How to choose the best pre-trained model for your Convolutional Neural Network?
Introduction to Transfer Learning
Let’s start by defining this term that is increasingly used in Data Science:
Transfer Learning refers to the set of methods that allow the transfer of knowledge acquired from solving a given problem to another problem.
Transfer Learning has been very successful with the rise of Deep Learning. Indeed, the models used in this field often require high computation times and important resources. However, by using pre-trained models as a starting point, Transfer Learning makes it possible to quickly develop high-performance models and efficiently solve complex problems in Computer Vision.
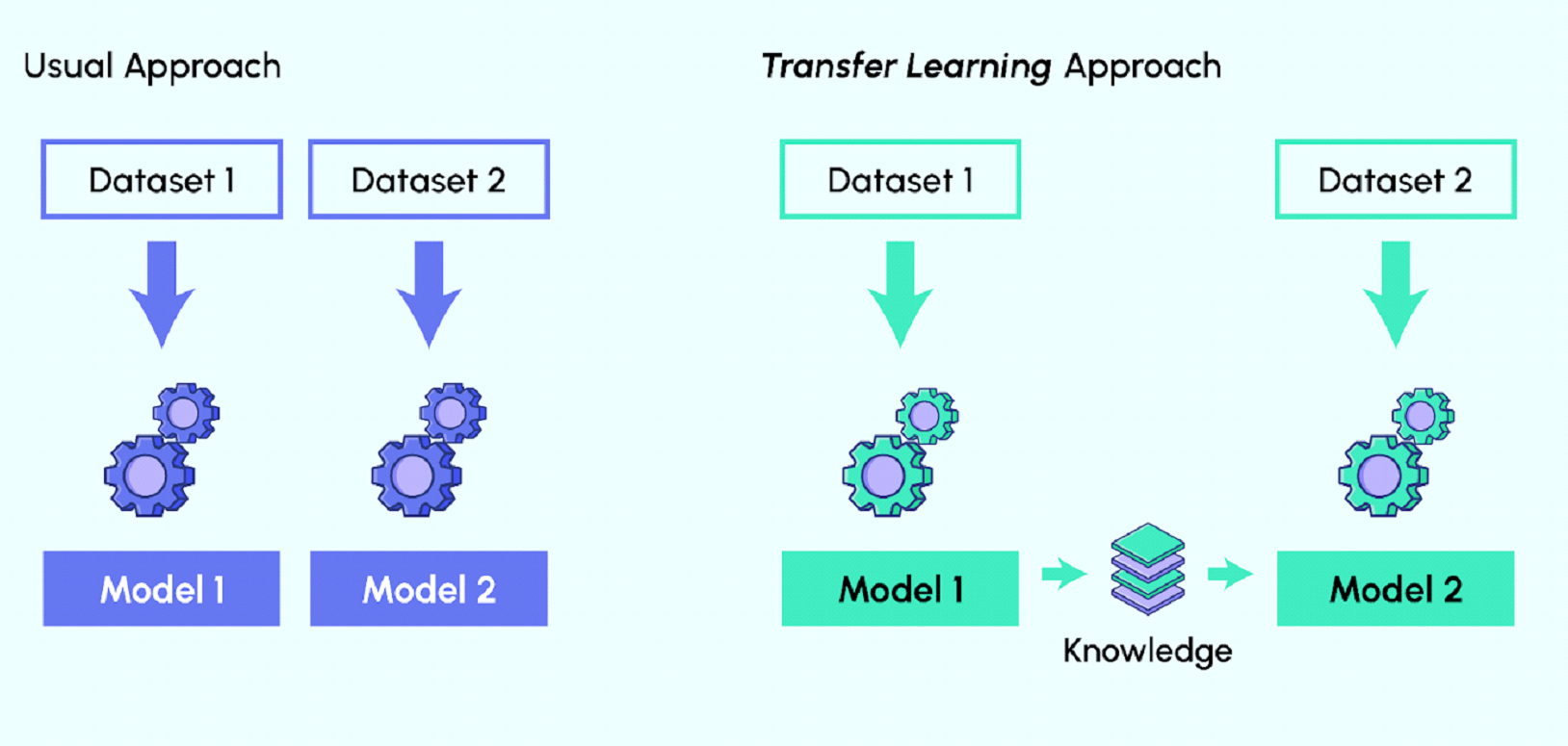
As most of the Deep learning technics, Transfer Learning is strongly inspired by the process with which we learn.
