Automatic Financial Trading Agent for Low-risk Portfolio Management using Deep Reinforcement Learning
This article focuses on autonomous trading agent to solve the capital market portfolio management problem. Researchers aim to achieve higher portfolio return while preferring lower-risk actions. It uses deep reinforcement learning Deep Q-Network (DQN) to train the agent. The main contribution of their work is the proposed target policy.
Introduction
Author emphasizes the importance of low-risk actions for two reasons: 1) the weak positive correlation between risk and profit suggests high returns can be obtained with low-risk actions, and 2) customer satisfaction decreases with increases in investment risk, which is undesirable. Author challenges the limitation of Supervised Learning algorithm since it requires domain knowledge. Thus, they propose Reinforcement Learning to be more suitable, because it only requires state, action and reward specifications.
The study verifies the method through the back-test in the cryptocurrency market because it is extremely volatile and offers enormous and diverse data. Agents then learn with shorter periods and are tested for the same period to verify the robustness of the method.
2 Proposed Method
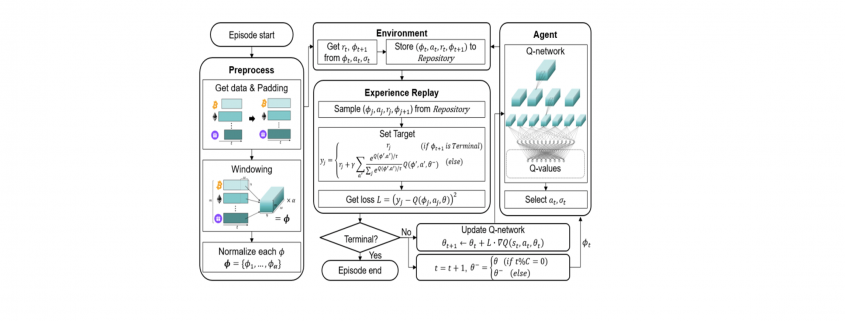
The overall structure of the proposed method is shown below.
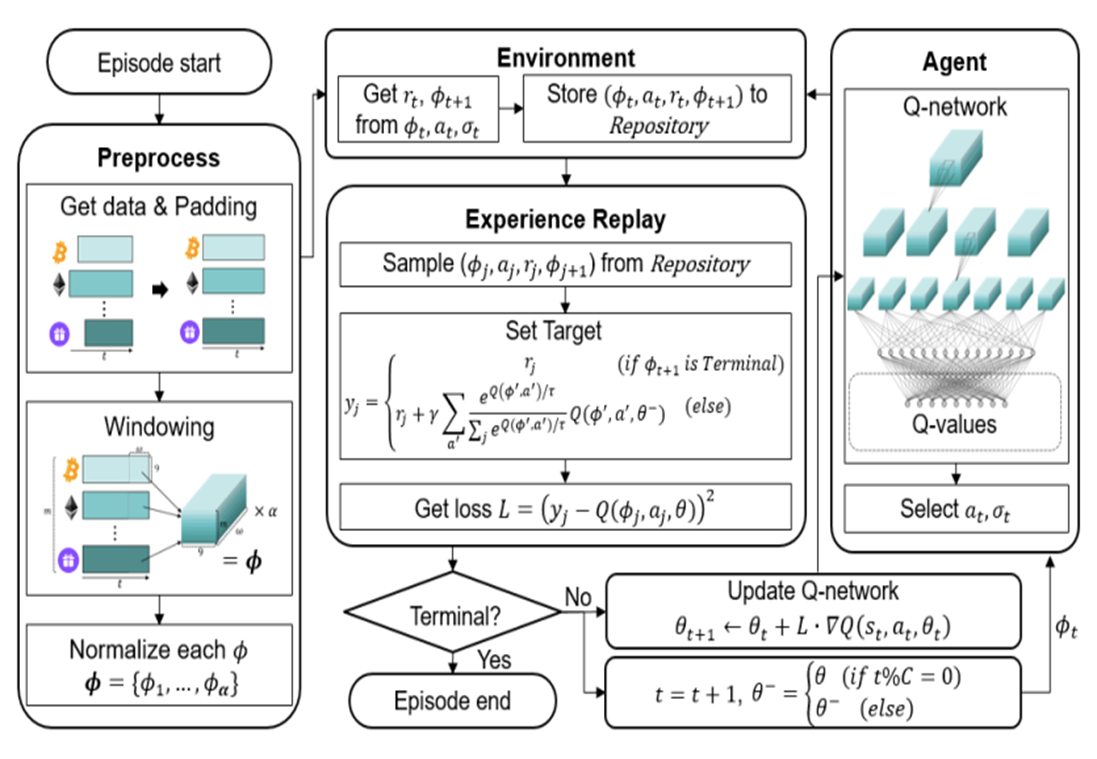
The architecutre of the proposed trading agent system.
2.1 Problem Definition
The portfolio consists of m assets and one base currency.
The price vector p stores the price p of all assets:
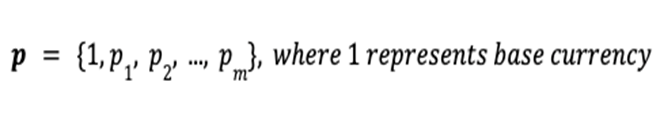
The portfolio vector w stores the amount of each asset:
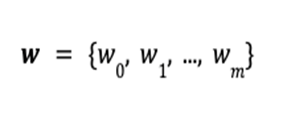
At time  , the total value
, the total value  of the portfolio is defined as the inner product of the price vector
of the portfolio is defined as the inner product of the price vector  and the portfolio vector
and the portfolio vector  .
.
![]()
Finally, the goal is to maximize the profit  at the terminal time step
at the terminal time step  .
.
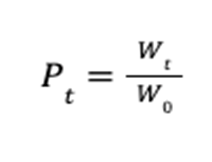
2.2 Asset Data Preprocessing
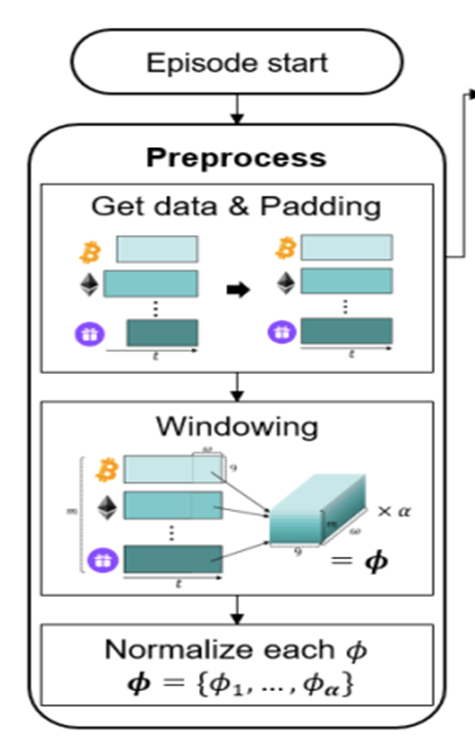
1) Asset Selection
Data is drawn from the Binance Exchange API, where top m traded coins are selected as assets.
2) Data Collection
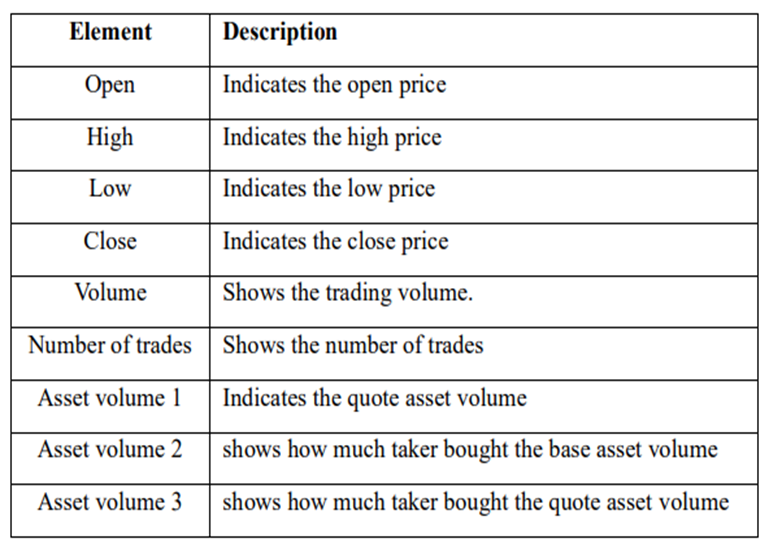
Each coin has 9 properties, shown in Table.1, so each trade history matrix has size (α * 9), where α is the size of the target period converted into minutes.
3) Zero-Padding
Pad all other coins to match the matrix size of the longest coin. (Coins have different listing days)
Comment: Author pointed out that zero-padding may be lacking, but empirical results still confirm their method covering the missing data well.
4) Stack Matrices
Stack m matrices of size (α * 9) to form a block of size (m* α * 9). Then, use sliding window method with widow size w to create (α – w + 1) number of sequential blocks with size (w * m * 9).

