Graphical understanding of dynamic programming and the Bellman equation: taking a typical approach at first
This is the second article of the series My elaborate study notes on reinforcement learning.
*I must admit I could not fully explain how I tried visualizing ideas of Bellman equations in this article. I highly recommend you to also take brief at the second section of the third article. (A comment added on 13/3/2022)
1, Before getting down on business
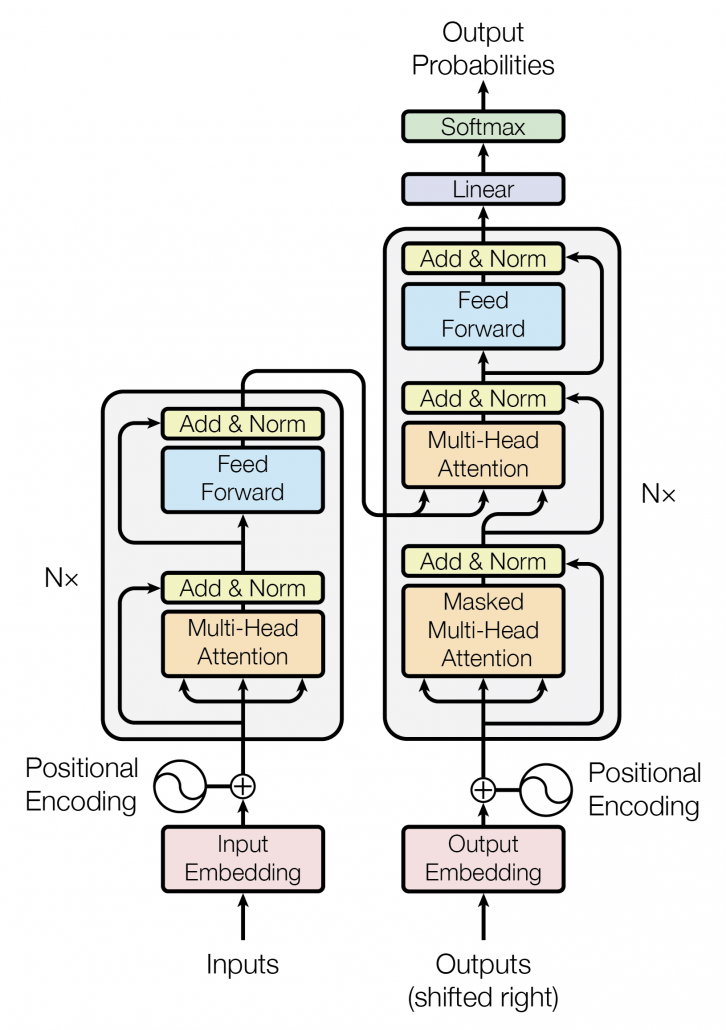
As the title of this article suggests, this article is going to be mainly about the Bellman equation and dynamic programming (DP), which are to be honest very typical and ordinary topics. One typical way of explaining DP in contexts of reinforcement learning (RL) would be explaining the Bellman equation, value iteration, and policy iteration, in this order. If you would like to merely follow pseudocode of them and implement them, to be honest that is not a big deal. However even though I have studied RL only for some weeks, I got a feeling that these algorithms, especially policy iteration are more than just single algorithms. In order not to miss the points of DP, rather than typically explaining value iteration and policy iteration, I would like to take a different approach. Eventually I am going to introduce DP in RL as a combination of the following key terms: the Bellman operator, the fixed point of a policy, policy evaluation, policy improvement, and existence of the optimal policy. But first, in this article I would like to cover basic and typical topics of DP in RL.
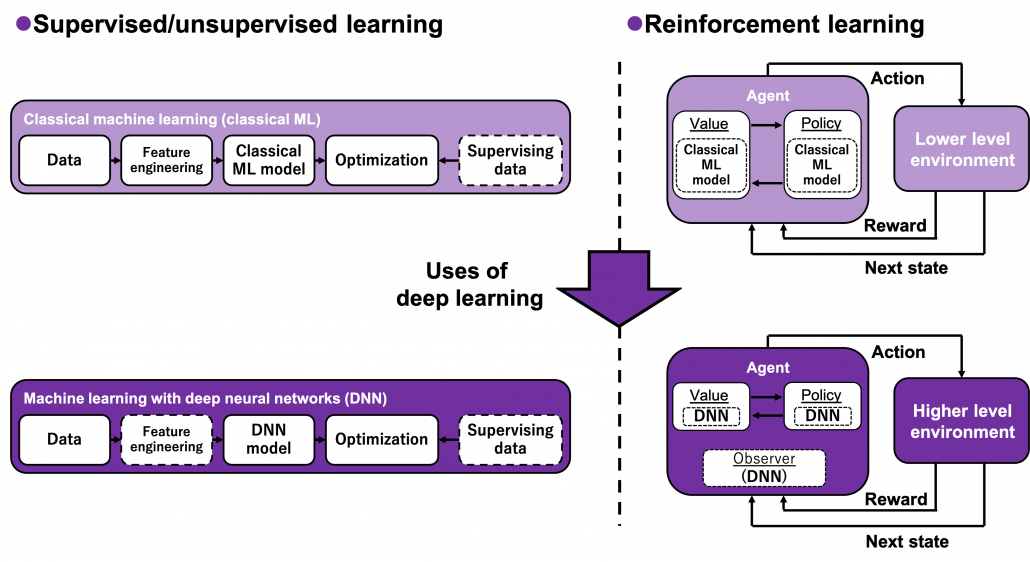
Many machine learning algorithms which use supervised/unsupervised learning more or less share the same ideas. You design a model and a loss function and input samples from data, and you adjust parameters of the model so that the loss function decreases. And you usually use optimization techniques like stochastic gradient descent (SGD) or ones derived from SGD. Actually feature engineering is needed to extract more meaningful information from raw data. Or especially in this third AI boom, the models are getting more and more complex, and I would say the efforts of feature engineering was just replaced by those of designing neural networks. But still, once you have the whole picture of supervised/unsupervised learning, you would soon realize other various algorithms is just a matter of replacing each component of the workflow. However reinforcement learning has been another framework of training machine learning models. Richard E. Bellman’s research on DP in 1950s is said to have laid a foundation for RL. RL also showed great progress thanks to development of deep neural networks (DNN), but still you have to keep it in mind that RL and supervised/unsupervised learning are basically different frameworks. DNN are just introduced in RL frameworks to enable richer expression of each component of RL. And especially when RL is executed in a higher level environment, for example screens of video games or phases of board games, DNN are needed to process each state of the environment. Thus first of all I think it is urgent to see ideas unique to RL in order to effectively learn RL. In the last article I said RL is an algorithm to enable planning by trial and error in an environment, when the model of the environment is not known. And DP is a major way of solving planning problems. But in this article and the next article, I am mainly going to focus on a different aspect of RL: interactions of policies and values.
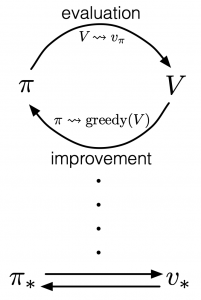 According to a famous Japanese textbook on RL named “Machine Learning Professional Series: Reinforcement Learning,” most study materials on RL lack explanations on mathematical foundations of RL, including the book by Sutton and Barto. That is why many people who have studied machine learning often find it hard to get RL formulations at the beginning. The book also points out that you need to refer to other bulky books on Markov decision process or dynamic programming to really understand the core ideas behind algorithms introduced in RL textbooks. And I got an impression most of study materials on RL get away with the important ideas on DP with only introducing value iteration and policy iteration algorithms. But my opinion is we should pay more attention on policy iteration. And actually important RL algorithms like Q learning, SARSA, or actor critic methods show some analogies to policy iteration. Also the book by Sutton and Barto also briefly mentions “Almost all reinforcement learning methods are well described as GPI (generalized policy iteration). That is, all have identifiable policies and value functions, with the policy always being improved with respect to the value function and the value function always being driven toward the value function for the policy, as suggested by the diagram to the right side.“
According to a famous Japanese textbook on RL named “Machine Learning Professional Series: Reinforcement Learning,” most study materials on RL lack explanations on mathematical foundations of RL, including the book by Sutton and Barto. That is why many people who have studied machine learning often find it hard to get RL formulations at the beginning. The book also points out that you need to refer to other bulky books on Markov decision process or dynamic programming to really understand the core ideas behind algorithms introduced in RL textbooks. And I got an impression most of study materials on RL get away with the important ideas on DP with only introducing value iteration and policy iteration algorithms. But my opinion is we should pay more attention on policy iteration. And actually important RL algorithms like Q learning, SARSA, or actor critic methods show some analogies to policy iteration. Also the book by Sutton and Barto also briefly mentions “Almost all reinforcement learning methods are well described as GPI (generalized policy iteration). That is, all have identifiable policies and value functions, with the policy always being improved with respect to the value function and the value function always being driven toward the value function for the policy, as suggested by the diagram to the right side.“
Even though I arrogantly, as a beginner in this field, emphasized “simplicity” of RL in the last article, in this article I am conversely going to emphasize the “profoundness” of DP over two articles. But I do not want to cover all the exhaustive mathematical derivations for dynamic programming, which would let many readers feel reluctant to study RL. I tried as hard as possible to visualize the ideas in DP in simple and intuitive ways, as far as I could understand. And as the title of this article series shows, this article is also a study note for me. Any corrections or advice would be appreciated via email or comment pots below.
2, Taking a look at what DP is like
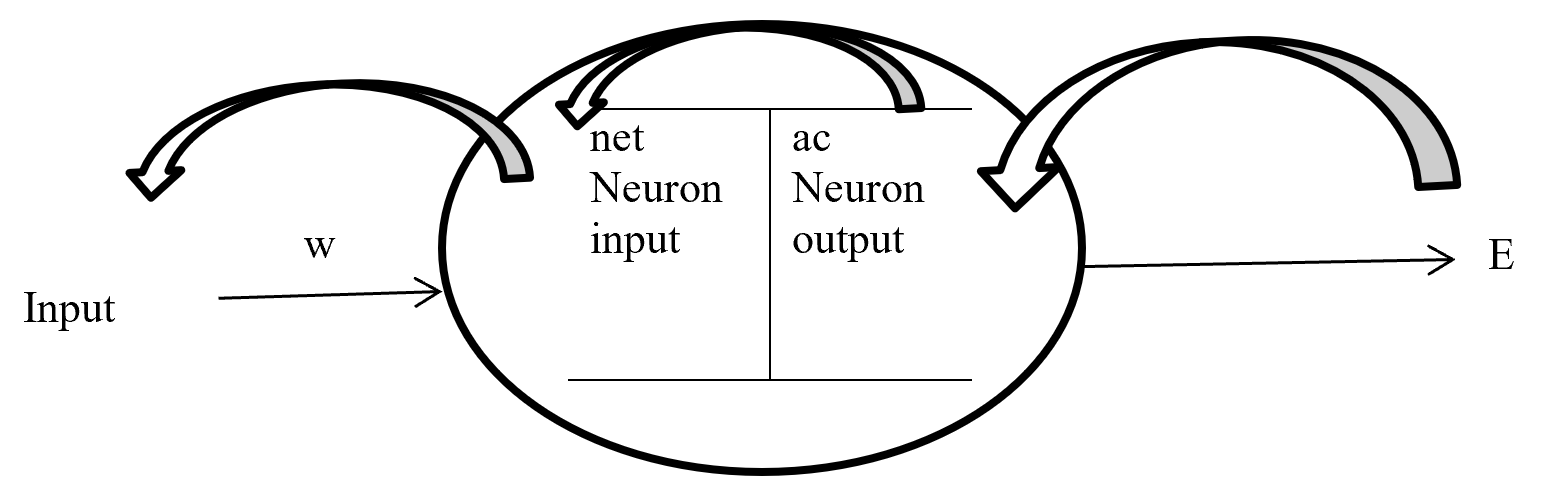
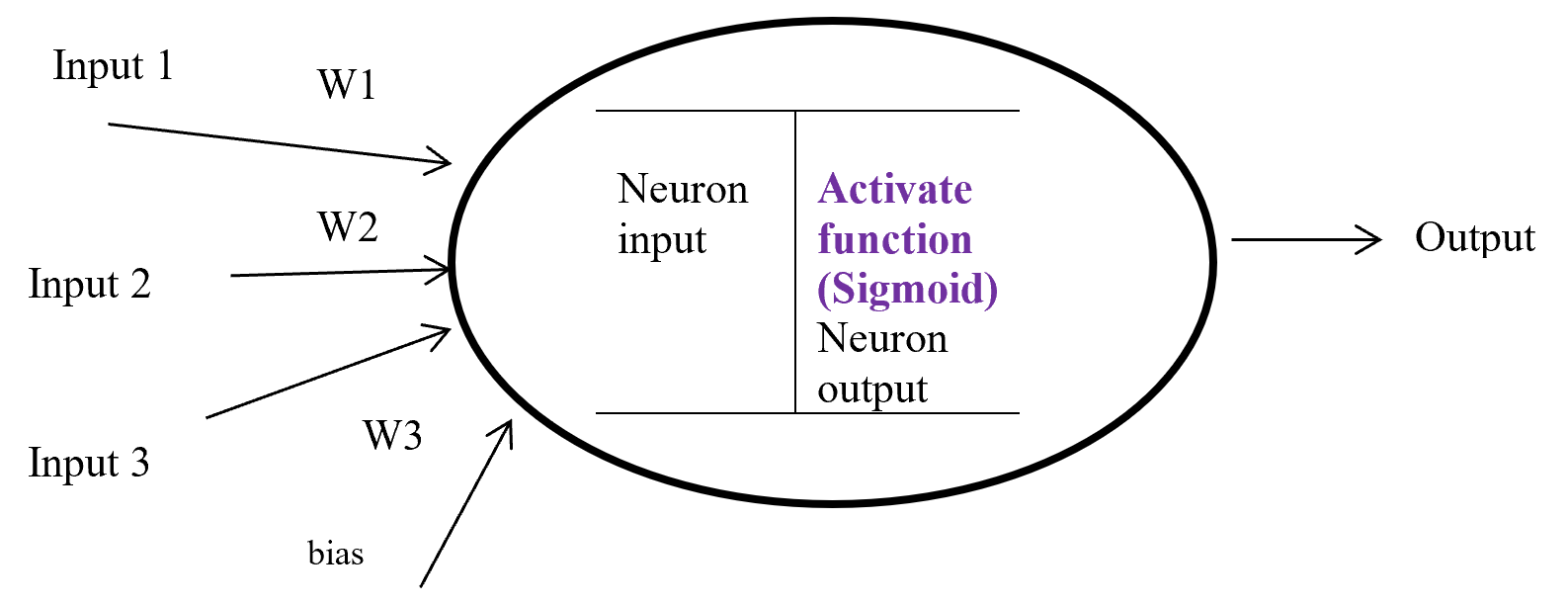
In the last article, I said that planning or RL is a problem of finding an optimal policy  for choosing which actions to take depending on where you are. Also in the last article I displayed flows of blue arrows for navigating a robot as intuitive examples of optimal policies in planning or RL problems. But you cannot directly calculate those policies. Policies have to be evaluated in the long run so that they maximize returns, the sum of upcoming rewards. Then in order to calculate a policy
for choosing which actions to take depending on where you are. Also in the last article I displayed flows of blue arrows for navigating a robot as intuitive examples of optimal policies in planning or RL problems. But you cannot directly calculate those policies. Policies have to be evaluated in the long run so that they maximize returns, the sum of upcoming rewards. Then in order to calculate a policy  , you need to calculate a value functions
, you need to calculate a value functions  . is a function of how good it is to be in a given state
. is a function of how good it is to be in a given state  , under a policy
, under a policy  . That means it is likely you get higher return starting from , when is high. As illustrated in the figure below, values and policies, which are two major elements of RL, are updated interactively until they converge to an optimal value or an optimal policy. The optimal policy and the optimal value are denoted as
. That means it is likely you get higher return starting from , when is high. As illustrated in the figure below, values and policies, which are two major elements of RL, are updated interactively until they converge to an optimal value or an optimal policy. The optimal policy and the optimal value are denoted as  and
and  respectively.
respectively.
Dynamic programming (DP) is a family of algorithms which is effective for calculating the optimal value and the optimal policy when the complete model of the environment is given. Whether in my articles or not, the rest of discussions on RL are more or less based on DP. RL can be viewed as a method of achieving the same effects as DP when the model of the environment is not known. And I would say the effects of imitating DP are often referred to as trial and errors in many simplified explanations on RL. If you have studied some basics of computer science, I am quite sure you have encountered DP problems. With DP, in many problems on textbooks you find optimal paths of a graph from a start to a goal, through which you can maximizes the sum of scores of edges you pass. You might remember you could solve those problems in recursive ways, but I think many people have just learnt very limited cases of DP. For the time being I would like you to forget such DP you might have learned and comprehend it as something you newly start learning in the context of RL.
*As a more advances application of DP, you might have learned string matching. You can calculated how close two strings of characters are with DP using string matching.
The way of calculating and with DP can be roughly classified to two types, policy-based and value-based. Especially in the contexts of DP, the policy-based one is called policy iteration, and the values-based one is called value iteration. The biggest difference between them is, in short, policy iteration updates a policy every times step, but value iteration does it only at the last time step. I said you alternate between updating and , but in fact that is only true of policy iteration. Value iteration updates a value function  . Before formulating these algorithms, I think it will be effective to take a look at how values and policies are actually updated in a very simple case. I would like to introduce a very good tool for visualizing value/policy iteration. You can customize a grid map and place either of “Treasure,” “Danger,” and “Block.” You can choose probability of transition and either of settings, “Policy Iteration” or “Values Iteration.” Let me take an example of conducting DP on a gird map like below. Whichever of “Policy Iteration” or “Values Iteration” you choose, you would get numbers like below. Each number in each cell is the value of each state, and you can see that when you are on states with high values, you are more likely to reach the “treasure” and avoid “dangers.” But I bet this chart does not make any sense if you have not learned RL yet. I prepared some code for visualizing the process of DP on this simulator. The code is available in this link.
. Before formulating these algorithms, I think it will be effective to take a look at how values and policies are actually updated in a very simple case. I would like to introduce a very good tool for visualizing value/policy iteration. You can customize a grid map and place either of “Treasure,” “Danger,” and “Block.” You can choose probability of transition and either of settings, “Policy Iteration” or “Values Iteration.” Let me take an example of conducting DP on a gird map like below. Whichever of “Policy Iteration” or “Values Iteration” you choose, you would get numbers like below. Each number in each cell is the value of each state, and you can see that when you are on states with high values, you are more likely to reach the “treasure” and avoid “dangers.” But I bet this chart does not make any sense if you have not learned RL yet. I prepared some code for visualizing the process of DP on this simulator. The code is available in this link.
*In the book by Sutton and Barto, when RL/DP is discussed at an implementation level, the estimated values of or  can be denoted as an array
can be denoted as an array  or
or  . But I would like you take it easy while reading my articles. I will repeatedly mentions differences of notations when that matters.
. But I would like you take it easy while reading my articles. I will repeatedly mentions differences of notations when that matters.
*Remember that at the beginning of studying RL, only super easy cases are considered, so a is usually just a NumPy array or an Excel sheet.
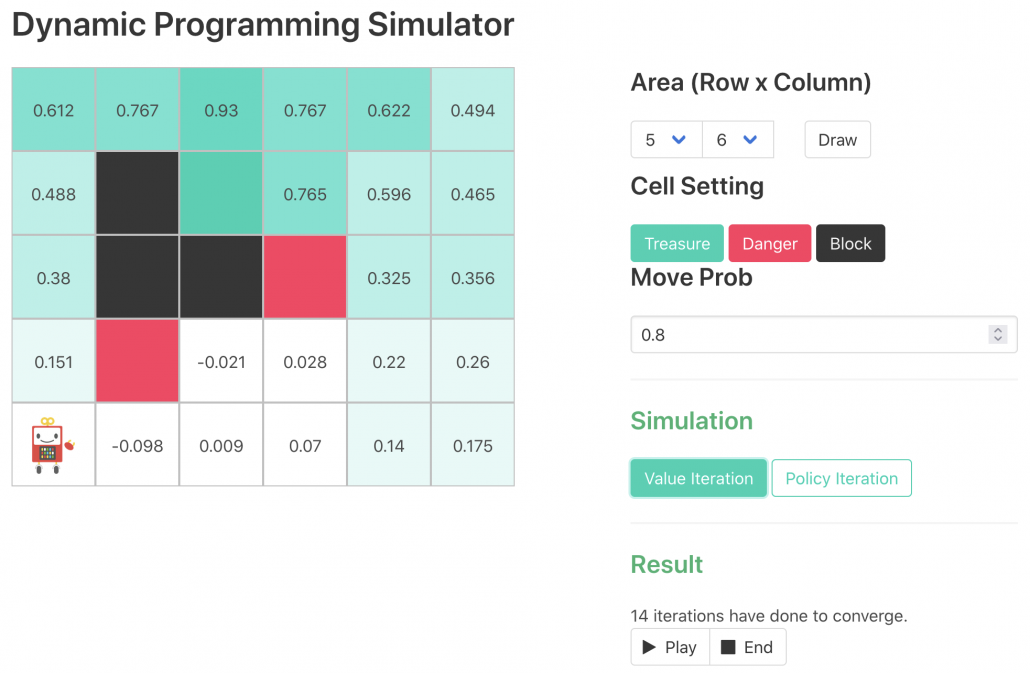
*The chart above might be also misleading since there is something like a robot at the left bottom corner, which might be an agent. But the agent does not actually move around the environment in planning problems because it has a perfect model of the environment in the head.
The visualization I prepared is based on the implementation of the simulator, so they would give the same outputs. When you run policy iteration in the map, the values and polices are updated as follows. The arrow in each cell is the policy in the state. At each time step the arrows is calculated in a greedy way, and each arrow at each state shows the direction in which the agent is likely to get the highest reward. After 3 iterations, the policies and values converge, and with the policies you can navigate yourself to the “Treasure,” avoiding “Dangers.”
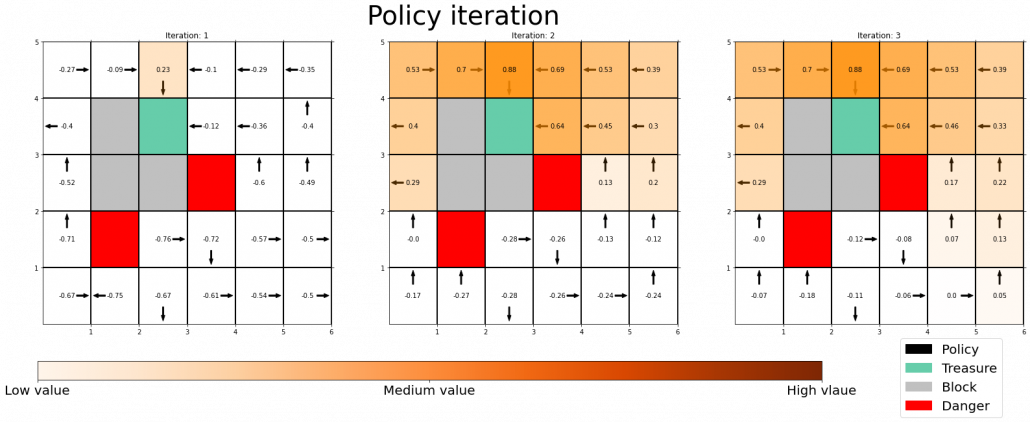
*I am not sure why policies are incorrect at the most left side of the grid map. I might need some modification of code.
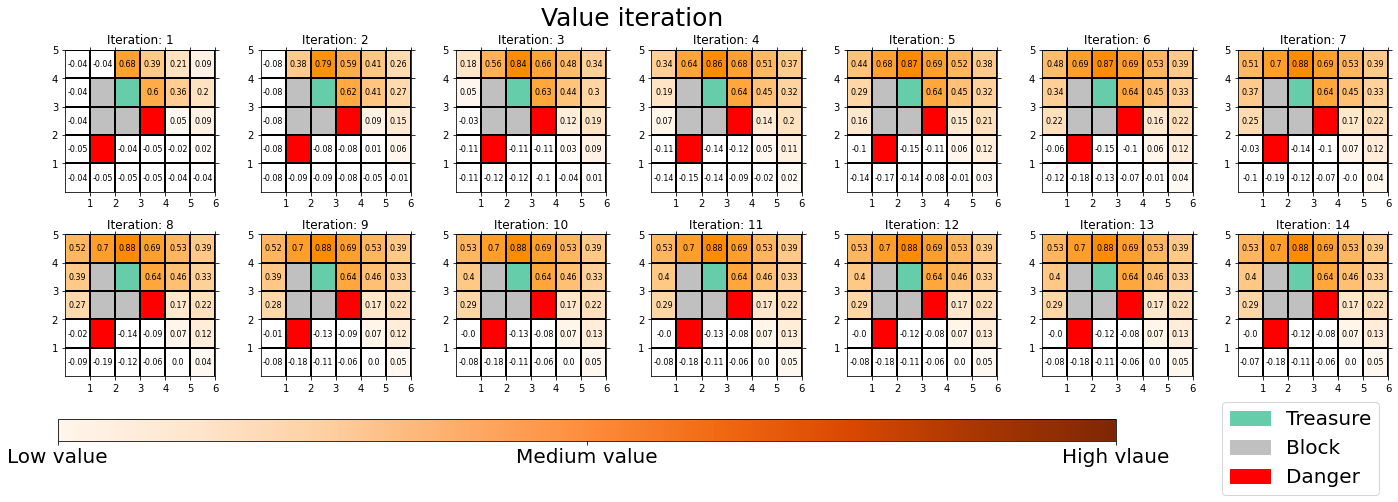
You can also update values without modifying policies as the chart below. In this case only the values of cells are updated. This is value-iteration, and after this iteration converges, if you transit to an adjacent cell with the highest value at each cell, you can also navigate yourself to the “treasure,” avoiding “dangers.”
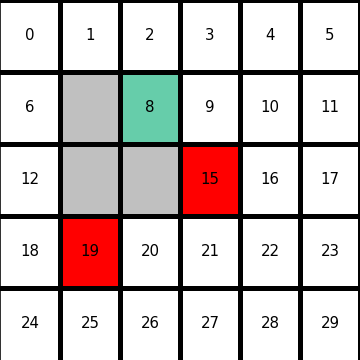
I would like to start formulating DP little by little,based on the notations used in the RL book by Sutton. From now on, I would take an example of the  grid map which I visualized above. In this case each cell is numbered from
grid map which I visualized above. In this case each cell is numbered from  to
to  as the figure below. But the cell 7, 13, 14 are removed from the map. In this case
as the figure below. But the cell 7, 13, 14 are removed from the map. In this case  , and
, and  . When you pass
. When you pass  , you get a reward
, you get a reward  , and when you pass the states
, and when you pass the states  or
or  , you get a reward
, you get a reward  . Also, the agent is encouraged to reach the goal as soon as possible, thus the agent gets a regular reward of
. Also, the agent is encouraged to reach the goal as soon as possible, thus the agent gets a regular reward of  every time step.
every time step.
In the last section, I mentioned that the purpose of RL is to find the optimal policy which maximizes a return, the sum of upcoming reward  . A return is calculated as follows.
. A return is calculated as follows.