Let’s take the example of someone who masters the guitar and wants to learn to play the piano. He can capitalize on his knowledge of music to learn to play a new instrument. In the same way, a car recognition model can be quickly adapted to truck recognition.
How is Transfer Learning concretely implemented to solve Computer Vision problems?
Now that we have defined Transfer Learning, let’s look at its application to Deep Learning problems, a field in which it is currently enjoying great success.
The use of Transfer Learning methods in Deep Learning consists mainly in exploiting pre-trained neural networks
Generally, these models correspond to very powerful algorithms that have been developed and trained on large databases and are now freely shared.
In this context, 2 types of strategies can be distinguished:
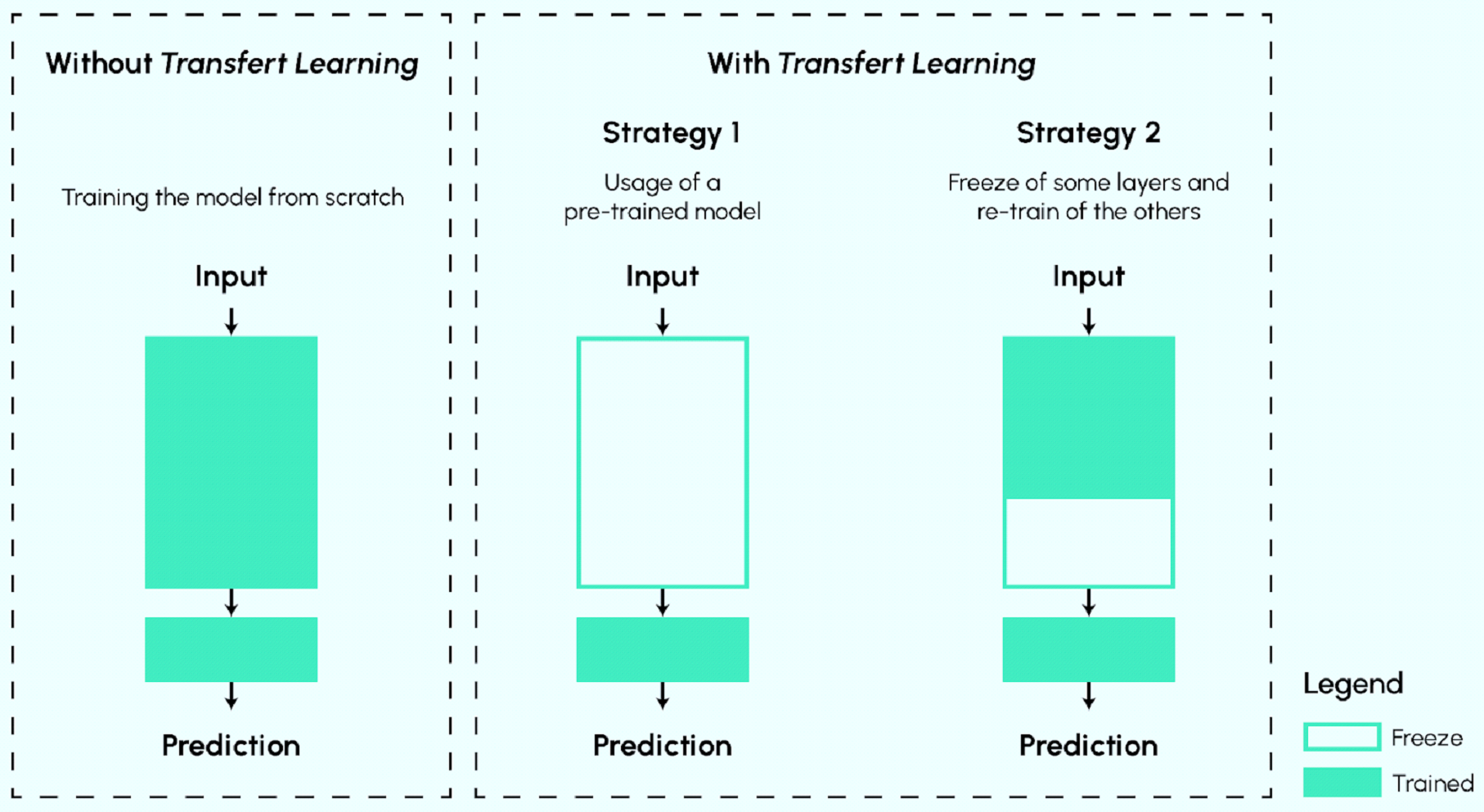
- Use of pre-trained models as feature extractors:
The architecture of Deep Learning models is very often presented as a stack of layers of neurons. These layers learn different features depending on the level at which they are located. The last layer (usually a fully connected layer, in the case of supervised learning) is used to obtain the final output. The figure below illustrates the architecture of a Deep Learning model used for cat/dog detection. The deeper the layer, the more specific features can be extracted.
