Interview – Von der Utopie zur Realität der KI: Möglichkeiten und Grenzen
Interview mit Prof. Dr. Sven Buchholz über die Evolution von der Utopie zur Realität der KI – Möglichkeiten und Grenzen
 Prof. Sven Buchholz hat eine Professur für die Fachgebiete Data Management und Data Mining am Fachbereich Informatik und Medien an der TH Brandenburg inne. Er ist wissenschaftlicher Leiter des an der Agentur für wissenschaftliche Weiterbildung und Wissenstransfer – AWW e. V. angesiedelten Projektes „Datenkompetenz 4.0 für eine digitale Arbeitswelt“ und Dozent des Vertiefungskurses „Machine Learning mit Python“, der seit 2018 von der AWW e. V. in Kooperation mit der TH Brandenburg angeboten wird.
Prof. Sven Buchholz hat eine Professur für die Fachgebiete Data Management und Data Mining am Fachbereich Informatik und Medien an der TH Brandenburg inne. Er ist wissenschaftlicher Leiter des an der Agentur für wissenschaftliche Weiterbildung und Wissenstransfer – AWW e. V. angesiedelten Projektes „Datenkompetenz 4.0 für eine digitale Arbeitswelt“ und Dozent des Vertiefungskurses „Machine Learning mit Python“, der seit 2018 von der AWW e. V. in Kooperation mit der TH Brandenburg angeboten wird.
Data Science Blog: Herr Prof. Buchholz, künstliche Intelligenz ist selbst für viele datenaffine Fachkräfte als Begriff noch zu abstrakt und wird mit Filmen wir A.I. von Steven Spielberg oder Terminator assoziiert. Gibt es möglicherweise unterscheidbare Stufen bzw. Reifegrade einer KI?
Für den Reifegrad einer KI könnte man, groß gedacht, ihre kognitiven Leistungen bewerten. Was Kognition angeht, dürfte Hollywood zurzeit aber noch meilenweit führen. Man kann natürlich KIs im selben Einsatzgebiet vergleichen. Wenn von zwei Robotern einer lernt irgendwann problemlos durch die Tür zu fahren und der andere nicht, dann gibt es da schon einen Sieger. Wesentlich ist hier das Lernen, und da geht es dann auch weiter. Kommt er auch durch andere Türen, auch wenn ein Sensor
ausfällt?
Data Science Blog: Künstliche Intelligenz, Machine Learning und Deep Learning sind sicherlich die Trendbegriffe dieser Jahre. Wie stehen sie zueinander?
Deep Learning ist ein Teilgebiet von Machine Learning und das ist wiederum ein Teil von KI. Deep Learning meint eigentlich nur tiefe neuronale Netze (NN). Das sind Netze, die einfach viele Schichten von Neuronen haben und folglich als tief bezeichnet werden. Viele Architekturen, insbesondere auch die oft synonym mit Deep Learning assoziierten sogenannten Convolutional NNs gibt es seit Ewigkeiten. Solche Netze heute einsetzen zu können verdanken wir der Möglichkeit auf Grafikkarten rechnen zu können. Ohne Daten würde das uns aber auch nichts nützen. Netze lernen aus Daten (Beispielen) und es braucht für erfolgreiches Deep Learning sehr viele davon. Was wir oft gerade sehen ist also, was man mit genug vorhandenen Daten „erschlagen“ kann. Machine Learning sind alle Algorithmen, die ein Modell als Ouput liefern. Die Performanz von Modellen ist messbar, womit ich quasi auch noch eine Antwort zur ersten Frage nachreichen will.
Data Science Blog: Sie befassen sich beruflich seit Jahren mit künstlicher Intelligenz. Derzeitige Showcases handeln meistens über die Bild- oder Spracherkennung. Zweifelsohne wichtige Anwendungen, doch für Wirtschaftsunternehmen meistens zu abstrakt und zu weit weg vom Kerngeschäft. Was kann KI für Unternehmen noch leisten?
Scherzhaft oder vielleicht boshaft könnte man sagen, alles was Digitalisierung ihnen versprochen hat.
Wenn sie einen Chat-Bot einsetzen, sollte der durch KI besser werden. Offensichtlich ist das jetzt kein Anwendungsfall, der jedes Unternehmen betrifft. Mit anderen Worten, es hängt vom Kerngeschäft ab. Das klingt jetzt etwas ausweichend, meint aber auch ganz konkret die Ist-Situation.