In RL a return is estimated in probabilistic ways, that is, an expectation of the return given a state  needs to be considered. And this is the value of the state. Thus the value of a state is calculated as follows.
needs to be considered. And this is the value of the state. Thus the value of a state is calculated as follows.
![\mathbb{E}_{\pi}\bigl[R_{t+1} + R_{t+2} + R_{t+3} + \cdots + R_T | S_t = s \bigr]](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-1446ab2bd566ff9ae22a26979bc864a2_l3.png "Rendered by QuickLaTeX.com")
In order to roughly understand how this expectation is calculated let’s take an example of the grid map above. When the current state of an agent is  , it can take numerous patterns of actions. For example (a)
, it can take numerous patterns of actions. For example (a)  , (b)
, (b)  , (c)
, (c)  . The rewards after each behavior is calculated as follows.
. The rewards after each behavior is calculated as follows.
- If you take a you take the course (a) , you get a reward of
 in total. The probability of taking a course of a) is
in total. The probability of taking a course of a) is 


- Just like the case of (a), the reward after taking the course
 is
is  . The probability of taking the action can be calculated in the same way as
. The probability of taking the action can be calculated in the same way as 
 .
. - The rewards and the probability of the case (c) cannot be calculated because future behaviors of the agent is not confirmed.
Assume that (a) and (b) are the only possible cases starting from , under the policy , then the the value of can be calculated as follows as a probabilistic sum of rewards of each behavior (a) and (b).
![\mathbb{E}_{\pi}\bigl[R_{t+1} + R_{t+2} + R_{t+3} + \cdots + R_T | S_t = s \bigr] = r_a \cdot p_a + r_b \cdot p_b](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-9af1a6e1d05f0e084ca3df7b2cab9ef9_l3.png "Rendered by QuickLaTeX.com")
But obviously this is not how values of states are calculated in general. Starting from a state a state , not only (a) and (b), but also numerous other behaviors of agents can be considered. Or rather, it is almost impossible to consider all the combinations of actions, transition, and next states. In practice it is quite difficult to calculate a sequence of upcoming rewards  ,and it is virtually equal to considering all the possible future cases.A very important formula named the Bellman equation effectively formulate that.
,and it is virtually equal to considering all the possible future cases.A very important formula named the Bellman equation effectively formulate that.
3, The Bellman equation and convergence of value functions
*I must admit I could not fully explain how I tried visualizing ideas of Bellman equations in this article. It might be better to also take brief at the second section of the third article. (A comment added on 3/3/2022)
The Bellman equation enables estimating values of states considering future countless possibilities with the following two ideas.
- Returns are calculated recursively.
- Returns are calculated in probabilistic ways.
First of all, I have to emphasize that a discounted return is usually used rather than a normal return, and a discounted one is defined as below

, where ![\gamma \in (0, 1]](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-914da56af30aaafcc35b558976e8fdca_l3.png "Rendered by QuickLaTeX.com") is a discount rate. (1)As the first point above, the discounted return can be calculated recursively as follows:
is a discount rate. (1)As the first point above, the discounted return can be calculated recursively as follows: 