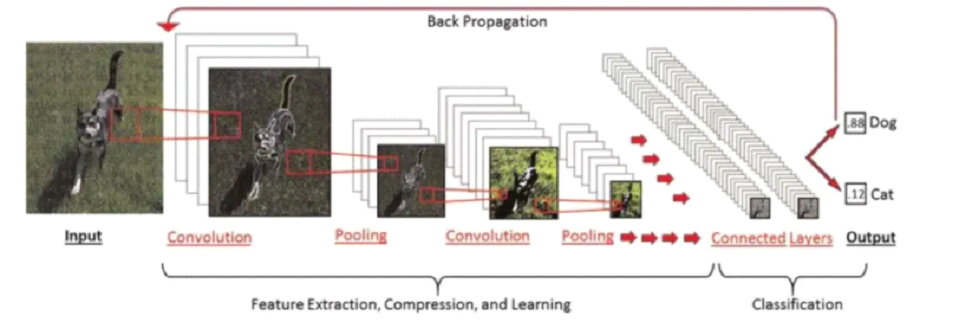
The idea is to reuse a pre-trained network without its final layer. This new network then works as a fixed feature extractor for other tasks.
To illustrate this strategy, let’s take the case where we want to create a model able to identify the species of a flower from its image. It is then possible to use the first layers of the convolutional neural network model AlexNet, initially trained on the ImageNet image database for image classification.
- Fitting of pre-trained models:
This is a more complex technique, in which not only the last layer is replaced to perform classification or regression, but other layers are also selectively re-trained. Indeed, deep neural networks are highly configurable architectures with various hyperparameters. Moreover, while the first layers capture generic features, the last layers focus more on the specific task at hand.
So the idea is to freeze (i.e. fix the weights) of some layers during training and refine the rest to meet the problem.
This strategy allows to reuse the knowledge in terms of the global architecture of the network and to exploit its states as a starting point for training. It thus allows to obtain better performances with a shorter training time.
The figure below summarizes the main Transfer Learning approaches commonly used in Deep Learning.
How to choose your pre-trained CNN ?
TensorFlow and Pytorch have built very accessible libraries of pre-trained models easily integrable to your pipelines, allowing the simple leveraging of the Transfer learning power.
In the first part you discovered what a pre-trained model is, let’s now dig into how to choose between the (very) large catalog of models accessible in open-source.
An unresolved question:
As you could have expected, there is no simple answer to this question. Actually, many developers just stick to the models they are used to and that performed well in their previous projects.
However, it is still possible to follow a few guidelines that can help you decide.
Criteria:
The two main aspects to take into account are the same as most of the machine learning tasks :
⦁ Accuracy : The Higher, the better
⦁ Speed : The Faster, the better
The dream being having a model that has a super fast training with an excellent accuracy. But as you could expect, usually to have a better accuracy, a deeper model is needed, therefore a model that takes more time to train. Thus, the goal is to maximize the tradeoff between accuracy and complexity. You can observe this tradeoff in the following graph taken from the Efficient Net model original paper.