5) Normalization
Normalize blocks with min-max normalization method. They are called history block 𝜙 and used as input (ie. state) for the agent.
3. Deep Q-Network
The proposed RL-based trading system follows the DQN structure.
Deep Q-Network has 2 networks, Q- and Target network, and a component called experience replay. The Q-network is the agent that is trained to produce the optimal state-action value (aka. q-value).
Comment: Q-value is calculated by the Bellman equation, which, in short, consists of the immediate reward from next action, and the discounted value of the next state by following the policy for all subsequent steps.
Here,
Agent: Portfolio manager
Action a: Trading strategy according to the current state
State 𝜙 : State of the capital market environment
Environment: Has all trade histories for assets, return reward r and provide next state 𝜙’ to agent again
DQN workflow:
DQN gets trained in multiple time steps of multiple episodes. Let’s look at the workflow of one episode.
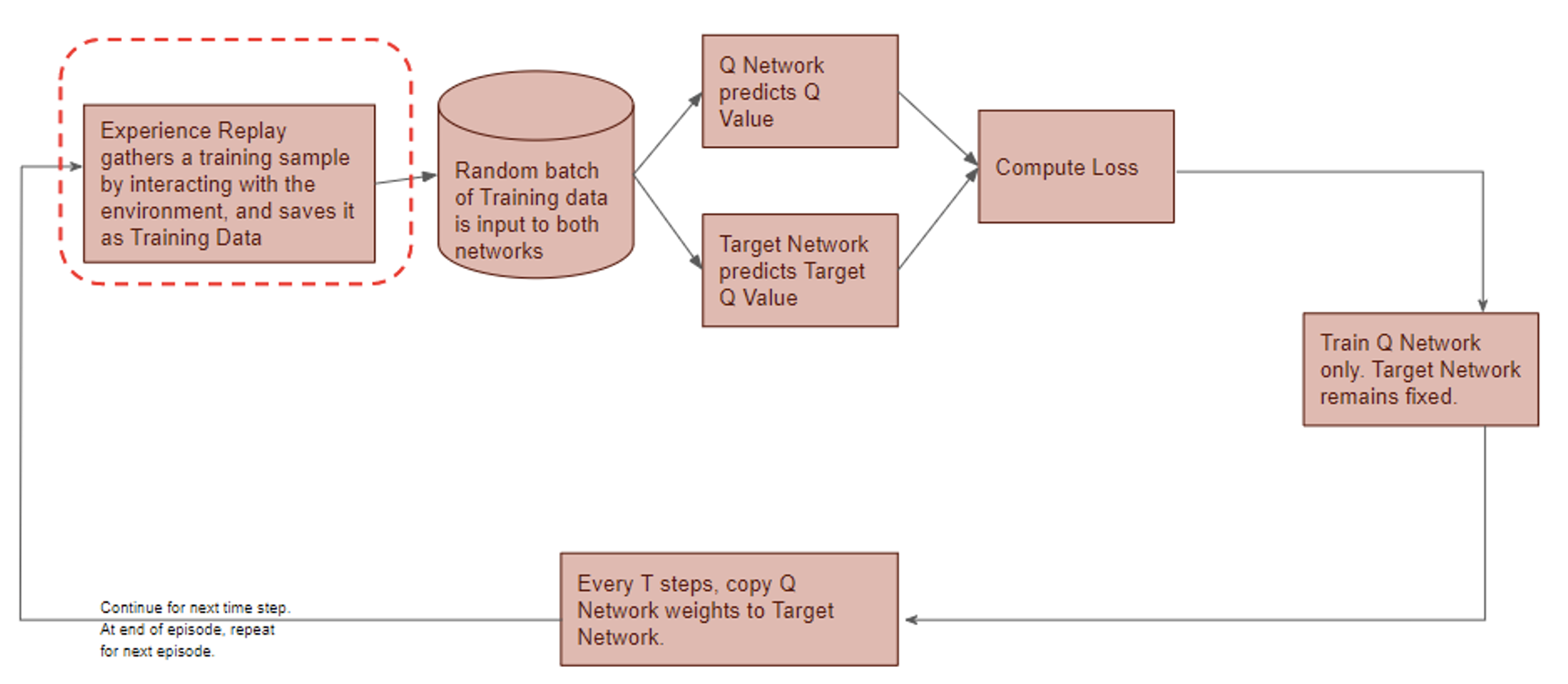
Training of a Deep Q-Network
1) Experience replay selects an action according to the behavior policy, executes in the environment, returns the reward and next state. This experience set ( ) is stored in the repository as a sample of training data.
) is stored in the repository as a sample of training data.
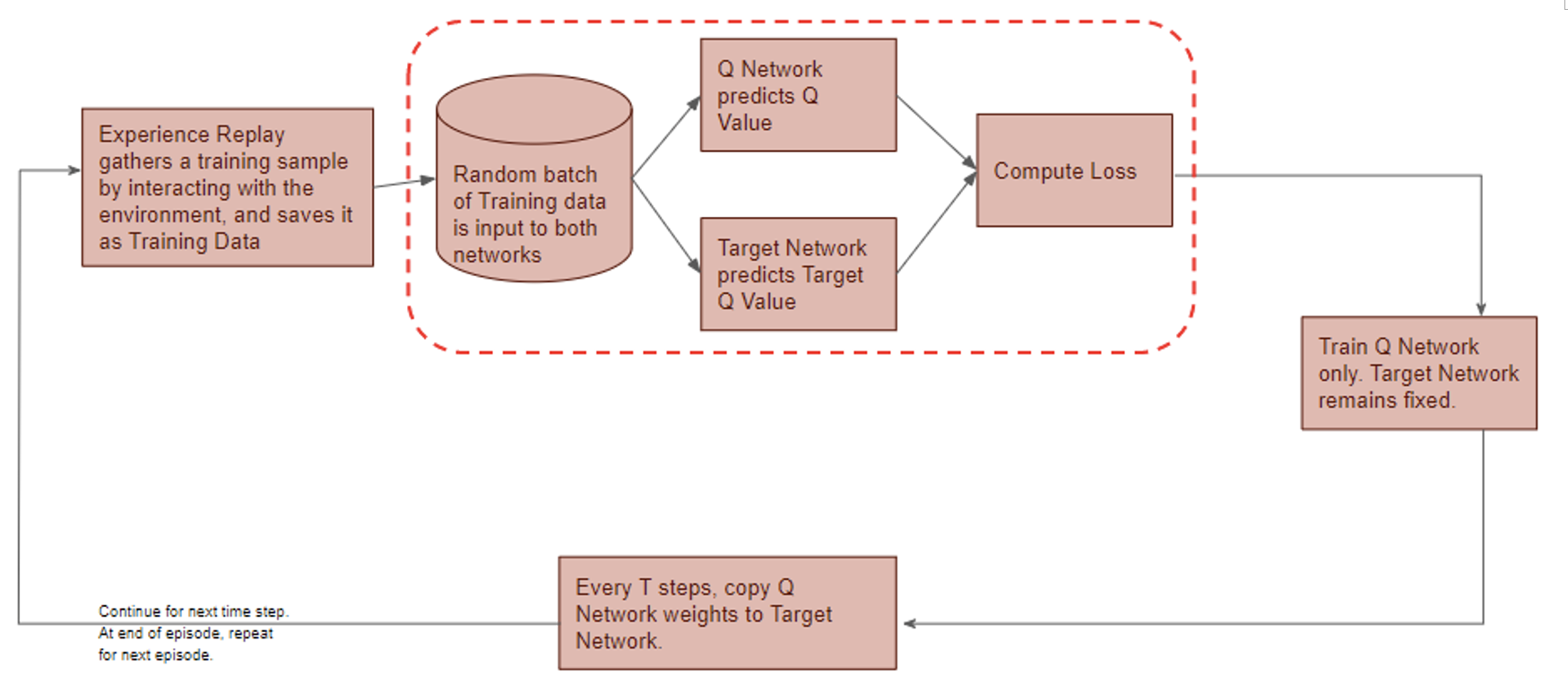
2) From the repository of prior observations, take a random batch of samples as the input to both Q- and Target network. The Q-network takes the current state and action from each data sample and predicts the q-value for that particular action. This is the ‘Predicted Q-Value’.Comment: Author uses 𝜀-greedy algorithm to calculate q-value and select action. To simplify, 𝜀-greedy policy takes the optimal action if a randomly generated number is greater than 𝜀, which represents a tradeoff between exploration and exploitation.
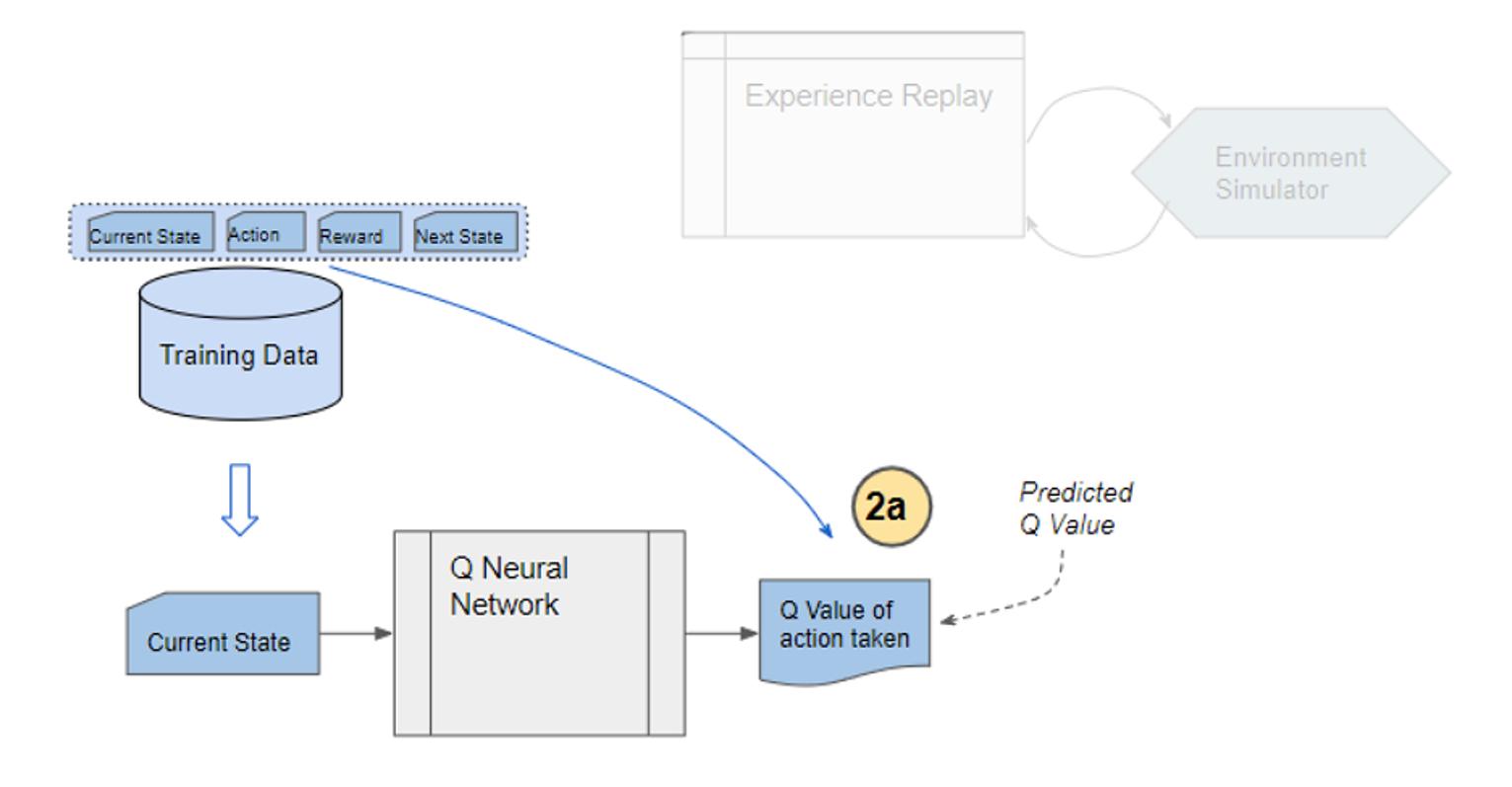 The Target network takes the next state from each data sample and predicts the best q-value out of all actions that can be taken from that state. This is the ‘Target Q-Value’.
The Target network takes the next state from each data sample and predicts the best q-value out of all actions that can be taken from that state. This is the ‘Target Q-Value’.
Comment: Author proposes a different target policy to calculate the target q-value.
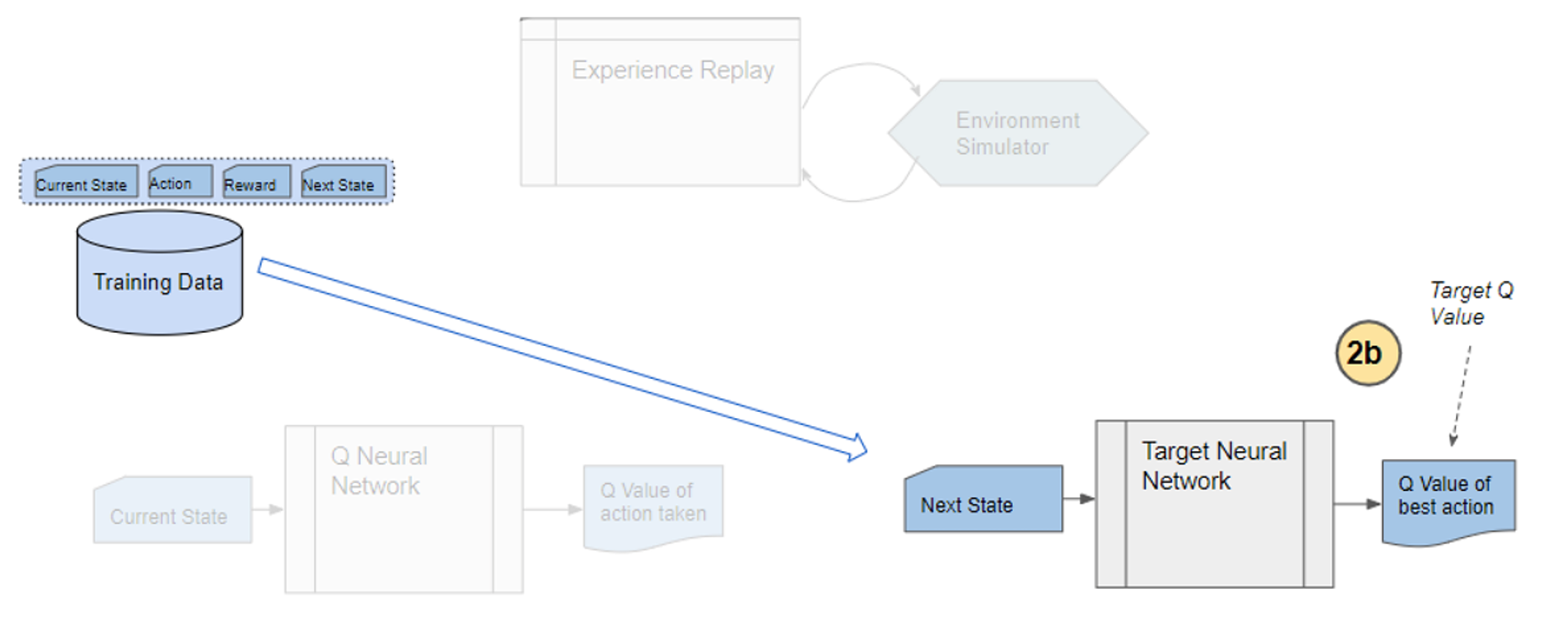
3) The Predicted q-value, Target q-value, and the observed reward from the data sample is used to compute the Loss to train the Q-network.
Comment: Target Network is not trained. It is held constant to serve as a stable target for learning and will be updated with a frequency different from the Q-network.
4) Copy Q-network weights to Target network after n time steps and continue to next time step until this episode is finished.
4.0 Main Contribution of the Research
4.1 Action and Reward
Agent determines not only action a but ratio , at which the action is applied.
- Action:
Hold, buy and sell. Buy and sell are defined discretely for each asset. Hold holds all assets. Therefore, there are (2m + 1) actions in the action set A.
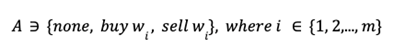
Agent obtains q-value of each action through q-network and selects action by using 𝜀-greedy algorithm as behavior policy. - Ratio:
 is defined as the softmax value for the q-value of each action (ie. i-th asset at
is defined as the softmax value for the q-value of each action (ie. i-th asset at  , then i-th asset is bought using 50% of base currency).
, then i-th asset is bought using 50% of base currency).

- Reward:
Reward depends on the portfolio value before and after the trading strategy. It is clipped to [-1,1] to avoid overfitting.
4.2 Proposed Target Policy
Author sets the target based on the expected SARSA algorithm with some modification.
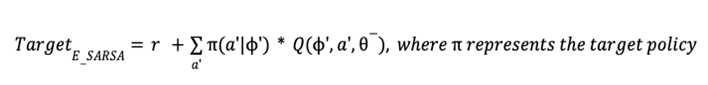
Comment: Author claims that greedy policy ignores the risks that may arise from exploring other outcomes other than the optimal one, which is fatal for domains where safe actions are preferred (ie. capital market).
The proposed policy uses softmax algorithm adjusted with greediness according to the temperature term 𝜏. However, softmax value is very sensitive to the differences in optimal q-value of states. To stabilize learning, and thus to get similar greediness in all states, author redefine 𝜏 as the mean of absolute values for all q-values in each state multiplied by a hyperparameter 𝜏’.

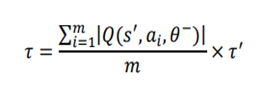
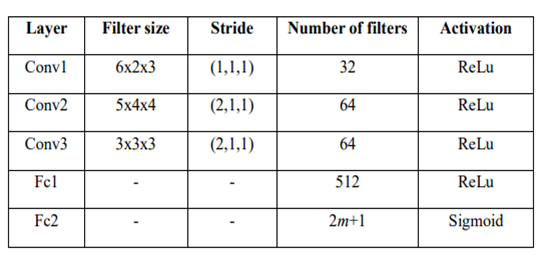
4.3 Q-Network Structure
This study uses Convolutional Neural Network (CNN) to construct the networks. Detailed structure of the networks is shown in Table 2.
Comment: CNN is a deep neural network method that hierarchically extracts local features through a weighted filter. More details see: https://towardsdatascience.com/stock-market-action-prediction-with-convnet-8689238feae3.
5 Experiment and Hyperparameter Tuning
5.1 Experiment Setting
Data is collected from August 2017 to March 2018 when the price fluctuates extensively.
Three evaluation metrics are used to compare the performance of the trading agent.
- Profit introduced in 2.1.
- Sharpe Ratio: A measure of return, taking risk into account.
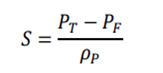
Comment: is the standard deviation of the expected return and  is the return of a risk-free asset, which is set to 0 here.
is the return of a risk-free asset, which is set to 0 here. - Maximum Drawdown: Maximum loss from a peak to a through, taking downside risk into account.
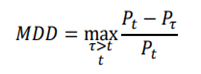
5.2 Hyperparameter Optimization
The proposed method has a number of hyperparameters: window size mentioned in 2.2, 𝜏’ in the target policy, and hyperparameters used in DQN structure. Author believes the former two are key determinants for the study and performs GridSearch to set w = 30, 𝜏’ = 0.25. The other hyperparameters are determined using heuristic search. Specifications of all hyperparameters are summarized in the last page.
Comment: Heuristic is a type of search that looks for a good solution, not necessarily a perfect one, out of the available options.
5.3 Performance Evaluation
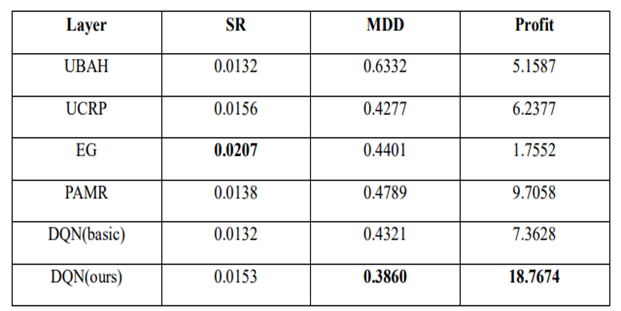
Benchmark algorithms:
UBAH (Uniform buy and hold): Invest in all assets and hold until the end.
UCRP (Uniform Constant Rebalanced Portfolio): Rebalance portfolio uniformly for every trading period.
Methods from other studies: hyperparameters as suggested in the studies
EG (Exponential Gradient)
PAMR (Passive Aggressive Mean Reversion Strategy)
Comment: DQN basic uses greedy policy as the target policy.
The proposed DQN method exhibits the best overall results out of the 6 methods. When the agent is trained with shorter periods, although MDD increases significantly, it still performs better than benchmarks and proves its robustness.
6 Conclusion
The proposed method performs well compared to other methods, but there is a main drawback. The encoding method lacked a theoretical basis to successfully encode the information in the capital market, and this opaqueness is a rooted problem for deep learning. Second, the study focuses on its target policy, while there remains room for improvement with its neural network structure.
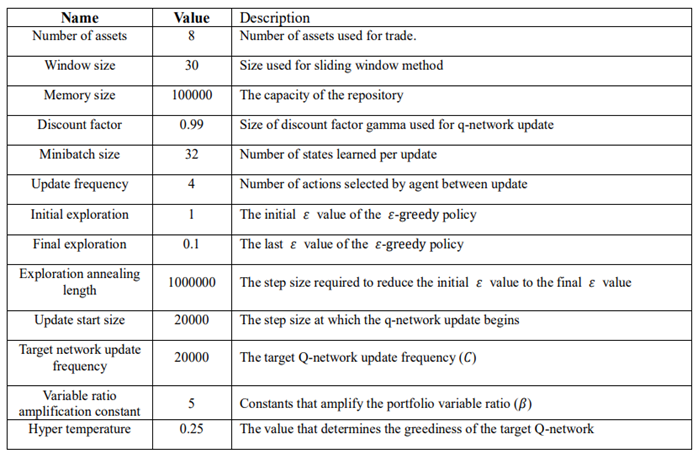
Specification of Hyperparameters.
References
- Shin, S. Bu and S. Cho, “Automatic Financial Trading Agent for Low-risk Portfolio Management using Deep Reinforcement Learning”, https://arxiv.org/pdf/1909.03278.pdf
- Li, P. Zhao, S. C. Hoi, and V. Gopalkrishnan, “PAMR: passive aggressive mean reversion strategy for portfolio selection,” Machine learning, vol. 87, pp. 221-258, 2012.
- P. Helmbold, R. E. Schapire, Y. Singer, and M. K. Warmuth, “On‐line portfolio selection using multiplicative updates,” Mathematical Finance, vol. 8, pp. 325-347, 1998.
http://www.kasimte.com/2020/02/14/how-does-temperature-affect-softmax-in-machine-learning.html