 . You can postpone calculation of future rewards corresponding to
. You can postpone calculation of future rewards corresponding to  this way. This might sound obvious, but this small trick is crucial for defining defining value functions or making update rules of them. (2)The second point might be confusing to some people, but it is the most important in this section. We took a look at a very simplified case of calculating the expectation in the last section, but let’s see how a value function is defined in the first place.
this way. This might sound obvious, but this small trick is crucial for defining defining value functions or making update rules of them. (2)The second point might be confusing to some people, but it is the most important in this section. We took a look at a very simplified case of calculating the expectation in the last section, but let’s see how a value function is defined in the first place.
![v_{\pi}(s) \doteq \mathbb{E}_{\pi}\bigl[G_t | S_t = s \bigr]](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-4a07b7408b4cebfe6e2558ca8d1573cf_l3.png "Rendered by QuickLaTeX.com")
This equation means that the value of a state is a probabilistic sum of all possible rewards taken in the future following a policy . That is, is an expectation of the return, starting from the state . The definition of a values is written down as follows, and this is what  means.
means.
![v_{\pi} (s)= \sum_{a}{\pi(a|s) \sum_{s', r}{p(s', r|s, a)\bigl[r + \gamma v_{\pi}(s')\bigr]}}](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-9b05fc8f5122733b29e251f8000f7bf2_l3.png "Rendered by QuickLaTeX.com")
This is called Bellman equation, and it is no exaggeration to say this is the foundation of many of upcoming DP or RL ideas. Bellman equation can be also written as ![\sum_{s', r, a}{\pi(a|s) p(s', r|s, a)\bigl[r + \gamma v_{\pi}(s')\bigr]}](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-c9afc3114f14adcf06a184c6656f404b_l3.png "Rendered by QuickLaTeX.com") . It can be comprehended this way: in Bellman equation you calculate a probabilistic sum of
. It can be comprehended this way: in Bellman equation you calculate a probabilistic sum of  , considering all the possible actions of the agent in the time step. is a sum of the values of the next state
, considering all the possible actions of the agent in the time step. is a sum of the values of the next state  and a reward
and a reward  , which you get when you transit to the state from . The probability of getting a reward after moving from the state to , taking an action
, which you get when you transit to the state from . The probability of getting a reward after moving from the state to , taking an action  is
is  . Hence the right side of Bellman equation above means the sum of
. Hence the right side of Bellman equation above means the sum of ![\pi(a|s) p(s', r|s, a)\bigl[r + \gamma v_{\pi}(s')\bigr]](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-c68792d33ebf817bf92b2c3122432011_l3.png "Rendered by QuickLaTeX.com") , over all possible combinations of , , and .
, over all possible combinations of , , and .
*I would not say this equation is obvious, and please let me explain a proof of this equation later.
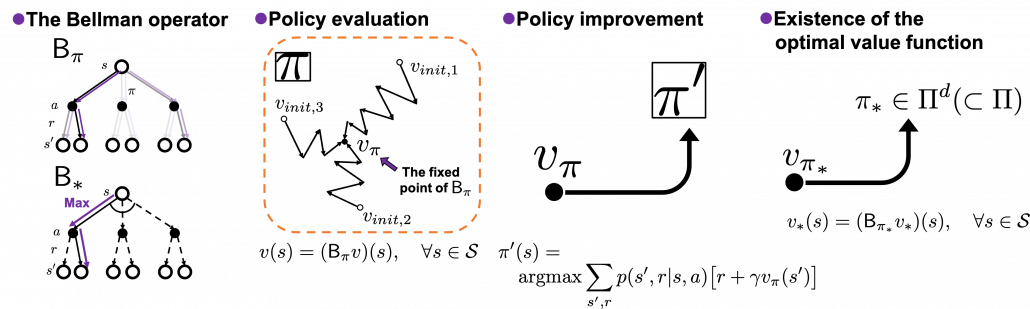
The following figures are based on backup diagrams introduced in the book by Sutton and Barto. As we have just seen, Bellman expectation equation calculates a probabilistic summation of  . In order to calculate the expectation, you have to consider all the combinations of , , and . The backup diagram at the left side below shows the idea as a decision-tree-like graph, and strength of color of each arrow is the probability of taking the path.
. In order to calculate the expectation, you have to consider all the combinations of , , and . The backup diagram at the left side below shows the idea as a decision-tree-like graph, and strength of color of each arrow is the probability of taking the path.
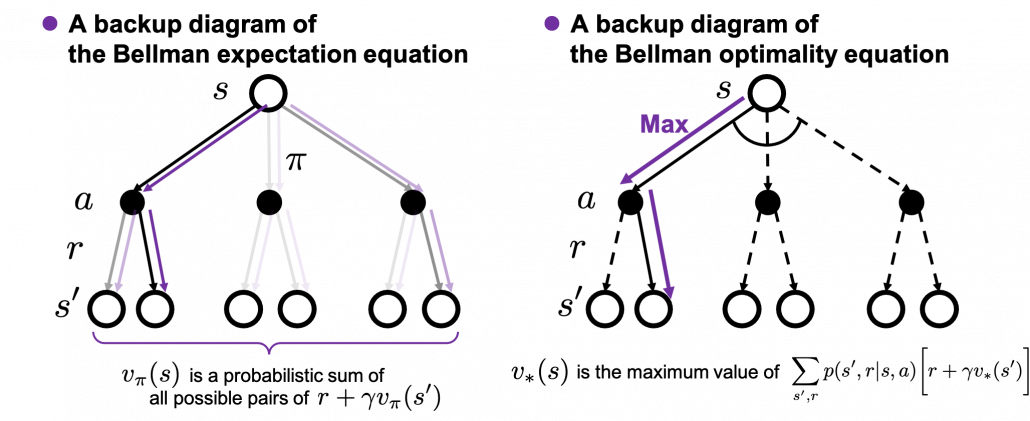
The Bellman equation I have just introduced is called Bellman expectation equation to be exact. Like the backup diagram at the right side, there is another type of Bellman equation where you consider only the most possible path. Bellman optimality equation is defined as follows.
![v_{\ast}(s) \doteq \max_{a} \sum_{s', r}{p(s', r|s, a)\bigl[r + \gamma v_{\ast}(s')\bigr]}](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-86f7734f497416e3b1922ee15d1688dc_l3.png "Rendered by QuickLaTeX.com")
I would like you to pay attention again to the fact that in definitions of Bellman expectation/optimality equations, / is defined recursively with /. You might have thought how to calculate / is the problem in the first place.
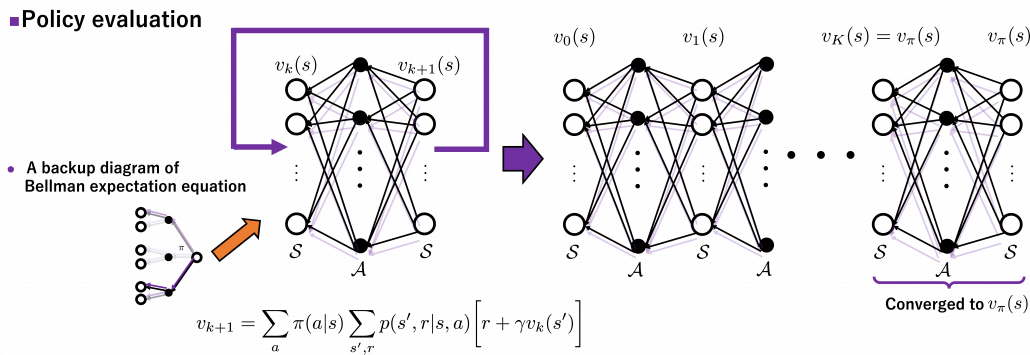
As I implied in the first section of this article, ideas behind how to calculate these and should be discussed more precisely. Especially how to calculate is a well discussed topic in RL, including the cases where data is sampled from an unknown environment model. In this article we are discussing planning problems, where a model an environment is known. In planning problems, that is DP problems where all the probabilities of transition  are known, a major way of calculating is iterative policy evaluation. With iterative policy evaluation a sequence of value functions
are known, a major way of calculating is iterative policy evaluation. With iterative policy evaluation a sequence of value functions  converges to with the following recurrence relation
converges to with the following recurrence relation
![v_{k+1}(s) =\sum_{a}{\pi(a|s)\sum_{s', r}{p(s', r | s, a) [r + \gamma v_k (s')]}}](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-0d6a73bc17d541f77b43a10e128462ce_l3.png "Rendered by QuickLaTeX.com") .
.
Once  converges to , finally the equation of the definition of holds as follows.
converges to , finally the equation of the definition of holds as follows.
![v_{\pi}(s) =\sum_{a}{\pi(a|s)\sum_{s', r}{p(s', r | s, a) [r + \gamma v_{\pi} (s')]}}](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-afdb0cd8be05e7e79fc3306f8ebc3732_l3.png "Rendered by QuickLaTeX.com") .
.
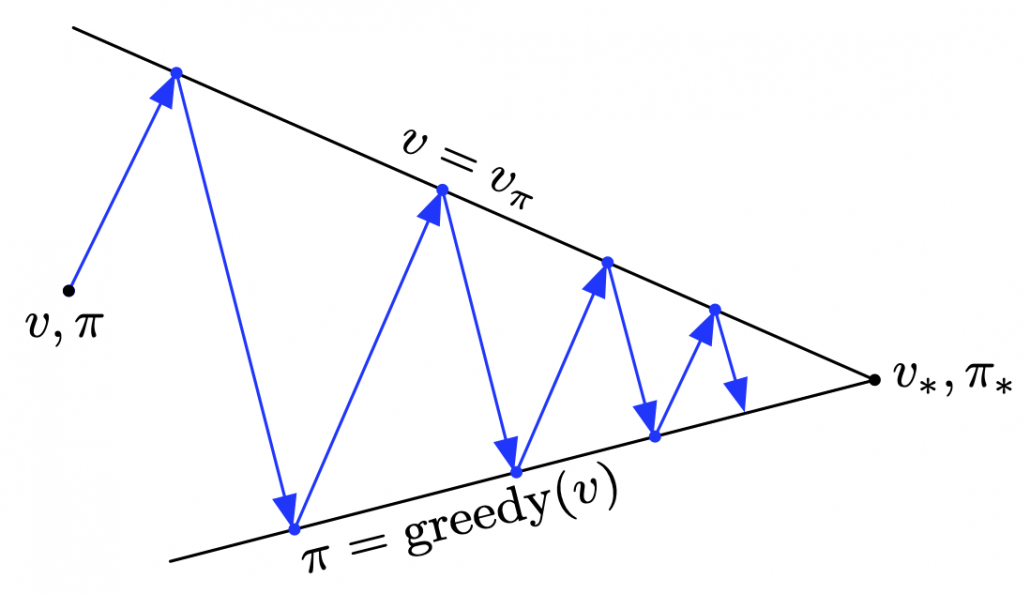
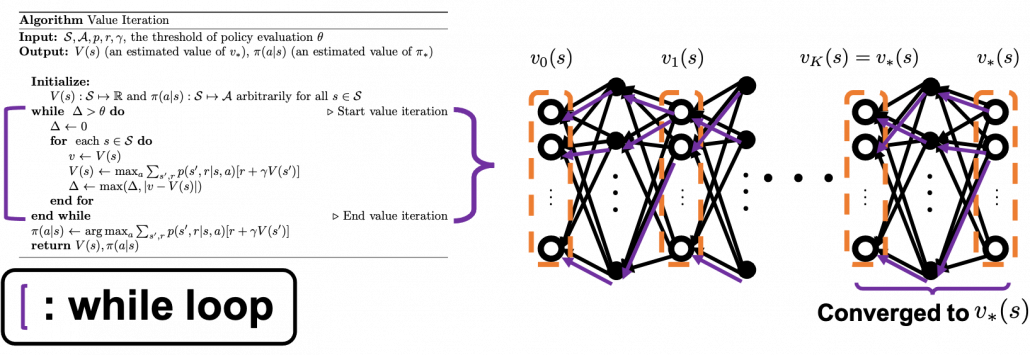
The convergence to is like the graph below. If you already know how to calculate forward propagation of a neural network, this should not be that hard to understand. You just expand recurrent relation of and  from the initial value at
from the initial value at  to the converged state at
to the converged state at  . But you have to be careful abut the directions of the arrows in purple. If you correspond the backup diagrams of the Bellman equation with the graphs below, the purple arrows point to the reverse side to the direction where the graphs extend. This process of converging an arbitrarily initialized
. But you have to be careful abut the directions of the arrows in purple. If you correspond the backup diagrams of the Bellman equation with the graphs below, the purple arrows point to the reverse side to the direction where the graphs extend. This process of converging an arbitrarily initialized  to is called policy evaluation.
to is called policy evaluation.
* are a set of states and actions respectively. Thus
are a set of states and actions respectively. Thus  , the size of
, the size of  is the number of white nodes in each layer, and the number of black nodes.
is the number of white nodes in each layer, and the number of black nodes.
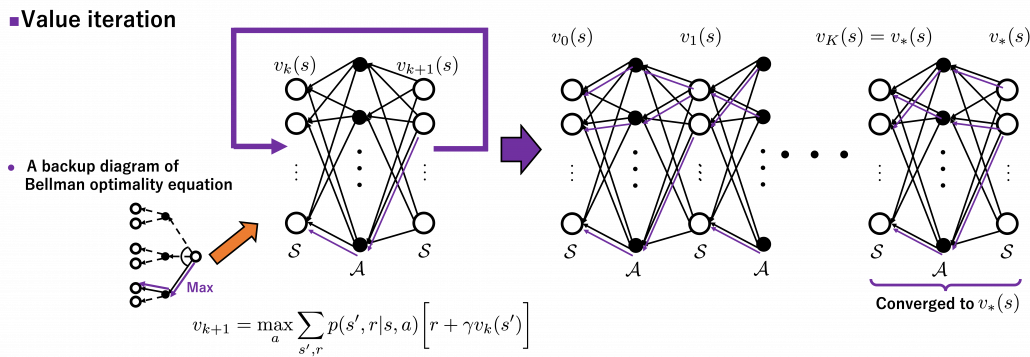
The same is true of the process of calculating an optimal value function . With the following recurrence relation
![v_{k+1}(s) =\max_a\sum_{s', r}{p(s', r | s, a) [r + \gamma v_k (s')]}](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-798ecf9bb29b6fcdecb3282f759d07d2_l3.png "Rendered by QuickLaTeX.com")
converges to an optimal value function . The graph below visualized the idea of convergence.
4, Pseudocode of policy iteration and value iteration
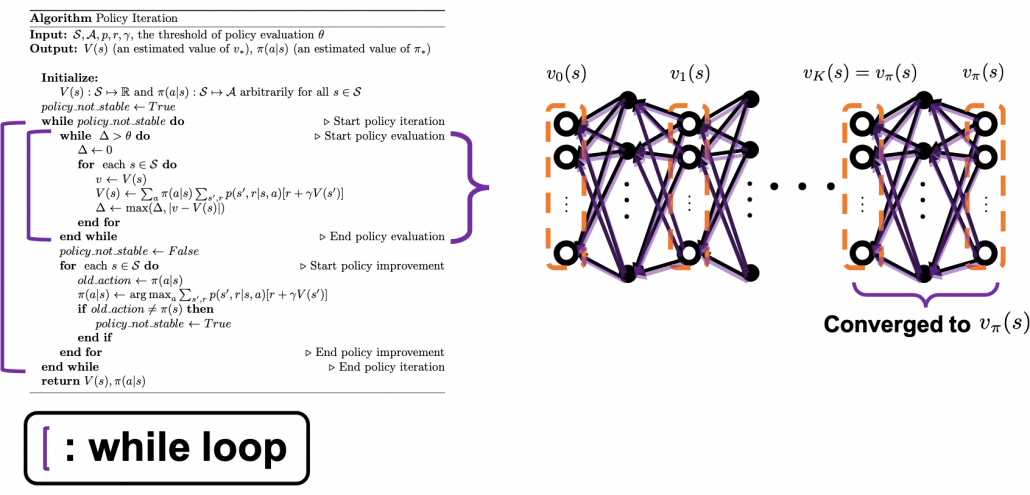
I prepared pseudocode of each algorithm based on the book by Sutton and Barto. These would be one the most typical DP algorithms you would encounter while studying RL, and if you just want to implement RL by yourself, these pseudocode would enough. Or rather these would be preferable to other more general and abstract pseudocode. But I would like to avoid explaining these pseudocode precisely because I think we need to be more conscious about more general ideas behind DP, which I am going to explain in the next article. I will cover only the important points of these pseudocode, and I would like to introduce some implementation of the algorithms in the latter part of next article. I think you should briefly read this section and come back to this section section or other study materials after reading the next article. In case you want to check the algorithms precisely, you could check the pseudocode I made with LaTeX in this link.
The biggest difference of policy iteration and value iteration is the timings of updating a policy. In policy iteration, a value function and are arbitrarily initialized. (1)The first process is policy evaluation. The policy is fixed, and the value function approximately converge to , which is a value function on the policy . This is conducted by the iterative calculation with the reccurence relation introduced in the last section.(2) The second process is policy improvement. Based on the calculated value function , the new policy is updated as below.
![\pi(a|s) \gets\text{argmax}_a {r + \sum_{s', r}{p(s', r|s, a)[r + \gamma V(s')]}}, \quad \forall s\in \mathcal{S}](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-5f4b9305832f16e171d2d5428f5251d8_l3.png "Rendered by QuickLaTeX.com")
The meaning of this update rule of a policy is quite simple: is updated in a greedy way with an action such that ![r + \sum_{s', r}{p(s', r|s, a)[r + \gamma V(s')]}](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-3cb4dfa2cd76474740b41aecacce9d84_l3.png "Rendered by QuickLaTeX.com") is maximized. And when the policy is not updated anymore, the policy has converged to the optimal one. At least I would like you to keep it in mind that a while loop of itrative calculation of is nested in another while loop. The outer loop continues till the policy is not updated anymore.
is maximized. And when the policy is not updated anymore, the policy has converged to the optimal one. At least I would like you to keep it in mind that a while loop of itrative calculation of is nested in another while loop. The outer loop continues till the policy is not updated anymore.
On the other hand in value iteration, there is mainly only one loop of updating , which converge to . And the output policy is the calculated the same way as policy iteration with the estimated optimal value function. According to the book by Sutton and Barto, value iteration can be comprehended this way: the loop of value iteration is truncated with only one iteration, and also policy improvement is done only once at the end.
As I repeated, I think policy iteration is more than just a single algorithm. And relations of values and policies should be discussed carefully rather than just following pseudocode. And whatever RL algorithms you learn, I think more or less you find some similarities to policy iteration. Thus in the next article, I would like to introduce policy iteration in more abstract ways. And I am going to take a rough look at various major RL algorithms with the keywords of “values” and “policies” in the next article.
Appendix
I mentioned the Bellman equation is nothing obvious. In this section, I am going to introduce a mathematical derivation, which I think is the most straightforward. If you are allergic to mathematics, the part blow is not recommendable, but the Bellman equation is the core of RL. I would not say this is difficult, and if you are going to read some texts on RL including some equations, I think mastering the operations I explain below is almost mandatory.
First of all, let’s organize some important points. But please tolerate inaccuracy of mathematical notations here. I am going to follow notations in the book by Sutton and Barto.
- Capital letters usually denote random variables. For example
 . And corresponding small letters are realized values of the random variables. For example
. And corresponding small letters are realized values of the random variables. For example  . (*Please do not think too much about the number of
. (*Please do not think too much about the number of  s on the small letters.)
s on the small letters.) - Conditional probabilities in general are denoted as for example
 . This means the probability of
. This means the probability of  are sampled given that
are sampled given that  is sampled.
is sampled. - In the book by Sutton and Barto, a probilistic funciton
 means a probability of transition, but I am using to denote probabilities in general. Thus
means a probability of transition, but I am using to denote probabilities in general. Thus  shows the probability that, given an agent being in state at time
shows the probability that, given an agent being in state at time  , the agent will do action , AND doing this action will cause the agent to proceed to state at time
, the agent will do action , AND doing this action will cause the agent to proceed to state at time  , and receive reward . is not defined in the book by Barto and Sutton.
, and receive reward . is not defined in the book by Barto and Sutton. - The following equation holds about any conditional probabilities:
 . Thus importantly,
. Thus importantly, 
- When random variables
 are discrete random variables, a conditional expectation of
are discrete random variables, a conditional expectation of  given
given  is calculated as follows:
is calculated as follows: ![\mathbb{E}[X|Y=y] = \sum_{x}{p(x|Y=y)}](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-5bee0d95ebfa141ff0bc520462f4cfa9_l3.png "Rendered by QuickLaTeX.com") .
.
Keeping the points above in mind, let’s get down on business. First, according to definition of a value function on a policy  and linearity of an expectation, the following equations hold.
and linearity of an expectation, the following equations hold.
![v_{\pi}(s) = \mathbb{E} [G_t | S_t =s] = \mathbb{E} [R_{t+1} + \gamma G_{t+1} | S_t =s]](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-fbb4801687a26cb911e5675ac25002bd_l3.png "Rendered by QuickLaTeX.com")
![=\mathbb{E} [R_{t+1} | S_t =s] + \gamma \mathbb{E} [G_{t+1} | S_t =s]](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-f485080bf287c6c9156187adc49b1b4c_l3.png "Rendered by QuickLaTeX.com")
Thus we need to calculate ![\mathbb{E} [R_{t+1} | S_t =s]](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-a585f119409ea2b556c68a0c1378a356_l3.png "Rendered by QuickLaTeX.com") and
and ![\mathbb{E} [G_{t+1} | S_t =s]](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-7f1e5cf67a9196db4f0aace79e81e322_l3.png "Rendered by QuickLaTeX.com") . As I have explained is the sum of
. As I have explained is the sum of  over all the combinations of
over all the combinations of  . And according to one of the points above,
. And according to one of the points above,  . Thus the following equation holds.
. Thus the following equation holds.
![\mathbb{E} [R_{t+1} | S_t =s] = \sum_{s', a, r}{p(s', a, r|s)r} =](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-dd202255b6a36417c897509dc2b69655_l3.png "Rendered by QuickLaTeX.com")
 .
.
Next we have to calculate
![\mathbb{E} [G_{t+1} | S_t =s]](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-6bc115f9e71f2fc3a69465acf6a91464_l3.png "Rendered by QuickLaTeX.com")
![= \mathbb{E} [R_{t + 2} + \gamma R_{t + 3} + \gamma ^2 R_{t + 4} + \cdots | S_t =s]](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-48b09c6d0d7d67902de3191e66a38be2_l3.png "Rendered by QuickLaTeX.com")
![= \mathbb{E} [R_{t + 2} | S_t =s] + \gamma \mathbb{E} [R_{t + 2} | S_t =s] + \gamma ^2\mathbb{E} [ R_{t + 4} | S_t =s] +\cdots](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-5cdf22993b5055312df2e1f797fd3b26_l3.png "Rendered by QuickLaTeX.com") .
.
Let’s first calculate ![\mathbb{E} [R_{t + 2} | S_t =s]](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-469530b7d89bba0e743a0a3b1015ccd3_l3.png "Rendered by QuickLaTeX.com") . Also
. Also ![\mathbb{E} [R_{t + 3} | S_t =s]](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-2bb7f6a67696da895bb485861837f1d2_l3.png "Rendered by QuickLaTeX.com") is a sum of
is a sum of  over all the combinations of (s”, a’, r’, s’, a, r).
over all the combinations of (s”, a’, r’, s’, a, r).
![\mathbb{E}_{\pi} [R_{t + 2} | S_t =s] =\sum_{s'', a', r', s', a, r}{p(s'', a', r', s', a, r|s)r'}](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-616b7769fe43ea42b46e5ca3f604ccee_l3.png "Rendered by QuickLaTeX.com")


