Bringing intelligence to where data lives: Python & R embedded in T-SQL
Introduction
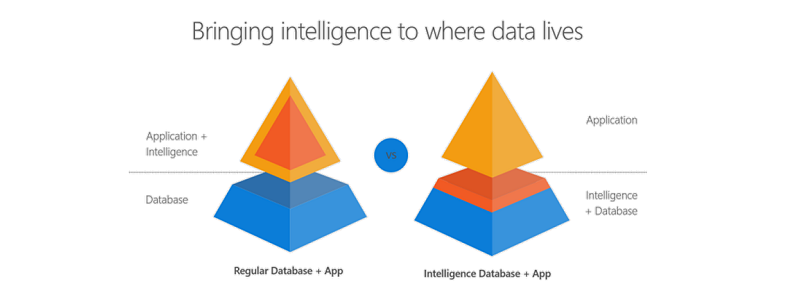
Did you know that you can write R and Python code within your T-SQL statements? Machine Learning Services in SQL Server eliminates the need for data movement. Instead of transferring large and sensitive data over the network or losing accuracy with sample csv files, you can have your R/Python code execute within your database. Easily deploy your R/Python code with SQL stored procedures making them accessible in your ETL processes or to any application. Train and store machine learning models in your database bringing intelligence to where your data lives.

You can install and run any of the latest open source R/Python packages to build Deep Learning and AI applications on large amounts of data in SQL Server. We also offer leading edge, high-performance algorithms in Microsoft’s RevoScaleR and RevoScalePy APIs. Using these with the latest innovations in the open source world allows you to bring unparalleled selection, performance, and scale to your applications.
If you are excited to try out SQL Server Machine Learning Services, check out the hands on tutorial below. If you do not have Machine Learning Services installed in SQL Server,you will first want to follow the getting started tutorial I published here:
How-To Tutorial
In this tutorial, I will cover the basics of how to Execute R and Python in T-SQL statements. If you prefer learning through videos, I also published the tutorial on YouTube.
Basics
Open up SQL Server Management Studio and make a connection to your server. Open a new query and paste this basic example: (While I use Python in these samples, you can do everything with R as well)
|
1 2 |
EXEC sp_execute_external_script @language = N'Python', @script = N'print(3+4)' |
Sp_execute_external_script is a special system stored procedure that enables R and Python execution in SQL Server. There is a “language” parameter that allows us to choose between Python and R. There is a “script” parameter where we can paste R or Python code. If you do not see an output print 7, go back and review the setup steps in this article.
Parameter Introduction
Now that we discussed a basic example, let’s start adding more pieces:
|
1 2 3 4 5 6 |
EXEC sp_execute_external_script @language =N'Python', @script = N' OutputDataSet = InputDataSet; ', @input_data_1 =N'SELECT 1 AS Col1'; |
Machine Learning Services provides more natural communications between SQL and R/Python with an input data parameter that accepts any SQL query. The input parameter name is called “input_data_1”.
You can see in the python code that there are default variables defined to pass data between Python and SQL. The default variable names are “OutputDataSet” and “InputDataSet” You can change these default names like this example:
|
1 2 3 4 5 6 7 8 |
EXEC sp_execute_external_script @language =N'Python', @script = N' MyOutput = MyInput; ', @input_data_1_name = N'MyInput', @input_data_1 =N'SELECT 1 AS foo', @output_data_1_name =N'MyOutput'; |
As you executed these examples, you might have noticed that they each return a result with “(No column name)”? You can specify a name for the columns that are returned by adding the WITH RESULT SETS clause to the end of the statement which is a comma separated list of columns and their datatypes.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
EXEC sp_execute_external_script @language =N'Python', @script=N' MyOutput = MyInput; ', @input_data_1_name = N'MyInput', @input_data_1 =N' SELECT 1 AS foo, 2 AS bar ', @output_data_1_name =N'MyOutput' WITH RESULT SETS ((MyColName int, MyColName2 int)); |
Input/Output Data Types
Alright, let’s discuss a little more about the input/output data types used between SQL and Python. Your input SQL SELECT statement passes a “Dataframe” to python relying on the Python Pandas package. Your output from Python back to SQL also needs to be in a Pandas Dataframe object. If you need to convert scalar values into a dataframe here is an example:
|
1 2 3 4 5 6 7 8 9 10 |
EXEC sp_execute_external_script @language =N'Python', @script=N' import pandas as pd c = 1/2 d = 1*2 s = pd.Series([c,d]) df = pd.DataFrame(s) OutputDataSet = df ' |
Variables c and d are both scalar values, which you can add to a pandas Series if you like, and then convert them to a pandas dataframe. This one shows a little bit more complicated example, go read up on the python pandas package documentation for more details and examples:
|
1 2 3 4 5 6 7 8 |
EXEC sp_execute_external_script @language =N'Python', @script=N' import pandas as pd s = {"col1": [1, 2], "col2": [3, 4]} df = pd.DataFrame(s) OutputDataSet = df ' |
You now know the basics to execute Python in T-SQL!
Did you know you can also write your R and Python code in your favorite IDE like RStudio and Jupyter Notebooks and then remotely send the execution of that code to SQL Server? Check out these documentation links to learn more: https://aka.ms/R-RemoteSQLExecution https://aka.ms/PythonRemoteSQLExecution
Check out the SQL Server Machine Learning Services documentation page for more documentation, samples, and solutions. Check out these E2E tutorials on github as well.
Would love to hear from you! Leave a comment below to ask a question, or start a discussion!