Welche Prozesse sind jetzt schon datengetrieben, welche Infrastruktur ist vorhanden. Wo ist schon wie optimiert worden? Im Einkauf, im Kundenmanagement und so weiter.
Data Science Blog: Es scheint sich also zu lohnen, in das Thema fachlich einzusteigen. Was braucht man dazu? Welches Wissen sollte als Grundlage vorhanden sein? Und: Braucht man dazu einen Mindest-IQ?
Gewisse mathematische und informatorische Grundlagen braucht man sicher relativ schnell. Zum Beispiel: Wie kann man Daten statistisch beschreiben, was darf man daraus folgern? Wann ist etwas signifikant? Einfache Algorithmen für Standardprobleme sollte man formal hinschreiben können und implementieren können. Welche Komplexität hat der Algorithmus, wo genau versteckt sie sich? Im Prinzip geht es aber erst einmal darum, dass man mit keinem Aspekt von Data Science Bauchschmerzen hat. Einen Mindest-IQ braucht es also nur insofern, um diese Frage für sich selbst beantworten zu können.
Data Science Blog: Gibt es aus Ihrer Sicht eine spezielle Programmiersprache, die sich für das Programmieren einer KI besonders eignet?
Das dürfte für viele Informatiker fast eine Glaubensfrage sein, auch weil es natürlich davon abhängt,
was für eine KI das sein soll. Für Machine Learning und Deep Learning lautet meine Antwort aber ganz klar Python. Ein Blick auf die bestimmenden Frameworks und Programmierschnittstellen ist da
ziemlich eindeutig.
Data Science Blog: Welche Trends im Bereich Machine Learning bzw. Deep Learning werden Ihrer Meinung nach im kommenden Jahr 2019 von Bedeutung werden?
Bei den Deep Learning Anwendungen interessiert mich, wie es mit Sprache weitergeht. Im Bereich Machine Learning denke ich, dass Reinforcement Learning weiter an Bedeutung gewinnt. KI-Chips halte ich für einen der kommenden Trends.
Data Science Blog: Es heißt, dass Data Scientist gerade an ihrer eigenen Arbeitslosigkeit arbeiten, da zukünftige Verfahren des maschinellen Lernens Data Mining selbstständig durchführen können. Werden Tools Data Scientists bald ersetzen?
Die Prognosen für das jährliche Datenwachstum liegen ja momentan so bei 30%. Wichtiger als diese Zahl alleine ist aber, dass dieses Wachstum von Daten kommt, die von Unternehmen generiert werden. Dieser Anteil wird über die nächsten Jahre ständig und rasant weiter wachsen. Nach den einfachen Problemen kommen also erst einmal mehr einfache Probleme und/oder mehr anspruchsvollere Probleme statt Arbeitslosigkeit. Richtig ist aber natürlich, dass Data Scientists zukünftig methodisch mehr oder speziellere Kompetenzen abdecken müssen. Deswegen haben die AWW e. V. und die TH Brandenburg ihr Weiterbildungsangebot um das Modul ‚Machine Learning mit Python‘ ergänzt.
Data Science Blog: Für alle Studenten, die demnächst ihren Bachelor, beispielsweise in Informatik, Mathematik, Ingenieurwesen oder Wirtschaftswissenschaften, abgeschlossen haben, was würden Sie diesen jungen Damen und Herren raten, wie sie gute Data Scientists mit gutem Verständnis für Machine Learning werden können?
Neugierig sein wäre ein Tipp von mir. Im Bereich Deep Learning gibt es ja ständig neue Ideen, neue Netze. Die Implementierungen sind meist verfügbar, also kann und sollte man die Sachen ausprobieren. Je mehr Netze sie selbst zum Laufen gebracht und angewendet haben, umso besser werden sie. Und auch nur so verlieren sie nicht den Anschluss.

