Von der Datenanalyse zur Prozessverbesserung: So gelingt eine erfolgreiche Process-Mining-Initiative
Den Prozessdaten auf der Spur: Systematische Datenanalyse kombiniert mit Prozessmanagement
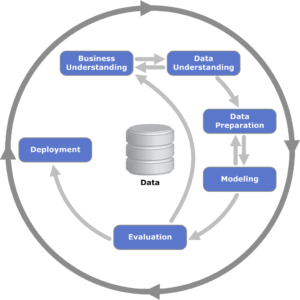
Die Digitalisierung verändert Organisationen aller Branchen. In zahlreichen Unternehmen werden alltägliche Betriebsabläufe softwarebasiert modelliert, automatisiert und optimiert. Damit hinterlässt fast jeder Prozess elektronische Spuren in den CRM-, ERP- oder anderen IT-Systemen einer Organisation. Process Mining gilt als effektive Methode, um diese Datenspuren zusammenzuführen und für umfassende Auswertungen zu nutzen. Sie kombiniert die systematische Datenanalyse mit Geschäftsprozessmanagement: Dabei werden Prozessdaten aus den verschiedenen IT-Systemen einer Organisation extrahiert und mit Hilfe von Data-Science-Technologien visualisiert und ausgewertet.
![]()
Read this article in English: From BI to PI: The Next Step in the Evolution of Data-Driven Decisions
Professionelle Process-Mining-Lösungen erlauben, die Ergebnisse dieser Prozessauswertungen auf Dashboards darzustellen und nach bestimmten Prozessen, Transaktionen, Abteilungen oder Kunden zu filtern. So ist es möglich, die Performance, Durchlaufzeiten und die Kosten einzelner Betriebsabläufe zu erfassen. Prozessverantwortliche werden auf diesem Wege auf Verzögerungen, ineffiziente Abläufe und mögliche Prozessverbesserungen aufmerksam.
Praxisbeispiel: Einkaufsprozess – Prozessabweichungen als Kosten- und Risikofaktor
Ein Beispiel aus dem Unternehmensalltag ist ein einfacher Einkaufsprozess: Ein Mitarbeiter benötigt einen neuen Laptop. Im Normalfall beginnt der Prozess mit der Anfrage des Mitarbeiters, die durch seinen Manager bestätigt wird. Ist kein Laptop vorrätig, löst das für den Einkauf zuständige Team die Bestellung aus. Zu einem späteren Zeitpunkt wird der Laptop dem Mitarbeiter übergeben und das Unternehmen erhält eine Rechnung. Diese Rechnung wird geprüft und fristgemäß gemäß den vorgegebenen Konditionen beglichen. Obwohl dieser alltägliche Prozess nicht sehr komplex ist, weicht er im Unternehmensalltag häufig vom modellierten Idealzustand ab, was unnötige Kosten und möglicherweise auch Risiken verursacht.
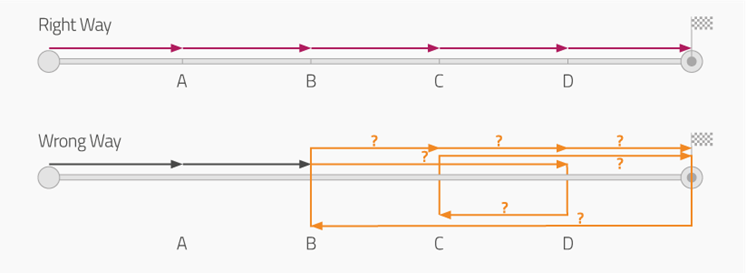
Die Gründe sind vielfältig:
- Freigaben fehlen
- Während des Bestellprozesses sind Informationen unvollständig
- Rechnungen werden aufgrund von unvollständigen Informationen mehrfach korrigiert
Process Mining ermöglicht, den gesamten Prozessverlauf alltäglicher Betriebsabläufe unter die Lupe zu nehmen und faktenbasierte Diskussionen zwischen den Fachabteilungen, Prozessverantwortlichen sowie dem Management in einer Organisation anzuregen. So werden unternehmensweite Prozessverbesserungen möglich – vorausgesetzt, die Methode wird richtig angewandt und ist strategisch durchdacht. Doch wie gelingt eine erfolgreiche unternehmensweite Process-Mining-Initiative über Abteilungsgrenzen hinaus?
