Bias and Variance in Machine Learning
Machine learning continues to be an ever more vital component of our lives and ecosystem, whether we’re applying the techniques to answer research or business problems or in some cases even predicting the future. Machine learning models need to give accurate predictions in order to create real value for a given industry or domain.
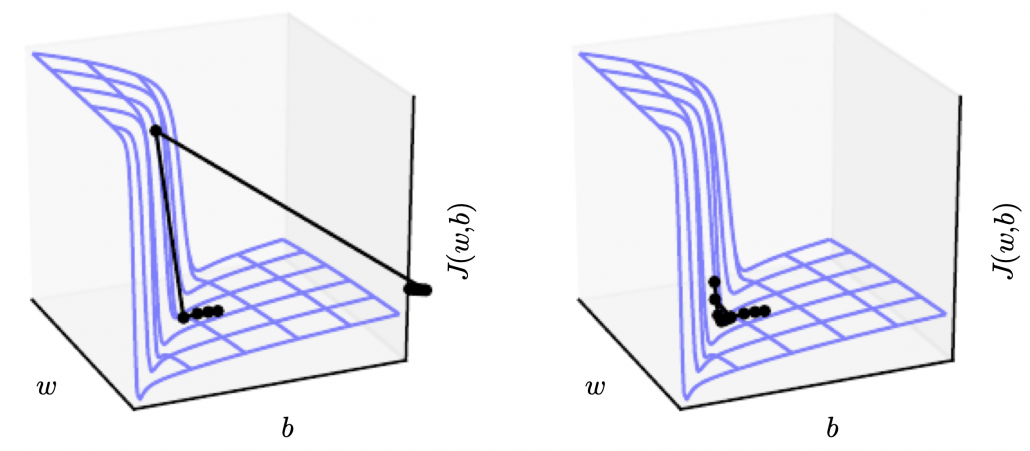
While training a model is one of the key steps in the Data Science Project Life Cycle, how the model generalizes on unseen data is an equally important aspect that should be considered in every Data Science Project Life Cycle. We need to know whether it works and, consequently, if we can trust its predictions. Could the model be merely memorizing the data it is fed with, and therefore unable to make good predictions on future samples, or samples that it hasn’t seen before?
Let’s know the importance of evaluation with a simple example, There are two student’s Ramesh and Suresh preparing for the CAT exam to get into top IIMs (Indian Institute of Management). They both are quite good friends and stayed in the room during preparation and put an equal amount of hard work while solving numerical problems.
They both prepared for almost the same number of hours for the entire year and appeared in the final CAT exam. Surprisingly, Ramesh cleared, but Suresh did not. When asked, we got to know that there was one difference in their strategy of preparation between them, Ramesh had joined a Test Series course where he used to test his knowledge and understanding by giving mock exams and then further evaluating on which portions he is lagging and making necessary adjustments to he is preparation cycle in order to do well in those areas. But Suresh was confident, and he just kept training himself without testing on the preparation he had done.
Like the above situation we can train a Machine Learning Algorithm extensively with many parameters and new techniques, but if you are skipping its evaluation step, you cannot trust your model to perform well on the unseen data. In this article, we explain the importance of Bias, Variance and the trade-off between them in order to know how well a machine learning model generalizes to new, previously unseen data.
Bias
Bias is the difference between the Predicted Value and the Expected Value or how far are the predicted values from the actual values. During the training process the model makes certain assumptions on the training data provided. After Training, when it is introduced to the testing/validation data or unseen data, these assumptions may not always be correct.
If we use a large number of nearest neighbors in the K-Nearest Neighbors Algorithm, the model can totally decide that some parameters are not important at all for the modelling. For example, it can just consider that only two predictor variables are enough to classify the data point though we have more than 10 variables.
This type of model will make very strong assumptions about the other parameters not affecting the outcome at all. You can take it as a model predicting or understanding only the simple relationship when the data points clearly indicate a more complex relationship.
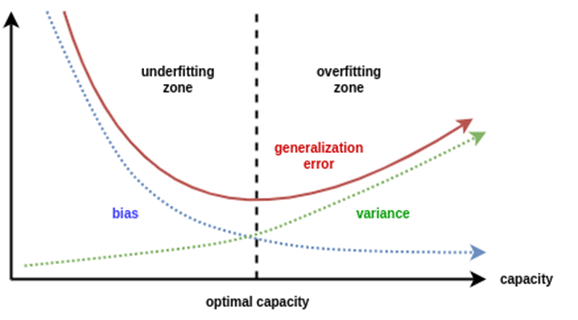
When the model has high bias error, it results in a very simplistic model that does not consider the complexity of the data very well leading to Underfitting.
Variance
Variance occurs when the model performs well on the trained dataset but does not do well on an unseen data set, it is when the model considers the fluctuations or i.e. the noise as in the data as well. The model will still consider the variance as something to learn from because it learns too much from the noise inside the trained data set that it fails to perform as expected on the unseen data.
Based on the above example from Bias, if the model learns that all the ten predictor variables are important to classify a given data point then it tends to have high variance. You can take it as the model is trying to understand every minute detail making it more complex and failing to perform well on the unseen data.
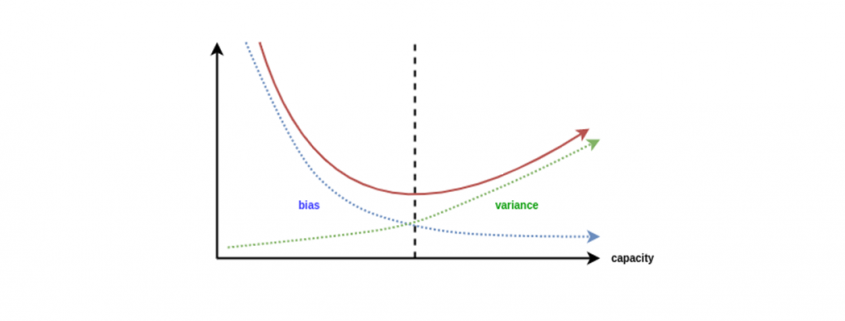
When a model has High Bias error, it underfits the data and makes very simplistic assumptions on it. When a model has High Variance error, it overfits the data and learns too much from it. When a model has balanced Bias and Variance errors, it performs well on the unseen data.
Bias-Variance Trade-off
Based on the definitions of bias and variance, there is clear trade-off between bias and variance when it comes to the performance of the model. A model will have a high error if it has very high bias and low variance and have a high error if it has high variance and low bias.
A model that strikes a balance between the bias and variance can minimize the error better than those that live on extreme ends.
We can find whether the model has High Bias using the below steps:
- We tend to get high training errors.
- The validation error or test error will be similar to the training error.
We can find whether the model has High Bias using the below steps:
- We tend to get low training error
- The validation error or test error will be very high.
We can fix the High Bias using below steps:
- We need to gather more input features or can even try to create few using the feature engineering techniques.
- We can even add few polynomial features in order to increase the complexity.
- If we are using any regularization terms in our model, we can try to minimize it.
We can fix the High Variance using below steps:
- We can gather more training data so that the model can learn more on the patterns rather than the noise.
- We can even try to reduce the input features or do feature selection.
- If we are using any regularization terms in our model we can try to maximize it.
Conclusion
In this article, we got to know the importance of the evaluation step in the Data Science Project Life Cycle, definitions of Bias and Variance, the trade-off between them and the steps we can take to fix the Underfitting and Overfitting of a Machine Learning Model.

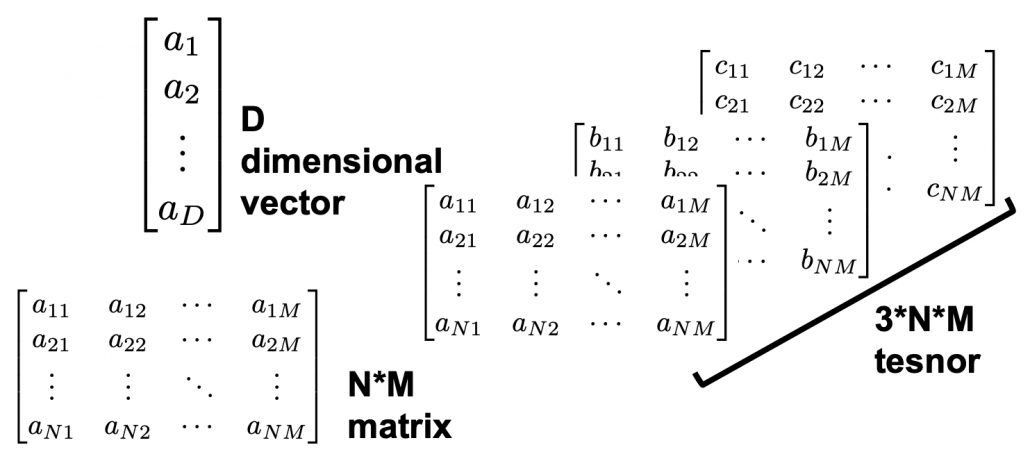
 be a vector space and let
be a vector space and let  be a mapping of
be a mapping of  into itself, defined as
into itself, defined as  , where
, where  is a
is a  matrix and
matrix and  is
is  dimensional vector. An element
dimensional vector. An element  is called an eigen vector if there exists a number
is called an eigen vector if there exists a number  such that
such that  and
and  . In this case
. In this case  , belonging to
, belonging to  . If
. If  is basis of the vector space
is basis of the vector space  matrices
matrices  , whose column vectors are eigen vectors
, whose column vectors are eigen vectors  , where
, where  .
