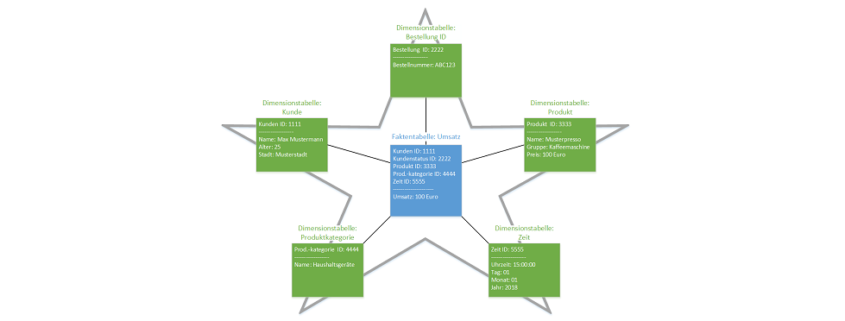
Datenmodell: Sternschema
Ob es unsere Schritte während des Sports sind, Klicks auf Websiten oder auch Geschäftszahlen eines Unternehmens – all diese Informationen werden in Form von Daten gespeichert. Dabei fallen große Mengen an Daten an, die in der Regel in einer relationalen Datenbank gespeichert werden, um sie besonders gut administrieren zu können.
Gerade in einem Unternehmen ist es wichtig, dass mehrere Benutzer parallel und mit wenig Verzögerung Anfragen und Änderungen in den Daten durchführen können. Daher werden viele Datenbanken in Unternehmen als OLTP-Datenbank-Systeme ausgelegt. OLTP steht für Online Transaction Processing, auch Echtzeit-Transaktionsverarbeitung ist dafür optimiert, schnelle und parallele Zugriffe auf Daten in der Datenbank zu gewährleisten.
Möchte man hingegen Daten auswerten und analysieren, sind OLTP-Datenbanken-Systeme weniger geeignet, da sie nicht für diese Art von Anfragen konzipiert worden sind. Um effektiv analytische Befehle an eine Datenbank stellen zu können, werden daher Datenbanken genutzt, die mit einer OLAP-Verarbeitung arbeiten. OLAP ist die Abkürzung für Online Analytical Processing. Im Gegensatz zu OLTP, in welchen die Daten in einem zweidimensionalen Modell gespeichert werden, sind Daten in einem OLAP-System in einer multidimensionalen Struktur untergebracht, welche für die Durchführung komplexer Analysebefehle optimiert ist.
Für Analysen werden oft Daten aus mehreren Datenbanken benötigt, weswegen sie in einem Datenlager – oder auch Data Warehouse genannt – zusammengefasst und gespeichert werden. Ein Data Warehouse, welche auf der OLAP-Verarbeitung basiert, ist somit eine für Analysezwecke optimierte Datenbank.
Es gibt verschiedene Datenmodelle um die Daten in einem Data Warehouse anzulegen. Das verbreiteste Datenmodell für diese Zwecke ist das sogenannte Sternen-Schema (Star Schema). Neben dem Sternen-Schema gibt es auch die sogenannten Galaxy- und Snowflake-Schemen, die wiederum eine Erweiterung des zuerst genannten Datenmodells sind. In diesem Artikel werden wir das Sternschema näher beleuchten.
Aufbau und Funktionsweise
Bei einem Sternschema werden die Daten grundlegend in zwei Gruppen unterteilt:
- Fakten, manchmal auch Metriken, Messwerte oder Kennzahlen genannt, sind die zu verwaltenden bzw. die zu analysierenden Daten und werden fortlaufend in der Faktentabelle gespeichert. Beispielhaft für Fakten sind Umsätze sowie Verkaufszahlen eines Unternehmens. Sie haben stets eine numerische Form.
- Dimensionen sind die Attribute bzw. Eigenschaften der Fakten und beschreiben sozusagen die Fakten im Detail. Diese werden in Dimensionstabellen gelistet. Jeder Dimensionsdatensatz bzw. jede Zeile einer Dimensionstabelle wird durch Primärschlüssel eindeutig identifiziert. Diese Schlüssel werden in der Faktentabelle als Fremdschlüssel gespeichert und somit sind Dimensions- und Faktentabelle miteinander verknüpft.
