
Einstieg in Natural Language Processing – Teil 2: Preprocessing von Rohtext mit Python
Dies ist der zweite Artikel der Artikelserie Einstieg in Natural Language Processing.
In diesem Artikel wird das so genannte Preprocessing von Texten behandelt, also Schritte die im Bereich des NLP in der Regel vor eigentlichen Textanalyse durchgeführt werden.
Tokenizing
Um eingelesenen Rohtext in ein Format zu überführen, welches in der späteren Analyse einfacher ausgewertet werden kann, sind eine ganze Reihe von Schritten notwendig. Ganz allgemein besteht der erste Schritt darin, den auszuwertenden Text in einzelne kurze Abschnitte – so genannte Tokens – zu zerlegen (außer man bastelt sich völlig eigene Analyseansätze, wie zum Beispiel eine Spracherkennung anhand von Buchstabenhäufigkeiten ect.).
Was genau ein Token ist, hängt vom verwendeten Tokenizer ab. So bringt NLTK bereits standardmäßig unter anderem BlankLine-, Line-, Sentence-, Word-, Wordpunkt- und SpaceTokenizer mit, welche Text entsprechend in Paragraphen, Zeilen, Sätze, Worte usw. aufsplitten. Weiterhin ist mit dem RegexTokenizer ein Tool vorhanden, mit welchem durch Wahl eines entsprechenden Regulären Ausdrucks beliebig komplexe eigene Tokenizer erstellt werden können.
Üblicherweise wird ein Text (evtl. nach vorherigem Aufsplitten in Paragraphen oder Sätze) schließlich in einzelne Worte und Interpunktionen (Satzzeichen) aufgeteilt. Hierfür kann, wie im folgenden Beispiel z. B. der WordTokenizer oder die diesem entsprechende Funktion word_tokenize() verwendet werden.
|
1 2 3 4 5 6 |
rawtext = 'This is a short example text that needs to be cleaned.' tokens = nltk.word_tokenize(rawtext) tokens ['This', 'is', 'a', 'short', 'example', 'text', 'that', 'needs', 'to', 'be', 'cleaned', '.'] |
Stemming & Lemmatizing
Andere häufig durchgeführte Schritte sind Stemming sowie Lemmatizing. Hierbei werden die Suffixe der einzelnen Tokens des Textes mit Hilfe eines Stemmers in eine Form überführt, welche nur den Wortstamm zurücklässt. Dies hat den Zweck verschiedene grammatikalische Formen des selben Wortes (welche sich oft in ihrer Endung unterscheiden (ich gehe, du gehst, er geht, wir gehen, …) ununterscheidbar zu machen. Diese würden sonst als mehrere unabhängige Worte in die darauf folgende Analyse eingehen.
Neben bereits fertigen Stemmern bietet NLTK auch für diesen Schritt die Möglichkeit sich eigene Stemmer zu programmieren. Da verschiedene Stemmer Suffixe nach unterschiedlichen Regeln entfernen, sind nur die Wortstämme miteinander vergleichbar, welche mit dem selben Stemmer generiert wurden!
Im forlgenden Beispiel werden verschiedene vordefinierte Stemmer aus dem Paket NLTK auf den bereits oben verwendeten Beispielsatz angewendet und die Ergebnisse der gestemmten Tokens in einer Art einfachen Tabelle ausgegeben:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
# Ready-to-use stemmers in nltk porter = nltk.PorterStemmer() lancaster = nltk.LancasterStemmer() snowball = nltk.SnowballStemmer(language='english') # Printing a table to compare the different stemmers header = 'Token\tPorter\tLancas.\tSnowball' print(header + '\n' + len(header) * '-') for token in tokens: print('\t'.join([token, porter.stem(token), lancaster.stem(token), snowball.stem(token)])) Token Porter Lancas. Snowball ----------------------------- This thi thi this is is is is a a a a short short short short example exampl exampl exampl text text text text that that that that needs need nee need to to to to be be be be cleaned clean cle clean . . . . |
Sehr ähnlich den Stemmern arbeiten Lemmatizer: Auch ihre Aufgabe ist es aus verschiedenen Formen eines Wortes die jeweilige Grundform zu bilden. Im Unterschied zu den Stemmern ist das Lemma eines Wortes jedoch klar als dessen Grundform definiert.
|
1 2 3 4 5 |
from nltk.stem import WordNetLemmatizer lemmatizer = WordNetLemmatizer() lemmas = [lemmatizer.lemmatize(t) for t in tokens()] |
Vokabular
Auch das Vokabular, also die Menge aller verschiedenen Worte eines Textes, ist eine informative Kennzahl. Bezieht man die Größe des Vokabulars eines Textes auf seine gesamte Anzahl verwendeter Worte, so lassen sich hiermit Aussagen zu der Diversität des Textes machen.