. Most textbooks keep explaining these type of stuff, but I have to say they lack efforts to make it understandable to readers with low mathematical literacy like me. Especially if you have to apply the idea to data science field, I believe you need more visual understanding of diagonalization. Therefore instead of just explaining the definitions and theorems, I would like to take a different approach. But in order to understand them in more intuitive ways, we first have to rethink waht linear transformation
Most textbooks keep explaining these type of stuff, but I have to say they lack efforts to make it understandable to readers with low mathematical literacy like me. Especially if you have to apply the idea to data science field, I believe you need more visual understanding of diagonalization. Therefore instead of just explaining the definitions and theorems, I would like to take a different approach. But in order to understand them in more intuitive ways, we first have to rethink waht linear transformation  means in more visible ways.
means in more visible ways. is a vector transformed by
is a vector transformed by  *I am not going to use the term “linear transformation” in a precise way in the context of linear algebra. In this article or in the context of data science or machine learning, “linear transformation” for the most part means products of matrices or vectors.
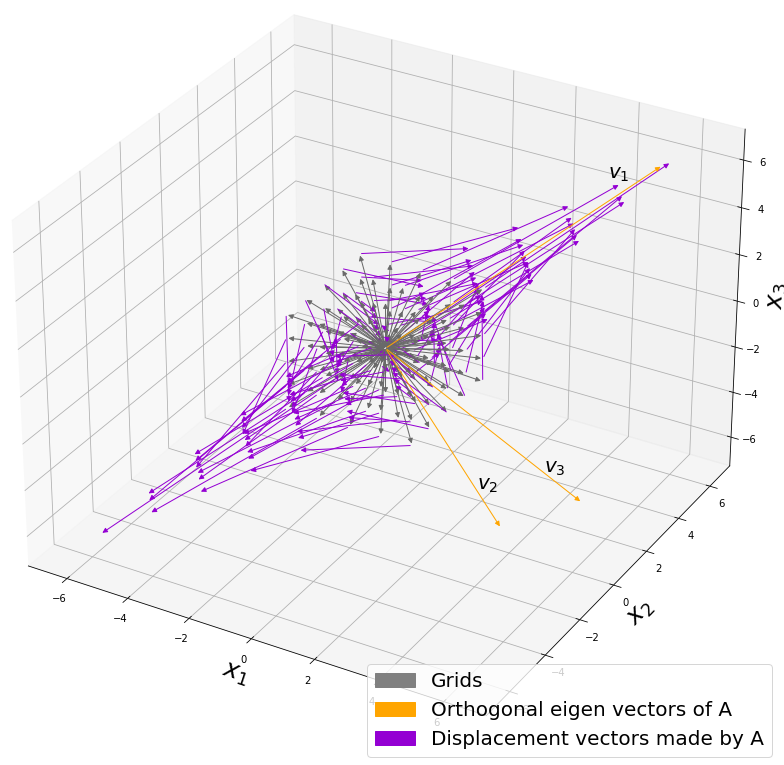
*I am not going to use the term “linear transformation” in a precise way in the context of linear algebra. In this article or in the context of data science or machine learning, “linear transformation” for the most part means products of matrices or vectors. 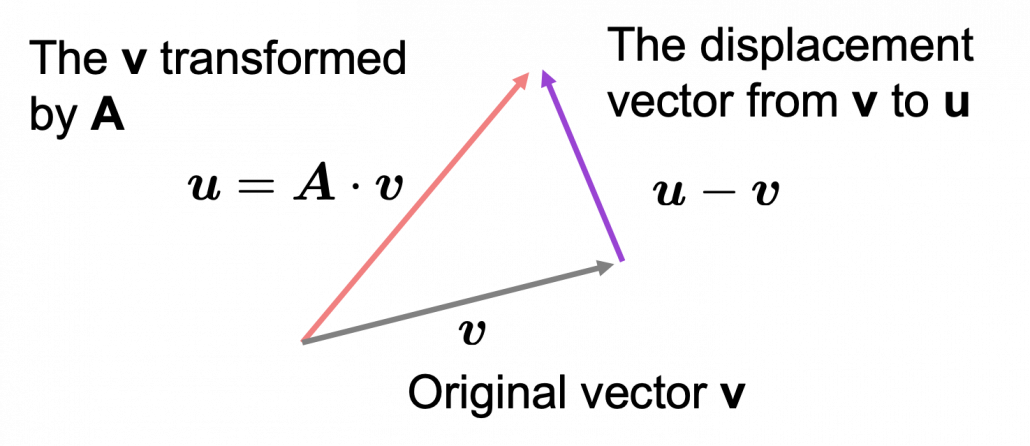 Let’s calculate the displacement vector with more vectors
Let’s calculate the displacement vector with more vectors  , and I prepared several grid vectors
, and I prepared several grid vectors  , which are in purple.
, which are in purple. square matrices
square matrices  , and I plotted displace vectors made by the matrices respectively in the figure below.
, and I plotted displace vectors made by the matrices respectively in the figure below. , the matrix does not have any real eigan values.
, the matrix does not have any real eigan values. is classified to, and I am going to explain positive semidefinite matrices in the fourth section.
is classified to, and I am going to explain positive semidefinite matrices in the fourth section.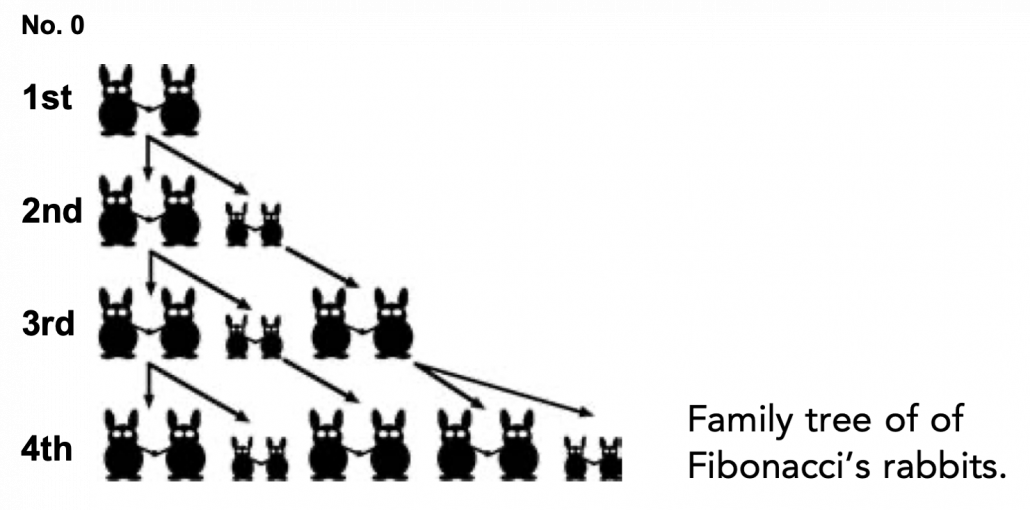
 be the number of pairs of grown up rabbits in the
be the number of pairs of grown up rabbits in the  generation. One pair of grown up rabbits produce one pair of young rabbit The concrete values of
generation. One pair of grown up rabbits produce one pair of young rabbit The concrete values of  are
are  ,
,  ,
,  ,
,  ,
,  ,
,  ,
,  ,
,  . Assume that
. Assume that  and that
and that  , then you can calculate the number of the pairs of grown up rabbits in the next generation with the following recurrence relation.