I would like you to remember that in Markov decision process the next state  and the reward only depends on the current state
and the reward only depends on the current state  and the action
and the action  at the time step.
at the time step.
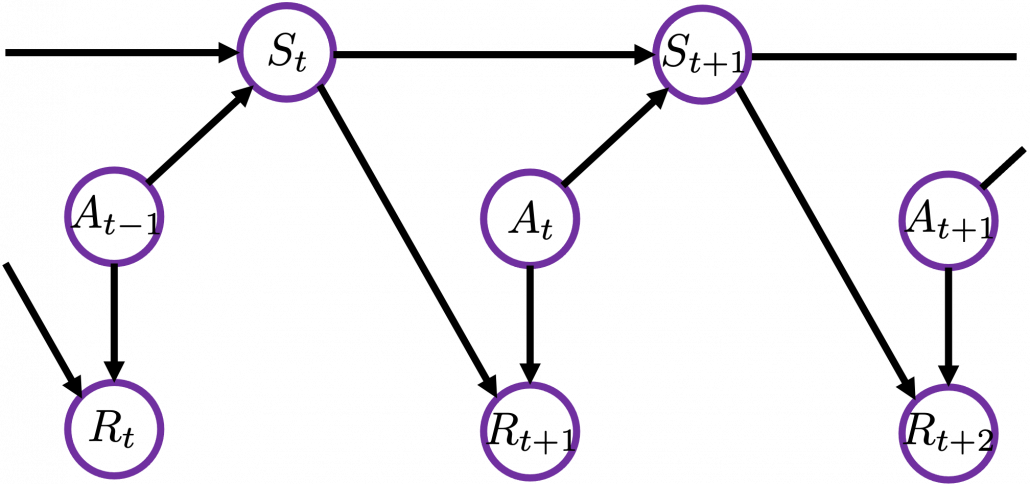
Thus in variables  , only have the following variables
, only have the following variables  . And again
. And again  . Thus the following equations hold.
. Thus the following equations hold.
![\mathbb{E}_{\pi} [R_{t + 2} | S_t =s]=\sum_{ s', a, r}{p(s', a, r|s)} \sum_{s'', a', r'}{p(s'', a', r'| s', a, r', s)r'}](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-1e4e2cb83f6dd183dce4e2a51990bbc2_l3.png "Rendered by QuickLaTeX.com")

![= \sum_{ s', a, r}{p(s', r|a, s)\pi(a|s)} \mathbb{E}_{\pi} [R_{t+2} | s']](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-664e5538f363a0ef817dd5f48fbbae6a_l3.png "Rendered by QuickLaTeX.com") .
.
![\mathbb{E}_{\pi} [R_{t + 3} | S_t =s]](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-64827bc08e99d614dc3838a85798c7d8_l3.png "Rendered by QuickLaTeX.com") can be calculated the same way.
can be calculated the same way.
![\mathbb{E}_{\pi}[R_{t + 3} | S_t =s] =\sum_{s''', a'', r'', s'', a', r', s', a, r}{p(s''', a'', r'', s'', a', r', s', a, r|s)r''}](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-421e1a0b214d777abba77463656339f8_l3.png "Rendered by QuickLaTeX.com")



![=\sum_{ s', a, r}{ p(s', r | s, a)p(a|s)} \mathbb{E}_{\pi} [R_{t+3} | s']](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-6e0ec2657d6aca22c01de6f4b10a136a_l3.png "Rendered by QuickLaTeX.com") .
.
The same is true of calculating ![\mathbb{E}_{\pi} [R_{t + 4} | S_t =s]](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-5370726e4df48fa2beda19166dc02906_l3.png "Rendered by QuickLaTeX.com") ,
, ![\mathbb{E}_{\pi} [R_{t + 5} | S_t =s]\dots](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-c60185b7e16dd3c9d80041a6d63e4901_l3.png "Rendered by QuickLaTeX.com") . Thus
. Thus
![v_{\pi}(s) =\mathbb{E} [R_{t+1} | S_t =s] + \gamma \mathbb{E} [G_{t+1} | S_t =s]](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-e78cd95d37820f82e6dce3d5c5943815_l3.png "Rendered by QuickLaTeX.com")
= ![+ \mathbb{E} [R_{t + 2} | S_t =s] + \gamma \mathbb{E} [R_{t + 3} | S_t =s] + \gamma ^2\mathbb{E} [ R_{t + 4} | S_t =s] +\cdots](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-9d5855daab70bbee7810386c6fc52bc1_l3.png "Rendered by QuickLaTeX.com")

![+\sum_{ s', a, r}{p(s', r|a, s)\pi(a|s)} \mathbb{E}_{\pi} [R_{t+2} |S_{t+1}= s']](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-028766cd22f5479faa5a4f1ea907da6b_l3.png "Rendered by QuickLaTeX.com")
![+\gamma \sum_{ s', a, r}{ p(s', r | s, a)p(a|s)} \mathbb{E}_{\pi} [R_{t+3} |S_{t+1} = s']](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-6679a24522d25f8e36d5caf2a7a8ce06_l3.png "Rendered by QuickLaTeX.com")
![+\gamma^2 \sum_{ s', a, r}{ p(s', r | s, a)p(a|s)} \mathbb{E}_{\pi} [ R_{t+4}|S_{t+1} = s'] + \cdots](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-cb1b0cd6d79e351b146b9b5766c7f5e2_l3.png "Rendered by QuickLaTeX.com")
![=\sum_{ s', a, r}{ p(s', r | s, a)p(a|s)} [r + \mathbb{E}_{\pi} [\gamma R_{t+2}+ \gamma R_{t+3}+\gamma^2R_{t+4} + \cdots |S_{t+1} = s'] ]](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-641a5ebcd67a76dc3f5367ee009e9b14_l3.png "Rendered by QuickLaTeX.com")
![=\sum_{ s', a, r}{ p(s', r | s, a)p(a|s)} [r + \mathbb{E}_{\pi} [G_{t+1} |S_{t+1} = s'] ]](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-133e0a40144cd6b8d9d24eb9c62541a3_l3.png "Rendered by QuickLaTeX.com")
![=\sum_{ s', a, r}{ p(s', r | s, a)p(a|s)} [r + v_{\pi}(s') ]](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-942d98bd0c9d7cc3ed2939137e05df53_l3.png "Rendered by QuickLaTeX.com")
 , where
, where 


 .
. .
. is a real symmetric matrix, there exist a rotation matrix
is a real symmetric matrix, there exist a rotation matrix  such that
such that  , where
, where  and
and  .
.  are eigenvectors corresponding to
are eigenvectors corresponding to  respectively.
respectively. .
. are positive semidefinite and real symmetric, which means you can always diagonalize
are positive semidefinite and real symmetric, which means you can always diagonalize  , based on
, based on  , such that
, such that 

 , where
, where  . I also explained that PCA is a case where
. I also explained that PCA is a case where  . Assume that you have got an orthonormal rotation matrix
. Assume that you have got an orthonormal rotation matrix  which diagonalizes
which diagonalizes  which are in red in the figure below. Projecting a point
which are in red in the figure below. Projecting a point  on the new orthonormal basis is simple: you just have to multiply
on the new orthonormal basis is simple: you just have to multiply  with
with  . Let
. Let  be
be  , and then
, and then  . You can see
. You can see  are
are  respectively, and the left side of the figure below shows the idea. When you replace the orginal orthonormal basis
respectively, and the left side of the figure below shows the idea. When you replace the orginal orthonormal basis  with
with  to
to  by a rotation matrix
by a rotation matrix 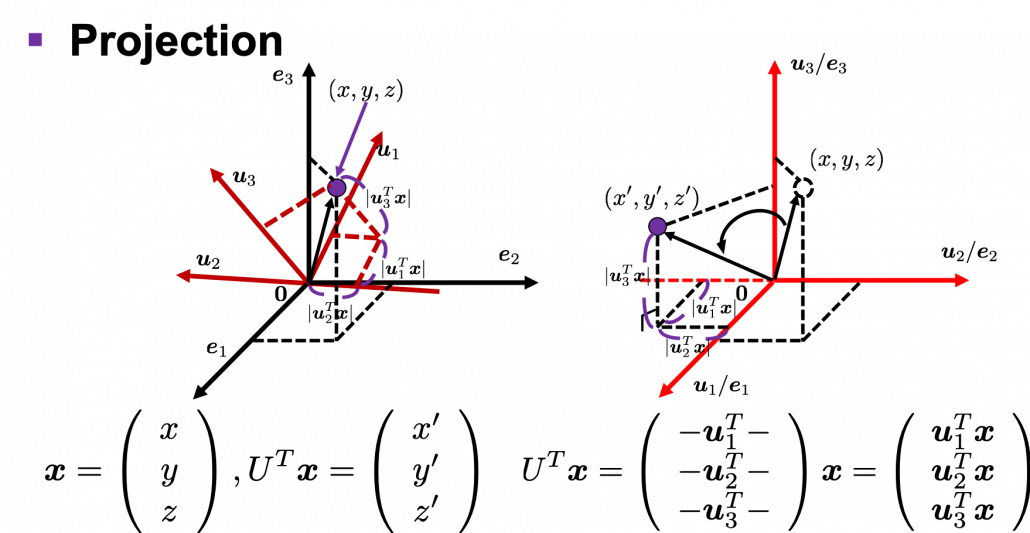
 , with one corner of the cube located at the origin point of those axes. The purple dot denotes the corner of the cube directly opposite the origin corner. The cube is rotated in three dimensions, with the origin corner staying fixed in place. After the rotation with a pivot at the origin, the edges of the cube are now aligned with a new set of orthogonal axes
, with one corner of the cube located at the origin point of those axes. The purple dot denotes the corner of the cube directly opposite the origin corner. The cube is rotated in three dimensions, with the origin corner staying fixed in place. After the rotation with a pivot at the origin, the edges of the cube are now aligned with a new set of orthogonal axes  , shown in red. You might understand that more clearly with an equation:
, shown in red. You might understand that more clearly with an equation: 
 . In short this rotation means you keep relative position of
. In short this rotation means you keep relative position of 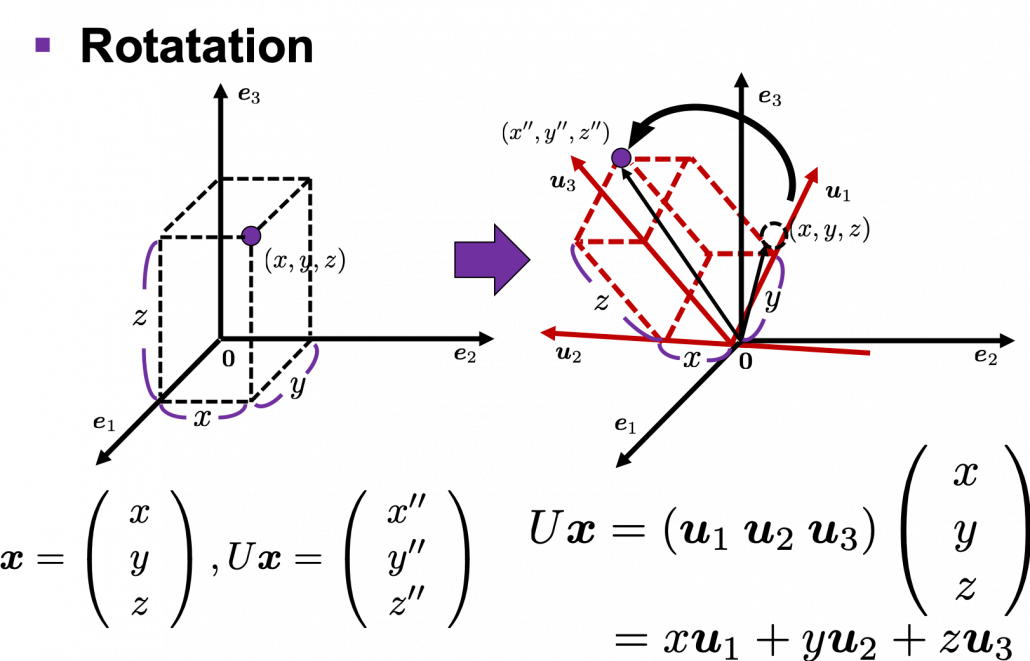
 is an orthonormal matrix and a vector
is an orthonormal matrix and a vector  , you can project
, you can project  or rotate it to
or rotate it to  , where
, where  and
and  . In other words
. In other words  , which means you can rotate back
, which means you can rotate back  to the original point
to the original point  , where
, where  is a real symmetric matrix. The distribution of
is a real symmetric matrix. The distribution of  is quadratic curves whose center point covers the origin, and it is known that you can express this distribution in a much simpler way using eigenvectors. When you project this function on eigenvectors of
is quadratic curves whose center point covers the origin, and it is known that you can express this distribution in a much simpler way using eigenvectors. When you project this function on eigenvectors of  for
for 



 . You can always diagonalize real symmetric matrices, so the formula implies that the shapes of quadratic curves largely depend on eigenvectors. We are going to see this in detail in the next section.
. You can always diagonalize real symmetric matrices, so the formula implies that the shapes of quadratic curves largely depend on eigenvectors. We are going to see this in detail in the next section. denotes an inner product of
denotes an inner product of  .
.
 , and in the case above
, and in the case above  was
was  , and you needed to flip one axis to make the determinant
, and you needed to flip one axis to make the determinant  . In the example in the figure below, you can match the basis. This also can be generalized to higher dimensions, but that is also beyond the scope of this article series. If you are really interested, you should prepare some coffee and snacks and textbooks on linear algebra, and some weekends.
. In the example in the figure below, you can match the basis. This also can be generalized to higher dimensions, but that is also beyond the scope of this article series. If you are really interested, you should prepare some coffee and snacks and textbooks on linear algebra, and some weekends.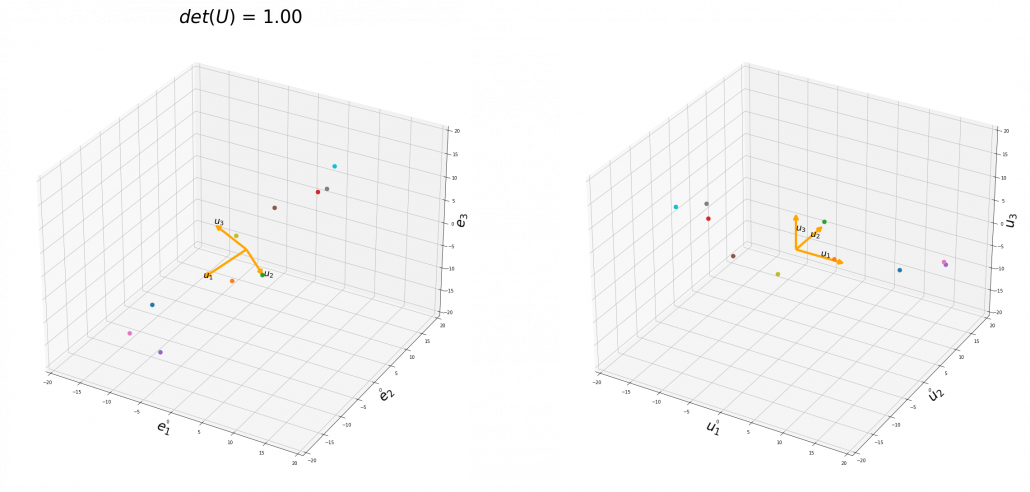
 , you can rotate the original ellipsoid so that it fits the data well.
, you can rotate the original ellipsoid so that it fits the data well.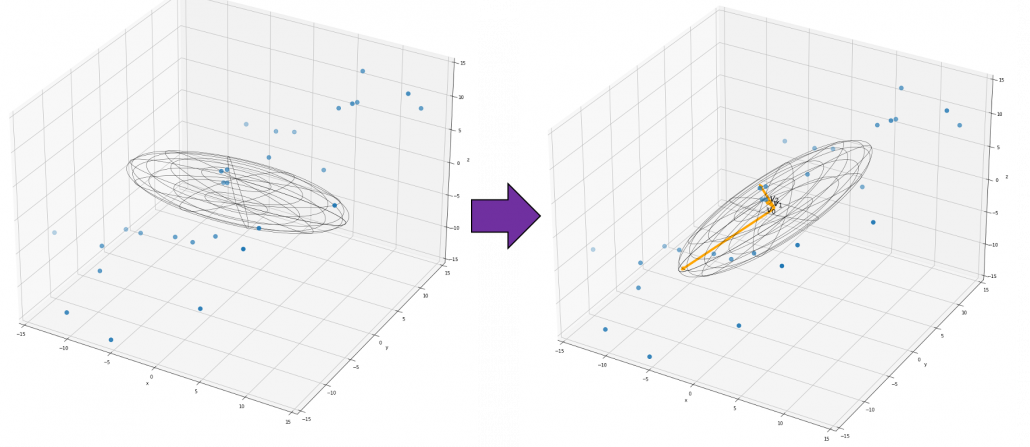
 , where
, where  , not
, not  .
. , where at least one of
, where at least one of  is not
is not  , then the quadratic curves can be simply denoted with a
, then the quadratic curves can be simply denoted with a  matrix
matrix  as follows:
as follows:  ,
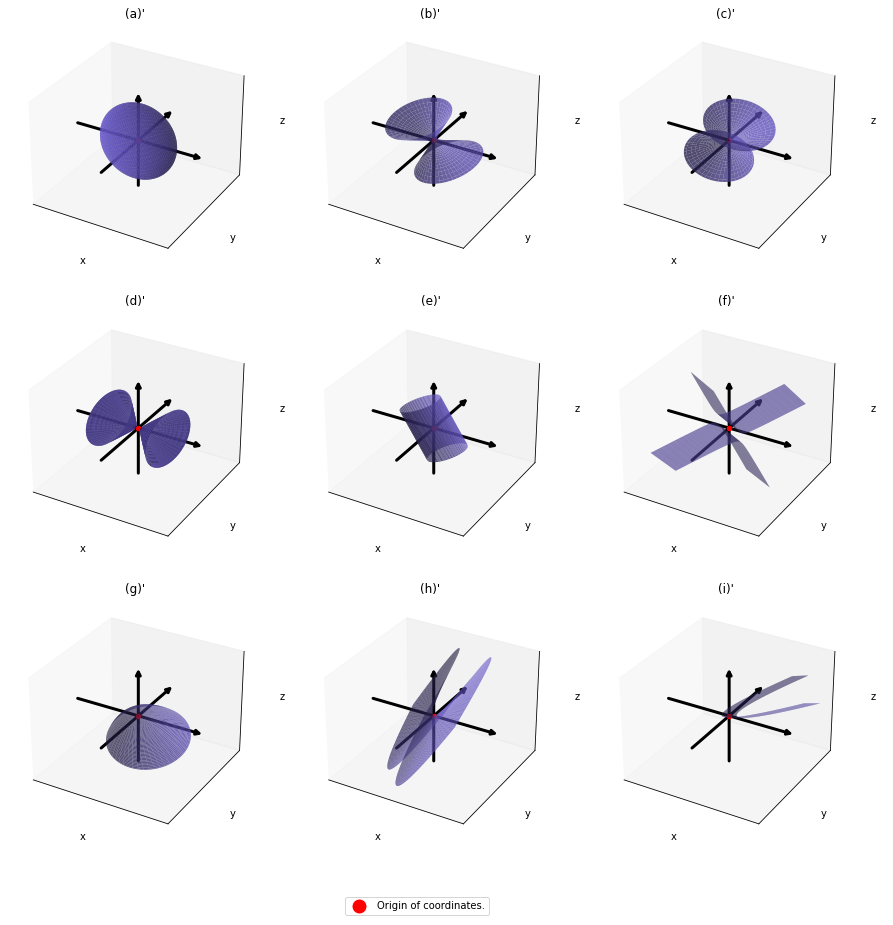
,  . General quadratic curves are roughly classified into the 9 types below.
. General quadratic curves are roughly classified into the 9 types below.
 .
.
 symmetric matrix
symmetric matrix  , there exist orthogonal/orthonormal matrices
, there exist orthogonal/orthonormal matrices  , where
, where 
 . After you apply rotation by
. After you apply rotation by 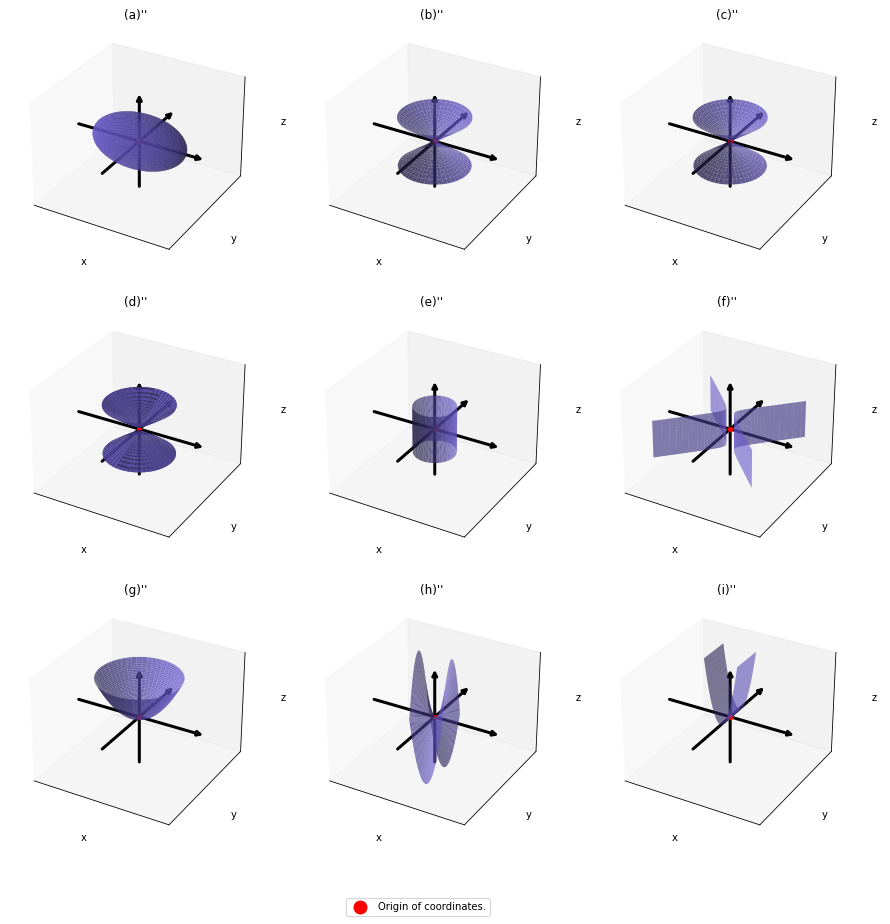




