Praxisbeispiel: Data Science im Banking
Wie sich mit Data Science die Profitabilität des Kreditkartengeschäfts einer Bank nachhaltig steigern lässt.
Die Fragestellung
Das Kreditkartengeschäft einer Bank brachte nicht die erhofften Gewinne ein, weshalb die Pricing-Strategie dieses Geschäftszweiges optimiert werden sollte. Hierbei sollte allerdings unbedingt vermieden werden, dass Kund:innen aufgrund erhöhter Zinskosten abspringen.
Die Frage, die sich hieraus ergab, lautete: Welche der Kund:innen würden höhere Zinskosten akzeptieren und welche würden bei einer Erhöhung der Zinsen ihre Kreditkarte kündigen? Um Kündigungen zu vermeiden, sollten deshalb zunächst eindeutige Kundensegmente identifiziert werden. Das Ziel war weiterhin, den weniger preissensitiven Kund:innen neue, lukrativere Kreditprodukte anzubieten, ohne gleichzeitig die Loyalität der Kund:innen zu gefährden.
Das Vorgehen
Um die verschiedenen Kundengruppen zu identifizieren, sollten die Kund:innen mithilfe einer Clustering-Analyse in klar voneinander abgegrenzte Segmente eingeteilt werden. Bei einer Clustering-Analyse handelt es sich um ein maschinelles Lernverfahren, bei dem Datenpunkte, in diesem Fall also Kund:innen zu Clustern oder Segmenten zusammengefasst werden. Bei einer solchen Analyse werden jene Kund:innen zu Clustern zusammengefasst, die sich in vielen Eigenschaften ähneln.
Der Vorteil an diesem Vorgehen ist, dass bei einer Clustering-Analyse eine Vielzahl an Eigenschaften gleichzeitig betrachtet werden kann. Außerdem können die erstellten Segmente dynamisch angepasst werden, wenn neue Daten in die Analyse eingehen. Zudem bietet ein Clustering-Modell die Möglichkeit, neue Kunden zu bewerten und einem bestehenden Cluster zuzuordnen, sofern die entsprechenden Daten über sie vorliegen.
Kunden segmentieren
Die Bank verfügte über vielfältige Daten den Kund:innen. Dazu gehörten persönliche Informationen wie Alter, Geschlecht, Bonität, Anzahl und Art der genutzten Kreditprodukte, Anzahl und Art der mit der Kreditkarte getätigten Transaktionen, aber auch Informationen zur bisherigen Beziehung zwischen Kund:in und Bank, wie beispielsweise Kontaktaufnahmen mit dem Kundenservice, Beschwerden, Net Promoter Score u.s.w.
Nachdem die Kund:innen anhand all dieser Eigenschaften einer Clustering-Analyse unterzogen worden waren, konnten verschiedene Gruppen identifiziert werden. Ein Vergleich dieser Gruppen untereinander ergab, dass es Kund:innen gibt, für die der Umfang der gebotenen Leistungen der Bank wichtiger war als der Zinssatz, also der Preis dieser Leistungen. Diese Kund:innen waren entsprechend als weniger preissensitiv bezüglich der Zinskosten einzuschätzen. In einem weiteren Segment wurden Kunden identifiziert, die eine Steigerung des Zinssatzes akzeptieren würden, weil sie die Kreditkarte sehr häufig verwendeten.
Durch die Bestimmung dieser wenig preissensitiven Cluster war die Bank zunächst in der Lage, diesen Kund:innen neue und lukrativere Kreditprodukte anzubieten.
Kundenloyalität messen
Darüber hinaus war der Bank wichtig, auch die Kundenzufriedenheit und -loyalität genauer zu beobachten, um Abwanderungen zu vermeiden.
Eine Möglichkeit, die Zufriedenheit und Loyalität von Kund:innen einzuschätzen besteht darin, ihre Sprache zu untersuchen, wenn sie im Austausch mit dem Kundenservice stehen. Aufgrund ihrer Wortwahl – ob mündlich oder schriftlich – können KI-Technologien den Emotionszustand der Kund:innen bestimmen. Positive Emotionen können hierbei allgemein als Zeichen der Loyalität und Zufriedenheit gedeutet werden, wohingegen negative Emotionen vor allem in Beschwerden oder schlechten Bewertungen vorkommen, die einen Kundenverlust zur Folge haben können. Das Ziel der Bank war es, Anfragen mit negativen Emotionen, also wahrscheinlich Beschwerden oder negative Bewertungen schneller zu erkennen, um diese priorisiert beantworten zu können und so einen drohenden Kundenverlust zu vermeiden.
