Digital und Data braucht Vorantreiber
2020 war das Jahr der Trendwende hin zu mehr Digitalisierung in Unternehmen: Telekommunikation und Tools für Unified Communications & Collaboration (UCC) wie etwa Microsoft Teams oder Skype boomen genauso wie der digitale Posteingang und das digitale Signieren von Dokumenten. Die Vernetzung und Automatisierung ganz im Sinne der Industrie 4.0 finden nicht nur in der Produktion und Logistik ihren Einzug, sondern beispielsweise auch in Form der Robot Process Automation (RPA) ins Büro – bei vielen Unternehmen ein aktuelles Top-Thema. Und in Zeiten, in denen der öffentliche Verkehr zum unangenehmen Gesundheitsrisiko wird und der Individualverkehr wieder cool ist, boomen digital unterstützte Miet- und Sharing-Angebote für Automobile mehr als je zuvor, gleichwohl autonome Fahrzeuge oder post-ausliefernde Drohnen nach wie vor schmerzlich vermisst werden.
Nahezu jedes Unternehmen muss in der heutigen Zeit nicht nur mit der Digitalisierung der Gesellschaft mithalten, sondern auch sich selbst digital organisieren können und bestenfalls eigene Innovationen vorantreiben. Hierfür ist sollte es mindestens eine verantwortliche Stelle geben, den Chief Digital Officer.
Chief Digital Officer gelten spätestens seit 2020 als Problemlöser in der Krise
Einem Running Gag zufolge haben wir den letzten Digitalisierungsvorschub keinem menschlichen Innovator, sondern der Corona-Pandemie zu verdanken. Und tatsächlich erzwang die Pandemie insbesondere die verstärkte Etablierung von digitalen Alternativen für die Kommunikation und Zusammenarbeit im Unternehmen sowie noch digitalere Shop- und Lieferdiensten oder auch digitale Qualifizierungs- und Event-Angebote. Dennoch scheint die Pandemie bisher noch mit überraschend wenig Innovationskraft verbunden zu sein, denn die meisten Technologien und Konzepte der Digitalisierung waren lange vorher bereits auf dem Erfolgskurs, wenn auch ursprünglich mit dem Ziel der Effizienzsteigerung im Unternehmen statt für die Einhaltung von Abstandsregeln. Die eigentlichen Antreiber dieser Digitalisierungsvorhaben waren bereits lange vorher die Chief Digital Officer (CDO).
Zugegeben ist der Grad an Herausforderung nicht für alle CDOs der gleiche, denn aus unterschiedlichen Branchen ergeben sich unterschiedliche Schwerpunkte. Die Finanzindustrie arbeitet seit jeher im Kern nur mit Daten und betrachtet Digitalisierung eher nur aus der Software-Perspektive. Die produzierende Industrie hat mit der Industrie 4.0 auch das Themenfeld der Vernetzung größere Hürden bei der umfassenden Digitalisierung, aber auch die Logistik- und Tourismusbranchen müssen digitalisieren, um im internationalen Wettbewerb nicht den Boden zu verlieren.
Digitalisierung ist ein alter Hut, aber aktueller denn je
Immer wieder wird behauptet, Digitalisierung sei neu oder – wie zuvor bereits behauptet – im Kern durch Pandemien getrieben. Dabei ist, je nach Perspektive, der Hauptteil der Digitalisierung bereits vor Jahrzehnten mit der Einführung von Tabellenkalkulations- sowie ERP-Software vollzogen. Während in den 1980er noch Briefpapier, Schreibmaschinen, Aktenordner und Karteikarten die Bestellungen auf Kunden- wie auf Lieferantenseite beherrschten, ist jedes Unternehmen mit mehr als hundert Mitarbeiter heute grundsätzlich digital erfasst, wenn nicht gar längst digital gesteuert. Und ERP-Systeme waren nur der Anfang, es folgten – je nach Branche und Funktion – viele weitere Systeme: MES, CRM, SRM, PLM, DMS, ITS und viele mehr.
Zwischenzeitlich kamen um die 2000er Jahre das Web 2.0, eCommerce und Social Media als nächste Evolutionsstufe der Digitalisierung hinzu. Etwa ab 2007 mit der Vorstellung des Apple iPhones, verstärkt jedoch erst um die 2010er Jahre durchdrangen mobile Endgeräte und deren mobile Anwendungen als weitere Befähiger und Game-Changer der Digitalisierung den Markt, womit auch Gaming-Plattformen sich wandelten und digitale Bezahlsysteme etabliert werden konnten. Zeitlich darauf folgten die Trends Big Data, Blockchain, Kryptowährungen, Künstliche Intelligenz, aber auch eher hardware-orientierte Themen wie halb-autonom fahrende, schwimmende oder fliegende Drohnen bis heute als nächste Evolutionsschritte der Digitalisierung.