 .
. , those points
, those points  . That means the rotation of the original quadratic curve with
. That means the rotation of the original quadratic curve with  . Also it is known that when
. Also it is known that when  , with proper translations and rotations, the quadratic curve
, with proper translations and rotations, the quadratic curve  in a very simple way by projecting
in a very simple way by projecting  in two ways. One is a normal “functions”
in two ways. One is a normal “functions”  , and the others are “curves”
, and the others are “curves”  . “Functions” get an input
. “Functions” get an input  or
or  . However if you replace
. However if you replace  , you can interpret the “curves” as “functions” which are denoted as
, you can interpret the “curves” as “functions” which are denoted as  . This might sounds too obvious to you, and my point is you can visualize how values of “functions” change only when the inputs are 2 dimensional.
. This might sounds too obvious to you, and my point is you can visualize how values of “functions” change only when the inputs are 2 dimensional. real matrices
real matrices  have two eigenvalues
have two eigenvalues  , the distribution of quadratic curves can be roughly classified to the following three types.
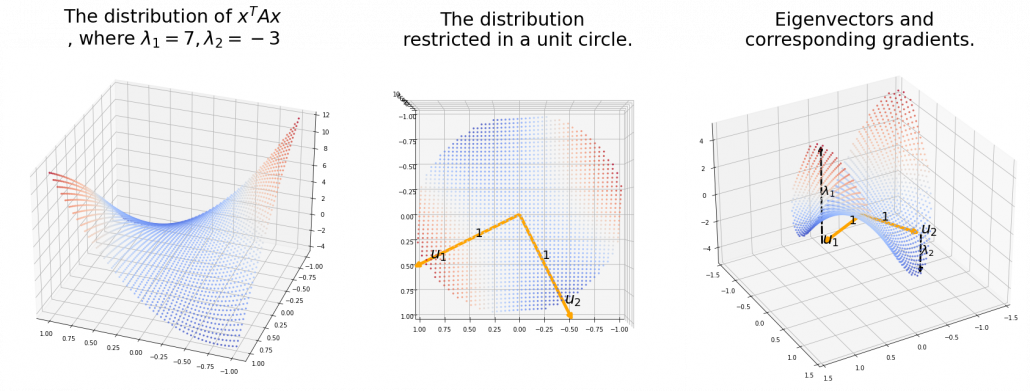
, the distribution of quadratic curves can be roughly classified to the following three types. and
and  are positive or negative.
are positive or negative. , and thier curves look like the three graphs below.
, and thier curves look like the three graphs below.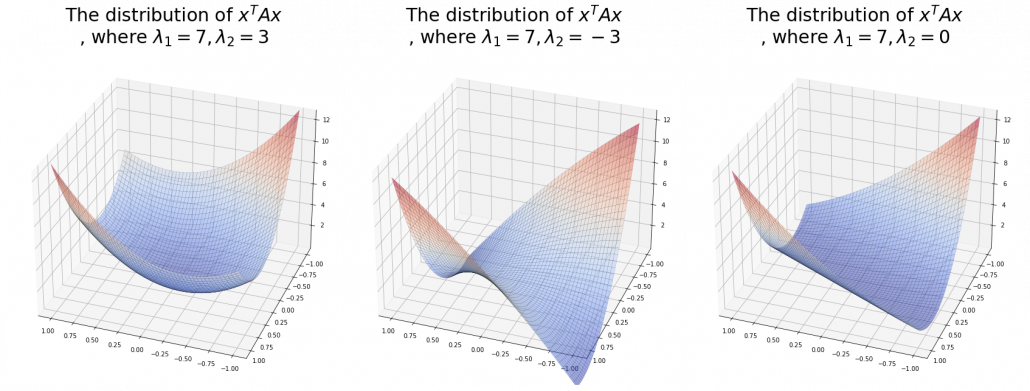
 ,
,  is the gradient of the direction. You can see that more clearly when you restrict the distribution of
is the gradient of the direction. You can see that more clearly when you restrict the distribution of  , which is classified to (g), the distribution looks like the left side, and if you restrict the distribution in the unit circle, the distribution looks like a bowl like the middle and the right side. When you move in the direction of
, which is classified to (g), the distribution looks like the left side, and if you restrict the distribution in the unit circle, the distribution looks like a bowl like the middle and the right side. When you move in the direction of  , you can climb the bowl as as high as
, you can climb the bowl as as high as  as high as
as high as 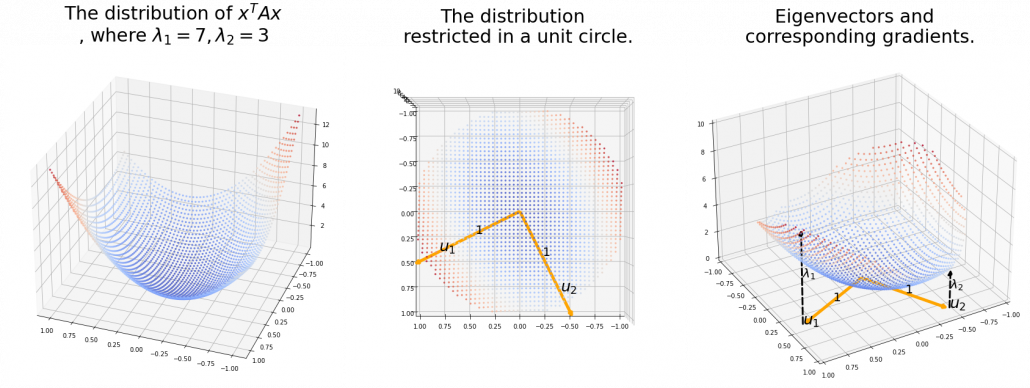
 . Hence, if you project
. Hence, if you project  , quadratic curves formed by a covariance matrix
, quadratic curves formed by a covariance matrix 
 . This shows that you can re-weight
. This shows that you can re-weight  , the coordinates of data projected projected on eigenvectors of
, the coordinates of data projected projected on eigenvectors of  , as I have visualized in the case of (g) type curve in the figure above.
, as I have visualized in the case of (g) type curve in the figure above.

 .
. the resulting cross section does not fit the original data well because the equation of the cross section is
the resulting cross section does not fit the original data well because the equation of the cross section is  The figure below is an example of slicing the same
The figure below is an example of slicing the same  , and the resulting cross section.
, and the resulting cross section.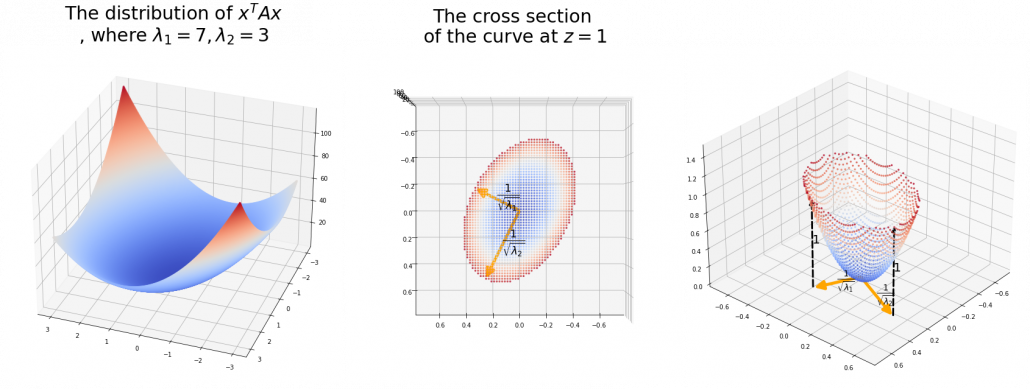
 is the radius of the ellipsoid corresponding to
is the radius of the ellipsoid corresponding to  , where
, where  .
.  means you multiply each eigenvalue to each element of
means you multiply each eigenvalue to each element of 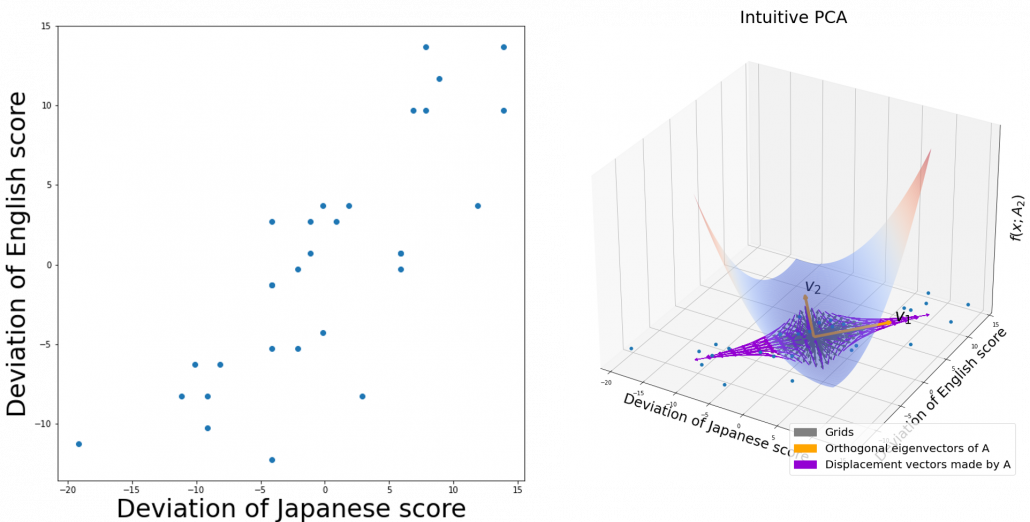
 , the ellipsoid which fits the distribution the best is
, the ellipsoid which fits the distribution the best is  . You might have seen the part
. You might have seen the part 
 somewhere else. It is the exponent of general Gaussian distributions:
somewhere else. It is the exponent of general Gaussian distributions: 
 . It is known that the eigenvalues of
. It is known that the eigenvalues of  are
are  , and eigenvectors corresponding to each eigenvalue are also
, and eigenvectors corresponding to each eigenvalue are also  respectively. Hence just as well as what we have seen, if you project
respectively. Hence just as well as what we have seen, if you project  on each eigenvector of
on each eigenvector of  be
be  be
be  , where
, where  . Just as we have seen,
. Just as we have seen, 



 . Hence
. Hence 
 .
.

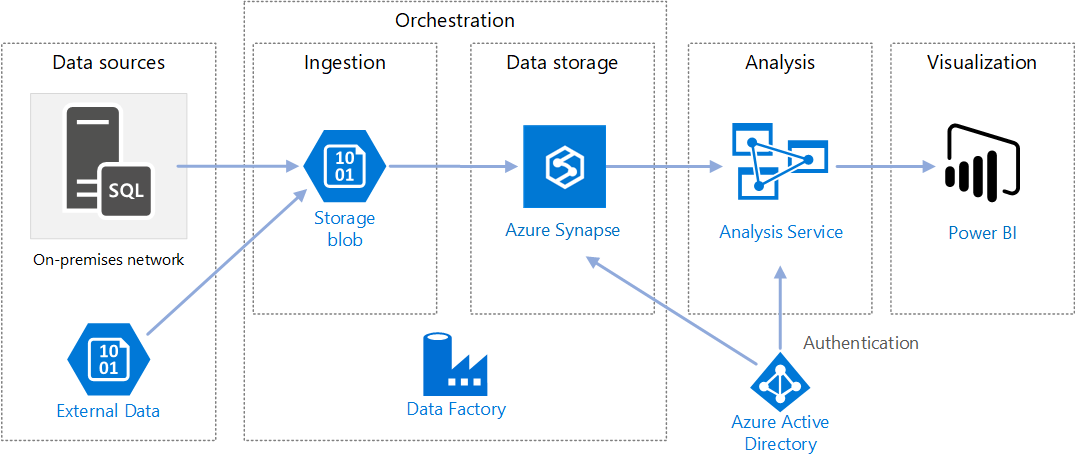 https://docs.microsoft.com/en-us/azure/architecture/reference-architectures/data/enterprise-bi-adfQuelle:
https://docs.microsoft.com/en-us/azure/architecture/reference-architectures/data/enterprise-bi-adfQuelle: 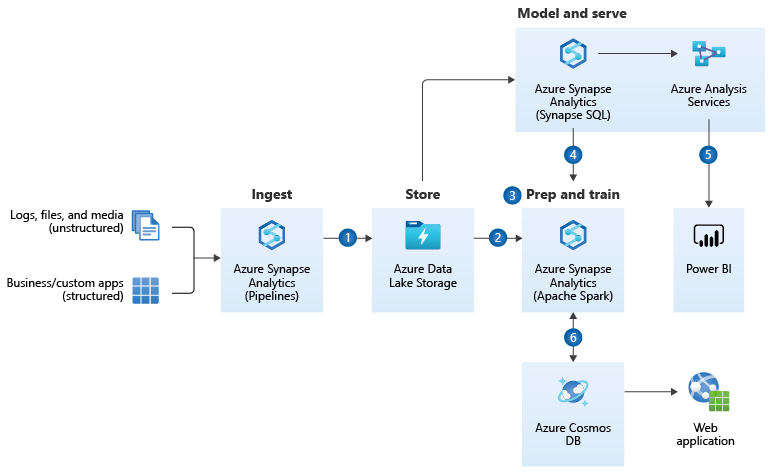 https://docs.microsoft.com/en-us/azure/architecture/solution-ideas/articles/enterprise-data-warehouseQuelle:
https://docs.microsoft.com/en-us/azure/architecture/solution-ideas/articles/enterprise-data-warehouseQuelle: 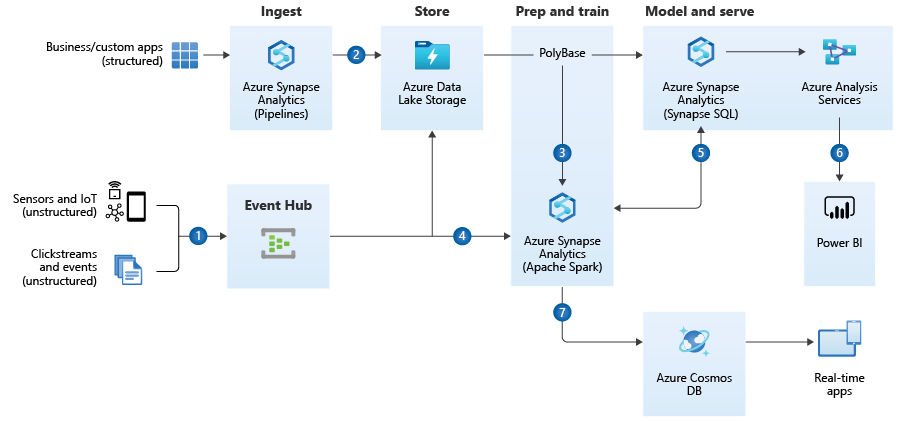
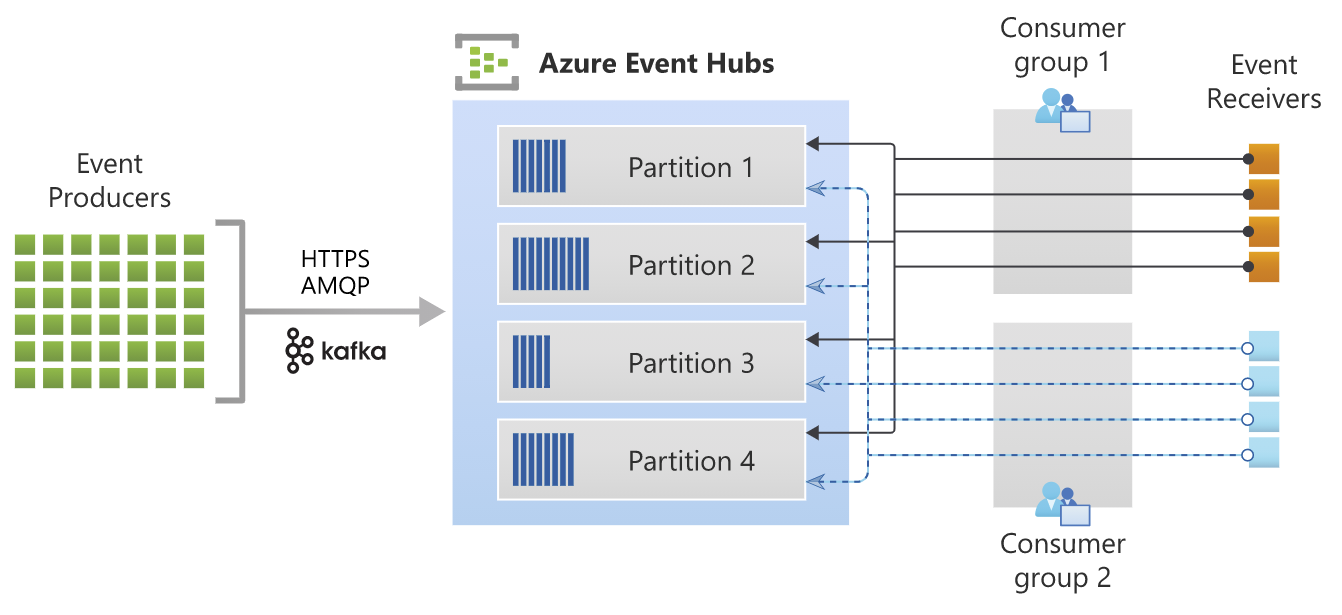 Quelle: https://docs.microsoft.com/de-de/azure/event-hubs/event-hubs-about
Quelle: https://docs.microsoft.com/de-de/azure/event-hubs/event-hubs-about 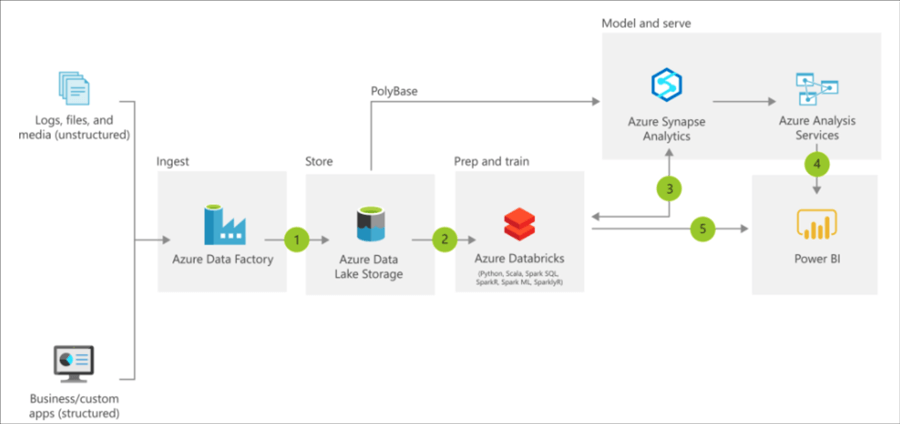

