
Künstliche Intelligenz und Data Science in der Automobilindustrie
Data Science und maschinelles Lernen sind die wesentlichen Technologien für die automatisch lernenden und optimierenden Prozesse und Produkte in der Automobilindustrie der Zukunft. In diesem Beitrag werde die zugrundeliegenden Begriffe Data Science (bzw. Data Analytics) und maschinelles Lernen sowie deren Zusammenhang definiert. Darüber hinaus wird der Begriff Optimizing Analytics definiert und die Rolle der automatischen Optimierung als Schlüsseltechnologie in Kombination mit Data Analytics dargelegt. Der Stand der Nutzung dieser Technologien in der Automobilindustrie wird anhand der wesentlichen Teilprozesse in der automobilen Wertschöpfungskette (Entwicklung, Einkauf, Logistik, Produktion, Marketing, Sales und Aftersales, Connected Customer) an exemplarischen Beispielen erläutert. Dass die Industrie heute erst am Anfang der Nutzungsmöglichkeiten steht, wird anhand von visionären Anwendungsbeispielen verdeutlicht, die die revolutionären Möglichkeiten dieser Technologien darstellen. Der Beitrag zeigt auf, wie die Automobilindustrie umfassend, vom Produkt und dessen Entstehungsprozess bis zum Kunden und dessen Verbindung zum Produkt, durch diese Technologie effizienter und kundenorientierter wird.
![]() Read this article in English:
Read this article in English:
“Artificial Intelligence and Data Science in the Automotive Industry”
Inhaltsverzeichnis
3 Säulen der künstlichen Intelligenz
3.1 Maschinelles Lernen
3.2 Computer Vision
3.3 Schließen und Entscheidungsfindung
3.4 Sprache und Kommunikation
3.5 Agenten und Aktionen
4 Data Mining und künstliche Intelligenz in der Automobilindustrie
4.1 Technische Entwicklung
4.2 Einkauf
4.3 Logistik
4.4 Produktion
4.5 Marketing
4.6 Sales, After Sales und Retail
4.7 Connected Customer
5 Vision
5.1 Autonome Fahrzeuge
5.2 Integrierte Fabrikoptimierung
5.3 Unternehmen agieren eigenständig
Autoren:
- Dr. Martin Hofmann (CIO – Volkswagen AG)
- Dr. Florian Neukart (Principal Data Scientist – Volkswagen AG)
- Prof. Dr. Thomas Bäck (Universität Leiden)
1 Einleitung
Data Science und maschinelles Lernen sind heute Schlüsseltechnologien im täglichen Leben, wie wir aus einer Vielzahl von Anwendungen wie etwa der Spracherkennung in Fahrzeugen und Mobiltelefonen, der automatischen Gesichts- und Verkehrsschilderkennung, oder auch den vom Menschen nicht mehr zu besiegenden maschinellen Schach- und seit kurzem auch Go-Algorithmen [1] ersehen können. Die Analyse großer Datenmengen durch Such-, Mustererkennungs- und Lernalgorithmen liefert Einsichten in das Verhalten von Prozessen, Anlagen, der Natur, und letztlich auch von Menschen, die fundamental neue Möglichkeiten eröffnen. Die heute schon umsetzbare Idee des autonomen Fahrens ist mit Hilfe von Spur- und Abstandshalteassistenten im Fahrzeug schon für viele Fahrer nahezu greifbare Realität.
Dass dies, auch im Bereich der Automobilindustrie, nur die Spitze des Eisbergs ist, wird schnell deutlich, wenn man sich vergegenwärtigt, dass Toyota ebenso wie der Tesla-Gründer Elon Musk nahezu zeitgleich Ende 2015 jeweils eine Investition in Höhe von einer Milliarde US Dollar in Forschung und Entwicklung im Bereich künstliche Intelligenz angekündigt haben. Die Entwicklung in Richtung vernetzter, autonomer und künstlich intelligenter Systeme, die kontinuierlich aus Daten lernen und optimale Entscheidungen treffen können, geht in geradezu revolutionierender Weise voran – und ist für viele Industriezweige von fundamentaler Bedeutung. Dazu zählt auch die Automobilindustrie als eine Schlüsselindustrie in Deutschland, in der sich die internationale Wettbewerbsfähigkeit in naher Zukunft auch über die neuen technischen und Serviceangebote definieren wird, die mit Hilfe von Data Science und maschinellem Lernen möglich werden.
Dieser Artikel gibt einen Überblick sowohl über die Methoden als auch einige der aktuellen Anwendungsbeispiele in der Automobilindustrie sowie einen Ausblick auf die sehr bald schon in dieser Industrie zu erwartenden möglichen Anwendungen. Dazu widmen sich die Abschnitte 2 und 3 zunächst den methodischen Teilbereichen Data Mining (bzw. Big Data Analytics) und künstliche Intelligenz. Hier werden die entsprechenden Prozesse, Methoden und Anwendungsbereiche kurz zusammengefasst und im Kontext dargestellt. Ein Überblick über aktuelle Anwendungsbeispiele in der Automobilindustrie wird in Abschnitt 4 gegeben, wobei dies anhand der Stufen der Wertschöpfungskette in der Industrie erfolgt – von der technischen Entwicklung über Produktion und Logistik bis hin zum Endkunden. Auf der Basis derartiger Beispiel wird in Abschnitt 5 die Vision für zukünftige Einsatzbereich anhand von drei Beispielen dargestellt, die Fahrzeuge als autonome, miteinander im Umfeld der Stadt interagierende Agenten zeigen, die integrierte Produktionsoptimierung darstellen, und schließlich das Unternehmen als autonom agierenden Agenten beschreiben.
Ob diese Visionen so oder in abgewandelter Weise Realität werden, ist heute nicht zu sagen – was wir aber mit Sicherheit vorhersehen können ist, dass die rasante Entwicklung in diesem Bereich zum Entstehen völlig neuer Produkte, Prozesse und Dienstleistungen führen wird, von denen wir viele heute nur erahnen können. Dies ist eine der Schlussfolgerungen, die neben anderen im Abschnitt 6 gezogen werden – gemeinsam mit einem Ausblick auf das, was die rasante Entwicklung dieses Gebietes noch bewirken kann.
2 Der Data Mining Prozess
Seitens Gartner wird heute der Begriff des Prescriptive Analytics als höchste Stufe der Fähigkeit, auf der Basis datenbasierter Analysen unternehmerische Entscheidungen zu fällen, verwendet. Verdeutlich wird dies durch die Frage „was sollte ich tun?“, und Prescriptive Analytics liefert die entsprechende Entscheidungsunterstützung, wenn der Mensch noch involviert ist, oder Automatisierung, wenn das nicht mehr der Fall ist.
Die Stufen darunter werden, in aufsteigender Folge hinsichtlich des Einsatzes und Nutzens von KI und Data Science, als Descriptive Analytics („was ist passiert?“), Diagnostic Analytics („warum ist es passiert?“) und Predictive Analytics („was wird passieren?“) definiert (siehe Abbildung 1). Die beiden letztgenannten Stufen basieren auf den Technologien der Data Science, inklusive Data Mining und Statistik, während Descritive Analytics im Wesentlichen die klassischen Business Intelligence Konzepte (Data Warehouse, OLAP) verwendet.
In diesem Artikel möchten wir den Begriff Prescriptive Analytics durch den Begriff Optimizing Analytics ersetzen, denn „vorschreiben“ kann eine Technologie vieles – im Sinne der Umsetzung im Unternehmen geht es aber doch immer darum, etwas „besser“ zu machen im Hinblick auf Zielkriterien oder Gütekriterien. Die Optimierung kann dabei durch Suchalgorithmen wie z.B. evolutionäre Algorithmen im nichtlinearen Fall und Methoden des Operations Research (OR) im – eher seltenen – linearen Fall ebenso unterstützt werden wie durch den Anwendungsexperten, der aus den Resultaten des Data Mining Schlussfolgerungen zur Verbesserung eines Prozesses zieht. Ein gutes Beispiel sind aus Daten gelernte Entscheidungsbäume, die vom Anwendungsexperten verstanden, mit seinem Expertenwissen abgestimmt, und dann geeignet umgesetzt werden können. Auch hier ist die Anwendung optimierend, allerdings mit einem menschlichen Zwischenschritt.
Wichtig ist in diesem Zusammenhang auch, dass es häufig eine Optimierung mehrerer Kriterien gleichzeitig ist, die in der Anwendung benötigt wird – daher sind Methoden der mehrkriteriellen Optimierung oder, allgemeiner, der Entscheidungsunterstützung, nötig. Diese Verfahren können eingesetzt werden, um bestmögliche Kompromisse zwischen miteinander in Konflikt stehenden Zielen zu finden. Als Beispiel seien die häufig auftretenden Konflikte zwischen Kosten und Qualität, Risiko und Gewinn, oder, in einem eher technischen Beispiel, Gewicht und passiver Insassensicherheit einer Karosserie genannt.
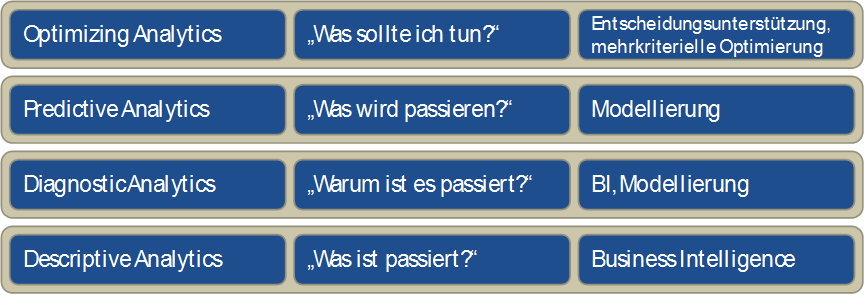
Abbildung 1: Die vier Ebenen der Nutzung von Datenanalyse im Unternehmen
Diese vier Ebenen bilden einen Rahmen, innerhalb dessen Datenanalysekompetenz und möglicher Nutzen für ein Unternehmen allgemein eingeordnet werden können. Dieser Rahmen ist in Abbildung 1 dargestellt und zeigt die vier aufeinander aufbauenden Schichten mit der jeweiligen Technologieklasse, die zur Umsetzung notwendig ist.
Im klassischen Cross-Industry Standard Process for Data Mining (CRISP-DM) [2] sind Optimierung bzw. Entscheidungsunterstützung überhaupt nicht enthalten. Aufbauend auf den Teilschritten Business Understanding, Data Understanding, Data Preparation, Modeling, und Evaluation, geht der CRISP direkt in das Deployment der Resultate im Geschäftsprozess über. Auch hier schlagen wir einen zusätzlichen Schritt der Optimierung vor, unter der wir wiederum mehrkriterielle Optimierung und Entscheidungsunterstützung verstehen. Diese Vorgehensweise ist schematisch in Abbildung 2 dargestellt.
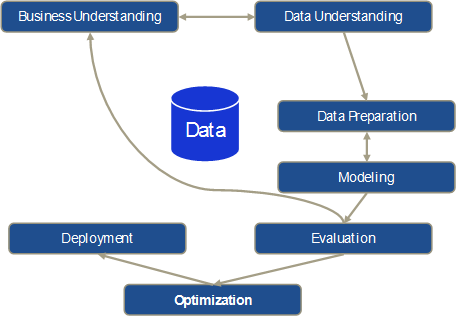
Abbildung 2: Um Optimization erweiterter klassischer CRISP-DM Prozess
Im CRISP ist zu beachten, dass es sich im Original um ein stark iteratives Schema zur manuellen Analyse von Daten durch Data Scientists handelt, was durch die Iterationen zwischen Business Understanding und Data Understanding sowie Data Preparation und Modeling reflektiert wird. Die Bewertung der Modellierungsresultate mit den Anwendungsexperten im Schritt Evaluation kann aber auch dazu führen, dass der Prozess komplett neu im Teilschritt Business Understanding begonnen wird, und so alle Teilschritte zum Teil oder vollständig wieder durchlaufen werden müssen (z.B. wenn weitere Daten hinzugenommen werden müssen).
Die manuelle, iterative Vorgehensweise ist auch der Tatsache geschuldet, dass die Grundidee des Ansatzes, so aktuell sie auch heute noch für die Mehrzahl der Anwendungen sein mag, mittlerweile fast 20 Jahre alt ist und sicher nur zum Teil mit einer Big Data Strategie kompatibel. Tatsächlich ist ja, neben der Verwendung nichtlinearer Modellierungsverfahren (im Gegensatz zu den üblichen verallgemeinerten linearen Modellen aus der statistischen Modellierung) und der Extraktion von Wissen aus Daten eine weitere Grundidee des Data Mining, dass Modelle auch mit Hilfe von Algorithmen aus Daten gewonnen werden und dieser Modellbildungsprozess großenteils automatisch ablaufen kann – da der Algorithmus „die Arbeit macht“.
Bei Anwendungen, in denen sehr viele Modelle erstellt werden müssen, die beispielsweise für Prognosen verwendet werden sollen (Beispiel: Absatzprognose für individuelle Fahrzeugmodelle und Märkte auf der Basis historischer Daten), spielt die automatische Modellierung eine wesentliche Rolle. Gleiches gilt auch für die Anwendung des Data Mining im On-line Modus, indem beispielsweise für einen Produktionsprozess ständig nicht nur Prognosemodelle (z.B. für die Prognose der Produktqualität) verwendet werden, sondern diese auch kontinuierlich adaptiert (d.h., nachtrainiert) werden müssen, weil sich Teilaspekte des Prozesses verändert haben (z.B. weil eine neue Rohmaterialcharge eingesetzt wird). Derartige Anwendungen erfordern die technische Fähigkeit, automatisch Daten zu erzeugen und so zu integrieren und aufzubereiten, dass Algorithmen des Data Mining darauf angewandt werden können. Zusätzlich sind die automatisierte Modellbildung sowie die automatische Optimierung notwendig, um Modelle zu aktualisieren und daraus in On-line Anwendungen optimale Handlungsvorschläge zu generieren. Diese können entweder als Vorschlag an den Prozessexperten kommuniziert werden, oder auch – insbesondere z.B. in kontinuierlichen Produktionsprozessen – direkt zur Steuerung des Prozesses verwendet werden. Wird auch die Sensorik im Produktionsprozess direkt integriert, die Daten also in Echtzeit gesammelt, wird so ein selbstlernendes cyber-physisches System [3] realisiert, das in der Fertigungstechnik die Realisierung der Industrie 4.0 [4] Vision ermöglicht.