Dieses Alter der Digitalisierung sowie der anhaltende Trend zur weiteren Durchdringung und neuen Facetten zeigen jedoch auch die Beständigkeit der Digitalisierung als Form des permanenten Wandels und dem Data Driven Thinking. Denn heute bestreben Unternehmen auch Mikroprozesse zu digitalisieren und diese besser mit der Welt interagieren zu lassen. Die Digitalisierung ist demzufolge bereits ein Prozess, der seit Jahrzehnten läuft, bis heute anhält und nur hinsichtlich der Umsetzungsschwerpunkte über die Jahre Verschiebungen erfährt – Daher darf dieser Digitalisierungsprozess keinesfalls aus dem Auge verloren werden. Digitalisierung ist kein Selbstzweck, sondern ein Innovationsprozess zur Erhaltung der Wettbewerbsfähigkeit am Markt.
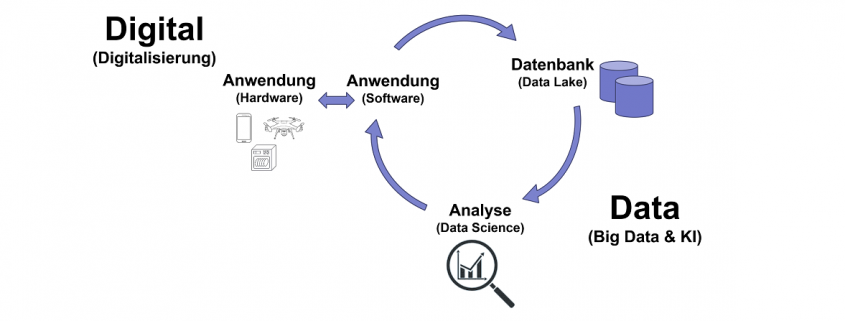
Digital ist nicht Data, aber Data ist die Konsequenz aus Digital
Trotz der längst erreichten Etablierung des CDOs als wichtige Position im Unternehmen, gilt der Job des CDOs selbst heute noch als recht neu. Zudem hatte die Position des CDOs keinen guten Start, denn hinsichtlich der Zuständigkeit konkurriert der CDO nicht nur sowieso schon mit dem CIO oder CTO, er macht sich sogar selbst Konkurrenz, denn er ist namentlich doppelbesetzt: Neben dem Chief Digital Officer gibt es ebenso auch den noch etwas weniger verbreiteten Chief Data Officer. Doch spielt dieser kleine namentliche Unterschied eine Rolle? Ist beides nicht doch das gemeinsame Gleiche?
Die Antwort darauf lautet ja und nein. Der CDO befasst sich mit den zuvor bereits genannten Themen der Digitalisierung, wie mobile Anwendungen, Blockchain, Internet of Thing und Cyber Physical Systems bzw. deren Ausprägungen als vernetze Endgeräte entsprechend der Konzepte wie Industrie 4.0, Smart Home, Smart Grid, Smart Car und vielen mehr. Die einzelnen Bausteine dieser Konzepte generieren Daten, sind selbst jedoch Teilnehmer der Digitalisierungsevolution. Diese Teilnehmer aus Hardware und Software generieren über ihren Einsatz Daten, die wiederum in Datenbanken gespeichert werden können, bis hin zu großen Volumen aus heterogenen Datenquellen, die gelegentlich bis nahezu in Echtzeit aktualisiert werden (Big Data). Diese Daten können dann einmalig, wiederholt oder gar in nahezu Echtzeit automatisch analysiert werden (Data Science, KI) und die daraus entstehenden Einblicke und Erkenntnisse wiederum in die Verbesserung der digitalen Prozesse und Produkte fließen.
Folglich befassen sich Chief Digital Officer und Chief Data Officer grundsätzlich im Kern mit unterschiedlichen Themen. Während der Chief Digital Officer sich um die Hardware- und Software im Kontext zeitgemäßer Digitalisierungsvorhaben und deren organisatorische Einordnung befasst, tut dies der Chief Data Officer vor allem im Kontext der Speicherung und Analyse von Daten sowie der Data Governance.
Treffen werden sich Digital und Data jedoch immer wieder im Kreislauf der kontinuierlichen Verbesserung von Produkt und Prozess, insbesondere bei der Gestaltung und Analyse der Digital Journey für Mitarbeiter, Kunden und Partnern und Plattform-Entscheidungen wie etwas Cloud-Systeme.
Oftmals differenzieren Unternehmen jedoch gar nicht so genau und betrachten diese Position als Verantwortliche für sowohl Digital als auch für Data und nennen diese Position entweder nach dem einen oder nach dem anderen – jedoch mit Zuständigkeiten für beides. In der Tat verfügen heute nur sehr wenige Unternehmen über beide Rollen, sondern haben einen einzigen CDO. Für die meisten Anwender klingt das trendige Digital allerdings deutlich ansprechender als das nüchterne Data, so dass die Namensgebung der Position eher zum Chief Digital Officer tendieren mag. Nichtsdestotrotz sind Digital-Themen von den Data-Themen recht gut zu trennen und sind strategisch unterschiedlich einzuordnen. Daher benötigen Unternehmen nicht nur eine Digital-, sondern ebenso eine Datenstrategie – Doch wie bereits angedeutet, können CDOs beide Rollen übernehmen und sich für beide Strategien verantwortlich fühlen.