 and
and 
 , where
, where  , respectively from English and German corpus, then we learn a mapping
, respectively from English and German corpus, then we learn a mapping  .
. . Thus
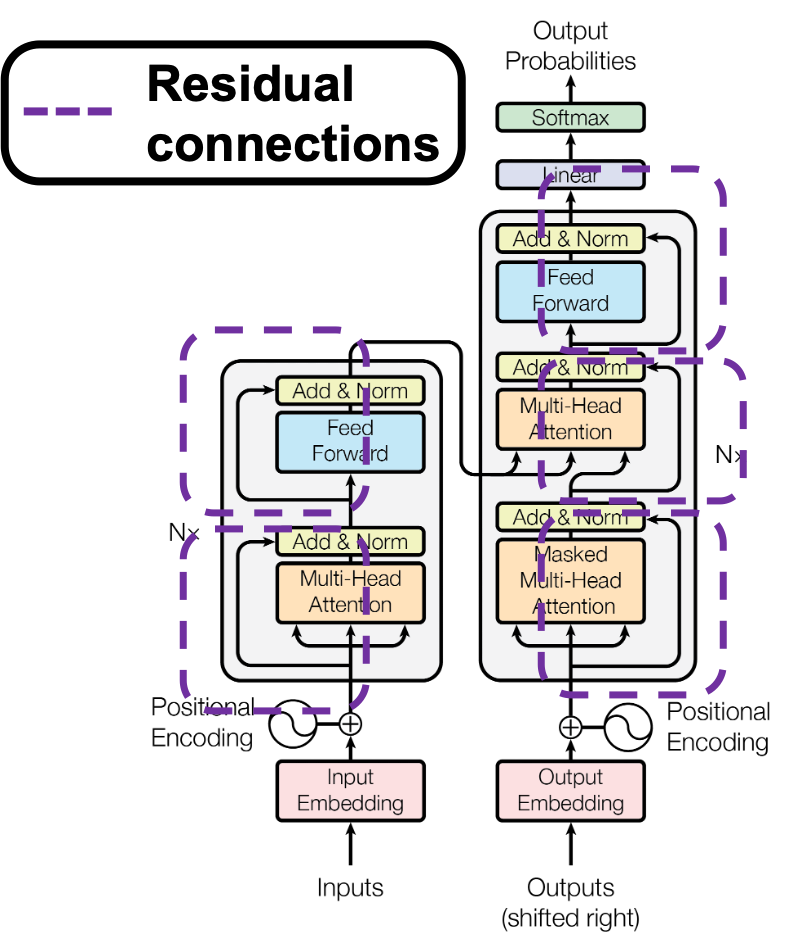
. Thus 
 layers. The decoder part also keeps converting the inputs in the target languages, also through
layers. The decoder part also keeps converting the inputs in the target languages, also through 
 . In short you stack two fully connected layers and activate it with a ReLU function. Let’s see how point_wise_feed_forward_network() function works in the implementation with some simple codes. As you can see from the number of parameters in each layer of the position wise feed forward neural network, the network does not depend on the length of the sentences.
. In short you stack two fully connected layers and activate it with a ReLU function. Let’s see how point_wise_feed_forward_network() function works in the implementation with some simple codes. As you can see from the number of parameters in each layer of the position wise feed forward neural network, the network does not depend on the length of the sentences.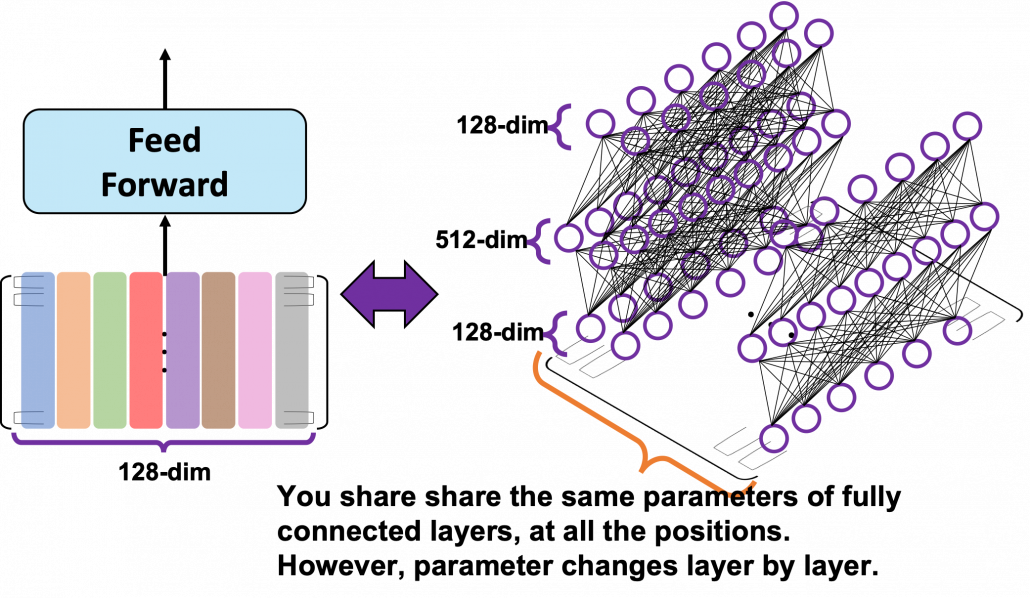
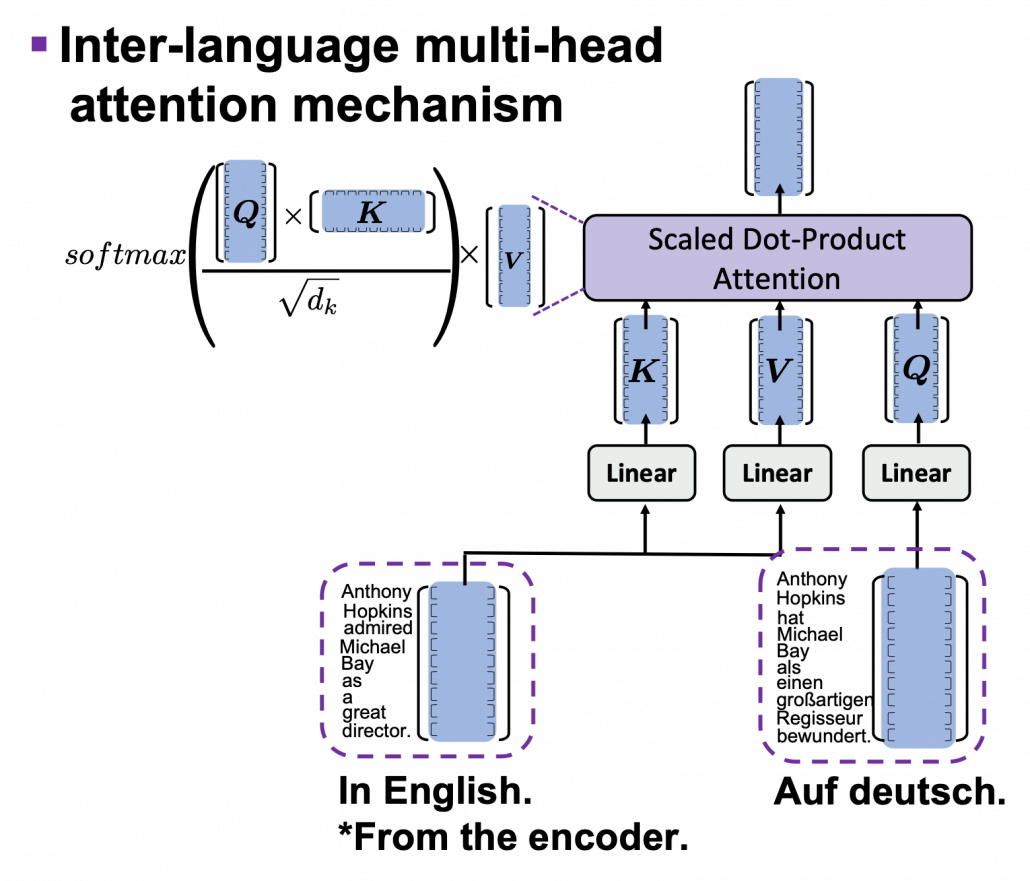
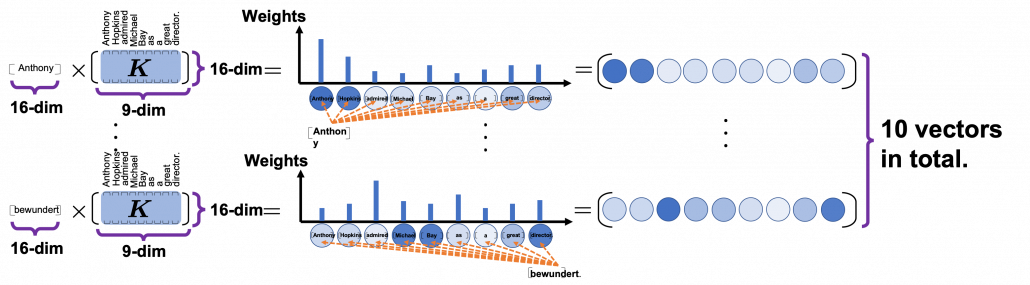
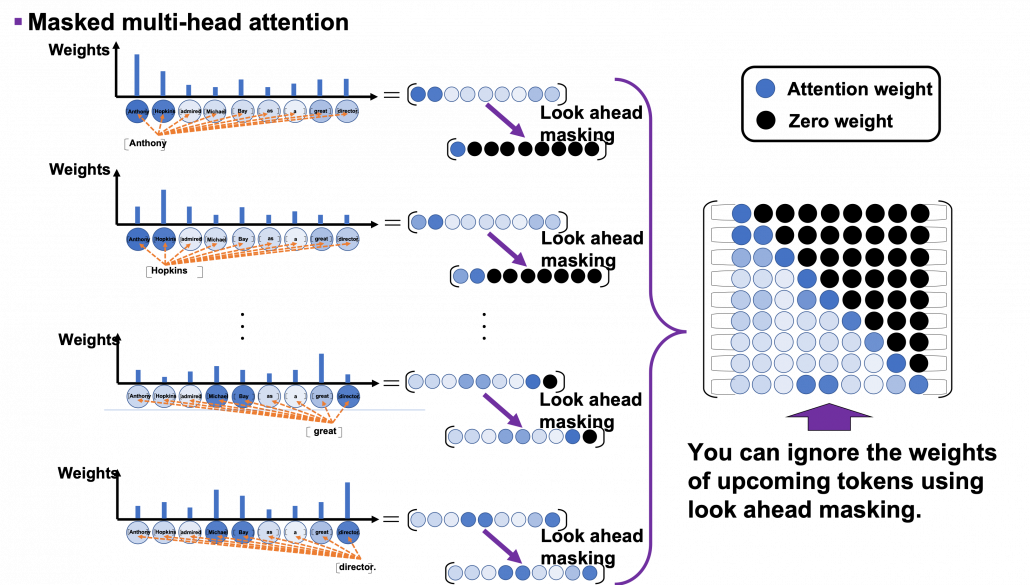
 . In the example above, the resulting multi-head attention map is a
. In the example above, the resulting multi-head attention map is a  matrix like in the figure below.
matrix like in the figure below.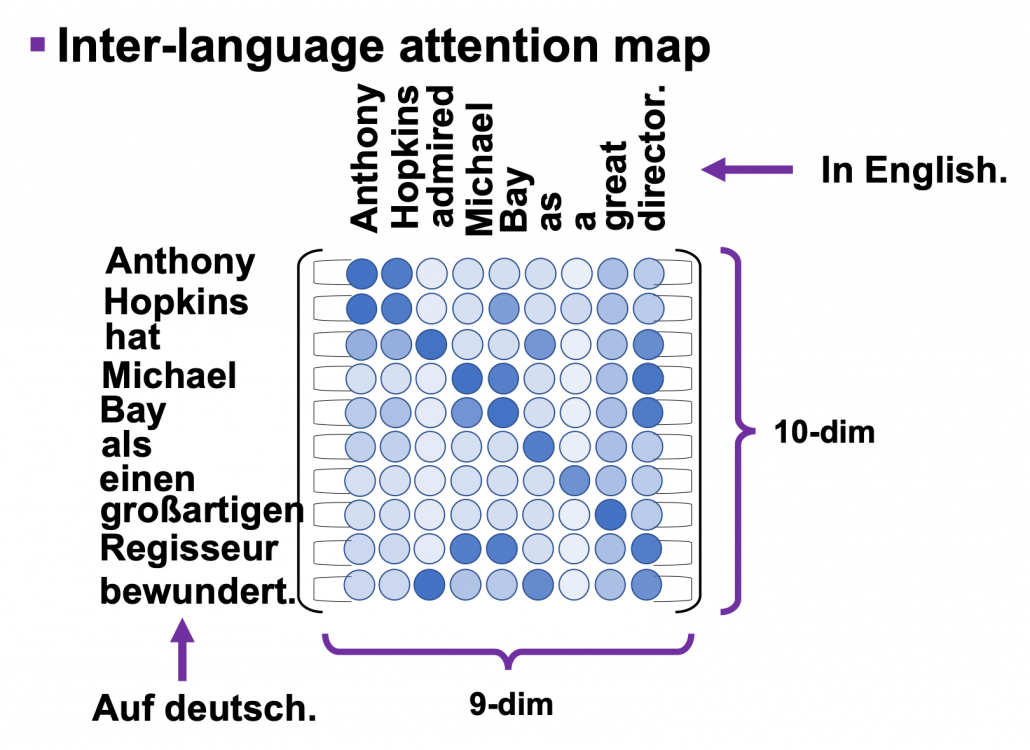
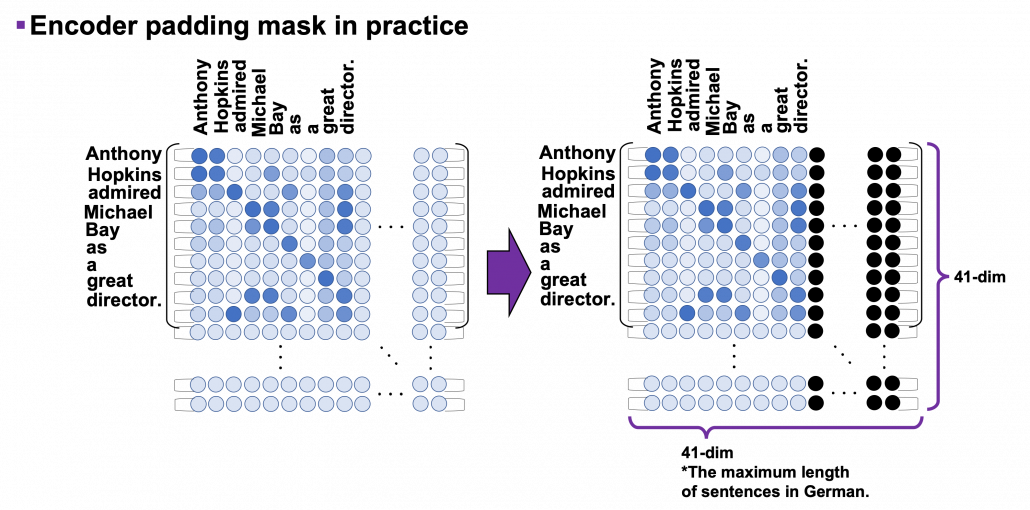
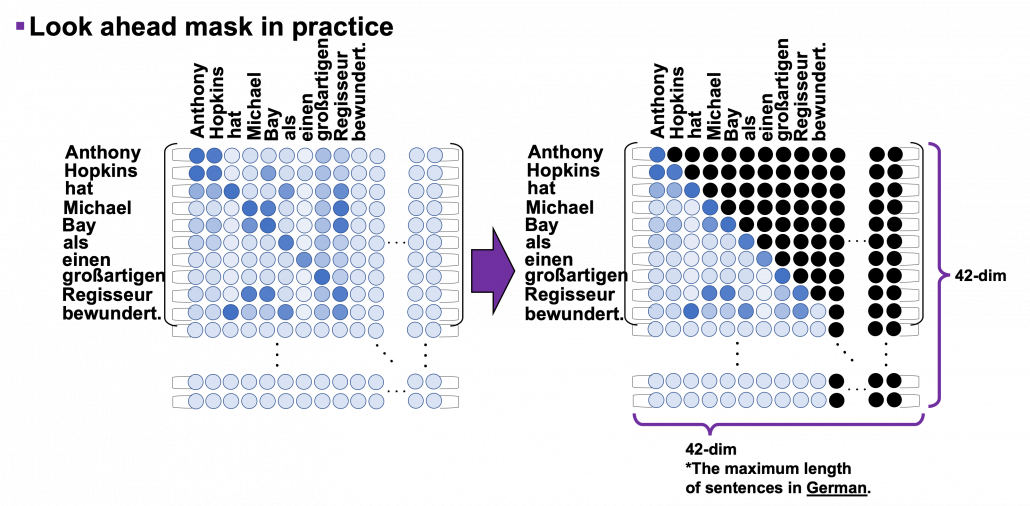
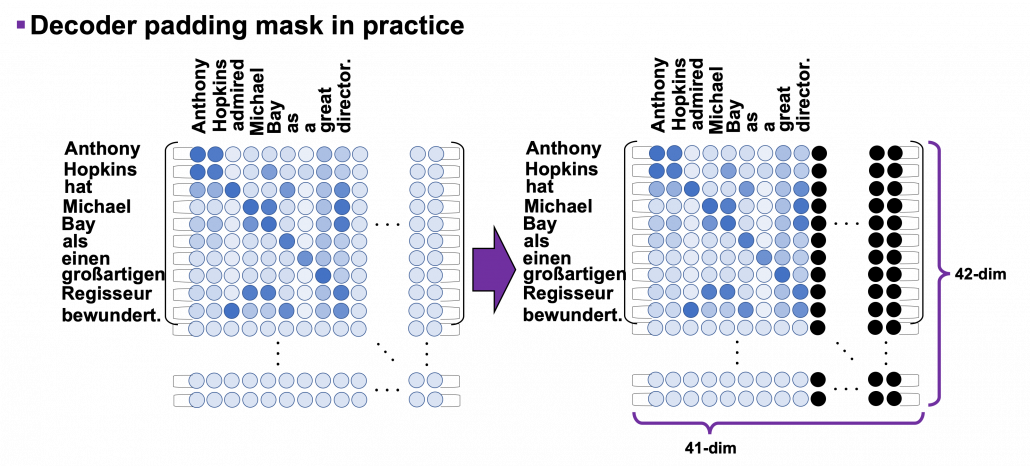
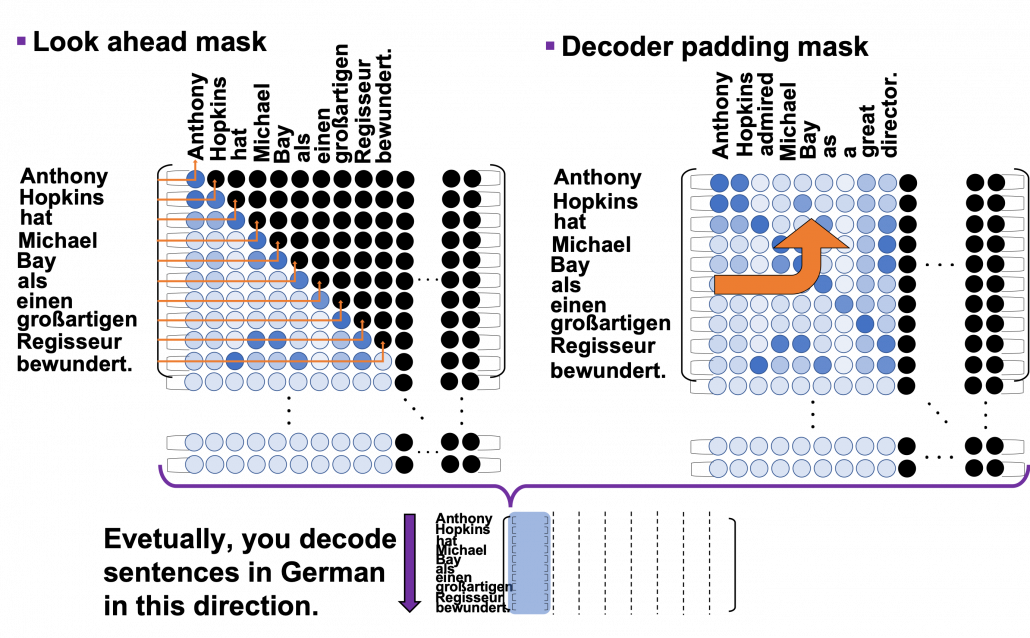
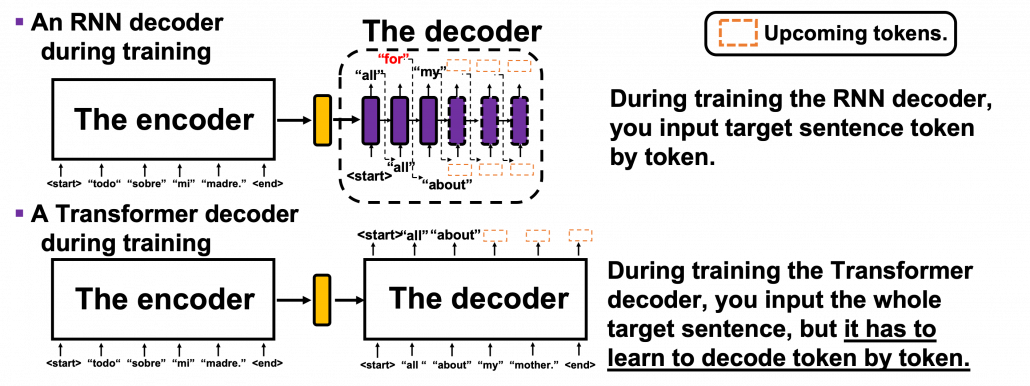
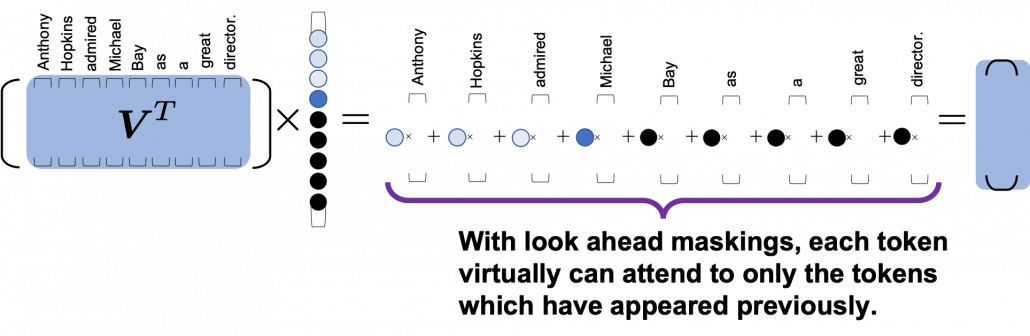
 can depend only on the known outputs at positions less than
can depend only on the known outputs at positions less than 
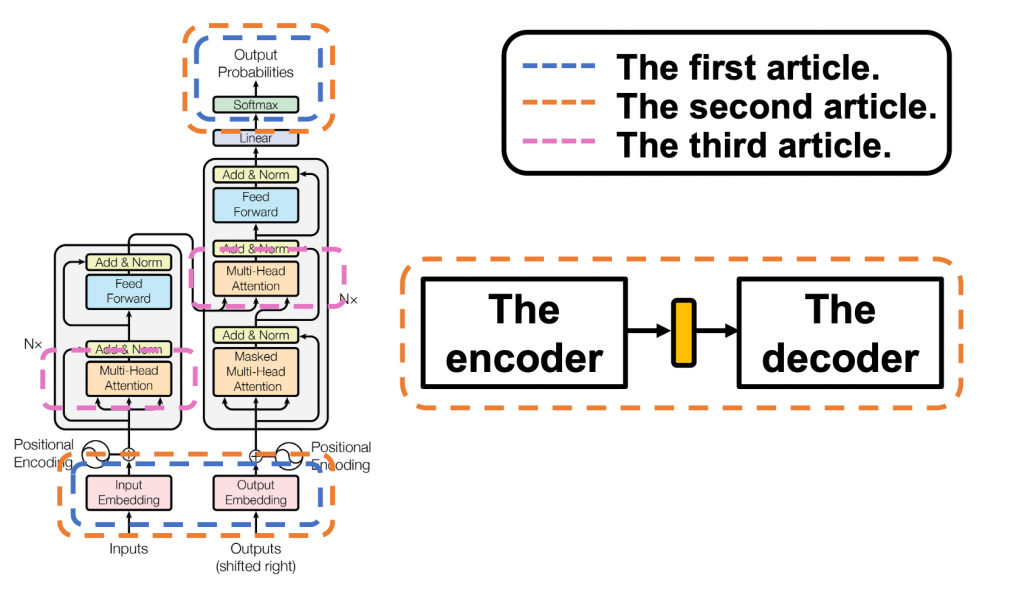
 tokens, basically you have to wait for
tokens, basically you have to wait for  the RNN cell retains the information at the time step
the RNN cell retains the information at the time step  only via recurrent connections. In this way you cannot attend to tokens in the earlier time steps, and this is obviously far from how we compare tokens in a sentence. You can bring information backward by bidirectional connection s in RNN models, but that all the more deteriorate parallelization of the model. And possessing information via recurrent connections, like a telephone game, potentially has risks of vanishing gradient problems. Gated RNN, such as LSTM or GRU mitigate the problems by a lot of nonlinear functions, but that adds to computational costs. If you understand multi-head attention mechanism, I think you can see that Transformer solves those problems.
only via recurrent connections. In this way you cannot attend to tokens in the earlier time steps, and this is obviously far from how we compare tokens in a sentence. You can bring information backward by bidirectional connection s in RNN models, but that all the more deteriorate parallelization of the model. And possessing information via recurrent connections, like a telephone game, potentially has risks of vanishing gradient problems. Gated RNN, such as LSTM or GRU mitigate the problems by a lot of nonlinear functions, but that adds to computational costs. If you understand multi-head attention mechanism, I think you can see that Transformer solves those problems. , but if you naively give the term
, but if you naively give the term ![[0, 1]](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-caffaae885a1287e3dfc31bfb1cd0694_l3.png "Rendered by QuickLaTeX.com") . With this approach, however, the resolution of encodings can vary depending on the length of the input sequence data. Thus these naive approaches do not meet the requirements above, and I guess even conventional RNN-based models were not so successful in these points.
. With this approach, however, the resolution of encodings can vary depending on the length of the input sequence data. Thus these naive approaches do not meet the requirements above, and I guess even conventional RNN-based models were not so successful in these points. ,
,  , where
, where  .
.  is the dimension of word embedding. The heat map below is the most typical type of visualization of positional encoding you would see everywhere, and in this case
is the dimension of word embedding. The heat map below is the most typical type of visualization of positional encoding you would see everywhere, and in this case  , and
, and  is discrete number which varies from
is discrete number which varies from  , thus the heat map blow is equal to a
, thus the heat map blow is equal to a  matrix, whose elements are from
matrix, whose elements are from 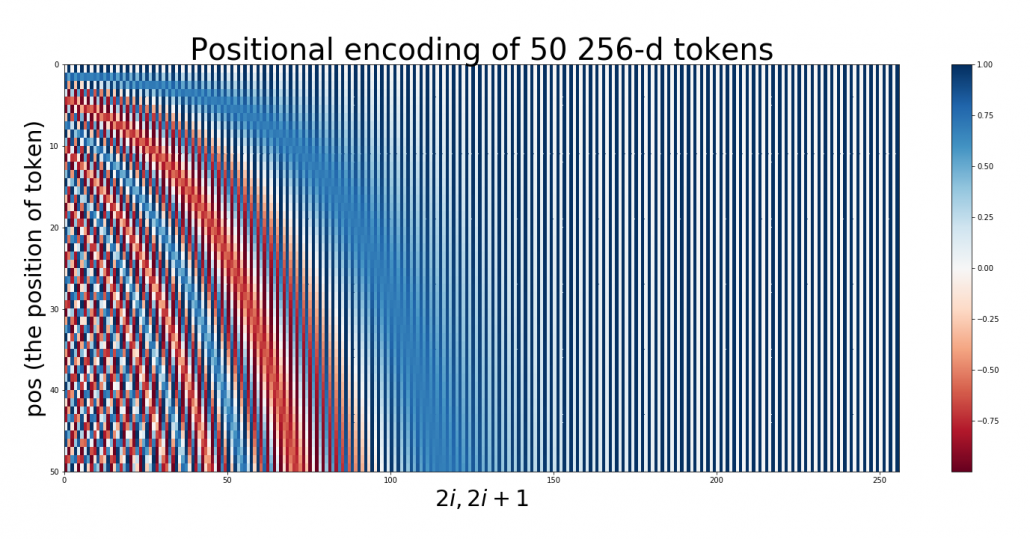

 .
. pairs of circles rather than
pairs of circles rather than 
 . If you constantly change the value
. If you constantly change the value  rotates clockwise on the unit circle in the figure below.
rotates clockwise on the unit circle in the figure below.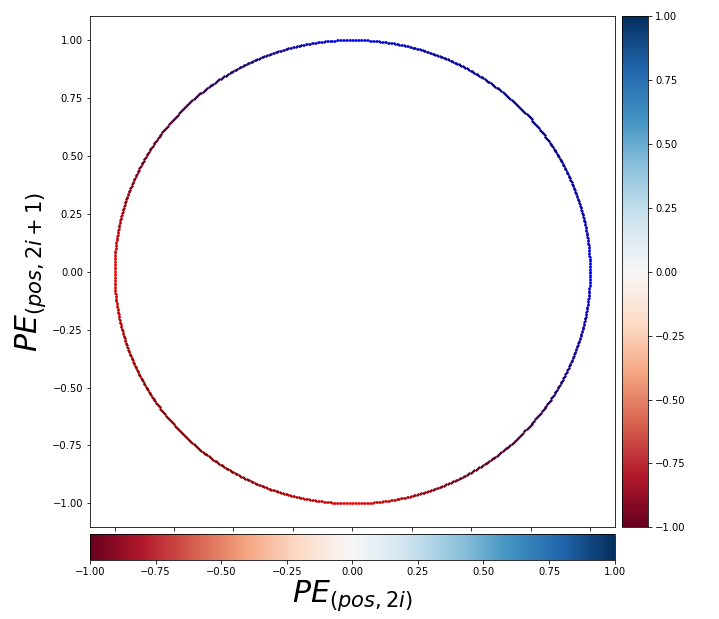
 ,
,  can be represented as a linear function of
can be represented as a linear function of  .” For each circle at any depth, I mean for any
.” For each circle at any depth, I mean for any 

 , where
, where  . Also the shift from “Bay” to “great” has the same rotation.
. Also the shift from “Bay” to “great” has the same rotation.

