Interview mit Prof. Thomas Schrader zur Motivation des Erlernens von Clinical Data Analytics
Prof. Dr. Thomas Schrader ist Fachbereichsleiter Informatik und Medien an der TH Brandenburg und hat seinen Projekt- und Lehrschwerpunkt in der Medizininformatik. Als Experte für Data Science verknüpft er das Wissen um Informatik und Statistik mit einem medizinischen Verständnis. Dieses Wissen wird genutzt, um eine beweisorientierte Diagnose stellen, aber auch, um betriebswirtschaftliche Prozesse zu verbessern. Prof. Thomas Schrader ist zudem Dozent und Mitgestalter des Zertifikatskurses Clinical Data Analytics.

Data Science Blog: Wie steht es um die medizinische Datenanalyse? Welche Motivation gibt es dafür, diese zu erlernen und anzuwenden?
Die Digitalisierung ist inzwischen auch in der Medizin angekommen. Befunde, Laborwerte und Berichte werden elektronisch ausgetauscht und stehen somit digital zur Verfügung. Ob im Krankenhaus, im Medizinischen Versorgungszentrum oder in der ambulanten Praxis, medizinische Daten dienen zur Befunderhebung, Diagnosestellung oder zur Therapiekontrolle.
Über mobile Anwendungen, Smart Phones und Smart Watches werden ebenfalls Daten erhoben und PatientInnen stellen diese zur Einsicht zur Verfügung.
Die Verwaltung der Daten und die richtige Nutzung der Daten wird zunehmend zu einer notwendigen Kompetenz im medizinischen Berufsalltag. Jetzt besteht die Chance, den Umgang mit Daten zu erlernen, deren Qualität richtig zu beurteilen und den Prozess der fortschreitenden Digitalisierung zu gestalten.
Daten haben Eigenschaften, Daten haben eine Lebenszeit, einen Lebenszyklus. Ähnlich einem Auto, sind verschiedene Personen in unterschiedlichen Rollen daran beteiligt und verantwortlich , Daten zu erheben, zu speichern oder Daten zur Verfügung zu stellen. Je nach Art der Daten, abhängig von der Datenqualität lassen sich diese Daten weiterverwenden und ggf. Schlussfolgerungen ziehen. Die Möglichkeit aus Daten Wissen zu generieren, ist für die medizinische Arbeit eine große Chance und Herausforderung.
Data Science Blog: Bedeutet MDA gleich BigData?
Big Data ist inzwischen ein Buzzwort: Alles soll mit BigData und der Anwendung von künstlicher Intelligenz gelöst werden. Es entsteht aber der Eindruck, dass nur die großen Firmen (Google, Facebook u.a.) von BigData profitieren. Sie verwenden ihre Daten, um Zielgruppen zu differenzieren, zu identifizieren und Werbung zu personalisieren.
Medizinische Datenanalyse ist nicht BigData! Medizinische Datenanalyse kann lokal mit den Daten eines Krankenhauses, eines MVZ oder ambulanten Praxis durchgeführt werden. Explorativ wird das Wissen aus diesen Daten erschlossen. Es können schon auf dieser Ebene Indikatoren der medizinischen Versorgung erhoben werden. Es lassen sich Kriterien berechnen, die als Indikatoren für die Detektion von kritischen Fällen dienen.
Mit einer eigenen Medizinischen Datenanalyse lassen sich eigene Daten analysieren, ohne jemals die Kontrolle über die Daten abzugeben. Es werden dabei Methoden verwendet, die teilweise auch bei Big Data Anwendung finden.
Data Science Blog: Für wen ist das Erlernen der medizinischen Datenanalyse interessant?
Die Medizinische Datenanalyse ist für alle interessant, die sich mit Daten und Zahlen in der Medizin auseinandersetzen. Die Frage ist eigentlich, wer hat nichts mit Daten zu tun?
