Business Intelligence Organizations
I am often asked how the Business Intelligence department should be set up and how it should interact and collaborate with other departments. First and foremost: There is no magic recipe here, but every company must find the right organization for itself.
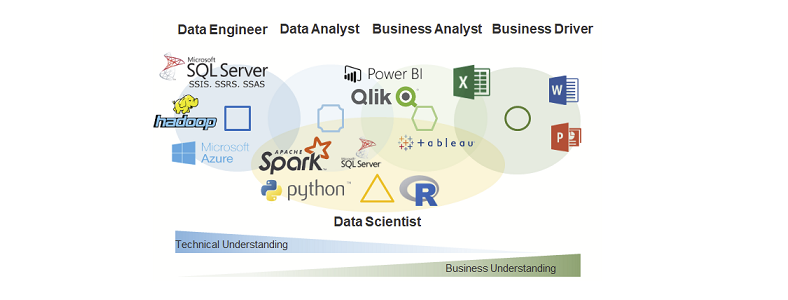
Before we can talk about organization of BI, we need to have a clear definition of roles for team members within a BI department.
A Data Engineer (also Database Developer) uses databases to save structured, semi-structured and unstructured data. He or she is responsible for data cleaning, data availability, data models and also for the database performance. Furthermore, a good Data Engineer has at least basic knowledge about data security and data privacy. A Data Engineer uses SQL and NoSQL-Technologies.
A Data Analyst (also BI Analyst or BI Consultant) uses the data delivered by the Data Engineer to create or adjust data models and implementing business logic in those data models and BI dashboards. He or she needs to understand the needs of the business. This job requires good communication and consulting skills as well as good developing skills in SQL and BI Tools such like MS Power BI, Tableau or Qlik.
A Business Analyst (also Business Data Analyst) is a person form any business department who has basic knowledge in data analysis. He or she has good knowledge in MS Excel and at least basic knowledge in data analysis and BI Tools. A Business Analyst will not create data models in databases but uses existing data models to create dashboards or to adjust existing data analysis applications. Good Business Analyst have SQL Skills.
A Data Scientist is a Data Analyst with extended skills in statistics and machine learning. He or she can use very specific tools and analytical methods for finding pattern in unknow or big data (Data Mining) or to predict events based on pattern calculated by using historized data (Predictive Analytics). Data Scientists work mostly with Python or R programming.

Organization Type 1 – Central Approach (Data Lab)
The first type of organization is the data lab approach. This organization form is easy to manage because it’s focused and therefore clear in terms of budgeting. The data delivery is done centrally by experts and their method and technology knowledge. Consequently, the quality expectation of data delivery and data analysis as well as the whole development process is highest here. Also the data governance is simple and the responsibilities clearly adjustable. Not to be underestimated is the aspect of recruiting, because new employees and qualified applicants like to join a central team of experts.
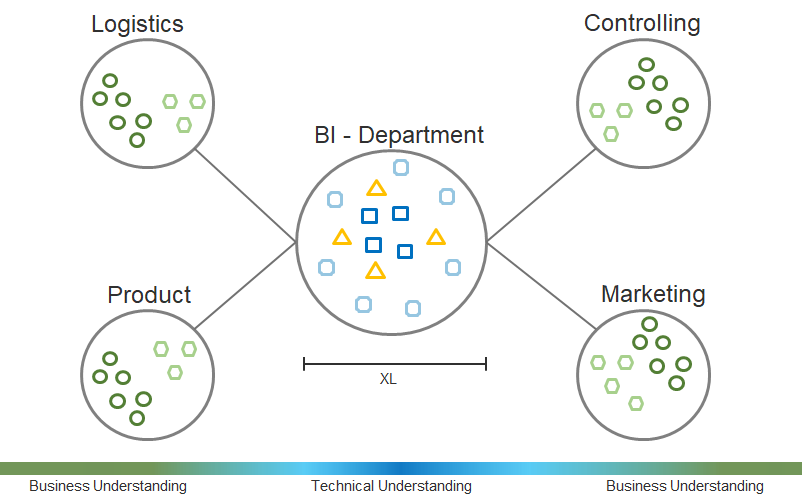
However, this form of organization requires that the company has the right working attitude, especially in the business intelligence department. A centralized business intelligence department acts as a shared service. Accordingly, customer-oriented thinking becomes a prerequisite for the company’s success – and customers here are the other departments that need access to the capacities of those centralized data experts. Communication boundaries must be overcome and ways of simple and effective communication must be found.