 Alice Albrecht is a research engineer at
Alice Albrecht is a research engineer at 



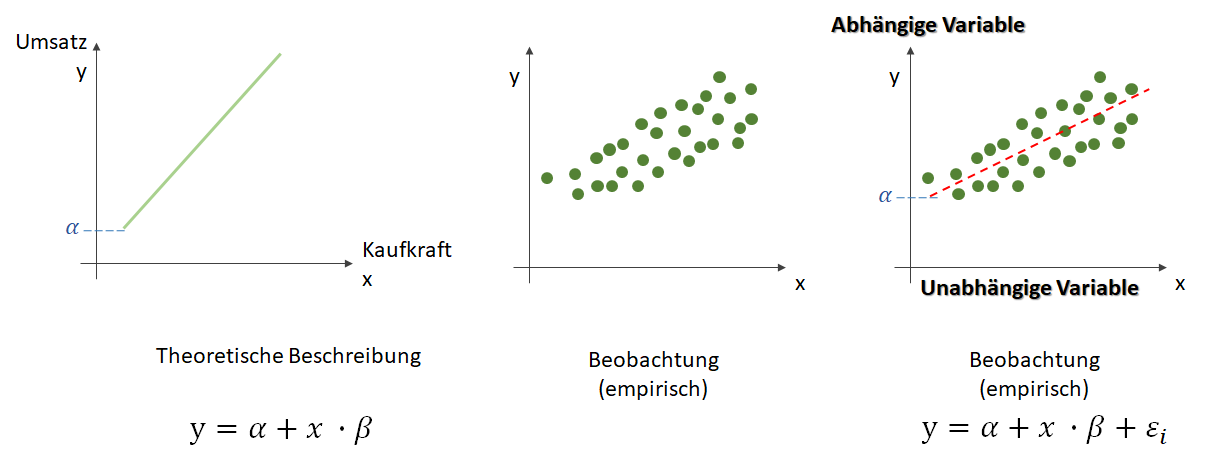
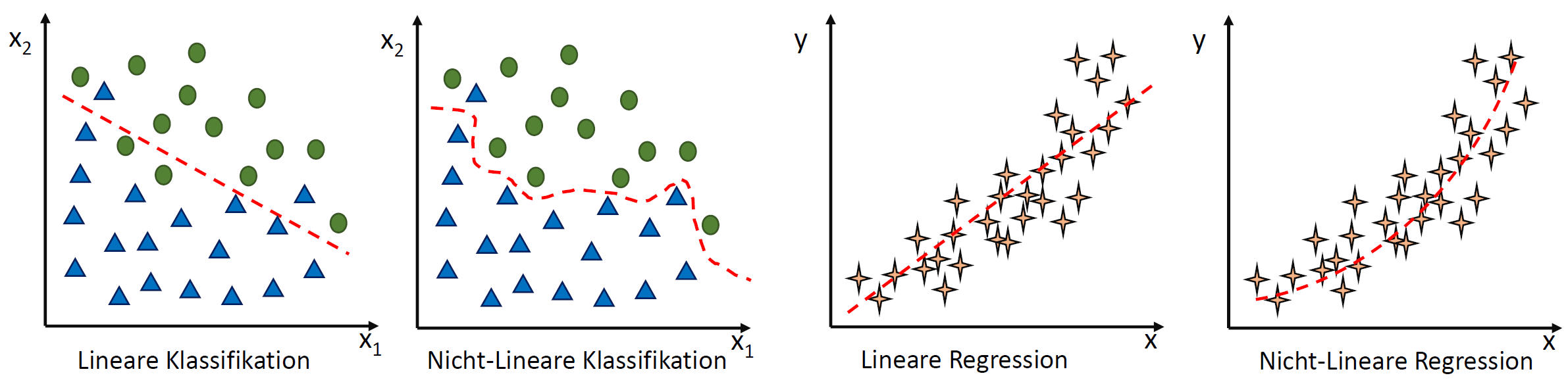
 , die unsere Punktwolke – mit der wir uns zutrauen, Vorhersagen über die abhängige Variable vornehmen zu können – möglichst gut beschreibt. Dabei ist
, die unsere Punktwolke – mit der wir uns zutrauen, Vorhersagen über die abhängige Variable vornehmen zu können – möglichst gut beschreibt. Dabei ist  der Zielwert (abhängige Variable) und
der Zielwert (abhängige Variable) und  der Eingabewert. Wir arbeiten also in einer zwei-dimensionalen Welt. Variablen, die die Funktion mathematisch definieren, werden oft als griechische Buchstaben darsgestellt. Die Variable
der Eingabewert. Wir arbeiten also in einer zwei-dimensionalen Welt. Variablen, die die Funktion mathematisch definieren, werden oft als griechische Buchstaben darsgestellt. Die Variable  (Alpha) ist der
(Alpha) ist der  . Dieser wird als Bias, selten auch als Default-Wert, bezeichnet. Der Bias ist also der Wert, wenn die
. Dieser wird als Bias, selten auch als Default-Wert, bezeichnet. Der Bias ist also der Wert, wenn die  (Beta) beschreibt die Steigung.