 , and it includes words from “a”, “ablation”, “actually” to “zombie”, “?”, “!”
, and it includes words from “a”, “ablation”, “actually” to “zombie”, “?”, “!” , and the others are
, and the others are  . When you want to choose the No. i word, which is “indeed” in the example below, its corresponding one-hot vector is
. When you want to choose the No. i word, which is “indeed” in the example below, its corresponding one-hot vector is  , where only the No. i element is
, where only the No. i element is 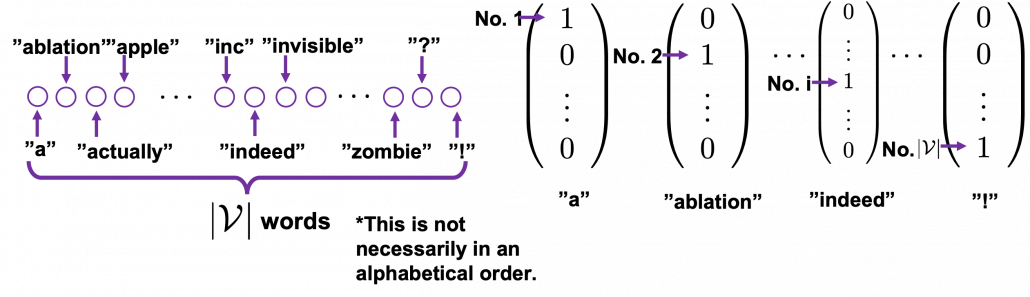
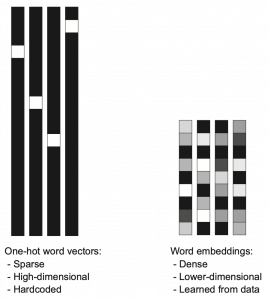
 dimensional vector, whose dimension is fewer than the vocabulary size
dimensional vector, whose dimension is fewer than the vocabulary size 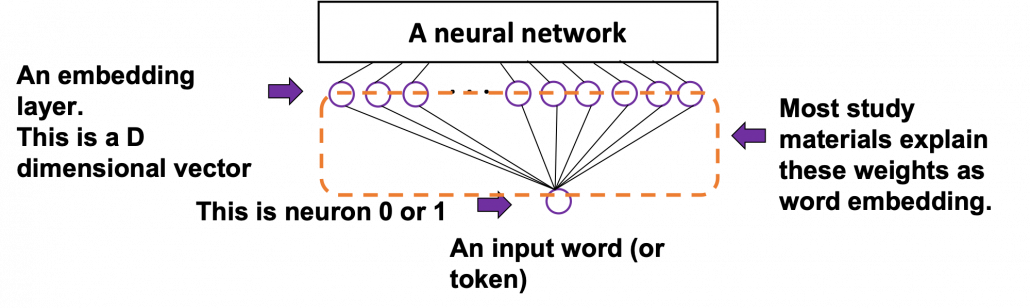
 . When the inputs are “You’ve got the touch” or “You’ve got the power” , you put the one-hot vector corresponding to “You’ve”, “got”, “the”, “touch” or “You’ve”, “got”, “the”, “power” sequentially every time step
. When the inputs are “You’ve got the touch” or “You’ve got the power” , you put the one-hot vector corresponding to “You’ve”, “got”, “the”, “touch” or “You’ve”, “got”, “the”, “power” sequentially every time step  .
.

 ,
,  .
. , a list of vectors. The vectors are usually embedding vectors, and the
, a list of vectors. The vectors are usually embedding vectors, and the  is the index of the order of tokens. For example the sentence “You’ve go the power.” can be expressed as
is the index of the order of tokens. For example the sentence “You’ve go the power.” can be expressed as  , where
, where  denote “You’ve”, “got”, “the”, “power”, “.” respectively. In this case
denote “You’ve”, “got”, “the”, “power”, “.” respectively. In this case  .
. usually includes two tokens
usually includes two tokens  and
and  at the beginning and the end of the sentence. They mean “Beginning Of Sentence” and “End Of Sentence” respectively. Thus in many cases
at the beginning and the end of the sentence. They mean “Beginning Of Sentence” and “End Of Sentence” respectively. Thus in many cases  .
.  and
and  are also both vectors, at least in the Tensorflow tutorial.
are also both vectors, at least in the Tensorflow tutorial.
 is the probability of incidence of the sentence. But it is easy to imagine that it would be very hard to directly calculate how likely the sentence
is the probability of incidence of the sentence. But it is easy to imagine that it would be very hard to directly calculate how likely the sentence  as a product of the probability of incidence or a certain word, given all the words so far. When you’ve got the words
as a product of the probability of incidence or a certain word, given all the words so far. When you’ve got the words  so far, the probability of the incidence of
so far, the probability of the incidence of  , given the context is
, given the context is  .
.  is a probability of the the sentence
is a probability of the the sentence  , and the probability of
, and the probability of  can be decomposed this way:
can be decomposed this way: 
 .
.

 .
.





 be
be  be
be ![P(\boldsymbol{x}^{(t+1)}|\boldsymbol{X}_{[0, t]})](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-9b85b225f0635a7627a99481018f6166_l3.png "Rendered by QuickLaTeX.com") be
be  , then
, then ![P(\boldsymbol{X}) = P(\boldsymbol{x}^{(0)})\prod_{t=0}^{\tau}{P(\boldsymbol{x}^{(t+1)}|\boldsymbol{X}_{[0, t]})}](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-59e2d215f0fea11ec20386dfef220a30_l3.png "Rendered by QuickLaTeX.com") . Language models calculate which words to come sequentially in this way.
. Language models calculate which words to come sequentially in this way.


![P(\boldsymbol{x}^{(0)})\prod_{t=0}^{4}{P(\boldsymbol{x}^{(t+1)}|\boldsymbol{X}_{[0, t]})}](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-4d263b8554a322d3ab8a8841552bc75b_l3.png "Rendered by QuickLaTeX.com") . Given a context
. Given a context  is
is  . In the figure below, the distribution at the left side is less confident because probabilities do not spread widely, on the other hand the one at the right side is more confident that next word is “got” because the distribution concentrates on “got”.
. In the figure below, the distribution at the left side is less confident because probabilities do not spread widely, on the other hand the one at the right side is more confident that next word is “got” because the distribution concentrates on “got”. is
is 

 .
.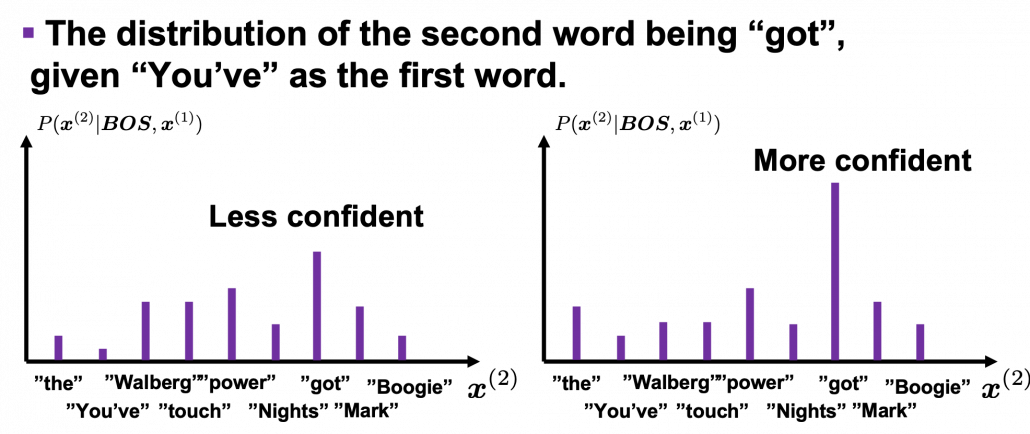



 gets higher. Thus
gets higher. Thus 



 gets lower, where usually
gets lower, where usually  or
or  .
. , which is composed of
, which is composed of  sentences in total. Each sentence
sentences in total. Each sentence 
![(\boldsymbol{x}^{(0)})\prod_{t=0}^{\tau ^{(n)}}{P(\boldsymbol{x}_{n}^{(t+1)}|\boldsymbol{X}_{n, [0, t]})}](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-ccc74ac2aee4f90a6b035dcfd2632927_l3.png "Rendered by QuickLaTeX.com") has
has  tokens in total excluding
tokens in total excluding  . And let
. And let  , where
, where ![z = \frac{-1}{|\mathcal{V}|}\sum_{n=1}^{|\mathcal{D}|}{\sum_{t=0}^{\tau ^{(n)}}{log_{b}P(\boldsymbol{x}_{n}^{(t+1)}|\boldsymbol{X}_{n, [0, t]})}](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-c1ccb76fcad455ad635fc1ec8b2f6f81_l3.png "Rendered by QuickLaTeX.com") . The
. The  is usually
is usually  or
or  .
. is vocabulary {“the”, “You’ve”, “Walberg”, “touch”, “power”, “Nights”, “got”, “Mark”, “Boogie”}. Also assume that the evaluation data set for perplexity of a language model is
is vocabulary {“the”, “You’ve”, “Walberg”, “touch”, “power”, “Nights”, “got”, “Mark”, “Boogie”}. Also assume that the evaluation data set for perplexity of a language model is  , where
, where 
 . In this case
. In this case 
 . I have already showed you how to calculate the perplexity of the sentence “You’ve got the touch.” above. You just need to do a similar thing on another sentence “You’ve got the power”, and then you can get the perplexity of the language model.
. I have already showed you how to calculate the perplexity of the sentence “You’ve got the touch.” above. You just need to do a similar thing on another sentence “You’ve got the power”, and then you can get the perplexity of the language model.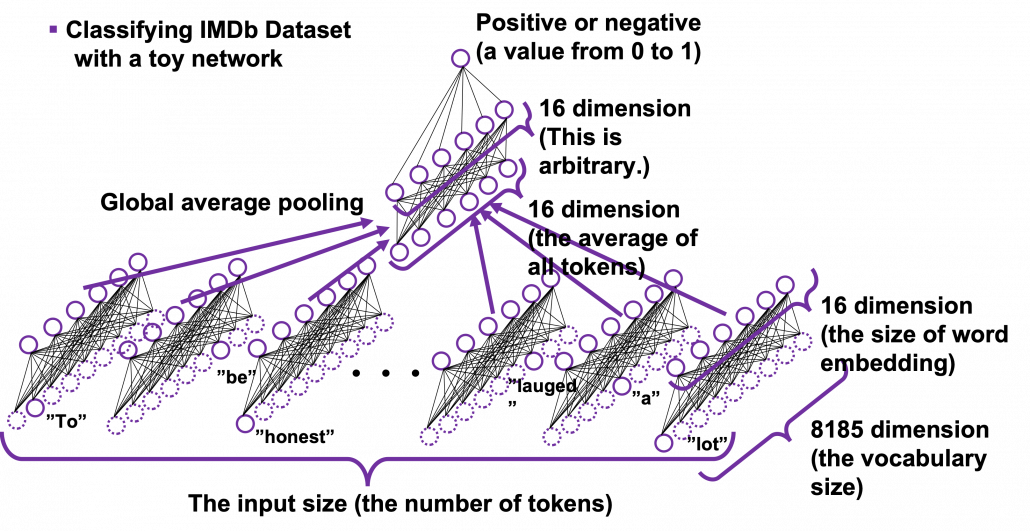

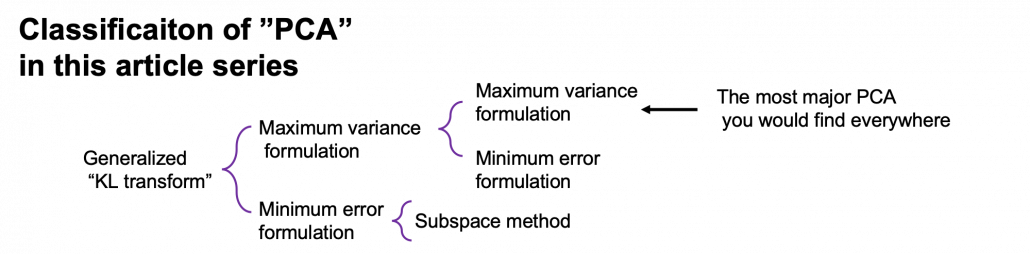
 is a certain type of
is a certain type of  matrix, the formula of a D-dimensional ellipsoid whose center is identical to the origin point is as follows:
matrix, the formula of a D-dimensional ellipsoid whose center is identical to the origin point is as follows:  , where
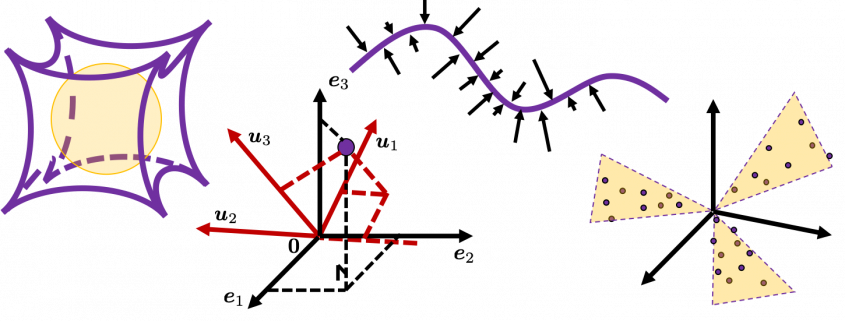
, where  . As is always the case with formulas in data science, you can visualize such ellipsoids if you are talking about 1, 2, or 3 dimensional data like in the figure below, but in general D-dimensional space, it is theoretical/imaginary stuff on blackboards.
. As is always the case with formulas in data science, you can visualize such ellipsoids if you are talking about 1, 2, or 3 dimensional data like in the figure below, but in general D-dimensional space, it is theoretical/imaginary stuff on blackboards.
 , where
, where  or
or  , where
, where  . These are special cases of the equation
. These are special cases of the equation  . In this case the axes of ellipsoids the same as those of the coordinate system. Thus in this simple case,
. In this case the axes of ellipsoids the same as those of the coordinate system. Thus in this simple case,  or
or  .
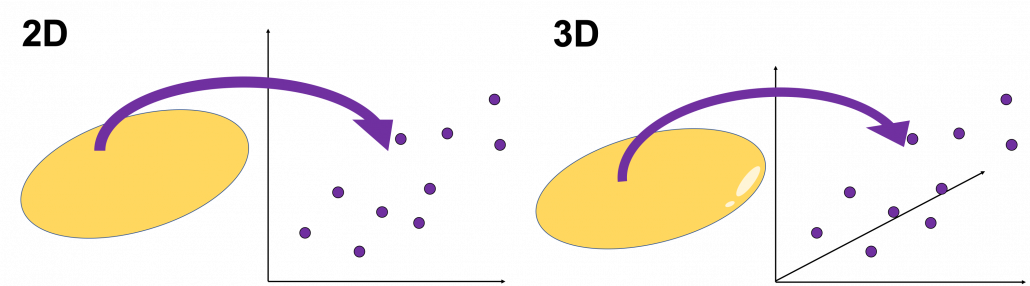
. as below (The samples are plotted in purple). Intuitively, the data “swell” the most along the vector
as below (The samples are plotted in purple). Intuitively, the data “swell” the most along the vector  . Also it is clear that
. Also it is clear that  is the only vector orthogonal to
is the only vector orthogonal to  expresses the data in a better way, and you you can get new coordinate points of the samples by projecting them on new axes as done with yellow lines below.
expresses the data in a better way, and you you can get new coordinate points of the samples by projecting them on new axes as done with yellow lines below.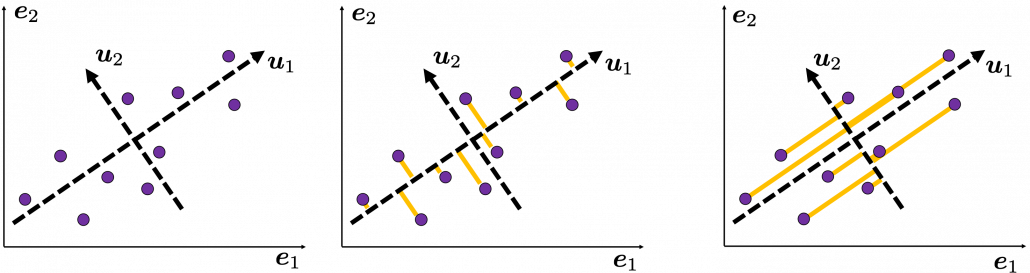
 as below, the data “swell” the most also along
as below, the data “swell” the most also along  .
.

 on the axis
on the axis  .
. is the mean of data in the original coordinate, then the deviation of
is the mean of data in the original coordinate, then the deviation of  on the axis
on the axis  , as shown in the figure. Hence the variance, I mean the mean of the deviation on is
, as shown in the figure. Hence the variance, I mean the mean of the deviation on is  , where
, where  is the total number of data points. After some deformations, you get the next equation
is the total number of data points. After some deformations, you get the next equation  , where
, where  .
.  is known as a covariance matrix.
is known as a covariance matrix. , and for mathematical derivation we need some college level calculus, so if that is too much for you, you can skip reading this part till the next section.
, and for mathematical derivation we need some college level calculus, so if that is too much for you, you can skip reading this part till the next section. including
including  . Introducing a
. Introducing a  . In conclusion
. In conclusion  satisfies
satisfies  . If you have read my last article on eigenvectors, you wold soon realize that this is an equation for calculating eigenvectors, and that means
. If you have read my last article on eigenvectors, you wold soon realize that this is an equation for calculating eigenvectors, and that means  . We have seen that
. We have seen that  is a the variance of data when projected on a vector
is a the variance of data when projected on a vector  is the biggest variance possible when the data are projected on a vector.
is the biggest variance possible when the data are projected on a vector. , and it it the second biggest variance possible, and in this case the date are projected on
, and it it the second biggest variance possible, and in this case the date are projected on 
 matrix
matrix  , and in fact the matrix is just a constant multiplication of this covariance matrix. I think now you understand that PCA is calculating the orthogonal eigenvectors of covariance matrix of data, that is diagonalizing covariance matrix with orthonormal eigenvectors. Hence we can guess that covariance matrix enables a type of linear transformation of rotation and expansion and contraction of vectors. And data points swell along eigenvectors of such matrix.
, and in fact the matrix is just a constant multiplication of this covariance matrix. I think now you understand that PCA is calculating the orthogonal eigenvectors of covariance matrix of data, that is diagonalizing covariance matrix with orthonormal eigenvectors. Hence we can guess that covariance matrix enables a type of linear transformation of rotation and expansion and contraction of vectors. And data points swell along eigenvectors of such matrix.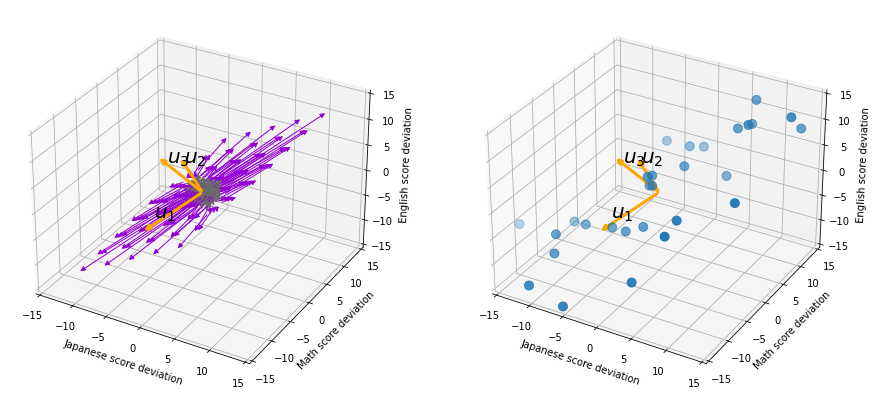
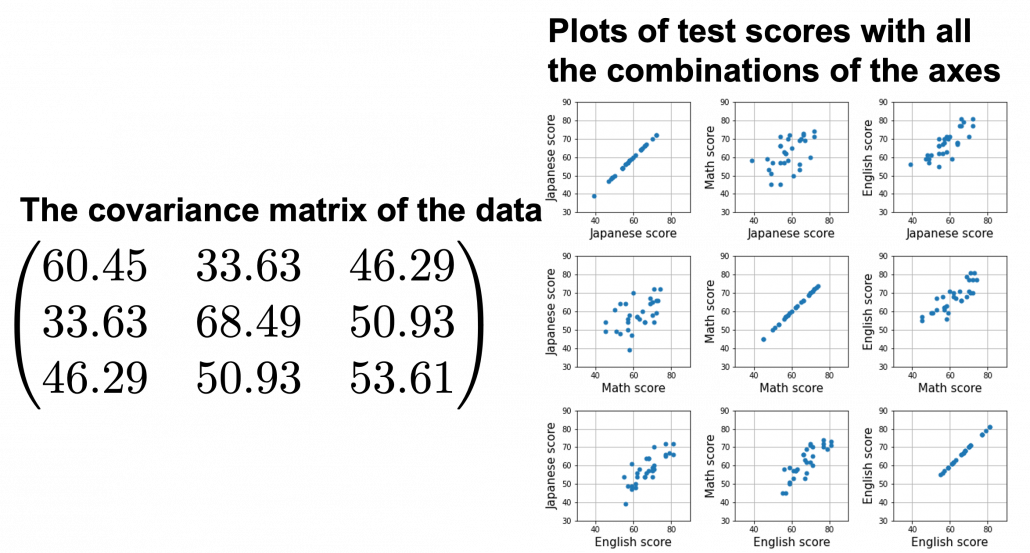
 denote Japanese, Math, English scores respectively. The mean of the data is
denote Japanese, Math, English scores respectively. The mean of the data is  , and the covariance matrix of data in the original coordinate system is
, and the covariance matrix of data in the original coordinate system is  . The eigenvalues of
. The eigenvalues of  are
are  , and
, and  , and their corresponding unit eigenvectors are
, and their corresponding unit eigenvectors are  respectively.
respectively.  is an orthonormal matrix, where
is an orthonormal matrix, where  . As I explained in the last article, you can diagonalize
. As I explained in the last article, you can diagonalize  :
:  .
. .
. means. Each element of
means. Each element of  denotes coordinate of the data point
denotes coordinate of the data point  , and
, and  ).
).  enables a rotation of a rigid body, which means the shape or arrangement of data will not change after the rotation, and
enables a rotation of a rigid body, which means the shape or arrangement of data will not change after the rotation, and  , and
, and  is the coordinate of
is the coordinate of  denotes the coordinate point of the purple point in the red coordinate system.
denotes the coordinate point of the purple point in the red coordinate system.  denotes the coordinates of data projected on new axes
denotes the coordinates of data projected on new axes  , which are unit eigenvectors of
, which are unit eigenvectors of 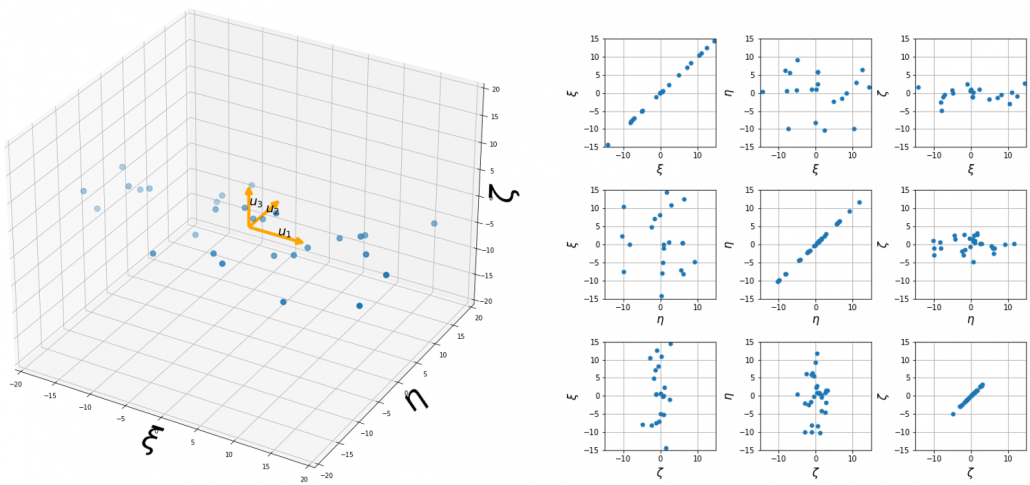
 , which means you can express deviations of the original data as linear combinations of the three factors
, which means you can express deviations of the original data as linear combinations of the three factors  , and
, and  . We expect that those three factors contain keys for understanding the original data more efficiently. If you concretely write down all the equations for the factors:
. We expect that those three factors contain keys for understanding the original data more efficiently. If you concretely write down all the equations for the factors:  ,
,  , and
, and  . If you examine the coefficients of the deviations
. If you examine the coefficients of the deviations  , and
, and  , we can observe that
, we can observe that  almost equally reflects the deviation of the scores of all the subjects, thus we can say
almost equally reflects the deviation of the scores of all the subjects, thus we can say  is
is  . You can see
. You can see  , where
, where  . The variance of data projected on new D-dimensional coordinate system is
. The variance of data projected on new D-dimensional coordinate system is 




 . This means that in the new coordinate system after PCA, covariances between any pair of variants are all zero.
. This means that in the new coordinate system after PCA, covariances between any pair of variants are all zero. .
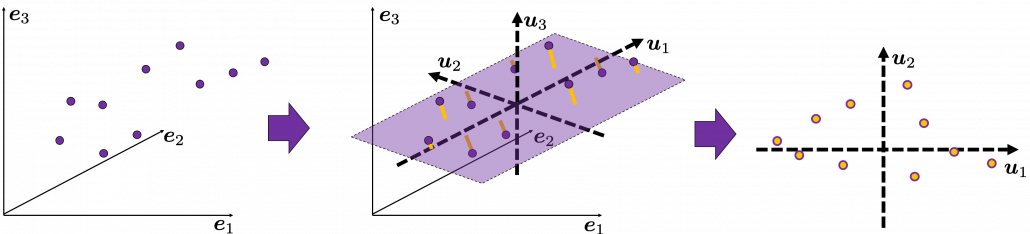
. from the reduced two dimensional coordinate system
from the reduced two dimensional coordinate system  . Then it mathematically clearer that we can express the data with two factors: “how smart the student is” and “whether he is at scientific side or liberal art side.”
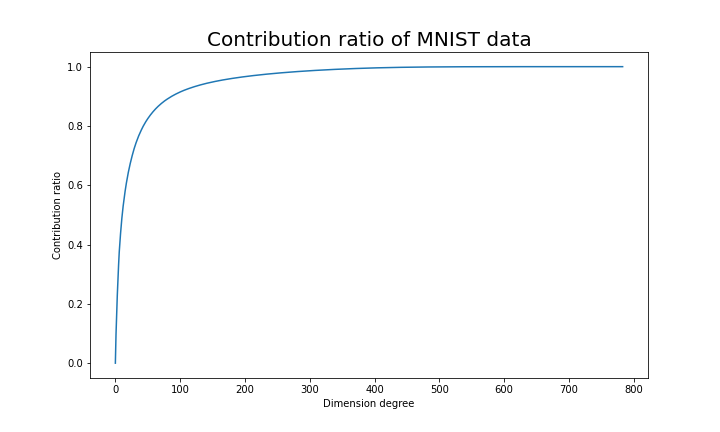
. Then it mathematically clearer that we can express the data with two factors: “how smart the student is” and “whether he is at scientific side or liberal art side.” is a statistic which indicates how much the corresponding
is a statistic which indicates how much the corresponding  is called the contribution ratio of eigenvector
is called the contribution ratio of eigenvector  and
and  are respectively
are respectively  ,
,  ,
,  . You can decide how many degrees of dimensions you reduce based on this information.
. You can decide how many degrees of dimensions you reduce based on this information.