, then you can calculate the number of the pairs of grown up rabbits in the next generation with the following recurrence relation.  .Let
.Let  be
be  , then the recurrence relation can be written as
, then the recurrence relation can be written as  , and the transition of
, and the transition of 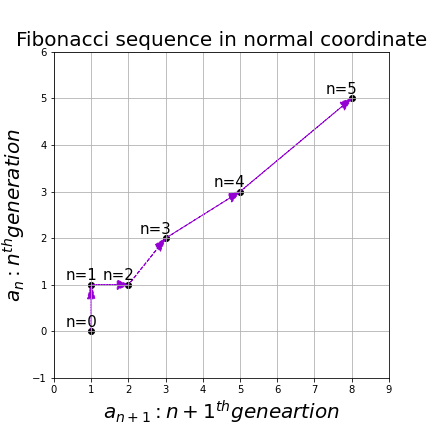
 are eigen values of
are eigen values of  are eigen vectors belonging to them respectively. Also let
are eigen vectors belonging to them respectively. Also let  scalars such that
scalars such that  . According to the definition of eigen values and eigen vectors belonging to them, the following two equations hold:
. According to the definition of eigen values and eigen vectors belonging to them, the following two equations hold:  . If you calculate
. If you calculate  is, using eigen vectors of
is, using eigen vectors of  . In the same way,
. In the same way,  , and
, and  . These equations show that in coordinate system made by eigen vectors of
. These equations show that in coordinate system made by eigen vectors of 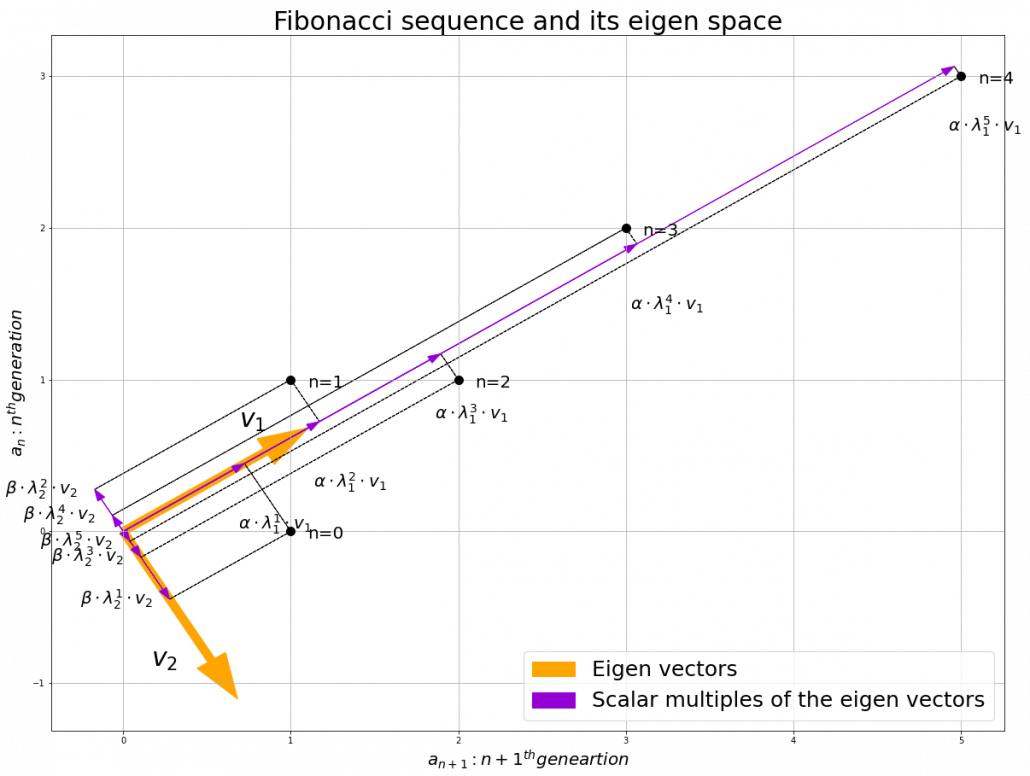
 for all values of the vector
for all values of the vector  , the
, the  for all the eigen values
for all the eigen values  .
. for all values of the vector
for all values of the vector  square positive semidefinite matrix
square positive semidefinite matrix  , whose linear transformation I visualized the second section, is also positive semidefinite.
, whose linear transformation I visualized the second section, is also positive semidefinite. . I visualized the displacement vectors made by the
. I visualized the displacement vectors made by the  .
.
 , there exist orthonormal matrices
, there exist orthonormal matrices  such that
such that  , where
, where  .
. , where
, where  . In other words column vectors
. In other words column vectors  form an orthonormal coordinate system.
form an orthonormal coordinate system. . Combining this fact with what I have told you so far, you we can reach one conclusion: you can orthogonalize a real symmetric matrix
. Combining this fact with what I have told you so far, you we can reach one conclusion: you can orthogonalize a real symmetric matrix  . This is known as spectral decomposition or singular value decomposition.
. This is known as spectral decomposition or singular value decomposition. is also orthonormal. In other words, assume
is also orthonormal. In other words, assume  ,
,  also forms a orthonormal coordinate system.
also forms a orthonormal coordinate system. expands or contracts vectors along each axis. I am going to explain that more precisely in the upcoming articles.
expands or contracts vectors along each axis. I am going to explain that more precisely in the upcoming articles.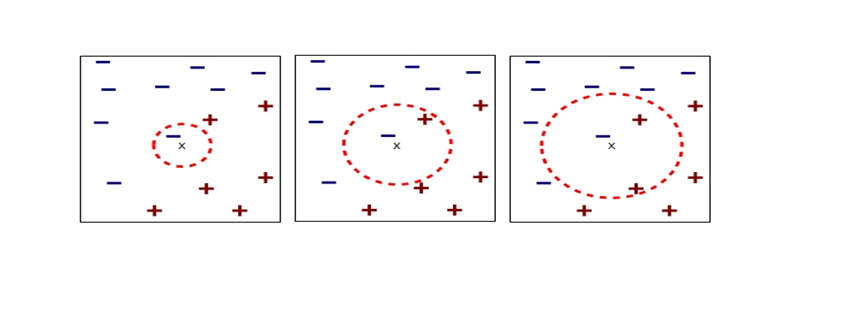
 plotted against parameter
plotted against parameter  out of 12 parameters.
out of 12 parameters.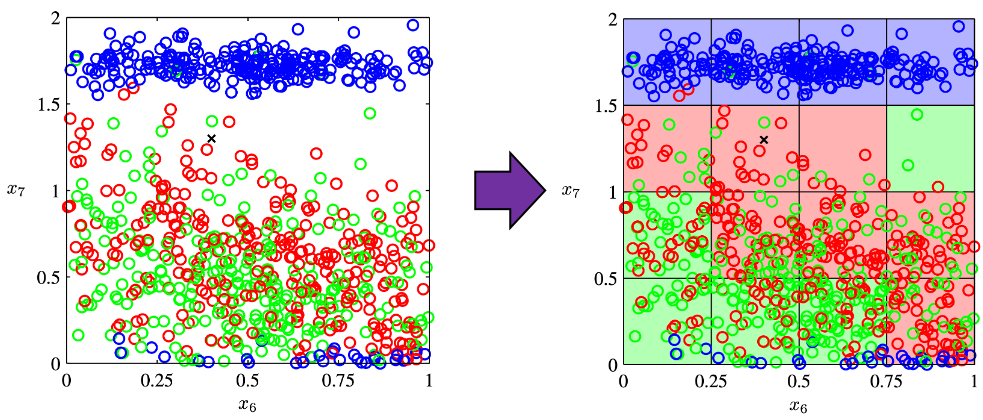
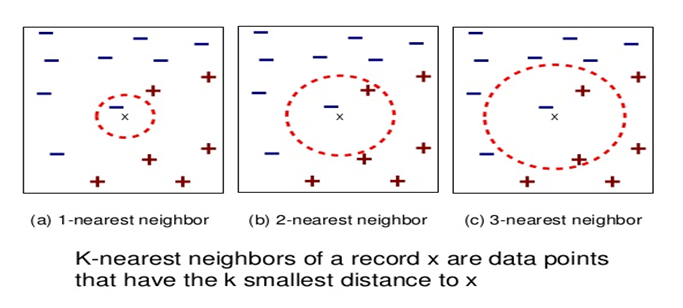
 grids respectively in 1, 2, 3 dimensional spaces, the number of the small regions in the grids are respectively 10, 100, 1000. Even though you cannot visualize it anymore, you can make grids for more than 3 dimensional data. If you continue increasing the degree of dimension, the number of grids increases exponentially, and that can soon surpass the number of training data points. That means there would be a lot of empty spaces in such high dimensional grids. And the classifying method above: coloring each grid and classifying unknown samples depending on the colors of the grids, does not work out anymore because there would be a lot of empty grids.
grids respectively in 1, 2, 3 dimensional spaces, the number of the small regions in the grids are respectively 10, 100, 1000. Even though you cannot visualize it anymore, you can make grids for more than 3 dimensional data. If you continue increasing the degree of dimension, the number of grids increases exponentially, and that can soon surpass the number of training data points. That means there would be a lot of empty spaces in such high dimensional grids. And the classifying method above: coloring each grid and classifying unknown samples depending on the colors of the grids, does not work out anymore because there would be a lot of empty grids.
