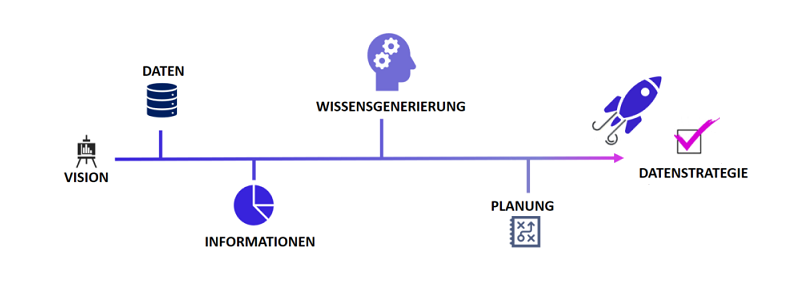
Die fünf Schritte zur Datenstrategie
Big Data ist allgegenwärtig – die Datenrevolution bietet in nahezu allen Branchen vielfältige Nutzungsmöglichkeiten. Bevor Sie jedoch investieren, sollten Sie sehr sorgfältig analysieren, welche Strategie auf Ihr Unternehmen exakt zugeschnitten ist: Ihre Datenstrategie.
Der Artikel Unternehmen brauchen eine Datenstrategie erläutert, wozu Unternehmen eine Datenstrategie erarbeiten sollten, dieser Artikel skizziert eine erprobte Vorgehensweise dafür. Diese Vorgehensweise basiert auf der Strategiearbeit unseres Teams, erhebt jedoch keinen Anspruch auf Vollständigkeit. Das überlegte Ausformulieren einer Datenstrategie ist eine individuelle Arbeit und so fällt es vielen Führungskräften und Mitarbeitern schwer, hierfür eine strukturierte Vorgehensweise zu finden.
Data Driven Thinking spielt bei der Formulierung der Datenstrategie eine wesentliche Rolle: Es ist die, an das Design Thinking angelehnte, Denkweise, Daten zu nutzen, um Fragen zu beantworten und damit verbundene Probleme zu lösen. Geübten Data Thinkern fällt das Durchdenken einer Datenstrategie relativ leicht. Für gedankliche Neueinsteiger in dieses Thema soll die folgende Vorgehensweise eine Hilfe bieten, denn aus meiner Erfahrung zeigten sich bisher folgende fünf Schritte als besonders erfolgskritisch. Diese Schritte sind einer Reihenfolge von der Vision bis zur Datenstrategie vorgegeben, mit dem Ziel, anfänglich ein Bewusstsein dafür zu schaffen, welche Datenquellen zur Verfügung stehen und welche Art von Daten in denen enthalten sind.
Die fünf Schritte zur Datenstrategie
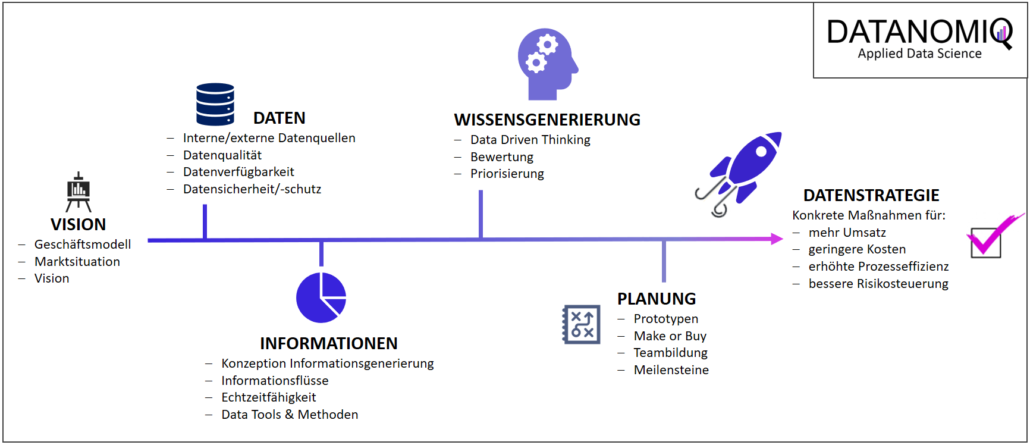
1. Die Vision [Kick-Off]
Jedes Unternehmen benötigt eine individuelle Datenstrategie, die auf die spezielle Ausgangssituation und den gesetzten Unternehmenszielen zugeschnitten ist. Jede Datenstrategie hat eine klare Standortbestimmung und verfolgt oder unterstützt eine bestimmte Vision für das Unternehmen, an der die zu erstellende Datenstrategie auszurichten ist. Der Kick-Off zur Datenstrategie geht u.a. folgenden Fragen nach: Wie sieht die Marktsituation aus? Wie genau funktionieren die Geschäftsmodelle und welche Vision sehen die involvierten Mitarbeiter für ihr Unternehmen?
