Understanding Linear Regression with all Statistical Terms
Linear Regression Model – This article is about understanding the linear regression with all the statistical terms.
What is Regression Analysis?
regression is an attempt to determine the relationship between one dependent and a series of other independent variables.
Regression analysis is a form of predictive modelling technique which investigates the relationship between a dependent (target) and independent variable (s) (predictor). This technique is used for forecasting, time series modelling and finding the causal effect relationship between the variables. For example, relationship between rash driving and number of road accidents by a driver is best studied through regression.
Why do we use Regression Analysis?
As mentioned above, regression analysis estimates the relationship between two or more variables. Let’s understand this with an easy example:
Let’s say, you want to estimate growth in sales of a company based on current economic conditions. You have the recent company data which indicates that the growth in sales is around two and a half times the growth in the economy. Using this insight, we can predict future sales of the company based on current & past information.
There are multiple benefits of using regression analysis. They are as follows:
It indicates the significant relationships between dependent variable and independent variable. It indicates the strength of impact of multiple independent variables on a dependent variable. Regression analysis also allows us to compare the effects of variables measured on different scales, such as the effect of price changes and the number of promotional activities. These benefits help market researchers / data analysts / data scientists to eliminate and evaluate the best set of variables to be used for building predictive models.
There are various kinds of regression techniques available to make predictions. These techniques are mostly driven by three metrics (number of independent variables, type of dependent variables and shape of regression line).
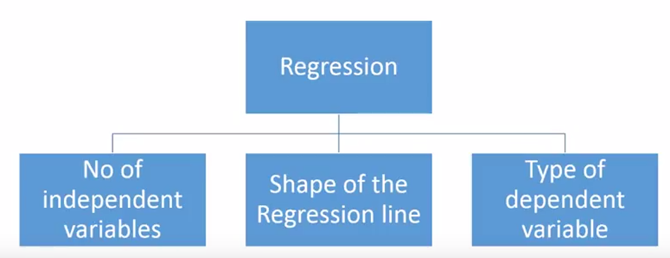
Number of independent variables, shape of regression line and type of dependent variable.
What is Linear Regression?
Linear Regression is the supervised Machine Learning model in which the model finds the best fit linear line between the independent and dependent variable i.e it finds the linear relationship between the dependent and independent variable.
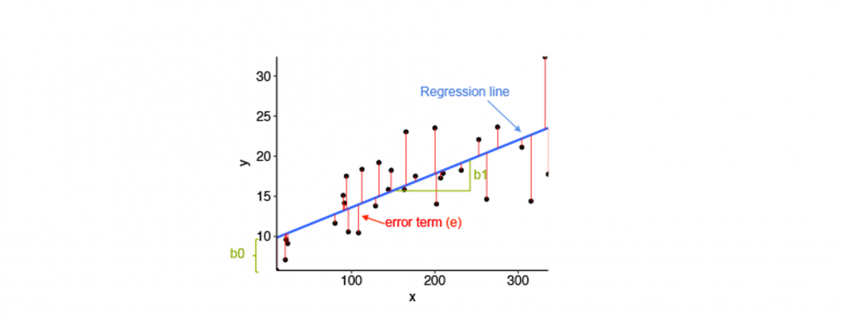
- Equation of Simple Linear Regression, where bo is the intercept, b1 is coefficient or slope, x is the independent variable and y is the dependent variable.
Equation of Multiple Linear Regression, where bo is the intercept, b1,b2,b3,b4…,bn are coefficients or slopes of the independent variables x1,x2,x3,x4…,xn and y is the  dependent variable.
dependent variable.
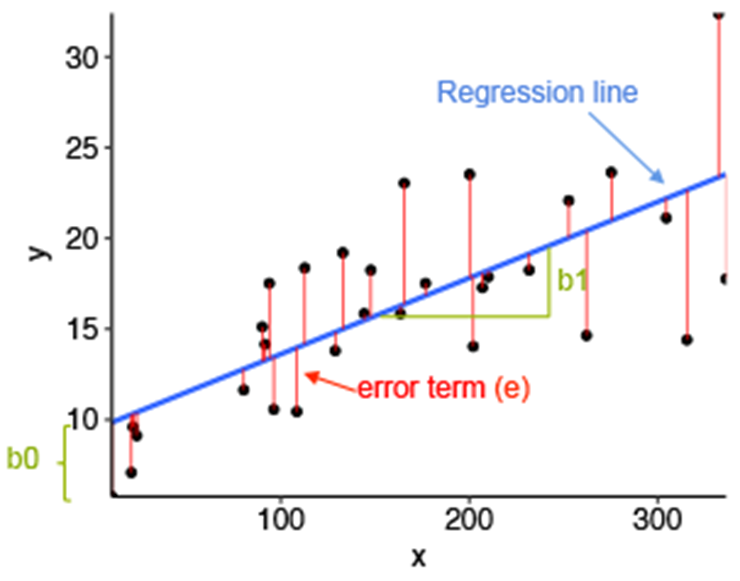
Linear regression and its error termin per value
Mathematical Approach:
Residual/Error = Actual values – Predicted Values
Sum of Residuals/Errors = Sum(Actual- Predicted Values)
Square of Sum of Residuals/Errors = (Sum(Actual- Predicted Values))^2