 , where
, where  is the center point and
is the center point and  is length of radius. When
is length of radius. When 
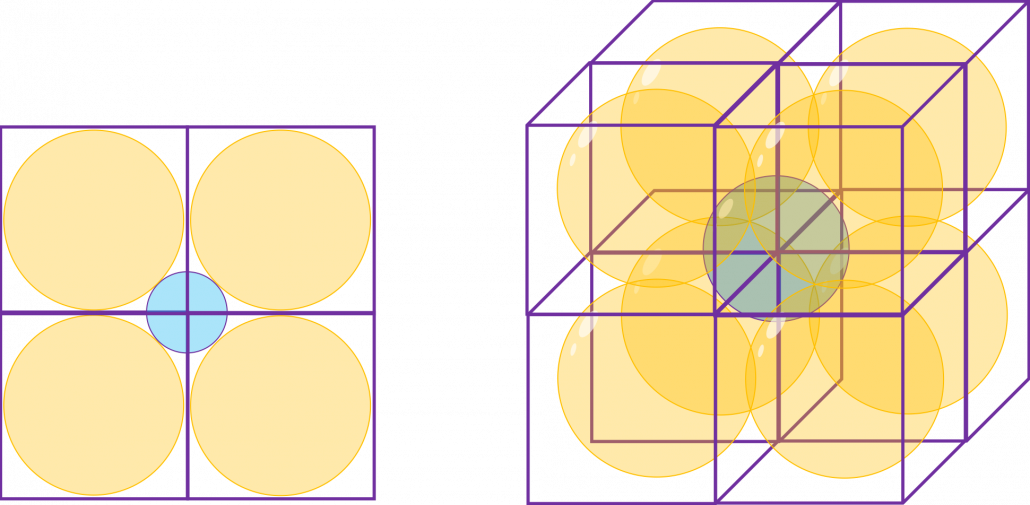
 , and that in each cube is
, and that in each cube is  .
. 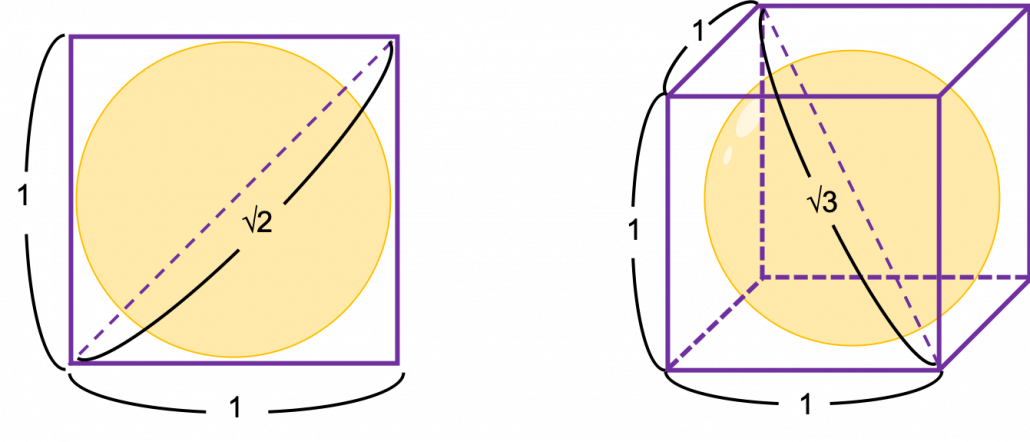
 , and the diameter of the blue sphere is
, and the diameter of the blue sphere is  .
. . If that is true, there is one strange point:
. If that is true, there is one strange point:  can soon surpass 2: that means in the chart above the blue sphere will stick out of the stacked cubes. That sounds like a paradox, but with one hypothesis, the phenomenon makes sense: cubes become more spiky as the degree of dimension grows. This hypothesis is a natural deduction because diagonal lines of hyper cubes get longer, and the the center of each surface of hypercubes still touches the unit D-ball with diameter 1, inscribing inscribing inside each unit hypercube.
can soon surpass 2: that means in the chart above the blue sphere will stick out of the stacked cubes. That sounds like a paradox, but with one hypothesis, the phenomenon makes sense: cubes become more spiky as the degree of dimension grows. This hypothesis is a natural deduction because diagonal lines of hyper cubes get longer, and the the center of each surface of hypercubes still touches the unit D-ball with diameter 1, inscribing inscribing inside each unit hypercube. 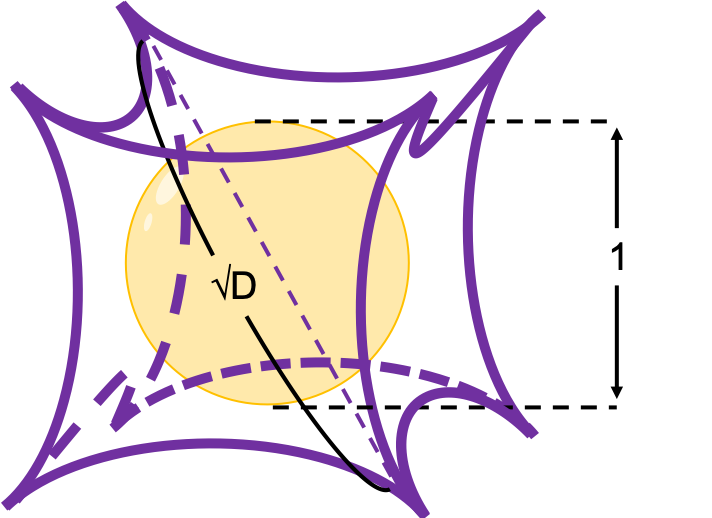

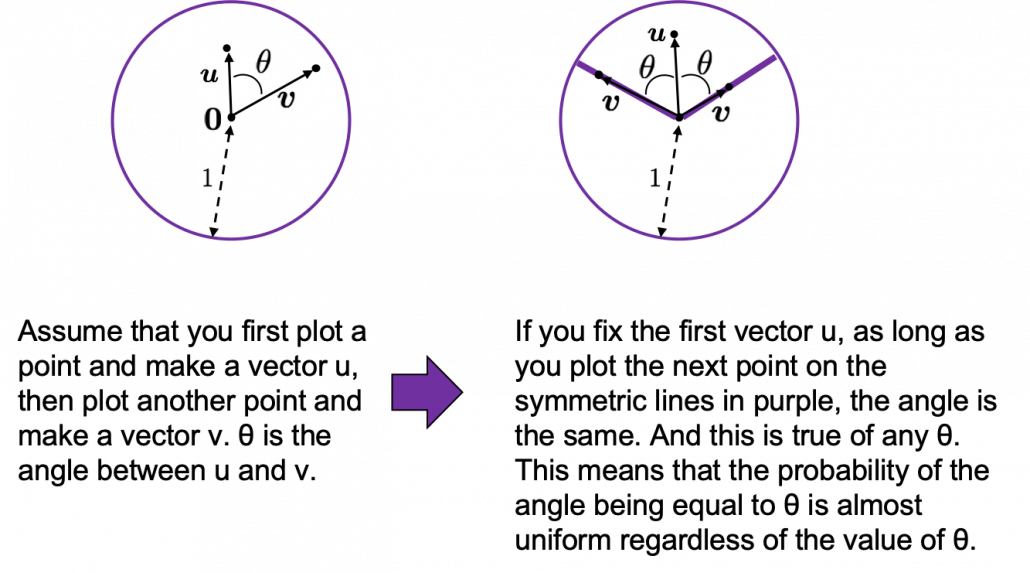
 . Let’s see the general meaning of angle between two vectors in any dimensional spaces. Assume that the angle between two vectors
. Let’s see the general meaning of angle between two vectors in any dimensional spaces. Assume that the angle between two vectors  , then
, then  is calculated as
is calculated as  . In 1, 2, or 3 dimensional space, you can actually see the angle, but again you can define higher dimensional angle, which you cannot visualize anymore. And angles are sometimes used as similarity of two vectors.