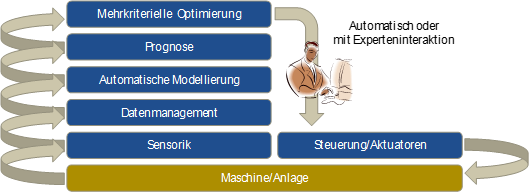
Abbildung 3: Architektur eines Industrie 4.0 Konzeptes für Optimizing Analytics
In Abbildung 3 ist dieser Ansatz schematisch dargestellt. Daten von der Anlage werden mit Hilfe der Sensoren erfasst und im Datenmanagementsystem integriert. Darauf aufbauend werden Prognosemodelle über die relevanten Outputs der Anlage (Qualität, Abweichung vom Sollwert, Varianz des Prozesses, oder ähnliches) kontinuierlich verwendet, um den Output der Anlage zu prognostizieren. Andere Möglichkeiten des maschinellen Lernens können hier verwendet werden, um z.B. Wartungsereignisse vorherzusagen (Predictive Maintenance) oder Anomalien im Prozess zu erkennen. Die Modelle werden kontinuierlich überwacht und bei einer beobachteten Drift des Prozesses ggf. automatisch nachtrainiert. Die mehrkriterielle Optimierung schließlich verwendet die Modelle, um kontinuierlich optimale Vorgaben für die Anlagensteuerung zu berechnen. Hier kann auch der menschliche Prozessexperte eingebunden werden, indem das System als Vorschlagsgenerator eingesetzt wird und ein Prozessexperte die Vorschläge bewertet, bevor sie an der Anlage umgesetzt werden.
Zur Abgrenzung vom „klassischen“ Data Mining wird der Begriff „Big Data“ heute häufig durch drei (manchmal auch vier oder fünf) wesentliche Charakteristika definiert: Volume, Velocity, und Variety, womit Bezug genommen wird auf das große Datenvolumen, die Geschwindigkeit, mit der Daten generiert werden, und die Heterogenität der zu analysierenden Daten, die sich nicht mehr in das klassische relationale Datenbankschema einordnen lassen. Veracity, also die Tatsache, dass in den Daten ggf. auch große Unsicherheiten verborgen sind (z.B. Messungenauigkeiten), und schließlich Value, also der Wert, den die Daten bzw. ihre Analyse für die Geschäftsprozesse eines Unternehmens darstellen, werden oft als zusätzliche Charakteristika genannt. Es ist also nicht nur das reine Datenvolumen, das die bisherigen Methoden der Datenanalyse von der Big Data-Thematik abgrenzt, sondern auch weitere technische Faktoren, die neue Verfahren wie z.B. Hadoop und MapReduce mit entsprechend angepassten Datenanalysealgorithmen erfordern, um Speicherung und Verarbeitung der Daten zu ermöglichen. Zusätzlich ermöglichen sog. In-Memory Datenbanken es heute, auch klassische Lern- und Modellierungsalgorithmen im Hauptspeicher auf große Datenmengen anzuwenden.
Wollte man also eine Hierarchie von Datenanalyse- und Modellbildungsverfahren und –techniken erstellen, so wäre stark vereinfacht die Statistik eine Teilmenge des Data Mining, und dieses wiederum eine Teilmenge von Big Data. Nicht jede Anwendung erfordert Data Mining oder Big Data Technologien, aber es ist doch ein deutlicher Trend zu beobachten, dass mit der zunehmenden Sammlung und Verknüpfung von größeren Datenmengen über Prozesse und Abteilungen eines Unternehmens hinweg die Notwendigkeiten und Möglichkeiten der Anwendung von Data Mining und Big Data sehr schnell wachsen. Oft reicht allerdings eine herkömmliche Hardwarearchitektur mit zusätzlichem Hauptspeicher für die Analysen auch größerer Datenmengen im Gigabyte-Bereich durchaus aus.
Bei aller Wichtigkeit, die der Optimizing Analytics beigemessen werden sollte, sollte der Blick auch immer offen bleiben für die breiten Einsatzmöglichkeiten von Algorithmen der künstlichen Intelligenz und des maschinellen Lernens. Das breite Spektrum von Lern- und Suchverfahren, mit Anwendungsmöglichkeiten wie z.B. die Erkennung von Bildern und Sprache, das Lernen von Wissen, die Steuerung und Planung in Bereichen wir Produktion und Logistik, u.v.a.m., kann im Rahmen dieses Artikels nur näherungsweise dargestellt werden.
3 Säulen der künstlichen Intelligenz
Eine frühe Definition künstlicher Intelligenz seitens des IEEE Neural Networks Council war ’the study of how to make computers do things at which, at the moment, people are better’ [5]. Das hat heute noch Gültigkeit, allerdings konzentriert sich die Forschung auch darauf, Software Dinge besser tun zu lassen, in welchen Computer schon immer besser waren, wie der Analyse von großen Datenmengen. Daten formen auch die Grundlage für die Entwicklung von künstlich intelligenten Softwaresystemen, die nicht nur Informationen sammeln sollen, sondern
- lernen,
- Informationen verstehen und interpretieren,
- sich adaptiv verhalten,
- planen,
- schließen,
- Probleme lösen,
- abstrakt denken,
- Ideen und Sprache verstehen und interpretieren.
3.1 Maschinelles Lernen
Auf dem gröbsten Level können Algorithmen im maschinellen Lernen (ML) in zwei Klassen eingeteilt werden – überwacht (supervised) und unüberwacht (unsupervised) – davon abhängig, ob der jeweilige Algorithmus die Spezifikation einer Zielvariablen benötigt oder nicht.
Überwachte Lernalgorithmen
Überwachte Lernverfahren erfordern neben den Eingangsvariablen (Prädiktoren) die bekannten Zielwerte (Labels) eines Problems. Um ein ML-Modell auf die Identifikation von Straßenschildern über Kameras zu trainieren, werden als Eingangsvariablen Bilder von Straßenschildern benötigt, idealerweise in unterschiedlichen Konfigurationen. Lichtverhältnisse, Winkel, Verschmutzung, etc. werden in diesem Fall als Rauschen oder Unschärfe in den Daten zusammengefasst, nichtsdestoweniger muss ein Straßenschild im Regen genauso gut erkannt werden wie bei Sonnenschein. Die Labels, also die korrekten Bezeichnungen, für derartige Daten werden üblicherweise manuell zugewiesen. Dieses korrekte Set aus Eingangsvariablen und deren korrekter Klassifikation machen einen Trainingsdatensatz aus. Obwohl wir in diesem Fall je Trainingsdatensatz nur ein Bild haben, sprechen wir von mehreren Eingangsvariablen, da ML-Algorithmen relevante Eigenschaften (Features) in den Trainingsdaten finden und den Zusammenhang zwischen diesen Features und der Klassenzuordnung für die im Beispiel angeführte Klassifikationsaufgabe lernen. Überwachtes Lernen wird hauptsächlich zur Vorhersage von numerischen Werten (Regression) und Klassifikation (Vorhersage einer Klassenzugehörigkeit) eingesetzt, wobei die Daten nicht auf ein bestimmtes Format beschränkt sind; die Verarbeitung von Bildern, Audiodateien, Videos, numerischen Daten und Text stellt für ML-Algorithmen kein Problem dar. Einige Beispiele für Klassifikation sind etwa Objekterkennung (Straßenschilder, Objekt vor dem Fahrzeug, etc.), Gesichtserkennung, Kreditrisikobewertung, Stimmenerkennung, Kundenabwanderung, um nur einige zu nennen.
Beispiele für Regression sind etwa die Ermittlung von kontinuierlichen, numerischen Werten auf mehreren (teils hunderten oder tausenden) Eingangsvariablen, wie etwa der optimalen Geschwindigkeit basierend auf Straßen- und Umweltverhältnissen in einem autonom agierenden Fahrzeug, die Ermittlung einer Finanzkennzahl wie etwa das Bruttoinlandsprodukt basierend auf einer veränderlichen Anzahl von Eingangsvariablen (Nutzung von Agrarflächen, Bildungsstand einer Population, Industrieproduktion, …) oder die Ermittlung von potenziellen Marktanteilen durch die Einführung neuer Modelle. Jede dieser Fragestellungen ist hochkomplex und kann nicht durch simple, lineare Zusammenhänge in einfache Gleichungen gefasst werden; oder um es noch herausfordernder auszudrücken: die erforderliche Expertise existiert gar nicht.
Unüberwachte Lernalgorithmen
Unüberwachte Lernverfahren greifen keine einzelnen Zielvariablen heraus, sondern es wird das Ziel verfolgt, eine generelle Charakterisierung eines Datensatzes zu erlangen. Häufig werden unüberwachte ML-Algorithmen eingesetzt, um Datensätze zu gruppieren (clustern), also Zusammenhänge zwischen einzelnen Datenpunkten (die sich aus einer beliebig hohen Anzahl von Attributen zusammensetzen können) zu finden und diese zu Gruppen (Clustern) zusammenzuführen. Der Output von unüberwachten ML-Algorithmen kann in einigen Fällen wiederum als Input für überwachte Verfahren verwendet werden. Beispiele für unüberwachtes Lernen sind etwa die Bildung von Kundengruppen basierend auf Kaufverhalten oder demografischen Daten, oder das Zeitreihenclustering, etwa um Millionen von Zeitreihen aus Sensoren zu vorher nicht offensichtlichen Gruppen zusammenzufassen.
Maschinelles Lernen (ML) ist also der Teil der künstlichen Intelligenz (KI), in welchem es Computern ermöglicht wird, zu lernen, ohne explizit programmiert worden zu sein. Im maschinellen Lernen konzentriert man sich auf die Entwicklung von Programmen, die es sich selbst beibringen zu wachsen und sich zu verändern, sobald neue Daten bereitgestellt werden. Prozesse, die als Flussdiagramm abgebildet werden können, sind demnach keine Kandidaten für Maschinenlernen – alles was hingegen dynamische, sich veränderliche Lösungsstrategien erfordert und nicht auf statische Regeln beschränkt werden kann, ist potenziell geeignet, um mit ML gelöst zu werden. ML wird etwa verwendet, wenn:
- Menschliche Expertise nicht existiert.
- Menschen ihre Expertise nicht ausdrücken können.
- Die Lösung sich über der Zeit verändert.
- Die Lösung auf spezifische Fälle angepasst werden muss.
Im Unterschied zur Statistik, die die Inferenz von einem Sample verfolgt, ist man in der Informatik daran interessiert, effiziente Algorithmen zur Lösung von Optimierungsproblemen sowie eine Repräsentation des Modells zur Evaluierung von Inferenz zu entwickeln. Häufig verwendete Verfahren für die Optimierung sind in diesem Zusammenhang sog. evolutionäre Algorithmen (genetische Algorithmen, Evolutionsstrategien), deren Grundprinzipien der natürlichen Evolution nachempfunden sind. [6] Diese Verfahren sind in der Anwendung auf komplexe nichtlineare Optimierungsprobleme sehr effizient.
ML ist nicht gleich Data Mining, obwohl ML in diesem Bereich Anwendung findet – Ziel von beiden ist es, in Daten nach Mustern zu suchen. Anstatt Daten für das menschliche Verständnis zu extrahieren, wie es im Data Mining der Fall ist, werden ML-Verfahren angewendet, um das eigene Verständnis eines Programms über die bereitgestellten Daten zu verbessern. Software, die ML-Verfahren implementiert, erkennt Muster in Daten und kann das darauf basierende Verhalten dynamisch anpassen. Wenn etwa ein autonom agierendes Fahrzeug (oder die Software, die die visuellen Signale der Kamera interpretiert) dazu trainiert wurde, bei vor dem Fahrzeug auftauchenden Passanten ein Bremsmanöver einzuleiten, muss das mit allen Passanten funktionieren, sowohl mit kleinen, großen, dicken, dünnen, verkleideten, von links kommenden, von rechts kommenden, etc. Das Fahrzeug soll im Gegenzug nicht bei einer am Straßenrand stehenden Mülltonne bremsen.
Die Komplexität in der Welt wird oft größer sein als die Komplexität eines ML-Modells, womit in den meisten Fällen versucht wird, Probleme in Sub-Probleme zu unterteilen und ML-Modelle auf diese Sub-Probleme anzuwenden. Der Output dieser Modelle wird dann integriert, um komplexe Aufgaben wie etwa autonomes Agieren von Fahrzeugen in strukturierten und unstrukturierten Umgebungen zu erlauben.
3.2 Computer Vision
Computer Vision (CV) ist ein sehr breites Forschungsfeld, in dem wissenschaftliche Theorien aus unterschiedlichen Feldern (wie so oft in der KI) zusammengeführt werden, angefangen bei Biologie, Neurowissenschaften und Psychologie bis hin zur Informatik, Mathematik und Physik. Zu Anfang ist wichtig, wie ein Bild physikalisch entsteht. Bevor Licht in einem zweidimensionalen Array auf Sensoren auftrifft, wird es gebrochen, absorbiert, gestreut oder reflektiert, und ein Bild entsteht, wenn durch die Messung der Intensität der Lichtstrahlen durch jedes Element im Bild (Pixel). Die drei grundlegenden Perspektiven auf CV sind:
- Die Rekonstruktion einer Szene und des Punktes, von dem aus die Szene betrachtet wird, basierend auf einem Bild, einer Bildsequenz oder eines Films.
- Die Nachahmung von biologischer, optischer Wahrnehmung, um besser zu verstehen, welche physischen und biologischen Vorgänge involviert sind, wie die Wetware funktioniert, und wie die Interpretation und das Verständnis funktionieren.
- In der technischen Forschung und Entwicklung liegt die Konzentration auf effizienten, algorithmischen Lösungen – in CV-Software werden häufig problemspezifische Lösungen entwickelt, die mit der optischen Wahrnehmung bei biologischen Organismen nur bedingt Gemeinsamkeiten haben.
Alle drei haben Überschneidungen und beeinflussen sich untereinander. Wird Wert auf die Hinderniserkennung gelegt, um bei einem vor dem Fahrzeug auftauchenden Passanten ein automatisiertes Bremsmanöver einzuleiten, ist es in erster Linie wichtig, den Passanten als Hindernis zu erkennen; eine Interpretation der gesamten Szene, wie etwa das Verständnis, dass das Fahrzeug sich auf eine Familie zubewegt, die ein Picknick auf einer Wiese macht, ist in diesem Fall nicht erforderlich. Dahingegen ist das Verständnis einer Szene dann eine Voraussetzung, wenn Kontext einen relevanten Input darstellt, etwa bei der Entwicklung robotischer Haushaltsgehilfen, die sehr wohl verstehen müssen, dass ein am Boden liegender Hausbewohner nicht nur ein zu umgehendes Hindernis ist, sondern aller Wahrscheinlichkeit nach nicht schläft und es sich um einen medizinischen Notfall handelt.
Sicht in einem biologischen Organismus wird als aktiver Prozess verstanden, der die Kontrolle des Sensors beinhaltet und eng an die erfolgreiche Durchführung einer Aktion gebunden ist. [7] Als Folge [8] sind CV-Systeme daher ebenfalls nicht passiv, das heißt, das System muss
- kontinuierlich mit Daten über Sensoren versorgt werden (Streaming) und
- basierend auf diesem Datenstrom agieren.
Davon abgesehen ist das Ziel von CV-Systemen nicht das Verstehen von Szenen in Bildern – es muss in erster Linie die relevante Information für eine bestimmte Aufgabe aus der Szene extrahiert werden. Vielmehr muss eine „region of interest“ ermittelt werden, die zur Verarbeitung herangezogen wird. Schließlich muss das System eine kurze Antwortzeit haben, da es wahrscheinlich ist, dass eine Szene sich über der Zeit verändert und eine stark verzögert ausgeführte Aktion nicht den gewünschten Effekt erzielt. Zur Objekterkennung („was“ befindet sich „wo“ in einer Szene) wurden viele unterschiedliche Methoden vorgeschlagen, unter anderem:
- Objektdetektoren, wobei in diesem Fall ein Fenster über das Bild bewegt und für jede Position eine Filter-Reaktion durch Abgleich von Template und Sub-Bild (Fensterinhalt) ermittelt wird, wobei jede neue Objektparametrierung einen separaten Scan erfordert. Anspruchsvollere Algorithmen rechnen gleichzeitig auf unterschiedlichen Skalen und wenden Filter an, die von einer großen Anzahl von Bildern gelernt wurden.