Application of Linear Regression:
Real-world examples of linear regression models
- Businesses often use linear regression to understand the relationship between advertising spending and revenue.
- Medical researchers often use linear regression to understand the relationship between drug dosage and blood pressure of patients.
- Agricultural scientists often use linear regression to measure the effect of fertilizer and water on crop yields.
- Data scientists for professional sports teams often use linear regression to measure the effect that different training regimens have on player performance.
- Stock predictions: A lot of businesses use linear regression models to predict how stocks will perform in the future. This is done by analyzing past data on stock prices and trends to identify patterns.
- Predicting consumer behavior: Businesses can use linear regression to predict things like how much a customer is likely to spend. Regression models can also be used to predict consumer behavior. This can be helpful for things like targeted marketing and product development. For example, Walmart uses linear regression to predict what products will be popular in different regions of the country.
Assumptions of Linear Regression:
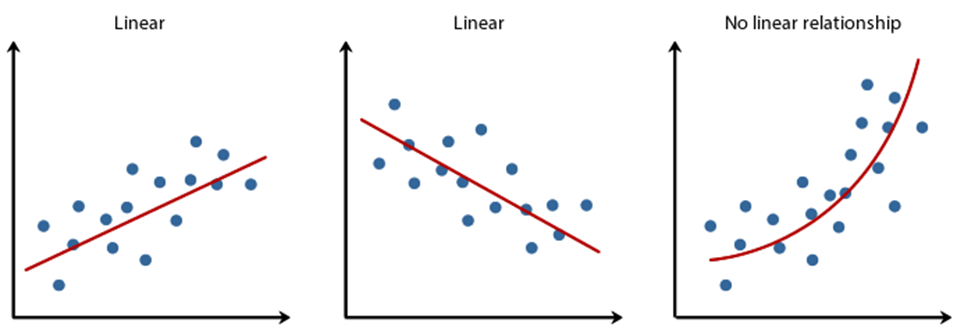
Linearity: It states that the dependent variable Y should be linearly related to independent variables. This assumption can be checked by plotting a scatter plot between both variables.
Normality: The X and Y variables should be normally distributed. Histograms, KDE plots, Q-Q plots can be used to check the Normality assumption.
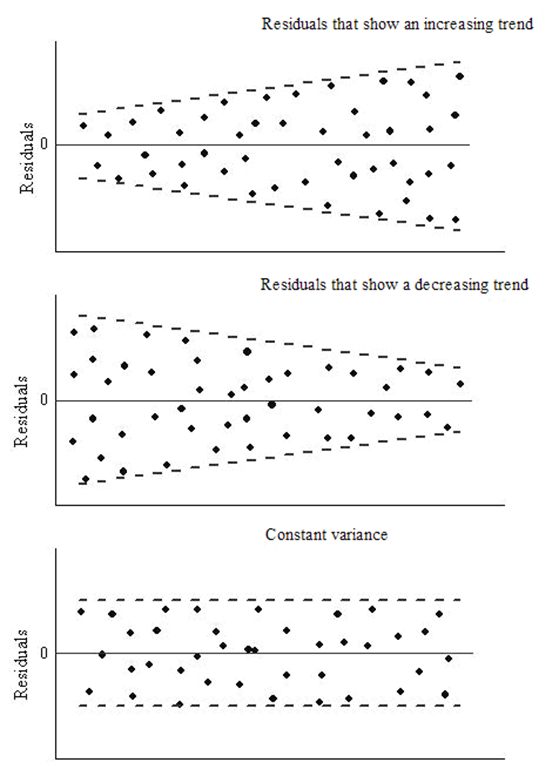
Homoscedasticity: The variance of the error terms should be constant i.e the spread of residuals should be constant for all values of X. This assumption can be checked by plotting a residual plot. If the assumption is violated then the points will form a funnel shape otherwise they will be constant.
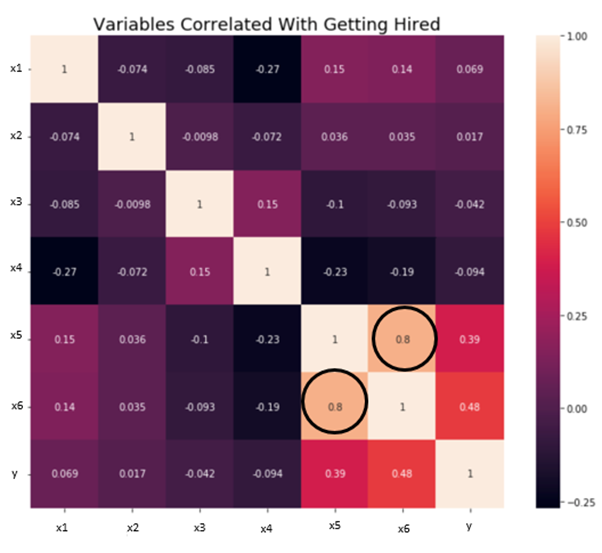
Independence/No Multicollinearity: The variables should be independent of each other i.e no correlation should be there between the independent variables. To check the assumption, we can use a correlation matrix or VIF score. If the VIF score is greater than 5 then the variables are highly correlated.
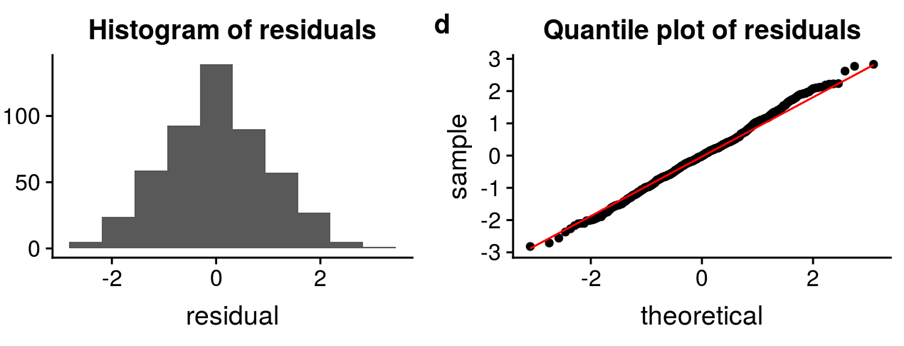
The error terms should be normally distributed. Q-Q plots and Histograms can be used to check the distribution of error terms.
No Autocorrelation: The error terms should be independent of each other. Autocorrelation can be tested using the Durbin Watson test. The null hypothesis assumes that there is no autocorrelation. The value of the test lies between 0 to 4. If the value of the test is 2 then there is no autocorrelation.

 , where
, where 


 .
. .
. is a real symmetric matrix, there exist a rotation matrix
is a real symmetric matrix, there exist a rotation matrix  such that
such that  , where
, where  and
and  .
.  are eigenvectors corresponding to
are eigenvectors corresponding to  respectively.
respectively. .
. are positive semidefinite and real symmetric, which means you can always diagonalize
are positive semidefinite and real symmetric, which means you can always diagonalize  , based on
, based on  , such that
, such that 

 , where
, where  . I also explained that PCA is a case where
. I also explained that PCA is a case where  . Assume that you have got an orthonormal rotation matrix
. Assume that you have got an orthonormal rotation matrix  which diagonalizes
which diagonalizes  which are in red in the figure below. Projecting a point
which are in red in the figure below. Projecting a point  on the new orthonormal basis is simple: you just have to multiply
on the new orthonormal basis is simple: you just have to multiply  with
with  . Let
. Let  be
be  , and then
, and then  . You can see
. You can see  are
are  respectively, and the left side of the figure below shows the idea. When you replace the orginal orthonormal basis
respectively, and the left side of the figure below shows the idea. When you replace the orginal orthonormal basis  with
with  to
to  by a rotation matrix
by a rotation matrix 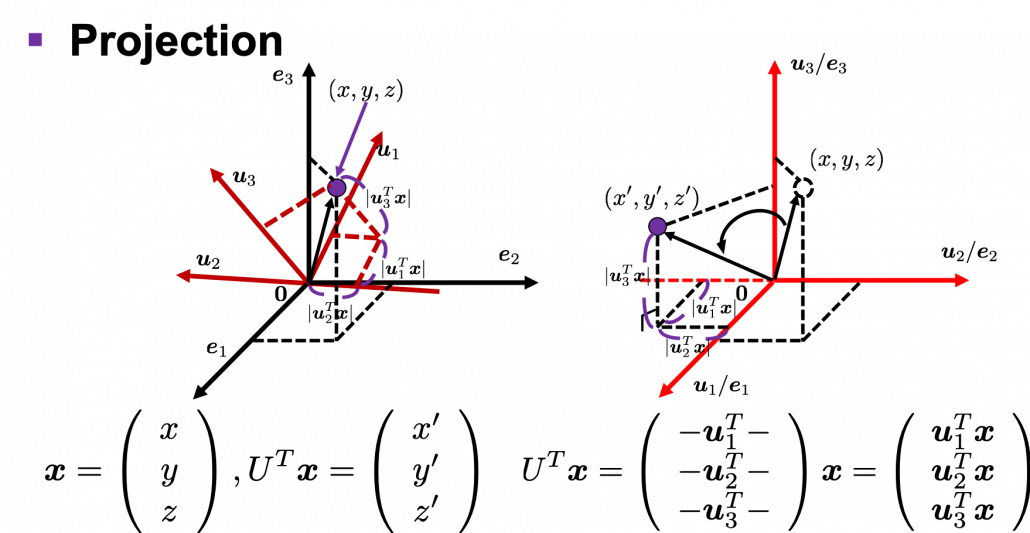
 , with one corner of the cube located at the origin point of those axes. The purple dot denotes the corner of the cube directly opposite the origin corner. The cube is rotated in three dimensions, with the origin corner staying fixed in place. After the rotation with a pivot at the origin, the edges of the cube are now aligned with a new set of orthogonal axes
, with one corner of the cube located at the origin point of those axes. The purple dot denotes the corner of the cube directly opposite the origin corner. The cube is rotated in three dimensions, with the origin corner staying fixed in place. After the rotation with a pivot at the origin, the edges of the cube are now aligned with a new set of orthogonal axes  , shown in red. You might understand that more clearly with an equation:
, shown in red. You might understand that more clearly with an equation: 
 . In short this rotation means you keep relative position of
. In short this rotation means you keep relative position of 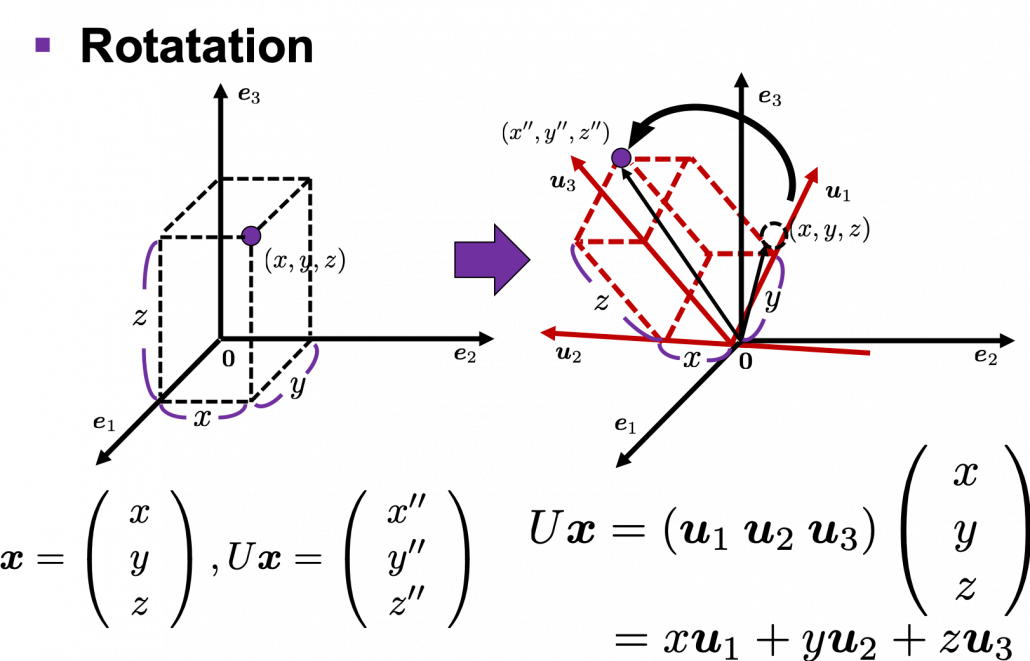
 is an orthonormal matrix and a vector
is an orthonormal matrix and a vector  , you can project
, you can project  or rotate it to
or rotate it to  , where
, where  and
and  . In other words
. In other words  , which means you can rotate back
, which means you can rotate back  to the original point
to the original point  , where
, where  is a real symmetric matrix. The distribution of
is a real symmetric matrix. The distribution of  is quadratic curves whose center point covers the origin, and it is known that you can express this distribution in a much simpler way using eigenvectors. When you project this function on eigenvectors of
is quadratic curves whose center point covers the origin, and it is known that you can express this distribution in a much simpler way using eigenvectors. When you project this function on eigenvectors of  for
for 



