Wie weit ist das maschinelle Lernen auf dem Gebiet der CAPTCHA-Lösung fortgeschritten?
Maschinelles Lernen ist mehr als ein Buzzword, denn unter der Haube stecken viele Algorithemen, die eine ganze Reihe von Problemen lösen können. Die Lösung von CAPTCHA ist dabei nur eine von vielen Aufgaben, die Machine Learning bewältigen kann. Durch die Arbeit an ein paar Problemen im Zusammenhang mit dem konvolutionellen neuronalen Netz haben wir festgestellt, dass es in diesem Bereich noch viel Verbesserungspotenzial gibt. Die Genauigkeit der Erkennung ist oftmals noch nicht gut genug. Schauen wir uns im Einzelnen an, welche Dienste wir haben, um dieses Problem anzugehen, und welche sich dabei als die besten erweisen.
Was ist CAPTCHA?
CAPTCHA ist kein fremder Begriff mehr für Web-Benutzer. Es handelt sich um die ärgerliche menschliche Validierungsprüfung, die auf vielen Websites hinzugefügt wird. Es ist ein Akronym für Completely Automated Public Turing test for tell Computer and Humans Apart. CAPTCHA kann als ein Computerprogramm bezeichnet werden, das dazu entwickelt wurde, Mensch und Maschine zu unterscheiden, um jede Art von illegaler Aktivität auf Websites zu verhindern. Der Sinn von CAPTCHA ist, dass nur ein Mensch diesen Test bestehen können sollte und Bots bzw. irgend eine Form automatisierter Skripte daran versagen. So entsteht ein Wettlauf zwischen CAPTCHA-Anbietern und Hacker-Lösungen, die auf den Einsatz von selbstlernenden Systemen setzen.
Warum müssen wir CAPTCHA lösen?
Heutzutage verwenden die Benutzer automatisierte CAPTCHA-Lösungen für verschiedene Anwendungsfälle. Und hier ein entscheidender Hinweis: Ähnlich wie Penetrationstesting ist der Einsatz gegen Dritte ohne vorherige Genehmigung illegal. Gegen eigene Anwendungen oder gegen Genehmigung (z. B. im Rahmen eines IT-Security-Tests) ist die Anwendung erlaubt. Hacker und Spammer verwenden die CAPTCHA-Bewältigung, um die E-Mail-Adressen der Benutzer zu erhalten, damit sie so viele Spams wie möglich erzeugen können oder um Bruteforce-Attacken durchführen zu können. Die legitimen Beispiele sind Fälle, in denen ein neuer Kunde oder Geschäftspartner zu Ihnen gekommen ist und Zugang zu Ihrer Programmierschnittstelle (API) benötigt, die noch nicht fertig ist oder nicht mit Ihnen geteilt werden kann, wegen eines Sicherheitsproblems oder Missbrauchs, den es verursachen könnte.
Für diese Anwendungsfälle sollen automatisierte Skripte CAPTCHA lösen. Es gibt verschiedene Arten von CAPTCHA: Textbasierte und bildbasierte CAPTCHA, reCAPTCHA und mathematisches CAPTCHA.
Es gibt einen Wettlauf zwischen CAPTCHA-Anbieter und automatisierten Lösungsversuchen. Die in CAPTCHA und reCAPTCHA verwendete Technologie werden deswegen immer intelligenter wird und Aktualisierungen der Zugangsmethoden häufiger. Das Aufrüsten hat begonnen.
Populäre Methoden für die CAPTCHA-Lösung
Die folgenden CAPTCHA-Lösungsmethoden stehen den Benutzern zur Lösung von CAPTCHA und reCAPTCHA zur Verfügung:
- OCR (optische Zeichenerkennung) via aktivierte Bots – Dieser spezielle Ansatz löst CAPTCHAs automatisch mit Hilfe der OCR-Technik (Optical Character Recognition). Werkzeuge wie Ocrad, tesseract lösen CAPTCHAs, aber mit sehr geringer Genauigkeit.
- Maschinenlernen — Unter Verwendung von Computer Vision, konvolutionalem neuronalem Netzwerk und Python-Frameworks und Bibliotheken wie Keras mit Tensorflow. Wir können tiefe neuronale Konvolutionsnetzmodelle trainieren, um die Buchstaben und Ziffern im CAPTCHA-Bild zu finden.
