R als Tool im Process Mining
Die Open Source Sprache R ermöglicht eine Vielzahl von Analysemöglichkeiten, die von einer einfachen beschreibenden Darstellung eines Prozesses bis zur umfassenden statistischen Analyse reicht. Dabei können Daten aus einem Manufacturing Execution System, kurz MES, als Basis der Prozessanalyse herangezogen werden. R ist ein Open Source Programm, welches sich für die Lösung von statischen Aufgaben im Bereich der Prozessoptimierung sehr gut eignet, erfordert jedoch auf Grund des Bedienungskonzepts als Scriptsprache, grundlegende Kenntnisse der Programmierung. Aber auch eine interaktive Bedienung lässt sich mit einer Einbindung der Statistikfunktionen in ein Dashboard erreichen. Damit können entsprechend den Anforderungen, automatisierte Analysen ohne Programmierkenntnisse realisiert werden.
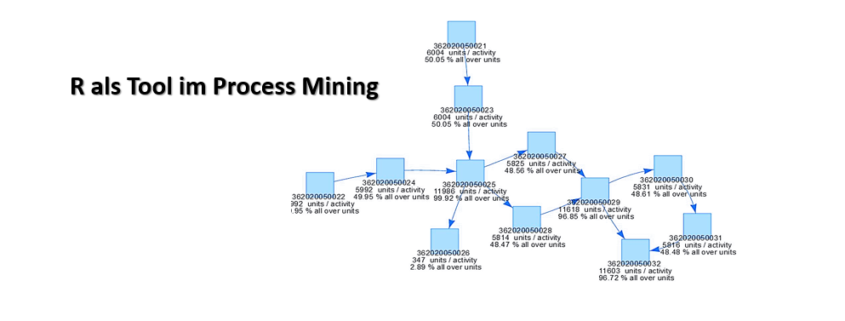
Der Prozess als Spagetti Diagramm