 . You can always diagonalize real symmetric matrices, so the formula implies that the shapes of quadratic curves largely depend on eigenvectors. We are going to see this in detail in the next section.
. You can always diagonalize real symmetric matrices, so the formula implies that the shapes of quadratic curves largely depend on eigenvectors. We are going to see this in detail in the next section. denotes an inner product of
denotes an inner product of  .
.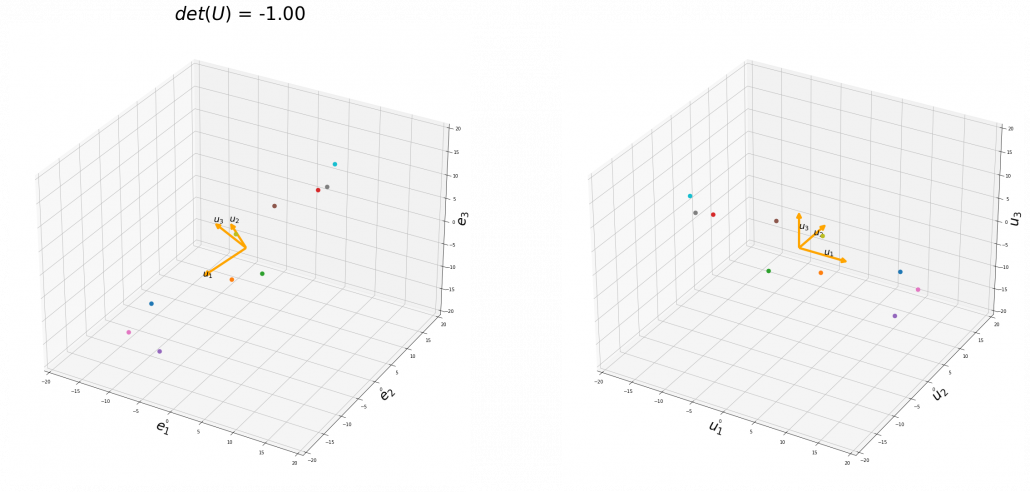
 , and in the case above
, and in the case above  was
was  , and you needed to flip one axis to make the determinant
, and you needed to flip one axis to make the determinant  . In the example in the figure below, you can match the basis. This also can be generalized to higher dimensions, but that is also beyond the scope of this article series. If you are really interested, you should prepare some coffee and snacks and textbooks on linear algebra, and some weekends.
. In the example in the figure below, you can match the basis. This also can be generalized to higher dimensions, but that is also beyond the scope of this article series. If you are really interested, you should prepare some coffee and snacks and textbooks on linear algebra, and some weekends.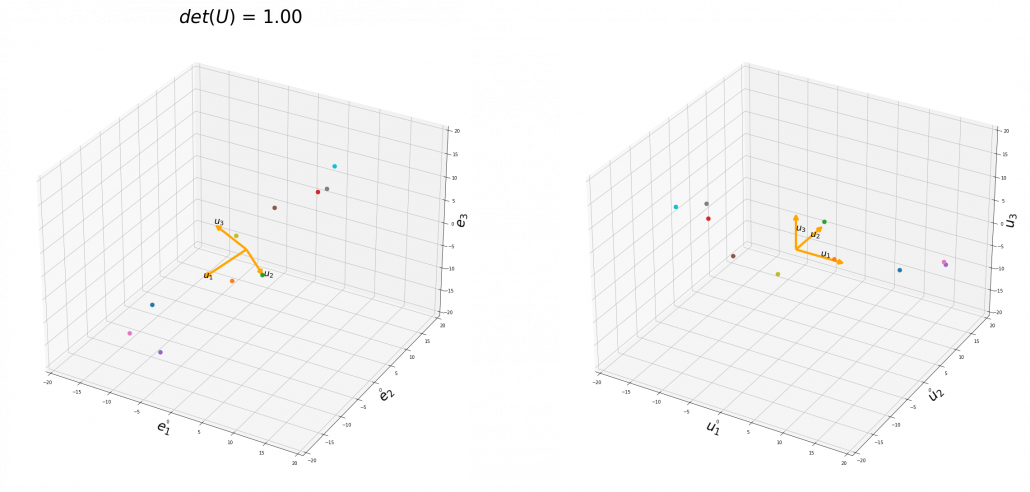
 , you can rotate the original ellipsoid so that it fits the data well.
, you can rotate the original ellipsoid so that it fits the data well.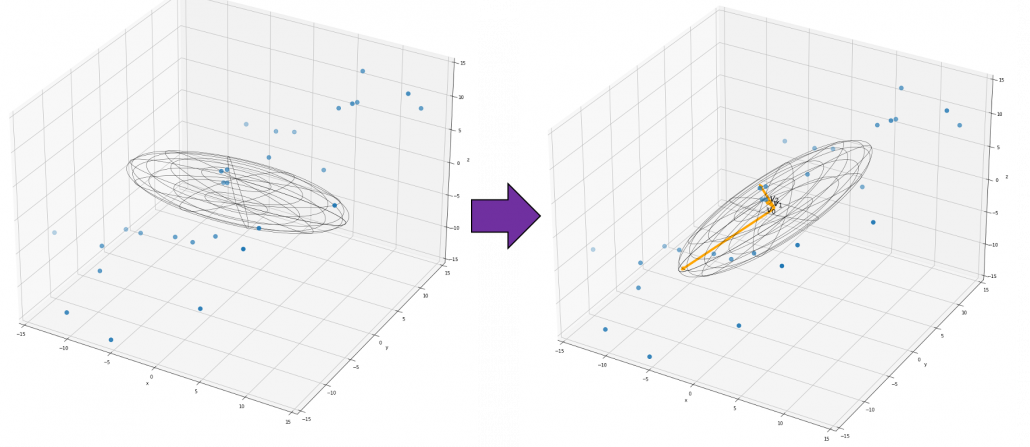
 , where
, where  , not
, not  .
. , where at least one of
, where at least one of  is not
is not  . Let
. Let  , then the quadratic curves can be simply denoted with a
, then the quadratic curves can be simply denoted with a  matrix
matrix  as follows:
as follows:  ,
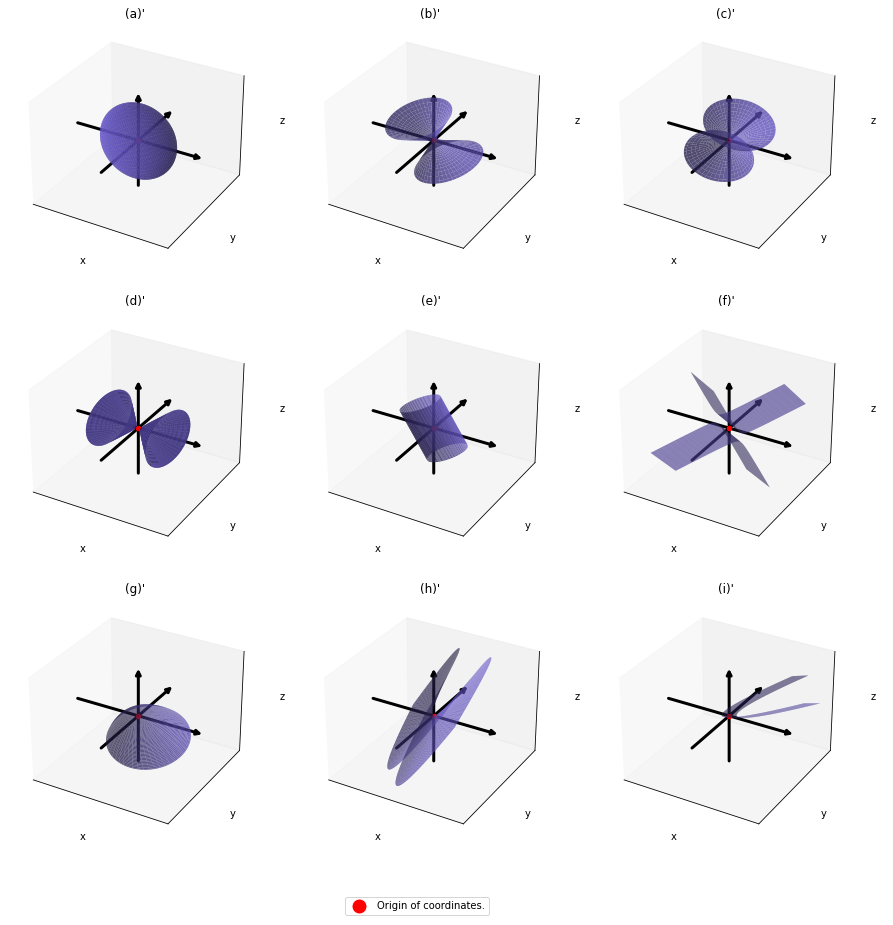
,  . General quadratic curves are roughly classified into the 9 types below.
. General quadratic curves are roughly classified into the 9 types below.
 .
.
 symmetric matrix
symmetric matrix  , there exist orthogonal/orthonormal matrices
, there exist orthogonal/orthonormal matrices  , where
, where 
 . After you apply rotation by
. After you apply rotation by 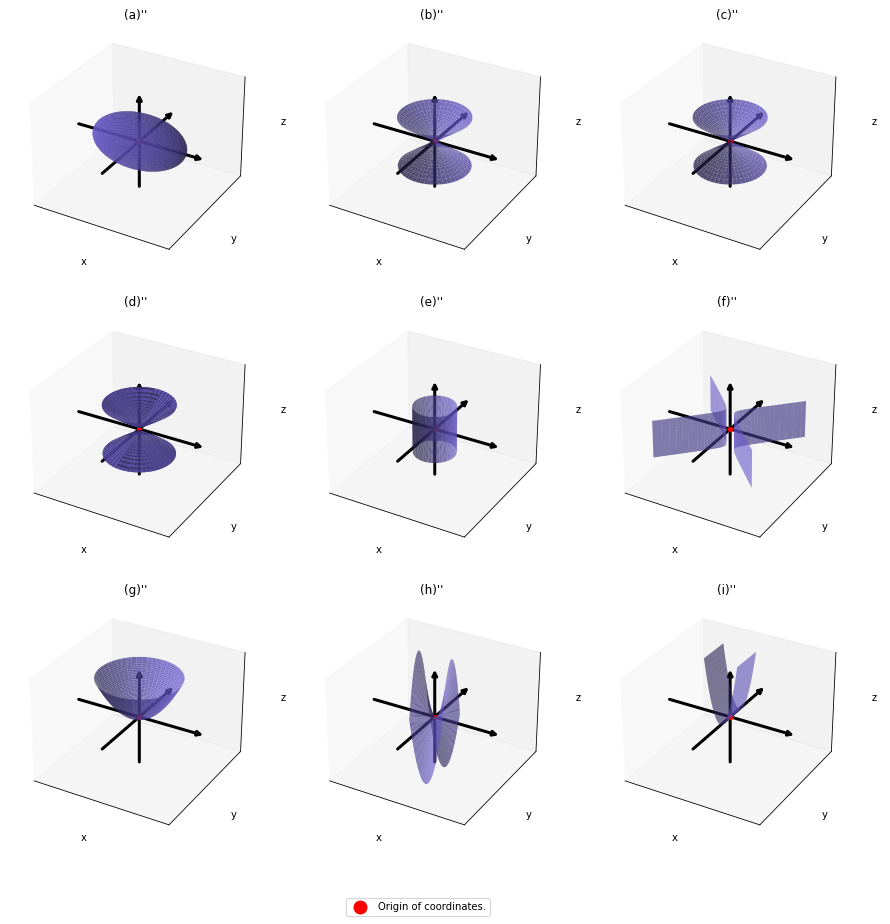




