Datenvisualisierung – Eine Wissenschaft für sich… oder auch zwei
Techniken für die Visualisierung und visuelle Analyse von Datenmengen gehören heute in vielen Unternehmen zu den essentiellen Werkzeugen, um große Datensätze zu untersuchen und sie greifbarer zu gestalten. Während die Anwendungssoftware dazu ständig weiterentwickelt wird, sind die dahinterliegenden Methoden ein beliebtes Forschungsthema in der Wissenschaft. Es gibt zahlreiche Tagungen, Workshops und Fachjournale, in denen neue Erkenntnisse, Verfahren und technische Innovationen ausgetauscht werden.
Interessant ist aber, dass sich in den vergangenen Jahrzehnten zwei große unabhängige Strömungen in der Forschung zum Thema Datenvisualisierung ausgeprägt haben. – Beide hängen mit dem übergeordneten Thema zusammen, begreifen sich jedoch sehr unterschiedlich.
Auf der einen Seite gibt es ein großes Forschungsfeld, das sich unter dem Namen Informationsvisualisierung oder “Information Visualization”, kurz “InfoVis”, zusammenfassen lässt. Diese weitreichende Disziplin befasst sich im Wesentlichen mit der Frage, wie größere Mengen von abstrakten Informationen (z.B. statistische Daten) für einen menschlichen Betrachter dargestellt werden können, so dass ein Erkenntnisgewinn ermöglicht bzw. erleichtert wird. Dabei konzentriert sich die Forschung auf visuelle Aspekte der Darstellungstechniken und deren effektiven Wert für den Betrachter sowie auf interaktive Anzeigemethoden. Beispielsweise wird für verschiedene Visualisierungstechniken, wie Punktwolken, Balken- oder Kurvendiagramme, die Wirkung von einzelnen Repräsentationselementen, also Formen, Farben und Animationen untersucht. Deren Effektivität wird in Benutzerstudien überprüft, wobei die Grenzen der kognitiven Verarbeitung verschiedener bildlicher Informationsquellen ausgelotet werden. Unter anderem wurden aufgrund dieser Erkenntnisse Taxonomien und Richtlinien vorgeschlagen, um möglichst effektive visuelle Darstellungen für bestimmte Problematiken zu schaffen. Dementsprechend gibt es starke Verbindungen zum Forschungsgebiet der Mensch-Maschine-Interaktion (“Human-Computer-Interaction” – HCI), zur Computergrafik und zur kognitiven Psychologie.
Erfolgreiche Softwareprodukte wie “Tableau” oder “Gephi” nutzen die Erkenntnisse der InfoVis-Forschung; und beliebte Blogs, z.B. “Infosthetics” oder “Information is beautiful“, widmen sich besonders innovativen und ästhetischen Repräsentationen von abstrakten Daten. Um interaktive Darstellungen zu gestalten ist z.B. “Processing” eine beliebte Programmiersprache, welche Prinzipien der visuellen Informationsdarstellung aufgreift und mit einfachen Mitteln das Erstellen einer angepassten Softwarelösung für die gegebene Problemstellung ermöglicht.
Auf der anderen Seite hat sich das Forschungsfeld der Dimensionsreduktion oder “Dimensionality Reduction” etabliert. Während die InfoVis-Gemeinde visuelle Repräsentationsformen und deren Zugänglichkeit für den Benutzer in den Vordergrund stellt, geht es bei der Dimensionsreduktion um mathematische Verfahren, welche Informationen automatisch verdichten. Die Eingabedaten können dabei in Form von klassischen Tabellen vorliegen, bei denen in jeder Zeile eine Instanz der Daten durch eine feste Menge von Attributen beschrieben wird, also Eigenschaften, die sich numerisch erfassen lassen. Beispielsweise ließe sich in einem bestehenden Produktsortiment jedes Produkt durch seinen Preis, seine Farbe als RGB-Wert, sein Gewicht etc. beschreiben. Dadurch ist jede Instanz als ein Punkt in einem mehrdimensionalen Koordinatensystem definiert. Falls eine Erfassung von numerischen Attributen schwierig ist, können die Daten auch durch paarweise Entfernungen oder Ähnlichkeiten zueinander beschrieben werden, wobei viele verschiedene Ähnlichkeitsmaße für spezifische Anwendungsfälle existieren, z.B. für Textdaten. Auch dadurch ist eine mehrdimensionale Darstellung definiert.