- Segmentbasierte Techniken extrahieren eine geometrische Beschreibung eines Objekts durch Gruppieren von Pixeln, welche die Ausdehnung eines Objekts in einem Bild definieren. Darauf basierend wird ein unveränderliches Featureset berechnet, das heißt, die darin enthaltenen Features behalten dieselben Werte unter diversen Bildtransformationen wie etwa Veränderung der Lichtverhältnisse, Skalierung oder Rotation. Diese Features werden herangezogen, um Objekte oder Objektklassen eindeutig zu identifizieren. Ein Beispiel ist die vorhin erwähnte Identifikation von Straßenschildern.
- Ausrichtungsbasierte Methoden nutzen parametrische Objektmodelle, die auf Daten trainiert werden. [9], [10] Algorithmen suchen nach Parametern wie Skalierung, Translation oder Rotation, die ein Modell optimal auf korrespondierende Features im Bild anpassen, wobei eine angenäherte Lösung durch einen reziproken Prozess gefunden werden kann, also etwa indem Features wie Konturen, Ecken oder andere, charakteristische Punkte im Bild für Parameterlösungen „wählen“, die kompatibel mit dem gefundenen Feature sind.
Bei der Objekterkennung muss entschieden werden, ob Algorithmen auf 2D- oder 3D-Repräsentationen von Objekten arbeiten sollen, wobei sehr oft 2D-Repräsenationen einen guten Kompromiss zwischen Genauigkeit und Verfügbarkeit darstellen. Die aktuelle Forschung (Deep Learning) zeigt, dass sogar Distanzen zwischen zwei Punkten basierend auf zwei 2D-Bildern, aufgenommen von unterschiedlichen Punkten, als Input akkurat ermittelt werden können. Bei Tageslicht und halbwegs guten Sichtverhältnissen kann dieser Input zusätzlich zu Daten aus Laser und Radar herangezogen werden, um die Genauigkeit zu erhöhen – zudem ist eine Kamera ausreichend, um die benötigten Daten zu generieren. Im Unterschied zu 3D-Objekten werden in 2D-Bildern keine Informationen wie Form, Tiefe oder Ausrichtung direkt enkodiert. Tiefenenkodierung kann auf vielfältige Art passieren, wie etwa Laser oder Stereokameras (wie bei uns Menschen) und strukturiertes-Licht-Ansätzen (wie Kinect). Die momentan am intensivsten verfolgte Forschungsrichtung betrifft Superquadrate – geometrische Formen definiert über Formeln, die beliebige Exponenten nutzen, um Strukturen wie Zylinder, Würfel und Kegel mit runden oder scharfen Ecken zu ermitteln. Mit einem kleinen Set aus Parametern kann eine große Vielfalt an unterschiedlichen Basisformen beschrieben werden. Werden 3D-Bilder über Stereokameras ermittelt, werden, bedingt durch die im Vergleich mit Laserscans schlechtere Datenqualität, statistische Methoden (wie die Generierung einer Stereo-Punktwolke) anstelle der vorhin angesprochenen Form-Methoden angewandt.
Weiterführende Forschung wird hinsichtlich Tracking [11],[12], kontextuellem Szenenverständnis [13],[14] und Überwachung [15] betrieben, allerdings sind diese aktuell für die Automobilindustrie von sekundärer Relevanz.
3.3 Schließen und Entscheidungsfindung
In der Literatur als „Knowlege Representation & Reasoning“ (KRR) bekannt, liegt in diesem Forschungsfeld der Schwerpunkt auf dem Design und der Entwicklung von Datenstrukturen und Inferenzalgorithmen. Probleme, die über Schließen gelöst werden, werden sehr häufig in Anwendungen gefunden, die Interaktion mit der physischen Welt (etwa Menschen) erfordern, wie etwa das Erstellen von Diagnosen, planen, Verarbeitung von natürlicher Sprache, Beantwortung von Fragen, etc. KRR bildet die Grundlage für KI auf menschlichem Niveau.
Schließen ist das Feld aus KRR, in dem datenbasierte Antworten ohne menschliche Intervention oder Hilfe gefunden werden müssen, wobei die Daten üblicherweise in einem formellen System mit eindeutiger und klarer Semantik präsentiert werden. Seit etwa 1980 geht man davon aus, dass die involvierten Daten eine Mixtur aus einfachen und komplexen Strukturen sind, wobei sich die ersteren in einem niedrigen Grad von Berechnungskomplexität befinden und Forschungsgrundlage für große Datenbanken bilden. Letztere werden in einer ausdrucksstärkeren Sprache präsentiert, welche weniger Platz zur Repräsentation benötigt, und korrespondieren mit Generalisierungen und fein-granularer Information.
Entscheidungsfindung ist eine Art von Schließen, in der die Beantwortung von Fragen über Präferenzen zwischen Aktivitäten im Vordergrund steht, etwa wenn ein autonom agierender Agent versucht, eine Aufgabe für einen Menschen zu erfüllen. Sehr oft passiert diese Entscheidungsfindung in einer dynamischen Domäne, die sich durch die Ausführung von Aktionen und dem Ablauf von Zeit verändert. Ein Beispiel ist das autonom agierende Fahrzeug, das auf Veränderungen im Verkehr reagieren muss.
Logik und Kombinatorik
Mathematische Logik ist die formale Basis vieler Applikationen in der realen Welt, wie der Berechnungstheorie, unser Gesetzessystem und diesbezügliche Argumentationen, und theoretische Entwicklungen und Beweise hinsichtlich Forschung und Entwicklung. Die anfängliche Vision war, jede Art von Wissen in Form von Logik abzubilden und darüber mit universellen Algorithmen zu schließen, wobei einige Herausforderungen aufgetreten sind; etwa ist nicht jede Art von Wissen einfach zu repräsentieren. Zudem kann es sehr komplex werden, das für Applikationen benötigte Wissen für komplexe Applikationen zu kompilieren, und zudem ist es nicht einfach, dieses Wissen in einer ausdrucksstarken, logischen Sprache zu lernen. [16] Außerdem ist es nicht einfach mit der erforderlichen, ausdrucksstarken Sprache zu schließen – im Extremfall ist ein derartiges Szenario rechnerisch nicht umsetzbar, sogar wenn die ersten beiden Herausforderungen gelöst werden können. Aktuell werden drei Debatten diesbezüglich geführt, und zwar steht an erster Stelle die Aussage, dass Logik viele Konzepte nicht repräsentieren kann, etwa Raum, Analogie, Form, Unsicherheit, etc. und deshalb kann sie nicht als aktiver Part in der Entwicklung einer KI auf menschlichem Niveau gezählt werden. Das Gegenargument lautet, dass Logik nur eines von vielen Werkzeugen ist. Momentan wird die Kombination von repräsentativer Aussagekraft, Flexibilität und Klarheit mit keiner anderen Methode oder anderem System erreicht. Die zweite Debatte dreht sich um die Aussage, dass Logik zu langsam für Inferenz ist und daher niemals eine Rolle in einem produktiven System spielen wird. Das Gegenargument hier ist, dass Wege zur Approximation von Inferenz mit Logik existieren, sodass die Verarbeitung sich den zeitlichen Limits annähert und Fortschritte hinsichtlich logischer Inferenz gemacht werden. Die dritte Debatte dreht sich um das Argument, dass es extrem schwierig oder gar unmöglich ist, Systeme aus logischen Axiomen in Anwendungen der realen Welt zu entwickeln. Die Gegenargumente basieren hauptsächlich auf der Forschung jener, die aktuell nach Techniken zum Lernen von logischen Axiomen aus natürlichsprachlichen Texten forschen.
Grundsätzlich wird zwischen vier verschiedenen Typen von Logik [17] unterschieden, die hier nicht weiter diskutiert werden:
- Aussagenlogik
- Prädikatenlogik erster Stufe
- Modale Logik
- Nichtmonotone Logik
An dieser Stelle sei noch die automatisierte Entscheidungsfindung erwähnt, etwa autonom agierende Roboter (Fahrzeuge), WWW-Agenten oder Kommunikationsagenten betreffend, speziell auch wenn es darum geht, Entscheidungsfindungsprozesse von Experten in Logik abzubilden und zu automatisieren. Sehr oft berücksichtigt ein solcher Entscheidungsprozess die Dynamik in der umgebenden Welt, etwa wenn ein Transportroboter in einer Produktionsanlage einem anderen ausweichen muss. Das ist jedoch keine Grundvoraussetzung, etwa wenn ein Entscheidungsprozess ohne klar definierte Richtung in der Zukunft vorgenommen wird, z.B. die Entscheidung, eine Lagerhalle zu einem spezifischen Preis an einem spezifischen Ort zu mieten. Die Entscheidungsfindung als Forschungsbereich umfasst mehrere Domänen, wie Informatik, Psychologie, Wirtschaft und alle ingenieurswissenschaftlichen Disziplinen. Einige grundsätzliche Fragen müssen zur Entwicklung von automatisierten Entscheidungsfindungssystemen geklärt werden:
- Ist die Domäne insofern dynamisch, als dass eine Folge von Entscheidungen erforderlich ist oder statisch, so dass eine einzelne oder mehrere gleichzeitige Entscheidungen getroffen werden müssen?
- Ist die Domäne deterministisch, nicht deterministisch oder gar stochastisch?
- Wird versucht, Nutzen zu optimieren oder ein Ziel zu erreichen?
- Ist die Domäne zu jeder Zeit voll umfänglich oder lediglich teilweise bekannt?
Logische Entscheidungsfindungsprobleme sind nicht-stochastischer Natur, was Planung und konfliktäres Verhalten umfasst. Beide erfordern es, dass die vorliegenden Informationen über die initialen und zwischenliegenden Zustände komplett sind, dass Aktionen ausschließlich deterministische, bekannte Auswirkungen haben und dass es eine spezifische Zieldefinition gibt. Diese Problemtypen finden in der realen Welt häufig Anwendung, wie etwa bei der Kontrolle von Robotern, in der Logistik, komplexem Verhalten im WWW, und der Computer- und Netzwerksicherheit.
Generell umfasst ein Planungsproblem eine initiale (bekannte) Situation, eine Zieldefinition und ein Set von erlaubten Aktionen oder Übergängen zwischen den Schritten. Das Ergebnis eines Planungsprozesses ist eine Sequenz oder eine Menge von Aktionen, deren korrekte Ausführung den Ausführenden von einem initialen Zustand in einen Zustand versetzt, der die Zielbedingungen erfüllt. Planen ist rechnerisch ein schwieriges Problem, sogar wenn einfache Problemspezifikationssprachen eingesetzt werden. Die Suche nach einem Plan kann praktisch auch bei einfacheren Problemen nicht den gesamten Zustandsraumgraphen durchlaufen, weil dieser exponentiell groß in der Zahl der Zustände, welche die Domäne definieren, ist. Daher wird versucht, effiziente Algorithmen zu entwickeln, die Teilgraphen abbilden, um diese in der Hoffnung, das Ziel zu erreichen, zu durchsuchen. Die aktuelle Forschung zielt auf die Entwicklung von neuen Suchmethoden und neuen Repräsentationen für Aktionen und Zuständen, die leichteres Planen erlauben, ab. Speziell wenn man einen oder mehrere gegeneinander agierende Agenten berücksichtigt, gilt es, eine Balance zwischen Lernen und Entscheiden zu finden – Exploration dem Lernen zuliebe, während Entscheidungen getroffen werden, kann zu einem unerwünschten Ergebnis führen.
Viele Probleme in der realen Welt sind Probleme, deren Dynamik stochastischer Natur ist. Der Kauf eines Fahrzeugs, dessen Eigenschaften uns unbekannt sind und dessen Wert beeinflussen, ist ein Beispiel dafür. Diese Abhängigkeiten beeinflussen die Kaufentscheidung und es ist daher erforderlich, Risiken und Unsicherheiten einfließen zu lassen. Stochastische Domänen sind praktisch schwieriger hinsichtlich Entscheidungsfindung, aber auch flexibler hinsichtlich Approximationen als deterministische Domänen – die Vereinfachung von praktischen Annahmen macht automatisierte Entscheidungsfindung auch praktisch möglich. Es existieren sehr viele Problemformulierungen, die unterschiedliche Aspekte und Entscheidungsfindungsprozesse in stochastischen Domänen abbilden können, wobei die bekanntesten Entscheidungsnetzwerke und Markov Entscheidungsprozesse sind.
Viele Anwendungen erfordern die Kombination von logischen (nicht-stochastischen) und stochastischen Elementen, etwa wenn die Kontrolle von Robotern High-Level-Spezifikationen in Logik und Low-Level-Repräsentationen hinsichtlich eines probabilistischen Sensormodells erfordert. Die Verarbeitung von natürlicher Sprache ist ein weiteres Gebiet, auf welches diese Annahme zutrifft, da High-Level-Wissen in Logik mit probabilistischen Low-Level-Modellen von Text und gesprochenen Signalen kombiniert wird.
3.4 Sprache und Kommunikation
Die Verarbeitung von Sprache wird in der künstlichen Intelligenz als grundlegend betrachtet, wobei zwischen zwei Feldern unterschieden wird: Komputationale Linguistik (Computational Linguistics, CL) und Verarbeitung von natürlicher Sprache (Natural Language Processing, NLP). Zusammengefasst ist der Unterschied, dass in der CL Forschung zur Nutzung von Computern zur Sprachverarbeitung betrieben wird, wobei NLP aus allen Applikationen besteht, wie etwa maschineller Übersetzung (machine translation, MT), Q&A, Dokumentenzusammenfassung, Informationsextrak-tion, um nur einige zu nennen. NLP erfordert also eine konkrete Aufgabe und ist nicht per se eine Forschungsdisziplin. NLP umfasst:
- Part-of-Speech-Tagging
- Natürliches Sprachverständnis
- Natürliche Sprachgenerierung
- Automatische Zusammenfassung
- Entitätenerkennung
- Parsing
- Spracherkennung
- Sentiment-Analyse
- Sprach-, Themen- und Wortsegmentierung
- Co-Referenz-Auflösung
- Diskursanalyse
- Maschinenübersetzung
- Wortbedeutungsdisambiguierung
- Morphologische Segmentierung
- Antworten auf Fragen
- Beziehungsextraktion
- Satzteilung
Die zentrale Vision der KI besagt, dass eine Version von erster-Ordnung Prädikatenlogik (first-order predicate calculus, FOPC), unterstützt durch für die jeweilige Problemstellung erforderliche Mechanismen, für die Repräsentation von Sprache und Wissen ausreichend ist. Diese These besagt, dass Logik die natürlicher Sprache unterliegende Semantik liefern kann und soll. Obwohl Versuche in der KI und Linguistik, eine Form der logischen Semantik als Schlüssel zur Repräsentation von Inhalten zu verwenden fortgeschritten sind, wurden diese hinsichtlich eines Programms, welches Englisch in formale Logik übersetzt, von geringem Erfolg gekrönt. Auch in der Psychologie wurde bis dato kein Beweis erbracht, dass eine derartige Übersetzung in Logik mit der Art und Weise, in der Menschen „Bedeutung“ speichern und manipulieren, korrespondiert. Die Übersetzung einer Sprache in FOPC ist daher aktuell noch ein Ziel, das nicht erreicht wurde. Zweifellos gibt es NLP-Anwendungen, welche logische Inferenzen zwischen Satzrepräsentationen etablieren müssen, aber wenn diese ausschließlich einen Teil einer Anwendung ausmachen, ist es nicht offensichtlich, dass sie etwas mit der unterliegenden Bedeutung der natürlichen Sprache (und dadurch mit CL/NLP) zu tun haben, da die originäre Aufgabe logischer Strukturen Inferenz war. Unterschiedliche Positionen haben sich herauskristallisiert:
- Position 1: Logische Inferenzen sind aufs Engste mit der Bedeutung von Sätzen verbunden, da deren Bedeutung zu kennen gleich dem Ableiten von Inferenzen ist, und Logik ist der beste Weg, das zu tun.