Beispiel: Max Mustermann, 25 Jahre alt, wohnhaft in Musterstadt hat eine Kaffeemaschine mit dem Namen ‘Musterpresso’ am 01.01.2018 um 15:00:00 gekauft.
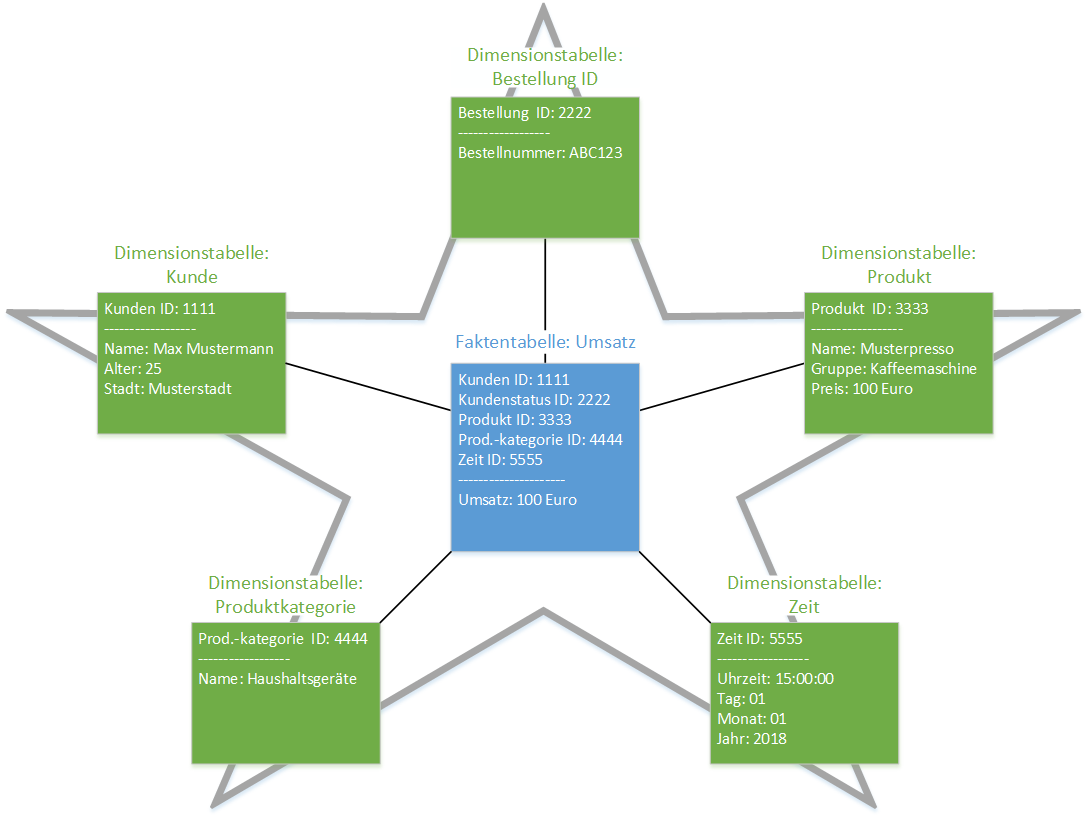
Wie in der Abbildung dargestellt, werden die Details, als Attribute dargestellt, vom Kunden wie Namen, Alter oder Wohnort in der Dimensionstabelle “Kunde” gespeichert und mit dem Primärschlüssel (in diesem Beispiel “1111”) gekennzeichnet. Dieser wird in der Faktentabelle als Fremdschlüssel gespeichert. Analog zu den Daten vom Kunden werden auch Dimensionstabellen für die Größen
- Bestellung,
- Produkt,
- Produktkategorie und
- Zeit gebildet.