 be a vector space and let
be a vector space and let  be a mapping of
be a mapping of  into itself, defined as
into itself, defined as  , where
, where  is
is  is called an eigen vector if there exists a number
is called an eigen vector if there exists a number  such that
such that  and
and  . In this case
. In this case  , belonging to
, belonging to  . If
. If  is basis of the vector space
is basis of the vector space  matrices
matrices  , whose column vectors are eigen vectors
, whose column vectors are eigen vectors  , where
, where  .
. Most textbooks keep explaining these type of stuff, but I have to say they lack efforts to make it understandable to readers with low mathematical literacy like me. Especially if you have to apply the idea to data science field, I believe you need more visual understanding of diagonalization. Therefore instead of just explaining the definitions and theorems, I would like to take a different approach. But in order to understand them in more intuitive ways, we first have to rethink waht linear transformation
Most textbooks keep explaining these type of stuff, but I have to say they lack efforts to make it understandable to readers with low mathematical literacy like me. Especially if you have to apply the idea to data science field, I believe you need more visual understanding of diagonalization. Therefore instead of just explaining the definitions and theorems, I would like to take a different approach. But in order to understand them in more intuitive ways, we first have to rethink waht linear transformation  means in more visible ways.
means in more visible ways. is a vector transformed by
is a vector transformed by  *I am not going to use the term “linear transformation” in a precise way in the context of linear algebra. In this article or in the context of data science or machine learning, “linear transformation” for the most part means products of matrices or vectors.
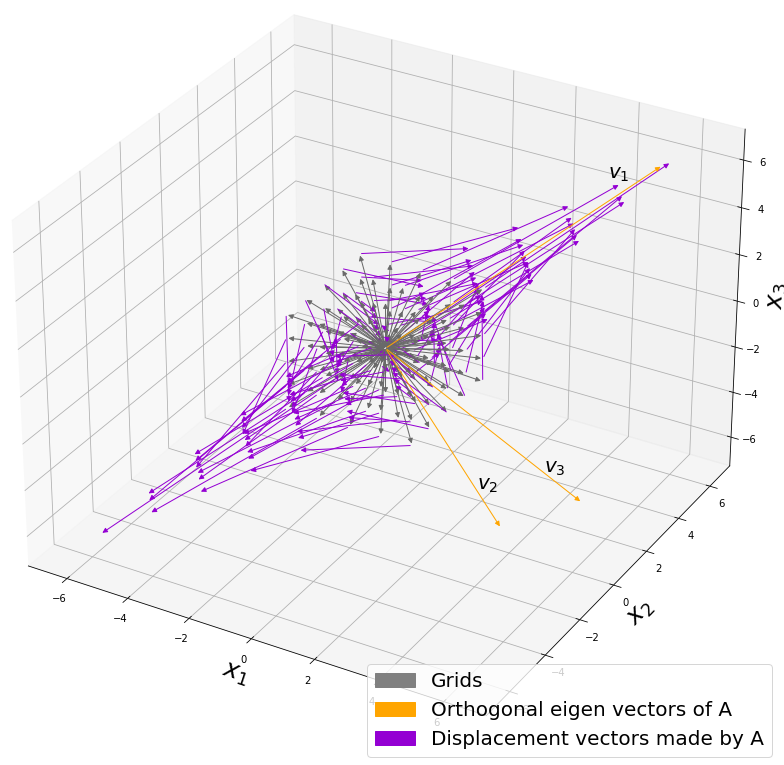
*I am not going to use the term “linear transformation” in a precise way in the context of linear algebra. In this article or in the context of data science or machine learning, “linear transformation” for the most part means products of matrices or vectors. 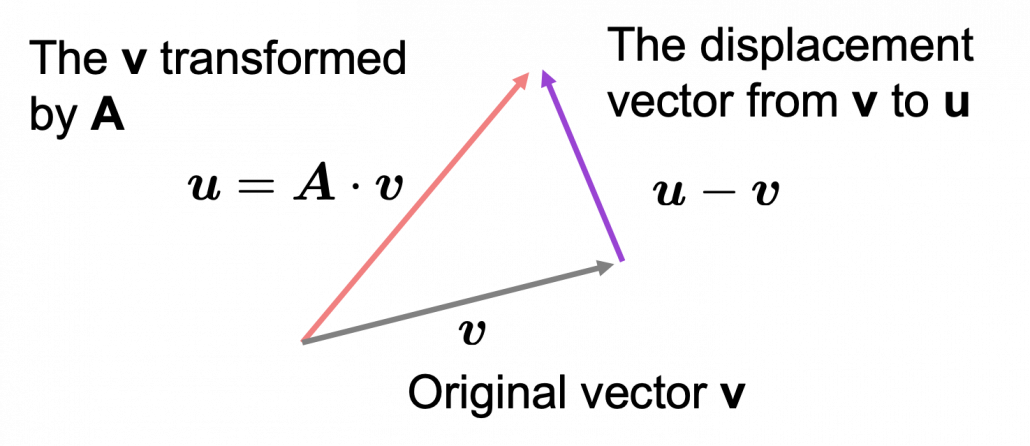 Let’s calculate the displacement vector with more vectors
Let’s calculate the displacement vector with more vectors  , and I prepared several grid vectors
, and I prepared several grid vectors  , which are in purple.
, which are in purple. square matrices
square matrices  , and I plotted displace vectors made by the matrices respectively in the figure below.
, and I plotted displace vectors made by the matrices respectively in the figure below. , the matrix does not have any real eigan values.
, the matrix does not have any real eigan values. is classified to, and I am going to explain positive semidefinite matrices in the fourth section.
is classified to, and I am going to explain positive semidefinite matrices in the fourth section.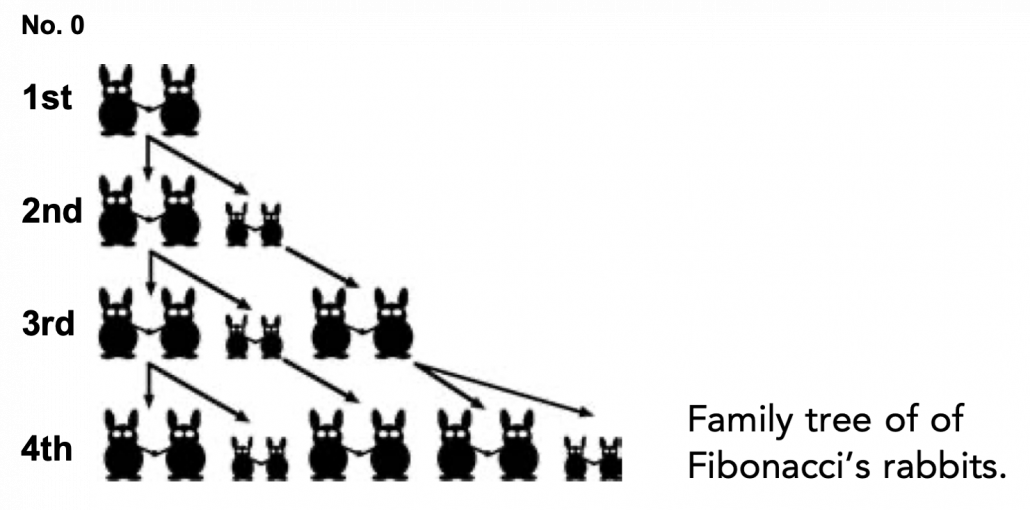
 be the number of pairs of grown up rabbits in the
be the number of pairs of grown up rabbits in the  generation. One pair of grown up rabbits produce one pair of young rabbit The concrete values of
generation. One pair of grown up rabbits produce one pair of young rabbit The concrete values of  are
are  ,
,  ,
,  ,
,  ,
,  ,
,  ,
,  ,
,  . Assume that
. Assume that  and that
and that  , then you can calculate the number of the pairs of grown up rabbits in the next generation with the following recurrence relation.
, then you can calculate the number of the pairs of grown up rabbits in the next generation with the following recurrence relation.  .Let
.Let  be
be  , then the recurrence relation can be written as
, then the recurrence relation can be written as  , and the transition of
, and the transition of 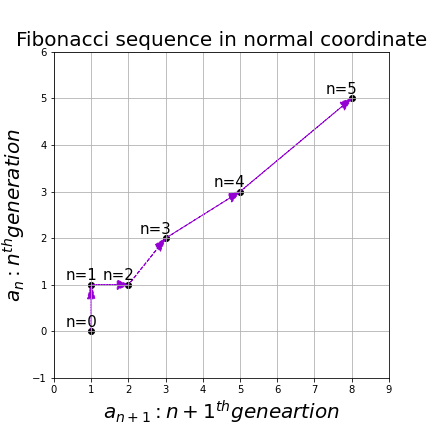
 are eigen values of
are eigen values of  scalars such that
scalars such that  . According to the definition of eigen values and eigen vectors belonging to them, the following two equations hold:
. According to the definition of eigen values and eigen vectors belonging to them, the following two equations hold:  . If you calculate
. If you calculate  is, using eigen vectors of
is, using eigen vectors of  . In the same way,
. In the same way,  , and
, and  . These equations show that in coordinate system made by eigen vectors of
. These equations show that in coordinate system made by eigen vectors of 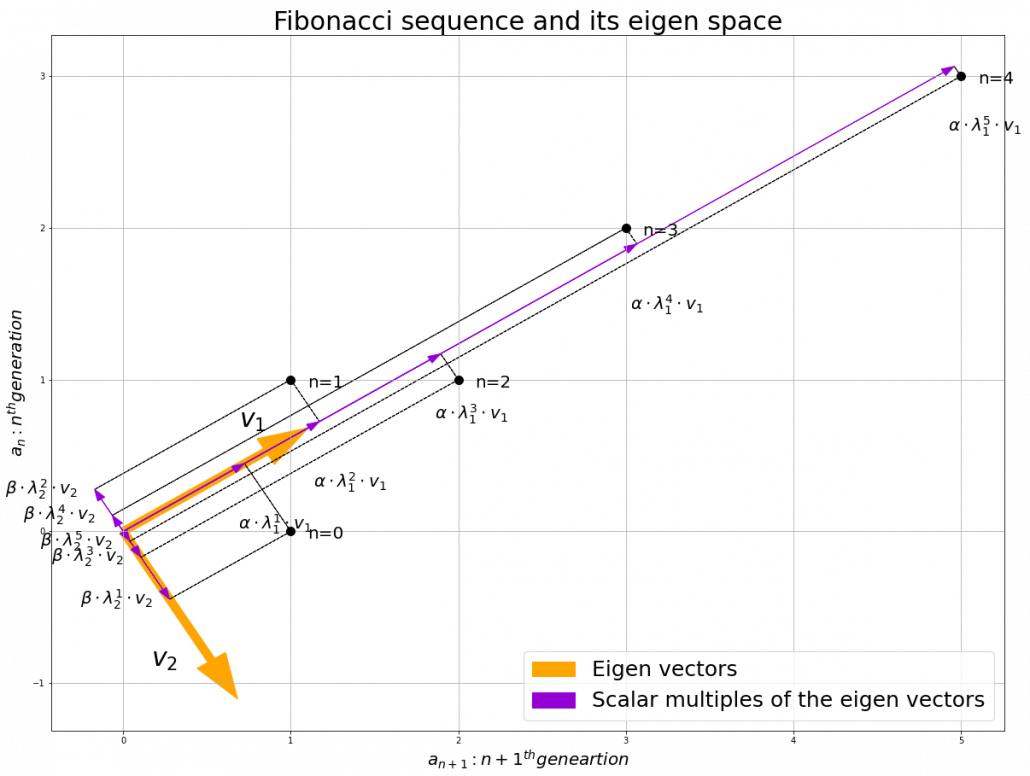
 for all values of the vector
for all values of the vector  for all the eigen values
for all the eigen values  .
. for all values of the vector
for all values of the vector  square positive semidefinite matrix
square positive semidefinite matrix  , whose linear transformation I visualized the second section, is also positive semidefinite.
, whose linear transformation I visualized the second section, is also positive semidefinite. .
.
 , there exist orthonormal matrices
, there exist orthonormal matrices  , where
, where  .
. , where
, where  . In other words column vectors
. In other words column vectors  form an orthonormal coordinate system.
form an orthonormal coordinate system. . Combining this fact with what I have told you so far, you we can reach one conclusion: you can orthogonalize a real symmetric matrix
. Combining this fact with what I have told you so far, you we can reach one conclusion: you can orthogonalize a real symmetric matrix  . This is known as spectral decomposition or singular value decomposition.
. This is known as spectral decomposition or singular value decomposition. is also orthonormal. In other words, assume
is also orthonormal. In other words, assume  ,
,  also forms a orthonormal coordinate system.
also forms a orthonormal coordinate system. expands or contracts vectors along each axis. I am going to explain that more precisely in the upcoming articles.
expands or contracts vectors along each axis. I am going to explain that more precisely in the upcoming articles.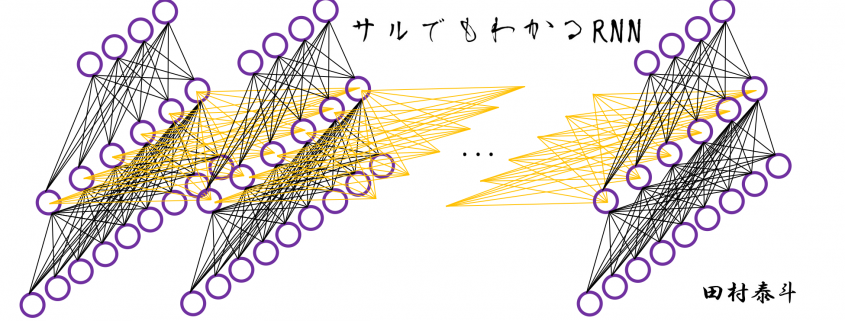
 , then
, then  is a variant, and
is a variant, and  are parameters. In case of classical machine learning algorithms, the number of those parameters are very limited because they were originally designed manually. Such functions for classical machine learning is useful for features found by humans, after trial and errors(feature engineering is a field of finding such effective features, manually). You adjust those parameters based on how different the outputs(estimated outcome of classification/regression) are from supervising vectors(the data prepared to show ideal answers).
are parameters. In case of classical machine learning algorithms, the number of those parameters are very limited because they were originally designed manually. Such functions for classical machine learning is useful for features found by humans, after trial and errors(feature engineering is a field of finding such effective features, manually). You adjust those parameters based on how different the outputs(estimated outcome of classification/regression) are from supervising vectors(the data prepared to show ideal answers).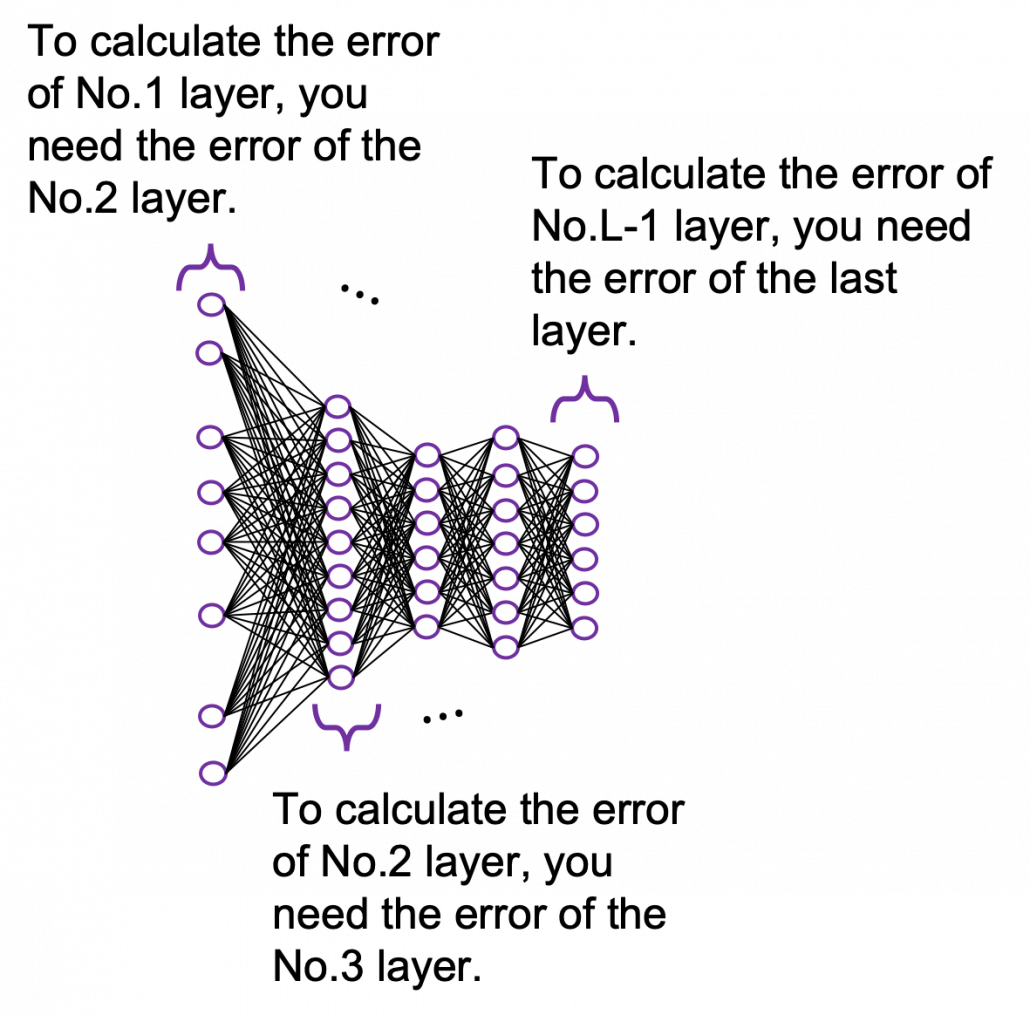
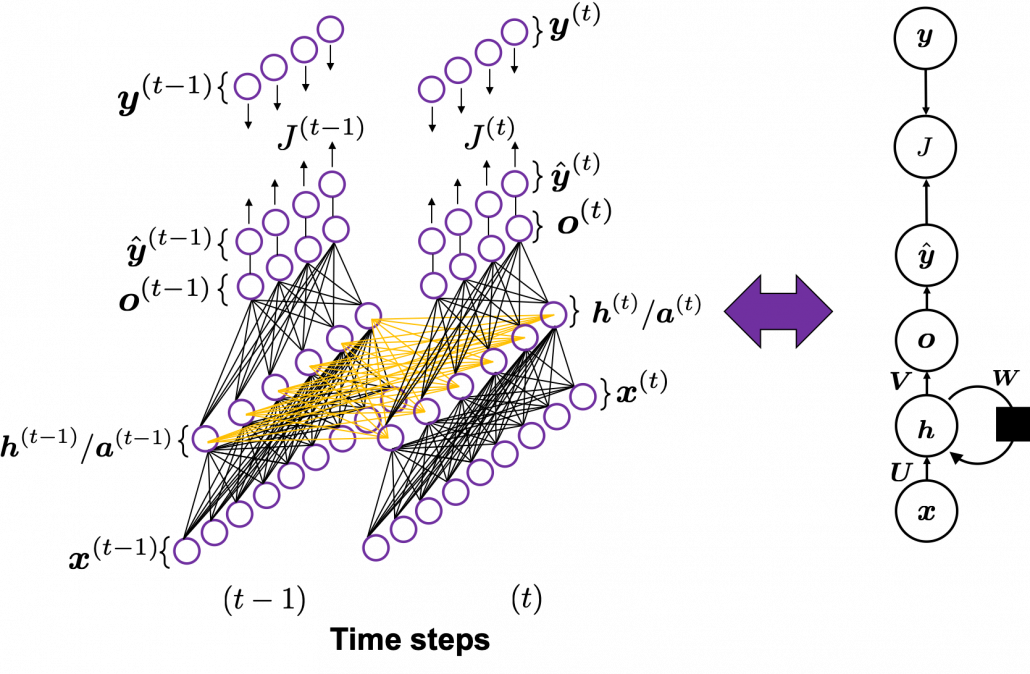
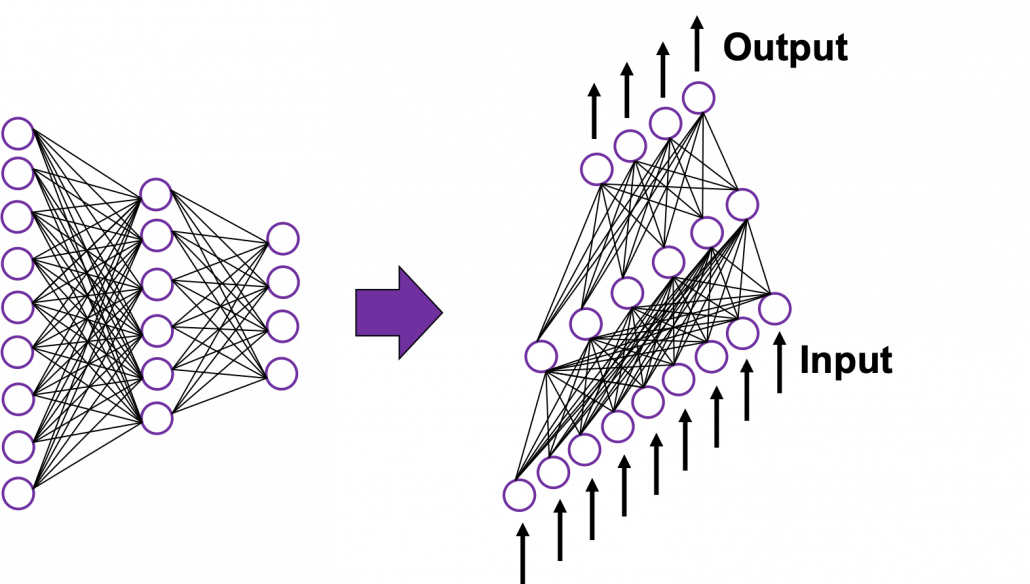 In fact the simple RNN which we are going to look at in this article has only three layers. From now on imagine that inputs of RNN come from the bottom and outputs go up. But RNNs have to keep information of earlier times steps during upcoming several time steps because as I mentioned in the last article RNNs are used for sequence data, the order of whose elements is important. In order to do that, information of the neurons in the middle layer of RNN propagate forward to the middle layer itself. Therefore in one time step of forward propagation of RNN, the input at the time step propagates forward as normal DCL, and the RNN gives out an output at the time step. And information of one neuron in the middle layer propagate forward to the other neurons like yellow arrows in the figure. And the information in the next neuron propagate forward to the other neurons, and this process is repeated. This is called recurrent connections of RNN.
In fact the simple RNN which we are going to look at in this article has only three layers. From now on imagine that inputs of RNN come from the bottom and outputs go up. But RNNs have to keep information of earlier times steps during upcoming several time steps because as I mentioned in the last article RNNs are used for sequence data, the order of whose elements is important. In order to do that, information of the neurons in the middle layer of RNN propagate forward to the middle layer itself. Therefore in one time step of forward propagation of RNN, the input at the time step propagates forward as normal DCL, and the RNN gives out an output at the time step. And information of one neuron in the middle layer propagate forward to the other neurons like yellow arrows in the figure. And the information in the next neuron propagate forward to the other neurons, and this process is repeated. This is called recurrent connections of RNN.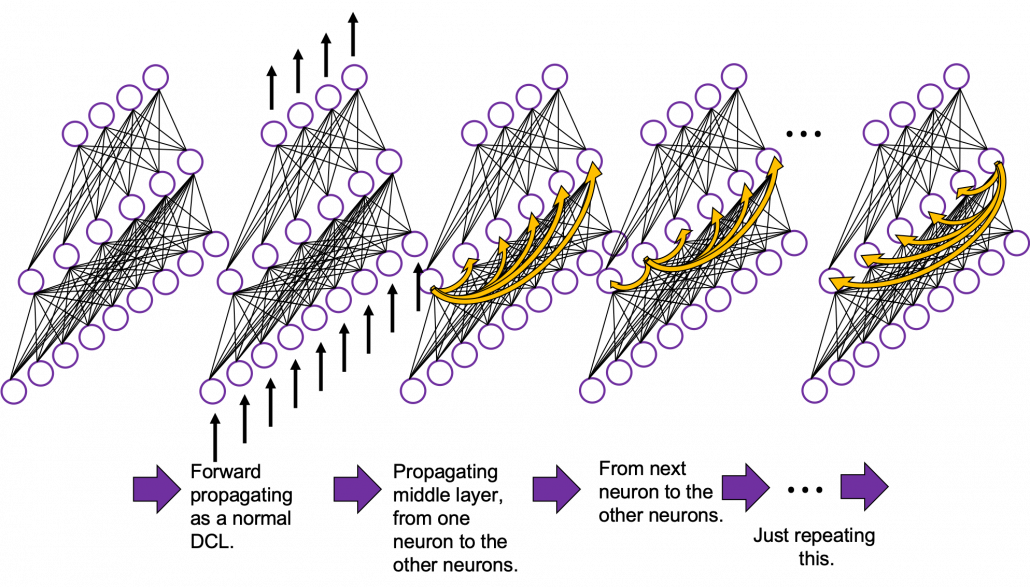
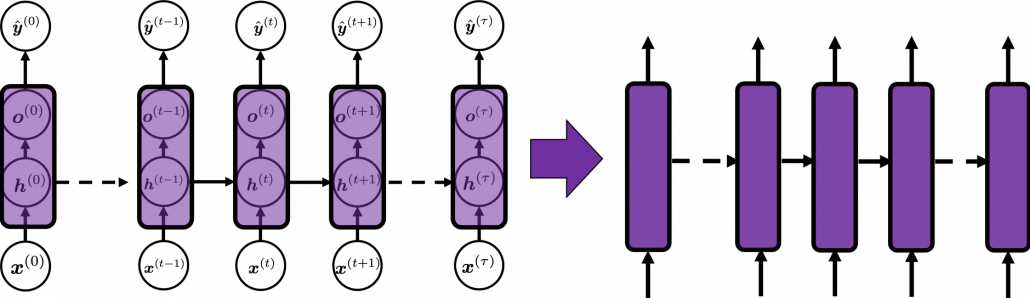
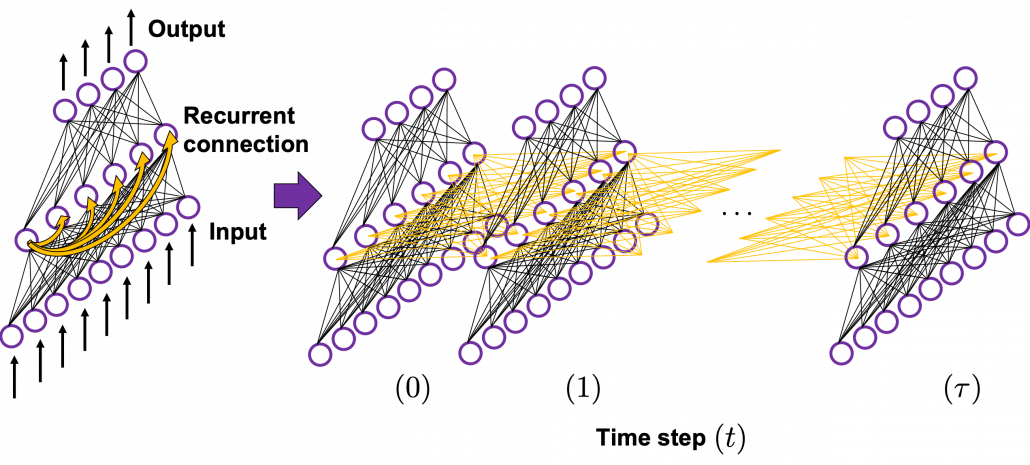 In many situations, RNNs are simplified as below. If you have read through this article until this point, I bet you gained some better understanding of RNNs, so you should little by little get used to this more abstract, blackboxed way of showing RNN.
In many situations, RNNs are simplified as below. If you have read through this article until this point, I bet you gained some better understanding of RNNs, so you should little by little get used to this more abstract, blackboxed way of showing RNN.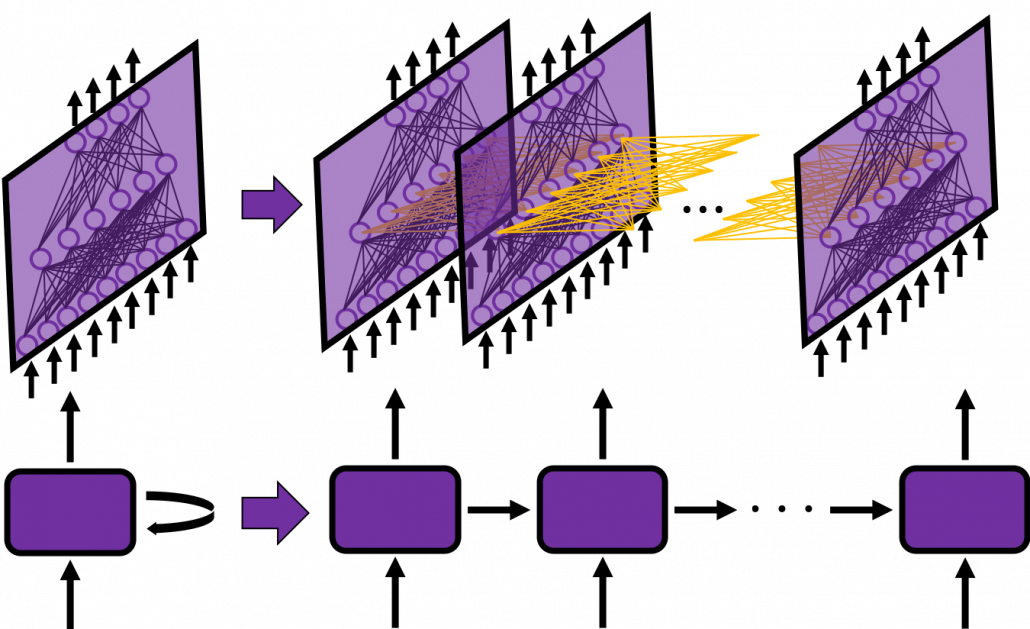
 .
.
 at time step
at time step propagate forward as a normal DCL, and gives out the output
propagate forward as a normal DCL, and gives out the output  (The notation on the
(The notation on the  is called “hat,” and it means that the value is an estimated value. Whatever machine learning tasks you work on, the outputs of the functions are just estimations of ideal outcomes. You need to adjust parameters for better estimations. You should always be careful whether it is an actual value or an estimated value in the context of machine learning or statistics). But the most important parts are the middle layers.
is called “hat,” and it means that the value is an estimated value. Whatever machine learning tasks you work on, the outputs of the functions are just estimations of ideal outcomes. You need to adjust parameters for better estimations. You should always be careful whether it is an actual value or an estimated value in the context of machine learning or statistics). But the most important parts are the middle layers.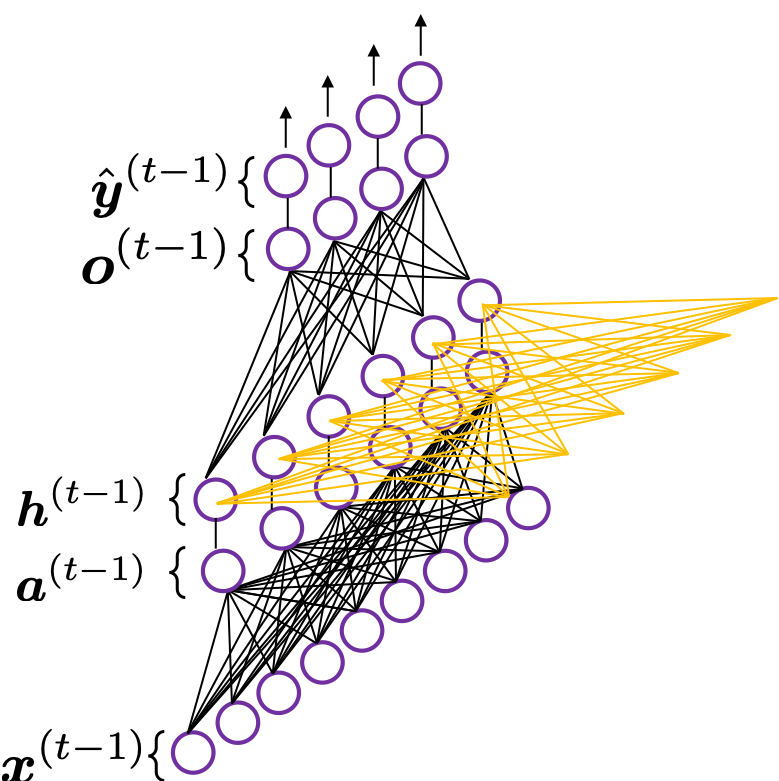
 is just linear summations of
is just linear summations of  is a combination of activated values of
is a combination of activated values of  from the last time step, with recurrent connections. The values of
from the last time step, with recurrent connections. The values of  , and the other is recurrent connections to
, and the other is recurrent connections to  .
.