2. Die Datenquellen
Zum Data Driven Thinking gehört es, Daten zu finden, die Antworten auf Ihre Fragen liefern. Ebenso funktioniert es, vorhandene Daten zu betrachten und daraus Lösungsideen zu entwickeln. Eine Grundvoraussetzung für die Beantwortung von Fragen mit Daten ist es, dass alle verfügbaren Datenquellen gut dokumentiert wurden und die Mitarbeiter Kenntnis sowohl über die Datenquellen als auch über deren Dokumentation haben. Ist das nicht der Fall, ist dies der erste wichtige Schritt zur Erstellung einer Datenstrategie.
Dafür brauchen Sie Ihre IT-Administratoren, einen guten Data Engineer (Was ist ein Data Engineer? Und was ein Data Scientist?) und Ihre, für die Datenstrategie abgestellten Mitarbeiter aus den Fachbereichen.
Das Ergebnis ist die Gewissheit, über welche Daten Sie bereits verfügen und über welche Sie verfügen könnten, würden Sie es wünschen. Zudem werden mit den Datenquellen verbundene Fragen geklärt: Wie sieht es mit der Datensicherheit und dem Datenschutz aus? Nur so betrachten Sie Ihre Datenpotenziale in den weiteren Schritten ganzheitlich und rechtssicher.
3. Die Konzeptionierung der Informationsgewinnung
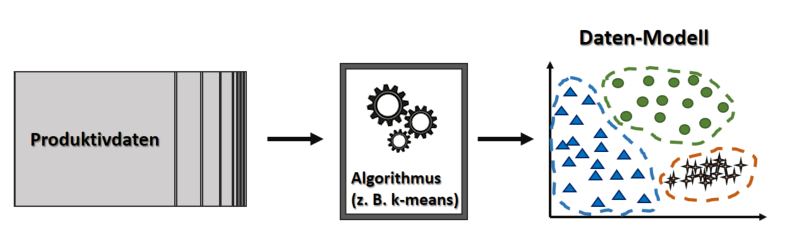
Sowohl in der Informatik als auch in der Managementlehre ist bekannt, dass aus Daten Informationen werden, wenn die einzelnen Datenpunkte miteinander verknüpft werden. Dennoch hapert es bei den meisten Unternehmen gerade an dieser Stelle. Bisher werden gerade einmal 1% aller Daten genutzt. Daten zu nutzen bedeutet dabei konkret, diese in Informationsflüsse umzuwandeln. Der Schritt der Konzeptionierung der Informationsgewinnung ist ein Ideenprozess darüber, wie – je nach Detailgrad – ganze Datenquellen oder auch nur einzelne Datentabellen innerhalb von Datenbanken miteinander verknüpft werden können – so wie es bisher noch nicht der Fall ist. Es ist ein gedanklicher Prozess des Data Engineering, mit der Fragestellung: Welche Informationsflüsse haben wir bereits und welche Datenquellen erschaffen neue Informationsflüsse (ggf. wenn sie miteinander verknüpft werden)?
Dafür brauchen Sie Ihre Mitarbeiter aus den Fachbereichen, den Data Engineer und idealerweise ab diesen Schritt einen Data Scientist.
Das Ergebnis ist eine Beschreibung der neuen Informationsgewinnung durch Zugriff auf bestimmte Daten.
4. Die Konzeptionierung der Wissensgenerierung
Werden Informationen in einem bestimmten Kontext betrachtet, entsteht Wissen. Im Kontext der Geschäftssitutation Ihres Unternehmens entsteht für Ihr Geschäft relevantes Wissen. In diesem Schritt der Erstellung Ihrer Datenstrategie wird beleuchtet, welche Informationen zur Wissensgenerierung von besonderem Interesse sein könnten und welches Wissen Sie über welche Informationen generieren.
