Ist Process Mining in Summe zu teuer?
Celonis, Signavio (SAP). UiPath, Microsoft, Software AG, Mehrwerk, process.science und viele weitere Process Mining Tool-Anbieter mehr… der Markt rund um Process Mining ist stark umkämpft. Trotz der hohen Vielfalt an Tools, gilt Process Mining in der Einführung und Durchführung als teuer. Viele Unternehmen verzeichnen zwar erste Erfolge mit dieser Analysemethodik und den dafür geschaffenen Tools, hadern jedoch mit den hohen Kosten für Lizensierung und Betrieb.
 Dabei gibt es viele Hebel für Unternehmen, die Kosten für diese Analysen deutlich zu reduzieren, dabei gesamtheitlicher analysieren zu können und sich von einzelnen Tool-Anbietern unabhängiger zu machen. Denn die Herausforderung beginnt bereits mit denen eigentlichen Zielen von Process Mining für ein Unternehmen, und diese sind oft nicht einmal direkt finanziell messbar.
Dabei gibt es viele Hebel für Unternehmen, die Kosten für diese Analysen deutlich zu reduzieren, dabei gesamtheitlicher analysieren zu können und sich von einzelnen Tool-Anbietern unabhängiger zu machen. Denn die Herausforderung beginnt bereits mit denen eigentlichen Zielen von Process Mining für ein Unternehmen, und diese sind oft nicht einmal direkt finanziell messbar.
Process Mining bitte nicht nur auf Prozesskosten reduzieren
Tool-Anbieter werben tendenziell besonders mit der potenziellen Reduktion von Prozesskosten und und mit der Working Capital Optimierung. Bei hohen Lizenzierungskosten für die Tools, insbesondere für die Cloud-Lösungen der Marktführer, ist dies die erfolgversprechendste Marketing-Strategie. Typische Beispiele für die Identifikation von Kostensenkungspotenzialen sind Doppelarbeiten und unnötige Prozessschleifen sowie Wartezeiten in Prozessen. Working Capital- und Cash- Kosten sind in den Standardprozessen Order-to-Cash (z. B. Verspätete Zahlungen) und Procure-to-Pay (z. B. zu späte Zahlungen, nicht realisierte Rabatte) zu finden.
Diese Anwendungsfälle sind jedoch analytisch recht trivial und bereits mit einfacher BI (Business Intelligence) oder dedizierten Analysen ganz ohne Process Mining bereits viel schneller aufzuspüren. Oft bieten bereits ERP-Systeme eine eigene Erkennung hierfür an, die sich mit einfach gestrikter BI leicht erweitern lässt.
Richtige Wirkung, die so eigentlich nur Process Mining mit der visuellen Prozessanalyse erzeugen kann, zeigt sich vor allem bei der qualitativen Verbesserung von Prozessen, denn oft frustrieren eingefahrene Unternehmensprozesse nicht nur Mitarbeiter, Lieferanten und Partner, sondern auch Kunden. Dabei geht es z. B. um die Verbesserung von Prozessen in der Fertigung und Montage, in der Logistik, dem Einkauf, Sales und After Sales. Diese Anwendungszwecke dienen zur zeitlichen Beschleunigung oder Absicherung (Stabilisierung) von Prozessen, und damit zur Erhöhung des Kundennutzens. Jede qualitative Verbesserung wird sich letztendlich auch im quantitativen, finanziellen Maße auswirken, wenn auch nicht so einfach messbar.
Die Absicherung von Prozessen aus der Compliance-Perspektive ist eines der typischen Einsatzgebiete, für die Process Mining prädestiniert ist. Audit Analytics und Betrugserkennung gehören zu den häufigsten Anwendungsgebieten. Das senkt zwar grundsätzlich keine Prozesskosten, ist jedoch in Anbetracht immer komplexerer Prozessketten bittere Notwendigkeit.
Prozess Mining kann ferner auch zur Dokumentation von Geschäftsprozessen genutzt werden, als Vorlage für Sollprozesse. Die Analyse von bestehenden Prozessen kann dann dabei helfen, den aktuellen Zustand eines Prozesses zu dokumentieren und Unternehmen können diese Informationen nutzen, um Prozessdokumentationen zu aktualisieren und zu verbessern. Mit Process Mining können Vor- und Nachher-Vergleiche durchgeführt sowie situative Worst- und Best-Practise herausextrahiert werden. Dies bietet sich insbesondere vor und nach Migrationen von ERP-Systemen an.
Process Mining muss nicht (zu) teuer sein
Bei hohen Kosten für Process Mining ist der Druck einer Organisation sehr hoch, diese Kosten irgendwie mit hohen potenziellen (!) Einsparungen zu rechtfertigen. Die Prozesse mit dem höchsten Kostensenkungsversprechen erhalten dadurch den Vorzug, oft auch dann, obwohl andere Prozesse die nötige Prozesstransparenz eigentlich noch viel nötiger hätten.
Zumindest der Einstieg in Process Mining kann mit den richtigen Tools sehr leichtfüßig und günstig erfolgen, aber auch die Etablierung dieser Analysemethodik im weltweiten Konzern kann mit einigen Stellhebeln erheblich günstiger und (in Anbetracht der hohen Dynamik unter den Tool-Anbietern) nachhaltiger realisiert werden, als wie es von den größeren Anbietern vorgeschlagen wird.
Unabhängiges und Nachhaltiges Data Engineering
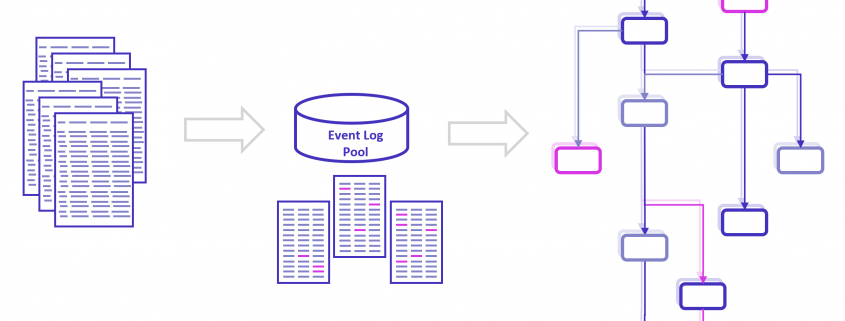
Die Arbeit hinter Process Mining kann man sich wie einen Eisberg vorstellen. Die sichtbare Spitze des Eisbergs sind die Reports und Analysen im Process Mining Tool. Das ist der Teil, den die meisten Analysten und sonstigen Benutzer des Tools zu Gesicht bekommen. Der andere Teil des Process Minings ist jedoch noch viel wesentlicher, denn es handelt sich dabei um das Fundament der Analyse: Die Datenmodellierung des Event Logs. Diese Arbeit ist der größere, jedoch unter der Oberfläche verborgene Teil des Eisbergs.
Jedes Process Mining Tool benötigt pro Use Case mindestens ein Event Log. Dabei handelt es sich um ein Prozessprotokoll mit universeller Mindestanforderung: Case, Activity, Timestamp
Diese Event Logs in einem Process Mining Tool zu modellieren und individuell anzupassen, ist langfristig keine gute Idee und erinnert an die Anfänge der Business Intelligence, als BI-Analysten Daten direkt in Tools wie Qlik Sense oder Power BI luden und für sich individuell modellierten.
Wie anfangs erwähnt, haben Unternehmen bei der Einführung von Process Mining die Qual der Wahl. Oft werden langwierige und kostenintensive Auswahlprozesse für die jeweiligen Tools angestoßen, damit die Wahl auf der augenscheinlich richtige Tool fällt.
Eine bessere Idee ist es daher, Event Logs nicht in einzelnen Process Mining Tools aufzubereiten, sondern zentral in einem dafür vorgesehenen Data Warehouse zu erstellen, zu katalogisieren und darüber auch die grundsätzliche Data Governance abzusichern. Die modellierten Daten können dann jedem Process Mining Tool zur Verfügung gestellt werden. Während sich Process Mining Tools über die Jahre stark verändern, bleiben Datenbanktechnologien für Data Warehousing über Jahrzehnte kompatibel und können in ihnen aufbereitete Event Logs allen Tools zur Verfügung stellen. Und übrigens lässt sich mit diesem Ansatz auch sehr gut eine gesamtheitlichere Verknüpfung realisieren und die Perspektive dynamisch verändern, was neuerdings als Object-centric Process Mining beworben wird, mit der richtigen Datenmoedellierung in einem Process Mining Data Warehouse für jedes Tool zu erreichen ist.
Nicht alles um jeden Preis in die Public Cloud
Unter der häufigen Prämisse, dass alle ERP-Rohdaten in eine Cloud geladen werden müssen, entstehen Kosten, die durchaus als überhöht und unnötig angesehen werden können. Daten-Uploads in eine Cloud-Lösung für Process Mining sollten nach Möglichkeit minimal ausfallen und lassen sich durch genaueres Anforderungsmanagement in den meisten Fällen deutlich reduzieren, verbunden mit Einsparungen bei Cloud-Kosten. Idealerweise werden nur fertige Event-Logs bzw. objekt-zentrische Datenmodelle in die Cloud geladen, nicht jedoch die dafür notwendigen Rohdaten.
Für besonders kritische Anwendungsfälle kann es von besonderem Stellenwert sein, einen Hybrid-Cloud-Ansatz anzustreben. Dabei werden besonders kritische Daten in ihrer granularen Form in einer Private Cloud (i.d.R. kundeneigenes Rechenzentrum) gehalten und nur die fertigen Event Logs in die Public Cloud (z. B. Celonis Process Mining) übertragen.
Mit AI ist mehr möglich als oft vermutet
Neben den einfachen Anwendungsfällen, die einige Tool-Anbieter bereits eingebaut haben (z. B. Matching von Zahlungsdaten zur Doppelzahlungserkennung oder die Vorhersage von Prozesszeiten), können mit Machine Learning bzw. Deep Learning auch anspruchsvollere Varianten-Cluster und Anomalien erkannt werden.
Unstrukturierte Daten können dank AI in Process Mining mit einbezogen werden, dazu werden mit Named Entity Recognition (NER, ein Teilgebiet des NLP) Vorgänge und Aktivitäten innerhalb von Dokumenten (z. B. Mails, Jira-Tickets) extrahiert und gemeinsam mit den Meta-Daten (z. B. Zeitstempel aus dem Dokument) in ein strukturiertes Event Log für Process Mining transformiert. Ähnliches lässt sich mit AI für Computer Vision übrigens auch auf Abläufe aus Videoaufnahmen durchführen. Dank AI werden damit noch viel verborgenere Prozesse sichtbar. Diese AI ist in noch keiner Process Mining Software zu finden, kann jedoch bausteinartig dem Process Mining Data Warehouse vorgeschaltet werden.
Fazit
Nicht all zu selten ist Process Mining den anwenden Unternehmen in Summe zu teuer, denn bereits einige Unternehmen sind über die Kosten gestolpert. Andere Unternehmen begrenzen die Kosten mit dem restriktiven Umgang mit Benuter-Lizenzen oder Anwendungsfällen, begrenzen damit jedoch auch den Analyseumfang und schöpfen nicht das volle Potenzial aus. Dies muss jedoch nicht sein, denn Kosten für Data Loads, Cloud-Hosting und Benutzerlizenzen für Process Mining lassen sich deutlich senken, wenn Process Mining als die tatsächliche Analyse-Methode verstanden und nicht auf ein bestimmtes Tool reduziert wird.
Zu Beginn kann es notwendig sein, Process Mining in einer Organisation überhaupt erst an den Start zu bringen und erste Erfolge zu erzielen. Unternehmen, die Process Mining und die damit verbundene Wirkung in Sachen Daten- und Prozesstransparenz, erstmals erlebt haben, werden auf diese Analysemethodik so schnell nicht mehr verzichten wollen. Schnelle erste Erfolge lassen sich mit nahezu jedem Tool erzielen. Nach Pilot-Projekten sollte der konzernweite Rollout jedoch in Sachen Performance, Kosten-Leistungsverhältnis und spätere Unabhängigkeit überdacht werden, damit Process Mining Initiativen langfristig mehr wirken als sie kosten und damit Process Mining auch bedenkenlos und ohne Budget-Engpässe qualitative Faktoren der Unternehmensprozesse verbessern kann.
Mit den richtigen Überlegungen fahren Sie die Kosten für Process Mining runter und den Nutzen hoch.
 Nach dutzenden
Nach dutzenden