 , and weights
, and weights  , then
, then  is a linear summation of
is a linear summation of  .
. and
and  is a linear summations all the elements of
is a linear summations all the elements of  , and
, and 
 , at every time step.
, at every time step. 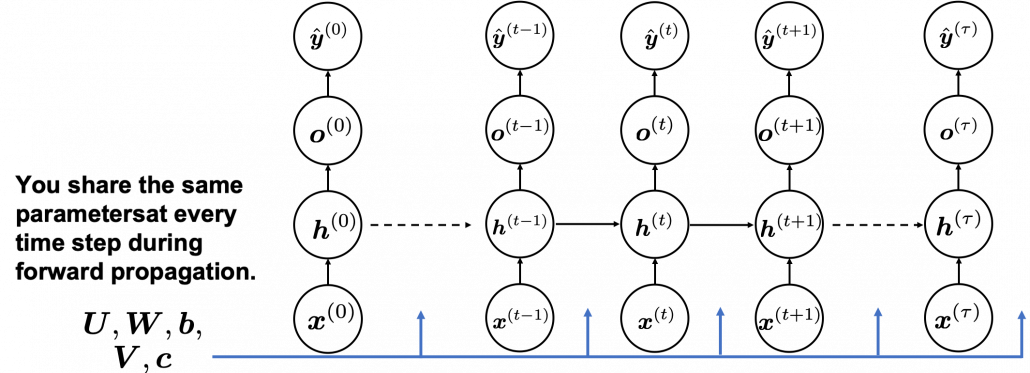
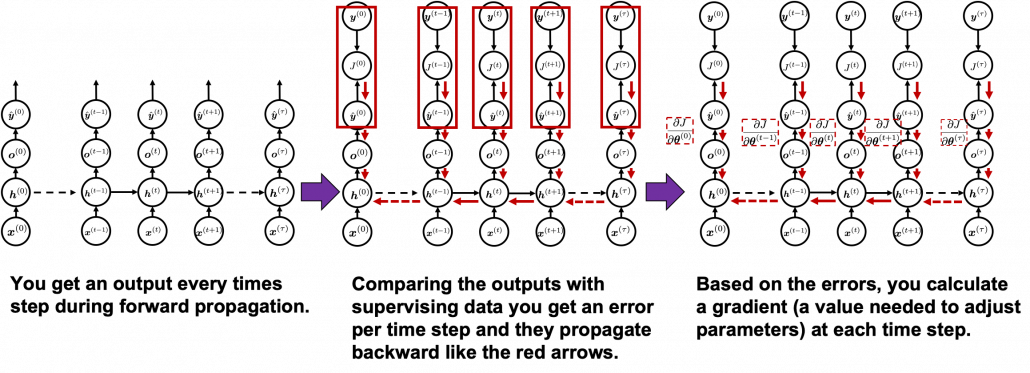 You need all the gradients to adjust parameters, but you do not necessarily need all the errors to calculate those gradients. Gradients in the context of machine learning mean partial derivatives of error functions (in this case
You need all the gradients to adjust parameters, but you do not necessarily need all the errors to calculate those gradients. Gradients in the context of machine learning mean partial derivatives of error functions (in this case  ) with respect to certain parameters, and mathematically a gradient of
) with respect to certain parameters, and mathematically a gradient of  is denoted as
is denoted as  . And another confusing point in many textbooks, including the MIT one, is that they give an impression that parameters depend on time steps. For example some study materials use notations like
. And another confusing point in many textbooks, including the MIT one, is that they give an impression that parameters depend on time steps. For example some study materials use notations like  , and I think this gives an impression that this is a gradient with respect to the parameters at time step
, and I think this gives an impression that this is a gradient with respect to the parameters at time step  . But many study materials denote gradients of those errors in the former way, so from now on let me use the notations which you can see in the figures in this article.
. But many study materials denote gradients of those errors in the former way, so from now on let me use the notations which you can see in the figures in this article. you need errors from time steps
you need errors from time steps  (as you can see in the figure, in order to calculate a gradient in a colored frame, you need all the errors in the same color).
(as you can see in the figure, in order to calculate a gradient in a colored frame, you need all the errors in the same color).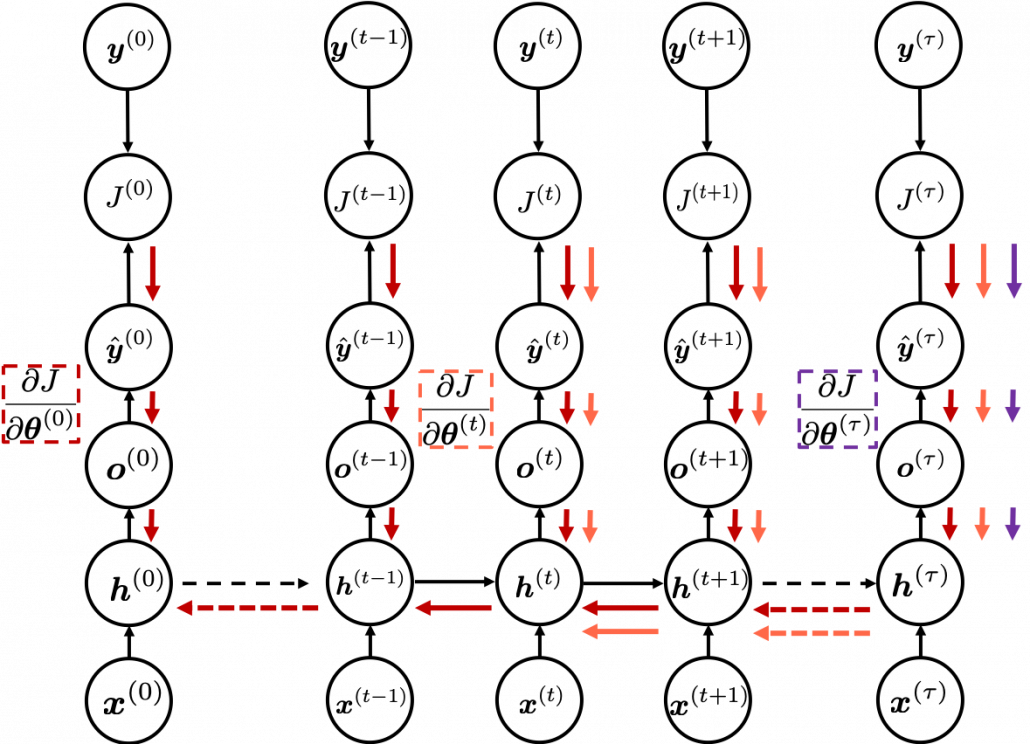
 different colors to show the whole process of RNN backprop, but that is not realistic. In the figure I displayed only the flows of errors necessary for calculating each gradient at time step
different colors to show the whole process of RNN backprop, but that is not realistic. In the figure I displayed only the flows of errors necessary for calculating each gradient at time step  .
. are correct notations, because
are correct notations, because  are values of neurons after forward propagation. They depend on time steps, and these are very values which I have been calling “errors.” That is why parameters do not depend on time steps, whereas errors depend on time steps.
are values of neurons after forward propagation. They depend on time steps, and these are very values which I have been calling “errors.” That is why parameters do not depend on time steps, whereas errors depend on time steps. . With this gradient
. With this gradient  , you can finally renew the value of
, you can finally renew the value of  one time.
one time.
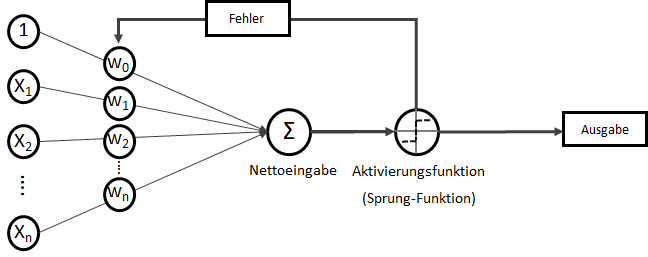
 . Wobei für
. Wobei für  als Bias-Input stets gilt:
als Bias-Input stets gilt:  . Der Bias-Input ist nur ein Platzhalter für das wichtige Bias-Gewicht.
. Der Bias-Input ist nur ein Platzhalter für das wichtige Bias-Gewicht.![\[ x = \begin{bmatrix} x_0\\ x_1\\ x_2\\ x_3\\ \vdots\\ x_n \end{bmatrix} \]](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-3a7aa03dea498a7231e3e497e3e5673d_l3.png "Rendered by QuickLaTeX.com")