Im ersten Augenblick fallen die ambulant und klinisch tätigen ÄrztInnen ein, für die MDA wichtig wäre: in einer Ambulanz kommt ein für diese Praxis typisches Spektrum an PatientInnen mit ihren Erkrankungsmustern. MDA kann diese spezifischen Eigenschaften charakterisieren, denn darin liegt ja Wissen: Wie häufig kommen meine PatientInnen mit der Erkrankung X zu mir in die Praxis? Dauert bei einigen PatientInnen die Behandlungszeit eigentlich zu lange? Bleiben PatientInnen weg, obwohl sie noch weiter behandelt werden müssten? Dahinter liegen also viele Fragen, die sich sowohl mit der Wirtschaftlichkeit als auch mit der Behandlungsqualität auseinandersetzen. Diese sehr spezifischen Fragen wird Big Data übrigens niemals beantworten können.
Aber auch die Pflegekräfte benötigen eigentlich dringend Werkzeuge für die Bereitstellung und Analyse der Pflegedaten. Aktuell wird sehr über die richtige Personalbesetzung von Stationen und Pflegeeinrichtungen diskutiert. Das eigentliche Problem dabei ist, dass für die Beantwortung dieser Frage Zahlen notwendig sind: über dokumentierte Pflegehandlungen, Arbeitszeiten und Auslastung. Inzwischen wird damit begonnen, dieses Daten zu erheben, aber es fehlen eine entsprechende Infrastruktur dieses Daten systematisch zu erfassen, auszuwerten und in einen internationalen, wissenschaftlichen Kontext zu bringen. Auch hier wird Big Data keine Erkenntnisse bringen: weil keine Daten vorhanden sind und weil keine ExpertIn aus diesem Bereich die Daten untersucht.
Die Physio-, ErgotherapeutInnen und LogopädInnen stehen aktuell unter dem hohen Druck, einen Nachweis ihrer therapeutischen Intervention zu bringen. Es geht auch hier schlicht darum, ob auch zukünftig alle Therapieformen bezahlt werden. Über die Wirksamkeit von Physio-, Ergo- und Logopädie können nur Statistiken Auskunft geben. Auch diese Berufsgruppen profitieren von der Medizinischen Datenanalyse.
In den Kliniken gibt es Qualitäts- und Risikomanager. Deren Arbeit basiert auf Zahlen und Statistiken. Die Medizinische Datenanalyse kann helfen, umfassender, besser über die Qualität und bestehende Risiken Auskunft zu geben.
Data Science Blog: Was kann genau kann die medizinische Datenanalyse leisten?
Die Technische Hochschule Brandenburg bietet einen Kurs Medizinische/ Klinische Datenanalyse an. In diesem Kurs wird basierend auf dem Lebenszyklus von Daten vermittelt, welche Aufgaben zu leisten sind, um gute Analysen durchführen zu können. Das fängt bei der Datenerhebung an, geht über die richtige und sichere Speicherung der Daten unter Beachtung des Datenschutzes und die Analyse der Daten. Da aber gerade im medizinischen Kontext die Ergebnisse eine hohe Komplexität aufweisen können, kommt auch der Visualisierung und Präsentation von Daten eine besondere Bedeutung zu. Eine zentrale Frage, die immer beantwortet werden muss, ist, ob die Daten für bestimmte Aussagen oder Entscheidungen tauglich sind. Es geht um die Datenqualität. Dabei ist nicht immer die Frage zu beantworten, ob das “gute” oder “schlechte” Daten sind, sondern eher um die Beschreibung der spezifischen Eigenschaften von Daten und die daraus resultierenden Verwendungsmöglichkeiten.
Data Science Blog: Sie bieten an der TH Brandenburg einen Zertifikatskurs zum Erlernen der Datenanalyse im Kontext der Medizin an. Was sind die Inhalte des Kurses?
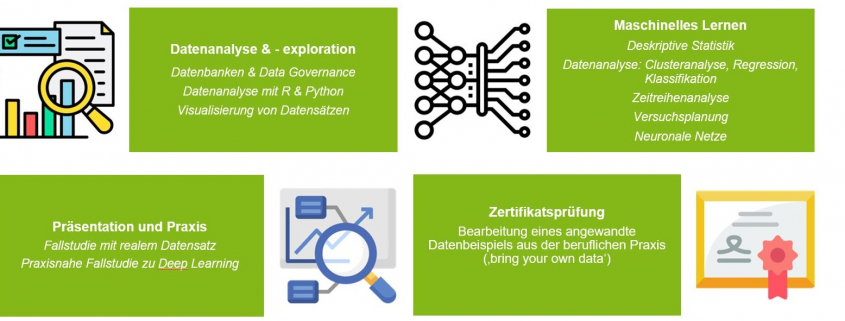
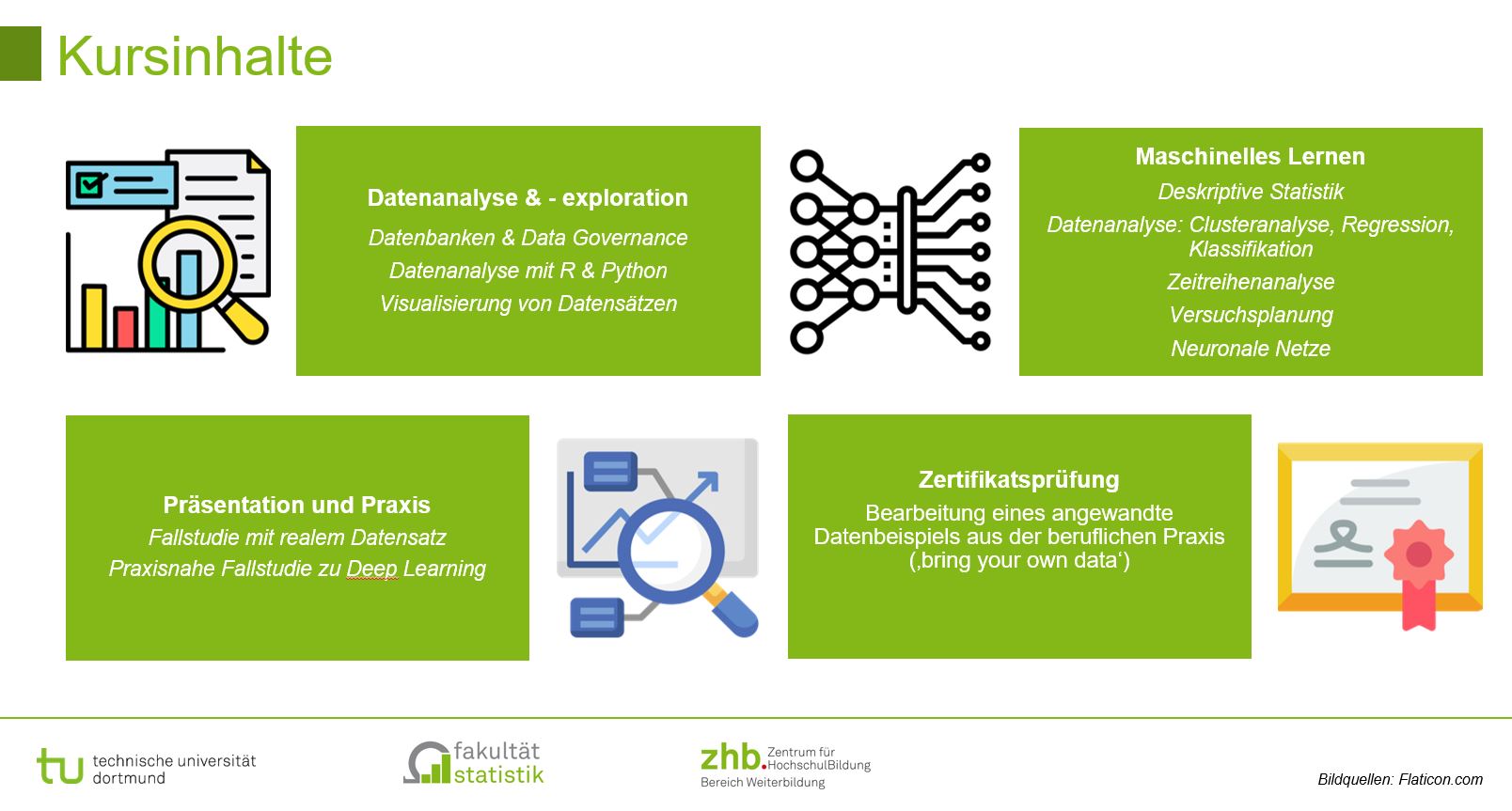
Der Kurs gliedert sich in drei Module:
– Modul 1 – Daten aus Klinik und Pflege – Von den Daten zur Information: In diesem Modul wird auf die unterschiedlichen Datenquellen eingegangen und deren Qualität näher untersucht. Daten allein sagen zuweilen sehr wenig, sie müssen in einen Zusammenhang gebracht werden, damit daraus verwertbare Informationen. Im Mittelpunkt stehen die Teile des Datenlebenszyklus, die sich mit der Erhebung und Speicherung der Daten beschäftigen.
– Modul 2 – Anwenden der Werkzeuge: Analysieren, Verstehen und Entscheiden – Von Information zum Wissen. Der Schritt von Information zu Wissen wird dann begangen, wenn eine Strukturierung und Analyse der Informationen erfolgt: Beschreiben, Zusammenfassen und Zusammenhänge aufdecken.
– Modul 3 – Best practice – Fallbeispiele: Datenanalyse für die Medizin von morgen – von smart phone bis smart home, von Registern bis sozialen Netzen: In diesem Modul wird an Hand von verschiedenen Beispielen der gesamte Datenlebenszyklus dargestellt und mit Analysen sowie Visualisierung abgeschlossen.
Data Science Blog: Was unterscheidet dieser Kurs von anderen? Und wie wird dieser Kurs durchgeführt?
Praxis, Praxis, Praxis. Es ist ein anwendungsorientierter Kurs, der natürlich auch seine theoretische Fundierung erhält aber immer unter dem Gesichtspunkt, wie kann das theoretische Wissen direkt für die Lösung eines Problems angewandt werden. Es werden Problemlösungsstrategien vermittelt, die dabei helfen sollen verschiedenste Fragestellung in hoher Qualität aufarbeiten zu können.
In wöchentlichen Online-Meetings wird das Wissen durch Vorlesungen vermittelt und in zahlreichen Übungen trainiert. In den kurzen Präsenzzeiten am Anfang und am Ende eines Moduls wird der Einstieg in das Thema gegeben, offene Fragen diskutiert oder abschließend weitere Tipps und Tricks gezeigt. Jedes Modul wird mit einer Prüfung abgeschlossen und bei Bestehen vergibt die Hochschule ein Zertifikat. Für den gesamten Kurs gibt es dann das Hochschulzertifikat „Clinical Data Analyst“.
 Der Zertifikatskurs „Clinical Data Analytics“ umfasst die Auswertung von klinischen Daten aus Informationssystemen im Krankenhaus und anderen medizinischen und pflegerischen Einrichtungen. Prof. Thomas Schrader ist einer der Mitgestalter des Kurses. Weitere Informationen sind stets aktuell auf www.th-brandenburg.de abrufbar.
Der Zertifikatskurs „Clinical Data Analytics“ umfasst die Auswertung von klinischen Daten aus Informationssystemen im Krankenhaus und anderen medizinischen und pflegerischen Einrichtungen. Prof. Thomas Schrader ist einer der Mitgestalter des Kurses. Weitere Informationen sind stets aktuell auf www.th-brandenburg.de abrufbar.