- Position 2: Es existiert eine Bedeutung außerhalb der Logik, welche eine Anzahl von semantischen Markern oder Primitiven postuliert, die an Worte gehängt werden, um deren Bedeutung auszudrücken – das ist uns heute als Annotation geläufig.
- Position 3: Die Prädikate der Logik und formale Systeme erscheinen generell lediglich unterschiedlich zu menschlicher Sprache, aber deren Termini sind faktisch die Wörter als die sie erscheinen.
Die Einführung von statistischen und KI-Methoden ins Feld ist der diesbezüglich letzte Trend. Die generelle Strategie ist es, zu lernen, wie Sprache verarbeitet wird, idealerweise in der Art, in der Menschen das tun, wobei das keine Grundvoraussetzung darstellt. Hinsichtlich ML bedeutet das Lernen basierend auf sehr großen Corpora, die von Menschen manuell übersetzt wurden. Das bedeutet oft, dass (algorithmisch) gelernt werden muss, wie Annotationen zugewiesen werden, wie Coropora mit part-of-speech Kategorien (Zuordnung von Wörtern und Satzzeichen eines Textes zu Wortarten) oder semantischen Markern oder Primitiven versehen werden, und das basierend auf von Menschen vorbereiteten (und daher korrekten) Corpora. Im überwachten Lernen und bezogen auf ML können etwa mögliche Assoziationen von part-of-speech-Tags mit Wörtern, die von Menschen auf den Text annotiert wurden, gelernt werden, so dass die Algorithmen neue, bis dato nicht bekannte Texte, ebenfalls annotieren können. [18] Das funktioniert genauso schwach überwacht oder unüberwacht, etwa wenn von Menschen keine Annotationen vorgenommen wurden und lediglich ein Text in einer Sprache mit inhaltlich identischen Texten in anderen Sprachen als Daten präsentiert werden oder gar relevante Cluster in Thesaurus-Daten gefunden werden, ohne ein Ziel definiert zu haben. [19] In Bezug auf KI und Sprache spielen Information Retrieval (IR) und Information Extraction (IE) eine große Rolle, wobei diese sehr stark zueinander korrelieren. Eine der Hauptaufgaben von IR ist die Gruppierung von Texten basierend auf deren Inhalt, wobei IE faktenähnliche Elemente aus Texten extrahiert, oder genutzt wird, um Fragen über Textinhalte beantworten können. Diese Felder korrelieren deshalb stark zueinander, da einzelne Sätze (nicht nur Langtexte) auch als Dokumente betrachtet werden können. Anwendung finden diese Methoden zum Beispiel bei Interaktionen von Usern mit Systemen, etwa wenn ein Fahrer dem Bordcomputer während der Fahrt eine Frage zum Betriebshandbuch stellt – nachdem der sprachliche Input in Text konvertiert wurde, wird basierend auf dem semantischen Inhalt der Frage nach einer Antwort im Handbuch gesucht und diese dann extrahiert und zurückgegeben.
3.5 Agenten und Aktionen
In der klassischen KI konzentrierte man sich hauptsächlich auf einzelne, isolierte Softwaresysteme, die relativ unflexibel auf vordefinierten Regeln agierten. Neue Technologien und Anwendungen haben die Anforderung nach künstlichen Entitäten geschaffen, die flexibler, adaptiver undautonomer sind und als soziale Einheiten in Multi-Agentensystemen agieren. In der klassischen KI (s.a. „Physical Symbol System Hypothesis“ [20], die in sogenannte „abwägende“ Systeme eingebettet wurde) wird in Einzelsystemen, die Aktionen ausführen müssen, eine Aktionstheorie, also wie Systeme Entscheidungen treffen und agieren, logisch dargestellt. Das System muss, basierend auf diesen Regeln, ein Theorem beweisen – Voraussetzung hierbei ist, dass dieses eine Beschreibung der Welt, in der es sich aktuell befindet, den gewünschten Zielzustand und ein Set von Aktionen, zusammen mit Voraussetzungen zur Ausführung von diesen und einer Liste mit den Resultaten einer jeden Aktion, erhält. Es hat sich herausgestellt, dass schon bei einfachen Problemstellungen durch die rechnerische Komplexität jedes zeitlich beschränkte System unbrauchbar ist, was einen großen Einfluss auf die symbolische KI hatte, resultierend in der Entwicklung von reaktiven Architekturen. Solche folgen Wenn-Dann-Regeln, welche Eingaben direkt in Aufgaben umsetzen. Derartige Systeme sind extrem simpel, dennoch können sie sehr komplexe Aufgaben lösen. Was ein Problem darstellt ist, dass derartige Systeme Prozeduren, aber kein deklaratives Wissen lernen, das heißt, sie lernen Attribute, die nicht einfach auf ähnliche Situationen generalisieren können. Es gab viele Versuche, abwägende und reaktive Systeme zu kombinieren, allerdings scheint es, als müsse man sich entweder auf unpraktische, abwägende Systeme konzentrieren oder aber auf sehr lose entwickelte reaktive Systeme – beides ist nicht optimal.
Prinzipien des neuen, agentenzentrierten Ansatzes
Der agentenorientiert Ansatz ist durch die folgenden Prinzipien charakterisierbar:
- Autonomes Verhalten:
Autonomie beschreibt die Fähigkeit von Systemen, ihre eigenen Entscheidungen zu treffen und Aufgaben in Vertretung des Systemdesigners auszuführen. Ziel ist, in Szenarien, in welchen es schwierig ist, ein System direkt zu kontrollieren, es autonom agieren zu lassen. Klassische Softwaresysteme führen Methoden aus, nachdem diese aufgerufen worden sind – sie haben keine Wahl; Agenten hingegen entscheiden nach ihren Ansichten, Wünschen und Absichten (Belief, Desire, Intention, BDI). [21]
- Adaptives Verhalten:
Da es unmöglich ist, alle Situationen, auf welche Agenten treffen, vorherzusagen, müssen diese flexibel agieren können. Sie müssen von und aus ihrer Umgebung lernen und sich anpassen können. Diese Aufgabe wird umso schwieriger, wenn nicht nur die Natur eine Quelle der Unsicherheit ist, sondern der Agent sich zudem in einem Multiagentensystem befindet. Ausschließlich Umgebungen, die nicht statisch und geschlossen sind, erlauben sinnhafte Anwendungsszenarien für BDI-Agenten – etwa kann durch Reinforcement Learning fehlendes Wissen über die Welt ausgeglichen werden. Agenten befinden sich dabei in einer Umgebung, die durch ein Set an möglichen Zuständen beschrieben wird. Jedes Mal, wenn ein Agent eine Aktion ausführt, wird er mit einem numerischen Wert „belohnt“, der ausdrückt, wie gut oder schlecht seine Aktion war. Das führt zu einer Reihe von Zuständen, Aktionen und Belohnungen. Der Agent ist nun angehalten, ein Vorgehen zu ermitteln, welches eine Maximierung der Belohnung nach sich zieht.
- Soziales Verhalten:
In einer Umgebung, in welcher unterschiedliche Entitäten agieren, ist es erforderlich, dass Agenten ihre Gegner erkennen und Gruppen bilden, sofern ein gemeinsames Ziel das erfordert. Agentenorientierte Systeme werden zur Personalisierung von User Interfaces, als Middleware und in Wettkämpfen, wie etwa dem RoboCup eingesetzt. In einem Szenario, in welchem ausschließlich autonom agierende Fahrzeuge auf den Straßen unterwegs sind, ist nicht nur Autonomie des einzelnen Agenten, sondern car2car-Kommunikation, also das Austauschen von Informationen zwischen Fahrzeugen und das darauf basierende Agieren als Gruppe ein unverzichtbarer Bestandteil. Durch Abstimmung zwischen den Agenten wird der Verkehrsfluss optimiert – Staus und Unfälle werden praktisch unmöglich (s.a. 5.1 Fahrzeuge als autonome, adaptive und soziale Agenten & die Stadt als Superagent).
Zusammenfassend gilt, dass der agentenorientierte Ansatz als zukunftsweisende Richtung in der KI-Community akzeptiert wird.
Multi-Agenten-Verhalten
Es werden unterschiedliche Ansätze verfolgt, um Multi-Agenten-Verhalten zu implementieren, wobei diese sich hauptsächlich dahingehend unterscheiden, wie viel Kontrolle der Designer über einzelne Agenten hat. [22],[23],[24] Es wird unterschieden zwischen
- verteilten Problemlösungssystemen (Distributed Problem Solving systems, DPS) und
- Multi-Agentensystemen (Multi-agent systems, MAS)
DPS erlauben dem Designer, jeden individuellen Agenten in der Domäne zu kontrollieren, wobei die Lösung der Aufgabe auf mehrere Agenten verteilt wird. Bei MAS hingegen gibt es mehrere Designer, und jeder kann nur seine eigenen Agenten beeinflussen und hat keinen Zugriff auf das Design aller anderen Agenten. In diesem Fall sehr wichtig ist das Design der Interaktionsprotokolle. In DPS versuchen Agenten, gemeinsam ein Ziel zu erreichen oder eine Aufgabe zu lösen, wohingegen bei MAS jeder Agent individuell motiviert wird und sein eigenes Ziel erreichen und seinen eigenen Benefit maximieren möchte. Die Forschung in DPS hat zum Ziel, Zusammenarbeitsstrategien zur Problemlösung unter Minimierung des Grades an Kommunikation zu erreichen. In MAS wird auf die koordinierte Interaktion geachtet, also wie die autonom agierenden Agenten dazu gebracht werden können, eine gemeinsame Kommunikationsbasis zu finden und einheitliche Aktionen vorzunehmen. [25] Idealerweise ist eine Welt, die ausschließlich von autonom agierenden Fahrzeugen befahren wird, ein DPS, allerdings wird durch die Konkurrenzsituation zwischen den OEMs zuerst ein MAS entstehen. Im Vordergrund werden also auch die Kommunikation und die Verhandlungen zwischen den Agenten stehen (s.a. Nash-equilibrium).
Multi-Agenten-Lernen
Dem Multi-Agenten-Lernen (MAL) wird erst seit relativ kurzer Zeit ein gewisser Grad an Aufmerksamkeit zuteil. [26],[27],[28],[29] Schlüsselprobleme sind etwa welche Techniken genutzt werden sollen und was genau Multi-Agenten-Lernen bedeutet. Aktuelle ML-Ansätze wurden entwickelt, um einzelne Agenten zu trainieren, wohingegen im MAL verteiltes Lernen im Vordergrund steht. Verteilt heißt nicht notwendigerweise, dass etwa ein neuronales Netz benutzt wird, in welchem während des Trainings viele identische Operationen ablaufen und diese daher parallelisiert werden können, sondern
- dass ein Problem in Subprobleme gesplittet wird und einzelne Agenten diese lernen, um über deren kombinierte Erkenntnisse das Hauptproblem lösen zu können oder
- viele Agenten unabhängig versuchen, das gleiche Problem zu lösen, indem sie gegeneinander konkurrieren.
Reinforcement Learning ist ein Ansatz, der diesbezüglich Anwendung findet. [30]
4 Data Mining und künstliche Intelligenz in der Automobilindustrie
Die Wertschöpfungskette in der Automobilindustrie kann auf einer hohen Abstraktionsebene grob mit den folgenden Teilprozessen beschrieben werden:
- Technische Entwicklung
- Einkauf
- Logistik
- Produktion
- Marketing
- Sales, After Sales und Retail
- Connected Customer
Jeder dieser Bereiche für sich ist bereits von erheblicher Komplexität, so dass die folgende Darstellung von Anwendungen des Data Mining und der künstlichen Intelligenz notwendigerweise auf einen Überblick beschränkt bleiben muss.
4.1 Technische Entwicklung
Die zu einem großen Teil virtuelle Fahrzeugentwicklung ist heute selbstverständlich für alle Hersteller Stand der Technik. CAD-Modelle und Simulation (typischerweise physikalischer Prozesse wie z.B. Mechanik, Strömung, Akustik, Schwingung, jeweils auf der Basis sogenannter Finite-Elemente-Modelle) finden in allen Phasen des Entwicklungsprozesses intensiv Verwendung.
Der Themenbereich Optimierung (häufig unter Verwendung von Evolutionsstrategien[31] oder genetischen Algorithmen und verwandten Methoden) ist meist weniger gut abgedeckt, obwohl sich hier gerade in der Entwicklung häufig beeindruckende Ergebnisse zeigen. Die Erweiterung auf die sogenannte multidisziplinäre Optimierung, bei der mehrere Entwicklungsdisziplinen (z.B. Insassensicherheit und NVH – noise, vibrations, harshness) miteinander gekoppelt und gleichzeitig optimiert werden, wird aufgrund der vermeintlich zu hohen Rechenzeitanforderungen heute vielfach noch kaum genutzt. Dabei bietet gerade dieser Ansatz großes Potenzial, abteilungsübergreifend in der Entwicklung schneller und effizienter zu einem gemeinsamen Auslegungsoptimum bzgl. der Anforderungen mehrerer Abteilungen zu kommen.
Hinsichtlich der Analyse und weiteren Nutzung von Simulationsresultaten wird heute bereits häufig Data Mining für die Erstellung sogenannter Response Surfaces verwendet – in dieser Anwendung wird mit Hilfe von Data Mining Verfahren (unter Nutzung des gesamten Spektrums, von linearen Modellen bis hin zu Gaußprozessen, support vector machines, und random forests) ein nichtlineares Regressionsmodell als Näherung für die Abbildung der Eingabevektoren für die Simulation auf die entsprechenden relevanten (numerischen) Simulationsresultate gelernt[32]. Da das Modell gute Interpolationseigenschaften aufweisen soll, werden zum Trainieren der Algorithmen typischerweise Kreuzvalidierungsverfahren verwendet, die es erlauben, die Vorhersagegüte des Modells für neue Eingabevektoren abzuschätzen. Das Ziel dieser Verwendung überwachter Lernverfahren besteht häufig darin, die rechenzeitintensive Simulation durch ein schnelles Approximationsmodell zu ersetzen, welches z.B. ein bestimmtes Bauteil repräsentiert und in einer weiteren Anwendung genutzt werden kann. Zudem können so zeitintensive Abstimmungsprozesse in der Entwicklung transparenter und schneller durchgeführt werden.