Um einen Überblick zu erhalten, wird der Prozess in einem „process value flowchart“, ähnlich einem Spagetti‐ Diagramm dargestellt und je nach Anforderung mit Angaben zu den Key Performance Indicators ergänzt. Im konkreten Fall werden die absolute Anzahl und der relative Anteil der bearbeiteten Teile angegeben. Werden Teile wie nachfolgend dargestellt, aufgrund von festgestellten Mängel bei der Qualitätskontrolle automatisiert ausgeschleust, können darüber Kennzahlen für den Ausschuss ermittelt werden.
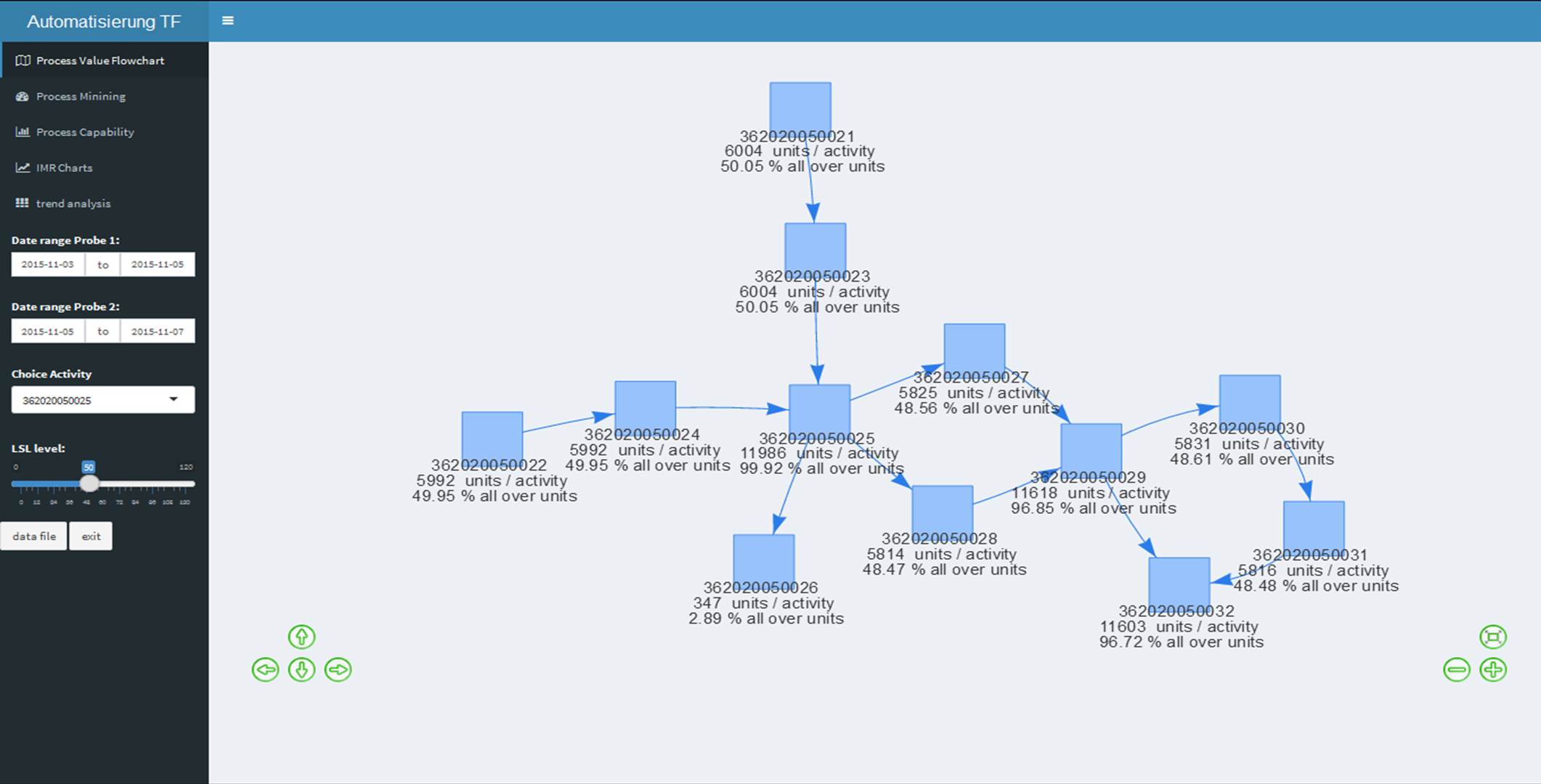
Der Prozess in Tabellen und Diagrammen
Im folgenden Chart sind grundlegende Angaben zu den ausgeführten Prozessschritten, sowie deren Varianten dargestellt. Die Statistikansicht bietet eine Übersicht zu den Fällen, den sogenannte „Cases“, sowie zur Dauer und Taktzeit der einzelnen Aktivitäten. Dabei handelt es sich um eine Fertigungsline mit hohem Automatisierungsgrad, bei der jeder Fertigungsschritt im MES dokumentiert wird. Die Tabelle enthält statistische Angaben zur Zykluszeit, sowie der Prozessdauer zu den einzelnen Aktivitäten. In diesem Fall waren keine Timestamps für das Ende der Aktivität vorhanden, somit konnte die Prozessdauer nicht berechnet werden.
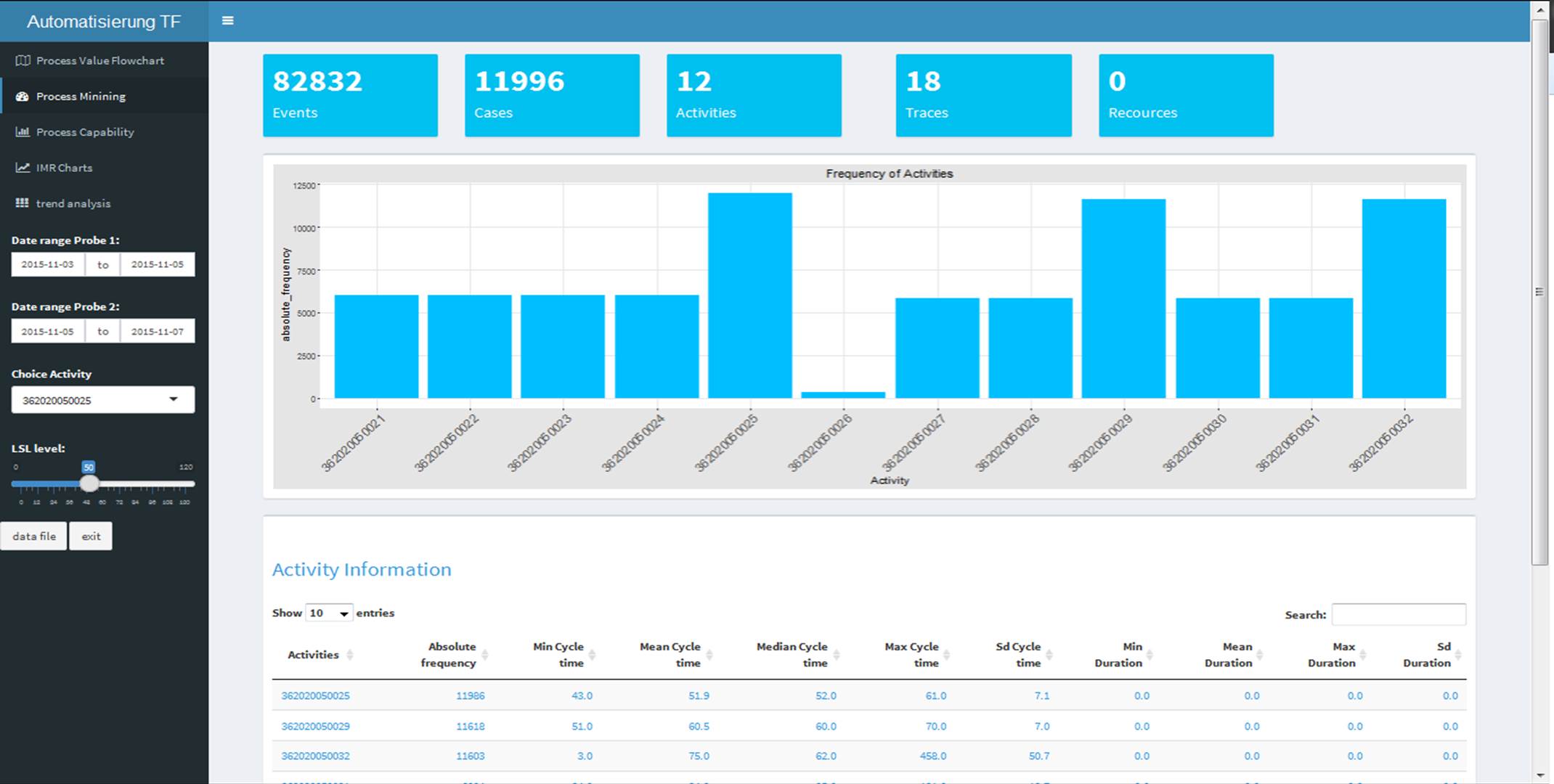
Die Anwendung von Six Sigma Tools
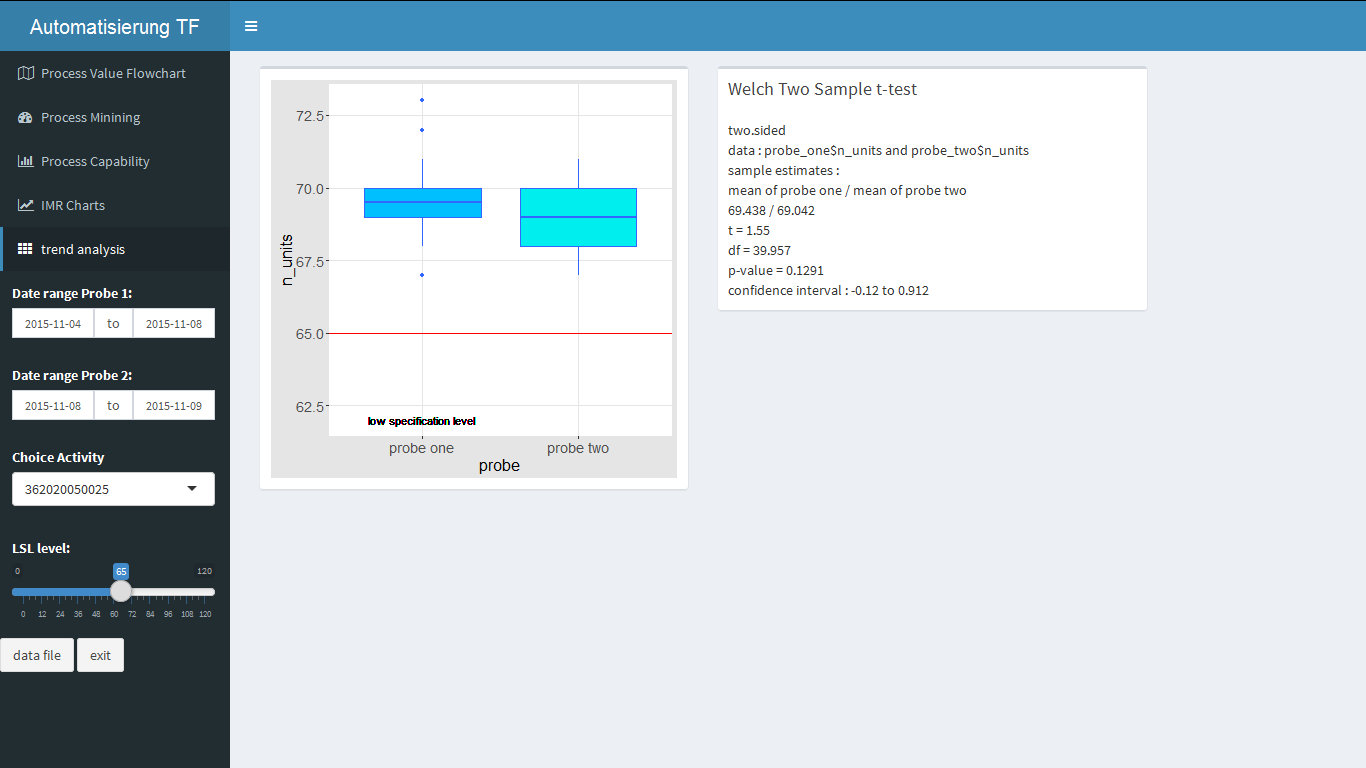
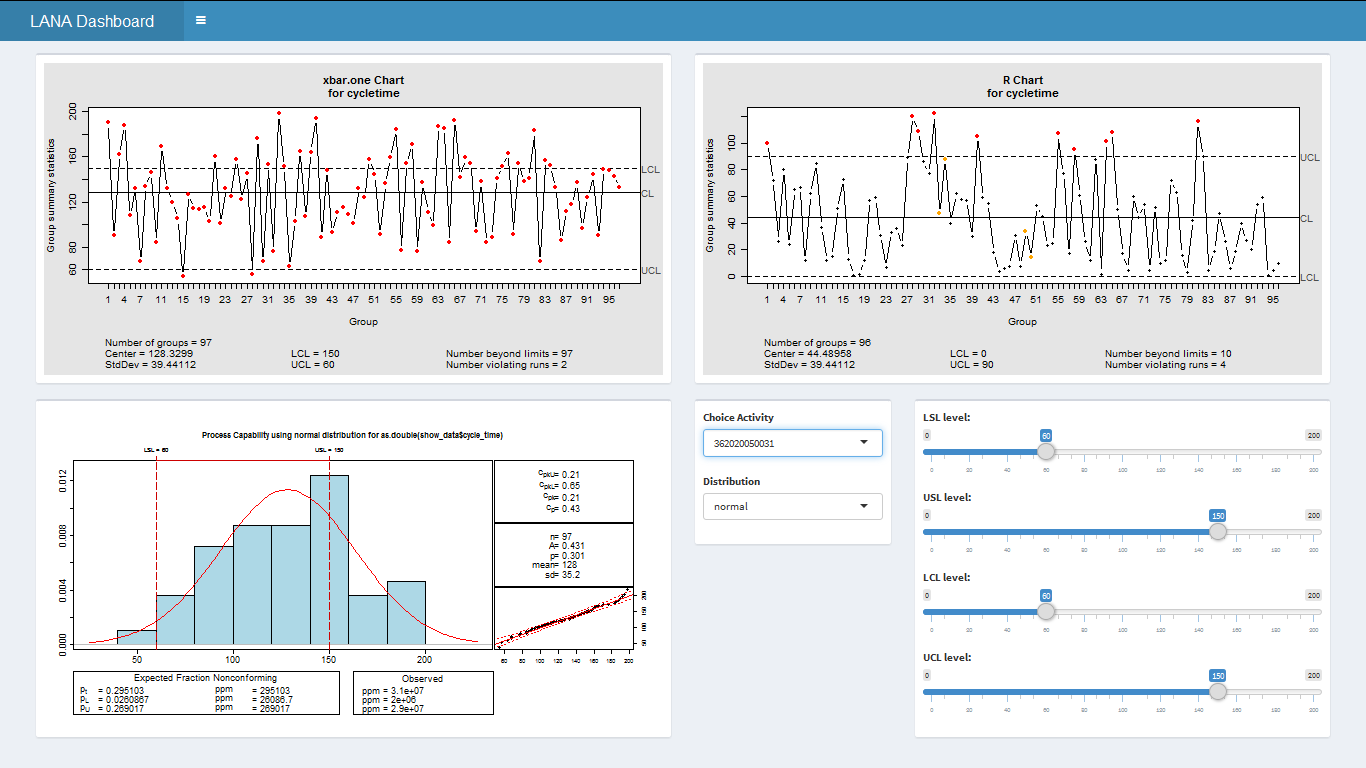
R verfügt über eine umfangreiche Sammlung von Bibliotheken zur Datendarstellung, sowie der Prozessanalyse. Darin sind auch Tools aus Six Sigma enthalten, die für die weitere Analyse der Prozesse eingesetzt werden können. In den folgenden Darstellungen wird die Möglichkeit aufgezeigt, zwei Produktionszeiträume, welche über eine einfache Datumseingabe im Dashboard abgegrenzt werden, gegenüber zu stellen. Dabei handelt es sich um die Ausbringung der Fertigung in Stundenwerten, die für jeden Prozessschritt errechnet wird. Das xbar und r Chart findet im Bereich der Qualitätssicherung häufig Anwendung zur ersten Beurteilung des Prozessoutputs.
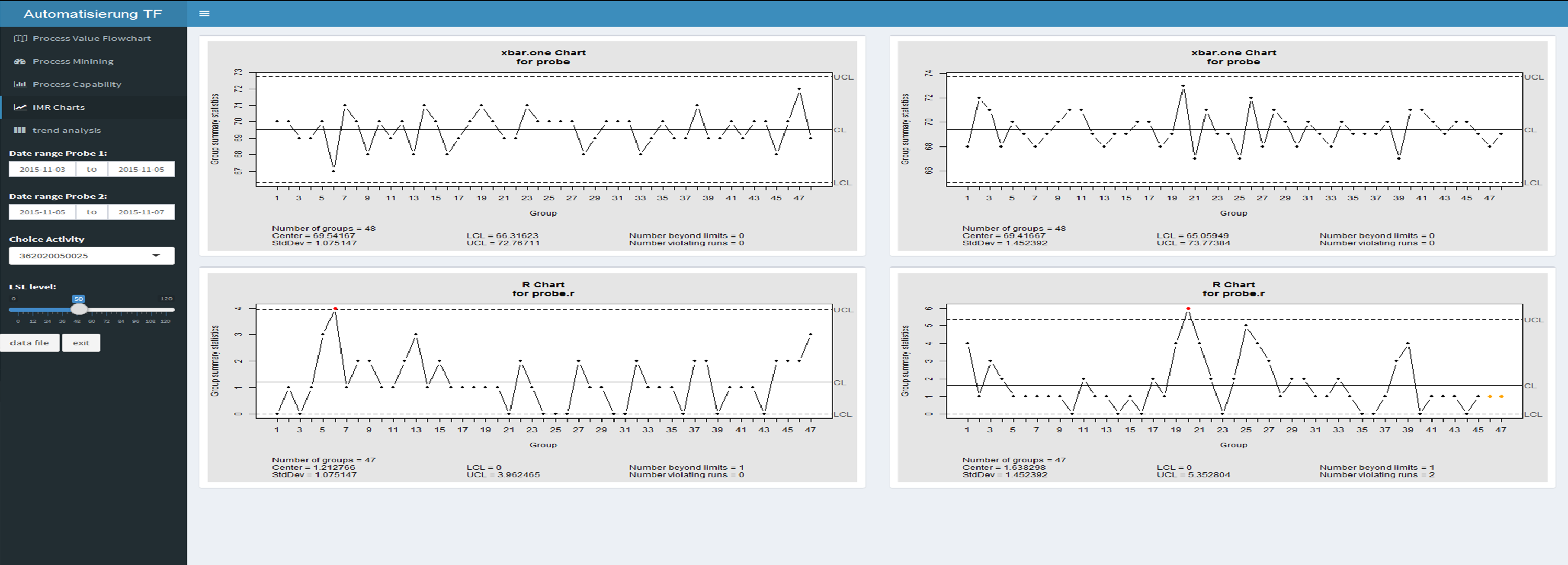