Wie sich eine erfolgreiche Process-Mining-Initiative auf den Weg bringen lässt
Jedes Unternehmen ist einzigartig und geht mit unterschiedlichen Fragestellungen an eine Process-Mining-Initiative heran: ob einzelne Prozesse gezielt verbessert, Prozesslebenszyklen verkürzt oder abteilungsübergreifende Abläufe an unterschiedlichen Standorten miteinander verglichen werden. Sie alle haben etwas gemeinsam: Eine erfolgreiche Process-Mining-Initiative erfordert ein strategisches Vorgehen.
Schritt 1: Mit Weitsicht planen und richtig kommunizieren
Wie definiere ich die Ziele und den Umfang der Process-Mining-Initiative?
Die Anfangsphase einer Process-Mining-Initiative dient der Planung und entscheidet häufig über den Erfolg eines Projektes. In erster Linie kommt es darauf an, die Ziele des Projektes zu definieren und die Erfolgsfaktoren zu bestimmen. Die Ziele einer erfolgreichen Process-Mining-Initiative sind SMART definiert: spezifisch, messbar, attainable/relevant, reasonable/umsetzbar und zeitgebunden/time-bound. Mögliche Ziele für das Projekt lassen sich zum Beispiel wie folgt formulieren:
- Prozessdauer auf 25 Tage reduzieren
- Hauptunterschiede zwischen zwei Ländern hinsichtlich bestimmter Prozesse identifizieren
- Prozessautomatisierung um 25% steigern
Unter diesen Voraussetzungen lässt sich auch der Rahmen der Process-Mining-Initiative festlegen: Sie halten fest, welche Prozesse, konkret betroffen sind und wie sie mit den IT-Systemen und Mitarbeiterrollen in Ihrer Organisation verknüpft sind.
Welche Rollen und Verantwortlichkeiten gibt es?
Die Ziele Ihrer Process-Mining-Initiative sollten unternehmensweit geteilt werden: Dies erfordert neben einer klaren Strategie eine transparente Kommunikation in der gesamten Organisation: Indem Sie Ihren Mitarbeitern das nötige Wissen an die Hand geben, um die Initiative erfolgreich mitzugestalten, sichern Sie sich auch ihre Unterstützung.
So verstehen sie nicht nur, warum dieses Projekt sinnvoll ist, sondern sind auch in der Lage, das Wissen auf ihre individuelle Rolle und Situation zu übertragen. Im Rahmen einer Process-Mining-Initiative sind verschiedene Projektbeteiligte in unterschiedlichen Rollen aktiv:
Während Projektträger verantwortlich für die Prozessanalyse sind (z. B. Chief Procurement Officer oder Process Owner), wissen Prozessexperten, wie ein bestimmter Prozess verläuft und kennen die verschiedenen Variationen. Sie nutzen Methoden wie Process Mining, um ihr Wissen zu vertiefen und Diskussionen über die gewonnenen Daten anzustoßen. Sie arbeiten eng mit Business-Analysten zusammen, die die Prozessanalyse vorantreiben. Datenexperten wiederum verfolgen die einzelnen Spuren, die ein Prozess in der IT-Landschaft einer Organisation hinterlässt und bereiten sie so auf, dass sie Aufschluss über die Performance eines Prozesses geben.
Wie gestaltet sich die Zusammenarbeit?
Diese unterschiedlichen Rollen gilt es im Rahmen einer erfolgreichen Process-Mining-Initiative an einen Tisch zu bringen: So können die gewonnen Erkenntnisse gemeinsam im Team interpretiert und diskutiert werden, um die richtigen Veränderungen anzustoßen. Die daraus gewonnen Prozessverbesserungen spiegeln das Know-how des gesamten Teams wider und sind das Ergebnis einer erfolgreichen Zusammenarbeit.
Schritt 2: Die technischen Voraussetzungen schaffen
Wie werden Prozessdaten systemübergreifend aggregiert und aufbereitet?
Nun wird es Zeit für die technischen Vorbereitungen: Entscheidend ist es, alle Anforderungen an die beteiligten IT-Systeme zu durchdenken und die IT-Verantwortlichen so früh wie möglich einzubeziehen. Um valide Daten für Prozessverbesserungen zu generieren, sind diese drei Teilschritte nötig:
- Datenextraktion: Relevante Daten aus unterschiedlichen IT-Systemen werden aggregiert (Datenquellen sind datenbasierte Tabellen aus ERP- und CRM-Lösungen, analytische Daten wie Reports, Logdateien, CSV-Dateien usw.)