In der Sprache ausgedrückte positive oder negative Emotionen können mit einer sogenannten Sentiment Analysis untersucht werden, wobei die Sprache der Kunden – ob schriftlich oder mündlich – mit KI-Technologien untersucht wird. Dafür kommt Natural Language Processing – eine Reihe der KI-Technologien zur Analyse menschlicher Sprache – zur Anwendung. Anhand dieser KI-Technologie wurden eingehende Nachrichten und Bewertungen einer automatischen Voruntersuchung unterzogen. Nachrichten und Bewertungen, die mit negativen Emotionen assoziiert wurden, wurden priorisiert bearbeitet. Durch die priorisierte Bearbeitung konnte eine 50%ige Reduktion der Antwortzeiten auf Beschwerden erzielt werden.
Die Ergebnisse
In diesem Projekt konnte die Bank durch verschiedene Ansätze das Kreditkartengeschäft optimieren sowie die Kundenreaktion auf die Zinssteigerung bzw. die Kundenloyalität in Echtzeit messen:
- Mithilfe von Clustering konnten Kund:innen in Cluster eingeteilt werden, die sich in bestimmten, für die Bank wichtige Eigenschaften stark ähnelten. Durch die Bestimmung wenig preissensitiver Cluster war die Bank in der Lage, diesen Kund:innen neue und lukrativere Kreditprodukte anzubieten, was das Kreditkartengeschäft profitabler machte.
- Mithilfe von Natural Language Processing konnten die Stimmungen der Kund:innen am Telefon mit dem Kundenservice oder per Email erfasst und ausgewertet werden. Negative Nachrichten wurden demzufolge priorisiert bearbeitet, was sich wiederum positiv auf die Kundenzufriedenheit und -loyalität auswirkte.
Neugierig geworden?
Dies ist nur eins von vielen Beispielen, wie Sie mit Data Science im Banking zu Erkenntnissen gelangen, die Sie gewinnbringend bzw. kostensparend einsetzen können.
Qualifizieren Sie sich mit den Seminaren und Trainings der Haufe Akademie rund um das Thema Data Science weiter!
