Überwachtes vs unüberwachtes maschinelles Lernen
Dies ist Artikel 1 von 4 aus der Artikelserie – Was ist eigentlich Machine Learning?
Der Unterschied zwischen überwachten und unüberwachtem Lernen ist für Einsteiger in das Gebiet des maschinellen Lernens recht verwirrend. Ich halte die Bezeichnung “überwacht” und “unüberwacht” auch gar nicht für besonders gut, denn eigentlich wird jeder Algorithmus (zumindest anfangs) vom Menschen überwacht. Es sollte besser in trainierte und untrainierte Verfahren unterschieden werden, die nämlich völlig unterschiedliche Zwecke bedienen sollen:
Während nämlich überwachte maschinelle Lernverfahren über eine Trainingsphase regelrecht auf ein (!) Problem abgerichtet werden und dann produktiv als Assistenzsystem (bis hin zum Automated Decision Making) funktionieren sollen, sind demgegenüber unüberwachte maschinelle Lernverfahren eine Methodik, um unübersichtlich viele Zeilen und Spalten von folglich sehr großen Datenbeständen für den Menschen leichter interpretierbar machen zu können (was nicht immer funktioniert).
Trainiere dir deinen Algorithmus mit überwachtem maschinellen Lernen
Wenn ein Modell anhand von mit dem Ergebnis (z. B. Klassifikationsgruppe) gekennzeichneter Trainingsdaten erlernt werden soll, handelt es sich um überwachtes Lernen. Die richtige Antwort muss während der Trainingsphase also vorliegen und der Algorithmus muss die Lücke zwischen dem Input (Eingabewerte) und dem Output (das vorgeschriebene Ergebnis) füllen.
Die Überwachung bezieht sich dabei nur auf die Trainingsdaten! Im produktiven Lauf wird grundsätzlich nicht überwacht (und das Lernen könnte sich auf neue Daten in eine ganz andere Richtung entwickeln, als dies mit den Trainingsdaten der Fall war). Die Trainingsdaten
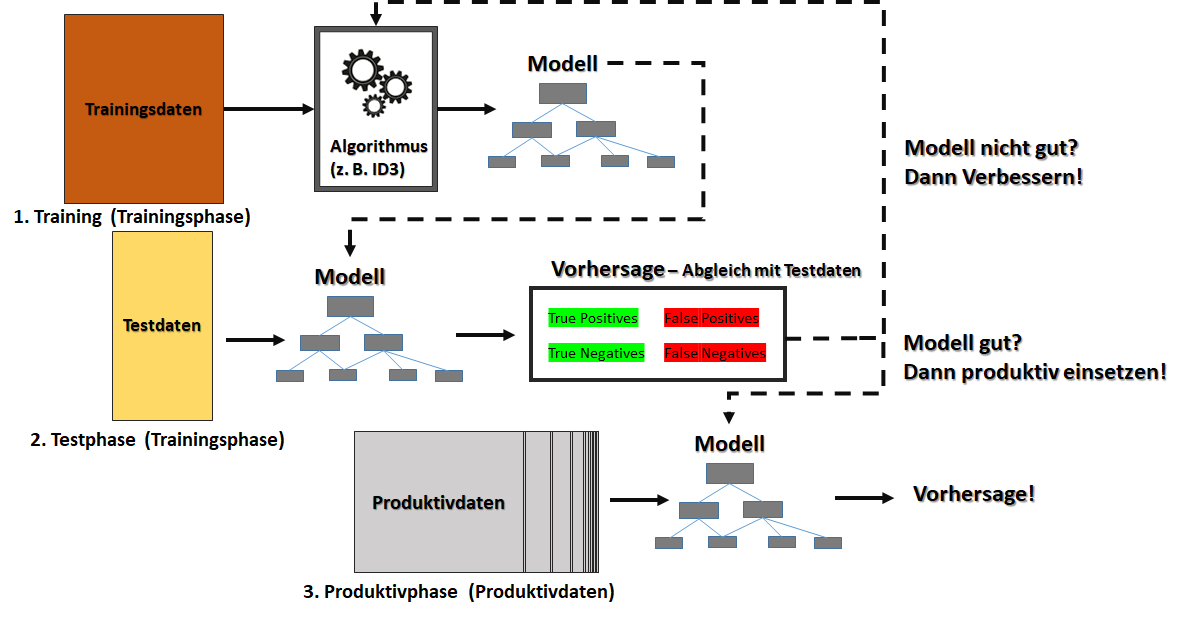
Eine besondere Form des überwachten Lernens ist die des bestärkenden Lernens. Bestärkendes Lernen kommt stets dann zum Einsatz, wenn ein Endergebnis noch gar nicht bestimmbar ist, jedoch der Trend hin zum Erfolg oder Misserfolg erkennbar wird (beispielsweise im Spielverlauf – AlphaGo von Google Deepmind soll bestärkend trainiert worden sein). In der Trainingsphase werden beim bestärkenden Lernen die korrekten Ergebnisse also nicht zur Verfügung gestellt, jedoch wird jedes Ergebnis bewertet, ob dieses (wahrscheinlich) in die richtige oder falsche Richtung geht (Annäherungslernen).
