
Python vs R: Which Language to Choose for Deep Learning?
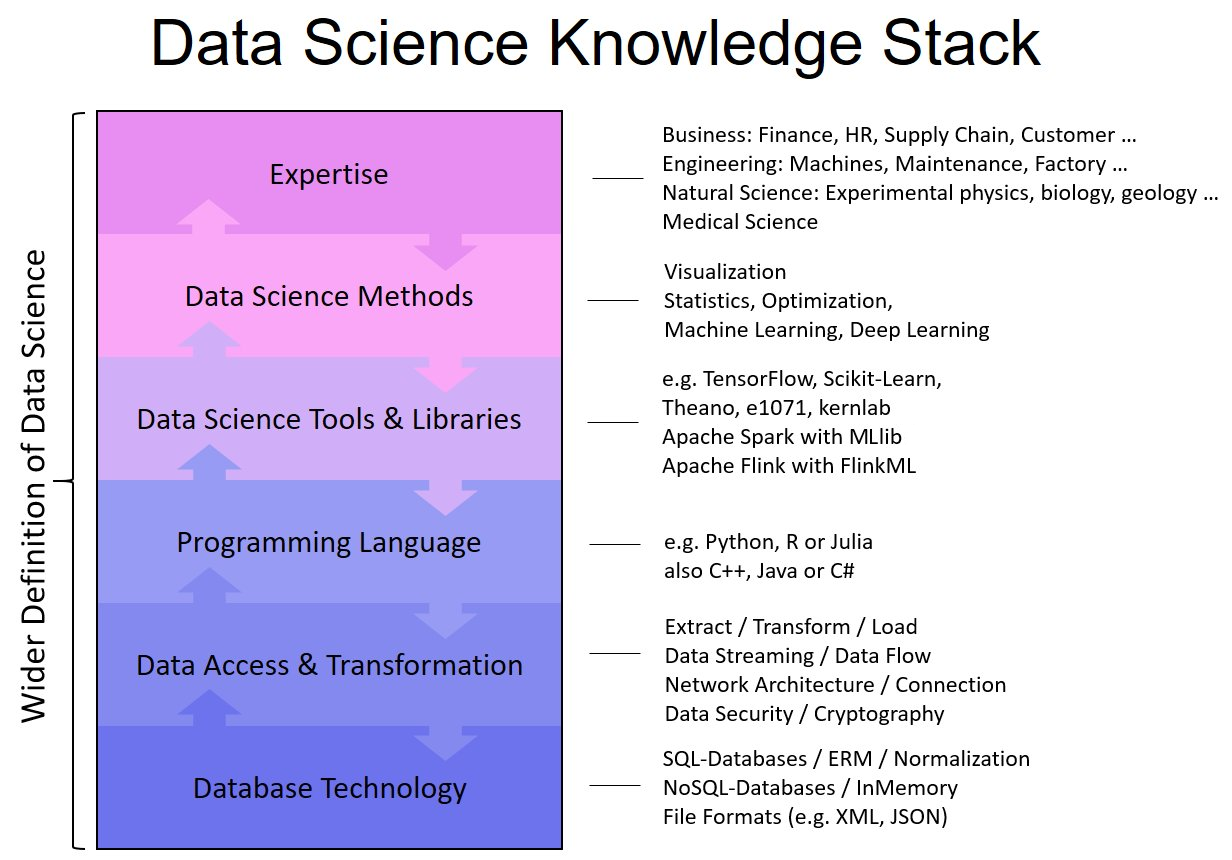
Data science is increasingly becoming essential for every business to operate efficiently in this modern world. This influences the processes composed together to obtain the required outputs for clients. While machine learning and deep learning sit at the core of data science, the concepts of deep learning become essential to understand as it can help increase the accuracy of final outputs. And when it comes to data science, R and Python are the most popular programming languages used to instruct the machines.
Python and R: Primary Languages Used for Deep Learning
Deep learning and machine learning differentiate based on the input data type they use. While machine learning depends upon the structured data, deep learning uses neural networks to store and process the data during the learning. Deep learning can be described as the subset of machine learning, where the data to be processed is defined in another structure than a normal one.