Sie wollen auf Augenhöhe mit Data Scientists kommunizieren und im richtigen Moment die richtigen Fragen stellen können?
Oder Sie wollen selbst tief in die Welt der Data Science eintauchen und programmieren können? Wir bieten Ihnen die Qualifizierungen, die für Sie passen!
Aktuelle Kursangebot des Data Science Blog Sponsors, die Haufe Akademie:


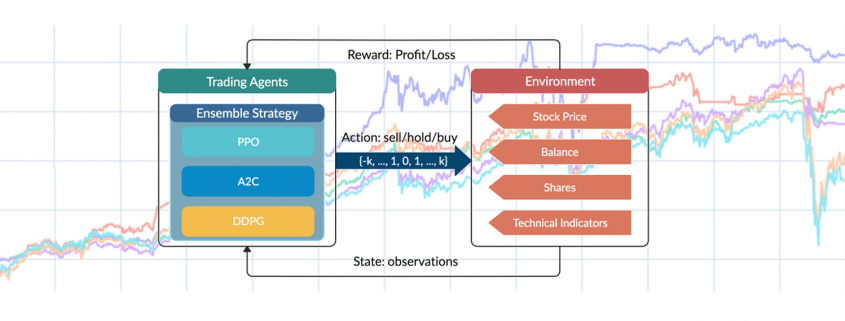
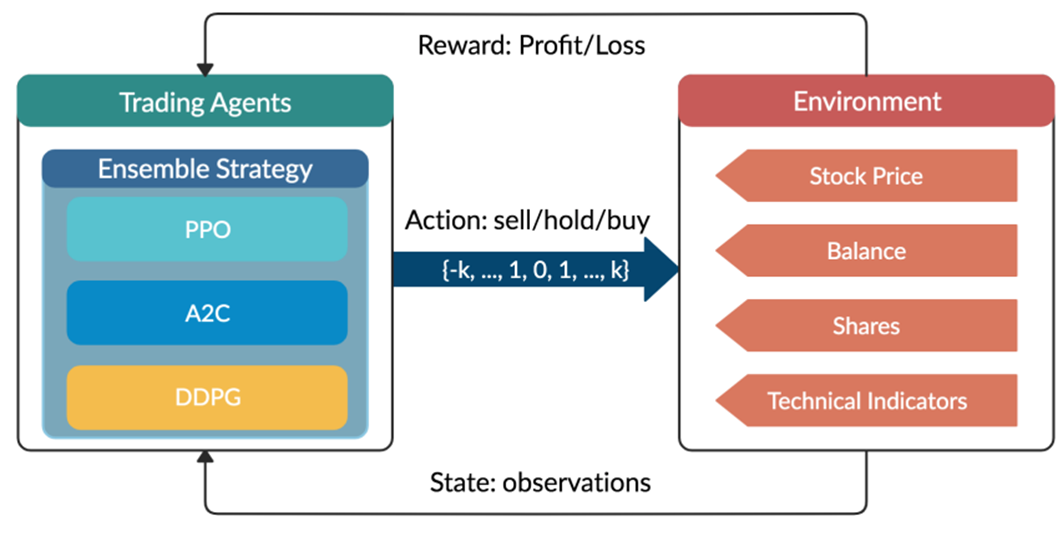
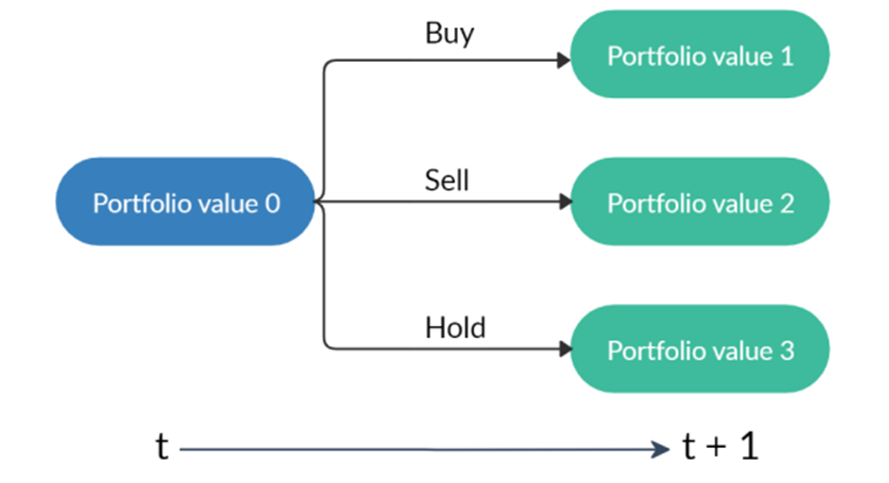
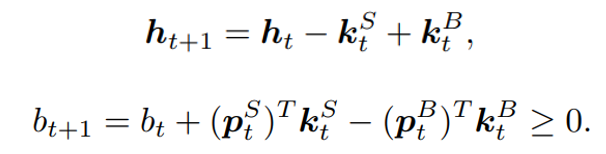
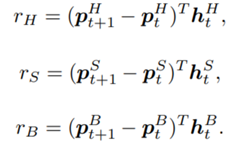
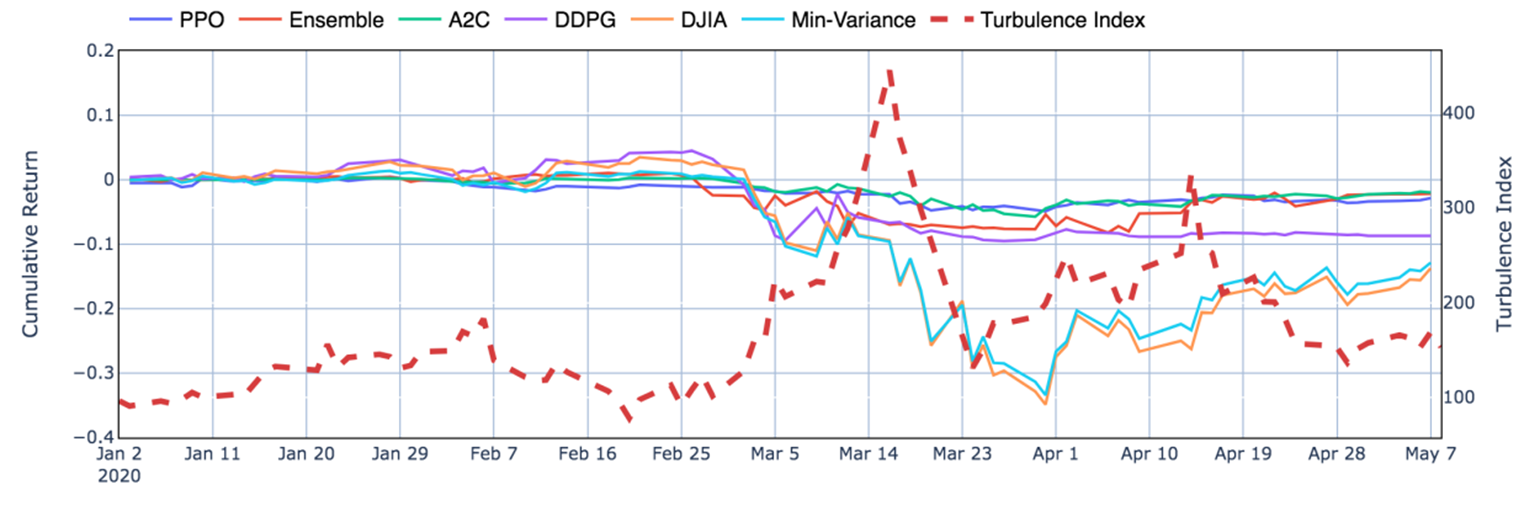
 are initialized to 0, while the policy π(s) is uniformly distributed among all actions. Afterwards, everything is updated through interacting with the stock market environment. By the Bellman Equation,
are initialized to 0, while the policy π(s) is uniformly distributed among all actions. Afterwards, everything is updated through interacting with the stock market environment. By the Bellman Equation,  is the expectation of the sum of direct reward
is the expectation of the sum of direct reward  and the future reqard
and the future reqard  at the next state discounted by a factor γ, resulting in the state-action value function:
at the next state discounted by a factor γ, resulting in the state-action value function:![[b_t, p_t, h_t, M_t, R_t, C_t, X_t]](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-0fbdf800e4e901e62bc4396f3815d15f_l3.png "Rendered by QuickLaTeX.com") storing information about
storing information about : Portfolio balance
: Portfolio balance : Adjusted close prices
: Adjusted close prices : Shares owned of each stock
: Shares owned of each stock : Moving Average Convergence Divergence
: Moving Average Convergence Divergence : Relative Strength Index
: Relative Strength Index : Commodity Channel Index
: Commodity Channel Index : Average Directional Index
: Average Directional Index
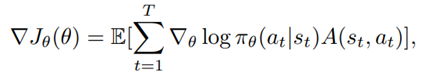
 is the policy network, and
is the policy network, and  is the advantage function to reduce the high variance of it:
is the advantage function to reduce the high variance of it: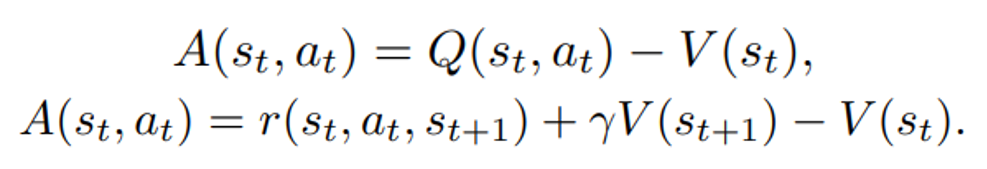
 is the value function of state
is the value function of state  , regardless of actions. DDPG: combines the frameworks of Q-learning and policy gradients and uses neural networks as function approximators; it learns directly from the observations through policy gradient and deterministically map states to actions. The Q-value is updated by:
, regardless of actions. DDPG: combines the frameworks of Q-learning and policy gradients and uses neural networks as function approximators; it learns directly from the observations through policy gradient and deterministically map states to actions. The Q-value is updated by: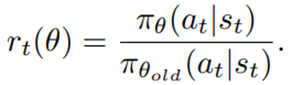



 Torsten Nahm ist Head of Data Science bei der DKB (Deutsche Kreditbank AG) in Berlin. Er hat Mathematik in Bonn mit einem Schwerpunkt auf Statistik und numerischen Methoden studiert. Er war zuvor u.a. als Berater bei KPMG und OliverWyman tätig sowie bei dem FinTech Funding Circle, wo er das Risikomanagement für die kontinentaleuropäischen Märkte geleitet hat.
Torsten Nahm ist Head of Data Science bei der DKB (Deutsche Kreditbank AG) in Berlin. Er hat Mathematik in Bonn mit einem Schwerpunkt auf Statistik und numerischen Methoden studiert. Er war zuvor u.a. als Berater bei KPMG und OliverWyman tätig sowie bei dem FinTech Funding Circle, wo er das Risikomanagement für die kontinentaleuropäischen Märkte geleitet hat.