Die gemeinsame Verantwortung von Digital und Data kann sogar als vorteilhafte Nebenwirkung besonders konsistente Entscheidungen ermöglichen und so typische Digital-Themen wie Blockchain oder RPA mit typischen Data-Themen wie Audit-Datenanalysen oder Process Mining verbinden. Oder der Dokumenten-Digitalisierung und -Verwaltung in der kombinierten Betrachtung mit Visual Computing (Deep Learning zur Bilderkennung).
Vielfältige Kompetenzen und Verantwortlichkeiten eines CDOs
Chief Digital Officer befassen sich mit Innovationsthemen und setzen sie für ihr Unternehmen um. Sie sind folglich auch Change Manager. CDOs dürfen keinesfalls bequeme Schönwetter-Manager sein, sondern müssen den Wandel im Unternehmen vorantreiben, Hemmnissen entgegenstehen und bestehende Prozesse und Produkte hinterfragen. Die Schaffung und Nutzung von digitalen Produkten und Prozessen im eigenen Unternehmen sowie auch bei Kunden und Lieferanten generiert wiederum Daten in Massen. Der Kreislauf zwischen Digital und Data treibt einen permanenten Wandel an, den der CDO für das Unternehmen positiv nutzbar machen muss und dabei immer neue Karriereperspektiven für sich und seine Mitarbeiter schaffen kann.
Zugegeben sind das keine guten Nachrichten für Mitarbeiter, die auf Beständigkeit setzen. Die Iterationen des digitalen Wandels zirkulieren immer schneller und stellen Ingenieure, Software-Entwickler, Data Scientists und andere Technologieverantwortliche vor den Herausforderungen des permanenten und voraussichtlich lebenslangen Lernens. Umso mehr muss ein CDO hier lernbereit und dennoch standhaft bleiben, denn Gründe für den Aufschub von Veränderungen findet im Zweifel jede Belegschaft.
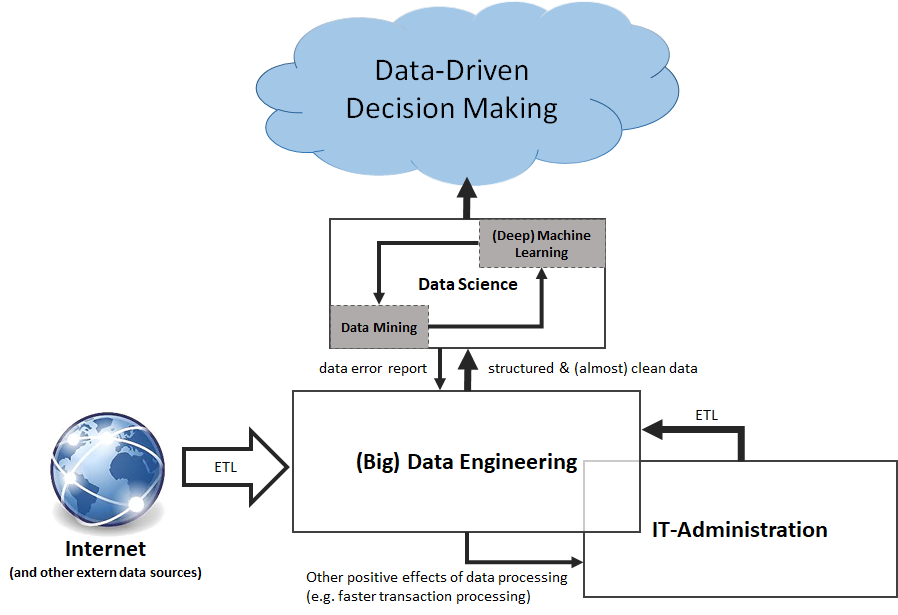
Ein CDO mit umfassender Verantwortung lässt auch das Thema der Datennutzung nicht aus und versteht Architekturen für Business Intelligence und Machine Learning. Um seiner Personalverantwortung gerecht zu werden, muss er sich mit diesen Themen auskennen und mit Experten für Digital und Data auf Augenhöhe sprechen können. Jeder CD sollte wissen, was zum Beispiel ein Data Engineer oder Data Scientist können muss, wie Business-Experten zu verstehen und Vorstände zu überzeugen sind – Denn als Innovator, Antreiber und Wandler fürchten gute CDOs nichts außer den Stillstand.








 scientists, which will involve more sophisticated analysis, predictive modeling, regressions and Bayesian classification. That stuff at scale doesn’t work well on anyone’s engine right now. If you want to do complex analytics on big data, you have a big problem right now.”
scientists, which will involve more sophisticated analysis, predictive modeling, regressions and Bayesian classification. That stuff at scale doesn’t work well on anyone’s engine right now. If you want to do complex analytics on big data, you have a big problem right now.”