 .
. , those points
, those points  . That means the rotation of the original quadratic curve with
. That means the rotation of the original quadratic curve with  . Also it is known that when
. Also it is known that when  , with proper translations and rotations, the quadratic curve
, with proper translations and rotations, the quadratic curve  in a very simple way by projecting
in a very simple way by projecting  in two ways. One is a normal “functions”
in two ways. One is a normal “functions”  , and the others are “curves”
, and the others are “curves”  . “Functions” get an input
. “Functions” get an input  or
or  . However if you replace
. However if you replace  of (g)”, (h)”, and (i)” with
of (g)”, (h)”, and (i)” with  , you can interpret the “curves” as “functions” which are denoted as
, you can interpret the “curves” as “functions” which are denoted as  . This might sounds too obvious to you, and my point is you can visualize how values of “functions” change only when the inputs are 2 dimensional.
. This might sounds too obvious to you, and my point is you can visualize how values of “functions” change only when the inputs are 2 dimensional. real matrices
real matrices  have two eigenvalues
have two eigenvalues  , the distribution of quadratic curves can be roughly classified to the following three types.
, the distribution of quadratic curves can be roughly classified to the following three types. and
and  are positive or negative.
are positive or negative. , and thier curves look like the three graphs below.
, and thier curves look like the three graphs below.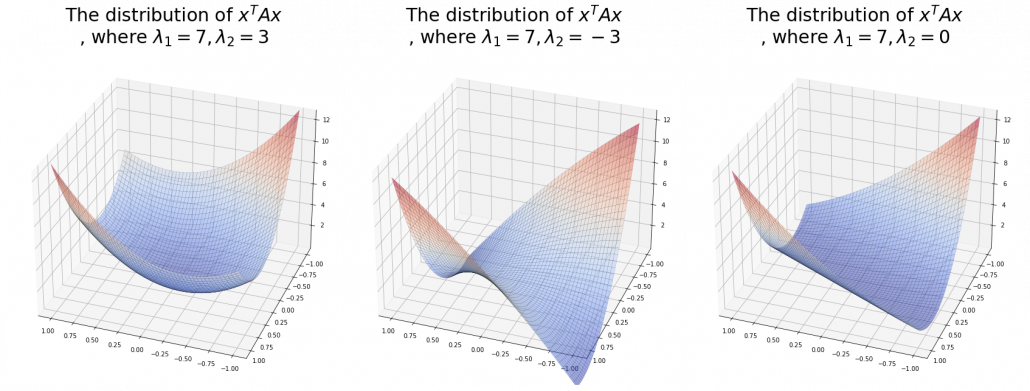
 ,
,  is the gradient of the direction. You can see that more clearly when you restrict the distribution of
is the gradient of the direction. You can see that more clearly when you restrict the distribution of  , which is classified to (g), the distribution looks like the left side, and if you restrict the distribution in the unit circle, the distribution looks like a bowl like the middle and the right side. When you move in the direction of
, which is classified to (g), the distribution looks like the left side, and if you restrict the distribution in the unit circle, the distribution looks like a bowl like the middle and the right side. When you move in the direction of  , you can climb the bowl as as high as
, you can climb the bowl as as high as  as high as
as high as 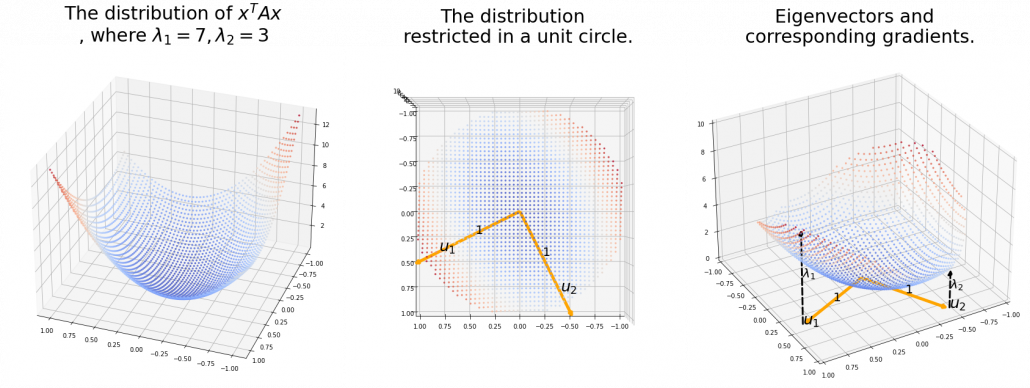
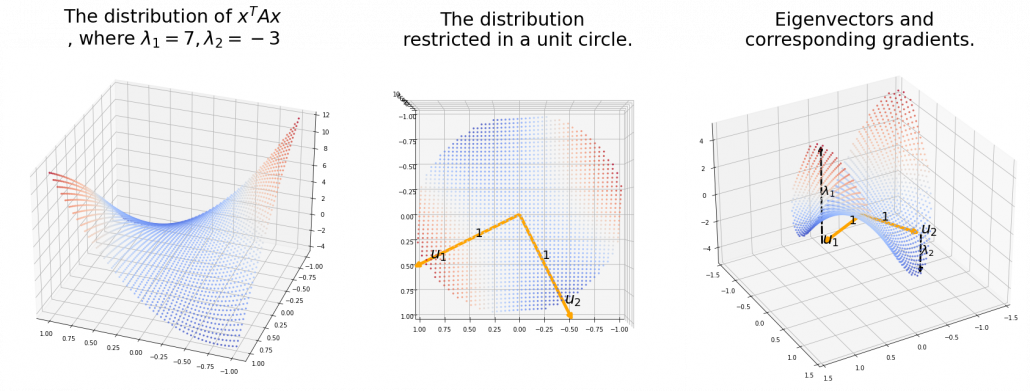
 . Hence, if you project
. Hence, if you project  , quadratic curves formed by a covariance matrix
, quadratic curves formed by a covariance matrix 
 . This shows that you can re-weight
. This shows that you can re-weight  , the coordinates of data projected projected on eigenvectors of
, the coordinates of data projected projected on eigenvectors of  , as I have visualized in the case of (g) type curve in the figure above.
, as I have visualized in the case of (g) type curve in the figure above.