Zu den überwachten Lernverfahren zählen alle Verfahren zur Regression oder Klassifikation, beispielsweise mit Algorithmen wir k-nearest-Neighbour, Random Forest, künstliche neuronale Netze, Support Vector Machines oder auch Verfahren der Dimensionsreduktion wie die lineare Diskriminanzanalyse.
Mit unüberwachtem Lernen verborgene Strukturen identifizieren
Beim unüberwachten Lernen haben wir es mit nicht mit gekennzeichneten Daten zu tun, die möglichen Antworten/Ergebnisse sind uns gänzlich unbekannt. Folglich können wir den Algorithmus nicht trainieren, indem wir ihm die Ergebnisse, auf die er kommen soll, im Rahmen einer Trainingsphase vorgeben (überwachtes Lernen), sondern wir nutzen Algorithmen, die die Struktur der Daten erkunden und für uns Menschen sinnvolle Informationen aus Ihnen bilden (oder auch nicht – denn häufig bleibt es beim Versuch, denn der Erfolg ist nicht garantiert!).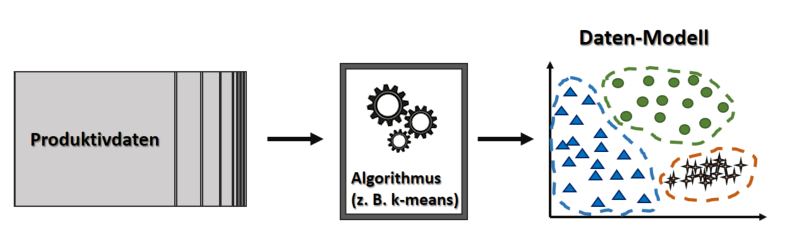 Unüberwachte Verfahren des maschinellen Lernens dienen dem Data Mining, also der Erkennung von Inhalten in Daten anhand von sichtbar werdenden Strukturen. Die Verfahren müssen nicht unbedingt mit Datenvisualisierung arbeiten, oft ist das aber der Fall, denn erst die visuellen Strukturen ermöglichen unseren menschlichen Gehirnen die Daten in einen Kontext zu bringen. Mir sind zwei Kategorien des unüberwachten Lernens bekannt, zum einem das Clustering, welches im Grunde ein unüberwachtes Klassifikationsverfahren darstellt, und zum anderen die Dimensionsreduktion PCA (Hauptkomponentenanalyse). Es gibt allerdings noch andere Verfahren, die mir weniger vertraut sind, beispielsweise unüberwacht lernende künstliche neuronale Netze, die Rauschen lernen, um Daten von eben diesem Rauschen zu befreien.
Unüberwachte Verfahren des maschinellen Lernens dienen dem Data Mining, also der Erkennung von Inhalten in Daten anhand von sichtbar werdenden Strukturen. Die Verfahren müssen nicht unbedingt mit Datenvisualisierung arbeiten, oft ist das aber der Fall, denn erst die visuellen Strukturen ermöglichen unseren menschlichen Gehirnen die Daten in einen Kontext zu bringen. Mir sind zwei Kategorien des unüberwachten Lernens bekannt, zum einem das Clustering, welches im Grunde ein unüberwachtes Klassifikationsverfahren darstellt, und zum anderen die Dimensionsreduktion PCA (Hauptkomponentenanalyse). Es gibt allerdings noch andere Verfahren, die mir weniger vertraut sind, beispielsweise unüberwacht lernende künstliche neuronale Netze, die Rauschen lernen, um Daten von eben diesem Rauschen zu befreien.


 Read this article in German:
Read this article in German: