Einführung in WEKA
Waikato Environment for Knowledge Analysis, kurz WEKA, ist ein quelloffenes, umfangreiches, plattformunabhängiges Data Mining Softwarepaket. WEKA ist in Java geschrieben und wurde an der WAIKATO Iniversität entwickelt. In WEKA sind viele wichtige Data Mining/Machine Learning Algorithmen implementiert und es gibt extra Pakete, wie z. B. LibSVM für Support Vector Machines, welches nicht in WEKA direkt implementiert wurde. Alle Einzelheiten zum Installieren und entsprechende Download-Links findet man unter auf der Webseite der Waikato Universität. Zusammen mit der Software wird ein Manual und ein Ordner mit Beispiel-Datensätzen ausgeliefert. WEKA arbeitet mit Datensätzen im sogenannten attribute-relation file format, abgekürzt arff. Das CSV-Format wird aber ebenfalls unterstützt. Eine Datei im arff-Format ist eine ASCI-Textdatei, welche aus einem Header- und einem Datateil besteht. Im Header muss der Name der Relation und der Attribute zusammen mit dem Typ stehen, der Datenteil beginnt mit einem @data-Schlüsselwort. Als Beispiel sei hier ein Datensatz mit zwei Attributen und nur zwei Instanzen gegeben.
|
1 2 3 4 5 6 7 |
@relation my_relation @attribute first_attribute numeric @attribute second_attribute numeric @attribute class {-1,1} @data 2.5 3.8 1 1.2 1.5 -1 |
WEKA unterstützt auch direktes Einlesen von Daten aus einer Datenbank (mit JDBC) oder URL. Sobald das Tool installiert und gestartet ist, landet man im Hauptmenü von WEKA – WEKA GUI Chooser 1.

Abbildung 1: WEKA GUI Chooser
Der GUI Chooser bietet den Einstieg in WEKA Interfaces Explorer, Experimenter, KnowledgeFlow und simple CLI an. Der Explorer ist ein graphisches Interface zum Bearbeiten von Datensätzen, Ausführen von Algorithmen und Visualisieren von den Resultaten. Es ist ratsam, dieses Interface als Erstes zu betrachten, wenn man in WEKA einsteigen möchte. Beispielhaft führen wir jetzt ein paar Algorithmen im Explorer durch.
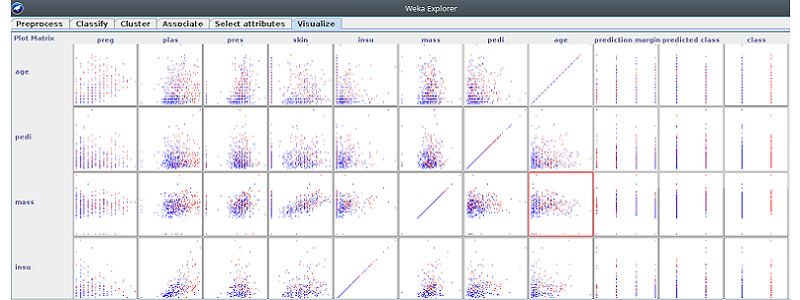
Der Explorer bietet mehrere Tabs an: Preprocess, Classify, Cluster, Associate, Select attributes und Visualize. Im Preprocess Tab hat man die Möglichkeit Datensätze vorzubereiten. Hier sind zahlreiche Filter zum Präprozessieren von Datensätzen enthalten. Alle Filter sind in supervised und unsupervised unterteilt, je nachdem, ob das Klassenattribut mitbetrachtet werden soll oder nicht. Außerdem kann man entweder Attribute oder Instanzen betrachten, mit Attributen lässt man Filter spaltenweise arbeiten und bei Instanzen reihenweise. Die Auswahl der Filter ist groß, man kann den ausgewählten Datensatz diskretisieren, normalisieren, Rauschen hinzufügen etc. Unter Visualize können z. B. die geladenen Datensätze visualisert werden. Mit Select attributes kann man mithilfe von Attribut Evaluator und Search Method ein genaueres Ergebnis erzielen. Wenn man im Preprocess den Datensatz lädt, erhält man einen Überblick über den Datensatz und dessen Visualisierung. Als Beispiel wird hier der Datensatz diabetes.arff genommen, welcher mit WEKA zusammen ausgeliefert wird. Dieser Datensatz enthält 768 Instanzen mit je 9 Attributen, wobei ein Attribut das Klassenattribut ist. Die Attribute enthalten z. B. Informationen über die Anzahl der Schwangerschaften, diastolischer Blutdruck, BMI usw. Alle Attribute, außer dem Klassenattribut, sind numerisch. Es gibt zwei Klassen tested negativ und tested positiv, welche das Resultat des Testens auf diabetes mellitus darstellen. über Preprocess -> Open File lädt man den Datensatz in WEKA und sieht alle relevanten Informationen wie z. B. Anzahl und Name der Attribute. Nach dem Laden kann der Datensatz klassifiziert werden.

Abbildung 2: Diabetes.arff Datensatz geladen in WEKA
Hierzu einfach auf Classify klicken und unter Choose den gewünschten Algorithmus auswählen. Für diesen Datensatz wählen wir jetzt den Algorithmus kNN (k-Nearest Neighbour). Der Algorithmus klassifiziert das Testobjekt anhand der Klassenzugehörigkeit von den k Nachbarobjekten, die am nähsten zu dem Testobjekt liegen. Die Distanz zwischen den Objekten und dem Testobjekt wird mit einer Ähnlichkeitsmetrik bestimmt, meistens als euklidische oder Manhattan-Distanz. In WEKA ist der Algorithmus unter lazy iBk zu finden. Wenn man auf das Feld neben dem Algorithmusnamen in WEKA mit rechter Maustaste klickt, kann man unter show properties die Werte für den ausgewählten Algorithmus ändern, bei iBk kann man u.A. den Wert für k ändern. Für den ausgewählten Datensatz diabetes.arff stellen wir beispielsweise k = 3 ein und führen die 10-fache Kreuzvalidierung durch, indem wir unter Test Options die Cross Validation auswählen. Nach der Klassifikation werden die Ergebnisse in einer Warhheitsmatrix präsentiert. In unserem Fall sieht diese wie folgt aus:
|
1 2 3 |
a b <-- classified as 410 90 | a = tested_negative 120 148 | b = tested_positive |
Die Anzahl der richtig klassifizierten Instanzen beträgt 72.6563 %. Wenn man in der Result list auf den entsprechenden Algorithmus einen Rechtsklick macht, kann man z. B. noch den Fehler der Klassifizierung visualisieren. Entsprechend lassen sich im Explorer unter Cluster Clustering-Algorithmen und unter Associate Assoziationsalgorithmen auf einen ausgewählten Datensatz anwenden. Die restlichen Interfaces von WEKA bieten z. T. die gleiche Funktionalität oder erweitern die Möglichkeiten des Experimentierens, fordern aber mehr Erfahrung und Wissen von dem User. Das Experimenter Interface dient dazu, mehrere Datensätze mit mehreren Algorithmen zu analysieren. Mit diesem Interface kann man groß-skalierte Experimente durchführen. Simple CLI bietet dem User eine Kommandozeile, statt einem graphischen Interface, an.