. In 1, 2, or 3 dimensional space, you can actually see the angle, but again you can define higher dimensional angle, which you cannot visualize anymore. And angles are sometimes used as similarity of two vectors. is the inner product of
is the inner product of 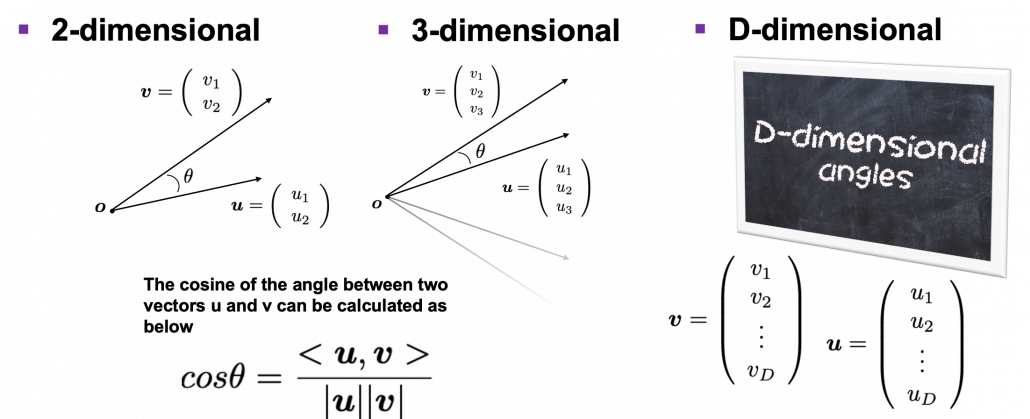
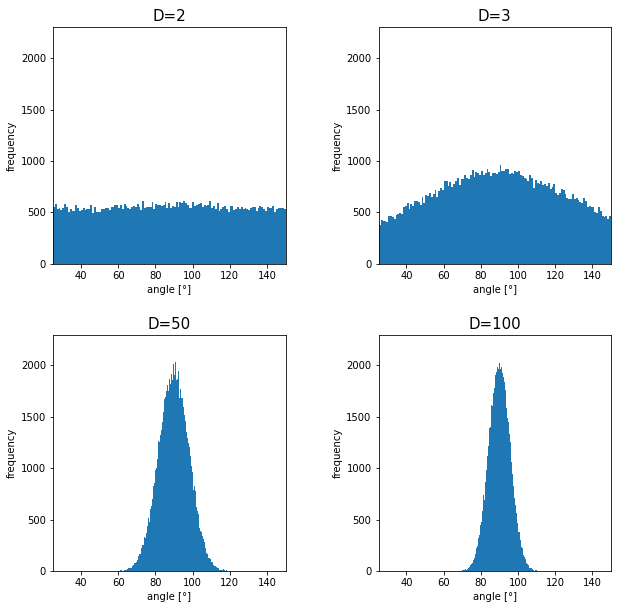
 How about in 3-dimensional space? In fact the distribution of
How about in 3-dimensional space? In fact the distribution of  is the most likely to be generated. As I explain in the figure below, if you compare the area of cross section of a hemisphere and the area of a cone whose vertex is the center point of the sphere, you can see why.
is the most likely to be generated. As I explain in the figure below, if you compare the area of cross section of a hemisphere and the area of a cone whose vertex is the center point of the sphere, you can see why.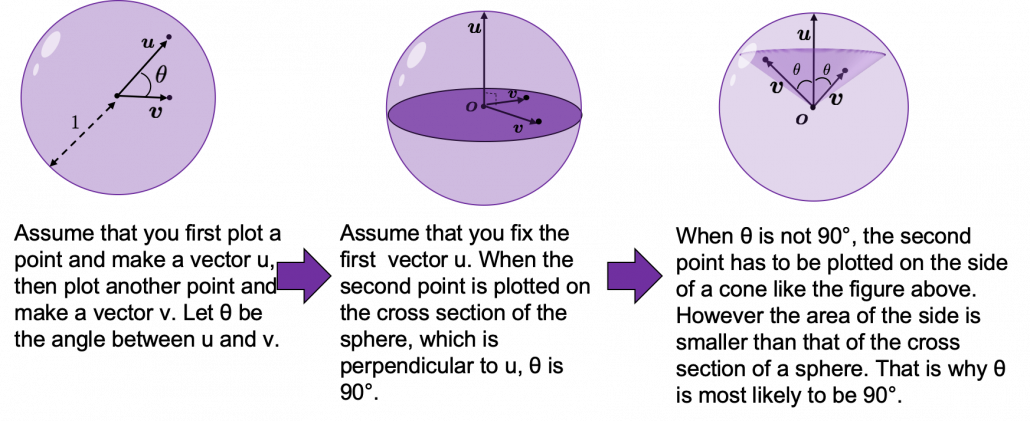

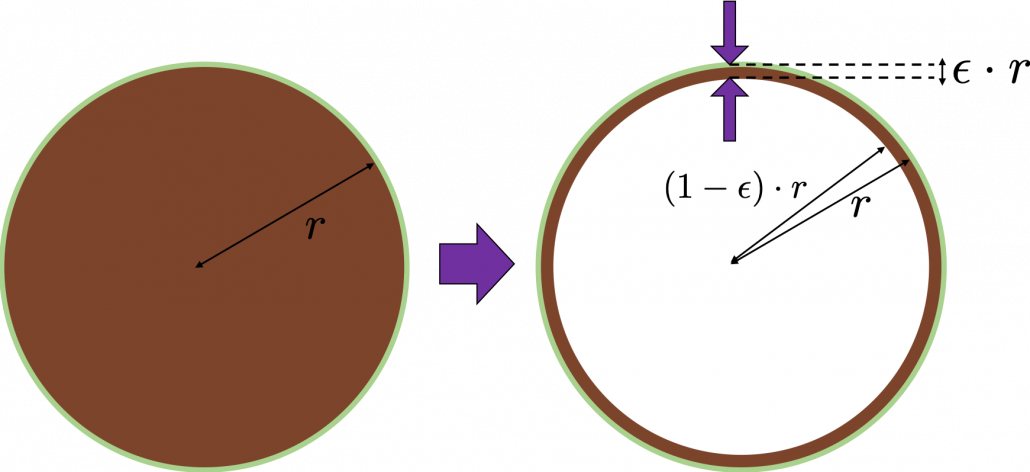
 surface of general spheres with radius
surface of general spheres with radius  First, in 2 two dimensional space, spheres are circles. The area of the brown part of the circle below is
First, in 2 two dimensional space, spheres are circles. The area of the brown part of the circle below is  . In order calculate the are of
. In order calculate the are of  thick surface of the circle, you have only to subtract the area of
thick surface of the circle, you have only to subtract the area of  . When
. When  , the area of outer most surface is
, the area of outer most surface is  , and its proportion to the area of the whole circle is
, and its proportion to the area of the whole circle is  .
.
 , so the proportion of the
, so the proportion of the  . Compared to the case in 2 dimensional space, the proportion is a little bigger.
. Compared to the case in 2 dimensional space, the proportion is a little bigger.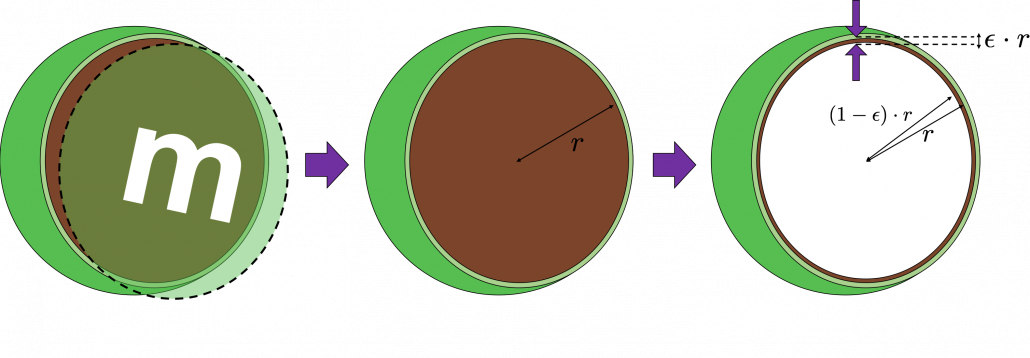
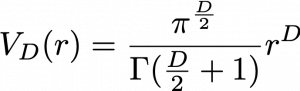
 is called gamma function, but in this article it is not so important. The most important point now is, if you discuss any D-ball, their volume only depends on their radius
is called gamma function, but in this article it is not so important. The most important point now is, if you discuss any D-ball, their volume only depends on their radius  . When
. When  , and when
, and when 
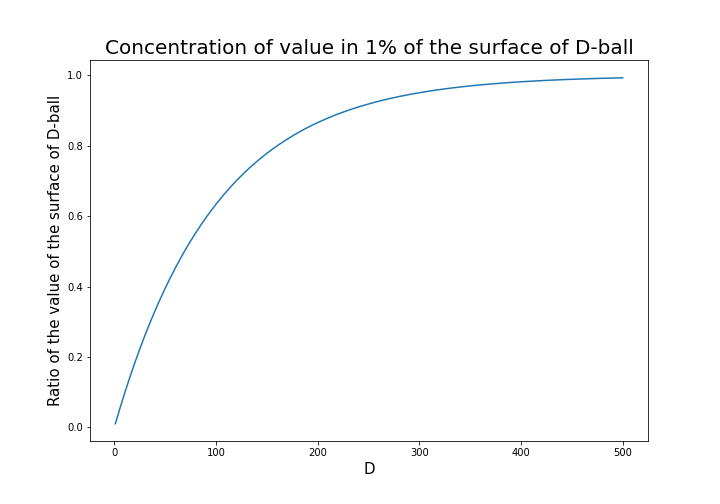
 radius of the center is almost zero. But if you reach the outermost
radius of the center is almost zero. But if you reach the outermost 






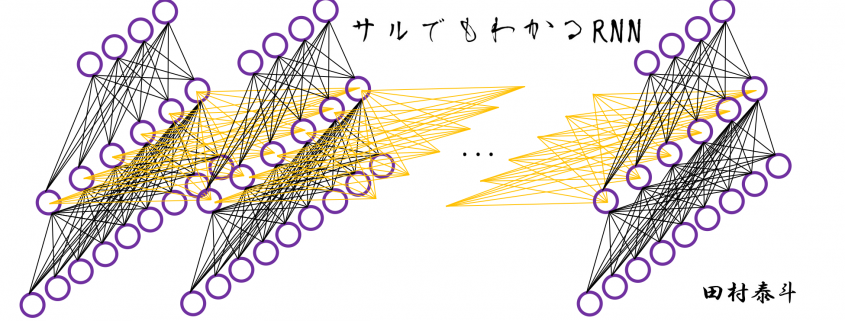
 , and relations of the functions are displayed as the graphical model at the left side of the figure below. Variables are a type of function, so you should think that every node in graphical models denotes a function. Arrows in purple in the right side of the chart show how information propagate in differentiation.