(Beta) beschreibt die Steigung. ein Fehler
ein Fehler  existiert. Diesen Fehler wollen wir in diesem Artikel ignorieren.
existiert. Diesen Fehler wollen wir in diesem Artikel ignorieren. statt
statt  ) sind nichts anderes als Gewichtungen zwischen den Eingaben.
) sind nichts anderes als Gewichtungen zwischen den Eingaben.![\[y = w_{0} \cdot x_{0} + w_{1} \cdot x_{1} + \ldots + w_{n} \cdot x_{n}\]](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-19728ae5f9e3065a4c17d50c417e0a8b_l3.png "Rendered by QuickLaTeX.com")
 . Verkürzt ausgedrückt:
. Verkürzt ausgedrückt:![\[y = \sum_{i=0}^n w_{i} \cdot x_{i}\]](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-3bbcbb30d482e7a1fd8da528030d6561_l3.png "Rendered by QuickLaTeX.com")
![\[y = w^T \cdot x\]](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-939f4bae6617db519d13b502d6337ee1_l3.png "Rendered by QuickLaTeX.com")
 .
.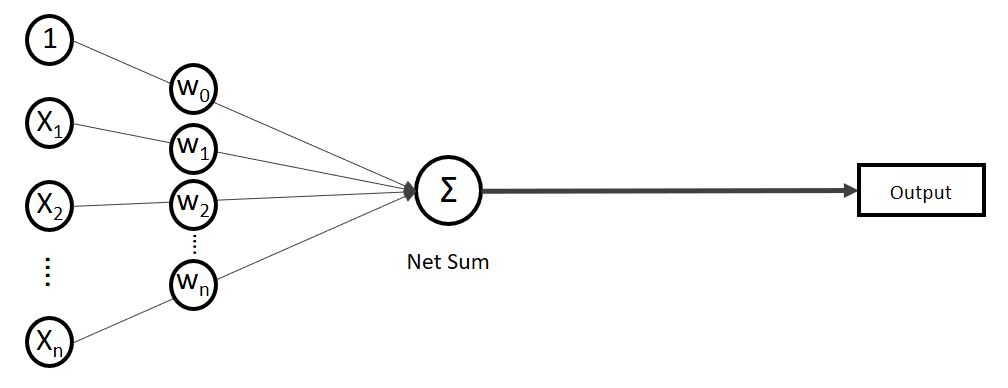
 . Auf der linken Seite finden wir alle Eingabewerte, wobei der erste Wert statisch mit 1.0 belegt ist, nur für den Zweck, den Bias (
. Auf der linken Seite finden wir alle Eingabewerte, wobei der erste Wert statisch mit 1.0 belegt ist, nur für den Zweck, den Bias (
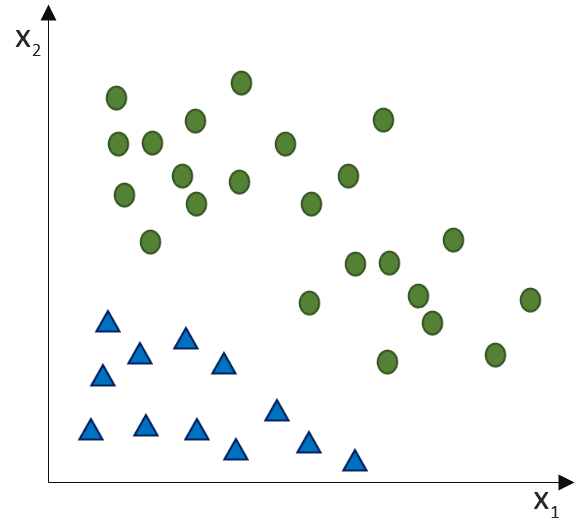
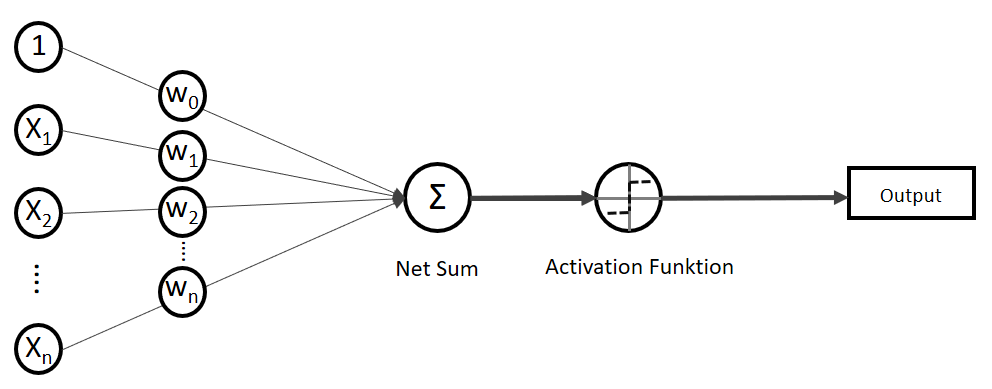
 (Phi), die uns die stetigen Werte der Nettoeingabe in einen binären Wert (z. B. 0 oder 1) umwandelt.