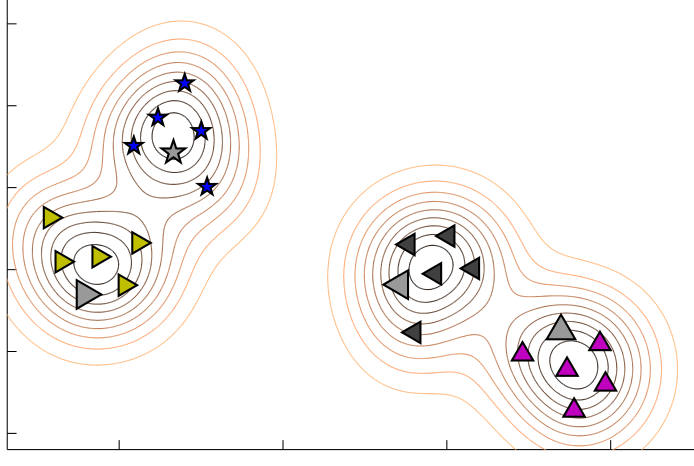
Die zentrale Fragestellung ist: Wie können mehrdimensionale Punkte in wenigen Dimensionen (z.B. auf einer zweidimensionalen Karte) so repräsentiert werden, dass wichtige Aspekte der räumlichen Anordnung weitgehend erhalten bleiben? Sobald eine gute zweidimensionale Repräsentation gefunden ist, wäre es z.B. möglich, das gesamte Produktsortiment als Punktwolke (Scatter Plot) auf einer Karte zu visualisieren, wobei Gruppen von ähnlichen Produkten dann direkt als Cluster erkennbar wären oder ungewöhnliche Spezialprodukte als Ausreißer sichtbar sind. Die entstehende Repräsentation soll also eine möglichst inhaltlich sinnvolle Nachahmung der originalen Lage der Datenpunkte sein, wobei sich hochdimensionale Daten nicht völlig wahrheitsgetreu niedrigdimensional abbilden lassen. Welche Fehler dabei in Kauf genommen werden dürfen, hängt stark von den gegebenen Daten und dem jeweiligen Anwendungsfall ab.
Dieser Herausforderung wird mit algorithmischen Verfahren begegnet. In den letzten fünfzehn Jahren wurde eine Vielzahl verschiedener Algorithmen zur Dimensionsreduktion vorgeschlagen, die auf verschiedene Weisen intelligente Kompromisse bei der Einbettung machen. Dabei erhält der Spezialfall der zweidimensionalen Reduktion eine besondere Aufmerksamkeit in der Forschung, weil damit die Visualisierung direkt ermöglicht wird. Die Algorithmen bedienen sich häufig bei existierenden Techniken der mathematischen Optimierung und weisen eine gewisse Verwandtschaft zu Ansätzen des Machine Learning auf. Das Verfahren wird also zuweilen als eine Art Lernproblem formuliert, wobei die Struktur der Originaldaten “trainiert” und daraufhin nachgebildet wird.
Während die ältesten mathematischen Methoden in diesem Bereich bereits Mitte des letzten Jahrhunderts vorgeschlagen wurden und bis heute vielfach Verwendung finden, gab es in den letzten Jahren signifikante Innovationen, welche fächerübergreifende Aufmerksamkeit erregt haben. Zwei Beispiele sind die Dimensionsreduktions-Methoden t-SNE (für “t-distributed Stochastic Neighbor Embedding”) und NeRV (“Neighbor Retrieval Visualizer”). Hiermit lassen sich auch für komplexe Daten wie digitale Bilder beeindruckende Ergebnisse erzielen. Allerdings wurden bisher Aspekte einer wirkungsvollen Darstellung sowie eine sinnvolle Gestaltung von Benutzerinteraktion in der Forschung weitgehend außen vor gelassen.
Eine engere Verknüpfung dieser beiden wissenschaftlichen Strömungen birgt daher erhebliches Potenzial für den Fortschritt im Bereich Visual Analytics, was seit einigen Jahren auch in den jeweiligen Forscher-Gemeinden mehr und mehr erkannt wird. Die Kommunikation zwischen beiden Disziplinen wird nun verstärkt, ein Trend der sich unter anderem an einer gestiegenen Anzahl von Schwerpunkt-Seminaren und spezifischen Workshops zur Verbindung dieser Forschungsfelder ablesen lässt. Beispielsweise fand im Frühjahr 2015 zum zweiten Mal ein Seminar zu dem Thema im Leibniz-Zentrum für Informatik auf dem Schloss Dagstuhl statt: Unter dem Titel “Bridging Information Visualization with Machine Learning” trafen sich eine Woche lang führende Forscher aus beiden Gebieten, um die Zusammenarbeit in gemeinsamen Projekten anzuregen. Wer wichtige Innovationen im Bereich Visual Analytics also nicht verpassen will, sollte die Entwicklung der Forschung weiter im Auge behalten. Wir dürfen gespannt sein, was die Zukunft der Datenvisualisierung bringt.







{kind=link}
My partner and I stumbled over here by a different website and
thought I might as well check things out. I like what I see
so now i’m following you. Look forward to exploring your web
page again.
I will really appreciate the writer’s choice for choosing this excellent article appropriate to my matter. Here is deep description about the article matter which helped me more.
data science course in guntur