Ein Beispiel: Es ist wünschenswert, die umformtechnische Realisierbarkeit[33] von Geometrievariationen von Bauteilen im Rahmen einer abteilungsübergreifenden Besprechung sofort bewerten zu können, anstatt aufwendige Simulationen zu rechnen und erst nach Ablauf von ein bis zwei Tagen ein Ergebnis zu haben. Ein Response Surface Modell, das vorher aus Simulationen trainiert wurde, kann in einer derartigen Besprechung sofort eine sehr gute Näherung für das Risiko des Auftretens von zu hohen Ausdünnungen oder Reißern liefern, die für die Bewertung der Geometrie sofort verwendet werden kann.
Häufig sind diese Anwendungen auf spezifische Entwicklungsbereiche fokussiert bzw. auch beschränkt, was unter anderem darauf zurückzuführen ist, dass das Simulationsdatenmanagement als zentrale Schnittstelle zwischen der Generierung der Daten und der Verwendung und Analyse der Daten ein Engpass ist. Dies gilt vor allem dann, wenn an eine abteilungs-, varianten- und modellreihenübergreifende Nutzung von Simulationsdaten gedacht wird, die für eine wirkliche Nutzung der Daten im Sinne einer kontinuierlich lernenden Entwicklungsorganisation wesentlich sein wird. Die Praxis besteht heute oft darin, dass innerhalb einer Abteilung die abteilungsspezifischen Simulationsdaten in Form von Dateibäumen im jeweiligen Dateisystem organisiert sind, was sie einer Auswertung durch Methoden des maschinellen Lernens schwer zugänglich macht. Hinzu kommt, dass Simulationsdaten bereits für eine einzelne Simulation sehr umfangreich werden können (für neueste CFD-Simulationen bis in den Terabyte-Bereich) und daher effiziente Speicherkonzepte für eine Analyse durch Maschinelles Lernen dringend benötigt werden.
Während also die Simulation und die auf einzelne Anwendungen begrenzte Nutzung von nichtlinearen Regressionsmodellen heute Standard sind, werden die Möglichkeiten des Optimizing Analytics kaum genutzt. Gerade im Hinblick auf so wesentliche Themen wie das multidisziplinäre (also auch abteilungsübergreifende) maschinelle Lernen, das Lernen aus historischen Daten (mit anderen Worten, das Lernen aus heutigen Entwicklungsprojekten für zukünftige) und das modellübergreifende Lernen sind erhebliche Potenziale zur Effizienzsteigerung heute noch nicht einmal näherungsweise erschlossen.
4.2 Einkauf
Im Einkauf steht eine Vielzahl von Daten über Zulieferer, Einkaufspreise, Rabatte, Liefertreue, Stundensätze, ggf. auch Rohmaterialspezifikationen und weitere Größen zur Verfügung. Eine Berechnung von Kennzahlen für die Lieferantenbewertung und damit ein Ranking von Lieferanten sind damit heute problemlos möglich. Mittels Methoden des Data Mining können die verfügbaren Daten genutzt werden, um beispielsweise Prognosen zu erstellen, wesentliche Charakteristika von Lieferanten zu identifizieren, die die Performanzkriterien am stärksten beeinflussen, oder auch die Liefertreue zu prognostizieren. Im Sinne des Optimizing Analytics stellt sich auch hier die Frage nach denjenigen Parametern, die seitens des Automobilherstellers beeinflussbar sind, um optimale Bedingungen zu erzielen.
Der Unternehmensbereich Finance stellt insgesamt ein sehr gutes Feld für Optimizing Analytics dar, denn die Datenbestände enthalten Informationen über die wesentlichen Erfolgskomponenten der Unternehmung. Exemplarisch sei nur kurz das Gebiet des sog. continuous monitoring[34] genannt, hier auf Controlling bezogen. Das Monitoring basiert auf Daten aus Finance und Controlling, die kontinuierlich aufbereitet und berichtet werden. Im Sinne von predictive Analytics könnten diese auch genutzt werden, um Prognosen über die nächste Woche oder den nächsten Monat automatisch zu erstellen. Im Sinne von Optimizing Analytics können den Prognosen auch Analysen der wesentlichen Einflussparameter sowie optimierende Maßnahmenvorschläge hinzugefügt werden.
Diese Themenbereiche sind heute mehr Vision als Realität, vermitteln aber eine Idee davon, was in den Bereichen Einkauf, Finance und Controlling möglich wäre.
4.3 Logistik
Im Logistikbereich kann zwischen Beschaffungslogistik, Produktionslogistik, Distributionslogistik und Ersatzteillogistik unterschieden werden.
In der Beschaffungslogistik wird die Prozesskette vom Wareneinkauf bis zum Transport des Materials zum Eingangslager betrachtet. Im Wareneinkauf sind für das Data Mining eine Vielzahl historischer Preisinformationen verfügbar, die für die Erstellung von Preisprognosen und, verknüpft mit Daten über die Liefertreue, Analysen der Performanz von Zulieferern verwendet werden können. Hinsichtlich des Transports können durch Optimizing Analytics die wesentlichen Kostenfaktoren identifiziert und optimiert werden.
Ähnliches gilt für die Produktionslogistik, die sich mit der Planung, Steuerung und Kontrolle der innerbetrieblichen Transport-, Umschlag- und Lagerprozesse befasst. Je nach Granularität der verfügbaren Daten können hier z.B. Engpässe identifiziert, Lagerbestände optimiert und zeitliche Aufwände minimiert werden.
Die Distributionslogistik kümmert sich um alle Aspekte der Überführung der Produkte an die Kunden, wobei hier für OEMs sowohl Neuwagen als auch Gebrauchtwagen gemeint sein können. Da hier Kosten und Liefertreue im Vordergrund stehen, sind alle Teilkomponenten der multimodalen Lieferkette zu berücksichtigen, von der Bahn über Schiff und den Transport mit LkWs bis hin zu Teilaspekten wie der optimalen Kombination von einzelnen Fahrzeugen auf einem LkW. Hinsichtlich der Gebrauchtwagenlogistik kann durch Optimizing Analytics die Zuordnung von Fahrzeugen auf einzelne Verkaufskanäle (z.B. Auktionen, Internet) auf der Basis einer geeigneten, fahrzeugspezifischen Restwertprognose optimiert werden, so dass der Gesamtverkaufserlös maximiert wird. Dies wurde von GM in Kombination mit einer Prognose des jeweils zu erwartenden fahrzeugspezifischen Verkaufserlöses bereits 2003 umgesetzt[35].
In der Ersatzteillogistik, also der Bereitstellung von Ersatzteilen und deren Lagerhaltung, ist vor allem die datengetriebene Prognose der jeweiligen Anzahl vorzuhaltender Ersatzteile, in Abhängigkeit vom Modellalter und dem Modell (bzw. verkauftem Volumen) ein wesentlicher potenzieller Einsatzbereich des Data Mining, da hiermit die Lagerkosten erheblich gesenkt werden können.
Wie die bisherigen Beispiele zeigen, ist im Bereich Logistik häufig die Datenanalyse und Optimierung mit der Simulation zu koppeln, da spezifische Aspekte der Logistikkette simuliert werden müssen, um Szenarien zu bewerten und zu optimieren. Ein Beispiel ist auch das Lieferantennetzwerk, dessen tieferes Verständnis dazu dienen kann, kritische Pfade in der Logistikkette zu identifizieren und zu vermeiden, falls möglich. Der Ausfall einer Lieferung eines Lieferanten auf dem kritischen Pfad würde dementsprechend einen Produktionsstillstand beim Automobilkonzern bewirken. Die Simulation des Lieferantennetzwerkes erlaubt es nicht nur, derartige mögliche Engpässe zu identifizieren, sondern auch die Optimierung von Gegenmaßnahmen durchzuführen. Um eine möglichst detailgetreue Simulation zu ermöglichen, zeigt sich, dass die genaue Abbildung aller Teilprozesse und Interaktionen der Zulieferer untereinander zu komplex und für den Automobilehersteller zudem intransparent ist, sobald man versucht, die Tier-2 und Tier-3 Ebenen mit zu berücksichtigen.
Daher bietet sich als Alternative die datengetriebene Modellierung an. Hierbei wird aus den verfügbaren Daten über das Lieferantennetzwerk (Zulieferer, Produkte, Termine, Lieferfristen, etc.) und die Logistik (Lagerbestände, Lieferfrequenzen, Produktionsreihenfolgen) mit Data Mining Verfahren ein Modell gelernt. Diese kann dann als Prognosemodell verwendet werden, um z.B. die Auswirkungen einer Lieferverzögerung für bestimmte Teile auf die Produktion zu prognostizieren. Darüber hinaus ermöglicht die Anwendung von Optimizing Analytics in diesem Fall, eine Worst-Case Analyse durchzuführen, also diejenigen Teile und Zulieferer zu identifizieren, deren Lieferverzögerung am schnellsten einen Produktionsstillstand verursachen würde. Dieses Beispiel zeigt sehr deutlich, dass die Optimierung im Sinne einer Szenarienanalyse auch dazu verwendet werden kann, das für den Automobilkonzern schlechteste Szenario zu ermitteln (und dann, als Vision, wiederum Gegenmaßnahmen zu optimieren).
4.4 Produktion
Die Produktion wird in allen Teilschritten des Produktionsprozesses durch konsequenten Einsatz des Data Mining profitieren. Für Fertigungsprozesse ist dabei wesentlich, dass alle Prozessparameter kontinuierlich erfasst und gespeichert werden. Da als Optimierungsziel häufig die Qualität bzw. die Verringerung von Defekten im Vordergrund steht, sind Daten über auftretende Defekte sowie die Art des Defekts notwendig, und müssen den Prozessparametern eindeutig zugeordnet werden können. Besonders in neuartigen Produktionsprozessen – als Beispiel sei CFK genannt[36] – sind auf diese Weise erhebliche Verbesserungen realisierbar. Weitere mögliche Optimierungsziele sind der Energieverbauch oder der Durchsatz eines Produktionsprozesses pro Zeiteinheit. Die Anwendung von Optimizing Analytics kann dabei off-line ebenso erfolgen wie on-line.
Bei der off-line Anwendung werden durch die Analyse Größen, die den Prozess wesentlich beeinflussen, identifiziert. Ferner werden Zusammenhänge zwischen diesen Einflussgrößen und den Zielgrößen (Qualität oder andere) abgeleitet und ggf. daraus auch Maßnahmen abgeleitet, die die Zielgrößen verbessern können. Häufig sind derartige Analysen auf eine spezielle Fragestellung bzw. eine akute Problematik am Prozess bezogen, und liefern hierzu auch sehr effizient eine Lösung – sie zielen aber nicht auf eine kontinuierliche Prozessoptimierung ab. Die Durchführung der Analysen sowie die Interpretation und Umsetzung der Resultate erfordern durchweg im Wesentlichen manuelle Teilschritte, die von Data Scientists oder Statistikern, meist in Rückkopplung mit den jeweiligen Prozessexperten, durchgeführt werden können.
Bei der on-line Anwendung besteht ein ganz wesentlicher Unterschied darin, dass nun die Vorgehensweise automatisiert wird – wodurch ganz neue Herausforderungen an die Datenerfassung und –integration, die Datenvorverarbeitung, die Modellierung und die Optimierung gestellt werden. Bereits die Bereitstellung der Prozess- und Qualitätsdaten sollte nun automatisiert erfolgen, da dann ein integrierter Datenbestand verfügbar ist, auf dessen Basis die Modellierung jederzeit durchgeführt werden kann und immer dann durchgeführt wird, wenn Veränderungen des Prozesses (inklusive schleichender, sog. Drift) detektiert werden. Die daraus resultierenden Prognosemodelle werden dann automatisch für die Optimierung verwendet und können in jedem Prozesszustand z.B. die Qualität prognostizieren sowie Maßnahmen vorschlagen (oder auch direkt umsetzen), um die betrachtete Zielgröße (hier wiederum Qualität) weiter zu optimieren. Diese automatisch modellierende und optimierende Umsetzung von Optimizing Analytics ist technisch verfügbar, stellt allerdings heute für die meisten Anwender eher eine Vision dar.
Die Anwendungsbereiche umfassen unter anderem die Umformtechnik (klassisch ebenso wie für neue Werkstoffe), den Karosseriebau, Korrosionsschutz und Lackierung, Antriebsstrang, Endmontage, und lassen sich auf alle Teilschritte adaptieren. Eine Gesamtbetrachtung über alle Prozessschritte hinweg, mit einer Analyse aller potenziellen Einflussfaktoren und deren Wirkung auf die Gesamtqualität ist als Vision ebenso denkbar – dafür ist eine Integration der Daten aus allen Teilprozessen notwendig vorzusehen.
4.5 Marketing
Im Marketing liegt der Fokus darauf, den Endkunden möglichst effizient zu erreichen, und die Menschen entweder dazu zu bringen, Kunde des Unternehmens zu werden, oder Kunde zu bleiben. Der Erfolg von Marketingaktivitäten kann an Verkaufszahlen gemessen werden – wobei es wichtig ist, die Marketingeffekte von anderen Effekten wie z.B. der allgemeinen wirtschaftlichen Situation der Kunden zu differenzieren. Die Messung des Erfolges von Marketingaktivitäten ist also ggf. komplex, da multivariate Einflussfaktoren vorliegen können.
Ideal wäre es auch im Marketing immer, Optimizing Analytics einsetzen zu können, da Optimierungsziele wie die Maximierung der Rückläuferquote aus einer Marketingaktivität, die Maximierung der Verkaufszahlen bei gleichzeitiger Minimierung des eingesetzten Budgets, die Optimierung des Marketing-Mix sowie der zeitlichen Ausführungsreihenfolge im Vordergrund stehen. Prognosemodelle, wie z.B. die Prognose der zusätzlichen Verkaufszahlen über der Zeit als Folge einer spezifischen Marketingaktion sind also nur ein Teil der benötigten Data Mining Resultate – die mehrkriterielle Entscheidungsunterstützung spielt auch hier eine entscheidende Rolle.
Hervorragende Beispiele für den Einsatz von Data Mining im Marketing sind die Themen „Churn“ (Kundenabwanderungen) und Kundenloyalität. In einem gesättigten Markt ist für Automobilkonzerne oberstes Gebot, die Abwanderung von Kunden zu vermeiden, also optimale Gegenmaßnahmen zu planen und durchzuführen. Dazu sind möglichst individualisierte Informationen über die Kundin, das Kundensegment, in das die Kundin eingeordnet werden kann, die Zufriedenheit und das Erlebnis mit dem aktuellen Fahrzeug, und Daten über Wettbewerber und deren Modelle und Preise notwendig. Aufgrund der Subjektivität mancher Daten (z.B. Zufriedenheitsumfragen, individuelle Zufriedenheitswerte) ist die individualisierte Vorhersage von Churn sowie optimaler Gegenmaßnahmen (z.B. personenbezogene Preisnachlässe, Tank- oder Barprämien, Incentives durch zusätzliche Features) ein komplexes und ständig aktuelles Thema.