Dafür brauchen Sie Ihren Data Scientist und Ihre Mitarbeiter aus den Fachbereichen
Als Ergebnis werden Analyseverfahren beschrieben, die die Generierung eines gewünschten Wissens (z. B. über Ihre Kunden, Lieferanten, Produkte oder besondere Ereignisse) wahrscheinlich machen (Data Mining) bis hin zur Errichtung eines Assistenzsystems (datengestützte Entscheidungsfindung) oder eines autonomen Systems (datengetriebene Entscheidungsfindung).
Übrigens: Data Driven Thinking ermöglicht Ihnen, bisher als nahezu unlösbar betrachtete Probleme doch noch zu lösen. Diese datengetriebene Denkweise wird für Führungskräfte der Zukunft unverzichtbar und gilt gegenwärtig als Karriere-Turbo in Richtung Führungsetage.
5. Die Planung der Umsetzung
Nachdem nun ein Bewusstsein dafür entstanden ist, welche Daten zur Verfügung stehen, wie aus ihnen Informationen erschaffen und Geschäftswissen zu generieren ist, kommt nun die Frage auf, wie dieses Gedankenkonstrukt in die Realität umzusetzen ist. Für die Umsetzung sind nun eine Menge Fragen zu klären, wie beispielsweise: Welche Tools sollen verwendet werden? Welches Team (Skillset) wird benötigt? Sollen Lösungen eingekauft oder selbst realisiert werden?
Dafür brauchen Sie Ihre Mitarbeiter aus den Fachbereichen, Ihren Data Scientist (Data Mining, Machine Learning) sowie – wenn Sie die Wissensgenerierung automatisieren möchten – erfahrene Software Entwickler.
Als Ergebnis erhalten Sie einen Plan, wie Ihre Datenstrategie technisch realisiert werden soll.
6. Die Datenstrategie [Resultat]
Nachdem Sie alle Fragen von der Vision bis zur konkreten Umsetzungsplanung beantwortet haben, fehlt nur noch die Ausformulierung Ihrer Ideen, Konzepte und der zu erwartenden Ergebnisse für jeden verständlich als ein Dokument namens Datenstrategie. Diese Datenstrategie soll Ihren Plan transparent machen und ist die Grundlage dafür, Ihre Mitarbeiter, Partner und letztendlich auch Ihre Vorgesetzten von Ihrer Strategie zu überzeugen.
 Mein Vortrag zur Datenstrategie am Data Leader Day 2017
Mein Vortrag zur Datenstrategie am Data Leader Day 2017
Am Data Leader Day am 09. November 2017 in Berlin erläutere ich als Keynote “Wie Sie für Ihr Unternehmen die richtige Datenstrategie entwickeln!”
Führungskräfte von Unternehmen wie Otto, Allianz, Deutsche Bahn und SAP ergänzen mit ihren eigenen Erfahrungen hinsichtlich Big Data Projekten zur Geschäftsoptimierung. Jetzt hier Tickets sichern und dabei sein!

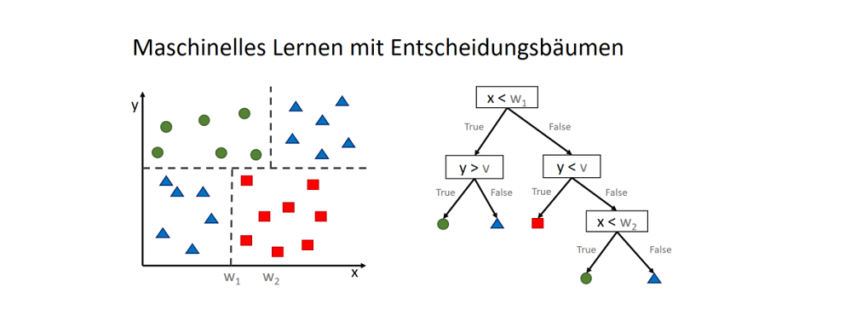
 ) im Sinne des ID3-Algorithmus ist die Differenz aus der Entropie (
) im Sinne des ID3-Algorithmus ist die Differenz aus der Entropie ( ) (siehe Teil 1 der Artikelserie:
) (siehe Teil 1 der Artikelserie:  ) und der Summe aus den gewichteten Entropien des Attributes für jeden einzelnen Wert (Value
) und der Summe aus den gewichteten Entropien des Attributes für jeden einzelnen Wert (Value  ), der im Attribut vorkommt:
), der im Attribut vorkommt:



 Read this article in German:
Read this article in German: