Data Science ist ein immer wichtigeres Instrument für Unternehmen, um wertvolle Einblicke in die eigenen Systeme zu bekommen, ineffiziente Arbeitsweisen zu optimieren und um sich Vorteile gegenüber dem Wettbewerb zu verschaffen. Auch abseits der klassischen Softwarekonzerne verstehen Unternehmen mehr und mehr, welche Potenziale in einer systematischen Datenanalyse und in bereits kleinen Machine Learning-Projekten stecken – sei es für die schnellere Auswertung großer Excel-Sheets oder für eine Datenaufbereitung als zusätzlichen Service, der sich als neues Feature an die Kundschaft verkaufen lässt.
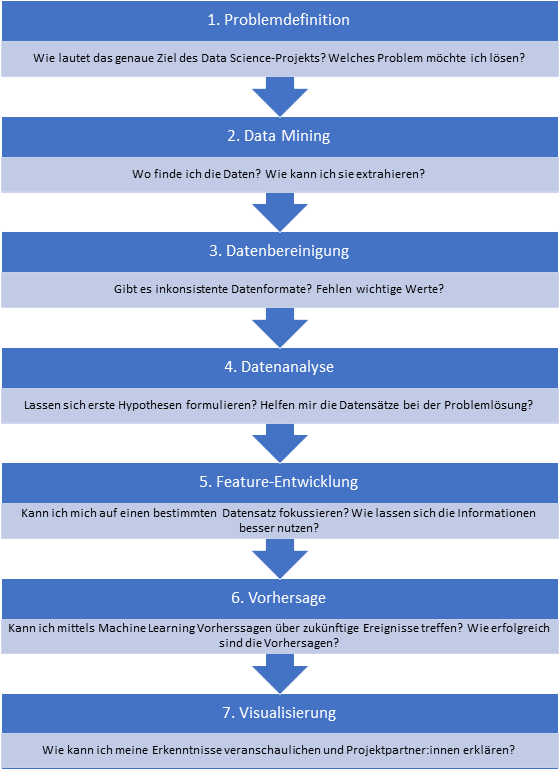
Das sind die typischen Phasen eines Data Science-Projekts. Jeder dieser sieben Schritte lässt sich mit Python umsetzen.
Python steht hoch im Kurs
Unternehmen, die den Nutzen der Data Science verstanden haben, suchen händeringend nach gut ausgebildeten Fachkräften. Eine essenzielle Fähigkeit hierfür: Das Programmieren mit Python. Die Open-Source-Programmiersprache wurde Anfang der 1990er-Jahre vom niederländischen Softwareentwickler Guido van Rossum entwickelt und hat sich innerhalb der letzten 30 Jahre als fester Bestandteil der internationalen IT-Landschaft etabliert.
Python überzeugt seine Anwender:innen mit größter Einfachheit, einer übersichtlichen Syntax und einer geringen Anzahl an Schlüsselwörtern. Im Gegensatz zu anderen beliebten Programmiersprachen wie etwa C++, PHP oder JavaScript kommen Python-Skripte mit vergleichsweise wenig Code aus und ermöglichen Anfänger:innen einen schnellen Einstieg. Zu guter Letzt ist Python plattformunabhängig, sodass Anwendungen auf Linux-, Mac-, Windows- und Unix-Systemen funktionieren.
Aber warum ist Python besonders in der Data Science so beliebt?
Zusätzlich zu den genannten Eigenschaften können sich Anwender:innen aus einem großen Pool an kostenlosen Erweiterungen (genannt „Libraries“ bzw. „Bibliotheken“) bedienen. So gibt es zahlreiche Bibliotheken
speziell für die Data Science, die Entwickler:innen und Python-Communities gratis zur Verfügung stellen. Damit lassen sich alle Schritte eines Data Science-Projekts – vom Sammeln und Bereinigen der Daten bis hin zur Analyse, Vorhersage und Visualisierung – nur mit Python als einziger Programmiersprache umsetzen.
Übrigens: Nur etwa fünf Prozent der weltweiten Python-Entwickler:innen arbeiten in Deutschland. Es werden zwar von Jahr zu Jahr mehr, aber dennoch ist die deutschsprachige Python-Community bisher vergleichsweise klein.
Einblick in die Praxis: Wie wird Python in der Data Science bereits angewendet?
Für viele Data Scientists ist Python die Sprache der Wahl, besonders wenn ein Programm mithilfe von künstlicher Intelligenz aus einem vorhandenen Datensatz „lernen“ und Aussagen über zukünftige Ereignisse treffen soll. Aufgrund seiner vielseitigen Anwendungsmöglichkeiten, der großen Data Science-Community bestehend aus Wissenschaftler:innen, Entwickler:innen und Hobby-Programmierer:innen sowie den frei verfügbaren Bibliotheken, vertrauen nicht nur die großen Tech-Konzerne wie Google, Netflix oder IBM auf Python. Auch Gesundheitsämter, Universitäten oder Banken setzen bei Data Science-Projekten auf Python. Was Sie mit der Programmiersprache theoretisch erreichen können und wie Python bereits eingesetzt wird, erfahren Sie hier anhand von drei Beispielen:
- Schneller und zuverlässiger FAQ-Service dank Chatbots
Auf vielen Webseiten öffnet sich heutzutage nach kurzer Zeit unten rechts ein kleines Chatfenster, in dem Nutzer:innen automatisch gefragt werden, ob sie Hilfe beim Online-Shopping, bei der Reklamation oder bei anderen Themen benötigen. Diese so genannten Chatbots dienen als kleine Helfer im Online-Service und sind meistens mit Python programmiert.