![\[ w = \begin{bmatrix} w_0\\ w_1\\ w_2\\ w_3\\ \vdots\\ w_n \end{bmatrix} \]](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-c70ad1733451ddc4512b23f2c739f80e_l3.png "Rendered by QuickLaTeX.com")
 bilden. Hier zeigt sich
bilden. Hier zeigt sich  mit
mit  als Y-Achsenschnitt wenn
als Y-Achsenschnitt wenn  .
.![\[ z = w_0 \cdot x_0 + w_1 \cdot x_1 + \dots + w_n \cdot x_n \]](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-3638f2ae3b558db6c95e18057b1b9898_l3.png "Rendered by QuickLaTeX.com")
 überschreitet, liefert die Sprungfunktion
überschreitet, liefert die Sprungfunktion  mit der Eingabe
mit der Eingabe 
 .
.![\[ z = w^T \cdot x \]](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-fc9f71e279d7fd0095c17065743df909_l3.png "Rendered by QuickLaTeX.com")
 steht dabei für transponieren. Transponieren bedeutet, dass Spalten zu Zeilen werden – oder umgekehrt.
steht dabei für transponieren. Transponieren bedeutet, dass Spalten zu Zeilen werden – oder umgekehrt. mit beispielhaften Inhalten:
mit beispielhaften Inhalten:![\[ x = \begin{bmatrix} 5\\ 12\\ 30\\ 2 \end{bmatrix} \]](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-97145f06e658d2f10086bd8c80293749_l3.png "Rendered by QuickLaTeX.com")
![\[ w = \begin{bmatrix} 1\\ 2\\ 5\\ 12 \end{bmatrix} \]](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-6cd08615346cc16d7e8c23bac32c19b9_l3.png "Rendered by QuickLaTeX.com")
![\[ z = w^T \cdot x = \big[1\text{ }2\text{ }5\text{ }12\big] \cdot \begin{bmatrix} 5\\ 12\\ 30\\ 2 \end{bmatrix} = 1 \cdot 5 + 2 \cdot 12 + 5 \cdot 30 + 12 \cdot 2 = 203 \]](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-70a3e9e9243199e97c549d1d9b0f44c0_l3.png "Rendered by QuickLaTeX.com")
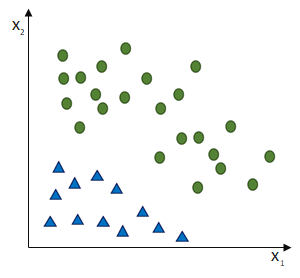
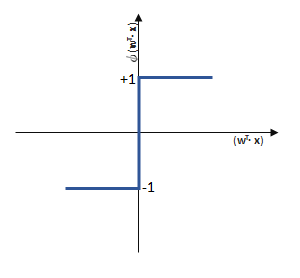
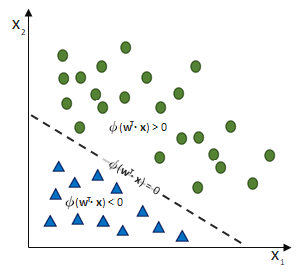



 entgegen des Fehlers (bzw. hin zur jeweils anderen möglichen Antwort) geschieht:
entgegen des Fehlers (bzw. hin zur jeweils anderen möglichen Antwort) geschieht:
 ausgehen.
ausgehen.







 ist und das SLP irrtümlicherweise die Klasse
ist und das SLP irrtümlicherweise die Klasse  ausgewiesen hat, obwohl die korrekte Klasse
ausgewiesen hat, obwohl die korrekte Klasse  wäre. (Und die Schrittweite lassen wir bei
wäre. (Und die Schrittweite lassen wir bei  )
)
 verringert sich entsprechend
verringert sich entsprechend  und somit wird die Wahrscheinlichkeit größer, dass wenn bei der nächsten Iteration (
und somit wird die Wahrscheinlichkeit größer, dass wenn bei der nächsten Iteration ( ) wieder die Klasse +1 korrekt sei, den Schwellwert
) wieder die Klasse +1 korrekt sei, den Schwellwert  zu unterschreiten und auf eben diese korrekte Klasse zu stoßen.
zu unterschreiten und auf eben diese korrekte Klasse zu stoßen. . So würde beispielsweise ein neues
. So würde beispielsweise ein neues  (bei Iteration
(bei Iteration  ) zu einer irrtümlichen Klassifikation
) zu einer irrtümlichen Klassifikation  (
( ) führen, würde die Entscheidungsgrenze zur korrekten Prädiktion der Klasse beim nächsten Durchlauf (
) führen, würde die Entscheidungsgrenze zur korrekten Prädiktion der Klasse beim nächsten Durchlauf ( ) an
) an 
 und
und 
 funktioniert.
funktioniert. springt, wenn z > 0 ist, ansonsten aber
springt, wenn z > 0 ist, ansonsten aber  bleibt.
bleibt.
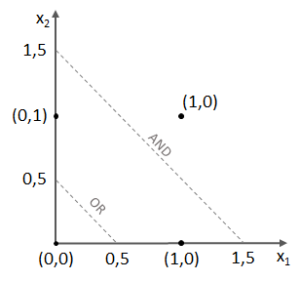
 ,
,
 ,
,
 ,
,
 ,
, ,
, ,
,