 .
. the resulting cross section does not fit the original data well because the equation of the cross section is
the resulting cross section does not fit the original data well because the equation of the cross section is  The figure below is an example of slicing the same
The figure below is an example of slicing the same  , and the resulting cross section.
, and the resulting cross section.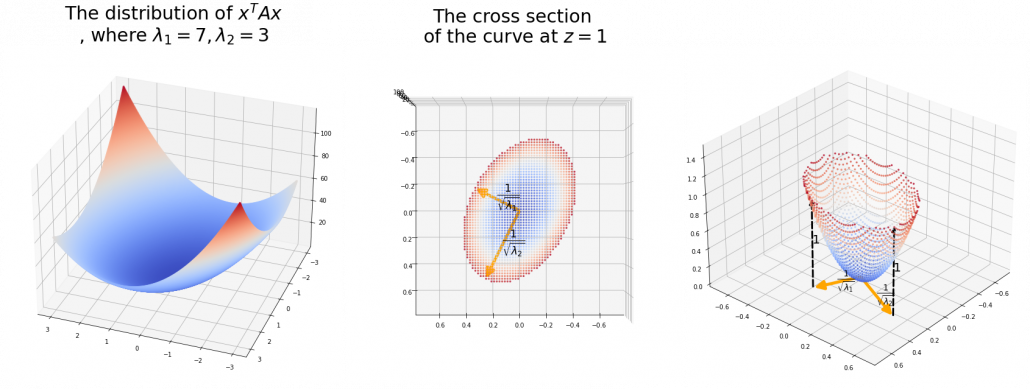
 is the radius of the ellipsoid corresponding to
is the radius of the ellipsoid corresponding to  , where
, where  .
.  means you multiply each eigenvalue to each element of
means you multiply each eigenvalue to each element of 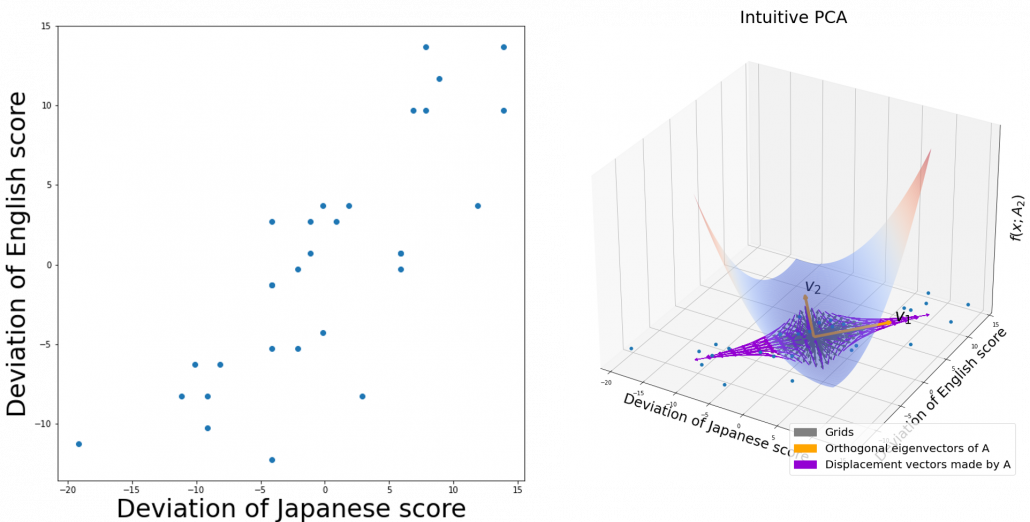
 , the ellipsoid which fits the distribution the best is
, the ellipsoid which fits the distribution the best is  . You might have seen the part
. You might have seen the part 
 somewhere else. It is the exponent of general Gaussian distributions:
somewhere else. It is the exponent of general Gaussian distributions: 
 . It is known that the eigenvalues of
. It is known that the eigenvalues of  are
are  , and eigenvectors corresponding to each eigenvalue are also
, and eigenvectors corresponding to each eigenvalue are also  respectively. Hence just as well as what we have seen, if you project
respectively. Hence just as well as what we have seen, if you project  on each eigenvector of
on each eigenvector of  be
be  be
be  , where
, where  . Just as we have seen,
. Just as we have seen, 