(Phi), die uns die stetigen Werte der Nettoeingabe in einen binären Wert (z. B. 0 oder 1) umwandelt. 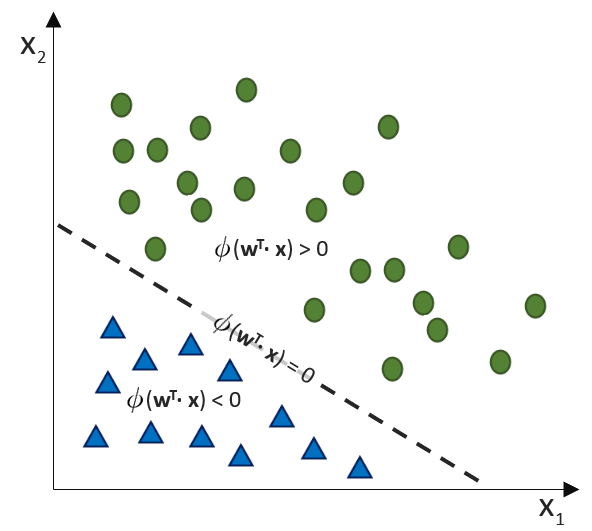
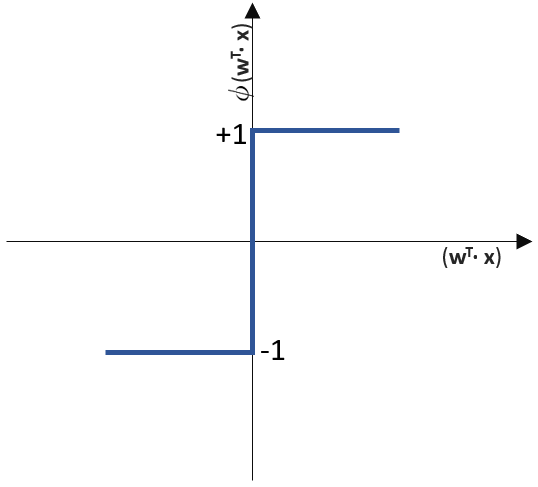
![\[ y = \phi(w^T \cdot x) = \left\{ \begin{array}{12} 1 & w^T \cdot x > 0\\ -1 & \text{otherwise} \end{array} \]](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-7b828cf4bbabf9e1a84ec9b628d51249_l3.png "Rendered by QuickLaTeX.com")

 ) im Sinne des ID3-Algorithmus ist die Differenz aus der Entropie (
) im Sinne des ID3-Algorithmus ist die Differenz aus der Entropie ( ) (siehe Teil 1 der Artikelserie
) (siehe Teil 1 der Artikelserie  ) und der Summe aus den gewichteten Entropien des Attributes für jeden einzelnen Wert (Value
) und der Summe aus den gewichteten Entropien des Attributes für jeden einzelnen Wert (Value  ), der im Attribut vorkommt:
), der im Attribut vorkommt:

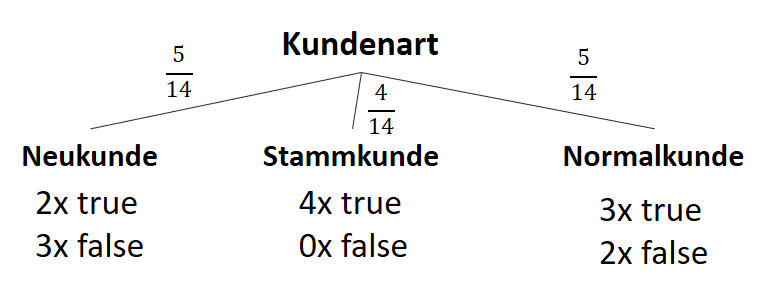



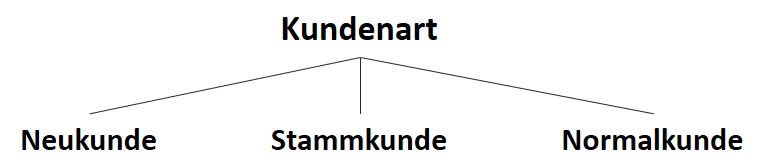
![\[ IG(S, A_{Kundenart}) = - \sum_{i=1}^n \frac{\bigl|S_i\bigl|}{\bigl|S\bigl|} \cdot H(S_i) \]](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-6380891cc61bb855d4208480091fdef0_l3.png "Rendered by QuickLaTeX.com")