, and relations of the functions are displayed as the graphical model at the left side of the figure below. Variables are a type of function, so you should think that every node in graphical models denotes a function. Arrows in purple in the right side of the chart show how information propagate in differentiation.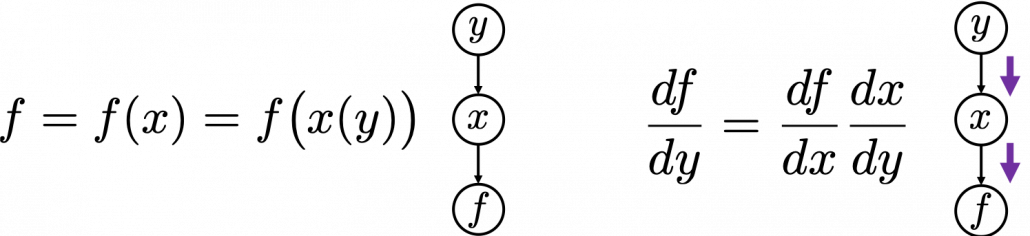
 , which has two variances
, which has two variances  and
and  . And both of the variances also share two variances
. And both of the variances also share two variances  and
and  . When you take partial differentiation of
. When you take partial differentiation of  . The variance
. The variance 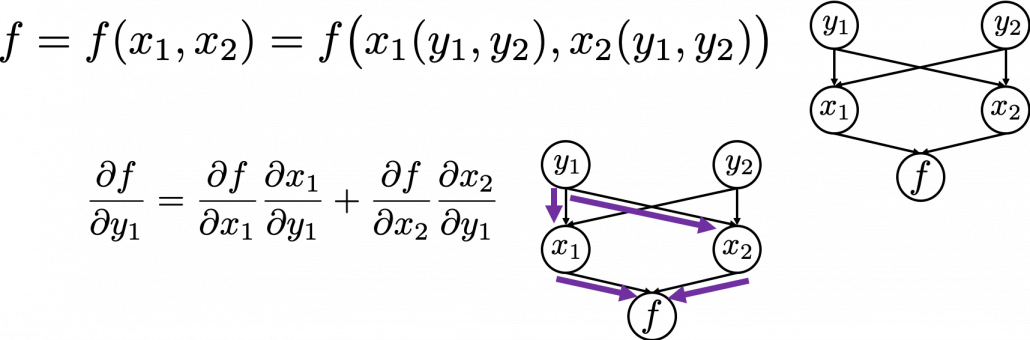
 is calculated as below. And you need to understand chain rules in this way to understanding any types of back propagation.
is calculated as below. And you need to understand chain rules in this way to understanding any types of back propagation.
 terms in total because
terms in total because  , gradients of the error function with respect to parameters, at each time step. But you have to be careful that even though these gradients depend on time steps, the parameters
, gradients of the error function with respect to parameters, at each time step. But you have to be careful that even though these gradients depend on time steps, the parameters  do not depend on time steps.
do not depend on time steps. because parameters themselves do not depend on time. However even
because parameters themselves do not depend on time. However even  propagate backward to all the
propagate backward to all the  . Conversely, in order to calculate
. Conversely, in order to calculate  . In the chart you need arrows of errors in purple for the gradient in a purple frame, orange arrows for gradients in orange frame, red arrows for gradients in red frame. And you need to sum up
. In the chart you need arrows of errors in purple for the gradient in a purple frame, orange arrows for gradients in orange frame, red arrows for gradients in red frame. And you need to sum up  , and you need this gradient
, and you need this gradient  to renew parameters, one time.
to renew parameters, one time.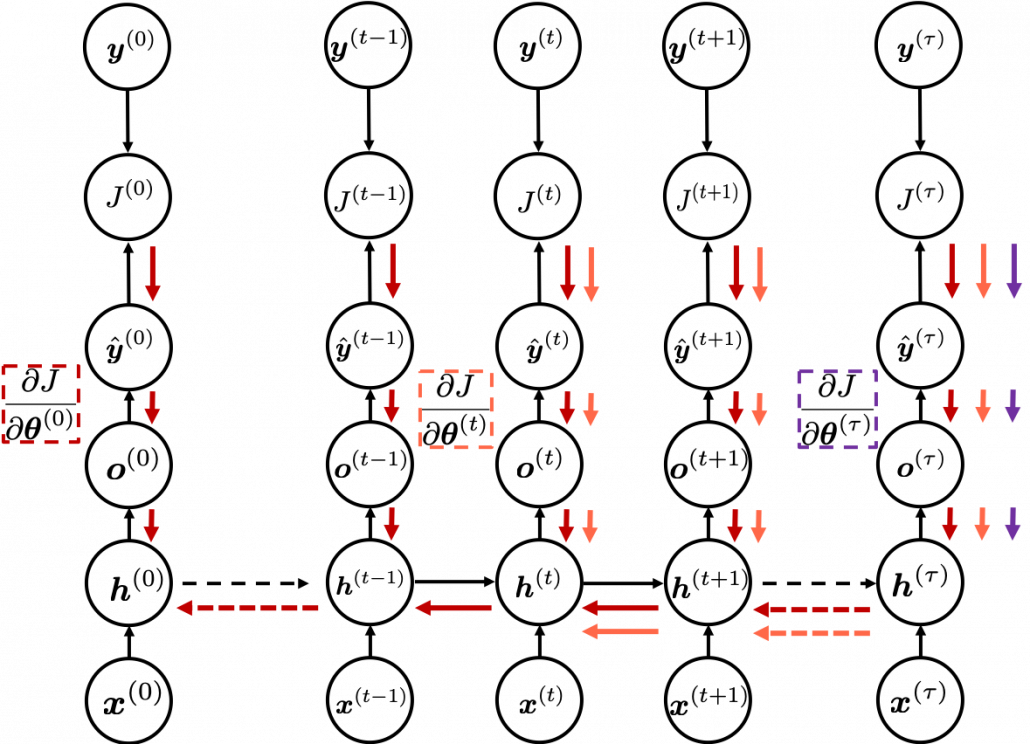
 .
