3D-Visualisierung von Graphen
Die Graphentheorie ist ein wichtiger Teil vieler Methoden und Anwendungsgebiete für Big Data Analytics. Graphen sind mathematisch beschreibbare Strukturen, ohne die im Ingenieurwesen nichts funktionieren würde. Ein Graph besteht aus zwei Knoten (Ecken, engl. Vertex), die über eine Kante (engl. Edge) verbunden sind.
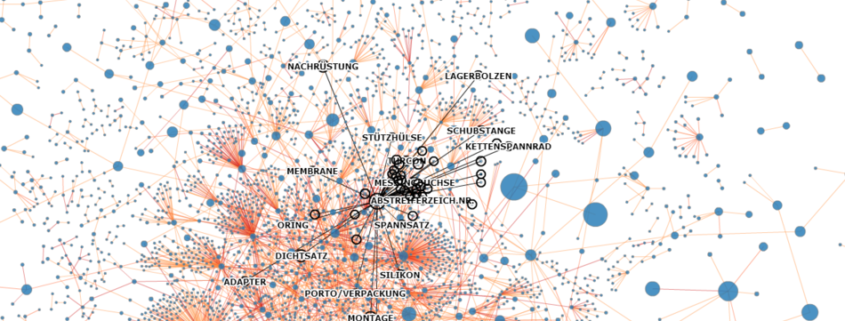
Auf Graphen stoßen Data Scientists beispielsweise bei der Social Media Analyse, beim Aufbau von Empfehlungssystemen (das Amazon-Prinzip) oder auch bei Prozessanalysen (Process Mining). Aber auch einige Big Data Technologien setzen ganz grundlegend auf Graphen, beispielsweise einige NoSQL-Datenbanken wie die Graphendatenbank Neo4j und andere.
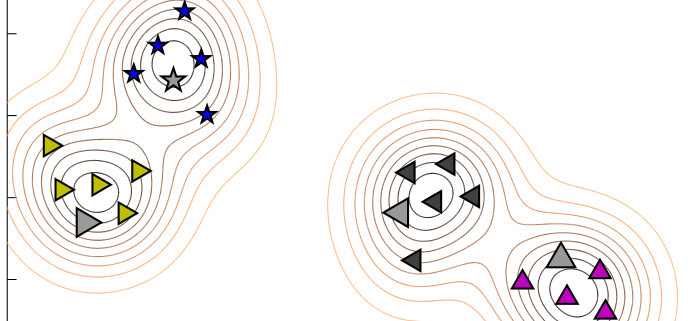
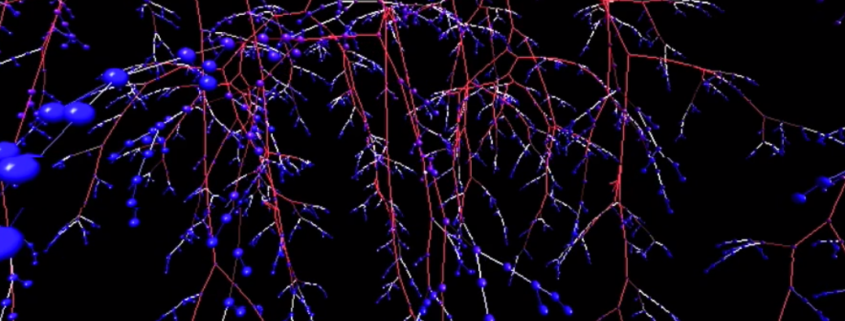
Graphen können nicht nur einfache Verkettungen, sondern komplexe Netzwerke abbilden. Das Schöne daran ist, dass Graphen nicht ganz so abstrakt sind, wie viele andere Bereiche der Mathematik, sondern sich wunderbar visualisieren lassen und wir auch in unserem Vorstellungsvermögen recht gut mit ihnen “arbeiten” können.

Mit der Visualisierung von Graphen, können wir uns Muster vor Augen führen und ein visuelles Data Mining betreiben. Iterative und auch rekursive Vorgänge sowie Abhängigkeiten zwischen einzelnen Objekten/Zuständen können visuell einfach besser verstanden werden. Bei besonders umfangreichen und zugleich vielfältigen Graphen ist eine Visualisierung in drei bzw. vier Dimensionen (x-, y-, z-Dimensionen + Zeit t) nicht nur schöner anzusehen, sondern kann auch sehr dabei helfen, ein Verständnis (z. B. über Graphen-Cluster) zu erhalten. Read more