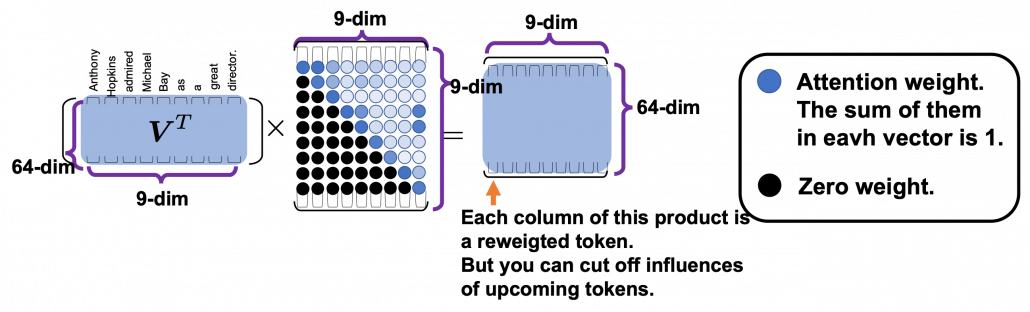

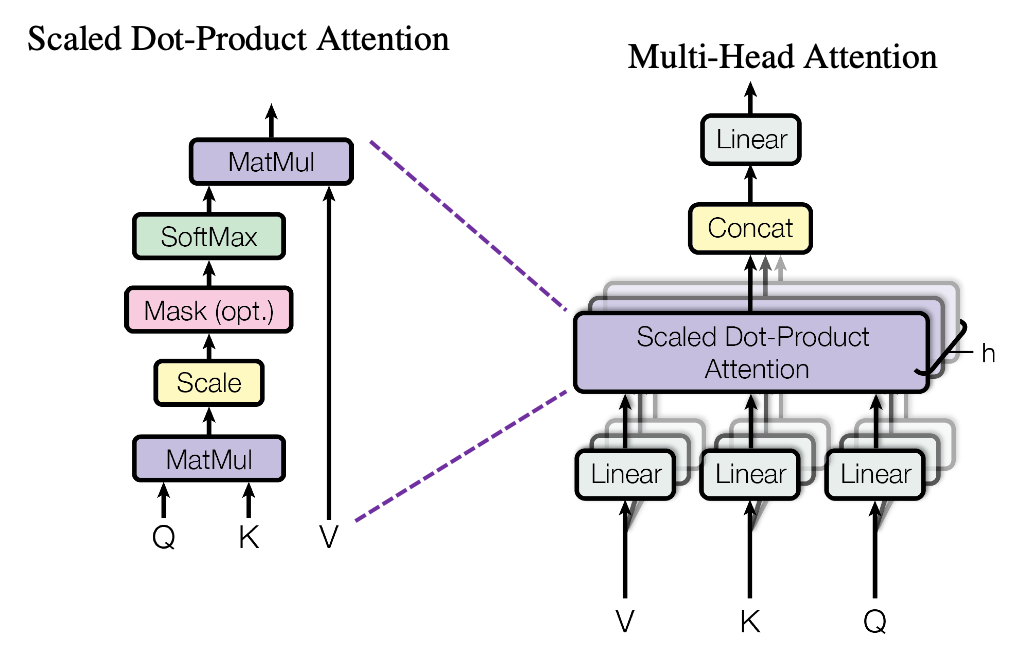
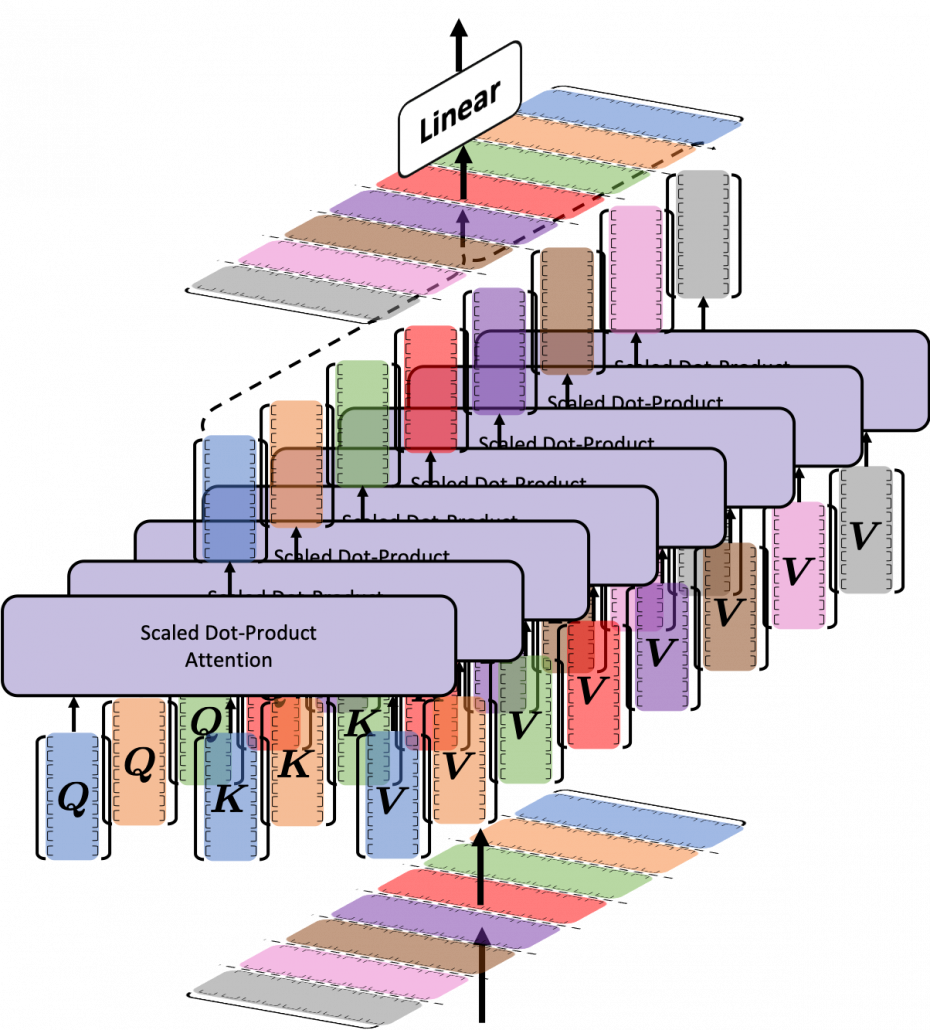
 matrix. You first split each token into
matrix. You first split each token into  dimensional, 8 vectors in total, as I colored in the figure below. In other words, the input matrix is divided into 8 colored chunks, which are all
dimensional, 8 vectors in total, as I colored in the figure below. In other words, the input matrix is divided into 8 colored chunks, which are all  matrices, but each colored matrix expresses the same sentence. And you calculate self-attentions of the input sentence independently in the 8 heads, and you reweight the “values” according to the attentions/weights. After this, you stack the sum of the reweighted “values” in each colored head, and you concatenate the stacked tokens of each colored head. The size of each colored chunk does not change even after reweighting the tokens. According to Ashish Vaswani, who invented Transformer model, each head compare “queries” and “keys” on each standard. If the a Transformer model has 4 layers with 8-head multi-head attention , at least its encoder has
matrices, but each colored matrix expresses the same sentence. And you calculate self-attentions of the input sentence independently in the 8 heads, and you reweight the “values” according to the attentions/weights. After this, you stack the sum of the reweighted “values” in each colored head, and you concatenate the stacked tokens of each colored head. The size of each colored chunk does not change even after reweighting the tokens. According to Ashish Vaswani, who invented Transformer model, each head compare “queries” and “keys” on each standard. If the a Transformer model has 4 layers with 8-head multi-head attention , at least its encoder has  heads, so the encoder learn the relations of tokens of the input on 32 different standards.
heads, so the encoder learn the relations of tokens of the input on 32 different standards.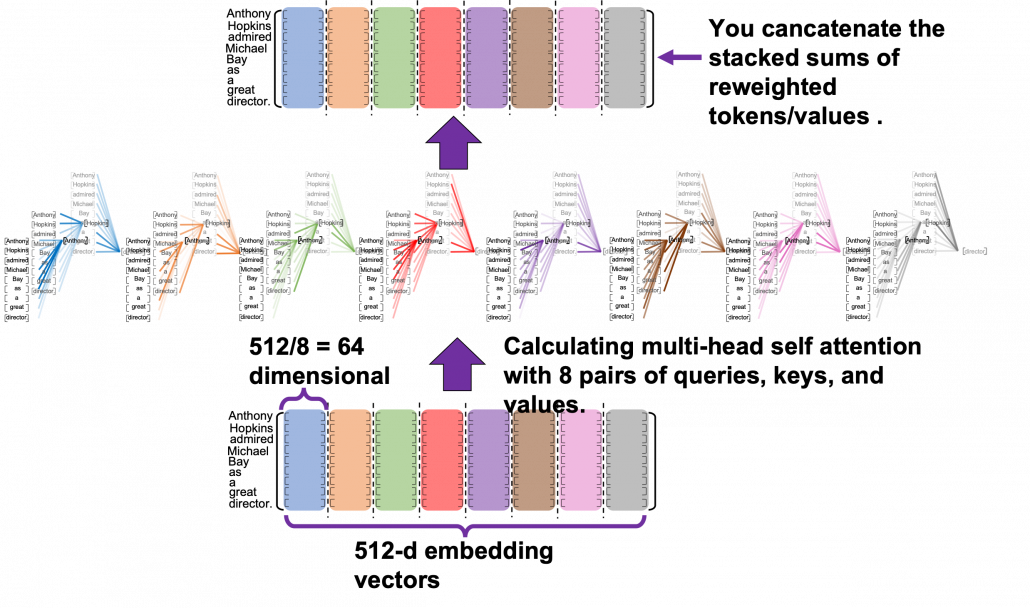
![[ \cdots ]](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-a935a6ae352397cdde28cd5115cc275a_l3.png "Rendered by QuickLaTeX.com") denotes a token, which is usually an embedding vector in practice.
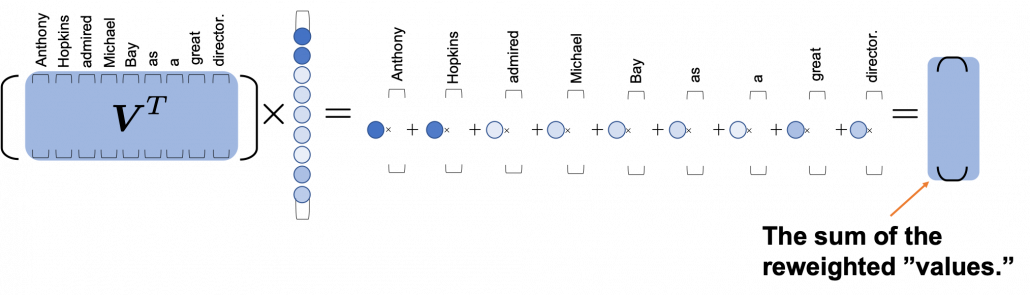
denotes a token, which is usually an embedding vector in practice.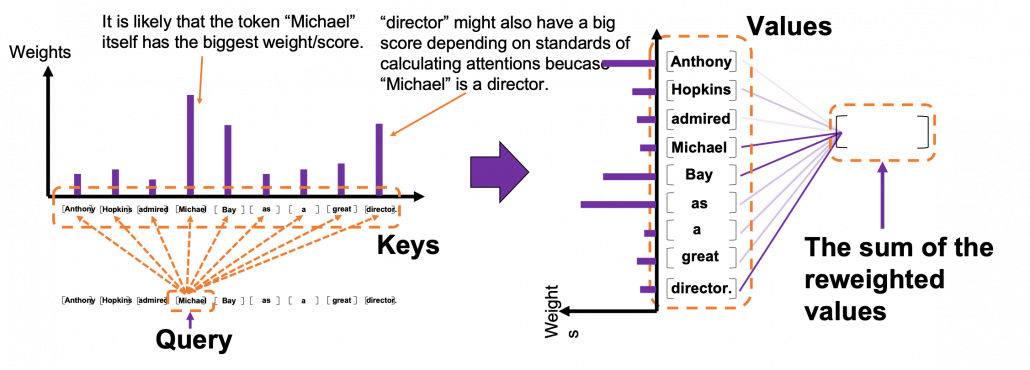 *I have been repeating the phrase “reweighting ‘values’ with attentions,” but you in practice calculate the sum of those reweighted “values.”
*I have been repeating the phrase “reweighting ‘values’ with attentions,” but you in practice calculate the sum of those reweighted “values.”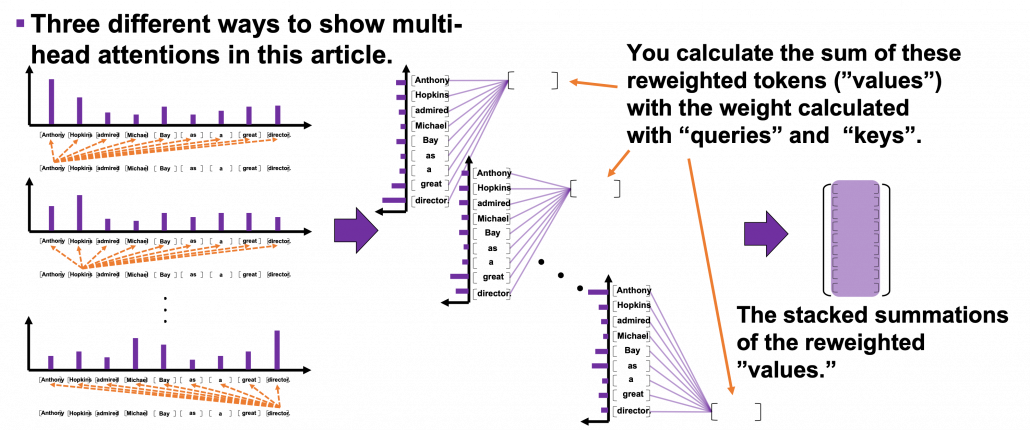

 . Let’s take an example of calculating a scaled dot-product in the blue head.
. Let’s take an example of calculating a scaled dot-product in the blue head. , which are “queries”, “keys”, and “values” respectively.
, which are “queries”, “keys”, and “values” respectively. by
by  in the formula. According to the original paper, it is known that re-scaling
in the formula. According to the original paper, it is known that re-scaling  by
by 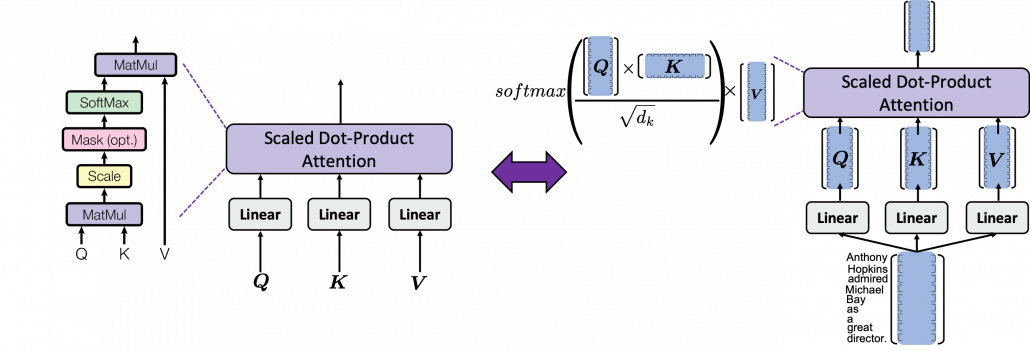
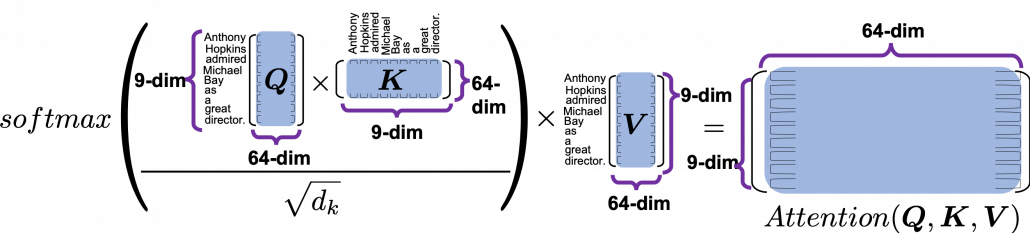
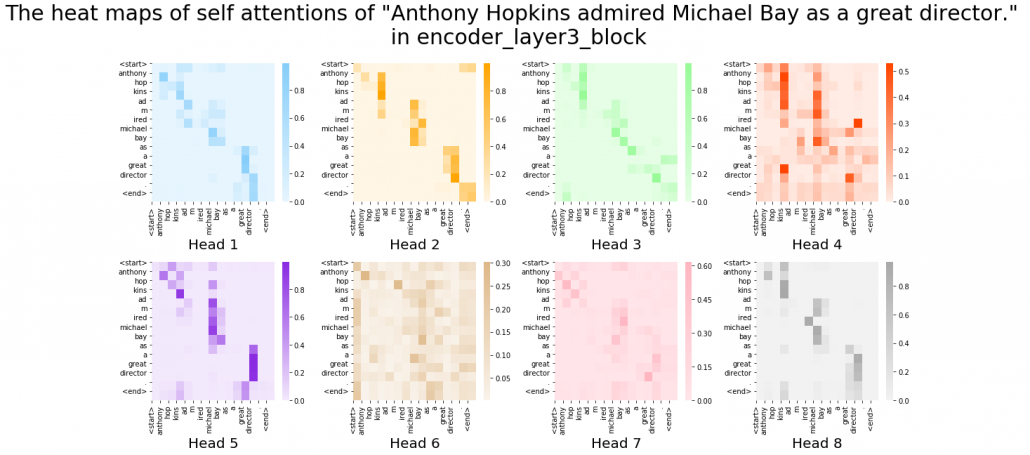
 , and the resulting
, and the resulting  matrix is a kind a heat map of self-attentions.
matrix is a kind a heat map of self-attentions.
 and regularizing them with a softmax function, you stack those vectors, and the stacked vectors is the heat map of attentions.
and regularizing them with a softmax function, you stack those vectors, and the stacked vectors is the heat map of attentions.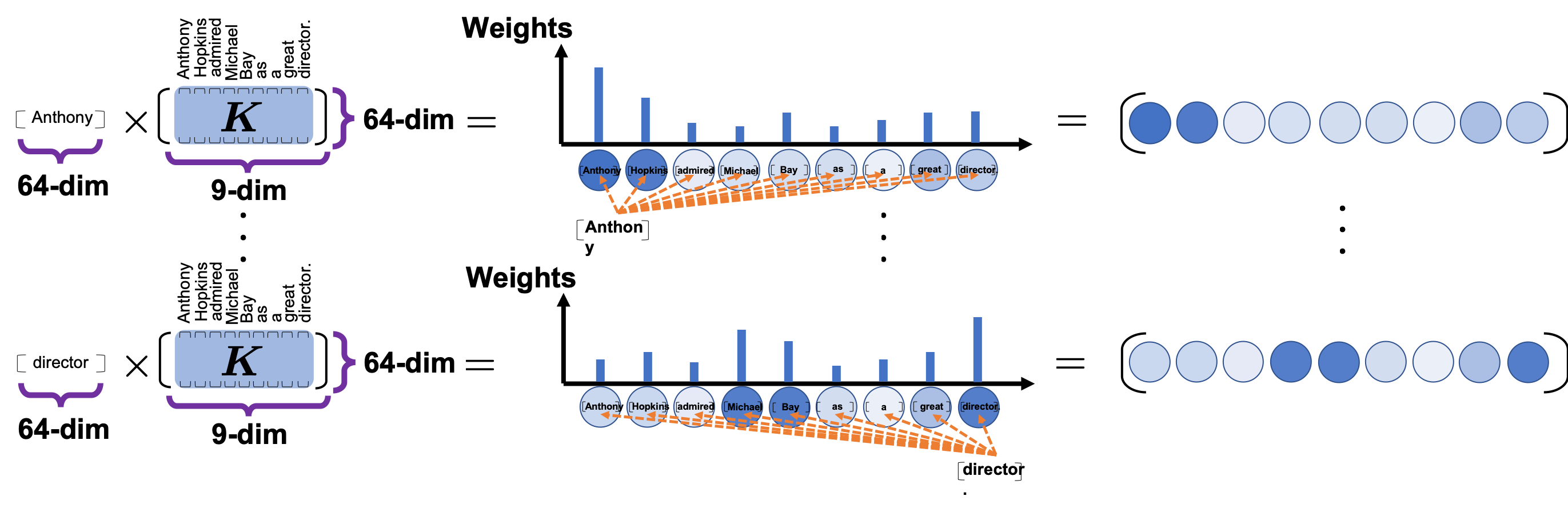
 . This also should be easy to understand if you know basics of linear algebra.
. This also should be easy to understand if you know basics of linear algebra.