurde er mehrfach für seine Leistungen ausgezeichnet und gilt heute als eine der erfahrensten Führungskräfte mit explizitem Know How in der Nutzung von Big Data für den eCommerce.