Da gleichzeitig höchste Datenvertraulichkeit gewährleistet wird und keinerlei personenbezogene Daten erfasst werden – außer der Kunde gibt explizit seine Zustimmung, um möglichst individuell zugeschnittene Angebote erhalten zu können – sind derartige Analysen und Optimierung nur auf der Ebene von Kundensegmenten möglich, die die Charakteristika einer anonymen Teilmenge der Kunden repräsentieren.
Die Kundenloyalität ist mit diesem Thema eng verwandt, und nimmt sich der Fragestellung an, wie die Loyalität von Bestandskunden erhalten und optimiert, also gesteigert werden kann. Damit verbunden ist immer das Thema des „Upselling“, also der Idee, dem Bestandskunden als nächstes Fahrzeug ein höherwertiges anzubieten und mit diesem Angebot erfolgreich sein zu können. Es ist offensichtlich, dass derartige Themen komplex sind, da sie hinsichtlich der Analysemöglichkeiten Daten über Kundensegmente, Marketingaktionen, und damit korrelierte Verkaufserfolge benötigen. Diese Daten sind aber meist nicht vorhanden, schwierig systematisch zu erheben, und durch Veracity, also Unsicherheit in den Daten, charakterisiert.
Für die Optimierung des Marketing Mix, ggf. inklusive des Themas Messebeteiligungen, gilt Ähnliches. Hier müssen über längere Zeiträume Daten gesammelt werden, um diese auswerten und daraus Schlussfolgerungen ziehen zu können. Für einzelne Marketingaktionen wie z.B. Briefsendungskampagnen ist die Auswertung der Rücklaufquote bezogen auf die Charakteristika der selektierten Zielgruppe sicher eher ein mögliches Ziel einer Datenanalyse und entsprechender Kampagnenoptimierung.
Grundsätzlich sind auch im Bereich Marketing sehr erfolgreiche Einsatzmöglichkeiten für Optimizing Analytics zu finden. Die Thematik der aufwendigen Datenerhebung, des Datenschutzes, und der teilweisen Ungenauigkeit der Daten erfordern hier jedoch eine langfristig angelegte Vorgehensweise und Planung der Datenerhebungsstrategie. Noch komplexer wird die Thematik, wenn vollständig „weiche“ Faktoren wie z.B. das Markenimage im Data Mining behandelt werden sollen – dann sind eigentlich alle Daten mit Unsicherheiten versehen und die entsprechenden Analysen (was sind wesentliche Treiber für das Markenimage, wie kann das Markenimage verbessert werden) eher tendenziell denn quantitativ nutzbar. Trotzdem gibt es damit im Rahmen einer Optimierung die Möglichkeit, zu bestimmen ob sich eine Maßnahme positiv oder negativ auswirken wird, so dass die Richtung bestimmt werden kann, in die die Maßnahmen gehen sollen.
4.6 Sales, After Sales und Retail
Die Diversität der Anwendungsmöglichkeiten und Anwendungen in diesem Bereich ist erheblich. Da der Faktor „Mensch“ in Form des Endkunden nun eine wesentliche Rolle spielt, sind neben objektiven Daten wie Absatzzahlen, individuellen Preisnachlässen und Händleraktionen auch eher subjektive Daten seitens des Kunden wie z.B. Kundenzufriedenheitsanalysen mit Hilfe von Fragebögen oder von Dritten erhobene Marktstudien zu Themen wie Markenimage, Pannenhäufigkeit, Markentreue und viele andere mehr potenziell zu berücksichtigen. Dabei gilt es häufig, eine Vielzahl von Datenquellen zu beschaffen, zu integrieren, für eine Analyse zugänglich zu machen, und schließlich im Hinblick auf die potenzielle Subjektivität der Bewertungen korrekt zu analysieren[37] – ein Prozess, der gegenwärtig wesentlich von der Expertise der Data Scientists, die die Analyse durchführen, abhängt.
Der Bereich Sales selbst ist mit dem Marketing eng verzahnt; schließlich geht es letztendlich darum, den Erfolg von Marketingaktivitäten im Hinblick auf den Absatz über Verkaufszahlen zu messen. Eine kombinierte Analyse von Marketingaktivitäten (also unter anderem Verteilung auf die einzelnen Medien, Häufigkeit der Schaltung, Kosten der jeweiligen Marketingaktivitäten) und Absatz kann dazu verwendet werden, die Marketingaktivitäten bzgl. Kosten und Effektivität zu optimieren, wobei hier immer ein Portfolio-basierter Ansatz gewählt wird. Das bedeutet, dass die optimale Auswahl eines Portfolios von Marketingaktivitäten und deren zeitliche Planung im Vordergrund stehen, und nicht die Fokussierung auf eine einzelne Marketingaktivität. Damit handelt es sich um eine Fragestellung aus dem Bereich der mehrkriteriellen Entscheidungsunterstützung, in dem in den letzten Jahren mit Hilfe von evolutionären Algorithmen und neuen portfoliobasierten Optimierungskriterien entscheidende Durchbrüche gelungen sind. Die Anwendungen im Bereich der Automobilindustrie halten sich jedoch bisher in sehr begrenztem Rahmen.
In ähnlicher Weise gibt es potenziell eine Verzahnung zwischen Kundenfeedback, Garantieleistungen und Produktion, da sich in der Kundenzufriedenheit ggf. weiche Faktoren und über die Garantieleistungen harte Faktoren ableiten lassen, die mit fahrzeugspezifischen Produktionsdaten gekoppelt und analysiert werden können. Auf diese Weise können Faktoren ermittelt werden, die das Auftreten von Qualitätsmängeln, die ab Werk nicht bestanden bzw. vorhersehbar waren, beeinflussen, solche Qualitätsmängel also zu prognostizieren und durch Optimizing Analytics auch zu reduzieren ermöglichen. Dazu ist es allerdings wiederum nötig, Daten aus ganz unterschiedlichen Bereichen – Produktion, Warranty, und After Sales – miteinander zu kombinieren, um sie so der Analyse zugänglich zu machen.
Für Gebrauchtfahrzeuge spielt im Flotten- oder Mietwagengeschäft der Restwert eine entscheidende Rolle, da die entsprechenden Volumina von zehntausenden von Fahrzeugen als Assets mit dem entsprechenden Restwert bilanziert werden. Dieses Risiko wird heute von den OEMs typischerweise an Banken bzw. Leasinggesellschaften ausgelagert, die allerdings wiederum Teil des Gesamtkonzerns sein können. Data Mining und insbesondere Predictive Analytics können hier eine entscheidende Rolle in der korrekten Bewertung der Assets spielen, wie bereits vor zehn Jahren seitens eines US-amerikanischen OEMs gezeigt wurde[38]. Mit Hilfe nichtlinearer Prognosemodelle können aus eigenen Vertriebsdaten auf Fahrzeugebene ausstattungsspezifisch individualisierte Restwertprognosen erstellt werden, die deutlich genauer als die als Marktstandard verfügbaren Modelle sind. So können auch Absatzkanäle bis hin zur geographischen Zuordnung der Gebrauchtfahrzeuge auf Auktionsplätze individuell auf Fahrzeugebene so optimiert werden, dass der Gesamterfolg des Vertriebs global maximiert wird.
Denkt man den Vertrieb konsequent weiter, so wird deutlich, dass das Wissen über jeden einzelnen Kunden hinsichtlich seiner Interessen und Präferenzen beim Fahrzeugkauf oder, zukünftig, bei der temporären Nutzung von verfügbaren Fahrzeugen, wesentlich ist. Je mehr individualisiertes Wissen über die soziodemographischen Faktoren der Kundin, ihr Kaufverhalten oder gar Klickverhalten auf der Website des OEM, ggf. auch ihr Fahrverhalten und die individuelle Nutzung eines Fahrzeugs verfügbar ist, umso treffender kann auf ihre Bedürfnisse eingegangen und ihr ein optimales Angebot für ein Fahrzeug (passendes Modell mit Ausstattungsmerkmalen) und dessen Finanzierung unterbreitet werden.
4.7 Connected Customer
Dieser Begriff ist sicher heute noch nicht etabliert, beschreibt aber die Zukunft, in der der Kunde und das Fahrzeug vollständig mit moderner Informationstechnologie integriert sind. Die Thematik ist eng mit Themen aus Marketing und Sales wie z.B. Customer Loyalty, individualisiertes User Interface und Fahrzeugverhalten im Allgemeinen, und anderen visionären Aspekten verknüpft (siehe auch Abschnitt 5). Durch die Verbindung mit dem Internet und intelligente Algorithmen kann das Fahrzeug auf Sprachbefehle regieren und Antworten suchen, die beispielsweise direkt mit dem Navigationssystem kommunizieren und das Fahrziel verändern können. Die Kommunikation von Fahrzeugen miteinander erlaubt es, Informationen über Straßen- und Verkehrsverhältnisse weitaus exakter und aktueller zu sammeln und auszutauschen, als das über zentralisierte Systeme möglich ist. Als Beispiel sei die oft räumlich und zeitlich sehr eingegrenzte Bildung von Blitzeis genannt, deren Erkennung und Kommunikation als Warnung an andere Fahrzeuge heute problemlos möglich ist.
5 Vision
In der Fahrzeugentwicklung wird heute bereits auf „Baukastensysteme“ gesetzt, die es ermöglichen, Komponenten modellreihenübergreifend zu verwenden. Gleichzeitig werden die Entwicklungszyklen immer kürzer. Es gibt allerdings in der virtuellen Fahrzeugentwicklung bisher keine Ansätze, mit Hilfe von Verfahren des maschinellen Lernens ein automatisches Lernen zu ermöglichen, durch das sowohl historisch aufeinander aufbauend, als auch modellreihenübergreifend Wissen extrahiert wird, welches zukünftige Entwicklungsprojekte unterstützen und effizienter gestalten kann. Diese Thematik ist eng mit der des Datenmanagements verzahnt, der Komplexität des Data Mining in Simulations- und Optimierungsdaten, sowie der Schwierigkeit, eine geeignete Repräsentation von Wissen über Fahrzeugentwicklungsaspekte zu definieren. Zudem stößt dieser Ansatz an organisatorische Grenzen des Fahrzeugentwicklungsprozesses, der heute oft vollständig am jeweils zu entwickelnden Modell orientiert ist. Das Thema „Data Mining in Simulationsdaten“ ist zudem aufgrund der Heterogenität der Daten (oft numerische Daten, aber auch Bilder und Videos, z.B. von Strömungsfeldern) und der Größe der Daten (mittlerweile im Bereich von Terabyte für eine einzige Simulation) extrem komplex und bestenfalls Gegenstand erster Forschungsansätze[39].
Neue Servicedienstleistungen werden über die Thematik des Predictive Maintenance, also der Vorhersage von Wartungsdienstleistungen, möglich. Automatisch gelerntes Wissen über das individuelle Fahrverhalten – also die jährliche, saisonale oder gar monatliche Fahrleistung sowie die Art des Fahrens – kann dazu benutzt werden, auf Fahrzeugebene Intervalle für notwendige Wartungsarbeiten (Bremsbeläge, Filter, Öl, etc.) mit großer Genauigkeit zu prognostizieren. Der Fahrer kann mit dieser Information so rechtzeitig den Werkstattbesuch planen, und die Vision eines Fahrzeugs, das in Abstimmung mit dem für den Bordcomputer über entsprechende Protokolle zugreifbaren Terminkalender des Fahrers selbständig Werkstattermine plant ist heute realistischer als der so oft zitierte Kühlschrank, der selbständig Lebensmittel nachbestellt.
In der Kombination mit einer automatischen Optimierung kann die Vertragswerkstatt vor Ort als zentrale Koordinationsstelle, in der die individuellen Serviceanforderungen der Fahrzeuge über eine entsprechende Telematikschnittstelle eintreffen, die Servicetermine in Echtzeit optimal planen – also z.B. die Auslastung unter Berücksichtigung der Personalverfügbarkeit möglichst gleichmäßig halten.
Hinsichtlich der Lern- und Anpassungsfähigkeiten des Fahrzeugs sind der Phantasie kaum Grenzen gesetzt. Das Fahrverhalten kann seitens des Fahrzeugs erkannt und klassifiziert werden – also einem bestimmten Fahrertypus zugeordnet. In Abhängigkeit davon kann das Fahrzeug selbst Anpassungen vornehmen, die vom Handling bis zum elektronischen Benutzerinterface reichen – auf diese Weise also eine über technische Ausstattungsmerkmale weit hinausgehende Individualisierung und Adaptation an den Fahrer bieten. Das erlernte Wissen über die Fahrerin kann beim Kauf eines neuen Fahrzeugs auf dieses übertragen und somit die vertraute Umgebung unmittelbar zur Verfügung gestellt werden.
5.1 Vision – Fahrzeuge als autonome, adaptive und soziale Agenten & die Stadt als Superagent
Die Forschung an autonom agierenden Fahrzeugen ist in der Automobilindustrie nicht mehr wegzudenken, und das fahrende Wohnzimmer ist nicht mehr ein undenkbares Szenario, sondern findet mehr und mehr positive Resonanz. Heute liegt der Entwicklungsschwerpunkt auf der Autonomie, und das aus gutem Grund: autonom agierende Fahrzeuge sind in den meisten Teilen der Welt nicht zugelassen und wenn doch, dann nicht weit verbreitet. Das Fahrzeug als Agent kann also nicht mit allen anderen Fahrzeugen kommunizieren, und von Menschen gesteuerte Fahrzeuge passen ihr Verhalten basierend auf den Ereignissen im Sichtfeld dieser Menschen an. Unterstützung wird von Navigationssystemen geboten, die auf Staus hinweisen und Ausweichrouten vorschlagen können. Gehen wir aber davon aus, dass jedes Fahrzeug ein voll vernetzter Agent ist, mit den zwei Hauptzielen:
- Beitrag zur Optimierung des Verkehrsflusses
- Vermeidung von Unfällen
In diesem Szenario kommunizieren die Agenten miteinander und verhandeln über Routen, wobei das Ziel die Minimierung der Gesamtfahrzeit ist (Parameter sind natürlich z.B. die Länge der Strecke, mögliche Geschwindigkeit, Baustellen, etc.). Unvorhersehbare Ereignisse werden minimiert, jedoch nicht unmöglich – so kann etwa ein Sturmschaden nach wie vor zur Blockierung einer Straße führen. Derartige Informationen müssen sofort an alle Fahrzeuge im relevanten Aktionsbereich kommuniziert werden, woraufhin neu optimiert werden muss. Schäden an Fahrzeugen werden durch prädiktive Wartung ebenfalls minimiert. Basierend auf der Analyse von historischen Daten wird vorhergesagt, wann mit hoher Wahrscheinlichkeit welcher Defekt auftritt, und das Fahrzeug (die Software im Fahrzeug, also der Agent) vereinbart einen Servicetermin ohne Zutun des Passagiers und fährt eigenständig in die Werkstätte – durch Zugriff auf dessen Kalender ist das möglich. Tritt dennoch ein Schadensfall auf, der die unmittelbare Weiterfahrt nicht ermöglicht, wird dies ebenfalls schnellstmöglich kommuniziert – entweder durch einen „Pannen“-Broadcast oder in eine Zentrale, und der Abschleppdienst steht unmittelbar in Form eines autonomen Schleppers bereit, idealerweise gefolgt von einem (ebenfalls autonomen) Ersatzfahrzeug. Die Fahrzeuge agieren also
- autonom, indem sie selbstständig einer Route hin zu einem Fahrziel folgen,
- adaptiv, indem sie auf unvorhergesehene Ereignisse wie Blockaden und Pannen reagieren können,
- sozial, indem sie zusammen an gemeinsamen Zielen arbeiten, und zwar der Optimierung des Verkehrsflusses und der Vermeidung von Unfällen (wobei die Situation natürlich komplexer ist und viele Sub-Ziele definiert werden müssen, um das zu erreichen).