R is developed specifically to support the concepts and implementation of data science and hence, the support provided by this language is incredible as writing codes become much easier with its simple syntax.
Python is already much popular programming language that can serve more than one development niche without straining even for a bit. The implementation of Python for programming machine learning algorithms is very much popular and the results provided are accurate and faster than any other language. (C or Java). And because of its extended support for data science concept implementation, it becomes a tough competitor for R.
However, if we compare the charts of popularity, Python is obviously more popular among data scientists and developers because of its versatility and easier usage during algorithm implementation. However, R outruns Python when it comes to the packages offered to developers specifically expertise in R over Python. Therefore, to conclude which one of them is the best, let’s take an overview of the features and limits offered by both languages.
Python
Python was first introduced by Guido Van Rossum who developed it as the successor of ABC programming language. Python puts white space at the center while increasing the readability of the developed code. It is a general-purpose programming language that simply extends support for various development needs.
The packages of Python includes support for web development, software development, GUI (Graphical User Interface) development and machine learning also. Using these packages and putting the best development skills forward, excellent solutions can be developed. According to Stackoverflow, Python ranks at the fourth position as the most popular programming language among developers.
Benefits for performing enhanced deep learning using Python are:
- Concise and Readable Code
- Extended Support from Large Community of Developers
- Open-source Programming Language
- Encourages Collaborative Coding
- Suitable for small and large-scale products
The latest and stable version of Python has been released as Python 3.8.0 on 14th October 2019. Developing a software solution using Python becomes much easier as the extended support offered through the packages drives better development and answers every need.
R
R is a language specifically used for the development of statistical software and for statistical data analysis. The primary user base of R contains statisticians and data scientists who are analyzing data. Supported by R Foundation for statistical computing, this language is not suitable for the development of websites or applications. R is also an open-source environment that can be used for mining excessive and large amounts of data.
R programming language focuses on the output generation but not the speed. The execution speed of programs written in R is comparatively lesser as producing required outputs is the aim not the speed of the process. To use R in any development or mining tasks, it is required to install its operating system specific binary version before coding to run the program directly into the command line.
R also has its own development environment designed and named RStudio. R also involves several libraries that help in crafting efficient programs to execute mining tasks on the provided data.
The benefits offered by R are pretty common and similar to what Python has to offer:
- Open-source programming language
- Supports all operating systems
- Supports extensions
- R can be integrated with many of the languages
- Extended Support for Visual Data Mining
Although R ranks at the 17th position in Stackoverflow’s most popular programming language list, the support offered by this language has no match. After all, the R language is developed by statisticians for statisticians!
Python vs R: Should They be Really Compared?
Even when provided with the best technical support and efficient tools, a developer will not be able to provide quality outputs if he/she doesn’t possess the required skills. The point here is, technical skills rank higher than the resources provided. A comparison of these two programming languages is not advisable as they both hold their own set of advantages. However, the developers considering to use both together are less but they obtain maximum benefit from the process.
Both these languages have some features in common. For example, if a representative comes asking you if you lend technical support for developing an uber clone, you are directly going to decline as Python and R both do not support mobile app development. To benefit the most and develop excellent solutions using both these programming languages, it is advisable to stop comparing and start collaborating!
R and Python: How to Fit Both In a Single Program
Anticipating the future needs of the development industry, there has been a significant development to combine these both excellent programming languages into one. Now, there are two approaches to performing this: either we include R script into Python code or vice versa.
Using the available interfaces, packages and extended support from Python we can include R script into the code and enhance the productivity of Python code. Availability of PypeR, pyRserve and more resources helps run these two programming languages efficiently while efficiently performing the background work.
Either way, using the developed functions and packages made available for integrating Python in R are also effective at providing better results. Available R packages like rJython, rPython, reticulate, PythonInR and more, integrating Python into R language is very easy.
Therefore, using the development skills at their best and maximizing the use of such amazing resources, Python and R can be togetherly used to enhance end results and provide accurate deep learning support.
Conclusion
Python and R both are great in their own names and own places. However, because of the wide applications of Python in almost every operation, the annual packages offered to Python developers are less than the developers skilled in using R. However, this doesn’t justify the usability of R. The ultimate decision of choosing between these two languages depends upon the data scientists or developers and their mining requirements.