. means. Neurons depend on time steps, but parameters do not depend on time steps. So if
means. Neurons depend on time steps, but parameters do not depend on time steps. So if  are neurons,
are neurons,  , but when
, but when  . In the
. In the  are not used as parameters, but in
are not used as parameters, but in 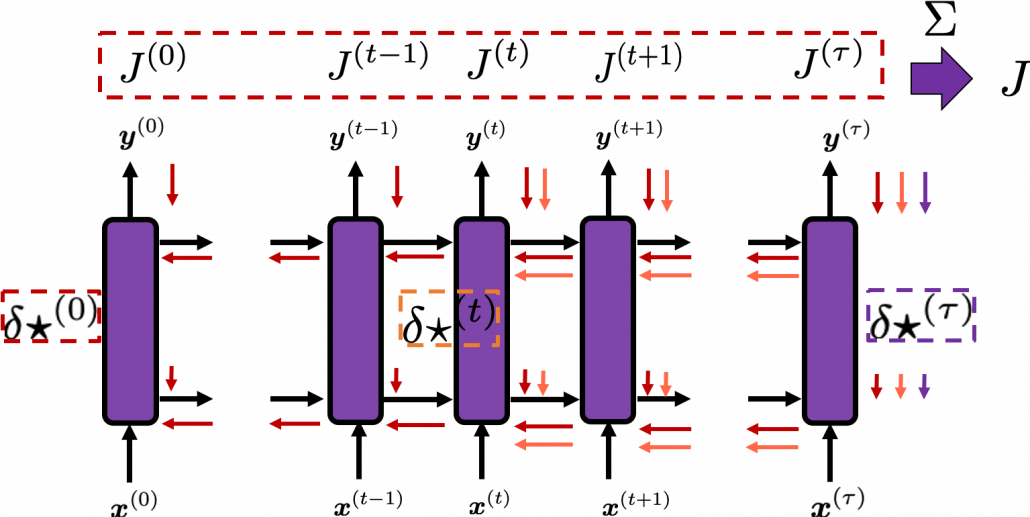
 as below. Unlike the last article, I also added the terms of peephole connections in the equations below, and I also introduced the variances
as below. Unlike the last article, I also added the terms of peephole connections in the equations below, and I also introduced the variances  for convenience.
for convenience.









 , where
, where  . And just as backprop of simple RNNs, in order to calculate gradients with respect to parameters, you need to calculate errors of neurons, that is gradients of error functions with respect to neurons, such as
. And just as backprop of simple RNNs, in order to calculate gradients with respect to parameters, you need to calculate errors of neurons, that is gradients of error functions with respect to neurons, such as  .
. , but the equation for this error is the most difficult, so I recommend you to put it aside for now. After calculating
, but the equation for this error is the most difficult, so I recommend you to put it aside for now. After calculating  . If you see the LSTM block below as a graphical model which I introduced, the information of
. If you see the LSTM block below as a graphical model which I introduced, the information of  flow like the purple arrows. That means,
flow like the purple arrows. That means,  only via
only via  , and this structure is equal to the first graphical model which I have introduced above. And if you calculate
, and this structure is equal to the first graphical model which I have introduced above. And if you calculate  .
. is an index of an element of vectors. If you can calculate element-wise gradients, it is easy to understand that as differentiation of vectors and matrices.
is an index of an element of vectors. If you can calculate element-wise gradients, it is easy to understand that as differentiation of vectors and matrices.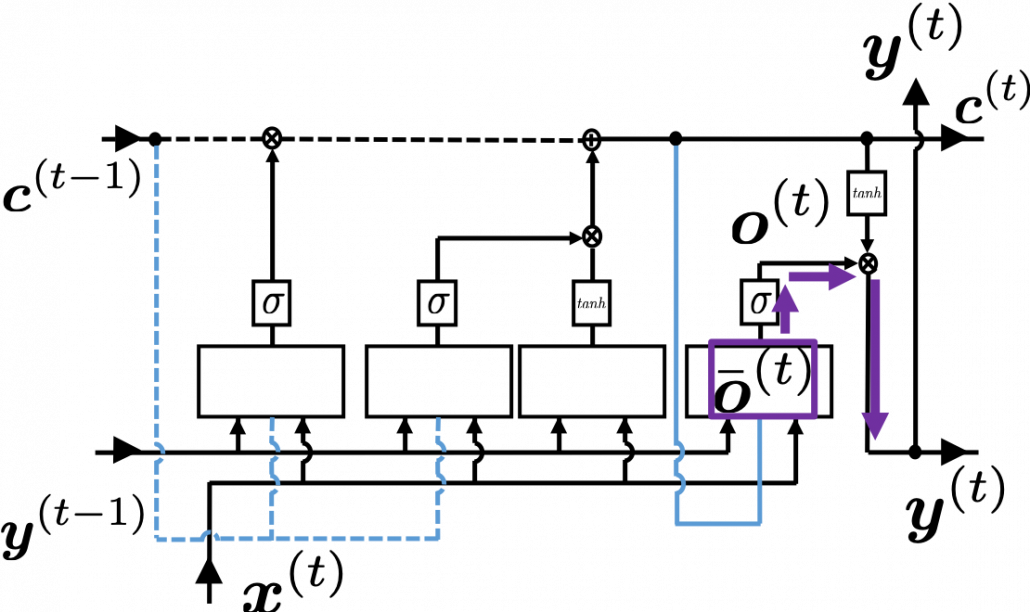
 , and chain rules are very important in this process. The flow of
, and chain rules are very important in this process. The flow of  , and the one which flows to
, and the one which flows to  . And the stream from
. And the stream from  to
to  ,
,  , and the one which directly converges as
, and the one which directly converges as 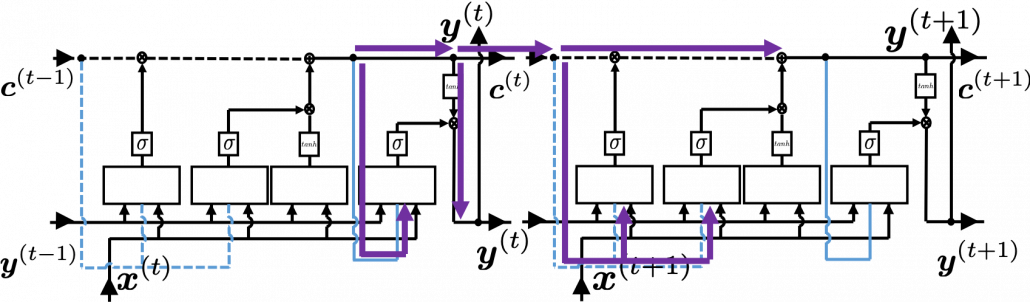
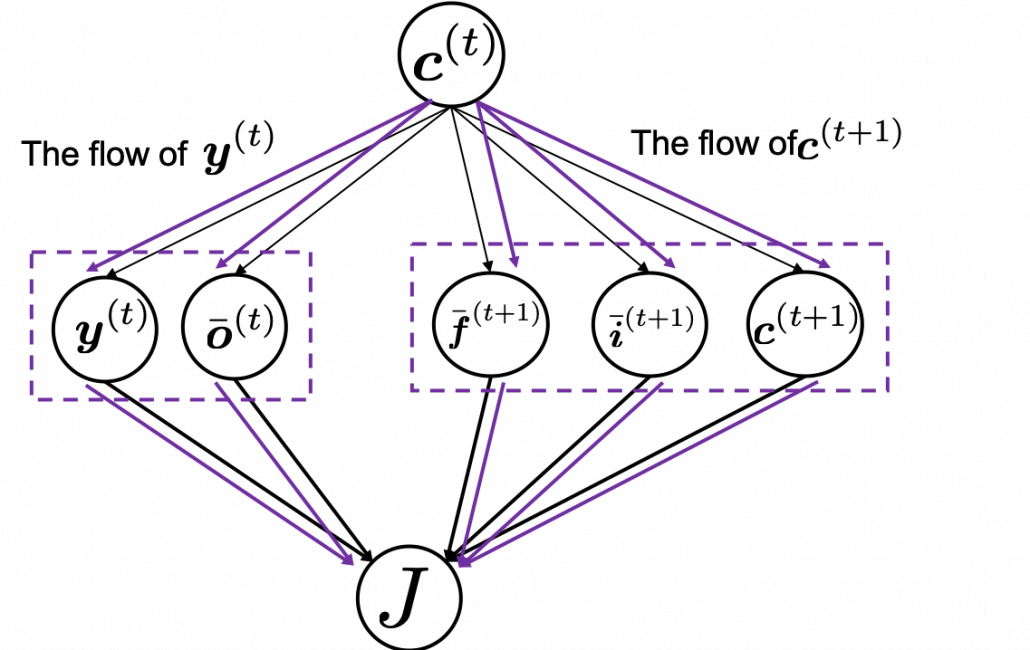
 element-wise as below.
element-wise as below.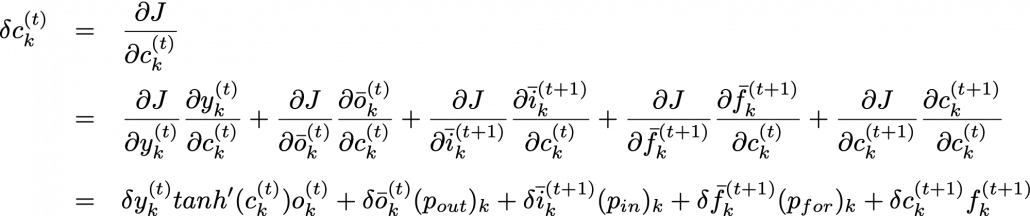
 . In the case above, in the part
. In the case above, in the part  the partial differential operator only affects
the partial differential operator only affects  of
of  . And in the part
. And in the part  , the partial differential operator
, the partial differential operator  only affects the part
only affects the part  of the term
of the term  . In the
. In the  part, only
part, only  , in the
, in the  part, only
part, only  , and in the
, and in the  part, only
part, only  of
of  ,
,  ,
,  are also relatively straigtforward as calculating
are also relatively straigtforward as calculating  . They all use the first type of chain rule in the first section. Thereby you can get these gradients:
. They all use the first type of chain rule in the first section. Thereby you can get these gradients:  ,
,  , and
, and  .