Zwei weitere Six Sigma typische Kennzahlen zur Beurteilung der Prozessfähigkeit sind der Cp und Cpk Wert und deren Ermittlung ein Bestandteil der R Bibliotheken ist. Bei der Berechnung wird von einer Normalverteilung der Daten ausgegangen, wobei das Ergebnis aus der Überprüfung dieser Annahme im Chart durch Zahlen, als auch grafisch dargestellt wird.

Von Interesse ist auch die Antwort auf die Frage, welchem Trend folgt der Prozess? Bereits aus der Darstellung der beiden Produktionszeiträume im Box‐Whiskers‐Plot könnte man anhand der Mediane auf einen Trend zu einer Verschlechterung der Ausbringung schließen, den der Interquartilsabstand nicht widerspiegelt. Eine weitere Absicherung einer Aussage über den Trend, kann über einen statistischen Vergleichs der Mittelwerte erfolgen.
Der Modellvergleich
Besteht die Anforderung einer direkten Gegenüberstellung des geplanten, mit dem vorgefundenen, sogenannten „Discovered Model“, ist aufgrund der Komplexität beim Modellvergleich, dieser in R mit hohem Programmieraufwand verbunden. Besser geeignet sind dafür spezielle Process Miningtools. Diese ermöglichen den direkten Vergleich und unterstützen bei der Analyse der Ursachen zu den dargestellten Abweichungen. Bei Produktionsprozessen handelt es sich meist um sogenannte „Milestone Events“, die bei jedem Fertigungsschritt durch das MES dokumentiert werden und eine einfache Modellierung des Target Process ermöglichen. Weiterführende Analysen der Prozessdaten in R sind durch einen direkten Zugriff über ein API realisierbar oder es wurde vollständig integriert. Damit eröffnen sich wiederum die umfangreichen Möglichkeiten bei der statistischen Prozessanalyse, sowie der Einsatz von Six Sigma Tools aus dem Qualitätsmanagement. Die Analyse kann durch eine, den Kundenanforderungen entsprechende Darstellung in einem Dashboard vereinfacht werden, ermöglicht somit eine zeitnahe, weitgehend automatisierte Prozessanalyse auf Basis der Produktionsdaten.
Resümee
Process Mining in R ermöglicht zeitnahe Ergebnisse, die bis zur automatisierten Analyse in Echtzeit reicht. Der Einsatz beschleunigt erheblich das Process Controlling und hilft den Ressourceneinsatz bei der Datenerhebung, sowie deren Analyse zu reduzieren. Es kann als stand‐alone Lösung zur Untersuchung des „Discovered Process“ oder als Erweiterung für nachfolgende statistische Analysen eingesetzt werden. Als stand‐alone Lösung eignet es sich für Prozesse mit geringer Komplexität, wie in der automatisierten Fertigung. Besteht eine hohe Diversifikation oder sollen standortübergreifende Prozessanalysen durchgeführt werden, übersteigt der Ressourcenaufwand rasch die Kosten für den Einsatz einer Enterprise Software, von denen mittlerweile einige angeboten werden.

 Herr Dr. Florian Neukart ist Principal Data Scientist der
Herr Dr. Florian Neukart ist Principal Data Scientist der