 . Hence
. Hence 
 .
.
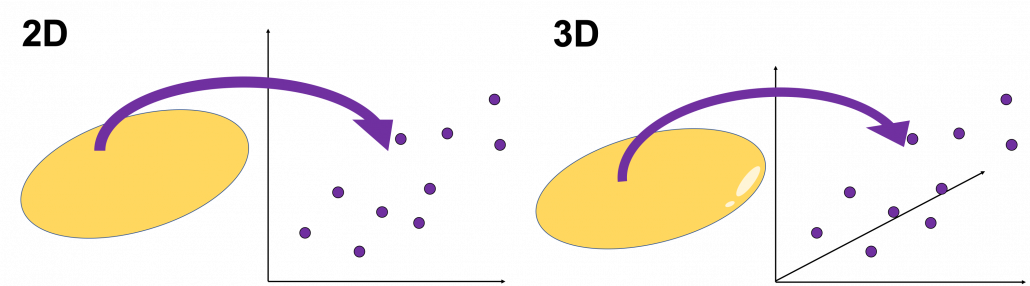
 matrix, the formula of a D-dimensional ellipsoid whose center is identical to the origin point is as follows:
matrix, the formula of a D-dimensional ellipsoid whose center is identical to the origin point is as follows:  , where
, where  . As is always the case with formulas in data science, you can visualize such ellipsoids if you are talking about 1, 2, or 3 dimensional data like in the figure below, but in general D-dimensional space, it is theoretical/imaginary stuff on blackboards.
. As is always the case with formulas in data science, you can visualize such ellipsoids if you are talking about 1, 2, or 3 dimensional data like in the figure below, but in general D-dimensional space, it is theoretical/imaginary stuff on blackboards.
 , where
, where  or
or  , where
, where  . These are special cases of the equation
. These are special cases of the equation  . In this case the axes of ellipsoids the same as those of the coordinate system. Thus in this simple case,
. In this case the axes of ellipsoids the same as those of the coordinate system. Thus in this simple case,  or
or  .
. as below (The samples are plotted in purple). Intuitively, the data “swell” the most along the vector
as below (The samples are plotted in purple). Intuitively, the data “swell” the most along the vector  expresses the data in a better way, and you you can get new coordinate points of the samples by projecting them on new axes as done with yellow lines below.
expresses the data in a better way, and you you can get new coordinate points of the samples by projecting them on new axes as done with yellow lines below.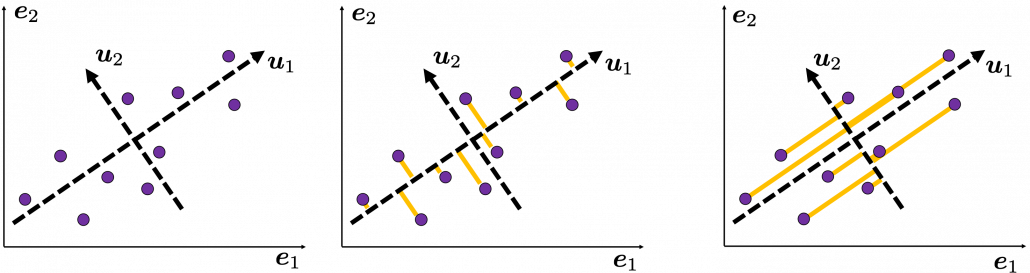
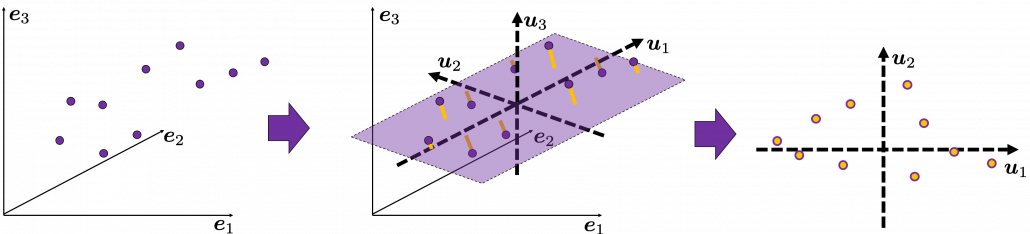
 as below, the data “swell” the most also along
as below, the data “swell” the most also along  .
.