.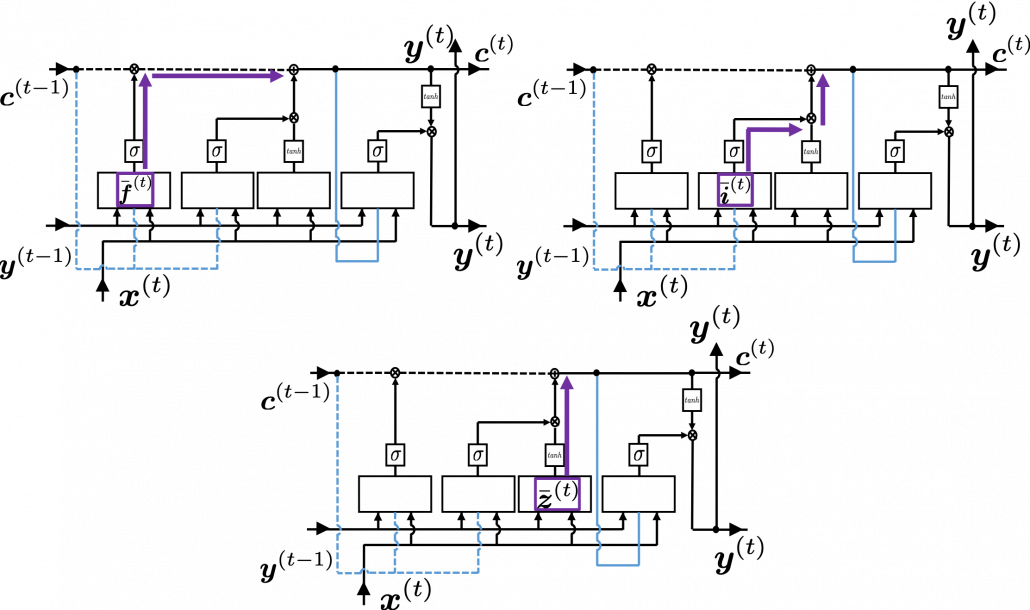
 , and the flows of
, and the flows of 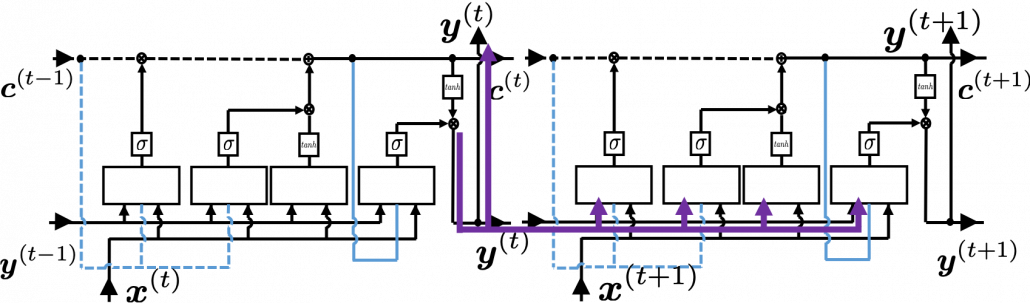




 . Let’s consider the gradient of
. Let’s consider the gradient of  , that is the error flowing from
, that is the error flowing from 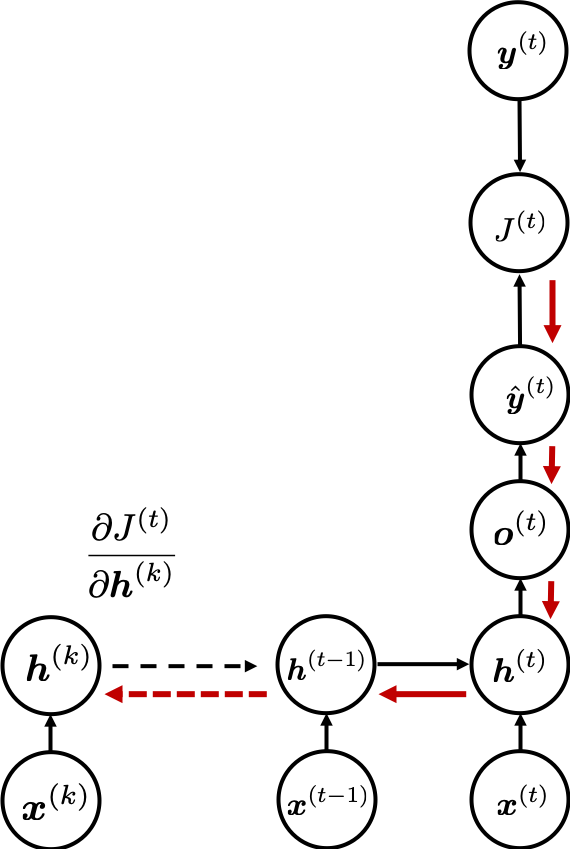
 , where
, where  .
. , but it seems that many study materials and web sites are mistaken in this point.
, but it seems that many study materials and web sites are mistaken in this point. . If you take norms of
. If you take norms of  you get an equality
you get an equality  . I will not go into detail anymore, but it is known that according to this inequality, multiplication of weight vectors exponentially converge to 0 or to infinite number.
. I will not go into detail anymore, but it is known that according to this inequality, multiplication of weight vectors exponentially converge to 0 or to infinite number. is an equivalent. For simplicity, let’s calculate only
is an equivalent. For simplicity, let’s calculate only  , which is equivalent to
, which is equivalent to  of simple RNN backprop.
of simple RNN backprop.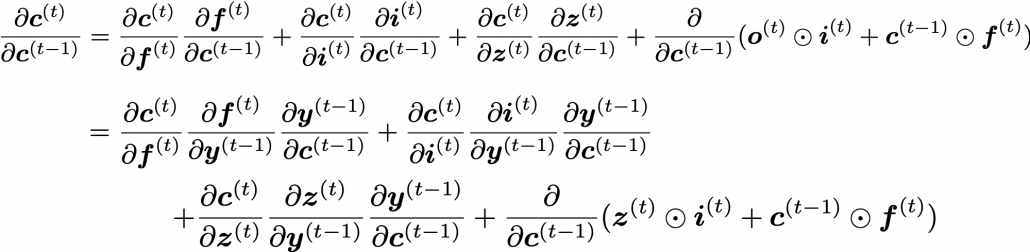
 affects in the chain rule above. That is, you need to calculate
affects in the chain rule above. That is, you need to calculate  , and the partial differential operator only affects
, and the partial differential operator only affects  . I think this is not a correct mathematical notation, but please forgive me for doing this for convenience.
. I think this is not a correct mathematical notation, but please forgive me for doing this for convenience.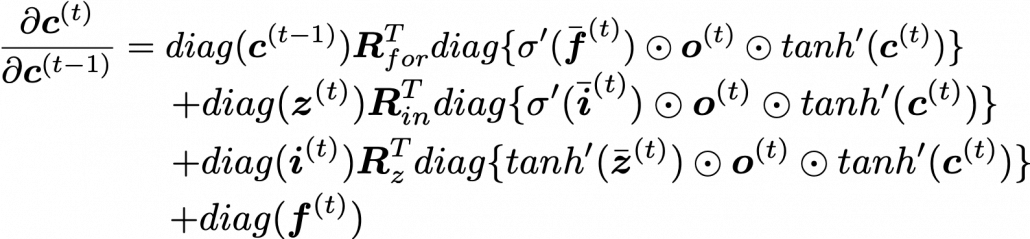
 is very effective. The unaffected value of the elements of
is very effective. The unaffected value of the elements of  can directly adjust the value of
can directly adjust the value of 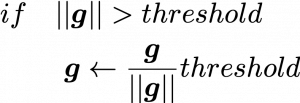
 is a gradient at the time step
is a gradient at the time step  is the maximum size of the “step.”
is the maximum size of the “step.” , that means the loss function
, that means the loss function