![\[ IG(S, A_{Kundenart}) = H(S) - \frac{\bigl|S_{Neukunde}\bigl|}{\bigl|S\bigl|} \cdot H(S_{Neukunde}) - \frac{\bigl|S_{Stammkunde}\bigl|}{\bigl|S\bigl|} \cdot H(S_{Stammkunde}) - \frac{\bigl|S_{Normalkunde}\bigl|}{\bigl|S\bigl|} \cdot H(S_{Normalkunde}) \]](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-b3c9d40c7a171fd7b9e5fbed0aed041a_l3.png "Rendered by QuickLaTeX.com")
![\[ IG(S, A_{Kundenart}) = 0.94 - \frac{5}{14} \cdot 0.97 - \frac{4}{14} \cdot 0.00 - \frac{5}{14} \cdot 0.97 = 0.247 \]](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-33144ba5df6858348666daef5a5cf5d3_l3.png "Rendered by QuickLaTeX.com")
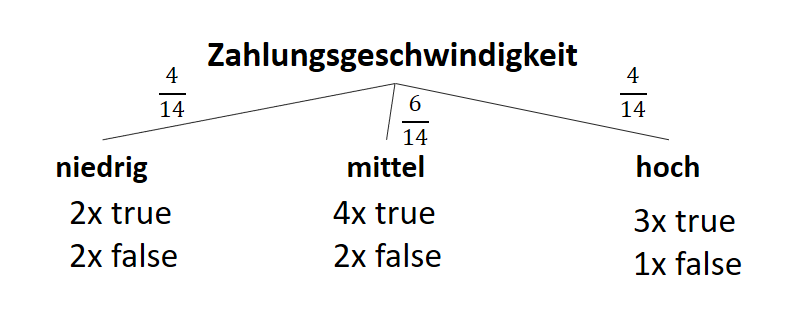



![\[ IG(S, A_{Zahlungsgeschwindigkeit}) = H(S) - \frac{\bigl|S_{niedrig}\bigl|}{\bigl|S\bigl|} \cdot H(S_{niedrig}) - \frac{\bigl|S_{mittel}\bigl|}{\bigl|S\bigl|} \cdot H(S_{mittel}) - \frac{\bigl|S_{schnell}\bigl|}{\bigl|S\bigl|} \cdot H(S_{schnell}) \]](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-a80e61c0adf9dff8ca219a28bce359cd_l3.png "Rendered by QuickLaTeX.com")
![\[ IG(S, A_{Zahlungsgeschwindigkeit}) = 0.94 - \frac{4}{14} \cdot 1.00 - \frac{6}{14} \cdot 0.92 - \frac{4}{14} \cdot 0.81 = 0.029 \]](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-ed4f1d54de66a9956bc2c1e53a0de2e8_l3.png "Rendered by QuickLaTeX.com")



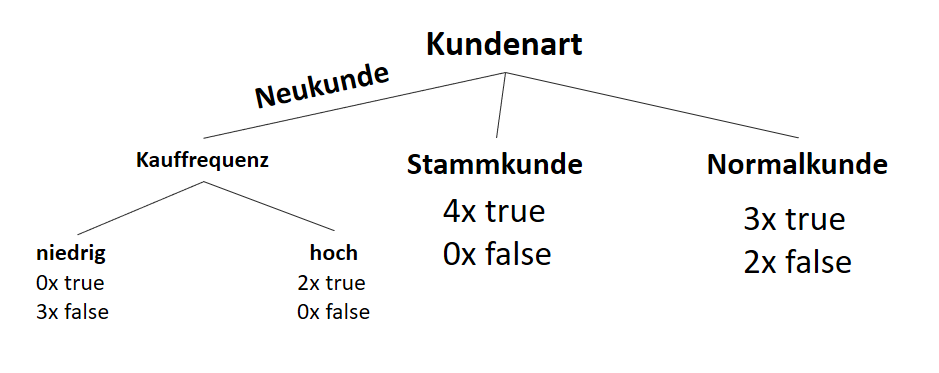
![\[ IG(S, A_{Kauffrequenz}) = H(S) - \frac{\bigl|S_{niedrig}\bigl|}{\bigl|S\bigl|} \cdot H(S_{niedrig}) - \frac{\bigl|S_{hoch}\bigl|}{\bigl|S\bigl|} \cdot H(S_{hoch}) \]](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-cbcfb6a5b118cfc2df4185ef03e4e1dd_l3.png "Rendered by QuickLaTeX.com")
![\[ IG(S, A_{Kauffrequenz}) = 0.94 - \frac{7}{14} \cdot 1.00 - \frac{7}{14} \cdot 0.59 = 0.150 \]](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-dc9f358f2d2cd071b815b3f6c571f813_l3.png "Rendered by QuickLaTeX.com")
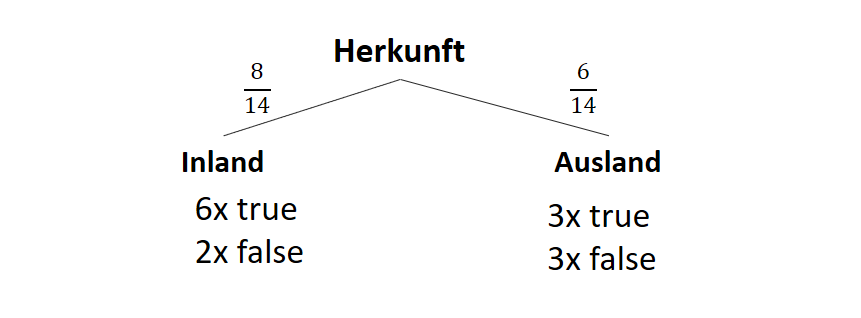


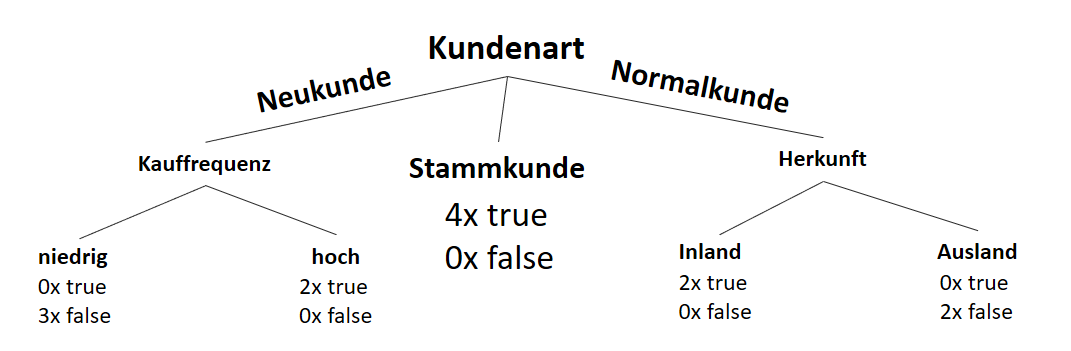
![\[ IG(S, A_{Herkunft}) = H(S) - \frac{\bigl|S_{Inland}\bigl|}{\bigl|S\bigl|} \cdot H(S_{Inland}) - \frac{\bigl|S_{Ausland}\bigl|}{\bigl|S\bigl|} \cdot H(S_{Ausland}) \]](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-3a0ecd4412fa44ca26c64ea16aa536d1_l3.png "Rendered by QuickLaTeX.com")
