Fehler-Rückführung mit der Backpropagation
Dies ist Artikel 4 von 6 der Artikelserie –Einstieg in Deep Learning.
Das Gradienten(abstiegs)verfahren ist der Schlüssel zum Training einzelner Neuronen bzw. deren Gewichtungen zu den Neuronen der vorherigen Schicht. Wer dieses Prinzip verstanden hat, hat bereits die halbe Miete zum Verständnis des Trainings von künstlichen neuronalen Netzen.
Der Gradientenabstieg wird häufig fälschlicherweise mit der Backpropagation gleichgesetzt, jedoch ist das nicht ganz richtig, denn die Backpropagation ist mehr als die Anwendung des Gradientenabstiegs.
Bevor wir die Backpropagation erläutern, nochmal kurz zurück zur Forward-Propagation, die die eigentliche Prädiktion über ein künstliches neuronales Netz darstellt:
Forward-Propagation
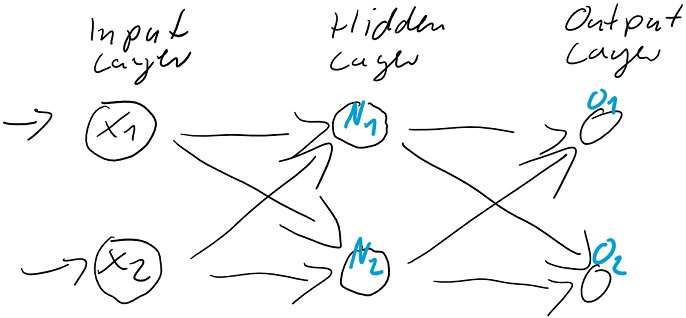
Abbildung 1: Ein simples kleines künstliches neuronales Netz mit zwei Schichten (+ Eingabeschicht) und zwei Neuronen pro Schicht.
In einem kleinen künstlichen neuronalen Netz, wie es in der Abbildung 1 dargestellt ist, und das alle Neuronen über die Sigmoid-Funktion aktiviert, wird jedes Neuron eine Nettoeingabe  berechnen…
berechnen…

… und diese Nettoeingabe in die Sigmoid-Funktion einspeisen…

… die dann das einzelne Neuron aktiviert. Die Aktivierung erfolgt also in der mittleren Schicht (N-Schicht) wie folgt:

Die beiden Aktivierungsausgaben  werden dann als Berechnungsgrundlage für die Ausgaben der Ausgabeschicht
werden dann als Berechnungsgrundlage für die Ausgaben der Ausgabeschicht  verwendet. Auch die Ausgabe-Neuronen berechnen ihre jeweilige Nettoeingabe und aktivieren über Sigmoid().
verwendet. Auch die Ausgabe-Neuronen berechnen ihre jeweilige Nettoeingabe und aktivieren über Sigmoid().
Ausgabe eines Ausgabeknotens als Funktion der Eingänge und der Verknüpfungsgewichte für ein dreischichtiges neuronales Netz, mit nur zwei Knoten je Schicht, kann also wie folgt zusammen gefasst werden:

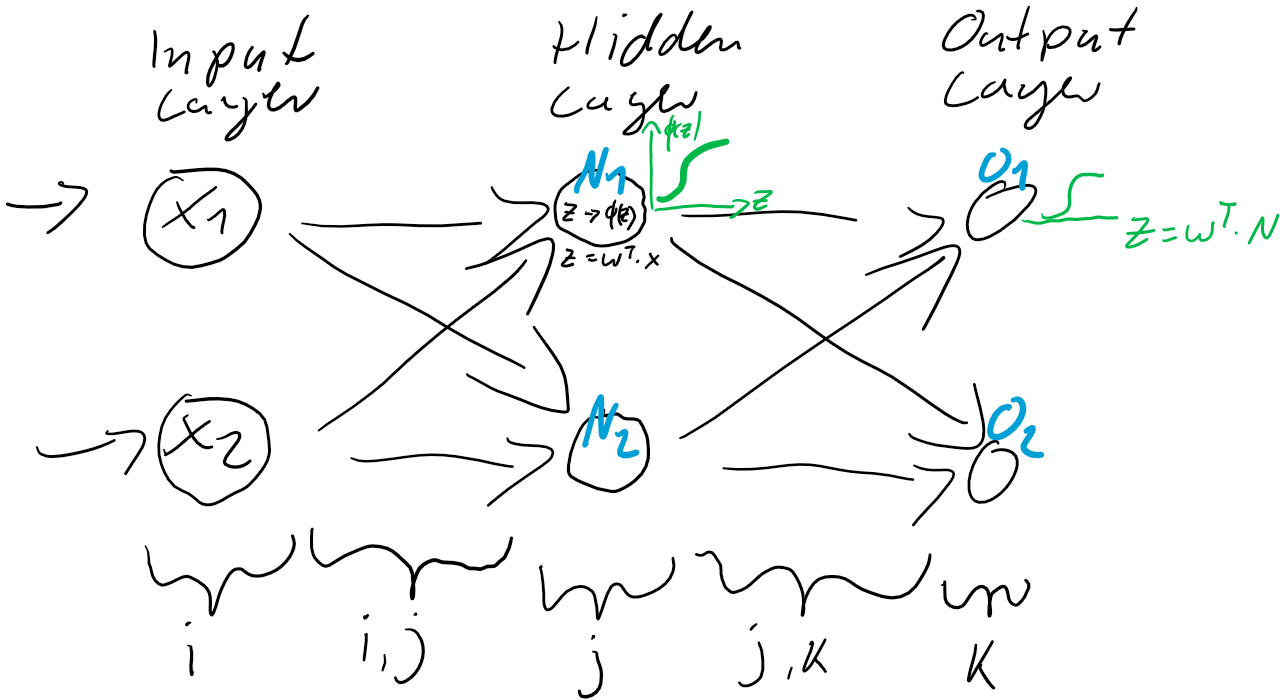
Abbildung 2: Forward-Propagation. Aktivierung via Sigmoid-Funktion.
Sollte dies die erste Forward-Propagation gewesen sein, wird der Output noch nicht auf den Input abgestimmt sein. Diese Abstimmung erfolgt in Form der Gewichtsanpassung im Training des neuronalen Netzes, über die zuvor erwähnte Gradientenmethode. Die Gradientenmethode ist jedoch von einem Fehler abhängig. Diesen Fehler zu bestimmen und durch das Netz zurück zu führen, das ist die Backpropagation.
Back-Propagation
Um die Gewichte entgegen des Fehlers anpassen zu können, benötigen wir einen möglichst exakten Fehler als Eingabe. Der Fehler berechnet sich an der Ausgabeschicht über eine Fehlerfunktion (Loss Function), beispielsweise über den MSE (Mean Squared Error) oder über die sogenannte Kreuzentropie (Cross Entropy). Lassen wir es in diesem Beispiel einfach bei einem simplen Vergleich zwischen dem realen Wert (Sollwert  ) und der Prädiktion (Ausgabe ) bleiben:
) und der Prädiktion (Ausgabe ) bleiben:

Der Fehler  ist also einfach der Unterschied zwischen dem Ziel-Wert und der Prädiktion. Jedes Training ist eine Wiederholung von Prädiktion (Forward) und Gewichtsanpassung (Back). Im ersten Schritt werden üblicherweise die Gewichtungen zufällig gesetzt, jede Gewichtung unterschiedlich nach Zufallszahl. So ist die Wahrscheinlichkeit, gleich zu Beginn die “richtigen” Gewichtungen gefunden zu haben auch bei kleinen neuronalen Netzen verschwindend gering. Der Fehler wird also groß sein und kann über den Gradientenabstieg durch Gewichtsanpassung verkleinert werden.
ist also einfach der Unterschied zwischen dem Ziel-Wert und der Prädiktion. Jedes Training ist eine Wiederholung von Prädiktion (Forward) und Gewichtsanpassung (Back). Im ersten Schritt werden üblicherweise die Gewichtungen zufällig gesetzt, jede Gewichtung unterschiedlich nach Zufallszahl. So ist die Wahrscheinlichkeit, gleich zu Beginn die “richtigen” Gewichtungen gefunden zu haben auch bei kleinen neuronalen Netzen verschwindend gering. Der Fehler wird also groß sein und kann über den Gradientenabstieg durch Gewichtsanpassung verkleinert werden.
In diesem Beispiel berechnen wir die Fehler  und
und  und passen danach die Gewichte
und passen danach die Gewichte  (
( &
&  und
und  &
&  ) der Schicht zwischen dem Hidden-Layer und dem Output-Layer an.
) der Schicht zwischen dem Hidden-Layer und dem Output-Layer an.
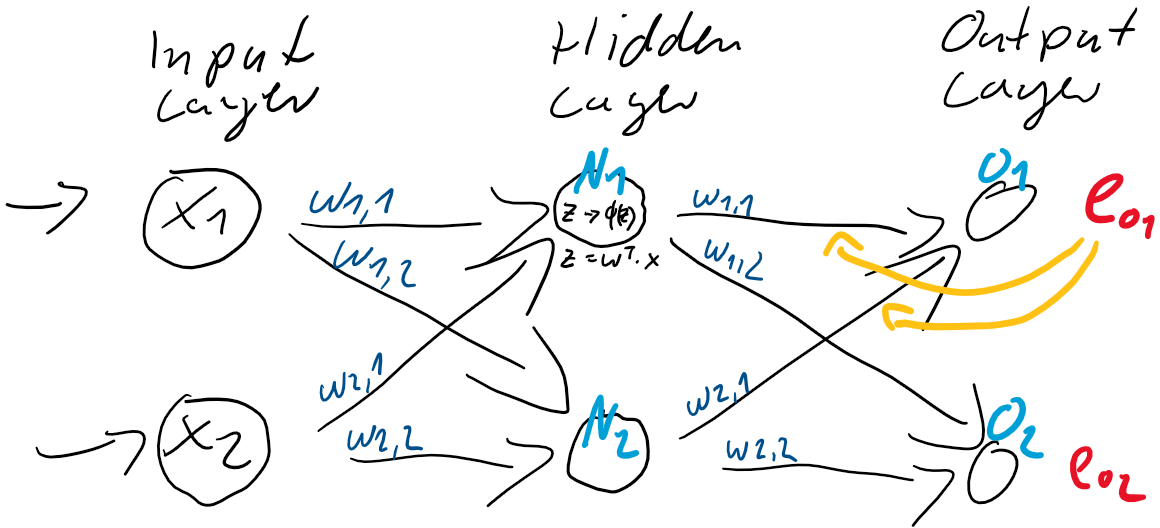
Abbildung 3: Anpassung der Gewichtungen basierend auf dem Fehler in der Ausgabe-Schicht.
Die Frage ist nun, wie die Gewichte zwischen dem Input-Layer  und dem Hidden-Layer anzupassen sind. Es stellt sich die Frage, welchen Einfluss diese auf die Fehler in der Ausgabe-Schicht haben?
und dem Hidden-Layer anzupassen sind. Es stellt sich die Frage, welchen Einfluss diese auf die Fehler in der Ausgabe-Schicht haben?
Um diese Gewichtungen anpassen zu können, benötigen wir den Fehler-Anteil der beiden Neuronen  und
und  . Dieser Anteil am Fehler der jeweiligen Neuronen ergibt sich direkt aus den Gewichtungen zum Output-Layer:
. Dieser Anteil am Fehler der jeweiligen Neuronen ergibt sich direkt aus den Gewichtungen zum Output-Layer:


Wenn man das nun generalisiert:
![\[ e_{N} = \left(\begin{array}{rr} \frac{w_{1,1}}{w_{1,1} + w_{1,2}} & \frac{w_{1,2}}{w_{1,1} + w_{1,2}} \\ \frac{w_{2,1}}{w_{2,1} + w_{2,2}} & \frac{w_{2,2}}{w_{2,1} + w_{2,2}} \end{array}\right) \cdot \left(\begin{array}{c} e_{1} \\ e_{2} \end{array}\right) \qquad \]](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-6fadfe69caec8e8c351788824875138a_l3.png "Rendered by QuickLaTeX.com")
Dabei ist es recht aufwändig, die Gewichtungen stets ins Verhältnis zu setzen. Diese Berechnung können wir verkürzen, indem ganz einfach direkt nur die Gewichtungen ohne Relativierung zur Kalkulation des Fehleranteils benutzt werden. Die Relationen bleiben dabei erhalten!
![\[ e_{N} = \left(\begin{array}{rr} w_{1,1} & w_{1,2} \\ w_{2,1} & w_{2,2} \end{array}\right) \cdot \left(\begin{array}{c} e_{1} \\ e_{2} \end{array}\right) \qquad \]](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-7dee7d02ac1aba606a45895afe90a837_l3.png "Rendered by QuickLaTeX.com")
Oder folglich in Kurzform: 
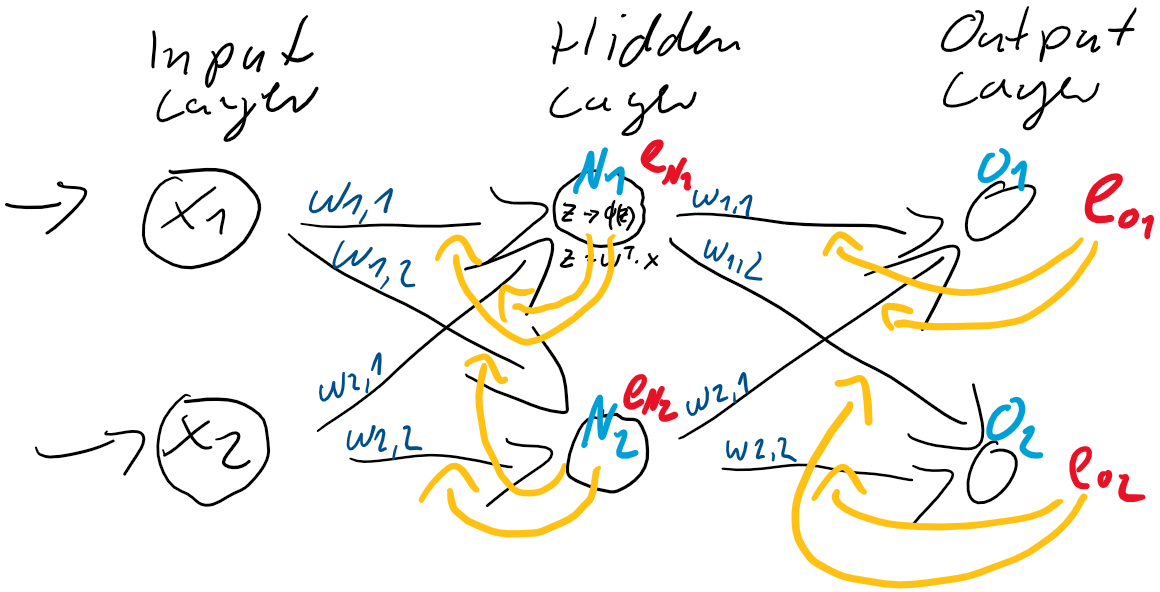
Abbildung 4: Vollständige Gewichtsanpassung auf Basis der Fehler in der Ausgabeschicht und der Fehleranteile in der verborgenden Schicht.
Und nun können, basierend auf den Fehleranteilen der verborgenden Schicht , die Gewichtungen  zwischen der Eingabe-Schicht
zwischen der Eingabe-Schicht  und der verborgenden Schicht angepasst werden, entgegen dieser Fehler
und der verborgenden Schicht angepasst werden, entgegen dieser Fehler  .
.
Die Backpropagation besteht demnach aus zwei Schritten:
- Fehler-Berechnung durch Abgleich der Soll-Werte mit den Prädiktionen in der Ausgabeschicht und durch Fehler-Rückführung zu den Neuronen der verborgenden Schichten (Hidden-Layer)
- Anpassung der Gewichte entgegen des Gradientenanstiegs der Fehlerfunktion (Loss Function)
Buchempfehlungen
Die folgenden zwei Bücher haben mir sehr beim Verständnis und beim Verständlichmachen der Backpropagation in künstlichen neuronalen Netzen geholfen.









Hallo, ich bin Anfänger in Sachen neuronale Netzwerke. Ich hätte da eine grundsätzliche Frage zum Thema Fehlerberechung und entsprechender Modifikation der Stärke des jeweiligen Gewichtes. Dies wird ja auch in diesem Blog erklärt. Warum muss man sich eigentlich den Fehler berechnen und schrittweise an die richtige Gewichtsstärke annähern? Man könnte doch die richtige Stärke des Gewichtes viel einfacher berechnen mittels einer simplen Quotientenbildung wie beim Dreisatz, d.h. bei Abweichung der Ladung des Neurons von einem gewünschten Zielwert die Stärke des Gewichtes analog erhöhen oder erniedrigen, z.B. Gewicht(aktuell)/Gewicht(gewünscht) = LadungNeuron(aktuell)/LadungNeuron(gewünscht) => Gewicht(gewünscht) = Gewicht(aktuell) * (Ladung(gewünscht)/Ladung(aktuell)). Warum muss man sich umständlich mittels z.B. einer Quadrat-Fehlerfunktion schrittweise annähern? Offensichtlich hab ich da einen Denkfehler, oder hängt es damit zusammen, daß ja mehrere Muster gelernt werden müssen und daher die von mir vorgeschlagene Berechnung die anderen Muster bzw. erlernten Gewichte löschen würde? Vielen Dank im voraus für eine Erklärung! T.P.
Eine gute Erklärung arbeitet stets mit einer Beispielrechnung und Zahlen zur Verdeutlichung, damit sich die Formeln leichter interpretieren lassen. Weil das so gut wie niemand macht, darf man sich unzählige Texte anschauen, um es schlussendlich immer noch nicht zu verstehen. Zahlen würden auch dazu beitragen, dass mit den Gradienten, der Fehlerberechnung und der back propagation zu verstehen. Weniger aufgeblähter Formelsalat würde auch etwas mehr Licht ins Dunkel bringen.