Dieser Artikel der Artikelserie Process Mining Tools beschäftigt sich mit dem Anbieter Fluxicon. Das im Jahr 2010 gegründete Unternehmen, bis heute geführt von den zwei Gründern Dr. Anne Rozinat und Dr. Christian W. Günther, die beide bei Prof. Wil van der Aalst in Eindhoven promovierten, sowie einem weiteren Mitarbeiter, ist eines der ersten Tool-Anbieter für Process Mining. Das Tool Disco ist das Kernprodukt des Fluxicon-Teams und bietet pures Process Mining.
Die beiden Gründer haben übrigens eine ganze Reihe an Artikeln zu Process Mining (ohne Sponsoring / ohne Entgelt) veröffentlicht.
| Lösungspakete: |
Standard-Lizenz |
| Zielgruppe: |
Lauf Fluxicon für Unternehmen aller Größen. |
| Datenquellen: |
Keine Standard-Konnektoren. Benötigt fertiges Event Log. |
| Datenvolumen: |
Unlimitierte Datenmengen, Beschränkung nur durch Hardware. |
| Architektur: |
On-Premise / Desktop-Anwendung |
Diese Software für Process Mining ist für jeden, der in Process Mining reinschnuppern möchte, direkt als Download verfügbar. Die Demo-Lizenz reicht aus, um eigene Event-Logs auszuprobieren oder das mitgelieferte Event-Log (Sandbox) zu benutzen. Es gibt ferner mehrere Evaluierungslizenz-Modelle sowie akademische Lizenzen via Kooperationen mit Hochschulen.
Fluxicon Disco erfreut sich einer breiten Nutzerbasis, die seit 2012 über das jährliche ‘Process Mining Camp’ (https://fluxicon.com/camp/index und http://processminingcamp.com ) und seit 2020 auch über das monatliche ‘Process Mining Café’ (https://fluxicon.com/cafe/) vorangetrieben wird.
Bedienbarkeit und Anpassungsfähigkeit der Analysen
Fluxicon Disco bietet den Vorteil des schnellen Einstiegs in datengetriebene Prozessanalysen und ist überaus nutzerfreundlich für den Analysten. Die Oberflächen sind leicht zu bedienen und die Bedeutung schnell zu erfassen oder zumindest zu erahnen. Die Filter-Möglichkeiten sind überraschend umfangreich und äußerst intuitiv bedien- und kombinierbar.
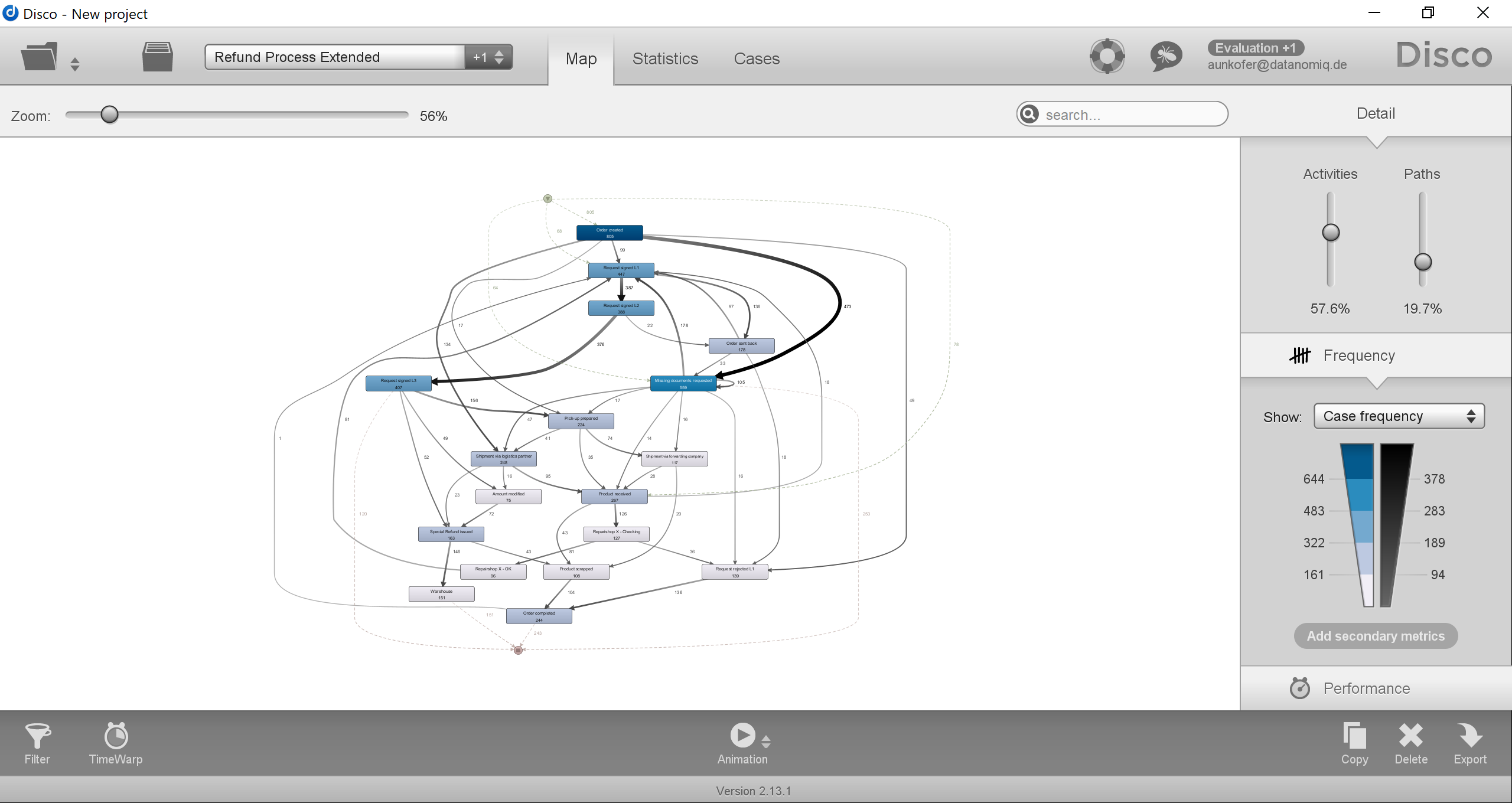
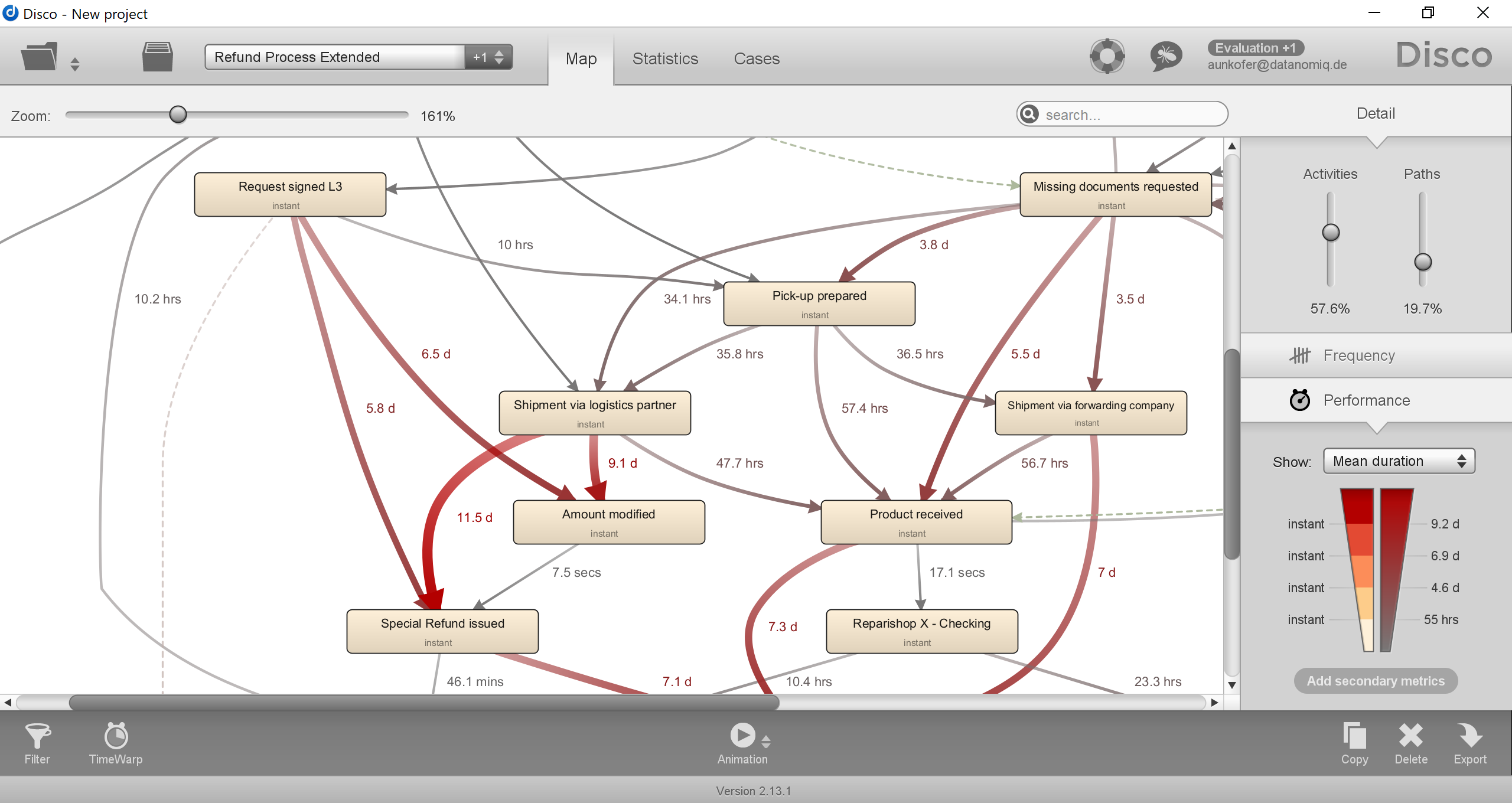
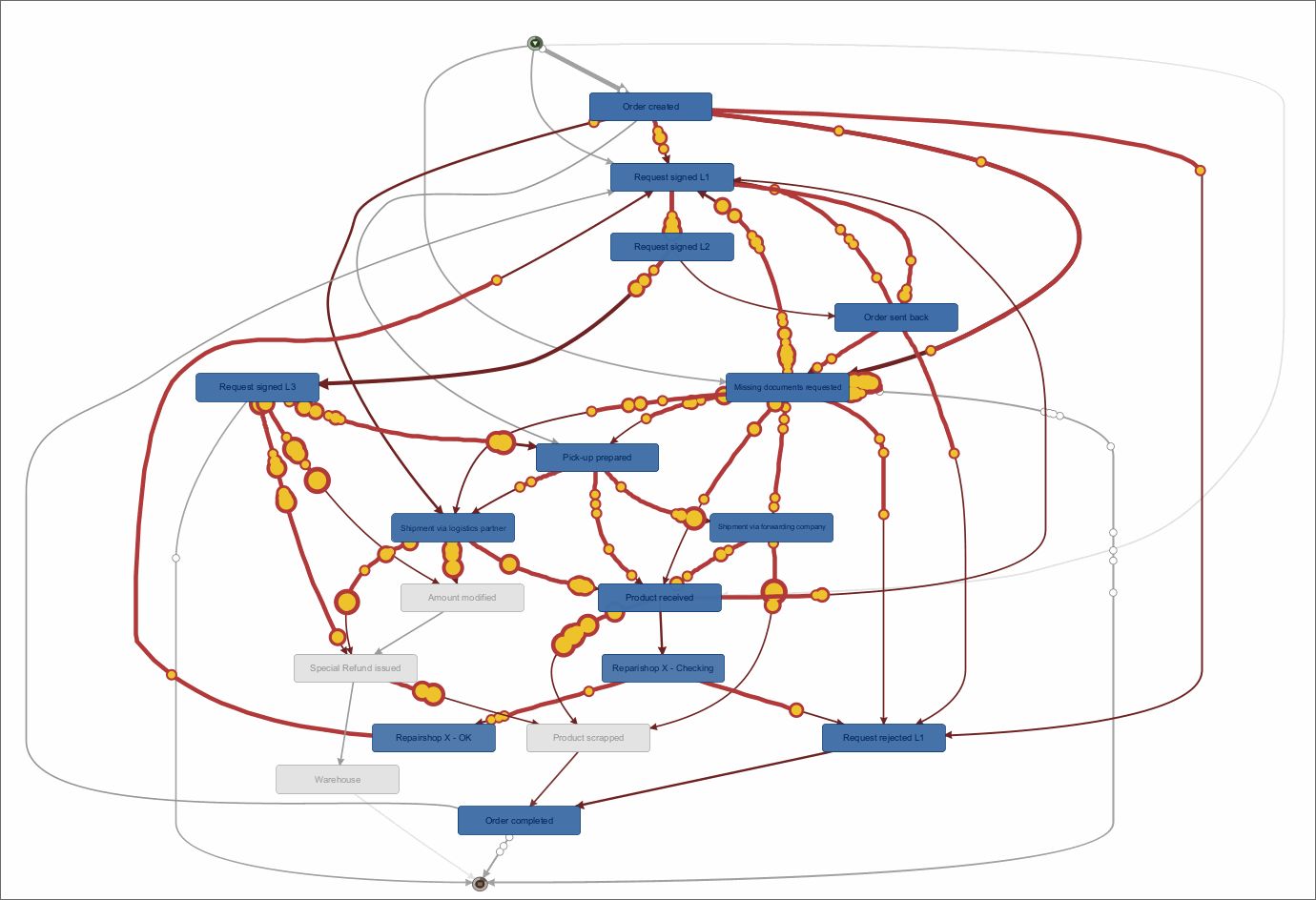
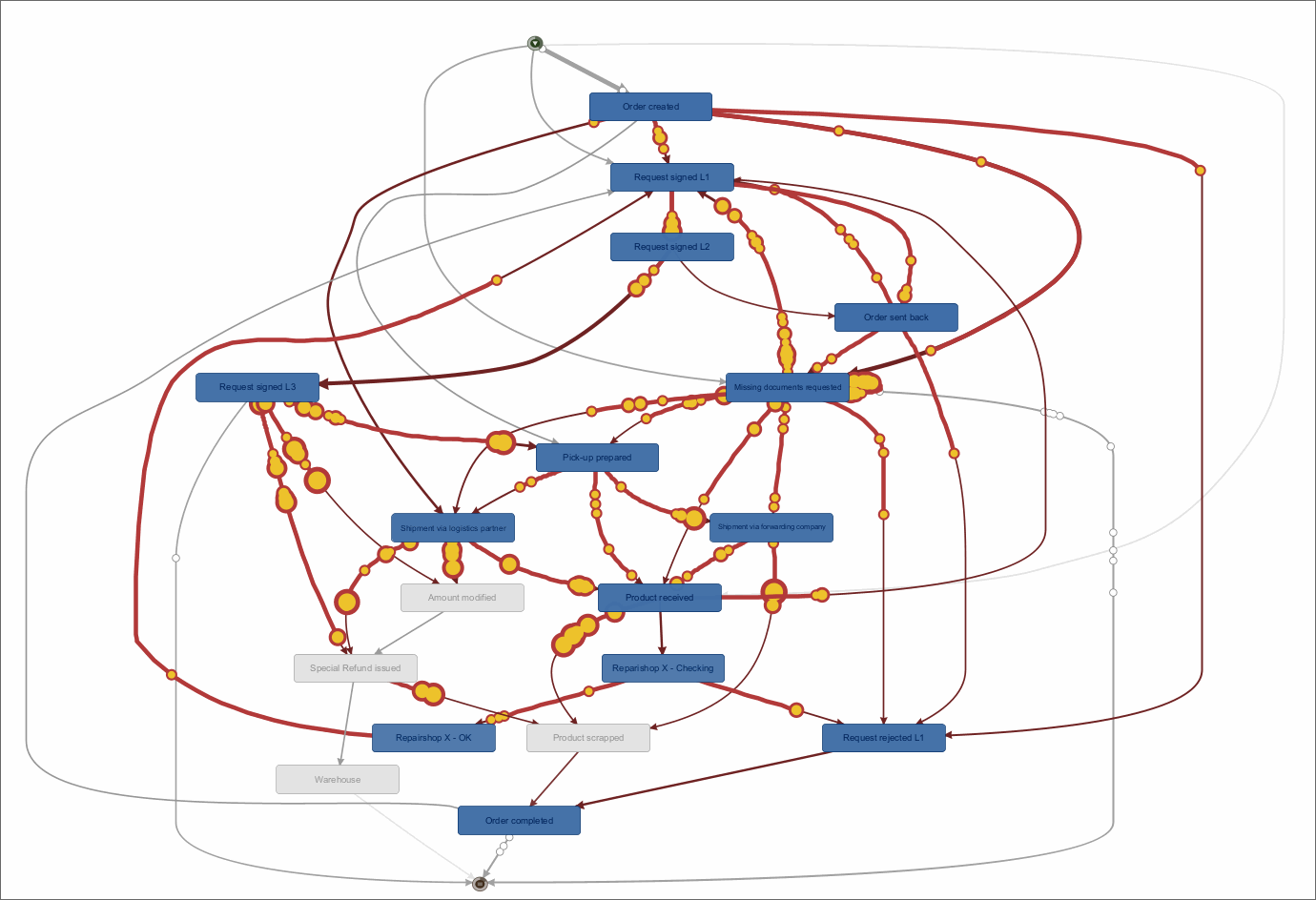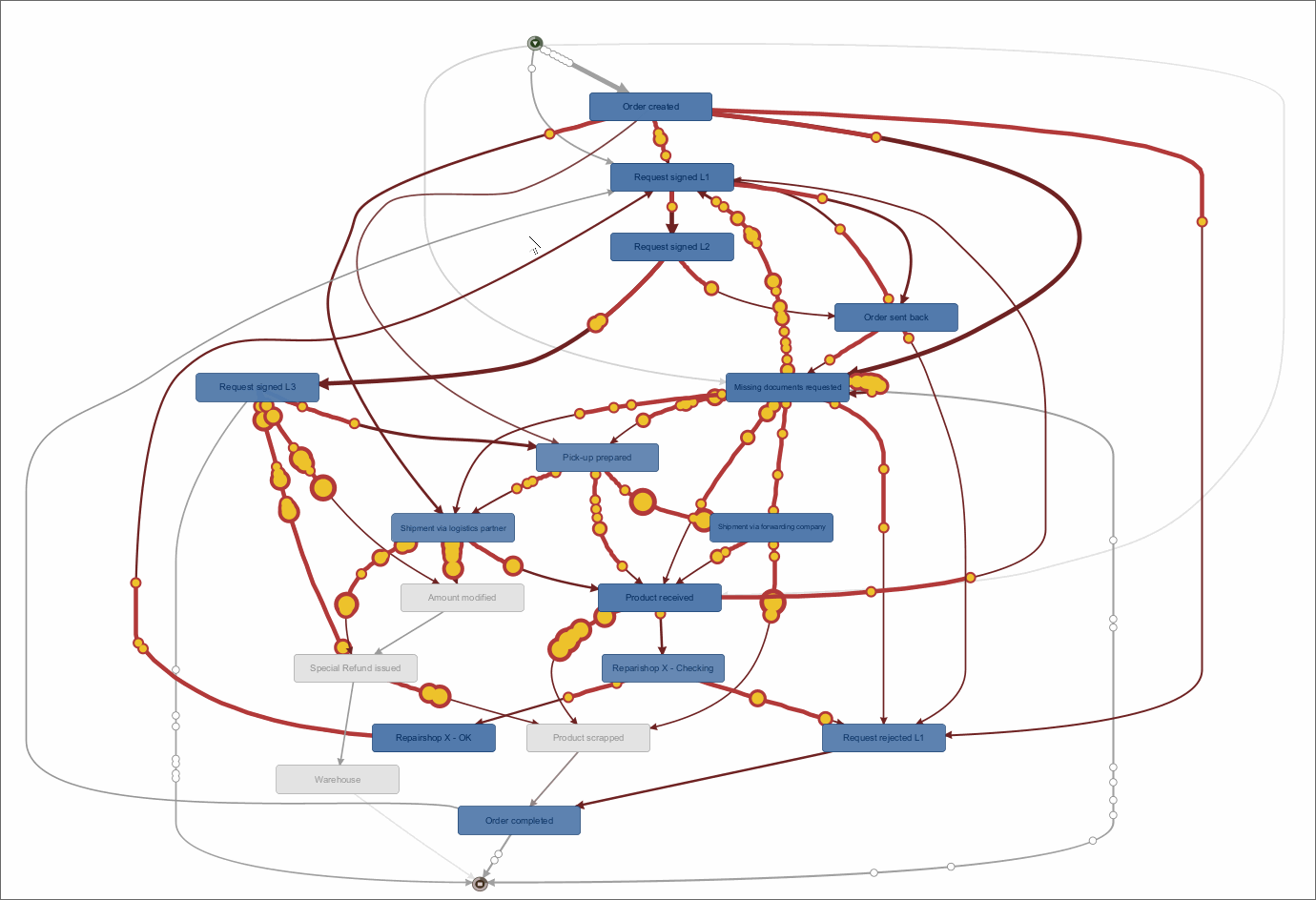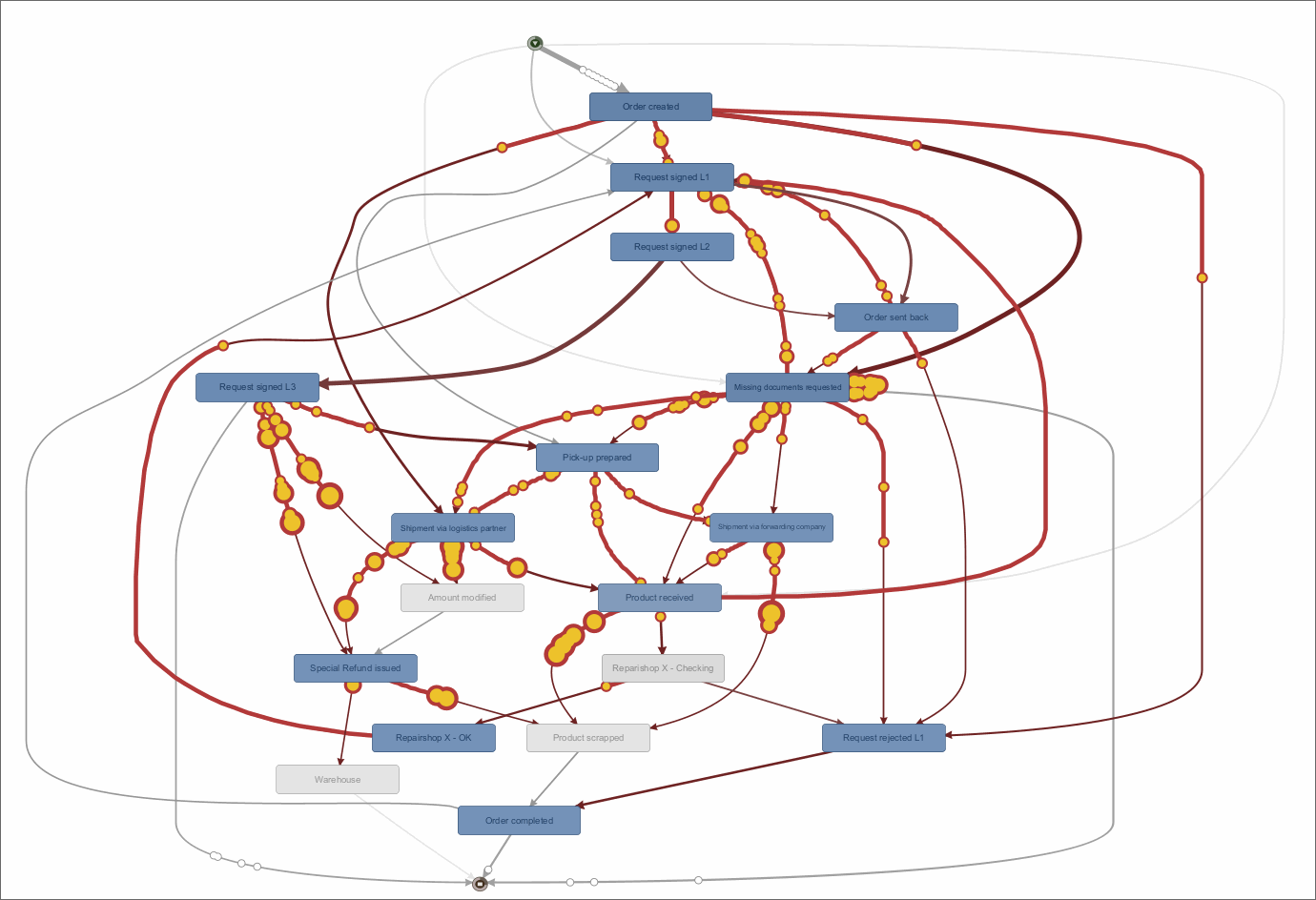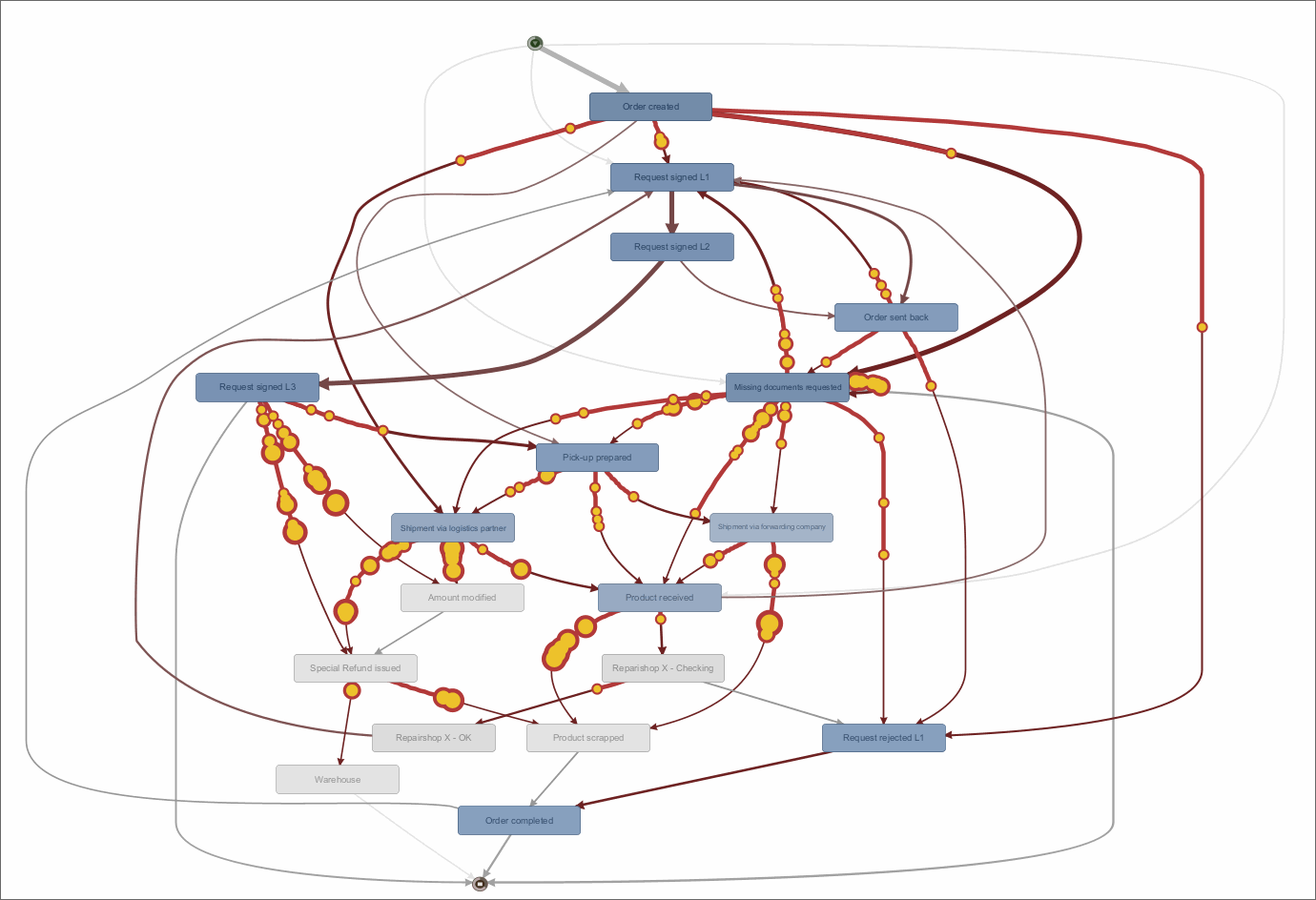
Fluxicon Disco Process Mining – Das Haupt-Dashboard zeigt den Process Flow aus der Rekonstruktion auf Basis des Event Logs. Hier wird die Frequenz-Ansicht gezeigt, die Häufigkeiten von Cases und Events darstellt.
Disco lässt den Analysten auf Process Mining im Kern fokussieren, es können keine Analyse-Diagramme strukturell hinzugefügt, geändert oder gelöscht werden, es bleibt ein statischer Report ohne weitere BI-Funktionalitäten.
Die Visualisierung des Prozess-Graphen im Bereich “Map” ist übersichtlich, stets gut lesbar und leicht in der Abdeckung zu steuern. Die Hauptmetrik kann zwischen der Frequenz- zur Zeit-Orientierung hin und her geschaltet werden. Neben der Hauptmetrik kann auch eine zweite Metrik (Secondary Metric) zur Ansicht hinzugefügt werden, was sehr sinnvoll ist, wenn z. B. neben der durchschnittlichen Zeit zwischen Prozessaktivitäten auch die Häufigkeit dieser Prozessfolgen in Relation gesetzt werden soll.
Die Ansicht “Statistics” zeigt die wesentlichen Einblicke nach allen Dimensionen aus statistischer Sicht: Welche Prozessaktivitäten, Ressourcen oder sonstigen Features treten gehäuft auf? Diese Fragen werden hier leicht beantwortet, ohne dass der Analyst selbst statistische Berechnungen anstellen muss – jedoch auch ohne es zu dürfen, würde er wollen.
Die weitere Ansicht “Cases” erlaubt einen Einblick in die Prozess-Varianten und alle Einzelfälle innerhalb einer Variante. Diese Ansicht ist wichtig für Prozessoptimierer, die Optimierungspotenziale vor allem in häufigen, sich oft wiederholenden Prozessverläufen suchen möchten. Für Compliance-Analysten sind hingegen eher die oft vielen verschiedenen Einzelfälle spezieller Prozessverläufe der Fokus.
Für Einsteiger in Process Mining als Methodik und Disco als Tool empfiehlt sich übrigens das Process Mining Online Book: https://processminingbook.com
Integrationsfähigkeit
Fluxicon Disco ist eine Desktop-Anwendung, die nicht als Cloud- oder Server-Version verfügbar ist. Es ist möglich, die Software auf einem Windows Application Server on Premise zu installieren und somit als virtuelle Umgebung via Microsoft Virtual Desktop oder via Citrix als virtuelle Anwendung für mehrere Anwender zugleich verfügbar zu machen. Allerdings ist dies keine hochgradige Integration in eine Enterprise-IT-Infrastruktur.
Auch wird von Disco vorausgesetzt, dass Event Logs als einzelne Tabellen bereits vorliegen müssen. Dieses Tool ist also rein für die Analyse vorgesehen und bietet keine Standardschnittstellen mit vorgefertigten Skripten zur automatischen Herstellung von Event Logs beispielsweise aus Salesforce CRM oder SAP ERP.
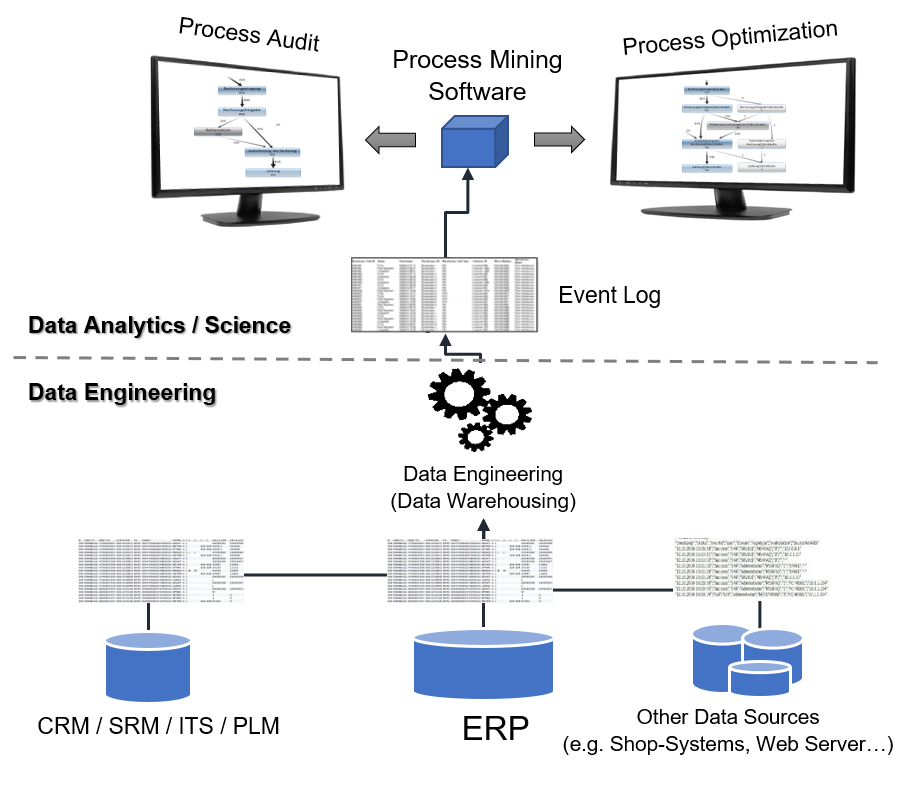
Grundsätzlich sollte Process Mining methodisch stets als Doppel-Disziplin betrachtet werden: Der erste Teil des Process 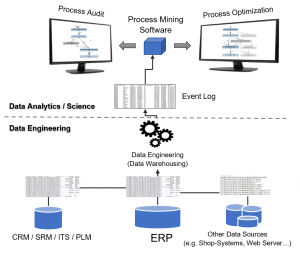 Minings fällt in die Kategorie Data Engineering und umfasst die Betrachtung der IT-Systeme (ERP, CRM, SRM, PLM, DMS, ITS,….), die für einen bestimmten Prozess relevant sind, und die in diesen System hinterlegten Datentabellen als Datenquellen. Die in diesen enthaltenen Datenspuren über Prozessaktivitäten müssen dann in ein Prozessprotokoll überführt und in ein Format transformiert werden, das der Inputvoraussetzung als Event Log für das jeweilige Process Mining Tool gerecht wird. Minimalanforderung ist hierbei zumindest eine Vorgangsnummer (Case ID), ein Zeitstempel (Event Time) einer Aktivität und einer Beschreibung dieser Aktivität (Event).
Minings fällt in die Kategorie Data Engineering und umfasst die Betrachtung der IT-Systeme (ERP, CRM, SRM, PLM, DMS, ITS,….), die für einen bestimmten Prozess relevant sind, und die in diesen System hinterlegten Datentabellen als Datenquellen. Die in diesen enthaltenen Datenspuren über Prozessaktivitäten müssen dann in ein Prozessprotokoll überführt und in ein Format transformiert werden, das der Inputvoraussetzung als Event Log für das jeweilige Process Mining Tool gerecht wird. Minimalanforderung ist hierbei zumindest eine Vorgangsnummer (Case ID), ein Zeitstempel (Event Time) einer Aktivität und einer Beschreibung dieser Aktivität (Event).
Das Event Log kann dann in ein oder mehrere Process Mining Tools geladen werden und die eigentliche Prozessanalyse kann beginnen. Genau dieser Schritt der Kategorie Data Analytics kann in Fluxicon Disco erfolgen.
Zum Einspeisen eines Event Logs kann der klassische CSV-Import verwendet werden oder neuerdings auch die REST-basierte Airlift-Schnittstelle, so dass Event Logs direkt von Servern On-Premise oder aus der Cloud abgerufen werden können.

Prinzip des direkten Zugriffs auf Event Logs von Servern via Airlift.
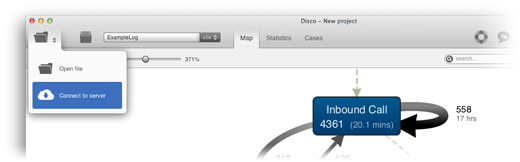
Import von Event Logs als CSV (“Open file”) oder von Servern auch aus der Cloud.
Sind diese Limitierungen durch die Software für ein Unternehmen, bzw. für dessen Vorhaben, vertretbar und bestehen interne oder externe Ressourcen zum Data Engineering von Event Logs, begeistert die Einfachheit von Process Mining mit Fluxicon Disco, die den schnellsten Start in diese Analyse verspricht, sofern die Daten als Event Log vorbereitet vorliegen.
Skalierbarkeit
Die Skalierbarkeit im Sinne hochskalierender Datenmengen (Big Data Readiness) sowie auch im Sinne eines Ausrollens dieser Analyse-Software auf einer Konzern-Ebene ist nahezu nicht gegeben, da hierzu Benutzer-Berechtigungsmodelle fehlen. Ferner darf hierbei nicht unberücksichtigt bleiben, dass Disco, wie zuvor erläutert, ein reines Analyse-/Visualisierungstool ist und keine Event Logs generieren kann (der Teil der Arbeit, der viele Hardware Ressourcen benötigt).
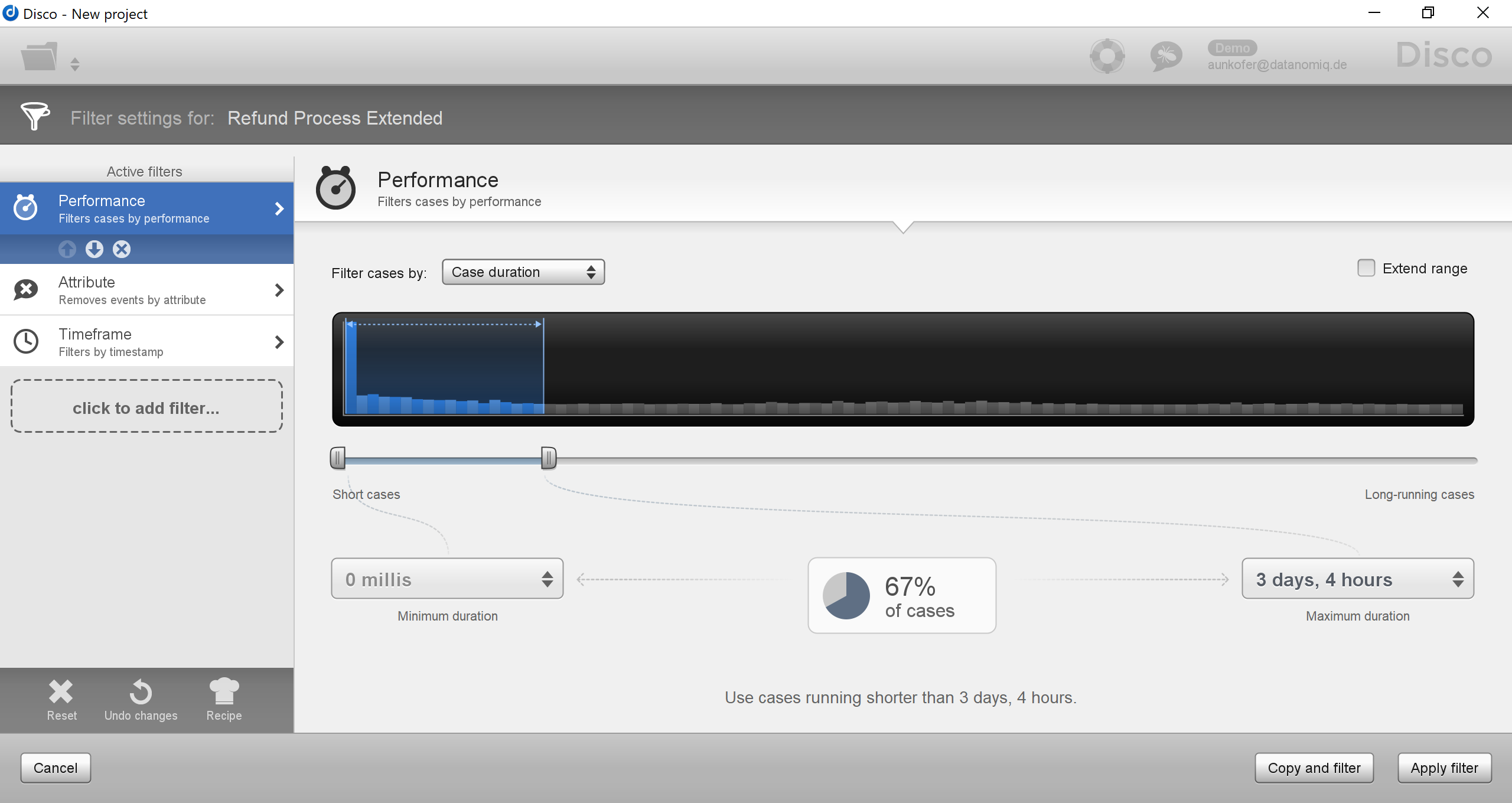
Für die reine Analyse läuft Disco jedoch auch mit vielen Daten sehr zügig und ist rein auf Ebene der Hardware-Ressourcen limitiert. Vertikales Upscaling ist auf dieser Ebene möglich, dazu empfiehlt sich diese Leselektüre zum System-Benchmark.
Zukunftsfähigkeit
Fluxicon Disco ist eines der Process Mining Tools der ersten Stunde und wird auch heute noch stetig vom Fluxicon Team mit kleinen Updates versorgt, die Weiterentwicklung ist erkennbar, beschränkt sich jedoch auf Process Mining im Kern.
Preisgestaltung
Die Preisgestaltung wird, wie auch bei den meisten anderen Anbietern für Process Mining Tools, nicht transparent kommuniziert. Aus eigener Einsatzerfahrung als Berater können mit Preisen um 1.000 EUR pro Benutzer pro Monat gerechnet werden, für Endbenutzer in Anwenderunternehmen darf von anderen Tarifen ausgegangen werden.