In Kombination mit Taxidiensten, die ebenfalls über eine autonome Flotte verfügen, könnten (das Einverständnis des jeweiligen Benutzers vorausgesetzt) Bewegungsdaten und Informationen zur vergangenen Nutzung von Taxidiensten dazu genutzt werden, potenziellen Kunden Taxen an Orte zu schicken, ohne dass diese aktiv werden müssen. In einer vereinfachten Form ist das auch anonymisiert umsetzbar, etwa indem datenbasiert Orte identifiziert werden, an welchen häufig (durch Identifikation von Clustern, s.a. 3.1. Maschinelles Lernen) zu spezifischen Zeiten oder Ereignissen Taxen benötigt werden (Rush Hour, Fußball-Matches, etc.).
Wenn zusätzlich die Straßen digital werden, also Asphaltstraßen durch Glas ersetzt und durch OLED-Technologie ergänzt werden, sind auch dynamische Veränderungen der Verkehrsführung möglich. Materialtechnisch ist das machbar:
- Die Oberflächenstruktur von Glas kann so entwickelt werden, dass dieses auch im Regen rutschfest ist.
- Glas kann so flexibel und gleichzeitig stabil designet werden, dass auch darüber fahrende LKWs es nicht zum Brechen bringen.
- Die Abwärme der Displays kann zur Beheizung genutzt werden – es gibt somit auch im Winter keine Eisfahrbahnen mehr.
Die Stadt kann so selbst als Agent in die Multi-Agentenumgebung eingebettet werden und zur Erreichung der definierten Ziele beitragen.
5.2 Vision – integrierte Fabrikoptimierung
Durch die Analyse von Kunden- und Werkstattmeldungen sowie Reparaturdaten über im Feld auftretende Fehler analysieren wir heute softwareseitig und automatisiert, ob für spezifische Fahrzeugmodelle oder verbaute Teile ein Anstieg an Fehlern zu erwarten ist. Das dabei verfolgte Ziel ist die frühzeitige Erkennung und Vermeidung von potenziellen Problemen, und zwar bevor groß angelegte Rückrufaktionen vorgenommen werden müssen. Die Ursachen von Fehlern im Feld können vielfältig sein, Mängel in der Qualität der Teile oder Fehler in der Produktion eingeschlossen, und wenn man bedenkt, dass täglich tausende Fahrzeuge die Produktionsanlagen von VW verlassen, hat schnelles Handeln oberste Priorität. Angenommen, die linguistische Analyse von Kundenaussagen und Werkstattmeldungen zeigt heute (November 2015), dass ein signifikanter Anstieg von Ausfällen des rechten Begrenzungslichts eines ab Juli 2015 ausgelieferten Modells x, Plattform C, zu erwarten ist. Signifikant bedeutet in diesem Fall, dass ein statistisch belegbarer Aufwärtstrend (Anstieg an gemeldeten Fehlern), basierend auf den Verkäufen von Januar 2015 – November 2015 extrahiert werden kann. Durch die Analyse von Fehler- und Reparaturketten kann ermittelt werden, welche Ereignisse zu dem Fehler führen, beziehungsweise welche Modelle noch betroffen sind beziehungsweise betroffen sein werden. Wird der Fehler in der Produktion, etwa an einem Produktionsroboter, festgemacht, ist das entweder auf einen Hard- und/oder Softwarefehler oder falsche oder unvollständige Parametrierung zurückzuführen. Im ungünstigsten Fall muss gar ein Update der Steuerung vorgenommen werden, um den Fehler abzustellen. Ein Softwareupdate kann zudem nicht unmittelbar passieren, da nach Eingang und Prüfung der Problemmeldung beim Hersteller erst an Patches gearbeitet werden muss. Auch eine Neuparametrierung kann aufgrund der Freiheitsgrade (Rotationsachsen), über die mehrachsige Manipulatoren verfügen, hochkomplex sein. Kurz gesagt, die Durchführung derartiger Korrekturen ist zeitintensiv, anspruchsvoll, und führt nur im Idealfall nicht zu Folgefehlern.
Ansätze aus der künstlichen Intelligenz (KI) erlauben es, diesen Prozess an mehreren Stellen zu optimieren.
In der KI-Forschung wird unter anderem daran gearbeitet, Systeme (wobei der Begriff „System“ synonym für ‘aus mehreren Einzelteilen zusammengesetztes Ganzes‘ steht, im Speziellen für Software oder eine Kombination aus Hard- und Software, wie einem Industrieroboter) in einem aktuell noch beschränkten Umfang zu befähigen, selbstständig Wissen aus Daten zu extrahieren und zu interpretieren.
Abbildung 4 – Daten, Wissen, Handlung
Wissen, im Gegensatz zu Daten, kann die Grundlage einer Handlung formen, und das Resultat einer Handlung kann wieder in Daten zurückgeführt werden, die wiederum die Basis zu neuem Wissen formen.
Führt man einem Agenten mit der Fähigkeit, zu lernen und Daten zu interpretieren, die Ergebnisse (Zustand der Welt vor der Aktion, Zustand der Welt nach der Aktion, s.a. Abschnitt 3.5) eigener oder der Handlungen anderer zu, wird dieser, ausgestattet mit einem Ziel und der Freiheit sich anzupassen, selbstständig versuchen, dieses Ziel zu erreichen. Biologische Agenten wie Menschen oder Tiere tun das intuitiv, ohne aktiv den Prozess der Transformation von Daten hin zu Wissen steuern beziehungsweise kontrollieren zu müssen. Splittert bei einer Heimwerkerarbeit das Holz, weil wir einen Nagel im zu steilen Winkel zu fest eingeschlagen haben, transformiert unser Gehirn ohne unser bewusstes Zutun den eingeschlagenen Winkel, die Materialbeschaffenheit, und die Wucht des Hammerschlags in Wissen und Erfahrung, was die Wahrscheinlichkeit, denselben Fehler zu wiederholen, minimiert.
In dem bereits diskutierten, speziellen Bereich der künstlichen Intelligenz, dem maschinellen Lernen, wird gezielt an der Nachahmung derartigen Verhaltens geforscht. Indem wir Software durch ML dazu befähigen, in einer spezifischen Problemdomäne von Daten zu lernen, von vergangenen Ereignissen auf die Lösung von bisher nicht dagewesenen zu schließen, eröffnen sich neue Möglichkeiten. ML ist in der Datenanalyse keine Neuheit und findet dort seit Jahren Anwendung; was allerdings neu ist, ist die Möglichkeit, hochkomplexe Modelle auf in die Petabytes gehenden Datenmengen in endlicher Zeit rechnen zu lassen. Wenn man sich eine Produktionsanlage als Organismus vorstellt, der das Ziel verfolgt, fehlerfreie Fahrzeuge zu produzieren, würde man diesen Organismus, die geschilderten Fähigkeiten vorausgesetzt, in seiner Entwicklung und Verbesserung unterstützen, indem man ihm Zugriff auf relevante Daten gewährt.
Zwei Stufen der Entwicklung werden dabei relevant sein:
Stufe 1 – Lernen aus Daten, Anwenden von Erfahrung
Um aus Daten lernen zu können, darf ein Roboter nicht allein nach statischer Programmierung funktionieren, sondern muss über ML-Verfahren selbstständig auf definierte Lernziele hinarbeiten können. Hinsichtlich ggf. auftretender Produktionsfehler bedeutet das im ersten Schritt, dass die auszuführenden Aktionen, die zu solchen führen können, erlernt und nicht nach einem Fluss- und Ereignisdiagramm programmiert wurden. Wenn etwa ersichtlich wird, dass das vorhin geschilderte Problem hinsichtlich Begrenzungslicht nicht nur erkannt, sondern auch auf dessen Ursache in der Produktion, etwa einen Roboter, der einen Scheinwerfer zu fest in die Fassung drückt, rückgeschlossen werden kann, gilt es nun nur noch, das Lernziel für die Korrekturmaßahme festzulegen. Nehmen wir an, der Produktionsfehler tritt nicht bei Robotern in anderen Produktionsanlagen auf, und dass linke Scheinwerfer generell korrekt verbaut werden. Wir als Menschen würden im besten Fall den Unterschied zwischen korrekt und inkorrekt arbeitenden Robotern visuell erfassen und interpretieren können, und auf ähnliche Art sollte auch der betroffene Roboter lernen. Der Unterschied liegt in der Art der Wahrnehmung – digitale Systeme können diesbezüglich noch viel besser „sehen“. Auch wenn das, was softwareseitig implementierte ML-Verfahren während des Lernprozesses an Veränderung durchlaufen oft auch für den jeweiligen Entwickler eines lernenden Systems auf Grund von stochastischen Komponenten und Komplexität nicht vollständig transparent ist, ist doch die Aktion transparent, also nicht wie ein System etwas tut, aber was es tut. Diese Signale gilt es zu nutzen, um den neuerlichen Lernprozess einzuleiten und die Steuerung des problematischen Roboters zu adaptieren. In besagtem Fall wären das die Bewegungssignale von Manipulator und Effektor eines korrekt funktionierenden Roboters, die mit beliebiger Genauigkeit mess- bzw. feststellbar sind. Dazu ist kein menschlicher Eingriff notwendig – die vollkommene Transparenz der Anlage ist durch kontinuierliche Sicherung und Analyse der im Produktionsprozess anfallenden Daten gegeben. Auch die Erkenntnis und Übermittlung der Fehler aus dem Feld erfordert keine menschliche Analyse; basierend auf linguistischen Analysen von Werkstatt- und Kundenmeldungen sowie Reparaturdaten erkennen wir schon heute frühzeitig, welche Probleme auf die Produktion zurückzuführen sind. Die entsprechende Lieferung dieser Daten an die betroffenen Akteure (es ist bei entsprechender Datenlage genau ersichtlich, welche Maschine sich selbst korrigieren muss) ermöglicht diesen dann, aus den Fehlern zu lernen und sich selbst zu korrigieren.
Stufe 2 – Beschränkungen der eigenen Programmierung überwinden – die Smart Factory als Individuum
Was wäre, wenn die Produktionsanlage Dinge lernen muss, für die auch die Flexibilität eines oder mehrerer ML-Verfahren, über welche einzelne Akteure (wie etwa Roboter oder Transporter) verfügen, nicht ausreichen? Wie ein biologischer Organismus könnte eine Produktionsanlage als eigene, aus Subkomponenten zusammengesetzte Entität agieren, ähnlich wie ein Mensch, die über natürliche Sprache ansprechbar ist, Kontext versteht und in der Lage ist, diesen zu interpretieren. Kontextverständnis und -interpretation stellen seit jeher eine Herausforderung in der KI-Forschung dar. Kontext wird in der Theorie als geteilte (oder gemeinsame) Interpretation einer Situation verstanden, wobei hier wiederum der Kontext einer Situation und der Kontext einer Entität zu einer Situation relevant ist. Für eine Produktionsanlage relevante Kontexte umfassen alles, was in natürlicher Sprache oder anderer Form ausgedrückt produktionsrelevant ist. Das folgende, vereinfachte Szenario hilft beim Verständnis: Angenommen, das finale Design für eine Karosserie wird durch ein Gremium während eines Meetings verabschiedet.
„Für das Facelift vom Golf 15 haben wir uns für folgende Karosserie entschieden, baue bitte einen Prototypen auf der Basis des Golf 15 analog dazu.“, sagt Herr Müller, das vor allen Teilnehmern scheinbar schwebende und nur durch Augmented Reality-Brillen sichtbare 3D-Modell betrachtend.
Die Simulation ist in diesem Szenario über evolutionäre Algorithmen denkbar, beschränkt auf den Möglichkeitsraum der tatsächlich baubaren Kombinationen. Dies kann, entsprechende Rechenleistung und Reduktion von Parametern vorausgesetzt, Simulationsdauern von mehreren Stunden auf Minuten reduzieren, was das dynamische Morphing von Bauteilen oder Bauteilkombinationen während eines Meetings ermöglichen kann.
Factory : „Basierend auf dem Modellinput habe ich ermittelt, dass die Anpassung der Programmierung meiner Roboter 26 Minuten in Anspruch nehmen wird. Für die Assemblierung der Bodengruppe müssen an den Robotern x, y die Werkzeuge x1, y1 gegen die Werkzeuge x2, y2 getauscht werden. Die Produktion des Prototypen wird in 6 Stunden und 37 Minuten abgeschlossen sein.“
Dieses Szenario ist natürlich stark vereinfacht, soll aber zeigen, wohin die Reise gehen kann. Um zu verstehen, was getan werden muss, muss die Produktionsanlage verstehen, was eine Karosserie ist, was ein Facelift ist, etc., und muss die Parameter und den Output einer Simulation so interpretieren können, dass dieses in Produktionsschritte umgelegt werden kann. Die Umlage in Produktionsschritte erfordert das Training einzelner ML-Komponenten auf den Robotern oder die Anpassung bzw. Erweiterung deren Programme basierend auf den Simulationsdaten, sodass vom Zuschneiden der Bleche bis hin zum Assemblieren und Integrieren der (noch fiktiven) Golf 15-Basis alle Schritte vorgenommen werden können. Das alles umfasst ein breites Spektrum an Methoden, angefangen von natürlichem Sprachverständnis und Sprachgenerierung bis hin zur Planung, Optimierung und selbstständigen Modellgenerierung, ist aber durchaus keine Science Fiction.
5.3 Vision – das Unternehmen agiert eigenständig
Für die Planung von Marketingmaßnahmen oder Kundenbedürfnissen etwa ist es für Unternehmen jeder Art unabdingbar zu beobachten, wie sich Absätze über der Zeit verändern, vorherzusagen, wie sich Märkte entwickeln und welche Kunden potenziell abwandern, auf Finanzkrisen zu reagieren oder schnell zu interpretieren, wie Katastrophen oder politische Strukturen sich auswirken können. All dies machen wir heute schon und was wir dafür benötigen, sind Daten. Wir sind nicht an den persönlichen Daten des Einzelnen interessiert, sondern daran, was man aus vielen Einzelkomponenten ableiten kann. Etwa können wir aus der Analyse von über 1600 Indikatoren vorhersagen, wie sich gewisse Finanzkennzahlen von Märkten entwickeln und darauf reagieren, oder aber mit hoher Wahrscheinlichkeit vorhersagen, welche Kundengruppen auf aktuell in der Vorserienentwicklung befindliche Modelle ansprechen und daraus Marketingmaßnahmen ableiten. Wir können sogar so weit gehen, dass wir komplett konfigurierte Modelle ermitteln, die den Geschmack von spezifischen Kundengruppen treffen. Wir treffen mit diesem Wissen Entscheidungen, passen unsere Produktion an, erstellen Marketingpläne oder schlagen im Konfigurator für Kundengruppen passende, fertig konfigurierte Modelle vor.