And if a developer or data scientist decides to develop skills for both- Python and R-based development, it turns out to be beneficial in the near future. Choosing any one or both to use in your project depends on the project requirements and expert support on hand.

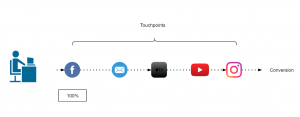
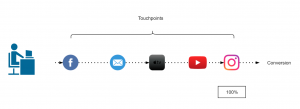
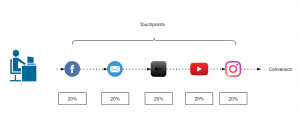
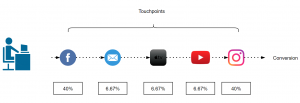



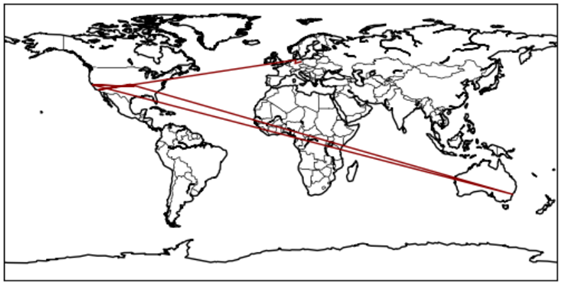
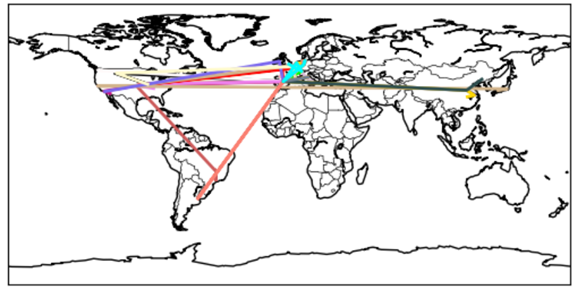
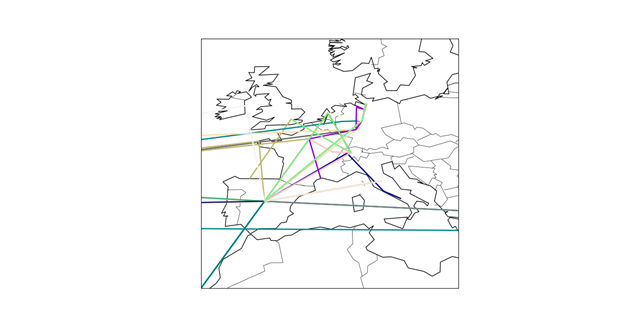



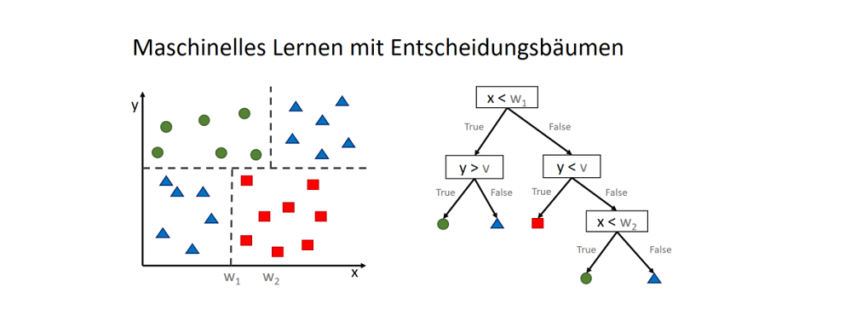
 ) im Sinne des ID3-Algorithmus ist die Differenz aus der Entropie (
) im Sinne des ID3-Algorithmus ist die Differenz aus der Entropie ( ) (siehe Teil 1 der Artikelserie:
) (siehe Teil 1 der Artikelserie:  ) und der Summe aus den gewichteten Entropien des Attributes für jeden einzelnen Wert (Value
) und der Summe aus den gewichteten Entropien des Attributes für jeden einzelnen Wert (Value  ), der im Attribut vorkommt:
), der im Attribut vorkommt: