In diesem Artikel soll es im Gegensatz zum vorherigen Artikel Alles über Geodaten weniger darum gehen, was man denn alles mit Geodaten machen kann, dafür aber mehr darum wie man dies anstellt. Es wird gezeigt, wie man aus dem öffentlich verfügbaren Datensatz des OpenStreetMap-Projekts eine Geodatenbank erstellt und einige Beispiele dafür gegeben, wie man diese abfragen und benutzen kann.
Wahl der Datenbank
Prinzipiell gibt es zwei große “geo-kompatible” OpenSource-Datenbanken bzw. “Datenbank-AddOn’s”: Spatialite, welches auf SQLite aufbaut, und PostGIS, das PostgreSQL verwendet.
PostGIS bietet zum Teil eine einfachere Syntax, welche manchmal weniger Tipparbeit verursacht. So kann man zum Beispiel um die Entfernung zwischen zwei Orten zu ermitteln einfach schreiben:
während dies in Spatialite “nur” mit einer normalen Funktion möglich ist:
Trotztdem wird in diesem Artikel Spatialite (also SQLite) verwendet, da dessen Einrichtung deutlich einfacher ist (schließlich sollen interessierte sich alle Ergebnisse des Artikels problemlos nachbauen können, ohne hierfür einen eigenen Datenbankserver aufsetzen zu müssen).
Der Hauptunterschied zwischen PostgreSQL und SQLite (eigentlich der Unterschied zwischen SQLite und den meissten anderen Datenbanken) ist, dass für PostgreSQL im Hintergrund ein Server laufen muss, an welchen die entsprechenden Queries gesendet werden, während SQLite ein “normales” Programm (also kein Client-Server-System) ist welches die Queries selber auswertet.
Hierdurch fällt beim Aufsetzen der Datenbank eine ganze Menge an Konfigurationsarbeit weg: Welche Benutzer gibt es bzw. akzeptiert der Server? Welcher Benutzer bekommt welche Rechte? Über welche Verbindung wird auf den Server zugegriffen? Wie wird die Sicherheit dieser Verbindung sichergestellt? …
Während all dies bei SQLite (und damit auch Spatialite) wegfällt und die Einrichtung der Datenbank eigentlich nur “installieren und fertig” ist, muss auf der anderen Seite aber auch gesagt werden dass SQLite nicht gut für Szenarien geeignet ist, in welchen viele Benutzer gleichzeitig (insbesondere schreibenden) Zugriff auf die Datenbank benötigen.
Benötigte Software und ein Beispieldatensatz
Was wird für diesen Artikel an Software benötigt?
– SQLite3 als Datenbank
– libspatialite als “Geoplugin” für SQLite
– spatialite-tools zum erstellen der Datenbank aus dem OpenStreetMaps (*.osm.pbf) Format
– python3, die beiden GeoModule spatialite, folium und cartopy, sowie die Module pandas und matplotlib (letztere gehören im Bereich der Datenauswertung mit Python sowieso zum Standart). Für pandas gibt es noch die Erweiterung geopandas sowie eine praktisch unüberschaubare Anzahl weiterer geographischer Module aber bereits mit den genannten lassen sich eine Menge interessanter Dinge herausfinden.
– und natürlich einen Geodatensatz: Zum Beispiel sind aus dem OpenStreetMap-Projekt extrahierte Datensätze hier zu finden.
Es ist ratsam, sich hier erst einmal einen kleinen Datensatz herunterzuladen (wie zum Beispiel einen der Stadtstaaten Bremen, Hamburg oder Berlin). Zum einen dauert die Konvertierung des .osm.pbf-Formats in eine Spatialite-Datenbank bei größeren Datensätzen unter Umständen sehr lange, zum anderen ist die fertige Datenbank um ein vielfaches größer als die stark gepackte Originaldatei (für “nur” Deutschland ist die fertige Datenbank bereits ca. 30 GB groß und man lässt die Konvertierung (zumindest am eigenen Laptop) am besten über Nacht laufen – willkommen im Bereich “BigData”).
Erstellen eine Geodatenbank aus OpenStreetMap-Daten
Nach dem Herunterladen eines Datensatzes der Wahl im *.osm.pbf-Format kann hieraus recht einfach mit folgendem Befehl aus dem Paket spatialite-tools die Datenbank erstellt werden:
|
|
spatialite_osm_map -o bremen-latest.osm.pbf -d bremen-latest.sqlite |
Erkunden der erstellten Geodatenbank
Nach Ausführen des obigen Befehls sollte nun eine Datei mit dem gewählten Namen (im Beispiel bremen-latest.sqlite) im aktuellen Ordner vorhanden sein – dies ist bereits die fertige Datenbank. Zunächst sollte man mit dieser Datenbank erst einmal dasselbe machen, wie mit jeder anderen Datenbank auch: Sich erst einmal eine Weile hinsetzen und schauen was alles an Daten in der Datenbank vorhanden und vor allem wo diese Daten in der erstellten Tabellenstruktur zu finden sind. Auch wenn dieses Umschauen prinzipiell auch vollständig über die Shell oder in Python möglich ist, sind hier Programme mit graphischer Benutzeroberfläche (z. B. spatialite-gui oder QGIS) sehr hilfreich und sparen nicht nur eine Menge Zeit sondern vor allem auch Tipparbeit. Wer dies tut, wird feststellen, dass sich in der generierten Datenbank einige dutzend Tabellen mit Namen wie pt_addresses, ln_highway und pg_boundary befinden.
Die Benennung der Tabellen folgt dem Prinzip, dass pt_*-Tabellen Punkte im Geokoordinatensystem wie z. B. Adressen, Shops, Bäckereien und ähnliches enthalten. ln_*-Tabellen enthalten hingegen geographische Entitäten, welche sich als Linien darstellen lassen, wie beispielsweise Straßen, Hochspannungsleitungen, Schienen, ect. Zuletzt gibt es die pg_*-Tabellen welche Polygone – also Flächen einer bestimmten Form enthalten. Dazu zählen Landesgrenzen, Bundesländer, Inseln, Postleitzahlengebiete, Landnutzung, aber auch Gebäude, da auch diese jeweils eine Grundfläche besitzen. In dem genannten Datensatz sind die Grundflächen von Gebäuden – zumindest in Europa – nahezu vollständig. Aber auch der Rest der Welt ist für ein “Wikipedia der Kartographie” insbesondere in halbwegs besiedelten Gebieten bemerkenswert gut erfasst, auch wenn nicht unbedingt davon ausgegangen werden kann, dass abgelegenere Gegenden (z. B. irgendwo auf dem Land in Südamerika) jedes Gebäude eingezeichnet ist.
Verwenden der Erstellten Datenbank
Auf diese Datenbank kann nun entweder direkt aus der Shell über den Befehl
|
|
spatialite bremen-latest.sqlite |
zugegriffen werden oder man nutzt das gleichnamige Python-Paket:
|
|
import spatialite import pandas as pd conn = spatialite.connect('bremen-latest.sqlite') |
Nach Eingabe der obigen Befehle in eine Python-Konsole, ein Jupyter-Notebook oder ein anderes Programm, welches die Anbindung an den Python-Interpreter ermöglicht, können die von der Datenbank ausgegebenen Ergebnisse nun direkt in ein Pandas Data Frame hineingeladen und verwendet/ausgewertet/analysiert werden.
Im Grunde wird hierfür “normales SQL” verwendet, wie in anderen Datenbanken auch. Der folgende Beispiel gibt einfach die fünf ersten von der Datenbank gefundenen Adressen aus der Tabelle pt_addresses aus:
|
|
query = ''' SELECT * FROM pt_addresses LIMIT 5; ''' df_addresses = pd.read_sql_query(query, conn, index_col='id') df_addresses |
Link zur Ausgabe
Es wird dem Leser sicherlich aufgefallen sein, dass die Spalte “Geometry” (zumindest für das menschliche Auge) nicht besonders ansprechend sowie auch nicht informativ aussieht: Der Grund hierfür ist, dass diese Spalte die entsprechende Position im geographischen Koordinatensystem aus Gründen wie dem deutlich kleineren Speicherplatzbedarf sowie der damit einhergehenden Optimierung der Geschwindigkeit der Datenbank selber, in binärer Form gespeichert und ohne weitere Verarbeitung auch als solche ausgegeben wird.
Glücklicherweise stellt spatialite eine ganze Reihe von Funktionen zur Verarbeitung dieser geographischen Informationen bereit, von denen im folgenden einige beispielsweise vorgestellt werden:
Für einzelne Punkte im Koordinatensystem gibt es beispielsweise die Funktionen X(geometry) und Y(geometry), welche aus diesem “binären Wirrwarr” den Längen- bzw. Breitengrad des jeweiligen Punktes als lesbare Zahlen ausgibt.
Ändert man also das obige Query nun entsprechend ab, erhält man als Ausgabe folgendes Ergebnis in welchem die Geometry-Spalte der ausgegebenen Adressen in den zwei neuen Spalten Longitude und Latitude in lesbarer Form zu finden ist:
|
|
query = ''' SELECT id, country, city, postcode, street, housename, housenumber, X(geometry) AS Latitude, Y(geometry) AS Longitue FROM pt_addresses LIMIT 5; ''' df_addresses = pd.read_sql_query(query, conn, index_col='id') df_addresses |
Link zur Tabelle
Eine weitere häufig verwendete Funktion von Spatialite ist die Distance-Funktion, welche die Distanz zwischen zwei Orten berechnet.
Das folgende Beispiel sucht in der Datenbank die 10 nächstgelegenen Bäckereien zu einer frei wählbaren Position aus der Datenbank und listet diese nach zunehmender Entfernung auf (Achtung – die frei wählbare Position im Beispiel liegt in München, wer die selbe Position z. B. mit dem Bremen-Datensatz verwendet, wird vermutlich etwas weiter laufen müssen…):
|
|
position = (11.4183792, 48.1527277) query = ''' SELECT Distance(MakePoint''' + str(position) + ''', geometry, 1) AS [Entfernung (m)], name AS Name, X(geometry) AS Latitude, Y(geometry) AS Longitude FROM pt_shop WHERE sub_type = 'bakery' ORDER BY Distance(MakePoint''' + str(position) + ''', geometry) LIMIT 10; ''' df = pd.read_sql_query(query, con) df |
Link zur Ausgabe
Ein Anwendungsfall für eine solche Liste können zum Beispiel Programme/Apps wie maps.me oder Google-Maps sein, in denen User nach Bäckereien, Geldautomaten, Supermärkten oder Apotheken “in der Nähe” suchen können sollen.
Diese Liste enthält nun alle Informationen die grundsätzlich gebraucht werden, ist soweit auch informativ und wird in den meißten Fällen der Datenauswertung auch genau so gebraucht, jedoch ist diese für das Auge nicht besonders ansprechend.
Viel besser wäre es doch, die gefundenen Positionen auf einer interaktiven Karte einzuzeichnen:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
import folium from folium import features m = folium.Map([position[1], position[0]], zoom_start=14) mks = [features.Marker([i[1]['Longitude'], i[1]['Latitude']]) for i in df.iterrows()] pps = [folium.Popup(i[1]['Name']) for i in df.iterrows()] for n in range(len(mks)): mks[n].add_child(pps[n]) m.add_child(mks[n]) m.save(os.path.join('mymap.html')) m |
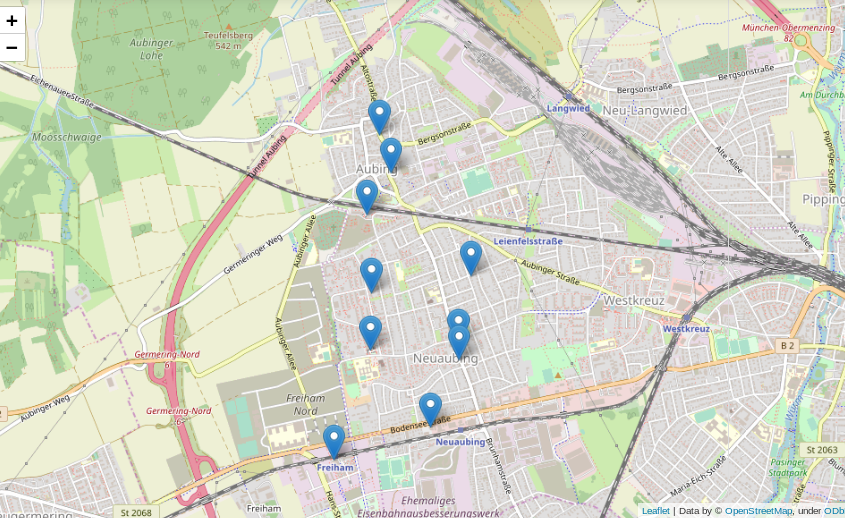
Was kann man sonst interessantes mit der erstellten Datenbank und etwas Python machen? Wer in Deutschland ein wenig herumgekommen ist, dem ist eventuell aufgefallen, dass sich die Endungen von Ortsnamen stark unterscheiden: Um München gibt es Stadteile und Dörfer namens Garching, Freising, Aubing, ect., rund um Stuttgart enden alle möglichen Namen auf “ingen” (Plieningen, Vaihningen, Echterdingen …) und in Berlin gibt es Orte wie Pankow, Virchow sowie eine bunte Auswahl weiterer *ow’s.
Das folgende Query spuckt gibt alle “village’s”, “town’s” und “city’s” aus der Tabelle pt_place, also Dörfer und Städte, aus:
|
|
# Finde alle Village's, Town's und City's in Deutschland query = ''' SELECT name AS Name, X(geometry) AS Longitude, Y(geometry) AS Latitude FROM pt_place WHERE sub_type IN ('village', 'town', 'city'); ''' dforte = pd.read_sql_query(query, con) dforte |
Link zur Ausgabe
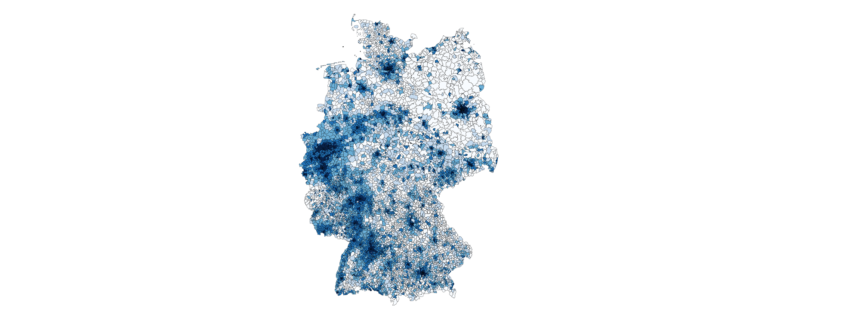
Graphisch mit matplotlib und cartopy in ein Koordinatensystem eingetragen sieht diese Verteilung folgendermassen aus:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
from matplotlib import pyplot as plt import cartopy.crs as ccrs import cartopy.feature as cfeature handles = [] plt.figure(num=None, figsize=(8, 6), dpi=100, facecolor='w', edgecolor='k') ax = plt.axes(projection=ccrs.PlateCarree()) ax.add_feature(cfeature.COASTLINE) ax.add_feature(cfeature.BORDERS) for suffix in 'ingen ing ow'.split(): matches = [(i[1]['Longitude'], i[1]['Latitude']) for i in dforte.iterrows() if i[1]['Name'].__class__ == ''.__class__ and i[1]['Name'].endswith(suffix)] handles.append(ax.scatter([i[0] for i in matches], [i[1] for i in matches], alpha=0.5)) plt.legend(labels='ingen ing ow'.split(), handles=handles) plt.savefig('ortsnamen_coastlines_boarders.png') plt.show() |
Die Grafik zeigt, dass stark unterschiedliche Vorkommen der verschiedenen Ortsendungen in Deutschland (Clustering). Über das genaue Zustandekommen dieser Verteilung kann ich hier nur spekulieren, jedoch wird diese vermutlich ähnlichen Prozessen unterliegen wie beispielsweise die Entwicklung von Dialekten.
Wer sich die Karte etwas genauer anschaut wird merken, dass die eingezeichneten Landesgrenzen und Küstenlinien nicht besonders genau sind. Hieran wird ein interessanter Effekt von häufig verwendeten geographischen Entitäten, nämlich Linien und Polygonen deutlich. Im Beispiel werden durch die beiden Zeilen
|
|
ax.add_feature(cfeature.COASTLINE) ax.add_feature(cfeature.BORDERS) |
die bereits im Modul cartopy hinterlegten Daten verwendet. Genaue Verläufe von Küstenlinien und Landesgrenzen benötigen mit wachsender Genauigkeit hingegen sehr viel Speicherplatz, da mehr und mehr zu speichernde Punkte benötigt werden (genaueres siehe hier).
Schlussfolgerung
Man kann also bereits mit einigen Grundmodulen und öffentlich verfügbaren Datensätzen eine ganze Menge im Bereich der Geodaten erkunden und entdecken. Gleichzeitig steht, insbesondere für spezielle Probleme, eine große Bandbreite weiterer Software zur Verfügung, für welche dieser Artikel zwar einen Grundsätzlichen Einstieg geben kann, die jedoch den Rahmen dieses Artikels sprengen würden.


















 Miroslav Šedivý is a Senior Software Architect at UBIMET GmbH, using Python to make the sun shine and the wind blow. He is an enthusiast of both human and programming languages and found Python as his language of choice to setup very productive environments. Mr. Šedivý was born in Czechoslovakia, studied in France and is now living in Germany. Furthermore, he helps in the organization of the events PyCon.DE and Polyglot Gathering.
Miroslav Šedivý is a Senior Software Architect at UBIMET GmbH, using Python to make the sun shine and the wind blow. He is an enthusiast of both human and programming languages and found Python as his language of choice to setup very productive environments. Mr. Šedivý was born in Czechoslovakia, studied in France and is now living in Germany. Furthermore, he helps in the organization of the events PyCon.DE and Polyglot Gathering.