Die Erstellung eines Marketingplans folgt teilweise einem statischen Prozess (was wird gemacht), aber wie etwas gemacht wird, ist variabel. Sobald man die Informationen darüber, wie und warum etwas gemacht wird, einer anderen Person erklären kann, kann man diese auch für Algorithmen verfügbar machen. Auf ein Beispiel heruntergebrochen, können wir vorhersagen, dass die Eröffnung einer weiteren Produktionsanlage eines unserer Konkurrenten im selben Land, in dem wir bereits produzieren, dazu führt, dass wir in einen Rückgang in unseren Verkäufen zu erwarten haben. Wir können sogar (mit einer gewissen Schwankungsbreite behaftet) vorhersagen, wie hoch der zu erwartende Verkaufsrückgang sein wird. „Wir“ sind in dem Fall die Algorithmen, die wir für diesen speziellen Anwendungsfall entwickelt haben. Da diese Situation mehr als einmal vorkommt und jedes Mal (nahezu) identische Inputparameter fordert, können wir dieselben Algorithmen für die Vorhersage von Ereignissen in anderen Ländern nutzen. Es wird damit möglich, das Wissen um vergangene Marketingaktionen zu nutzen, um zukünftige Aktionen durchzuführen. Kurz gesagt, Algorithmen erstellen die Marketingpläne.
Versehen mit einem Ziel, wie etwa der Maximierung des Benefits für unsere Kunden unter Berücksichtigung der Wirtschaftlichkeit, könnten Subklassen von Algorithmen interne (wie z.B. Verkaufszahlen und Konfiguratordaten) und externe Daten (wie z.B. Entwicklungen von Aktienmärkten, Finanzkennzahlen, politischen Strukturen) eigenständig Output für ein „Marketing-Programm“ oder ein „GDP-Programm“ generieren. Versehen mit den Möglichkeiten, Ressourcen eines Unternehmens zu nutzen und selbstständig zu agieren, könnte dieses selbstständig auf Fluktuationen in Märkten reagieren, gefährdete Zulieferer subventionieren und vieles mehr. Die Möglichkeiten sind umfangreich, und technisch können derartige Szenarien heutzutage bereits konzipiert werden. Permanentes Monitoring von Aktienkursen, Verstehen und Interpretieren von Nachrichtenmeldungen und die Berücksichtigung von demografischen Veränderungen sind nur einige Bereiche, die relevant sind und unter Anderem eine Kombination von natürlichem Sprachverständnis, wissensbasierten Systemen und logischem Schließen erfordern. Sehr häufig wird in der KI-Forschung die Sprache oder visuelle Information als Grundlage von Verständnis über Dinge herangezogen, weil auch wir Menschen sehr vieles über Sprache oder visuelle Reize erlernen und verstehen.
6 Schlussfolgerungen
Die künstliche Intelligenz hat bereits Einzug in unseren Alltag gehalten und ist nicht mehr ausschließlich Gegenstand von Science Fiction-Romanen. KI wird zum aktuellen Zeitpunkt hauptsächlich in den folgenden Bereichen eingesetzt:
- In der analytischen Datenverarbeitung.
- In Domänen, in welchen schnell, qualifiziert und auf einer großen Menge an (oft heterogenen) Daten Entscheidungen getroffen werden müssen, oder
- bei monotonen, aber dennoch ständige Aufmerksamkeit erfordernden Tätigkeiten.
In der analytischen Datenverarbeitung werden wir im Laufe der nächsten Jahre nicht mehr nur auf Entscheidungsunterstützungssysteme einsetzen, sondern solche, die uns Entscheidungen abnehmen. Speziell in der Datenanalyse entwickeln wir aktuell für spezifische Fragestellungen individuelle, analytische Lösungen, die jedoch nicht kontextübergreifend eingesetzt werden können – etwa kann eine zur Anomalieerkennung in Aktienkursverläufen entwickelte Lösung nicht dazu verwendet werden, Inhalte von Bildern zu verstehen. Das wird auch zukünftig nicht der Fall sein, allerdings werden KI-Systeme einzelne, interagierende Komponenten integrieren und so immer komplexere, momentan Menschen vorbehaltene Aufgaben übernehmen können – ein klarer Trend, den wir jetzt schon beobachten können. Ein System, welches nicht nur aktuelle Daten über Aktienmärkte verarbeitet, sondern zudem die Entwicklung von politischen Strukturen über Nachrichtentexte oder Videos verfolgt und analysiert, Stimmungen aus Texten in Blogs oder Social Networks extrahiert, relevante Finanzkennzahlen monitort und vorhersagt, usw., erfordert die Integration vieler unterschiedlicher Subkomponenten – diese zum Zusammenspiel zu bewegen, ist Gegenstand aktueller Forschung, und Fortschritte werden wöchentlich publiziert. In einer Welt, in der KI-Systeme in der Lage sind, sich selbst kontinuierlich zu verbessern und etwa Unternehmen effektiver zu steuern als Menschen, was bleibt da für den Menschen? Zeit zur Konzentration auf die Erweiterung des eigenen Wissens, der Verbesserung der Gesellschaft, der Beseitigung von Hunger, Elimination von Krankheiten, Ausbreitung unserer Spezies über unser eigenes Sonnensystem hinweg.[40] Einige Theorien besagen, dass Quantencomputer für die Entwicklung von starken KI-Systemen erforderlich sind,[41] und nur jemand, der sehr unvorsichtig ist, würde behaupten, ein effektiver Quantencomputer wäre innerhalb der nächsten 10 Jahren verfügbar. Und nur jemand, der unvorsichtig ist, würde behaupten, dass das nicht der Fall sein wird. Davon unabhängig muss, wie die Geschichte uns bei der Mehrzahl relevanter, wissenschaftlicher Errungenschaften zeigt, auch die künstliche Intelligenz mit Bedacht eingesetzt werden – Systeme, die mit steigender Hardwareleistung exponentiell mehr Entscheidungen in extrem kurzen Zeitspannen treffen können, können viel Positives bewirken, aber auch missbraucht werden.
Über die Autoren

Dr. Martin Hofmann
Dr. Martin Hofmann ist Executive Vice President der Volkswagen Gruppe und CIO der Volkswagen AG. Zu seinen bekannten Initiativen im Kontext von Big Data und Data Science gehören die Gründung des Code Lab in San Francisco, dem Data Lab in München sowie dem Digital:Lab in Berlin.

Dr. Florian Neukart
Dr. Florian Neukart ist Principal Data Scientist bei der Volkswagen Group of America. Darüber hinaus ist er seit Jahren in der Forschung und Lehre in den Bereichen Quanten-Computer und künstlicher Intelligenz aktiv.

Prof. Dr. Thomas Bäck
Prof. Dr. Thomas Bäck ist an der niederländischen Universität Leiden in der Forschung und Lehre tätig. Sein wissenschaftlicher Fokus liegt auf Optimierungsalgorithmen, Predictive Analytics sowie deren Anwendung in der Industrie 4.0. In mehr als 20 Jahren sammelte Prof. Bäck Erfahrung in der Anwendung und Implementierung der Algorithmen beispielsweise bei Volkswagen, Daimler und BMW.
Quellen
[1] D. Silver et. al.: Mastering the game of Go with deep neural networks and tree search, Nature 529, 484-489 (28. Januar 2016).
[2] https://en.wikipedia.org/wiki/Cross_Industry_Standard_Process_for_Data_Mining
[3] Systeme, “bei denen informations- und softwaretechnische mit mechanischen bzw. elektronischen Komponenten verbunden sind, wobei Datentransfer und –austausch sowie Kontrolle bzw. Steuerung über eine Infrastruktur wie das Internet in Echtzeit erfolgen.“ (Gabler Wirtschaftslexikon, Springer, siehe http://wirtschaftslexikon.gabler.de/Definition/cyber-physische-systeme.html).
[4] Ebenda wird Industrie 4.0 definiert als „ein Marketingbegriff, der auch in der Wissenschaftskommunikation verwendet wird, und steht für ein „Zukunftsprojekt“ der deutschen Bundesregierung. Die sog. Vierte industrielle Revolution zeichnet sich durch Individualisierung bzw. Hybridisierung der Produkte und die Integration von Kunden und Geschäftspartnern in die Geschäftsprozesse aus.“ (Gabler Wirtschaftslexikon, Springer, siehe http://wirtschaftslexikon.gabler.de/Definition/industrie-4-0.html).
[5] E. Rich, K. Knight: Artificial Intelligence, 5, 1990
[6] Th. Bäck, D.B. Fogel, Z. Michalewicz: Handbook of Evolutionary Computation, Institute of Physics Publishing, New York, 1997.
[7] R. Bajcsy: Active perception, Proceedings of the IEEE, 76:996-1005, 1988
[8] J. L. Crowley, H. I. Christensen: Vision as a Process: Basic Research on Computer Vision Systems, Berlin: Springer, 1995
[9] D. P. Huttenlocher, S. Ulman: Recognizing solid objects by alignment with an image, International Journal of Computer Vision, 5: 195-212, 1990
[10] K. Frankish, W. M. Ramsey: The Cambridge handbook of artificial intelligence, Cambridge: Cambridge University Press, 2014
[11] F. Chaumette, S. Hutchinson: Visual servo control I: Basic approaches, IEEE Robotics and Automation Magazine, 13(4): 82-90, 2006
[12] E. D. Dickmanns: Dynamic Vision for Perception and Control of Motion, London: Springer, 2007
[13] T. M. Straat, M. A. Fischler: Context-based vision: Recognizing objects using information from both 2D and 3D imagery, IEEE Transactions on Pattern Analysis and Machine Intelligence, 13: 1050-65, 1991
[14] D. Hoiem, A. A. Efros, M. Hebert: Putting objects in perspective, Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition (CVPR), 2137-44, 2006
[15] H. Buxton: Learning and understanding dynamic scene activity: A review, Vision Computing, 21: 125-36, 2003
[16] N. Lavarac, S. Dzeroski: Inductive Logic Programming, vol. 3: Nonmonotonic Reasoning and Uncertain Reasoning, Oxford University Press: Oxford, 1994
[17] K. Frankish, W. M. Ramsey: The Cambridge handbook of artificial intelligence, Cambridge: Cambridge University Press, 2014
[18] G. Leech, R. Garside, M. Bryant: . CLAWS4: The tagging of the British National Corpus. In Proceedings of the 15th International Conference on Computational Linguistics (COLING 94) Kyoto, Japan, pp622-628, 1994
[19] K. Spärck Jones: Information retrieval and artificial intelligence, Artificial Intelligence 141: 257-81, 1999
[20] A. Newell, H. A. Simon: Computer science as empirical enquiry: Symbols and search, Communications of the ACM 19:113-26
[21] M. Bratman, D. J. Israel, M. E. Pollack: Plans and resource-bounded practical reasoning, Computational Intelligence, 4: 156-72, 1988
[22] H. Ah. Bond, L. Gasser: Readings in Distributed Artificial Intelligence, San Mateo, CA: Morgan Kaufmann, 1988
[23] E. H. Durfee: Coordination for Distributed Problem Solvers, Boston, MA: Kluwer Academic, 1988
[24] G. Weiss: Multiagent Systems: A modern approach to distributed artificial intelligence, Cambridge, MA: MIT Press, 1999
[25] K. Frankish, W. M. Ramsey: The Cambridge handbook of artificial intelligence, Cambridge: Cambridge University Press, 2014
[26] E. Alonso: Multi-Agent Learning, Special issue of Autonomous Agents and Multi-Agent Systems 15(1), 2007
[27] E. Alonso: M. d’Inverno, D. Kudenko, M. Luck, J. Noble: Learning in multi-agent systems, Knowledge Engineering Review 16: 277-84, 2001
[28] M. Veloso, P. Stone: Multiagent systems: A survey from a machine learning perspective, Autonomous Robots 8: 345-83, 2000
[29] R. Vohra, M. Wellmann: Foundations of multi-agent learning, Artificial Intelligence 171:363-4, 2007
[30] L. Busoniu, R. Babuska, B. De Schutter: A comprehensive survey of multi-agent reinforcement learning, IEEE Transactions on Systems, Man, and Cybernetics – Part C: Applications and Reviews 38: 156-72, 2008
[31] Die Evolutionsstrategien sind eine in Deutschland entwickelte Variante der sog. Evolutionären Algorithmen. Sie sind für derartige Aufgabenstellungen deutlich leistungsfähiger als die genetischen Algorithmen. Siehe z.B. Th. Bäck: Evolutionary Algorithms in Theory and Practice, Oxford University Press, NY, 1996.
[32] Z.B.: Th. Bäck, C. Foussette, P. Krause: Automatische Metamodellierung von CAE-Simulationsmodellen, ATZ – Automobiltechnische Zeitschrift 117(5), 64-69, 2015.
[33] Für Details: http://www.divis-gmbh.de/fileadmin/download/fallbeispiele/140311_Fallbeispiel_BMW_Machbarkeitsbewertung_Umformsimulation_DE.pdf
[34] Der Begriff wird sehr vielfältig verwendet, und ist in der Tat sehr allgemein. Wir verwenden ihn hier im Sinne einer kontinuierlichen Überwachung der Unternehmenskennzahlen, die z.B. auf Wochenebene automatisch erstellt und analysiert werden.
[35] http://www.automotive-fleet.com/news/story/2003/02/gm-installs-nutechs-vehicle-distribution-system.aspx
[36] C. Sorg: Data Mining als Methode zur Industrialisierung und Qualifizierung neuer Fertigungsprozesse für CFK-Bauteile in automobiler Großserienproduktion. Dissertation, TU München, 2014. Dr. Hut Verlag.
[37] Als ein Beispiel sei auf den Beitrag http://www.enbis.org/activities/events/current/214_ENBIS_12_in_Ljubljana/programmeitem/1183_Ask_the_Right_Questions__or_Apply_Involved_Statistics__Thoughts_on_the_Analysis_of_Customer_Satisfaction_Data verwiesen.
[38] http://www.syntragy.com/doc/q3-05%5B1%5D.pdf
[39] L. Gräning, B. Sendhoff: Shape mining: A holistic data mining approach to engineering design. Advanced Engineering Informatics 28(2), 166-185, 2014.
[40] F. Neukart: Reverse-Engineering the Mind, siehe https://www.scribd.com/mobile/doc/195264056/Reverse-Engineering-the-Mind, 2014
[41] F. Neukart: On Quantum Computers and Artificial Neural Networks, Signal Processing Research 2(1), 2013








I just like the helpful information you provide on your
articles. I’ll bookmark your blog and take a look at once more right here regularly.
I am reasonably sure I will learn many new stuff
proper here! Good luck for the following!