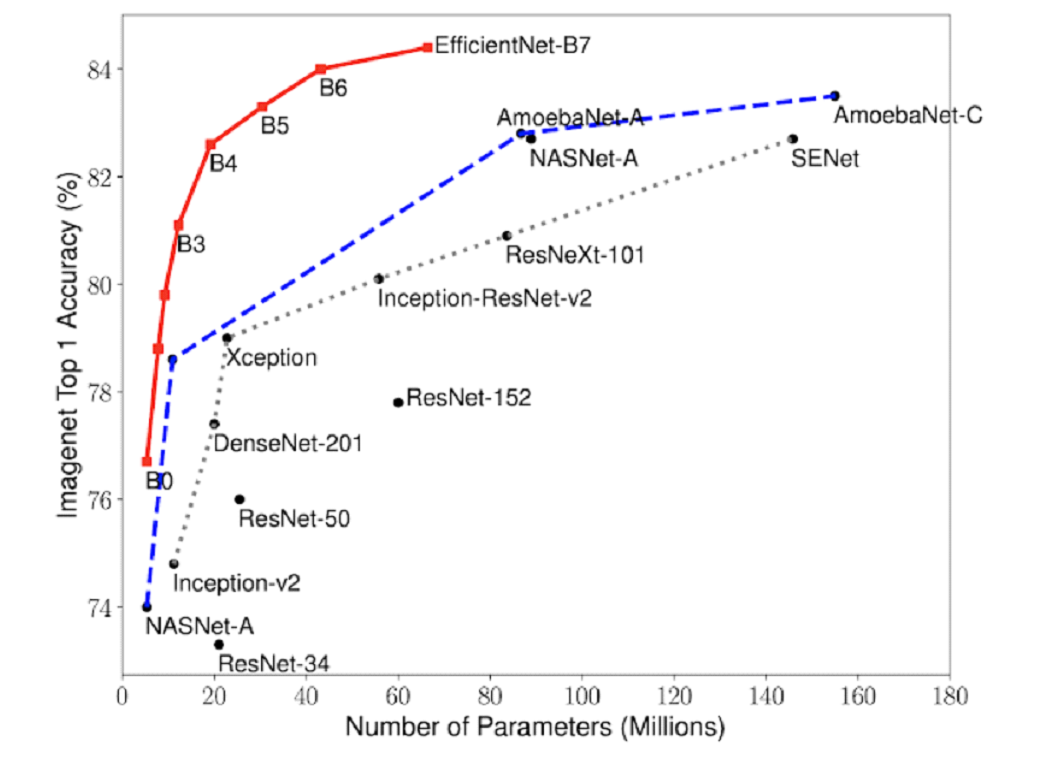
As you can observe on this graph, bigger models are not always better. There is always a risk that a more complex model overfits your data, because it can give too much importance to subtle details in features. Knowing that the best is to start with the smallest model, that is what’s done in the industry. A “good-enough” model that is small and therefore quickly trained is preferred. Of course if you aim for great accuracy with no interest in a quick training then you can target the large model and even try ensemble techniques combining multiple models power.
Most performant models at this time :
Here are a few models that are widely used today in the field of computer vision. From image classification to complex image captioning, those structures offers great performances :
- ResNet50
- EfficientNet
- Inceptionv3
ResNet 50 : ResNet was developed by Microsoft and aims at resolving the ‘vanishing gradient problem’. It allows the creation of a very deep model (up to a hundred layers).
Top-1 accuracy : 74.9%
Top-5 accuracy : 92.1%
Size : 98MB
Parameters : 26 millions
EfficientNet : This model is a state-of-the art convolutional neural network trained by Google. It is based on the same construction as ResNet but with an intelligent rescaling method.
Top-1 accuracy : 77.1%
Top-5 accuracy : 93.3.0%
Size : 29MB
Parameters : 5 millions
InceptionV3 : Inception Networks (GoogLeNet/Inception v1) have proved to be more computationally efficient, both in terms of the number of parameters generated by the network and the economical cost incurred. It is based on Factorized Convolutions.
Top-1 accuracy : 77.9%
Top-5 accuracy : 93.7%
Size : 92MB
Parameters : 24 millions
Final Note:
To summarize, in this article, we have seen that Transfer Learning is the ability to use existing knowledge, developed to solve a given problem, to solve a new problem. We saw the top 3 State-of-the-Art pre-trained models for image classification. Here I summarized the performance and some detail on each of those models.

However, as you have now understood, this is a continuously growing domain and there is always a new model to look forward to and push the boundaries further. The best way to keep up is to read papers introducing new model construction and try the most performing new releases.

Thank you very much Mr Mickael Komendyak. I really enjoyed reading your article. Especially how you made things simple and easy to understand