![\[ IG(S, A_{Herkunft}) = 0.94 - \frac{8}{14} \cdot 0.81 - \frac{6}{14} \cdot 1.00 = 0.05 \]](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-ab4db275a73c092813d00f26ef4c1183_l3.png "Rendered by QuickLaTeX.com")
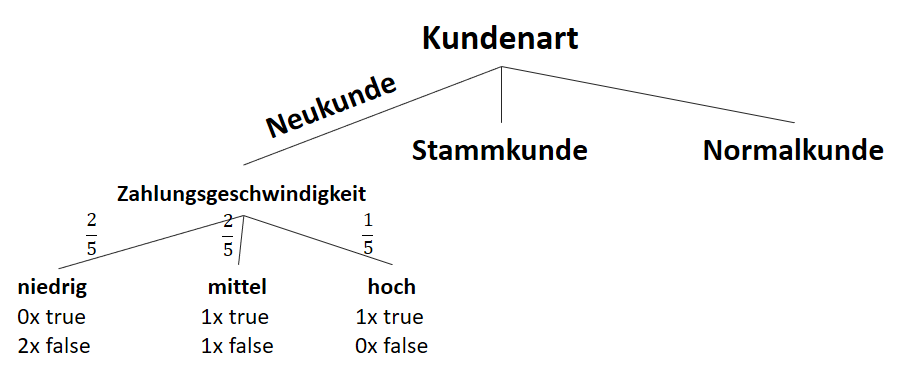



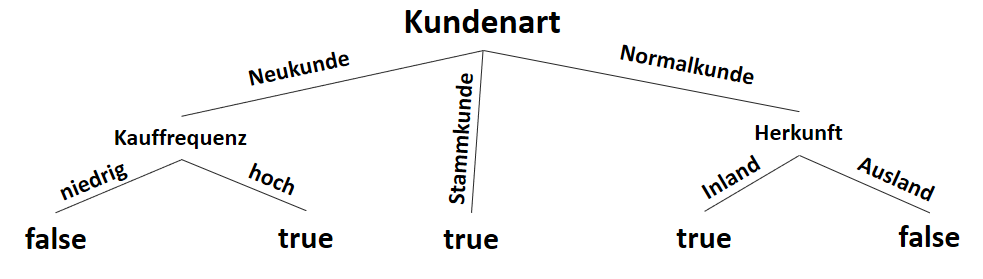
![\[ IG(S_{Neukunde},A_{Zahlungsgeschwindigkeit}) = 0.97 - \frac{3}{5} \cdot 0.00 - \frac{2}{5} \cdot 1.00 - \frac{1}{5} \cdot 0.00 = 0.57 \]](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-35c0216b5e69ee73831980225531ecc7_l3.png "Rendered by QuickLaTeX.com")
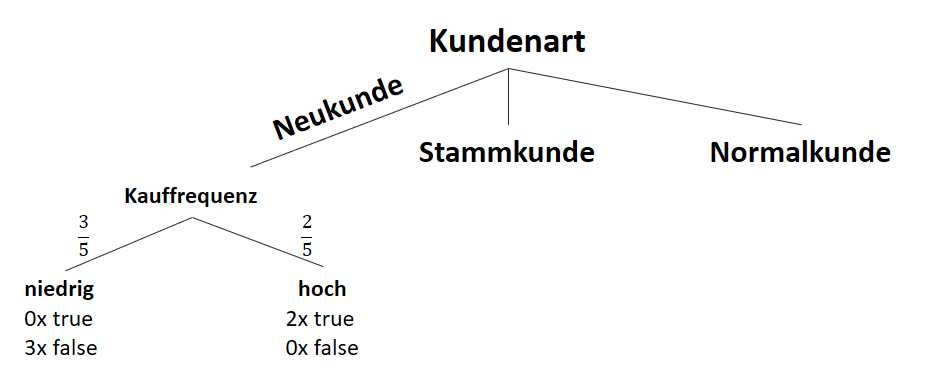
![\[ IG(S_{Neukunde},A_{Kauffrequenz}) = 0.97 - \frac{3}{5} \cdot 0.00 - \frac{2}{5} \cdot 0.00 = 0.97 \]](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-5f6849e7156c9505f53b484a8e7f505a_l3.png "Rendered by QuickLaTeX.com")



![\[ IG(S_{Neukunde},A_{Herkunft}) = 0.97 - \frac{3}{5} \cdot 0.92 - \frac{2}{5} \cdot 1.00 = 0.018 \]](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-890f306c397d0ac28cbbd9a316eb049b_l3.png "Rendered by QuickLaTeX.com")