- Online-CAPTCHA-Lösungsdienstleistungen — Diese Dienste verfügen teilweise über menschliche Mitarbeiter, die ständig online verfügbar sind, um CAPTCHAs zu lösen. Wenn Sie Ihre CAPTCHA-Lösungsanfrage senden, übermittelt der Dienst sie an die Lösungsanbieter, die sie lösen und die Lösungen zurückschicken.
Leistungsanalyse der OCR-basierten Lösung
OCR Die OCR ist zwar eine kostengünstige Lösung, wenn es darum geht, eine große Anzahl von trivialen CAPTCHAs zu lösen, aber dennoch liefert sie nicht die erforderliche Genauigkeit. OCR-basierte Lösungen sind nach der Veröffentlichung von ReCaptcha V3 durch Google selten geworden. OCR-fähige Bots sind daher nicht dazu geeignet, CAPTCHA zu umgehen, die von Titanen wie Google, Facebook oder Twitter eingesetzt werden. Hierfür müsste ein besser ausgestattetes CAPTCHA-Lösungssystem eingesetzt werden.
OCR-basierte Lösungen lösen 1 aus 3 trivialen CAPTCHAs korrekt.
Leistungsanalyse der ML-basierten Methode
Schauen wir uns an, wie Lösungen auf dem Prinzip des Maschinenlernens funktionieren:
Die ML-basierte Verfahren verwenden OpenCV, um Konturen in einem Bild zu finden, das die durchgehenden Gebiete feststellt. Die Bilder werden mit der Technik der Schwellenwertbildung vorverarbeitet. Alle Bilder werden in Schwarzweiß konvertiert. Wir teilen das CAPTCHA-Bild mit der OpenCV-Funktion findContour() in verschiedene Buchstaben auf. Die verarbeiteten Bilder sind jetzt nur noch einzelne Buchstaben und Ziffern. Diese werden dann dem CNN-Modell zugeführt, um es zu trainieren. Und das trainierte CNN-Modell ist bereit, die richtige Captchas zu lösen.

Die Präzision einer solchen Lösung ist für alle textbasierten CAPTCHAs weitaus besser als die OCR-Lösung. Es gibt auch viele Nachteile dieser Lösung, denn sie löst nur eine bestimmte Art von CAPTCHAs und Google aktualisiert ständig seinen reCAPTCHA-Generierungsalgorithmus. Die letzte Aktualisierung schien die beste ReCaptcha-Aktualisierung zu sein, die disen Dienst bisher beeinflusst hat: Die regelmäßigen Nutzer hatten dabei kaum eine Veränderung der Schwierigkeit gespürt, während automatisierte Lösungen entweder gar nicht oder nur sehr langsam bzw. inakkurat funktionierten.
Das Modell wurde mit 1⁰⁴ Iterationen mit korrekten und zufälligen Stichproben und 1⁰⁵ Testbildern trainiert, und so wurde eine mittlere Genauigkeit von ~60% erreicht.
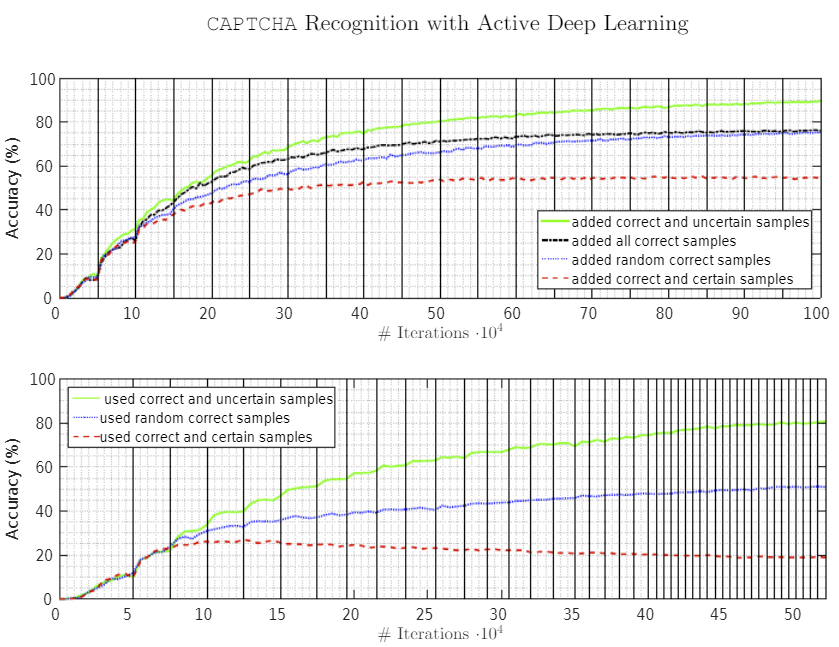
Bild-Quelle: “CAPTCHA Recognition with Active Deep Learning” @ TU München https://www.researchgate.net/publication/301620459_CAPTCHA_Recognition_with_Active_Deep_Learning
Wenn Ihr Anwendungsfall also darin besteht, eine Art von CAPTCHA mit ziemlich einfacher Komplexität zu lösen, können Sie ein solches trainiertes ML-Modell hervorragend nutzen. Eine bessere Captcha-Lösungslösung als OCR, muss aber noch eine ganze Menge Bereiche umfassen, um die Genauigkeit der Lösung zu gewährleisten.
Online-Captcha-Lösungsdienst
Online-CAPTCHA-Lösungsdienste sind bisher die bestmögliche Lösung für dieses Problem. Sie verfolgen alle Aktualisierungen von reCAPTCHA durch Google und bieten eine tadellose Genauigkeit von 99%.
Warum sind Online-Anti-Captcha-Dienste leistungsfähiger als andere Methoden?
Die OCR-basierten und ML-Lösungen weisen nach den bisherigen Forschungsarbeiten und Weiterentwicklungen viele Nachteile auf. Sie können nur triviale CAPTCHAs ohne wesentliche Genauigkeit lösen. Hier sind einige Punkte, die in diesem Zusammenhang zu berücksichtigen sind:
– Ein höherer Prozentsatz an korrekten Lösungen (OCR gibt bei wirklich komplizierten CAPTCHAs ein extrem hohes Maß an falschen Antworten; ganz zu schweigen davon, dass einige Arten von CAPTCHA überhaupt nicht mit OCR gelöst werden können, zumindest vorerst).
– Kontinuierlich fehlerfreie Arbeit ohne Unterbrechungen mit schneller Anpassung an die neu hinzugekommene Komplexität.
– Kostengünstig mit begrenzten Ressourcen und geringen Wartungskosten, da es keine Software- oder Hardwareprobleme gibt; alles, was Sie benötigen, ist eine Internetverbindung, um einfache Aufträge über die API des Anti-Captcha-Dienstes zu senden.
Die großen Anbieter von Online-Lösungsdiensten
Jetzt, nachdem wir die bessere Technik zur Lösung Ihrer CAPTCHAs geklärt haben, wollen wir unter allen Anti-Captcha-Diensten den besten auswählen. Einige Dienste bieten eine hohe Genauigkeit der Lösungen, API-Unterstützung für die Automatisierung und schnelle Antworten auf unsere Anfragen. Dazu gehören Dienste wie 2captcha, Imagetyperz, CaptchaSniper, etc.
2CAPTCHA ist einer der Dienste, die auf die Kombination von Machine Learning und echten Menschen setzen, um CAPTCHA zuverlässig zu lösen. Dabei versprechen Dienste wie 2captcha:
- Schnelle Lösung mit 17 Sekunden für grafische und textuelle Captchas und ~23 Sekunden für ReCaptcha
- Unterstützt alle populären Programmiersprachen mit einer umfassenden Dokumentation der fertigen Bibliotheken.
- Hohe Genauigkeit (bis zu 99% je nach dem CAPTCHA-Typ).
- Das Geld wird bei falschen Antworten zurückerstattet.
- Fähigkeit, eine große Anzahl von Captchas zu lösen (mehr als 10.000 pro Minute)
Schlussfolgerung
Convolutional Neural Networks (CNN) wissen, wie die einfachsten Arten von Captcha zu bewältigen sind und werden auch mit der weiteren Enwicklung schritthalten können. Wir haben es mit einem Wettlauf um verkomplizierte CAPTCHAs und immer fähigeren Lösungen der automatisierten Erkennung zutun. Zur Zeit werden Online-Anti-Captcha-Dienste, die auf einen Mix aus maschinellem Lernen und menschlicher Intelligenz setzen, diesen Lösungen vorerst voraus sein.