Außerdem kann das auftreten bestimmter Worte später bei der automatischen Einordnung in Kategorien wichtig werden: Will man beispielsweise Nachrichtenmeldungen nach Themen kategorisieren und in einem Text tritt das Wort „DAX“ auf, so ist es deutlich wahrscheinlicher, dass es sich bei diesem Text um eine Meldung aus dem Finanzbereich handelt, als z. B. um das „Kochrezept des Tages“.
Dies mag auf den ersten Blick trivial erscheinen, allerdings können auch mit einfachen Modellen, wie dem so genannten „Bag-of-Words-Modell“, welches nur die Anzahl des Auftretens von Worten prüft, bereits eine Vielzahl von Informationen aus Texten gewonnen werden.
Das reine Vokabular eines Textes, welcher in der Variable “rawtext” gespeichert ist, kann wie folgt in der Variable “vocab” gespeichert werden. Auf die Ausgabe wurde in diesem Fall verzichtet, da diese im Falle des oben als Beispiel gewählten Satzes den einzelnen Tokens entspricht, da kein Wort öfter als ein Mal vorkommt.
|
1 2 3 4 5 6 |
from nltk import wordpunct_tokenizer from nltk.stem import WordNetLemmatizer lemma = WordNetLemmatizer() vocab = set([WordNetLemmatizer().lemmatize(t) for t in wordpunct_tokenize(text.lower())]) |
Stopwords
Unter Stopwords werden Worte verstanden, welche zwar sehr häufig vorkommen, jedoch nur wenig Information zu einem Text beitragen. Beispiele in der beutschen Sprache sind: der, und, aber, mit, …
Sowohl NLTK als auch cpaCy bringen vorgefertigte Stopwordsets mit.
|
1 2 3 4 5 6 |
from nltk.corpus import stopwords stoplist = stopwords.words('english') stopset = set(stopwords.words('english')) [t for t in tokens if not t in stoplist] ['This', 'short', 'example', 'text', 'needs', 'cleaned', '.'] |
Vorsicht: NLTK besitzt eine Stopwordliste, welche erst in ein Set umgewandelt werden sollte um die lookup-Zeiten kurz zu halten – schließlich muss jedes einzelne Token des Textes auf das vorhanden sein in der Stopworditerable getestet werden!
|
1 2 |
%timeit [w for w in tokens if not w in stopset] # 1.11 ms %timeit [w for w in tokens if not w in stoplist] # 26.6 ms |
POS-Tagging
POS-Tagging steht für „Part of Speech Tagging“ und entspricht ungefähr den Aufgaben, die man noch aus dem Deutschunterricht kennt: „Unterstreiche alle Subjekte rot, alle Objekte blau…“. Wichtig ist diese Art von Tagging insbesondere, wenn man später tatsächlich strukturiert Informationen aus dem Text extrahieren möchte, da man hierfür wissen muss wer oder was als Subjekt mit wem oder was als Objekt interagiert.
Obwohl genau die selben Worte vorkommen, bedeutet der Satz „Die Katze frisst die Maus.“ etwas anderes als „Die Maus frisst die Katze.“, da hier Subjekt und Objekt aufgrund ihrer Reihenfolge vertauscht sind (Stichwort: Subjekt – Prädikat – Objekt ).
Weniger wichtig ist dieser Schritt bei der Kategorisierung von Dokumenten. Insbesondere bei dem bereits oben erwähnten Bag-of-Words-Modell, fließen POS-Tags überhaupt nicht mit ein.
Und weil es so schön einfach ist: Die obigen Schritte mit spaCy
Die obigen Methoden und Arbeitsschritte, welche Texte die in natürlicher Sprache geschrieben sind, allgemein computerzugänglicher und einfacher auswertbar machen, können beliebig genau den eigenen Wünschen angepasst, einzeln mit dem Paket NLTK durchgeführt werden. Dies zumindest einmal gemacht zu haben, erweitert das Verständnis für die funktionsweise einzelnen Schritte und insbesondere deren manchmal etwas versteckten Komplexität. (Wie muss beispielsweise ein Tokenizer funktionieren der den Satz “Schwierig ist z. B. dieser Satz.” korrekt in nur einen Satz aufspaltet, anstatt ihn an jedem Punkt welcher an einem Wortende auftritt in insgesamt vier Sätze aufzuspalten, von denen einer nur aus einem Leerzeichen besteht?) Hier soll nun aber, weil es so schön einfach ist, auch das analoge Vorgehen mit dem Paket spaCy beschrieben werden:
|
1 2 3 4 |
import spacy nlp = spacy.load('en') doc = nlp(rawtext) |
Dieser kurze Codeabschnitt liest den an spaCy übergebenen Rohtext in ein spaCy Doc-Object ein und führt dabei automatisch bereits alle oben beschriebenen sowie noch eine Reihe weitere Operationen aus. So stehen neben dem immer noch vollständig gespeicherten Originaltext, die einzelnen Sätze, Worte, Lemmas, Noun-Chunks, Named Entities, Part-of-Speech-Tags, ect. direkt zur Verfügung und können.über die Methoden des Doc-Objektes erreicht werden. Des weiteren liegen auch verschiedene weitere Objekte wie beispielsweise Vektoren zur Bestimmung von Dokumentenähnlichkeiten bereits fertig vor.
