Python gilt unter Data Scientists als Alternative zu R Statistics. Ich bevorzuge Python auf Grund seiner Syntax und Einfachheit gegenüber R, komme hinsichtlich der vielen Module jedoch häufig etwas durcheinander. Aus diesem Grund liste ich hier die – meiner Einschätzung nach – zehn nützlichsten Bibliotheken für Python, um einfache Datenanalysen, aber auch semantische Textanalysen, Predictive Analytics und Machine Learning in die Tat umzusetzen.
NumPy – Numerische Analyse
NumPy ist eine Open Source Erweiterung für Python. Das Modul stellt vorkompilierte Funktionen für die numerische Analyse zur Verfügung. Insbesondere ermöglicht es den einfachen Umgang mit sehr großen, multidimensionalen Arrays (Listen) und Matrizen, bietet jedoch auch viele weitere grundlegende Features (z. B. Funktionen der Zufallszahlenbildung, Fourier Transformation, linearen Algebra). Ferner stellt das NumPy sehr viele Funktionen mathematische Funktionen für das Arbeiten mit den Arrays und Matrizen bereit.
matplotlib – 2D/3D Datenvisualisierung
Die matplotlib erweitert NumPy um grafische Darstellungsmöglichkeiten in 2D und 3D. Das Modul ist in Kombination mit NumPy wohl die am häufigsten eingesetzte Visualisierungsbibliothek für Python.
Die matplotlib bietet eine objektorientierte API, um die dynamischen Grafiken in Pyhton GUI-Toolkits einbinden zu können (z. B. GTL+ oder wxPython).
NumPy und matplotlib werden auch mit den nachfolgenden Bibliotheken kombiniert.
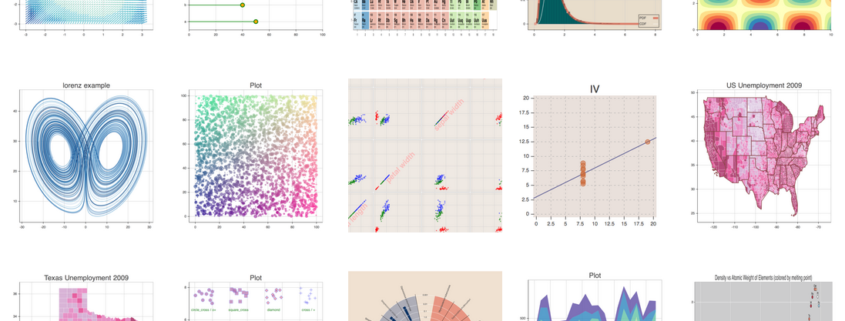
Bokeh – Interaktive Datenvisualisierung
Während die Plot-Funktionen von matplotlib statisch angezeigt werden, kann in den Visualsierungsplots von Bokeh der Anwender interaktiv im Chart klicken und es verändern. Bokeh ist besonders dann geeignet, wenn die Datenvisualisierung als Dashboard im Webbrowser erfolgen soll.
Das Bild über diesen Artikel zeigt Visualiserungen mit dem Python Package Bokeh.
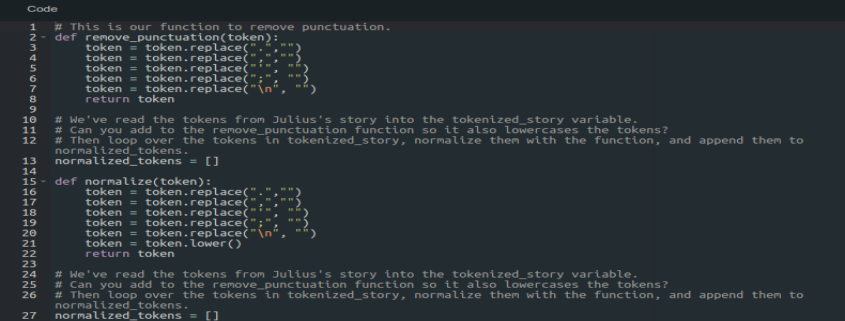
Pandas – Komplexe Datenanalyse
Pandas ist eine Bibliothek für die Datenverarbeitung und Datenanalyse mit Python. Es erweitert Python um Datenstrukturen und Funktionen zur Verarbeitung von Datentabellen. Eine besondere Stärke von Pandas ist die Zeitreihenanalyse. Pandas ist freie Software (BSD License).
Statsmodels – Statistische Datenanalyse
Statsmodels is a Python module that allows users to explore data, estimate statistical models, and perform statistical tests. An extensive list of descriptive statistics, statistical tests, plotting functions, and result statistics are available for different types of data and each estimator.
Die explorative Datenanalyse, statistische Modellierung und statistische Tests ermöglicht das Modul Statsmodels. Das Modul bringt neben vielen statistischen Funktionen auch eigene Plots (Visualisierungen) mit. Mit dem Modul wird Predictive Analytics möglich. Statsmodels wird häufig mit NumPy, matplotlib und Pandas kombiniert.
SciPy – Lineare Optimierung
SciPy ist ein sehr verbreitetes Mathematik-Modul für Python, welches den Schwerpunkt auf die mathematische Optimierung legt. Funktionen der linearen Algebra, Differenzialrechnung, Interpolation, Signal- und Bildverarbeitung sind in SciPy enthalten.
scikit-learn – Machine Learning
scikit-learn ist eine Framework für Python, das auf NumPy, matplotlob und SciPy aufsetzt, dieses jedoch um Funktionen für das maschinelle Lernen (Machine Learning) erweitert. Das Modul umfasst für das maschinelle Lernen notwendige Algorithmen für Klassifikationen, Regressionen, Clustering und Dimensionsreduktion.
Mlpy – Machine Learning
Alternativ zu scikit-learn, bietet auch Mlpy eine mächtige Bibliothek an Funktionen für Machine Learning. Mlpy setzt ebenfalls auf NumPy und SciPy, auf, erweitert den Funktionsumfang jedoch um Methoden des überwachten und unüberwachten maschinellen Lernens.
NLTK – Text Mining
NLTK steht für Natural Language Toolkit und ermöglicht den effektiven Einstieg ins Text Mining mit Python. Das Modul beinhaltet eigene (eher einfache) Visualisierungsmöglichkeiten zur Darstellung von Textmuster-Zusammenhängen, z. B. in Baumstrukturen. Für Text Mining und semantische Textanalysen mit Python gibt es wohl nichts besseres als NLTK.
Theano – Multidimensionale Berechnungen & GPU-Processing
Theano is a Python library that allows you to define, optimize, and evaluate mathematical expressions involving multi-dimensional arrays efficiently
Für multidimensionale Datenanalysen bzw. die Verarbeitung und Auswertung von multidimensionalen Arrays gibt es wohl nichts schnelleres als die Bibliothek Theano. Theano ist dabei eng mit NumPy verbunden.
Theano ermöglicht die Auslagerung der Berechnung auf die GPU (Grafikprozessor), was bis zu 140 mal schneller als auf der CPU sein soll. Getestet habe ich es zwar nicht, aber grundsätzlich ist es wahr, dass die GPU multidimensionale Arrays schneller verarbeiten kann, als die CPU. Zwar ist die CPU universeller (kann quasi alles berechnen), die GPU ist aber auf die Berechnung von 3D-Grafiken optimiert, die ebenfalls über multidimensionalen Vektoren verarbeitet werden.