Organization Type 2 – Stakeholder Focus Approach
Other companies want to shift more responsibility for data governance, and especially data use and analytics, to those departments where data plays a key role right now. A central business intelligence department manages its own projects, which have a meaning for the entire company. The specialist departments, which have a special need for data analysis, have their own data experts who carry out critical projects for the specialist department. The central Business Intelligence department does not only provide the technical delivery of data, but also through methodical consulting. Although most of the responsibility lies with the Business Intelligence department, some other data-focused departments are at least co-responsible.
The advantage is obvious: There are special data experts who work deeper in the actual departments and feel more connected and responsible to them. The technical-business focus lies on pain points of the company.
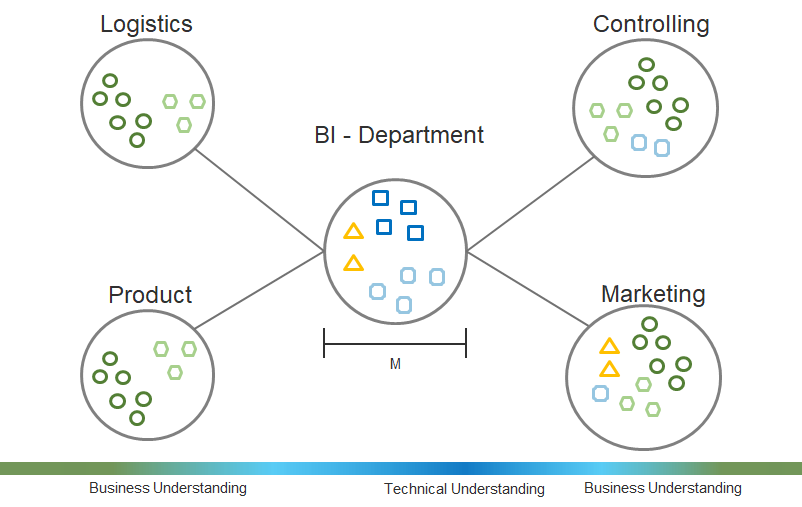
However, this form of Ogranization also has decisive disadvantages: The danger of developing isolated solutions that are so special in some specific areas that they will not really work company-wide increases. Typically the company has to deal with asymmetrical growth of data analytics
know-how. Managing data governance is more complex and recruitment is becoming more difficult as the business intelligence department is weakened and smaller, and data professionals for other departments need to have more business focus, which means they are looking for more specialized profiles.
Organization Type 3 – Decentral Approach
Some companies are also taking a more extreme approach in the other direction. The Business Intelligence department now has only Data Engineers building and maintaining the data warehouse or data lake. As a result, the central department only provides data; it is used and analyzed in all other departments, specifically for the respective applications.
The advantage lies in the personal responsibility of the respective departments as „pain points“ of the company are in focus in belief that business departments know their problems and solutions better than any other department does. Highly specialized data experts can understand colleagues of their own department well and there is no no shared service mindset neccessary, except for the data delivery.
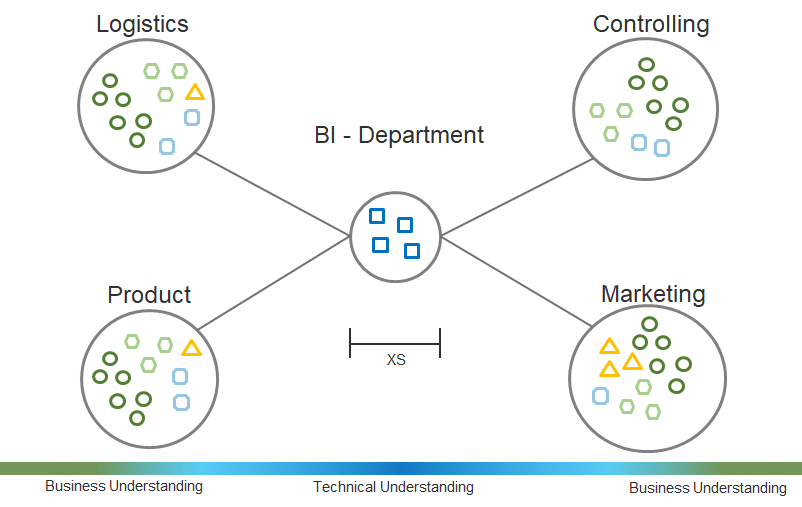
Of course, this organizational form has clear disadvantages since many isolated solutions are unavoidable and the development process of each data-driven solution will be inefficient. These insular solutions may work with luck for your own department, but not for the whole company. There is no one single source of truth. The recruiting process is more difficult as it requires more specialized data experts with more business background. We have to expect an asymmetrical growth of data analytics know-how and a difficult data governance.