 on the axis
on the axis  .
. is the mean of data in the original coordinate, then the deviation of
is the mean of data in the original coordinate, then the deviation of  on the axis
on the axis  , as shown in the figure. Hence the variance, I mean the mean of the deviation on is
, as shown in the figure. Hence the variance, I mean the mean of the deviation on is  , where
, where  is the total number of data points. After some deformations, you get the next equation
is the total number of data points. After some deformations, you get the next equation  , where
, where  .
.  , and for mathematical derivation we need some college level calculus, so if that is too much for you, you can skip reading this part till the next section.
, and for mathematical derivation we need some college level calculus, so if that is too much for you, you can skip reading this part till the next section. . Introducing a
. Introducing a  . In conclusion
. In conclusion  satisfies
satisfies  . If you have read my last article on eigenvectors, you wold soon realize that this is an equation for calculating eigenvectors, and that means
. If you have read my last article on eigenvectors, you wold soon realize that this is an equation for calculating eigenvectors, and that means  . We have seen that
. We have seen that  is a the variance of data when projected on a vector
is a the variance of data when projected on a vector 
 , and in fact the matrix is just a constant multiplication of this covariance matrix. I think now you understand that PCA is calculating the orthogonal eigenvectors of covariance matrix of data, that is diagonalizing covariance matrix with orthonormal eigenvectors. Hence we can guess that covariance matrix enables a type of linear transformation of rotation and expansion and contraction of vectors. And data points swell along eigenvectors of such matrix.
, and in fact the matrix is just a constant multiplication of this covariance matrix. I think now you understand that PCA is calculating the orthogonal eigenvectors of covariance matrix of data, that is diagonalizing covariance matrix with orthonormal eigenvectors. Hence we can guess that covariance matrix enables a type of linear transformation of rotation and expansion and contraction of vectors. And data points swell along eigenvectors of such matrix.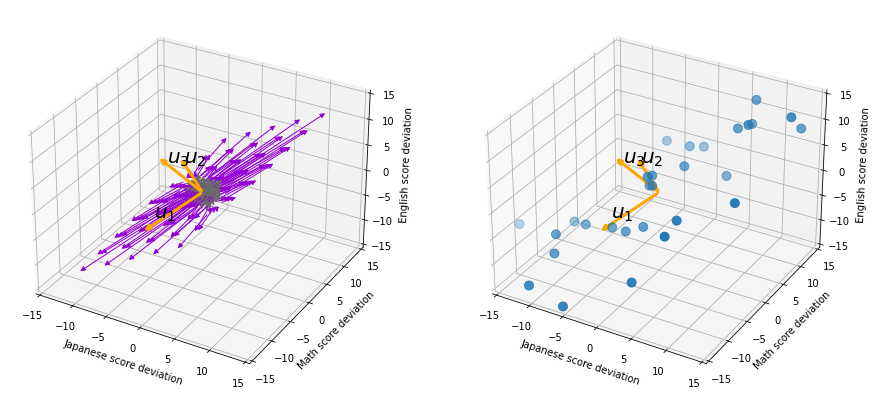
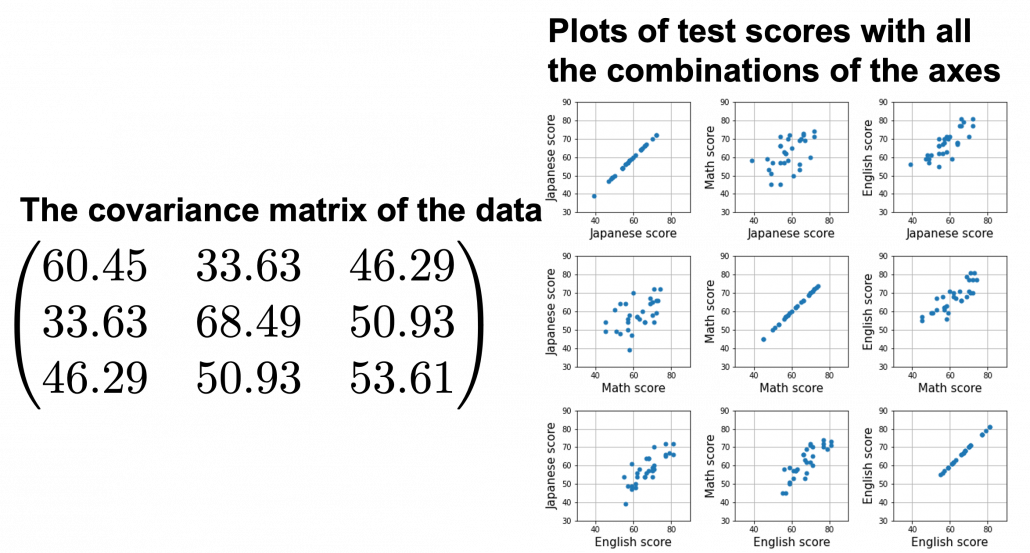
 denote Japanese, Math, English scores respectively. The mean of the data is
denote Japanese, Math, English scores respectively. The mean of the data is  , and the covariance matrix of data in the original coordinate system is
, and the covariance matrix of data in the original coordinate system is  . The eigenvalues of
. The eigenvalues of  are
are  , and
, and  , and their corresponding unit eigenvectors are
, and their corresponding unit eigenvectors are  respectively.
respectively.  is an orthonormal matrix, where
is an orthonormal matrix, where  . As I explained in the last article, you can diagonalize
. As I explained in the last article, you can diagonalize  .
. .
. , and
, and  ).
).  enables a rotation of a rigid body, which means the shape or arrangement of data will not change after the rotation, and
enables a rotation of a rigid body, which means the shape or arrangement of data will not change after the rotation, and  , and
, and  is the coordinate of
is the coordinate of  denotes the coordinate point of the purple point in the red coordinate system.
denotes the coordinate point of the purple point in the red coordinate system.  denotes the coordinates of data projected on new axes
denotes the coordinates of data projected on new axes 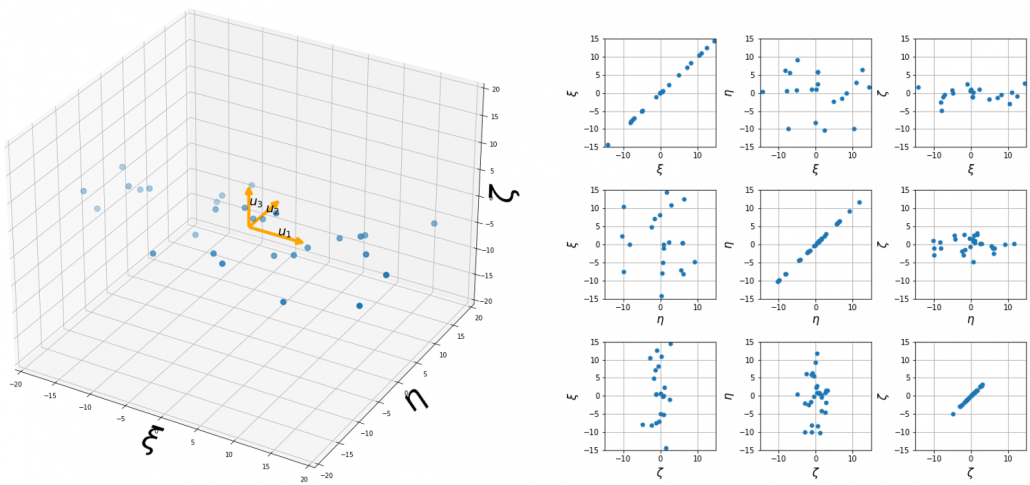
 , which means you can express deviations of the original data as linear combinations of the three factors
, which means you can express deviations of the original data as linear combinations of the three factors  , and
, and  . We expect that those three factors contain keys for understanding the original data more efficiently. If you concretely write down all the equations for the factors:
. We expect that those three factors contain keys for understanding the original data more efficiently. If you concretely write down all the equations for the factors:  ,
,  , and
, and  . If you examine the coefficients of the deviations
. If you examine the coefficients of the deviations  , and
, and  , we can observe that
, we can observe that  almost equally reflects the deviation of the scores of all the subjects, thus we can say
almost equally reflects the deviation of the scores of all the subjects, thus we can say  is
is  . You can see
. You can see  . The variance of data projected on new D-dimensional coordinate system is
. The variance of data projected on new D-dimensional coordinate system is 




 . This means that in the new coordinate system after PCA, covariances between any pair of variants are all zero.
. This means that in the new coordinate system after PCA, covariances between any pair of variants are all zero. .
. . Then it mathematically clearer that we can express the data with two factors: “how smart the student is” and “whether he is at scientific side or liberal art side.”
. Then it mathematically clearer that we can express the data with two factors: “how smart the student is” and “whether he is at scientific side or liberal art side.” is called the contribution ratio of eigenvector
is called the contribution ratio of eigenvector  and
and  are respectively
are respectively  ,
,  ,
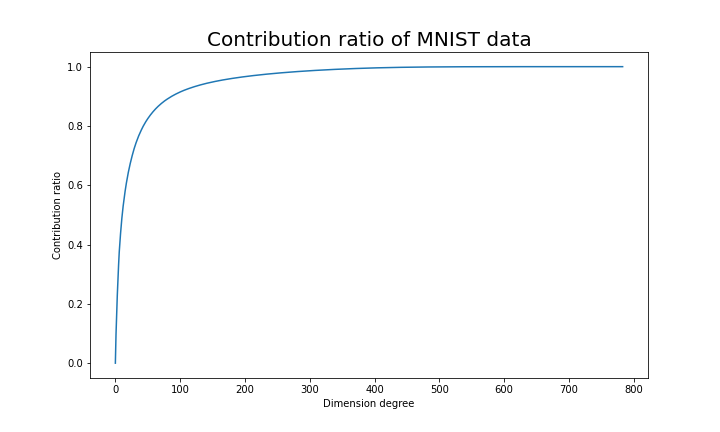
,  . You can decide how many degrees of dimensions you reduce based on this information.
. You can decide how many degrees of dimensions you reduce based on this information.


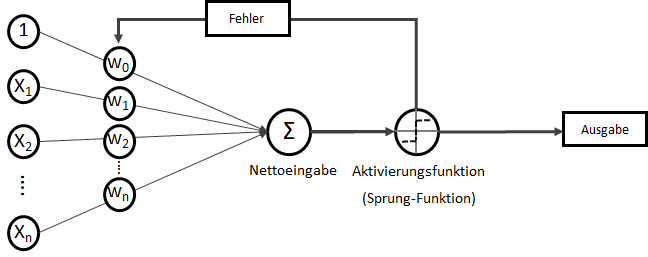
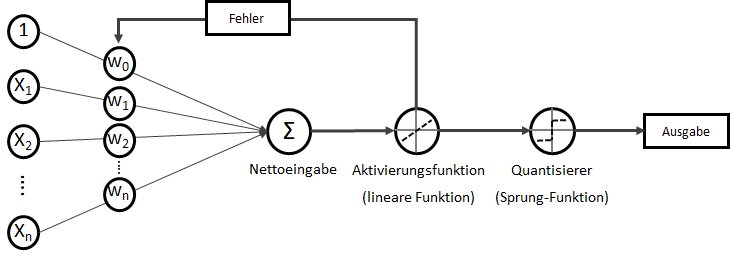
 . Wobei für
. Wobei für  als Bias-Input stets gilt:
als Bias-Input stets gilt:  . Der Bias-Input ist nur ein Platzhalter für das wichtige Bias-Gewicht.
. Der Bias-Input ist nur ein Platzhalter für das wichtige Bias-Gewicht.![\[ x = \begin{bmatrix} x_0\\ x_1\\ x_2\\ x_3\\ \vdots\\ x_n \end{bmatrix} \]](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-3a7aa03dea498a7231e3e497e3e5673d_l3.png "Rendered by QuickLaTeX.com")