Studierende von mehr als 700 Universitäten weltweit (siehe https://fluxicon.com/academic/) können Fluxicon Disco kostenlos nutzen und das sehr unkompliziert. Sie bekommen bereits automatisch akademische Lizenzen, sobald sie sich mit ihrer Uni-Email-Adresse in dem Tool registrieren. Forscher und Studierende, deren Uni noch kein Partner ist, können sehr leicht auch individuelle akademische Lizenzen anfragen.
Fazit
Fluxicon Disco ist ein Process Mining Tool der ersten Stunde und das bis heute. Das Tool beschränkt sich auf das Wesentliche, bietet keine Big Data Plattform mit Multi-User-Management oder anderen Möglichkeiten integrierter Data Governance, auch sind keine Standard-Schnittstellen zu anderen IT-Systemen vorhanden. Auch handelt es sich hierbei nicht um ein Tool, das mit anderen BI-Tools interagieren oder gar selbst zu einem werden möchte, es sind keine eigenen Report-Strukturen erstellbar. Fluxicon Disco ist dafür der denkbar schnellste Einstieg mit minimaler Rüstzeit in Process Mining für kleine bis mittelständische Unternehmen, für die Hochschullehre und nicht zuletzt auch für Unternehmensberatungen oder Wirtschaftsprüfungen, die ihren Kunden auf schlanke Art und Weise Ist-Prozessanalysen ergebnisorientiert anbieten möchten.
Dass Disco seitens Fluxicon nur für kleine und mittelgroße Unternehmen bestimmt ist, ist nicht ganz zutreffend. Die meisten Kunden sind grosse Unternehmen (Banken, Versicherungen, Telekommunikationsanabieter, Ministerien, Pharma-Konzerne und andere), denn diese haben komplexe Prozesse und somit den größten Optimierungsbedarf. Um Process Mining kommen die Unternehmen nicht herum und so sind oft auch mehrere Tools verschiedener Anbieter im Einsatz, die sich gegenseitig um ihre Stärken ergänzen, für Fluxicon Disco ist dies die flexible Nutzung, nicht jedoch das unternehmensweite Monitoring. Der flexible und schlanke Einsatz von Disco in vielen Unternehmen zeigt sich auch mit Blick auf die Sprecher und Teilnehmer der jährlichen Nutzerkonferenz, dem Process Mining Camp.



 Über Exasol-CEO Martin Golombek
Über Exasol-CEO Martin Golombek


 Torsten Nahm ist Head of Data Science bei der DKB (Deutsche Kreditbank AG) in Berlin. Er hat Mathematik in Bonn mit einem Schwerpunkt auf Statistik und numerischen Methoden studiert. Er war zuvor u.a. als Berater bei KPMG und OliverWyman tätig sowie bei dem FinTech Funding Circle, wo er das Risikomanagement für die kontinentaleuropäischen Märkte geleitet hat.
Torsten Nahm ist Head of Data Science bei der DKB (Deutsche Kreditbank AG) in Berlin. Er hat Mathematik in Bonn mit einem Schwerpunkt auf Statistik und numerischen Methoden studiert. Er war zuvor u.a. als Berater bei KPMG und OliverWyman tätig sowie bei dem FinTech Funding Circle, wo er das Risikomanagement für die kontinentaleuropäischen Märkte geleitet hat.