
Cross-industry standard process for data mining
Introduced in 1996, the cross-industry standard process for data mining (CRISP-DM) became the most
common procedure for all data mining projects. This method consists of six phases: Business
understanding, Data understanding, Data preparation, Modeling, Evaluation and Deployment (see
Figure 1). It is being used not just as a reference manual but as a user guide as it explains every phase
in detail (Hipp, 2000). The six phases of this model are explained below:
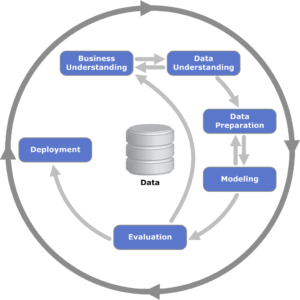
Figure 1: Different phases of CRISP-DM
Business Understanding
It includes understanding the business problem and determining the
objective of the business as well as of the project. It is also important to understand the previous work
done on the project (if any) to achieve the business goals and to examine if the scope of the project has changed.
The job of a Data Scientist is not limited to coding or just make a machine learning model and I guess that’s why this whole lifecycle was developed. The key points a project owner should take care in this process are:
– Identify stakeholders and involve them to define the scope your project
– Describe your product (your machine learning model)
– Identify how your product ties into the client’s business processes
– Identify metrics / KPIs for measuring success
Data understanding
The initial step in this phase is to gather all the data from different sources. It is
then important to describe the data, generate graphs for distribution in order to get familiar with the
data. This phase is important as without enough data or without understanding about the data analysis
cannot be performed. In data mining terms this can be compared to Exploratory data analysis (EDA)
where techniques from descriptive statistics are used to have an insight into the data. For instance, if it is
a time series data it makes sense to know from when until when the data is available before diving deep into
the data.
Data preparation
This phase takes most of the time in data mining project as a lot of methods from
data cleaning, feature subset, feature engineering, the transformation of data etc. are used before the final
dataset is trained for modeling purpose. The single dataset can also be prepared in different forms as some
algorithms can learn more with a certain type of data, some algorithms can deal with imbalance dataset
and for some algorithms, the target variable must be balanced. This phase also requires sometimes to
calculate new KPI’s according to the business need or sometimes to reduce the dimension of the dataset.
Modeling and Evaluation
Various models are selected and build in this process and appropriate hyperparameters are
selected after an intensive grid search. Once all the models are built it is now time to evaluate and compare performances of all the models.
Deployment
A model is of no use if it is not deployed into production. Until now you have been doing the job of a data scientist but for deployment, you need some software engineering
skills. There are several ways to deploy a machine learning model or python code. Few of them are:
- Re-implement your python code in C++, Java etc. (LOL)
- Save the coefficients and use them to get predictions
- Serialized objects (REST API with flask, Django)
To understand the concept of deploying an ML model using REST API this post is highly recommended.

Leave a Reply
Want to join the discussion?Feel free to contribute!