Die Folgende Übersicht soll eine kurze (aber noch lange nicht vollständige) Übersicht über die automatisch von spaCy generierten Objekte und Methoden zur Textanalyse geben:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
# Textabschnitte doc.text # Originaltext sents = doc.sents # Sätze des Dokuments tokens = [token for token in doc] # Tokens/Worte des Dokuments parags = doc.text_with_ws.split('\n\n') # Absätze des Dokuments # Eigenschaften einzelner Tokens [t.lemma_ for t in doc] # Lemmata der einzelnen Tokens [t.tag_ for t in doc] # POS-Tags der einzelnen Tokens # Objekte zur Textanalyse doc.vocab # Vokabular des Dokuments doc.sentiment # Sentiment des Dokuments doc.noun_chunks # NounChunks des Dokuments entities = [ent for ent in doc.ents] # Named Entities (Persons, Locations, Countrys) # Objekte zur Dokumentenklassifikation doc.vector # Vektor doc.tensor # Tensor |
Diese „Vollautomatisierung“ der Vorabschritte zur Textanalyse hat jedoch auch seinen Preis: spaCy geht nicht gerade sparsam mit Ressourcen wie Rechenleistung und Arbeitsspeicher um. Will man einen oder einige Texte untersuchen so ist spaCy oft die einfachste und schnellste Lösung für das Preprocessing. Anders sieht es aber beispielsweise aus, wenn eine bestimmte Analyse wie zum Beispiel die Einteilung in verschiedene Textkategorien auf eine sehr große Anzahl von Texten angewendet werden soll. In diesem Fall, sollte man in Erwägung ziehen auf ressourcenschonendere Alternativen wie zum Beispiel gensim auszuweichen.
Wer beim lesen genau aufgepasst hat, wird festgestellt haben, dass ich im Abschnitt POS-Tagging im Gegensatz zu den anderen Abschnitten auf ein kurzes Codebeispiel verzichtet habe. Dies möchte ich an dieser Stelle nachholen und dabei gleich eine Erweiterung des Pakets spaCy vorstellen: displaCy.
Displacy bietet die Möglichkeit, sich Zusammenhänge und Eigenschaften von Texten wie Named Entities oder eben POS-Tagging graphisch im Browser anzeigen zu lassen.
|
1 2 3 4 5 6 7 8 |
import spacy from spacy import displacy rawtext = 'This is a short example sentence that needs to be cleaned.' nlp = spacy.load('en') doc = nlp(rawtext) displacy.serve(doc, style='dep') |
Nach ausführen des obigen Codes erhält man eine Ausgabe die wie folgt aussieht:
|
1 2 |
Serving on port 5000... Using the 'dep' visualizer |
Nun öffnet man einen Browser und ruft die URL ‘http://127.0.0.1:5000’ auf (Achtung: localhost anstatt der IP funktioniert – warum auch immer – mit displacy nicht). Im Browser sollte nun eine Seite mit einem SVG-Bild geladen werden, welches wie folgt aussieht
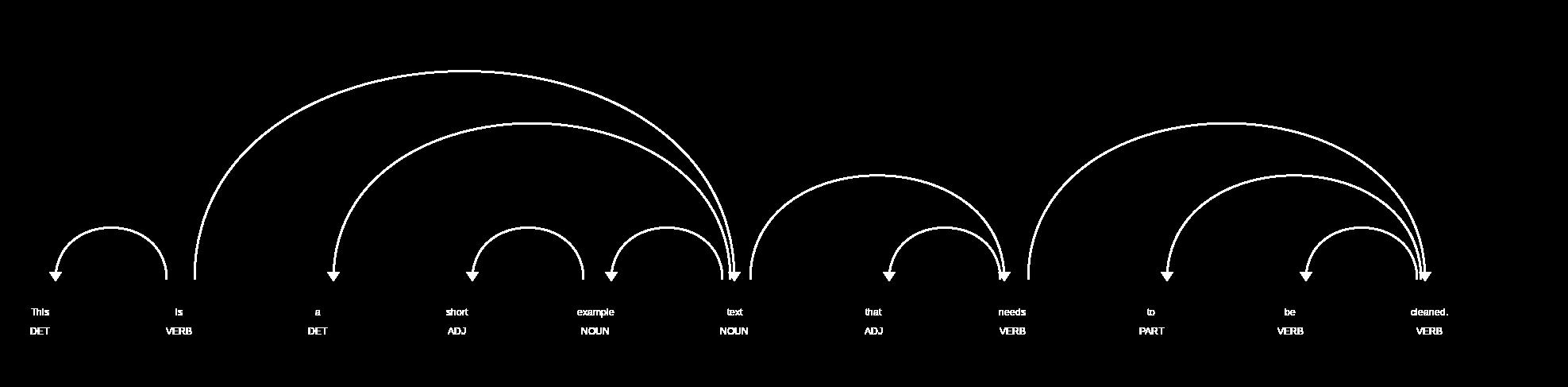
Die Abbildung macht deutlich was POS-Tagging genau ist und warum es von Nutzen sein kann wenn man Informationen aus einem Text extrahieren will. Jedem Word (Token) ist eine Wortart zugeordnet und die Beziehung der einzelnen Worte durch Pfeile dargestellt. Dies ermöglicht es dem Computer zum Beispiel in dem Satzteil “der grüne Apfel”, das Adjektiv “grün” auf das Nomen “Apfel” zu beziehen und diesem somit als Eigenschaft zuzuordnen.