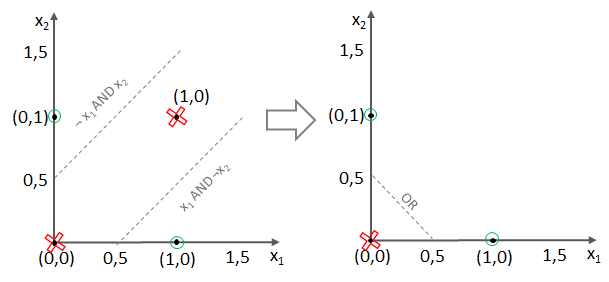
 und somit
und somit 
 und somit
und somit 
 und somit
und somit 
 und somit
und somit 
 und somit
und somit 
 und somit
und somit 
 und somit
und somit 
 und somit
und somit 
 und somit
und somit  und somit
und somit  und somit
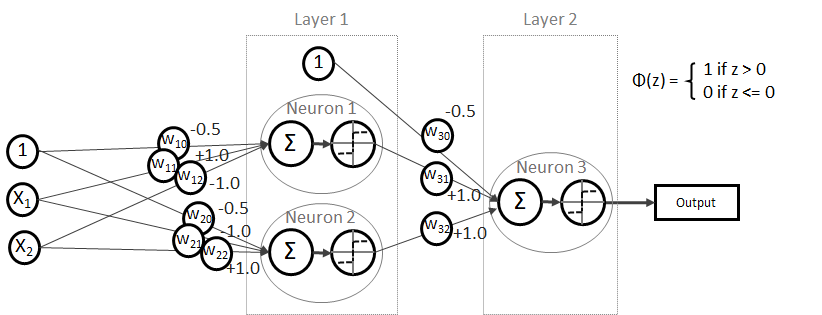
und somit 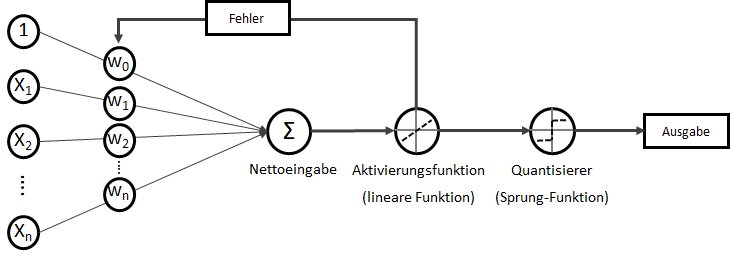



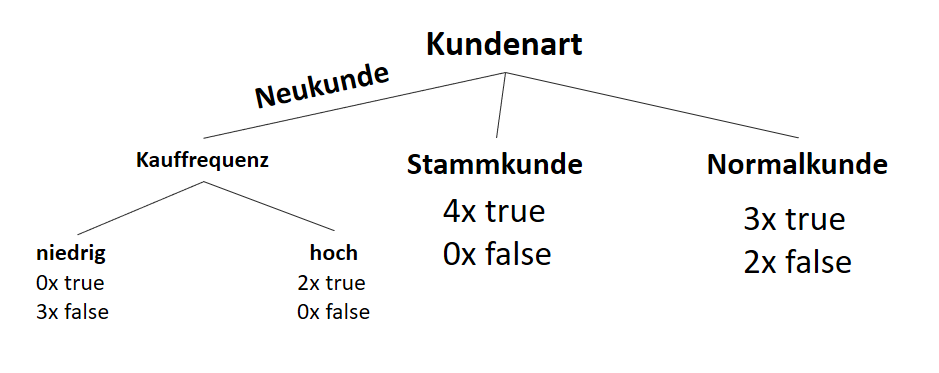
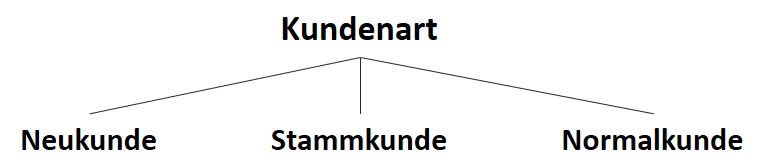
 ) (siehe Teil 1 der Artikelserie
) (siehe Teil 1 der Artikelserie  ), der im Attribut vorkommt:
), der im Attribut vorkommt:

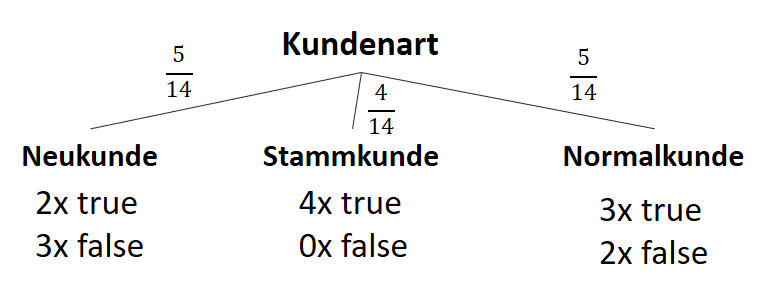



![\[ IG(S, A_{Kundenart}) = - \sum_{i=1}^n \frac{\bigl|S_i\bigl|}{\bigl|S\bigl|} \cdot H(S_i) \]](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-6380891cc61bb855d4208480091fdef0_l3.png "Rendered by QuickLaTeX.com")
![\[ IG(S, A_{Kundenart}) = H(S) - \frac{\bigl|S_{Neukunde}\bigl|}{\bigl|S\bigl|} \cdot H(S_{Neukunde}) - \frac{\bigl|S_{Stammkunde}\bigl|}{\bigl|S\bigl|} \cdot H(S_{Stammkunde}) - \frac{\bigl|S_{Normalkunde}\bigl|}{\bigl|S\bigl|} \cdot H(S_{Normalkunde}) \]](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-b3c9d40c7a171fd7b9e5fbed0aed041a_l3.png "Rendered by QuickLaTeX.com")
![\[ IG(S, A_{Kundenart}) = 0.94 - \frac{5}{14} \cdot 0.97 - \frac{4}{14} \cdot 0.00 - \frac{5}{14} \cdot 0.97 = 0.247 \]](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-33144ba5df6858348666daef5a5cf5d3_l3.png "Rendered by QuickLaTeX.com")
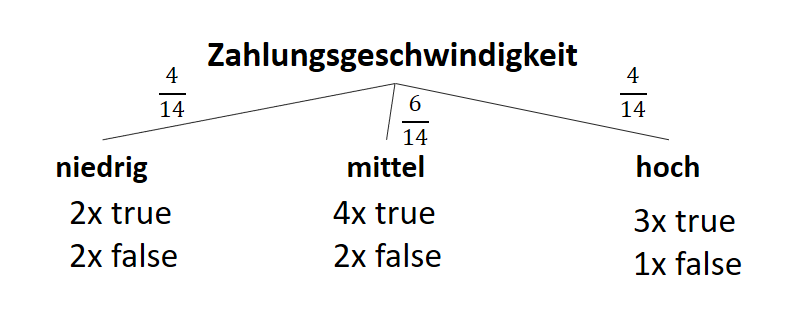



![\[ IG(S, A_{Zahlungsgeschwindigkeit}) = H(S) - \frac{\bigl|S_{niedrig}\bigl|}{\bigl|S\bigl|} \cdot H(S_{niedrig}) - \frac{\bigl|S_{mittel}\bigl|}{\bigl|S\bigl|} \cdot H(S_{mittel}) - \frac{\bigl|S_{schnell}\bigl|}{\bigl|S\bigl|} \cdot H(S_{schnell}) \]](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-a80e61c0adf9dff8ca219a28bce359cd_l3.png "Rendered by QuickLaTeX.com")
![\[ IG(S, A_{Zahlungsgeschwindigkeit}) = 0.94 - \frac{4}{14} \cdot 1.00 - \frac{6}{14} \cdot 0.92 - \frac{4}{14} \cdot 0.81 = 0.029 \]](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-ed4f1d54de66a9956bc2c1e53a0de2e8_l3.png "Rendered by QuickLaTeX.com")



![\[ IG(S, A_{Kauffrequenz}) = H(S) - \frac{\bigl|S_{niedrig}\bigl|}{\bigl|S\bigl|} \cdot H(S_{niedrig}) - \frac{\bigl|S_{hoch}\bigl|}{\bigl|S\bigl|} \cdot H(S_{hoch}) \]](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-cbcfb6a5b118cfc2df4185ef03e4e1dd_l3.png "Rendered by QuickLaTeX.com")
![\[ IG(S, A_{Kauffrequenz}) = 0.94 - \frac{7}{14} \cdot 1.00 - \frac{7}{14} \cdot 0.59 = 0.150 \]](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-dc9f358f2d2cd071b815b3f6c571f813_l3.png "Rendered by QuickLaTeX.com")
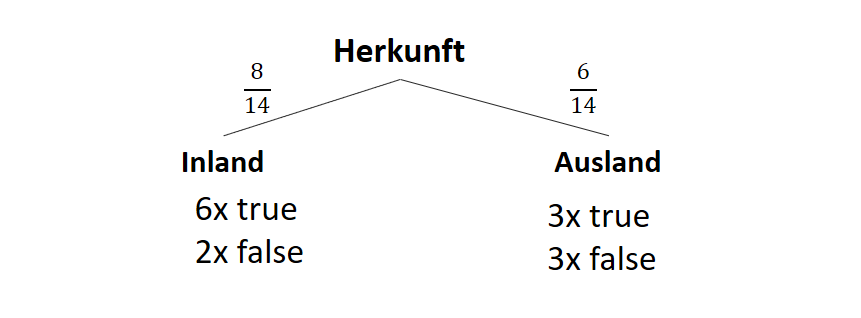


![\[ IG(S, A_{Herkunft}) = H(S) - \frac{\bigl|S_{Inland}\bigl|}{\bigl|S\bigl|} \cdot H(S_{Inland}) - \frac{\bigl|S_{Ausland}\bigl|}{\bigl|S\bigl|} \cdot H(S_{Ausland}) \]](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-3a0ecd4412fa44ca26c64ea16aa536d1_l3.png "Rendered by QuickLaTeX.com")
![\[ IG(S, A_{Herkunft}) = 0.94 - \frac{8}{14} \cdot 0.81 - \frac{6}{14} \cdot 1.00 = 0.05 \]](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-ab4db275a73c092813d00f26ef4c1183_l3.png "Rendered by QuickLaTeX.com")
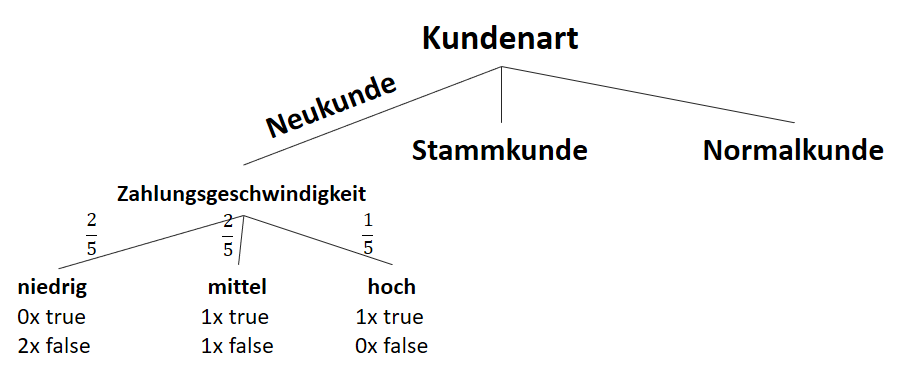



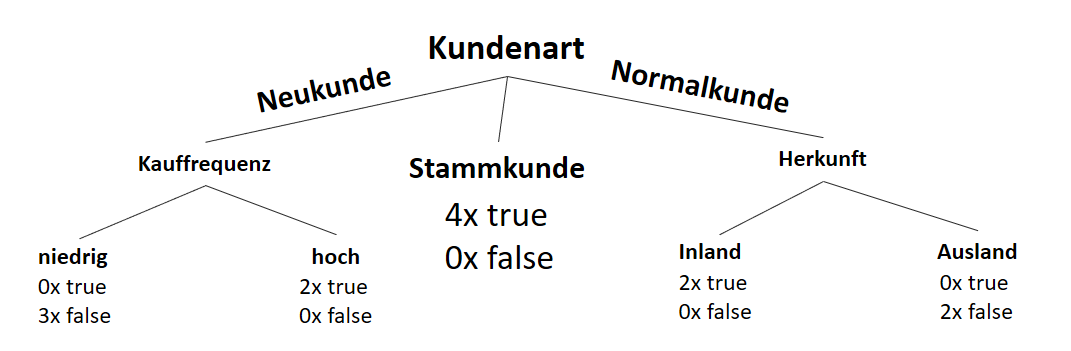
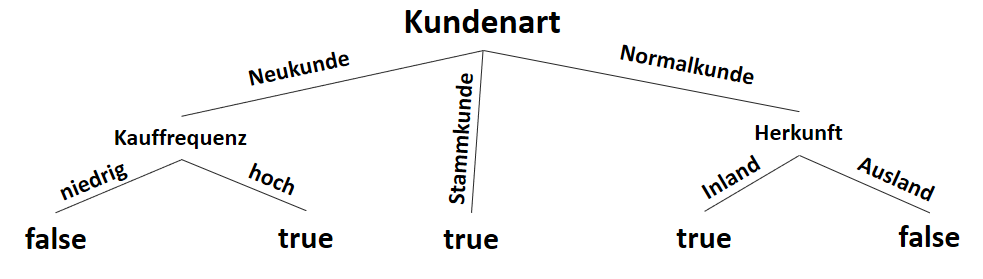
![\[ IG(S_{Neukunde},A_{Zahlungsgeschwindigkeit}) = 0.97 - \frac{3}{5} \cdot 0.00 - \frac{2}{5} \cdot 1.00 - \frac{1}{5} \cdot 0.00 = 0.57 \]](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-35c0216b5e69ee73831980225531ecc7_l3.png "Rendered by QuickLaTeX.com")
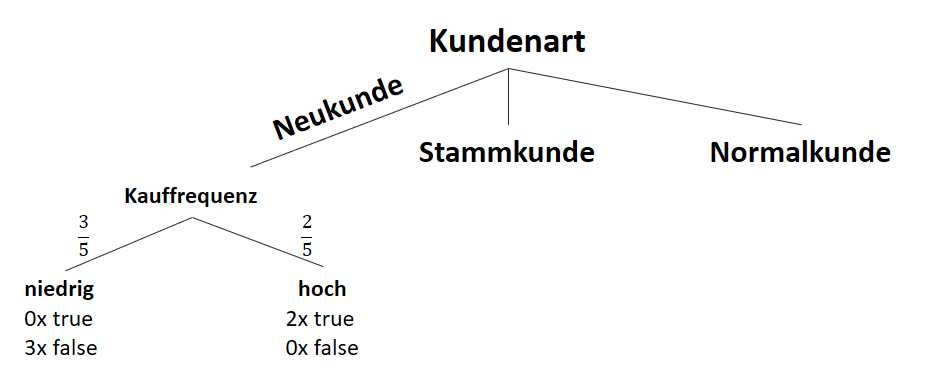
![\[ IG(S_{Neukunde},A_{Kauffrequenz}) = 0.97 - \frac{3}{5} \cdot 0.00 - \frac{2}{5} \cdot 0.00 = 0.97 \]](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-5f6849e7156c9505f53b484a8e7f505a_l3.png "Rendered by QuickLaTeX.com")



![\[ IG(S_{Neukunde},A_{Herkunft}) = 0.97 - \frac{3}{5} \cdot 0.92 - \frac{2}{5} \cdot 1.00 = 0.018 \]](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-890f306c397d0ac28cbbd9a316eb049b_l3.png "Rendered by QuickLaTeX.com")