Die Fakten, welche in diesem Beispiel der Umsatz von Max Mustermann ein Fakt wäre, können nun mithilfe der Fremdschlüssel
- Kunden ID,
- Bestellung ID,
- Produkt ID,
- Produktkategorie ID und
- Zeit
aus der Faktentabelle aufgerufen werden.
Bei der Bildung von Tabellen ist es möglich, dass identische Werte mehrfach gespeichert werden. Dabei können Redundanzen und Anomalien in der Datenbank enstehen, welche zusätzlich einen erhöhten Speicherbedarf erfordern. Um dies zu verhindern werden Tabellen normalisiert. Bei einer Normalisierung einer Tabelle bzw. einer Tabellenstruktur wird es angestrebt, Redundanzen bis auf ein Maximum zu reduzieren. Je nach Grad der Normalisierung können diese in verschiedene Normalformen (1NF -2NF-3NF-BCNF-4NF-5NF) unterteilt werden.
Die Normalisierung in eine höhere Normalform hat jedoch zur Folge, dass die Abfrage-Performance abnimmt. Da das Sternschema-Modell darauf ausgelegt ist Leseoperationen effizient durchzuführen, sind Faktentabellen in der dritten Normalform (3NF) abgespeichert, da alle Redundanzen in dieser Form beseitigt worden sind und dennoch eine hohe Performance gewährleistet. Dimensionstabellen sind hingegen nur bis zur zweiten Normalform (2NF) optimiert. Es werden also bewusst Redundanzen und ein erhöhter Speicherbedarf in den Dimensionstabellen für eine schnelle Abfrage der Daten in Kauf genommen.
Vor- und Nachteile
Wie bereits erwähnt, sind Dimensionstabellen im Sternschema nicht vollständig normalisiert. Damit nimmt man zugunsten höherer Performance mögliche Anomalien und auch einen erhöhten Speicherbedarf in Kauf. Durch das einfache Modell ist dafür jedoch eine intuitive Bedienung möglich und auch Veränderungen sowie Erweiterungen des Modell sind leicht realisierbar.
| Vorteile | Nachteile |
| Einfaches Modell ermöglicht eine intuitive Bedienung. | Durch mehrfaches Speichern identischer Werte steigt die Redundanz in den Dimenionstabellen |
| Veränderungen und Erweiterungen können leicht umgesetzt werden. | Bei häufigen Abfragen sehr großer Dimensionstabellen verschlechtern sich die Antwortzeiten |
| Durch Verzicht der Normalisierung in den Dimensionstabellen ist die hierarchische Beziehung innerhalb einer Dimension leicht darstellbar | Erhöhter Speicherbedarf durch Nicht-Normalisierung der Dimensionstabellen |
Zusammenfassung
Das Sternschema ist ein Datenmodell, welches für analytische Zwecke im Data Warehouse und bei OLAP-Anwendungen zum Einsatz kommt. Es ist darauf optimiert, effiziente Leseoperationen zu gewährleisten.
Der Name des Modells beruht auf der sternförmigen Anordnung von Dimensionstabellen um die Faktentabelle, wobei die Dimensionstabellen die Attribute der Fakten beinhalten und in den Faktentabellen die zu analysierenden Größen gespeichert sind. Charakteristisch ist dabei, dass die Dimensionstabellen nicht bis zur dritten Normalform normalisiert sind. Der sich daraus ergebende Vorteil ist die schnelle Verarbeitung von Abfragen. Auch ist die intuitive Bedienung ein positiver Aspekt des einfachen Datenmodells. Jedoch können durch den Verzicht der Normalisierung Redundanzen innerhalb der Dimensionstabellen durch mehrfache Speicherung von identischen Werten entstehen. Ebenfalls ist bei häufigen Anfragen von großen Dimensionstabellen ein verschlechtertes Antwortverhalten feststellbar.
Daher sind sie vor allem dann effektiv, wenn
- schnelle Anfrageverarbeitungen notwendig sind,
- sich schnell ändernde Datenstrukturen (der Original-Daten) vorliegen,
- Dimensionstabellen in ihrer Größe überschaubar bleiben,
- und ein breites Spektrum an Benutzern Zugriff auf die Daten benötigt.