- Datenumwandlung gemäß den Anforderungen für Process Mining: Die extrahierten Daten werden in Cases (Abfolge verschiedener Prozessschritte) umgewandelt, mit einem Zeitstempel versehen und in Event-Logs gespeichert.
- Datenübertragung: Die Process-Mining-Software greift auf die gespeicherten Event-Logs zu.
Welche Rolle spielen Konnektoren?
Diese Teilschritte werden erfahrungsgemäß mittels eines Software-Konnektors durchgeführt und in regelmäßigen Abständen wiederholt. Ein Software-Konnektor hat die Aufgabe, die Daten aus der IT-Landschaft eines Unternehmens nach den Anforderungen der Process-Mining-Lösung zu übersetzen. Er wird speziell für die Kombination mit bestimmten IT-Systemen wie SAP, Oracle oder Salesforce entwickelt und steuert die gesamte Datenintegration von der Extraktion über die Umwandlung bis zur Datenübertragung.
Process-Mining-Lösungen wie Signavio Process Intelligence verfügen über Standardkonnektoren sowie über eine API für individuell entwickelte Konnektoren. Im Rahmen der technischen Vorbereitungen gilt es, mit Blick auf das jeweilige Szenario über die Möglichkeiten der Umsetzbarkeit zu entscheiden und andere technische Lösungen zu evaluieren.
Schritt 3: Von der Prozessanalyse zur Prozessverbesserung
Wie lassen sich die ermittelten Daten für Verbesserungen nutzen?
Sind die umgewandelten Daten in der Process-Mining-Lösung verfügbar, beginnt die Prozessauswertung. Durch IT-gestütztes Process Mining erhalten Prozessexperten die Möglichkeit, alle vorliegenden Daten zu visualisieren und einzelne Prozesse detailliert auszuwerten. Die vorliegenden Prozesse werden nun hinsichtlich unterschiedlicher Faktoren untersucht, etwa mit Blick auf Durchlaufzeiten, Performance und den Prozessfluss. Im direkten Vergleich lässt sich auf diesem Wege ermitteln, welche Faktoren sich auf die Erfolgskennzahlen auswirken und an welchen Stellen Verzögerungen oder Abweichungen auftreten.
Die so gewonnen Erkenntnisse bilden eine wichtige Grundlage für faktenbasierte Diskussionen zwischen den verschiedenen Stakeholdern der Process-Mining-Initiative. Doch erst die konkreten Schritte, die aus dieser Datenbasis abgeleitet werden, entscheiden über den Erfolg des Projektes: Entscheidend ist, wie diese Erkenntnisse in die Praxis umgesetzt werden.
Eine Process-Mining-Lösung, die nicht als reines Analysetool zur Verfügung steht, sondern in eine umfassende Lösung für die Modellierung, Automatisierung und Analyse professioneller Geschäftsprozesse integriert ist, erleichtert den Schritt von der Business Process Discovery zur Prozessverbesserung. Schließlich gilt es, konkrete Prozessverbesserungen und Änderungen zu planen, in den Unternehmensalltag zu integrieren und die Ergebnisse auszuwerten – auch über das Ende der Process-Mining-Initiative hinaus.
Warum ist ein Process-Mining-Projekt nie vollständig abgeschlossen?
Wer einmal mit der Prozessverbesserung beginnt, wird feststellen: Viele weitere Stellen in den Prozessen warten nur darauf, verbessert zu werden. Daher lohnt es sich, einige Wochen nach der initialen Prozessverbesserung neue Daten zu extrahieren, um herauszufinden, welche Veränderungen nachweislich zu mehr Effizienz geführt haben. Eine kontinuierliche Messung und Auswertung erleichtert einen umfassenden Blick auf die eigene Organisation:
- Funktionieren die überarbeiteten Prozesse wie geplant?
- Haben Prozessveränderungen unvorhersehbare Effekte?
- Treten Schwachstellen in anderen Prozessen auf?
- Haben sich die Prozesse verändert, seitdem sie überarbeitet wurden?
- Wie lässt sich ein bestimmter Prozess weiter verbessern?
Somit lässt sich zusammenfassen: Wem es gelingt, die Datenspuren in den IT-Systemen der eigenen Organisation zu verfolgen, ist auf dem richtigen Weg zur kontinuierlichen Verbesserung. Davon profitieren nicht nur die Prozesse und IT-Systeme, sondern auch die Mitarbeiter in den Organisationen.

 Ross Perez is the Senior Director, Marketing EMEA at
Ross Perez is the Senior Director, Marketing EMEA at