Nachdem dieser Artikel wichtige Schritte des Preprocessing von Texten beschrieben hat, geht es im nächsten Artikel darum was man an Texten eigentlich analysieren kann und welche Analysemöglichkeiten die verschiedenen für Python vorhandenen Module bieten.







Schöne Übersicht!
Klasse, wie man mit Spacy mit einer Zeile Code einen Korpus erstellt. Das geht auch mit NLTK, etwas komplizierter, dafür aber Big Data tauglicher.
An dieser Stelle könnte man noch erwähnen, dass es gut ist mit dem vorverarbeiteten Korpus erste Analysen anzustellen, vor Allem wenn sich der Datensatz erweitern wird. Zum Beispiel durchschnittliche Paragraphenlänge, Anzahl einzigartiger Wörter u.Ä. Damit behält man die Entwicklung des Datensets im Auge und kann bei Unregelmäßigkeiten schnell reagieren.
Hast du eigentlich Erfahrungen gesammelt mit der Prozessierung/Analyse deutscher Sprache und kannst vielleicht über Besonderheiten berichten?
Hallo,
entschuldigung dass ich erst jetzt antworte. Ich habe auch schon deutsche Texte auseinander genommen (auch wenn die meißten Texte nach wie vor in Englisch sind). Im Grunde gelten die selben Regeln aber es gibt einige Unterschiede die einem evtl. nicht direkt in den Sinn kommen:
– ä, ö, ü und ß: Wie man mit diesen Zeichen umgeht muss man je nach Fall unterscheiden (z. B. je nach Textencoding, den verwendeten Dictionaries, ect.). Ich ersetze diese Buchstaben gerne durch ae, oe, ue und ss um keine Probleme mit anderen Encodings zu bekommen (kann z. B. zu Problemen führen wenn das Ergebnis auf verschiedenen Betriebssystemen verwendet werden soll – Windows verwendet vor allem Latin-7 während das www eigentlich vollständig auf UTF-8 setzt). Natürlich müssen dann auch bei einer Suche im Query die entsprechenden Ersetzungen vorgenommen werden, sonst passt es nicht mehr.
– Je nachdem wo man seine Texte herbekommt ist es oft sinnvoll ‘-\n’ (also Bindestrich-Zeilenumbruch) zu ersetzen. Das spielt zwar keine Rolle bei automatisch umgebrochenen Texten wie sie aus HTML raus kommen aber dafür um so mehr wenn man sich die Texte aus PDF’s und Word-Dokumenten extrahiert. Gerade lange Worte die oft sehr spezifische Information über z. B. den Inhalt enthalten fallen sonst oft raus.
– Durch die Verkettung von Substantiven ergeben sich oft recht lange Worte die in keinem Wörterbuch zu finden sind. Ich hatte erwartet dass dies evtl. zu Schwierigkeiten führt, diese sind bisher aber eigentlich weitestgehend ausgeblieben.
Ich hoffe, dass dir das etwas weiterhilft. Im Grunde gelten weitestgehend die selben Regeln wie im Englischen, nur dass es im Durchschnitt etwas schwieriger ist gute fertige Dictionaries, Tagger, ect. zu finden. Für Deutsch sind diese aber sowohl in NLTK als auch in Spacy vorhanden oder können über das Paket direkt installiert werden.
Gruß Chris
Wird teil 3 noch erscheinen?
denke ich auch
Guten Morgen Chris
Wann können wir die Teile 3 und 4 von Dir lesen?
Chris befindet sich gerade auf Weltreise, wir hoffen, er kommt zurück und führt seine Serie fort.