- Waldbrände verhindern – oder zumindest ihre Entwicklung vorhersagen
Auch die Natur kann von der Datenwissenschaft mit Python profitieren. Um beispielsweise den Verlauf eines Waldbrandes vorherzusagen und ihn schneller zu kontrollieren, kann eine Kombination aus den Daten vergangener Waldbrände, Informationen über den aktuellen Zustand des Waldes sowie Wetter- und Windvorhersagen eine große Hilfe sein.
Mithilfe der Datenwissenschaft können Forstämter und Kommunen dafür sorgen, dass die Feuerwehr ihre Einsätze besser plant, weniger Schäden entstehen und chaotische Waldbrände vermieden werden. Je mehr Daten zur Verfügung stehen, desto zuverlässiger unterstützt die Datenanalyse bei der Waldbrandbekämpfung.
- Große Potenziale für Medizin und Pharmazie
Data Science und Machine Learning bieten auch für Medizin und Pharmazie gewaltige Chancen, um Medikamente, Therapien und Vorhersagen zu optimieren. Ein wichtiges Stichwort ist hierbei die computergestützte Diagnose – etwa bei der Früherkennung von Parkinson oder verschiedenen Krebsarten.
In Kombination mit klassischen Untersuchungsmethoden lassen sich so schneller zuverlässigere Prognosen treffen, die das Eingriffsrisiko minimieren und somit Leben retten.
Was muss ich mitbringen, um Python zu lernen?
Wie bereits erwähnt ist Python eine einfache Programmiersprache, die gut lesbar ist und mit wenig Code auskommt. Trotzdem zögern viele Anfänger:innen, wenn sie das erste Mal die Kommandozeile aufrufen und mit einem Programm beginnen. Wesentlich komplexer wird es, wenn sich Anwender:innen in Python an einem Data Science-Projekt widmen, da hier nicht nur eine gewisse Code-Kenntnis, sondern auch Mathematik und Statistik wichtig sind. Wir empfehlen Ihnen deshalb: Konzentrieren Sie sich auf die folgenden vier Bereiche, um möglichst einfach in die Welt der Data Science mit Python einzusteigen.
Statistik und Mathematik
Es lässt sich nicht leugnen, dass Mathematik das Herzstück der Data Science ist. Um jedoch Daten gewinnbringend mit Python auszuwerten, muss man auch kein Alan Mathematik-Spezialist sein. Es ist von Vorteil, wenn Sie Ihre Mathematikkenntnisse aus der Schulzeit auffrischen und sich vor Ihrem ersten Projekt in die statistischen Grundphänomene einlesen. So fällt es Ihnen später leichter, Korrelationen und Fehler im Datensatz zu erkennen.
Interesse an Programmierung und Visualisierung
Zwar unterscheidet sich Python in Syntax und Struktur von anderen bekannten Programmiersprachen, aber dennoch fällt Ihnen der Einstieg leichter, wenn Sie bereits vorab ein Interesse am Programmieren besitzen. Allein das Verständnis, wie aus einem HTML-Code eine ansehnliche Webseite wird, vereinfacht es Ihnen, den Zusammenhang von Code-Input und Programm-Output zu verstehen.Es gibt aber auch Python-Trainings und -Kurse, in denen keinerlei Programmiererfahrungen vorausgesetzt werden. Darüber hinaus spielt die Visualisierung der Daten eine wichtige Rolle, um die Erkenntnisse der Data Science auch für andere Kolleg:innen begreifbar zu machen.
Englischkenntnisse sind von Vorteil
Da wie eingangs erwähnt nur wenige Python-Entwickler:innen aus Deutschland stammen, werden Sie viele Tutorials und Foren-Beiträge in englischer Sprache vorfinden. Damit Sie besser verstehen, welche Anweisungen die Python-Community empfiehlt, ist eine gewisse Englischkenntnis bzw. ein Wörterbuch in greifbarer Nähe vorteilhaft.
Motivation und Neugier
Zuletzt hängt der Erfolg Ihrer Data Science-Projekte mit Python auch von Ihrer Motivation und Neugier ab. In diversen Foren, wie zum Beispiel auf der US-amerikanischen Plattform Reddit, finden Sie kleine Aufgaben speziell für Anfänger:innen, die Ihnen Schritt für Schritt den Umgang mit Python erleichtern. Wenn Sie sich mit solchen Aufgaben üben, werden Sie schnell den Umgang mit Python erlernen.
Die Trainings der Haufe Akademie zu Python und Data Science
Die Haufe Akademie ist ein Sponsor des Data Science Blogs. Lernen Sie mit ihr die Basics der Programmiersprache Python und erfahren Sie, wie Sie selbst einfache Automatisierungen wie auch größere Data Science-Projekte erfolgreich umsetzen können. Mehr erfahren über die Haufe Akademie!