![\[ w = \begin{bmatrix} w_0\\ w_1\\ w_2\\ w_3\\ \vdots\\ w_n \end{bmatrix} \]](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-c70ad1733451ddc4512b23f2c739f80e_l3.png "Rendered by QuickLaTeX.com")
 mit
mit  als Y-Achsenschnitt wenn
als Y-Achsenschnitt wenn  .
.![\[ z = w_0 \cdot x_0 + w_1 \cdot x_1 + \dots + w_n \cdot x_n \]](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-3638f2ae3b558db6c95e18057b1b9898_l3.png "Rendered by QuickLaTeX.com")
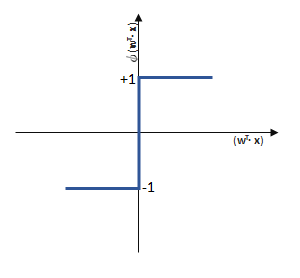
 überschreitet, liefert die Sprungfunktion
überschreitet, liefert die Sprungfunktion  mit der Eingabe
mit der Eingabe 
 .
.![\[ z = w^T \cdot x \]](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-fc9f71e279d7fd0095c17065743df909_l3.png "Rendered by QuickLaTeX.com")
 steht dabei für transponieren. Transponieren bedeutet, dass Spalten zu Zeilen werden – oder umgekehrt.
steht dabei für transponieren. Transponieren bedeutet, dass Spalten zu Zeilen werden – oder umgekehrt. und
und  mit beispielhaften Inhalten:
mit beispielhaften Inhalten:![\[ x = \begin{bmatrix} 5\\ 12\\ 30\\ 2 \end{bmatrix} \]](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-97145f06e658d2f10086bd8c80293749_l3.png "Rendered by QuickLaTeX.com")
![\[ w = \begin{bmatrix} 1\\ 2\\ 5\\ 12 \end{bmatrix} \]](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-6cd08615346cc16d7e8c23bac32c19b9_l3.png "Rendered by QuickLaTeX.com")
![\[ z = w^T \cdot x = \big[1\text{ }2\text{ }5\text{ }12\big] \cdot \begin{bmatrix} 5\\ 12\\ 30\\ 2 \end{bmatrix} = 1 \cdot 5 + 2 \cdot 12 + 5 \cdot 30 + 12 \cdot 2 = 203 \]](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-70a3e9e9243199e97c549d1d9b0f44c0_l3.png "Rendered by QuickLaTeX.com")
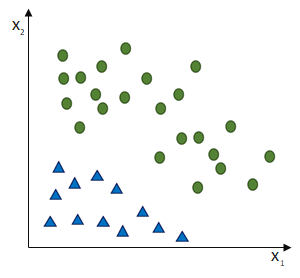
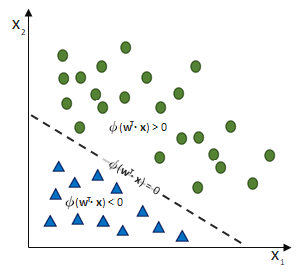



 entgegen des Fehlers (bzw. hin zur jeweils anderen möglichen Antwort) geschieht:
entgegen des Fehlers (bzw. hin zur jeweils anderen möglichen Antwort) geschieht:
 ausgehen.
ausgehen.







 ist und das SLP irrtümlicherweise die Klasse
ist und das SLP irrtümlicherweise die Klasse  ausgewiesen hat, obwohl die korrekte Klasse
ausgewiesen hat, obwohl die korrekte Klasse  wäre. (Und die Schrittweite lassen wir bei
wäre. (Und die Schrittweite lassen wir bei  )
)
 verringert sich entsprechend
verringert sich entsprechend  und somit wird die Wahrscheinlichkeit größer, dass wenn bei der nächsten Iteration (
und somit wird die Wahrscheinlichkeit größer, dass wenn bei der nächsten Iteration ( ) wieder die Klasse +1 korrekt sei, den Schwellwert
) wieder die Klasse +1 korrekt sei, den Schwellwert  zu unterschreiten und auf eben diese korrekte Klasse zu stoßen.
zu unterschreiten und auf eben diese korrekte Klasse zu stoßen. . So würde beispielsweise ein neues
. So würde beispielsweise ein neues  (bei Iteration
(bei Iteration  ) zu einer irrtümlichen Klassifikation
) zu einer irrtümlichen Klassifikation  (
( ) führen, würde die Entscheidungsgrenze zur korrekten Prädiktion der Klasse beim nächsten Durchlauf (
) führen, würde die Entscheidungsgrenze zur korrekten Prädiktion der Klasse beim nächsten Durchlauf ( ) an
) an 
 und
und 
 funktioniert.
funktioniert. springt, wenn z > 0 ist, ansonsten aber
springt, wenn z > 0 ist, ansonsten aber  bleibt.
bleibt.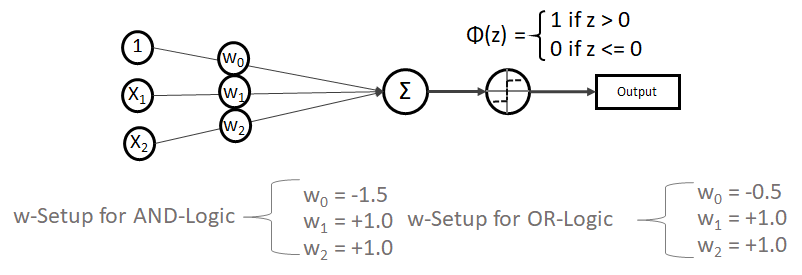
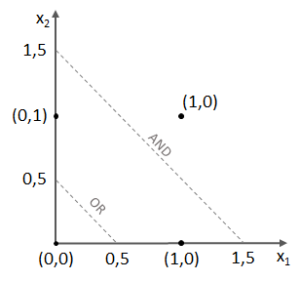
 ,
,
 ,
,
 ,
,
 ,
, ,
, ,
,

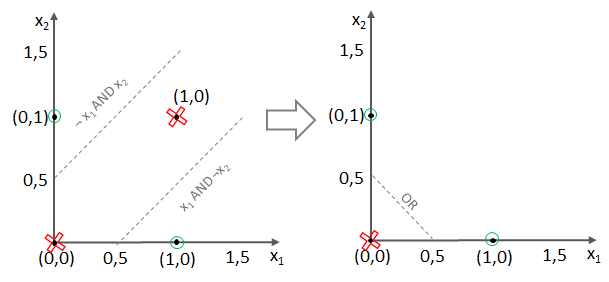
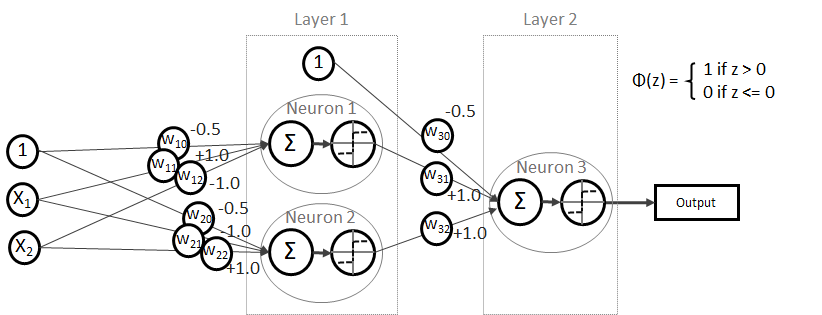
 und somit
und somit 
 und somit
und somit 
 und somit
und somit 
 und somit
und somit 
 und somit
und somit 
 und somit
und somit 
 und somit
und somit 
 und somit
und somit 
 und somit
und somit  und somit
und somit  und somit
und somit